
BBRefinement: A Universal Scheme to Improve the Precision of Box Object Detectors


Abstract
:1. Introduction
1.1. Problem Statement
- We propose BBRefinement, a specialized, one-purpose object detector that processes mixture data and can work as an extension to any object detector to improve its accuracy.
- We designed a specialized augmentation technique that combines the augmentation of information about the object’s class and bounding box dimensions.
- We define two losses, the first aiming at metrics that involve a single IoU threshold, and the second minimizing metrics that involve multiple IoU thresholds.
- BBRefinement is universal. It can be trained only once and then coupled with an arbitrary object detector that produces the same object classes.
- The proposed scheme is capable of suppressing known difficulties in the object detection area, thus resulting in a higher mAP, mainly for large and medium-sized objects.
- It is fast, and adds only 50 ms overhead per predicted image.
- It can be used to improve the quality of imprecise labels.
1.2. Related Work
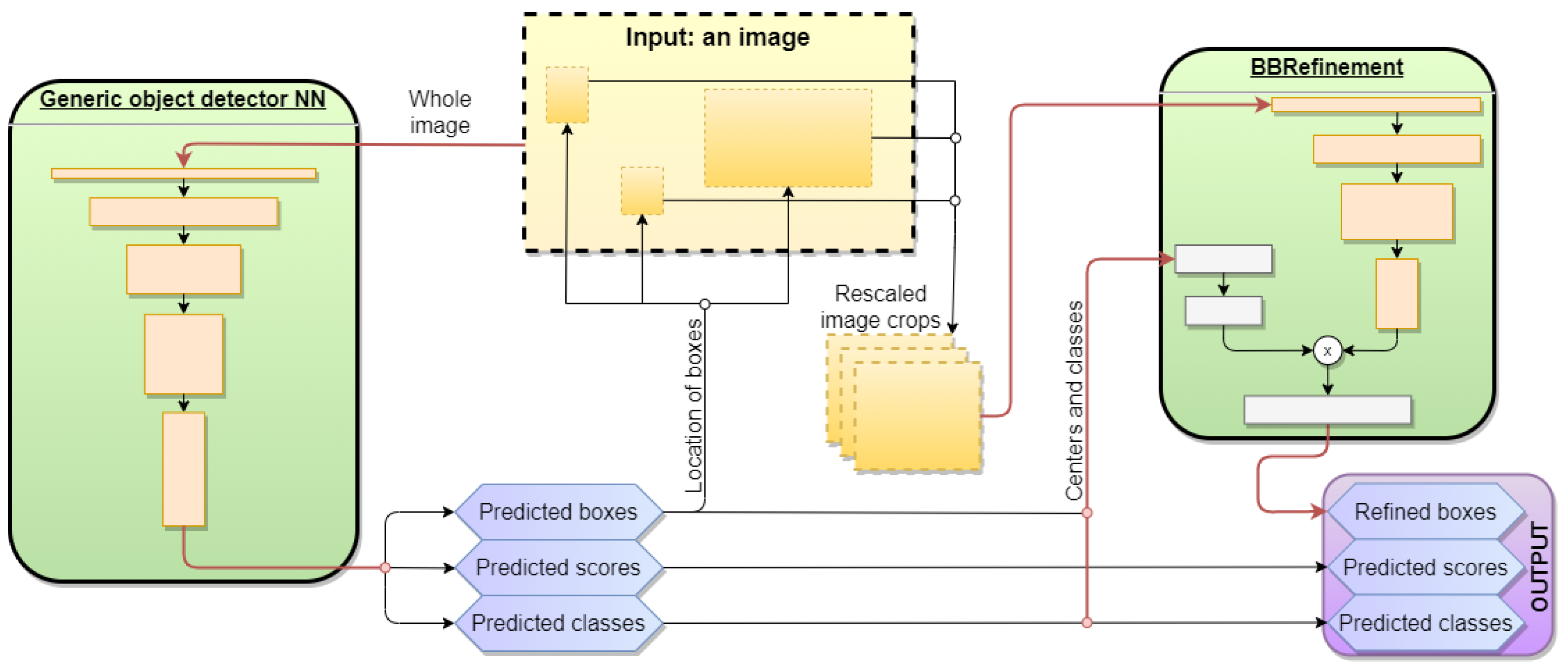
2. Explaining BBRefinement
2.1. Problem with a Naive Single Object Detector
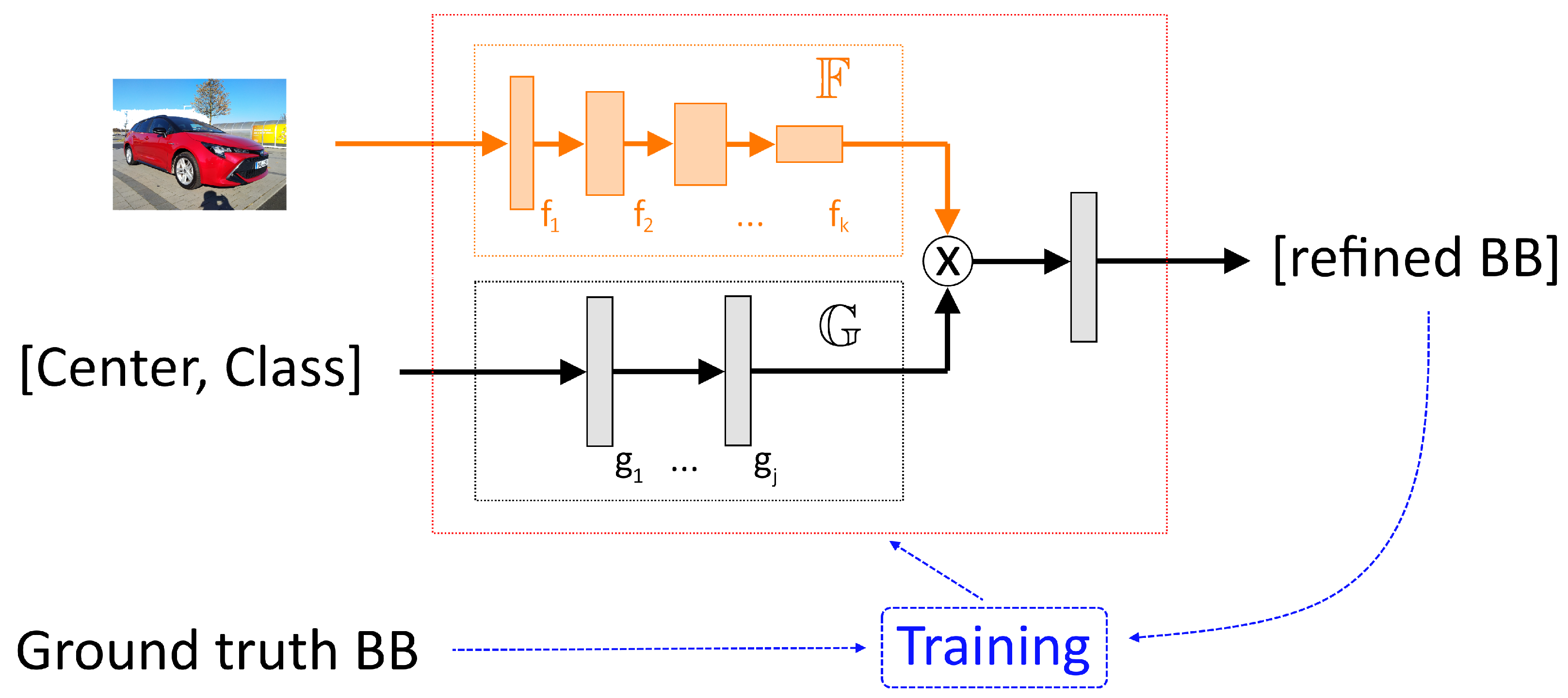
2.2. The Principle of BBRefinement
3. Benchmark
4. Discussion
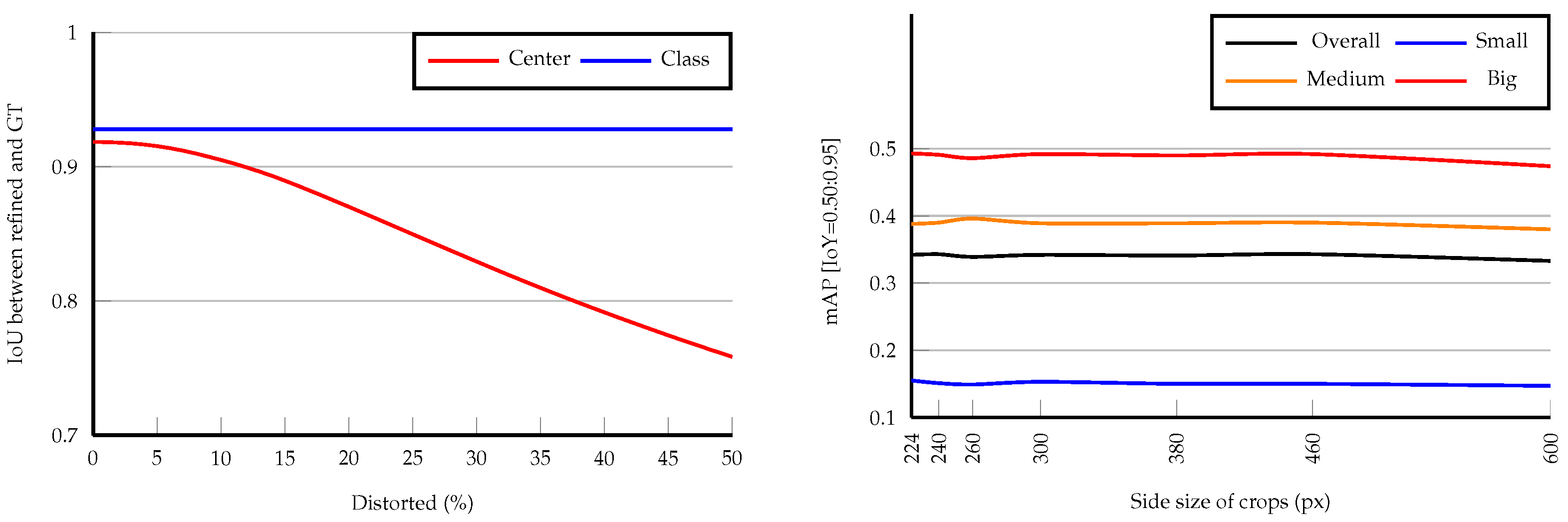
5. Ablation Study
6. Concluding Remarks
