1. Introduction
Nowadays, most transactions take place online, meaning that credit cards and other payment systems are involved. These methods are convenient both for the companies and for the consumers. In the midst of all this are the banks, which must make sure that all the transactions are legal and non-fraudulent. This is an arduous and complicated task, due to fraudsters always trying to make every fraudulent transaction seem legitimate, which makes fraud detection a very challenging and difficult task [
1]. For this reason, banks need to hire skilled software engineers and experts in fraud detection, but they also need to use specialized software, and altogether, it can be very expensive. Traditionally, fraud detection has been based on expert systems [
2], which are techniques that solve problems and answers questions within a specific context. The great problem with these expert systems is that the more specialized they are, the more expensive they are to maintain [
2]. Artificial intelligence (AI) has the potential to disrupt and redefine the existing financial services industry. In the general context of AI, there is machine learning (ML), which encompasses models for prediction and pattern recognition that require limited human intervention. In the financial services industry, the application of ML methods has the potential to improve outcomes for both businesses and consumers, and it can be a powerful tool against the credit fraud. At present, many works [
1,
3,
4,
5] are being devoted to develop ML models against credit fraud. Using ML to generate prediction models can improve efficiency, reduce costs, enhance quality, and raise customer satisfaction [
6]. Nevertheless, one of the big challenges and a potentially large obstacle in these models is their lack of transparency in decision making. These models are often black boxes, as we only know their inputs and outputs, but not the processes running inside. This makes them hard to comprehensively understand, and their properties are complicated to validate, so certain forms of risks could go undetected. This type of complexity constitutes a significant barrier to using ML in existing CFD [
7,
8]. These black boxes have implications for financial supervisors, who will need to take account of the opportunities for enhanced compliance and safety created by ML, and to be aware of the ways that ML could be used to undermine the goals of existing regulations. For example, the United States prohibits discrimination based on several categories, including race, sex, and marital status. Moreover, a lending algorithm could be found in violation of this prohibition even if the algorithm does not directly use any of the prohibited categories, but rather uses data that may be highly correlated with protected categories. The lack of transparency could become an even more difficult problem in the European Union, where the General Data Protection Regulation adopted in 2016 and due to take effect in 2018 gives their citizens the right to receive explanations for decisions based solely on automated processing [
9].
Even given this limitation, ML has potential applications in a variety of areas in financial services. The nature of opaque ML imposes significant limits on the use of ML for writing regulations [
9]; for example, the U.S. prohibits discrimination on the basis of various categories including race, sex, and marital status [
4]. Other of the consequences of black-box models are the potential biases in the results obtained and the difficulties involved in understanding the reasoning processes followed by the algorithms to reach specific conclusions [
6,
10]. The data used to train the ML models may not be representative in fraud operations [
9], thereby risking the recommendation of wrong decisions. Some firms emphasize the need for additional guidance on how to interpret current regulations. Towards breaking down this barrier, the interpretability of these models is fundamental. The regulation authorities are composed by humans, and in this sense the explanations must be understood by humans. In like fashion, the decision models need to be an easily understandable, or in other words, they need to allow us to check which attributes are necessary to produce explanations that are comprehensible [
11].
On the one hand, the easiest way to achieve interpretability is to use globally interpretable models, meaning that they have meaningful parameters (and features) from which useful information can be extracted in order to explain predictions [
11], such as linear regression or other linear models, including gradient boosting, support vector machines, and linear discriminant analysis. On the other hand, to achieve high accuracy, it is necessary to select the most representative variables for linear models. Hence, the methodology proposed in this present work has as two objectives: first, to reduce the dimensionality while selecting the informative features; and second, to use interpretable models to produce explanations comprehensible to humans. In the companion paper [
12], and after different strategies to obtain interpretability in linear models have been developed and compared herein, we present a thoughtful analysis of non-linear models.
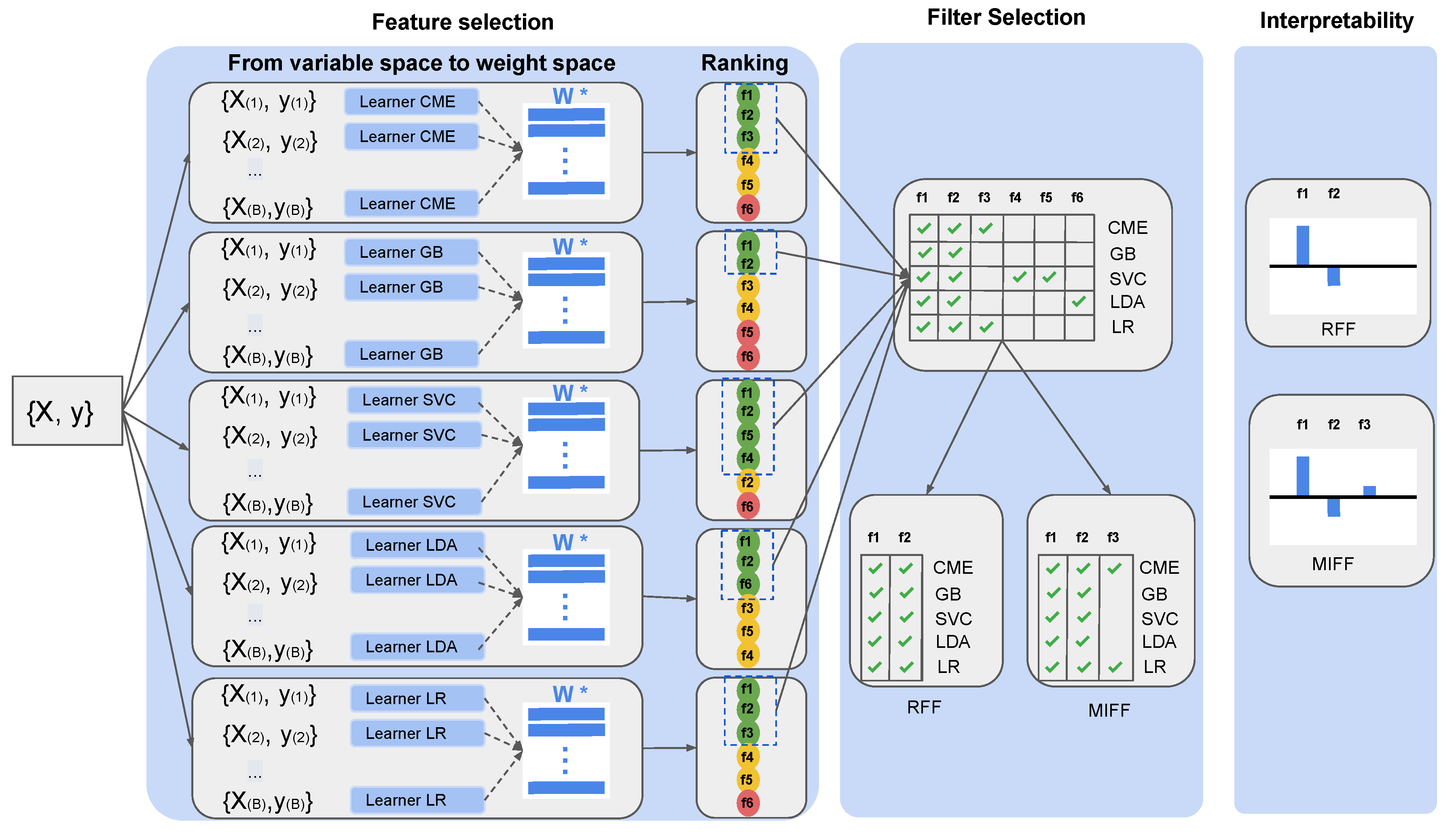
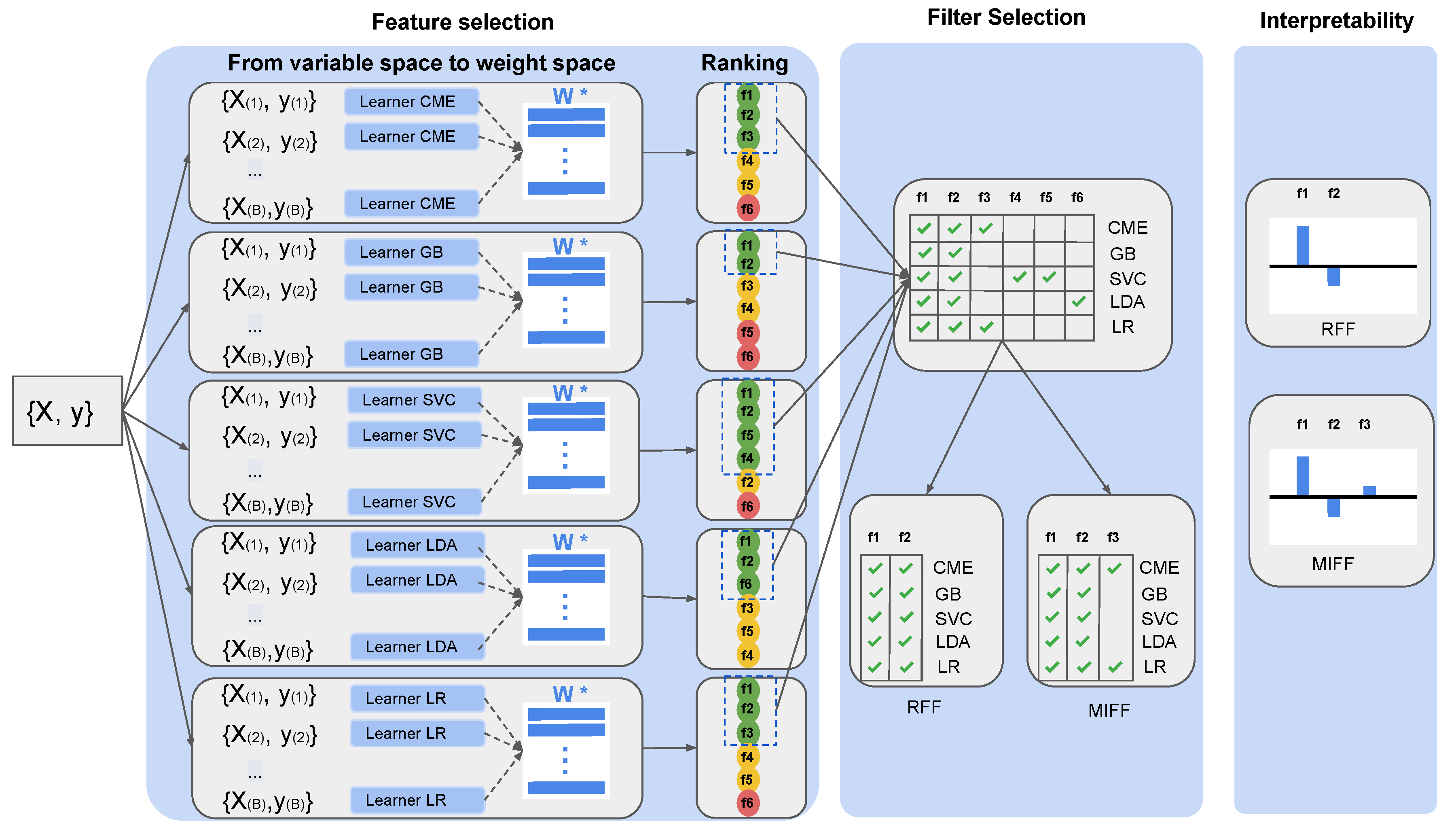
We aimed to create a reliable, unbiased, and interpretable methodology to automatically measure credit fraud detection (CFD) risk. To do so, we emulated a controlled environment using a synthetic dataset that allowed us to propose detailed analysis of all possible variables. The results obtained in this closed and controlled environment, together with the knowledge acquired, allowed us to perform validation on a real database. The proposed methodology incorporates a recently published novel feature selection technique, called informative variable identifier (IVI) [
13], which is capable of distinguishing among informative and noisy variables. In the original work, IVI was implemented using only one ML method. We further extended this method and performed intensive benchmarking of a set of different techniques, to extend the method’s validation and to enhance its generalization capabilities in the context of CFD applications. Different subsets of relevant features were obtained as a result of this exploration. We classified them according to newly proposed innovative filters, and to attend to recurrence, according to recurrent feature filter (RFF) and maximally-informative feature filter (MIFF). This reclassification allowed dimensionality reduction: an improvement in accuracy can be obtained as a consequence. In the method, interpretability and traceability are maintained over the process by using linear methods in the matching of each transaction and its corresponding evaluation. Therefore, the contribution of each informative feature obtained in this final model forms a straightforward indication for further legal auditing and regulatory compliance.
This work is organized as follows. A short review of the vast literature in the field of CFD and ML-based systems is presented in
Section 2. In
Section 3, the IVI algorithm and the RFF and MIFF filters are described in detail. In
Section 4, first, the synthetic and the German credit datasets we used are described. Then, we present the qualitative and quantitative benchmarking on synthetic data and a different analysis on a German credit dataset. Finally, in
Section 5, discussion and observations are presented and conclusions are stated.
4. Experiments and Results
In this work, we propose a novel methodology to simultaneously face the double challenge of applying new, powerful, and proven AI tools, while maintaining the interpretability of the underlying descriptors, thereby allowing compliance with the rigorous regulations of data protection and non-discrimination in force for financial institutions. The developed methodology helps the interpretable linear methods by capturing the relevant features and leaving aside the black boxes, while minimizing the potential bias. To do so, experiments for both synthetic and real data were performed as follows. First, we compared a number of the ML methods with the IVI technique in order to evaluate their capacities for automatic classification. Second, we modeled different learning architectures that allowed us to evaluate the predictive value of the result (CFD), using various sets and subsets of features. This second analysis offers a quantified vision of the predictive capacities of the method–features pairs, to adequately qualify the different options. Third, a detailed evaluation of the incremental predicted value was performed for each of the previously defined methods. We analyzed them feature by feature, along with the speed of convergence and the predictive capacity of each. A final exercise in the analysis of the coefficients, applied to each of the features in the different methods, allowed us to assess the contributions (interpretability) of the different features to the final predictions.
This section is divided into two main subsections presenting the experiments on the synthetic and real datasets. Prior to the experiments, the datasets are introduced. The general strategy guiding the experimentation was to scrutinize and fine-tune the synthetic dataset to validate the methodology, for later evaluation of the generalization capabilities to actual CFD cases in the real dataset.
4.1. Datasets
Although there are a large number of articles published about CFDs, it is not easy to access the actual data used due to data protection and confidentiality restrictions. That is why in this work, initial analysis has been prepared using surrogate signals generated by the authors, which helped us to define and model the detailed study to be carried out. This analysis process based on synthetic signals offered the required flexibility to evaluate the predictive capacity of the different variables, thanks to the effective knowledge provided by having built it. The knowledge acquired during this process allowed us to subsequently analyze the eventual generalization on the real dataset. For this last step, we used the database provided by Strathclyde University [
35].
Synthetic Dataset. The first dataset introduces a synthetic linear classification problem with a binary output variable, and it was developed for the original proposal of the IVI algorithm [
13]. It has 485 input features. In this work, and for reasons of representability and execution time, we have used a subset of features while keeping the feature names. The dataset used here included a set of 23 input features distributed as follows: 11 input features were drawn from a normal distribution, and 5 of them were used to linearly generate a binary output variable, specifically
, and
. Therefore, these five features are informative for the problem. A set of another 12 features were randomly created with no relation to the previous ones, so that they could be considered as noisy and non-informative variables. Additionally, a new group of six variables were computed as redundant with the informative input features.
German Credit Dataset. This repository is known as the German credit fraud (Stattog) [
35], and it contains real data used to evaluate credit applications in Germany. We used a version of this dataset that was produced by Strathclyde University. The German credit dataset contains information on 1000 loan applicants. Each applicant is described by a set of 20 different features. Among these 20 features, 17 of them are categorical and three are continuous. All these features are commonly used in CFDs, and some examples are: credit purpose, savings, present employment, and credit amount. There are no missing values. To facilitate FS and in order to train the models, the values of the three continuous attributes were normalized, and for the discrete features, they were converted to one-hot encoding. After these pre-processing stages, the final dataset was 61-dimensional.
4.2. Analyzing the Synthetic Dataset
As we introduced earlier, we first applied the novel FS strategy based on the IVI algorithm to identify the relevant features. This effort was intensively executed by the five different algorithms introduced earlier, namely, CME, SVC, GB, LR, and LDA. This approach allowed us to achieve a more unbiased perspective of the real effective potential of selected features, and of the sustainability and consistency across methods.