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| BB | Bounding Box |
| FPS | Frames per Second |
| GT | Ground Truth |
| IoU | Intersection over Union |
| mAP | Mean Average Precision |
| SOTA | State Of The Art |
References
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2014; pp. 740–755. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; pp. 91–99. [Google Scholar]
- Gidaris, S.; Komodakis, N. Object detection via a multi-region and semantic segmentation-aware cnn model. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1134–1142. [Google Scholar]
- Li, J.; Liang, X.; Li, J.; Wei, Y.; Xu, T.; Feng, J.; Yan, S. Multistage object detection with group recursive learning. IEEE Trans. Multimed. 2017, 20, 1645–1655. [Google Scholar] [CrossRef]
- Gong, J.; Zhao, Z.; Li, N. Improving Multi-stage Object Detection via Iterative Proposal Refinement. In Proceedings of the BMVC, Cardiff, UK, 9–12 September 2019; p. 223. [Google Scholar]
- Zhang, S.; Wen, L.; Bian, X.; Lei, Z.; Li, S.Z. Single-shot refinement neural network for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4203–4212. [Google Scholar]
- Zhang, S.; Wen, L.; Lei, Z.; Li, S.Z. RefineDet++: Single-Shot Refinement Neural Network for Object Detection. IEEE Trans. Circuits Syst. Video Technol. 2020, 31, 674–687. [Google Scholar] [CrossRef]
- Cai, Z.; Vasconcelos, N. Cascade r-cnn: Delving into high quality object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6154–6162. [Google Scholar]
- Felzenszwalb, P.F.; Girshick, R.B.; McAllester, D.; Ramanan, D. Object detection with discriminatively trained part-based models. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 32, 1627–1645. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2016; pp. 21–37. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Law, H.; Deng, J. Cornernet: Detecting objects as paired keypoints. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 734–750. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-End Object Detection with Transformers. arXiv 2020, arXiv:2005.12872. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Tan, M.; Le, Q.V. Efficientnet: Rethinking model scaling for convolutional neural networks. arXiv 2019, arXiv:1905.11946. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Rezatofighi, H.; Tsoi, N.; Gwak, J.; Sadeghian, A.; Reid, I.; Savarese, S. Generalized intersection over union: A metric and a loss for bounding box regression. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 658–666. [Google Scholar]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-IoU Loss: Faster and Better Learning for Bounding Box Regression. In Proceedings of the The Thirty-Fourth AAAI Conference on Artificial Intelligence (AAAI-20), New York, New York, USA, 2020, 7–12 February; pp. 12993–13000.