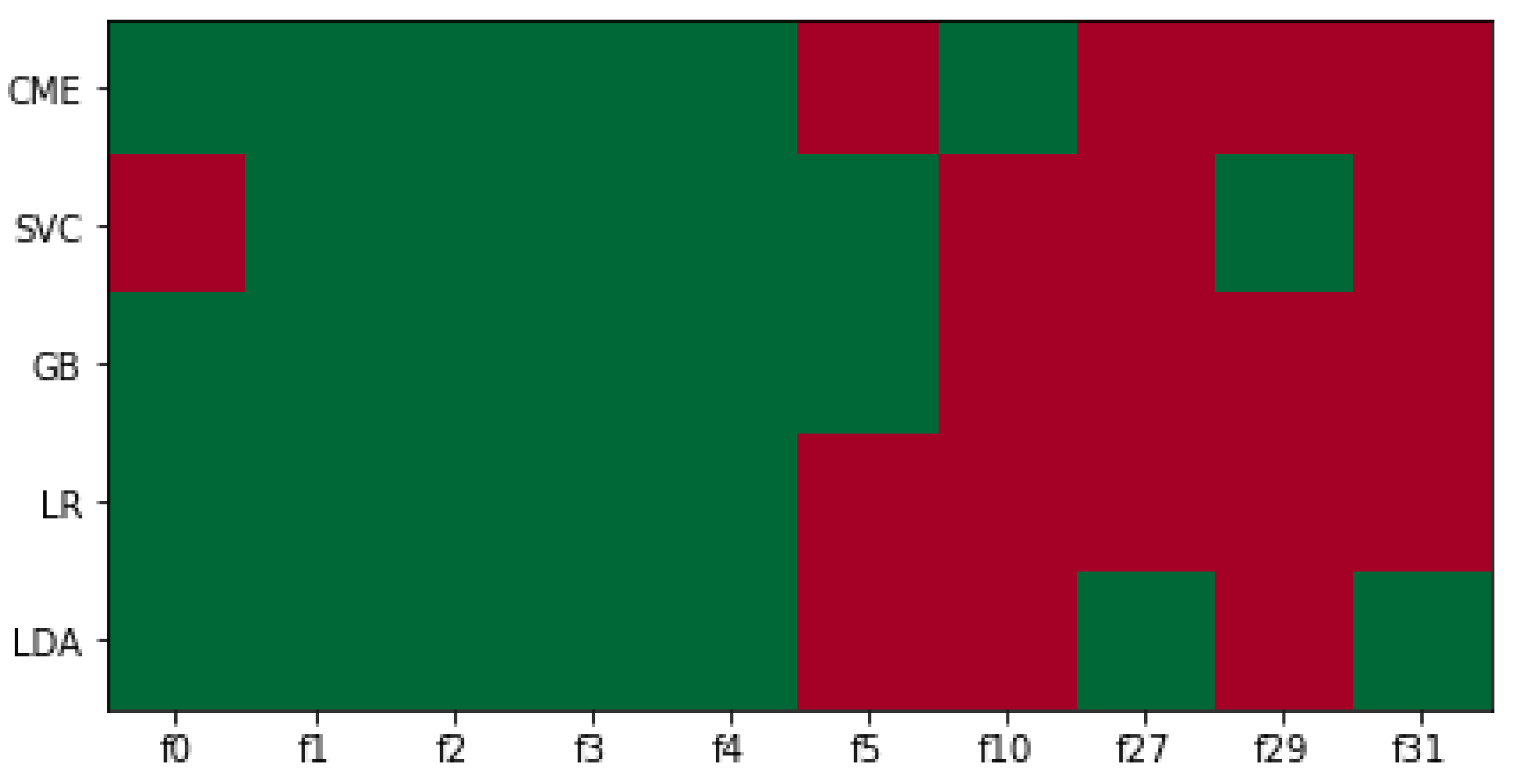
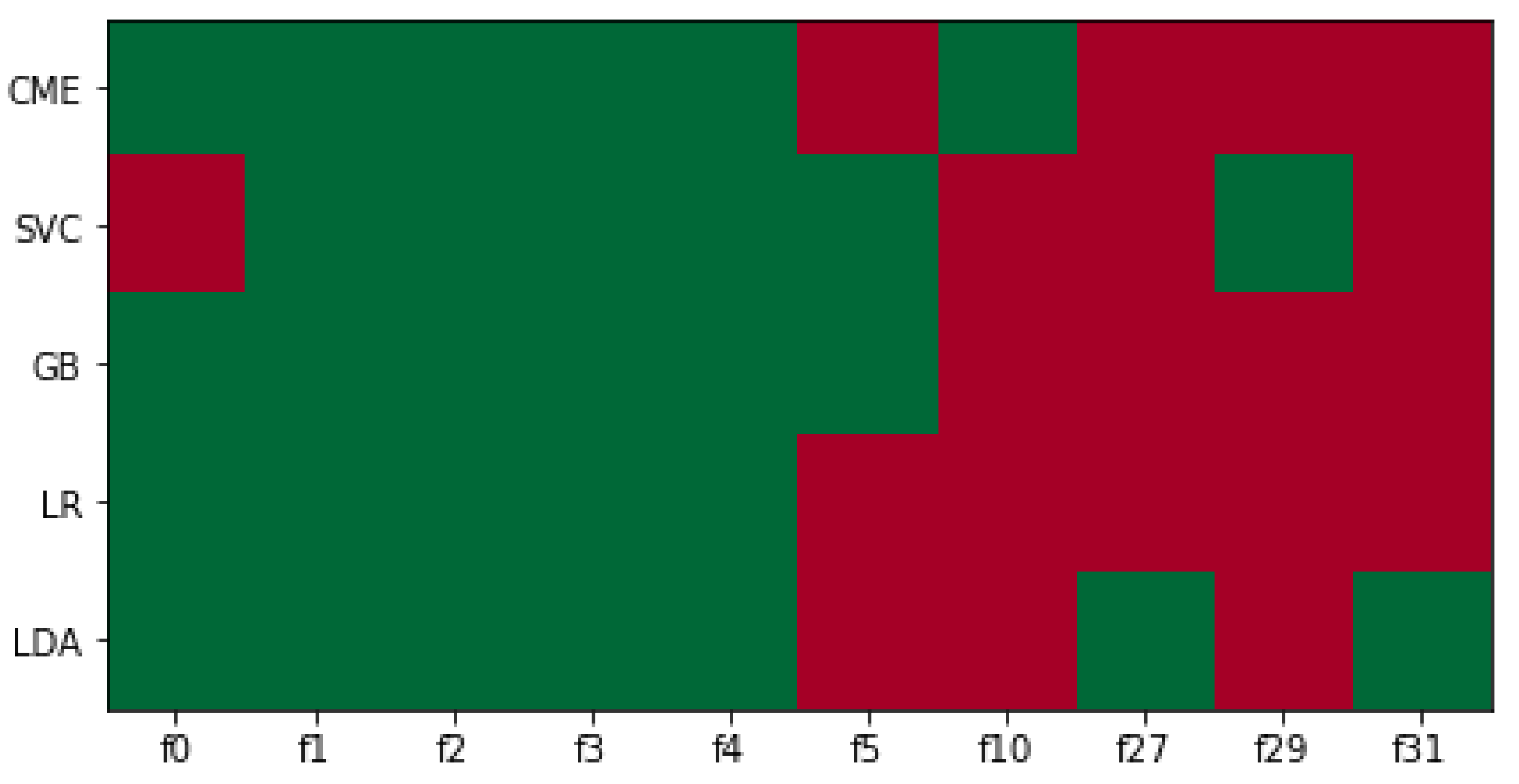
Figure 2 summarizes the outcome of the IVI algorithm for each individual ML technique. In this figure, validated selected features (columns) are in green and those ones not identified as significant by the algorithm (rows) are in red.
We should recall at this point that features identified as relevant for all ML methods were classified as categorized as RFF, as they recurrently and consistently were relevant in all methods. Features – were all included in this set, but f0 was not identified as such due to the miss-classification by SVC. In the same vein, features identified as relevant for at least two methods were understood to be informative for further analysis and so were chosen for the MIFF group of variables. For this specific case, features – met the MIFF criteria and were included as members of this filter. These features perfectly match with the relevant features on the synthetic dataset (–), other than one redundant feature (). Attending to these results, we can conclude that the IVI algorithm was consistent with the different ML methods, so it appears to have a valid feature selection ability.
In an attempt to verify and quantify the results, accuracy was calculated in sixteen different scenarios, for SVC, GB, LR, and LDA, and considering different sets of features, namely: (i) all the available features; (ii) only the relevant features according to IVI for each corresponding ML method; (iii) MIFF-classified features; (iv) RFF-classified features. CME was not considered for this task, as CME is a fast weight-generator method but is not a classifier.
Table 1 summarizes the means and standard deviations of the 100 resampling executions for 16 different scenarios. This table shows how the accuracy remained mostly invariant among all the classification methods, as the different columns reflect almost no change in terms of mean or standard deviation. The only exception can be found in the case of GB, which in all cases, still shows a smaller classification capability to the rest of the analyzed methods. Similarly, in the case of LDA, when applied to all the available variables, a slight reduction in its prediction capacity can be appreciated. The benchmark illustrates that the best results were obtained when the MIFF filter was used, and there was equivalent predictive power when all the variables were used, reaching in both cases the predictive accuracy of 98.8%. The standard deviation was in all cases lower than 4%. The IVI model offered in all cases, very similar results to the outstanding methods (97% accuracy). On the contrary, the RFF filtering suffered in its predictive capacity compared to the rest of the models, showing the lack of expressive power (90% accuracy) due to the non-incorporation of variables as a consequence of the incorrect classification of relevant variables.
As a general result of the analysis, we can recall that although we focused on a limited number of families of ML linear algorithms, each of them treated independently revealed equivalent performance, and the accuracy was tightly related to the features incorporated as input variables. These results indicates two separate, relevant ideas: (i) the importance of FS as a key element for the performance of the ML model; (ii) the limited relationship among accuracy and the ML method that is chosen provides the possibility of picking the method based on its computational efficiency without leaving out any potential expressive capacity.
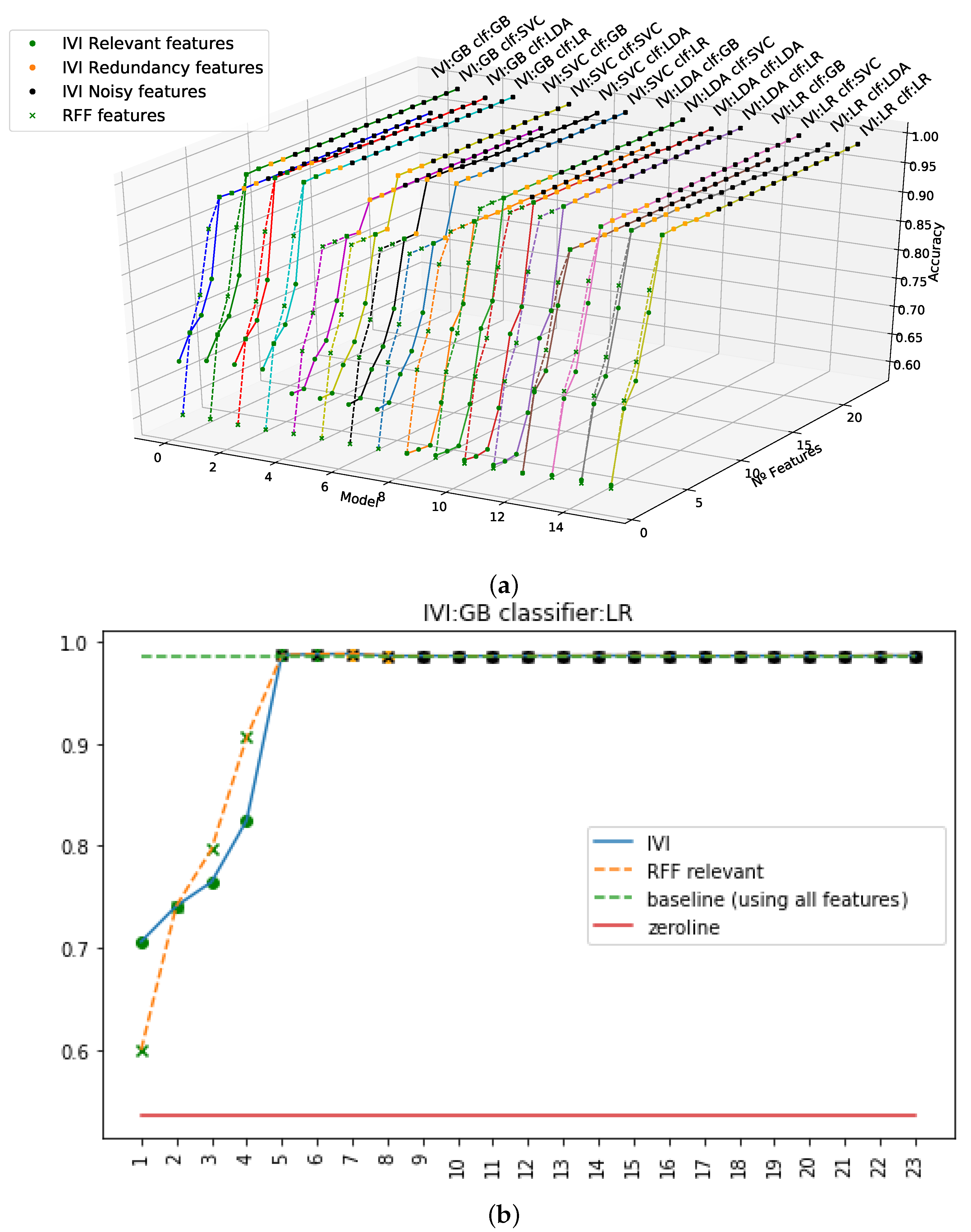
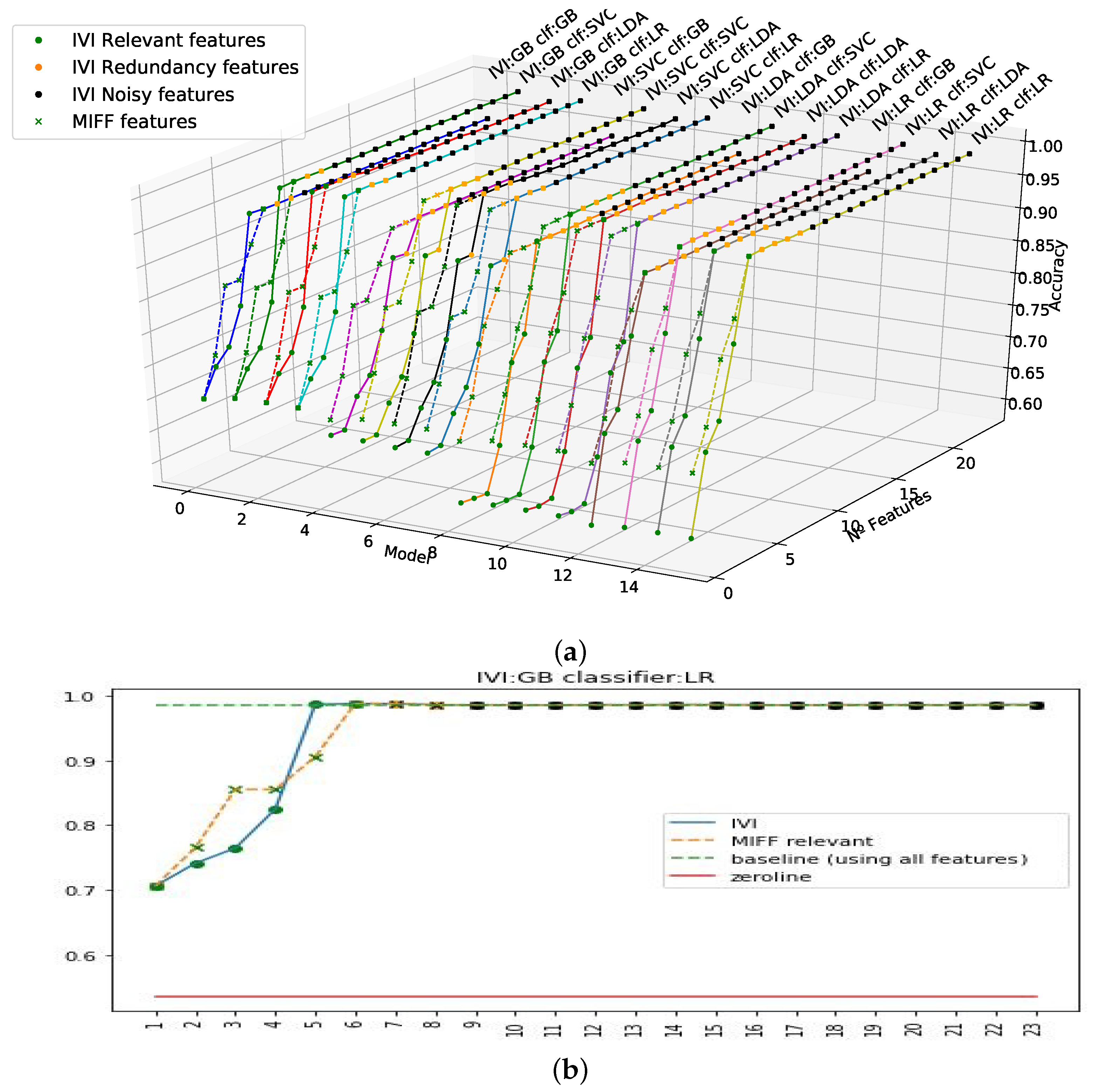
The results obtained in previous experiments suggested the need for a greater and in-depth analysis of both the FS techniques and the variables themselves, for a better understanding of the underlying dynamics. To do so, a number of experiments were conducted considering all variables, for both filters (RFF and MIFF). Experiments were designed in a way to visualize the contribution of each variable by incrementally adding features on a one-by-one basis.