- Zeiler, M.D. Adadelta: An adaptive learning rate method. arXiv 2012, arXiv:1212.5701. [Google Scholar]
- Smith, L.N. Cyclical learning rates for training neural networks. In Proceedings of the 2017 IEEE Winter Conference on Applications of Computer Vision (WACV), Santa Rosa, CA, USA, 24–31 March 2017; pp. 464–472. [Google Scholar]
- Pizer, S.M.; Johnston, R.E.; Ericksen, J.P.; Yankaskas, B.C.; Muller, K.E. Contrast-limited adaptive histogram equalization: Speed and effectiveness. In Proceedings of the First Conference on Visualization in Biomedical Computing; IEEE Computer Society: Washington, DC, USA, 1990; pp. 337–338. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Brock, A.; De, S.; Smith, S.L. Characterizing signal propagation to close the performance gap in unnormalized ResNets. arXiv 2021, arXiv:2101.08692. [Google Scholar]
- Radiuk, P.M. Impact of training set batch size on the performance of convolutional neural networks for diverse datasets. Inf. Technol. Manag. Sci. 2017, 20, 20–24. [Google Scholar] [CrossRef]
- Qiao, S.; Chen, L.C.; Yuille, A. DetectoRS: Detecting Objects with Recursive Feature Pyramid and Switchable Atrous Convolution. arXiv 2020, arXiv:2006.02334. [Google Scholar]
- Hurtik, P.; Molek, V.; Hula, J.; Vajgl, M.; Vlasanek, P.; Nejezchleba, T. Poly-YOLO: Higher speed, more precise detection and instance segmentation for YOLOv3. arXiv 2020, arXiv:2005.13243. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| BBRefinement, EfficientNet | ||||||||
|---|---|---|---|---|---|---|---|---|
| Model | Source | Baseline | B0 | B1 | B2 | B3 | B4 | Boost |
| All objects | ||||||||
| Faster R-CNN, ResNet-50 C4 1x | Detectron2 | 35.7 | 37.3 | 37.4 | 37.7 | 37.8 | 37.7 | +2.1 |
| Faster R-CNN ResNet-101 C4 3x | Detectron2 | 41.1 | 41.6 | 41.6 | 42.0 | 42.1 | 42.0 | +1.0 |
| Faster R-CNN, ResNeXt-101 FPN 3x | Detectron2 | 43.0 | 43.0 | 43.1 | 43.4 | 43.5 | 43.4 | +0.5 |
| RetinaNet, ResNet-50 FPN 1x | Detectron2 | 37.4 | 38.2 | 38.3 | 38.6 | 38.6 | 38.6 | +1.2 |
| RetinaNet, ResNet-101 FPN 3x | Detectron2 | 40.4 | 40.6 | 40.6 | 41.0 | 41.0 | 40.9 | +0.6 |
| Cascade Mask R-CNN, ResNet-50 FPN 1x | Detectron2 | 42.1 | 41.1 | 41.1 | 41.5 | 41.5 | 41.5 | −0.6 |