Figure 3 and
Figure 4 represent the resultsof the corresponding experiments. In the experiments, the variables were added up in sequential order according to their relevance, starting with the most relevant one as defined by the IVI method.
Figure 3a presents the evolution of the sequential results for all the experiments when applying the RFF filter, and
Figure 4a shows the results of applying the MIFF filtering, both in an M-mode presentation (3D perspective) and in a profile representation. The plots represent two scenarios for each method, as a continuous lines depicts the corresponding results for the standard IVI representation, and the overlaid dotted line follows the process using the RFF or MIFF filtering. IVI standard features were incorporated in the incremental feature experiments in order of relevance (specifically, first informative, then redundant, and finally, noisy). As only filtered features were chosen for RFF and MIFF, the remaining components were added according to standard IVI sequence to complete the full feature set. In
Figure 3 and
Figure 4, we can observe the convergence in accuracy using the RFF and MIFF filters. We can see in these figures that once we achieved higher accuracy with the relevant features, the accuracy did not experience variations when adding new features. It can be observed that redundant and noisy features were properly classified within the IVI strategy, and no increment in accuracy was obtained when these last (redundant and noisy) variables were added into the model. Meanwhile, in MIFF and RFF experiments, missclassified features may contribute in advance to the sequence to build the model, either delaying the convergence or even limiting the classification power. In our observations, we confirmed that after applying RFF, we did not find a strong limitation in final classification power (see
Figure 3 for RFF and
Figure 4 for MIFF). Both models sensitively matched the IVI method’s accuracy. As a result, a more efficient and faster way to train the final models with a lower number of variables. This effect is used so long as high accuracy is reached consistently in the filtering models.
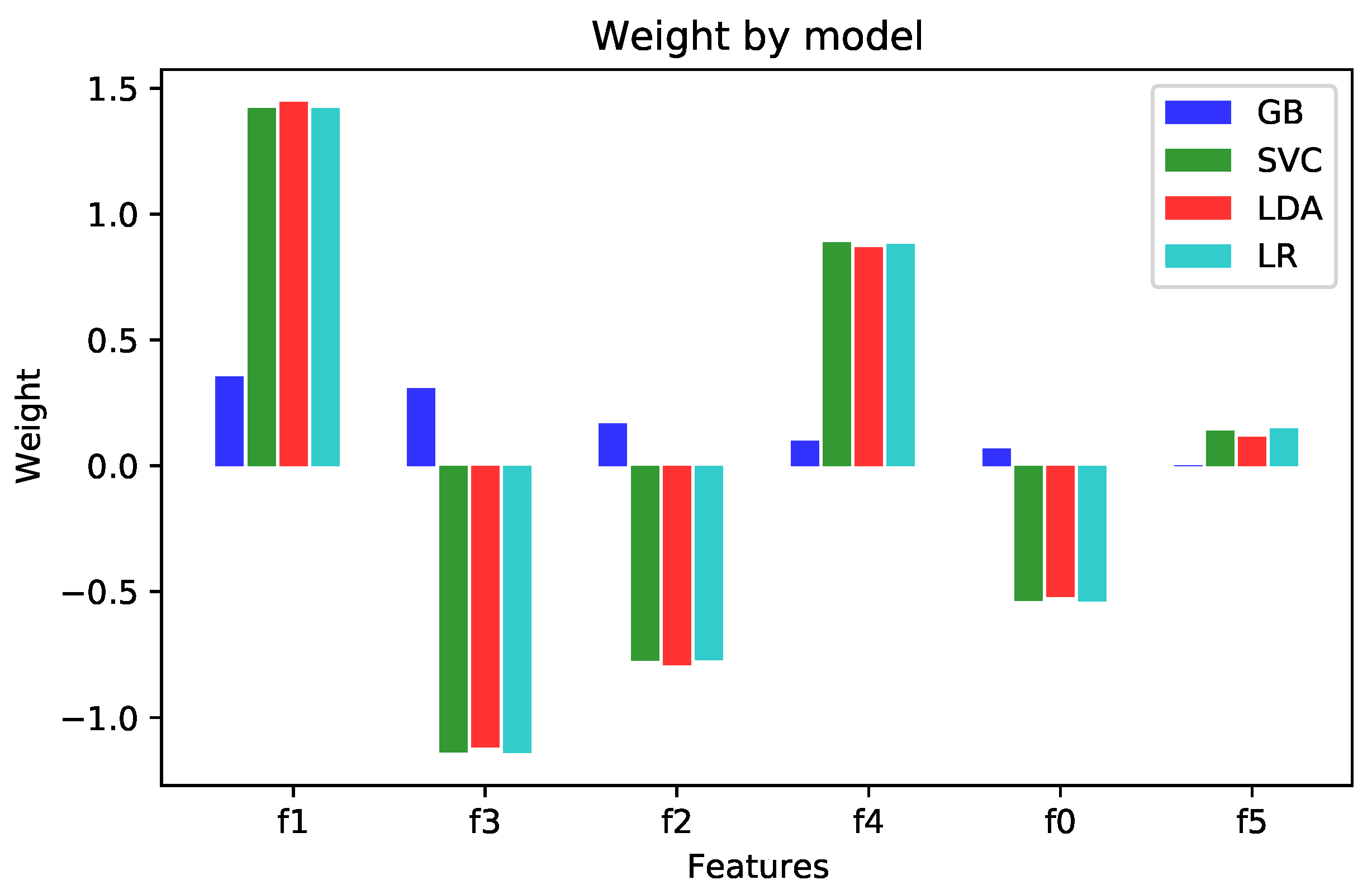
A third experiment aimed to measure the contribution of each of the variables to the final model.
Figure 5, collects the weights for the MIFF analysis, and can be understood as the contributions of the different experiments. Additionally, as can be appreciated in the figure, although all features presented similar weights,
and
received slightly higher weights than the others. An exception to this was found for
, which had a small weight in all ML algorithms we analyzed. This result is consistent with the fact that this feature was effectively irrelevant and misclassified by the algorithm, thereby allowing further adjustment to the model.
4.3. German Credit Dataset
In this experiment, we applied the knowledge previously acquired in the synthetic dataset, but this time using actual data from the German credit dataset. The main purpose of this was to verify if the results obtained with real data would be the same, when using the same methodology as for the synthetic dataset.
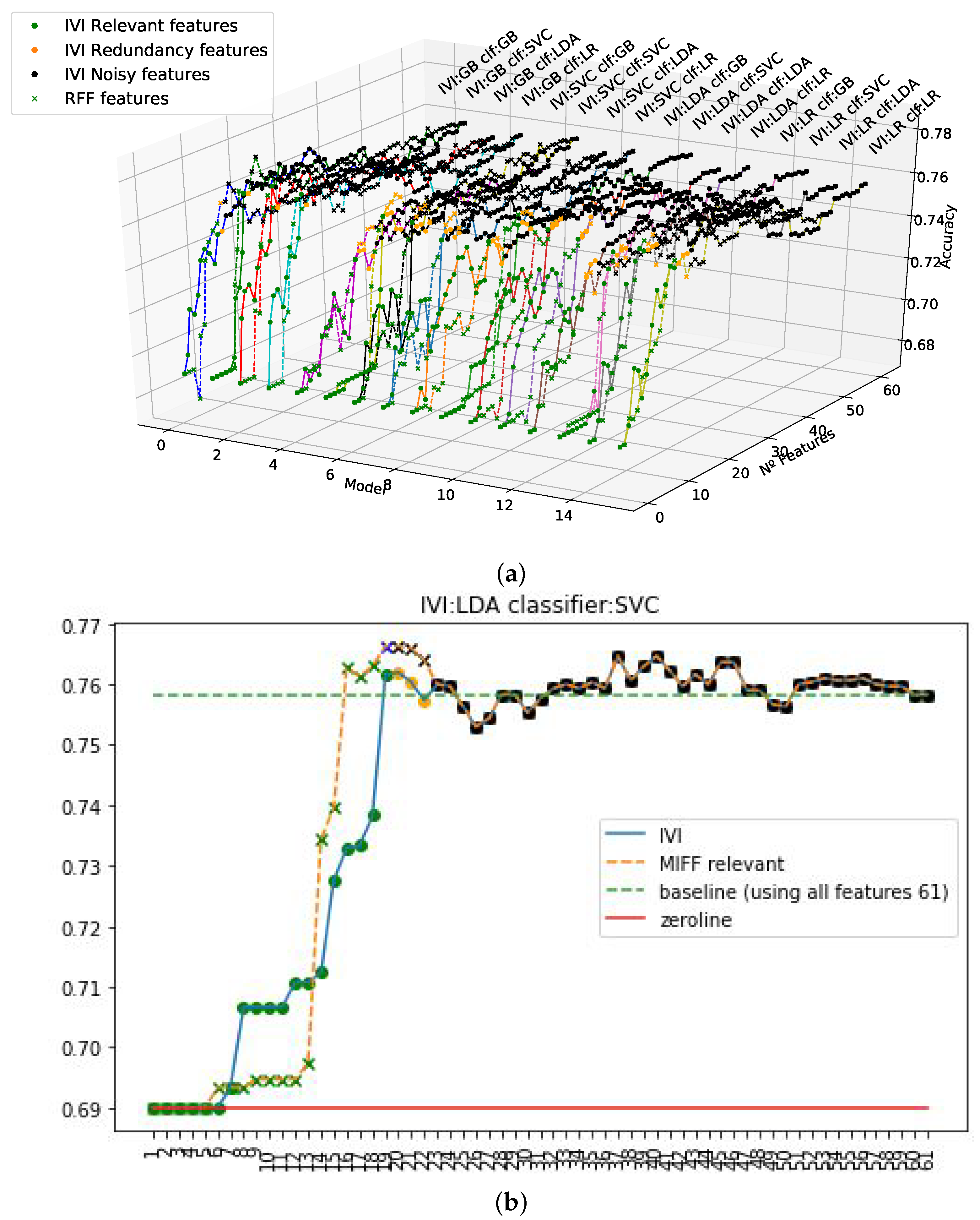
Following the previously scrutinized methodology, our FS technique was applied to this new dataset. Results for the German credit dataset with the IVI technique and all the ML algorithms are presented in
Figure 6. A number of features were unfailingly identified as relevant for all the ML algorithm, following the same pattern observed with the synthetic dataset and showing consistency with previously described results in terms of these repeated informative features. Equivalently to prior descriptive analysis, features were classified as RFF if they had been selected in all the ML algorithms used, and MIFF if they had been selected by at least in two of them.
Four experiments were guided using one hundred epochs of bootstrap tests in order to evaluate the statistical significance. Results in
Table 2 show systematically an almost insignificant standard deviation, with independence from the dataset. The method–characteristic paired models show high accuracy in all cases: the values were close to 75% in all cases. Regarding the methods, they all showed similar values for the different sets of variables, except the SVC method, which presented a drop of 4% with respect to the rest for the set of RFF variables. Singularly, this same method (SVC) offered the best result with the remaining feature set, by systematically surpassing the rest of the methods and reaching a maximum of 76.63% with the MIFF filter. On the other hand, lower results were steadily found, although still strong, with the GB method. Accuracy was worse by more than 1% for the feature sets at best, with the sole exception of the RFF, with which SVC presented a decline even larger. From a feature-set perspective, the results were very homogeneous among the methods, and singularly better in the case of MIFF, due to precision figures over 75.10% in all cases. On the contrary, the RFF filter showed not only uneven behavior across methods, but also consistently poorer results. The results shown here correlate highly with those of the analysis carried out with the synthetic dataset, thereby validating the hypotheses formulated during the exercise.
All the ML algorithms using MIFF showed higher accuracy using the IVI features. The only exception was LR, which had a slight reduction in accuracy. Those results are consistent with those previously obtained, and again, FS using MIFF improved the training procedure in terms of computational efficiency, by reducing the number of features needed to reach higher accuracy, and thus confirming empirically the hypothesis settled with the synthetic dataset.
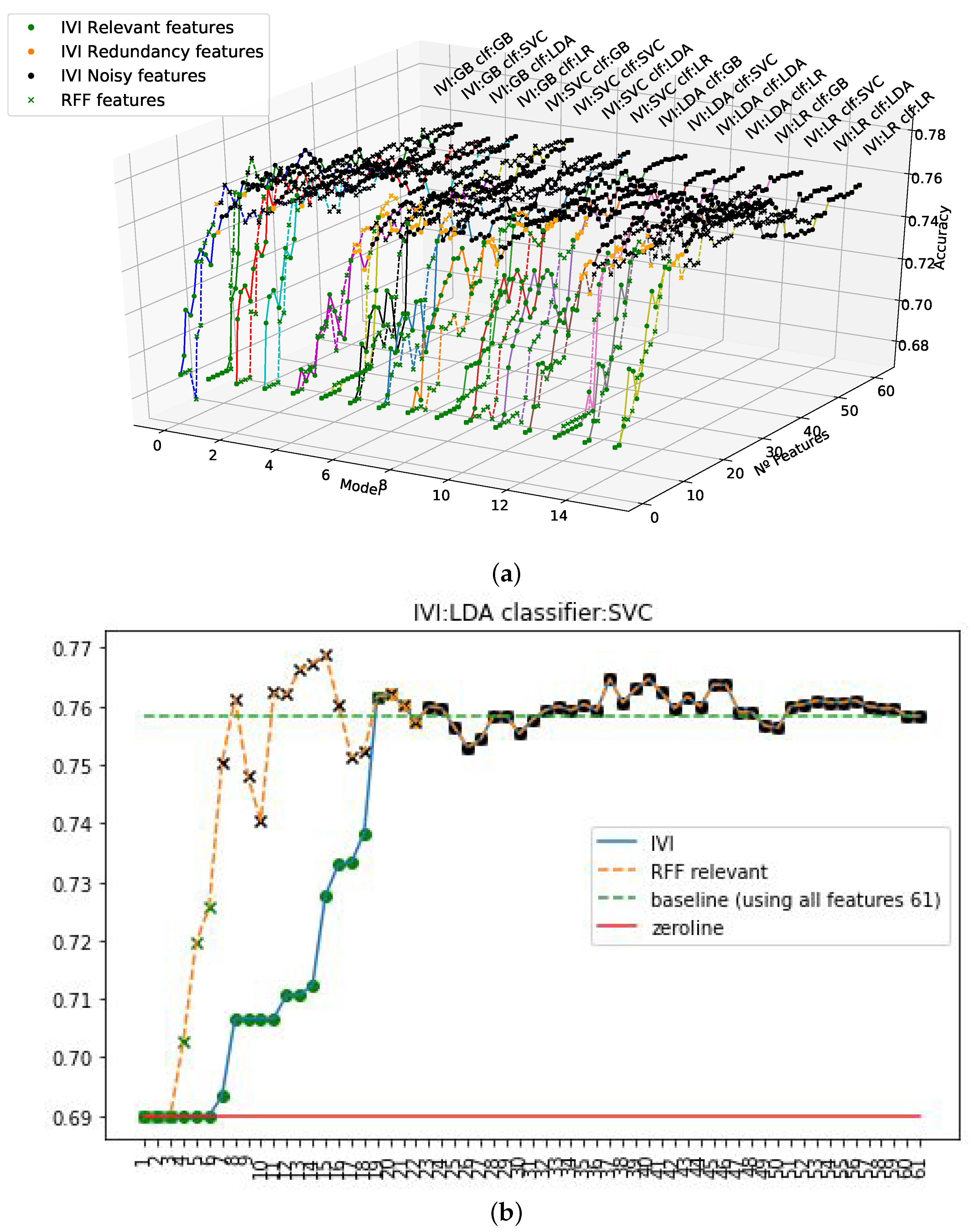
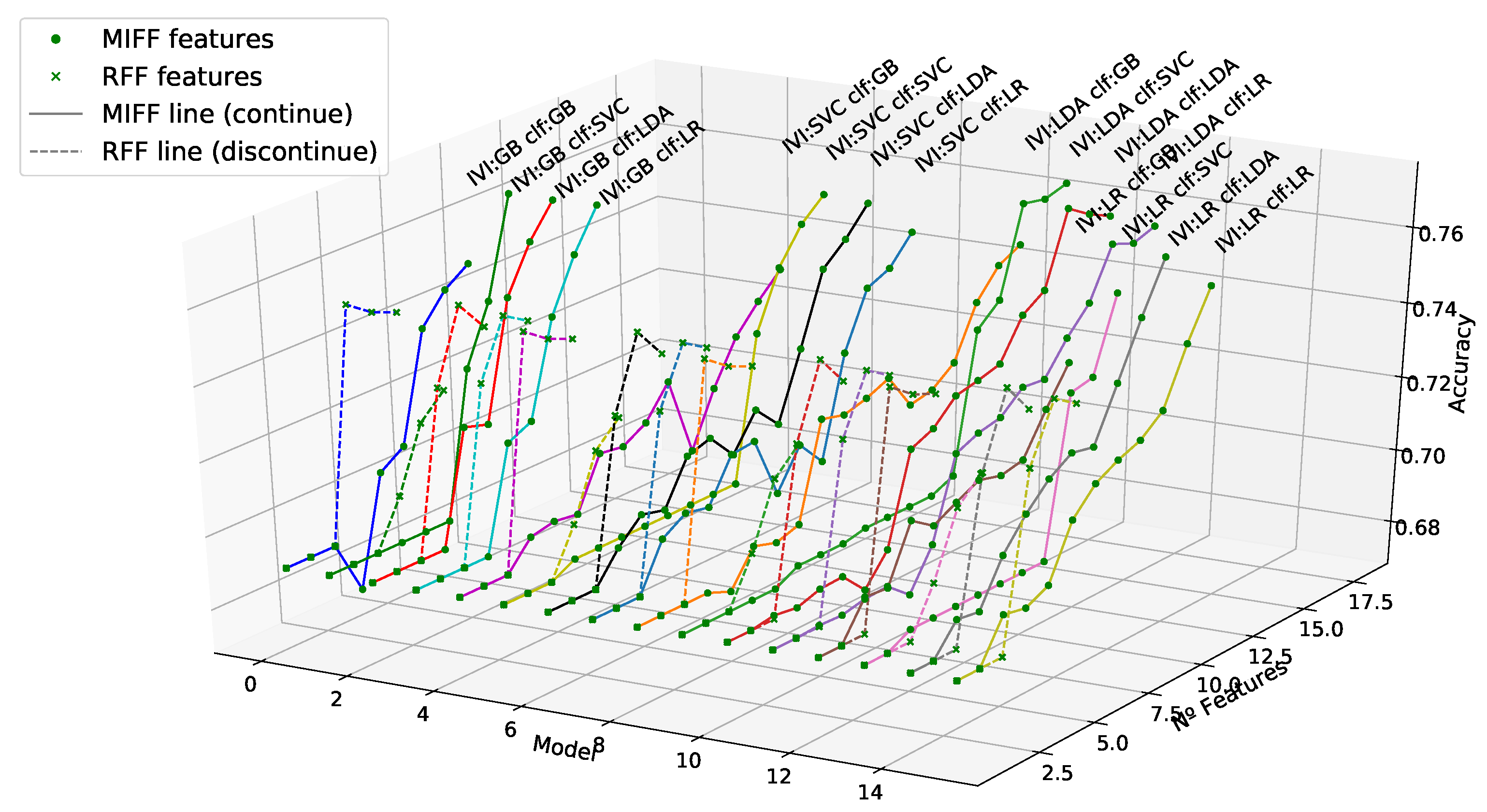
Equivalent representations appeared earlier for all evaluated models and available features. They are depicted in
Figure 7 and
Figure 8. In particular, in
Figure 7 we see the parallel and comparative processes followed in the IVI algorithm and the RFF filtered features; and in
Figure 8, we also see the corresponding analysis for MIFF. It can be observed in figure that accuracy systematically increased in all cases when relevant features were added toward the maximum value. After that, the accuracy remained stable, despite the redundant and noisy features being added. Furthermore, when MIFF and RFF filters were used, we reduced the number of features to reach the maximum accuracy against the standard IVI approach. The best results were obtained using the MIFF filter.
Figure 7 show slightly lower accuracy when compared to IVI. As we mentioned earlier, this is related to the extremely restricted set of candidates allowed to become relevant features when using this filtering technique.
In the informative representation in
Figure 8a,b, we can see an interesting effect. Using RFF, we had an explosive increment in terms of accuracy, while using a relatively small set of features, but we did not achieve the maximum. However, when using MIFF, an initial slight ramp-up was obtained, but we achieved the maximum in accuracy, surpassing IVI’s accuracy while using a smaller number of features. This situation was the same in all models, as represented in
Figure 9 from a different perspective. In this representation, for the reader’s convenience, the high dimensionality of the data is restricted in terms of the number of features to just the relevant ones, in an attempt to visualize this effect across the different plots.
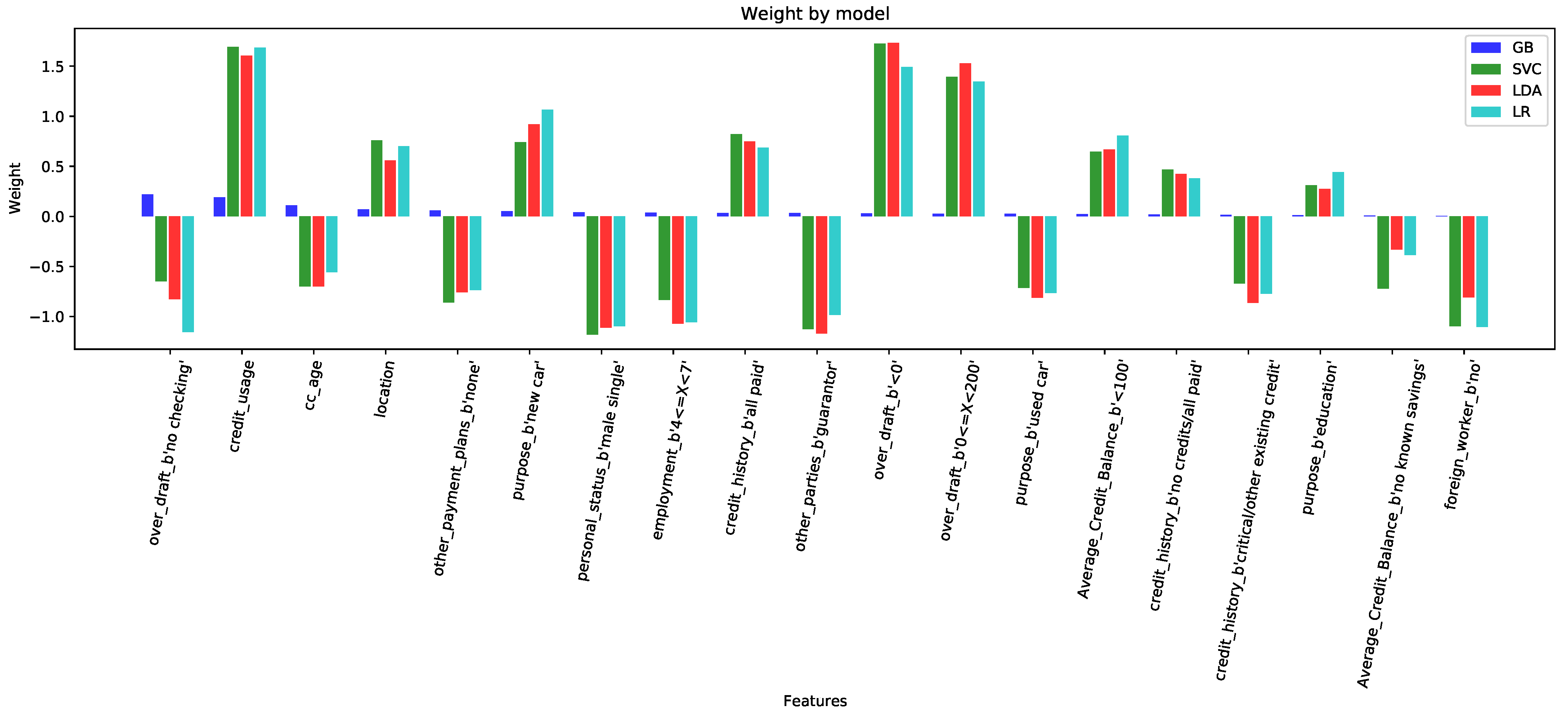
In the same way as it previously analyzed in the synthetic dataset, the contributions to the decision process of the weights of the features in all the experiments were evaluated. Again, (i) the smaller contributions or weights of a number of variables meant they were classified as noisy or redundant, (ii) the large contributions of other variables classified them as relevant, and (iii) a number of them had small to medium contributions and were redundant, but were misclassified.
Figure 10 illustrates the coefficients corresponding to the MIFF features. The representation illustrates the existence of large-contribution variables, over ±1.0 (over_draft_<0, credit_usage, purpose_new_car, employment, other_parties_guarantor), and the large-contribution ones over ±0.5 (credit_history_other_existing_credits, average_credit_balance_<100, location purpose_ education), and a small proportion of variables with a significantly lower contribution less than 0.5 (purpose_rent, current_balance, credit_history_no_credits, foreign_worker). This last group very likely corresponds to the redundant variables that were incorrectly classified, and therefore, subjected to be excluded at a later stage. It is necessary to point out at this point the identification of 3 variables outstanding the general classification with contributions 50% higher than their peers. In particular, credit_usage was the most relevant feature for all algorithms, and the second most relevant was over_draft_<0. These results are consistent with literature [
36,
37] and with the companion paper [
12]. This special subset should be conveniently analyzed separately from an interpretability perspective, given this remarkable behavior: it is not only more important than the rest, but was consistently reproduced in every method. We should mentioned here the special situation of the GB method. Although significance apparently offered proportional matching with the rest of the methods, its magnitudes are far lower than those of the rest of the methods, following its behavior in the synthetic scenario.
5. Discussion and Conclusions
In this paper, we elaborated on the possibility of applying the almost ubiquitous current ML techniques to CFD. One of the main drawbacks of these technologies is that even though they are extremely effective and powerful in almost all disciplines, they are mostly black boxes: it is virtually impossible to decode the way the variables are treated internally. This last statement is intrinsically incompatible with regulations issued by administrative bodies, as whatever tool is used should be compliant with non-discriminatory rules and transparency. In this work, we proposed a novel methodology to address the mentioned drawbacks when applying ML to the CFD problem, which uses state-of-the-art algorithms capable of quantifying the information of the variables and their relationships. This approach offers a new method for interpretability to cope with this multifaceted dilemma. In this paper, we presented an intensive analysis of a number of statistical learning techniques (GB, SVR, LR, and LDA), together with new feature selection procedures, applied both on a synthetic dataset for development, and on a real dataset for validation. As a general conclusion of all the experiments, we can say that it is possible to develop an ML model supporting the novel feature selection techniques presented in this paper. The result will not only provide the detection of CFD, but also at the same time allows one to visualize the contribution of each feature in the decision process, thereby offering the necessary interpretability of the model and the results. To deal with the complex dichotomy of machine learning tools and interpretability, we elaborated on informative features and calculated their contributions to the decision process, leaving aside black boxes and minimizing potential biases by using state-of-the-art ML techniques. We claim that it is possible to build robust, explanatory linear models that simultaneously meet the regulatory constraints and use the power of ML techniques. To do so, our work was twofold. First, we developed a synthetic dataset to define and fine-tune the models. Second, the successful models were later on applied to a real dataset to verify generalization and consistency.
The main conclusions when analyzing the synthetic dataset are described hereafter. First, using the IVI model, we were able to systematically identify the features with informative value. Additionally, the use of a subset of the variables when applying the filters described in this paper improved the performance in terms of the computational efficiency by limiting the number of variables. We found that all noisy and redundant variables were consistently excluded from this extended method. Two different filtering procedures were proposed, RFF and MIFF. The first one is much more restrictive and was the fastest way to reach a reasonable level of accuracy, but failed in the classification of a number of features. On the other hand, the second filter, although it had redundant variables, did not misclassify any noisy features. As the interpretations of linear models were proposed based on the final weights obtained, and considering that far lower contributions were found for these redundant features, the joint application of MIFF and weight evaluation could be considered as an efficient and accurate model, even in the cases when redundant features are identified. Based on these results, we conclude that formulation and classification using IVI, together with RFF and MIFF filtering, offers an automatic and efficient system that improves the generalization and prediction capabilities of CFD on synthetic datasets.
The results of applying these methodologies to the German Credit dataset [
5,
38] were in general terms consistent with the previous findings on the synthetic dataset. The results obtained suggested that the use of presented method not only improved the results (with a 4% accuracy increase compared to previous papers’ results) but also enhances computational efficiency by reducing the number of features. From a methodological perspective, the applied model was confirmed to be valid, as accuracies for all method–characteristic models were homogeneous. Their lowerest values were close to 75% on average with a standard deviation of close to 2%. From a computational perspective, and considering the four different sub-sets of features evaluated, namely, all features, IVI features, MIFF, and RFF, the last two offered significant reductions in the number of variables, thereby significantly improving the computer’s workload. For both, accuracy was high, although MIFF offered higher stability in the results across methods. Detailed analysis showed that RFF managed to incorporate effectively none but relevant variables, but missed in certain cases some of the relevant ones. MIFF managed in all cases to include them all, but also included some redundant ones. The integration of redundant variables in MIFF did not generate any lack of accuracy or stability in the predictive capacity, and they could be removed at a later stage, as their contributions (weights) steadily had far lower magnitudes compared to their peers’ weights. On the contrary, in the RFF case, the rapid convergence due to the adjusted base of variables selected in this subset was not accompanied by the most stable behavior in the results, due to the absence of some significant variables due to the incorrect classification. Thus, there was an up to four percent reduction in precision compared to other the models. We can therefore argue at this point, that a very strict strategy in the search for truly informative variables, such as RFF, although it intensively accelerates convergence and computational efficiency, sometimes prevents all informative variables from being collected, causing a lack of convergence or instability in the results. On the other hand, not so aggressive strategies for selecting variables, such as the MIFF, offer greater flexibility, which, although they sometimes allow the selection of redundant variables, maximize the probability of incorporating all the relevant ones, without excessively increasing the computational needs. For this reason, the use of IVI classification techniques, together with the application of MIFF selection sets, can offer the right balance between computational requirements and accuracy. From an ML perspective, the methodology used is consistent due to all the methods showing similar results with little differences for each of the feature sets, although SVR again was the method that provided the best results, and GB under-performed slightly among its peers.
Finally, as introduced earlier, the system presented here, using exclusively linear strategies, offers a powerful interpretable state-of-the-art technique beating the predictability of other more sophisticated and more difficult to interpret ML applications. This approach paves the way for greater interpretability, as the contributions of the different final features could be matched to the weights of those very same variables. Following the synthetic analysis, coefficients of the variables tended to be very high for relevant features, and low or very low for redundant or noisy features, respectively. For the specific case of MIFF, there were some very highly contributing variables and highly contributing ones, plus a small proportion of variables with significantly lower contributions, which happened to be redundant. Three variables stood out with contributions 50% higher than their peers. This special subset of variables should be specially evaluated as a key and supporting features of the model, as they not only showed large contributions, but consistently reproduced the modulating power in every implemented method. It should be noted now that these variables (average credit with unknown savings, clients with overdraft, and purpose of credit being for a new car) were already identified in the literature [
36,
37], conveying, therefore, double validation: of the results and of the model itself.
As a general conclusion, we can state that it is possible to create in five steps, an unbiased, interpretable classification model: (i) an initial IVI analysis; (ii) benchmarking of ML classifiers to reduce the bias; (iii) FS and filtering of the variables; (iv) a bootstrap analysis for statistical significance estimations; (v) a feature significance calculation, based on the coefficients, which pave the way toward the desired interpretability of the ultimate model. This model offers a novel multi-tapper approach for effective, efficient, and interpretable classification that can be used in many fields, but specifically where black boxes are not acceptable due to regulatory restrictions. Hence, the innovative techniques presented in this work in relation to the FS applying the aforementioned relevance filters through cross-analysis of different classification techniques, have proven to be not only more effective than previous techniques, but offer more computationally efficient methods for the analysis. With all that, we reduced the potential biases and opened the way to develop models for legally restricted applications.
The necessary interpretability for models to be used in CFD could be obtained through the analysis of the coefficient for each of the variables for every single classification. These coefficients, already limited in number after this strict process of validation, constitute the contributions of all of these variables to the decisions or recommendations obtained. We can discuss at this point not only the importance of these coefficients to estimating said contributions, but also using them as a second validation tool for the variables, having observed that the variables that participate with less intensity could be eliminated without relevant effects from a practical point of view. Additionally, this same combination of factors can be jointly interpreted as an analysis pattern offering a direct characterization of the finally implemented model.
Further analyses could be eventually proposed based on our concepts, e.g., to provide deep learning anomaly detection strategies. In the companion paper [
12], we present a thoughtful analysis of non-linear models in that direction, leveraging the valid results and conclusions of the present work.
We can conclude that the proposed methodology, in combination with state-of-the-art linear ML models, can provide fast methods to discover the most relevant features in CFD problems. The black-box methods can be left behind, and we can instead generate interpretable models in which the potential biases are minimized. With this work, the groundwork has been laid to provide interpretability to CFD, and we shall see how this will affect the legal and ethical considerations.


 ,
, 










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}