| Mask R-CNN ResNet-50 FPN 1x | Detectron2 | 38.6 | 39.6 | 39.7 | 40.0 | 40.2 | 40.0 | +1.2 |
| Mask R-CNN ResNeXt-101 FPN 3x | Detectron2 | 44.3 | 44.0 | 44.1 | 44.4 | 44.5 | 44.4 | +0.2 |
| DETR, ResNet-50 | Standalone | 34.3 | 35.7 | 35.8 | 36.0 | 36.1 | 35.9 | +1.8 |
| YOLOv3 | MMDetection | 33.5 | 34.3 | 34.4 | 34.6 | 34.7 | 34.5 | +1.2 |
| SSD 512 | MMDetection | 29.4 | 31.2 | 31.3 | 31.5 | 31.6 | 31.4 | +2.2 |
| Small objects | ||||||||
| Faster R-CNN, ResNet-50 C4 1x | Detectron2 | 19.2 | 19.2 | 19.3 | 19.1 | 19.1 | 18.9 | +0.1 |
| Faster R-CNN ResNet-101 C4 3x | Detectron2 | 22.2 | 22.1 | 22.0 | 22.2 | 22.3 | 22.0 | +0.1 |
| Faster R-CNN, ResNeXt-101 FPN 3x | Detectron2 | 27.2 | 25.9 | 25.8 | 25.7 | 25.8 | 25.6 | −1.3 |
| RetinaNet, ResNet-50 FPN 1x | Detectron2 | 24.0 | 22.0 | 22.0 | 22.1 | 22.1 | 21.8 | −1.9 |
| RetinaNet, ResNet-101 FPN 3x | Detectron2 | 24.0 | 23.4 | 23.2 | 23.3 | 23.6 | 23.2 | −0.4 |
| Cascade Mask R-CNN, ResNet-50 FPN 1x | Detectron2 | 24.3 | 22.6 | 22.4 | 22.5 | 22.6 | 22.5 | −1.7 |
| Mask R-CNN ResNet-50 FPN 1x | Detectron2 | 22.5 | 21.9 | 21.7 | 21.8 | 22.0 | 21.7 | −0.5 |
| Mask R-CNN ResNeXt-101 FPN 3x | Detectron2 | 27.5 | 26.4 | 26.1 | 26.2 | 26.3 | 26.2 | −1.1 |
| DETR, ResNet-50 | Standalone | 14.3 | 16.0 | 15.9 | 15.9 | 15.9 | 15.7 | +1.7 |
| YOLOv3 | MMDetection | 19.6 | 19.7 | 19.6 | 19.7 | 20.0 | 19.5 | +0.4 |
| SSD 512 | MMDetection | 11.7 | 12.8 | 12.5 | 12.7 | 12.7 | 12.5 | +1.1 |
| Medium objects | ||||||||
| Faster R-CNN, ResNet-50 C4 1x | Detectron2 | 40.9 | 42.3 | 42.6 | 42.8 | 42.8 | 42.8 | +1.9 |
| Faster R-CNN ResNet-101 C4 3x | Detectron22 | 45.5 | 46.2 | 46.3 | 46.6 | 46.6 | 46.6 | +1.1 |
| Faster R-CNN, ResNeXt-101 FPN 3x | Detectron2 | 46.1 | 46.5 | 46.7 | 47.0 | 47.0 | 46.9 | +0.9 |
| RetinaNet, ResNet-50 FPN 1x | Detectron2 | 41.6 | 42.8 | 42.9 | 43.2 | 43.2 | 43.1 | +1.6 |
| RetinaNet, ResNet-101 FPN 3x | Detectron2 | 44.3 | 44.8 | 44.9 | 45.3 | 45.2 | 45.0 | +1.0 |
| Cascade Mask R-CNN, ResNet-50 FPN 1x | Detectron2 | 45.2 | 44.5 | 44.6 | 45.0 | 45.1 | 44.9 | −0.1 |
| Mask R-CNN ResNet-50 FPN 1x | Detectron2 | 42.0 | 43.3 | 43.4 | 43.8 | 43.8 | 43.7 | +1.8 |
| Mask R-CNN ResNeXt-101 FPN 3x | Detectron2 | 47.6 | 47.9 | 48.0 | 48.4 | 48.3 | 48.3 | +0.8 |
| DETR, ResNet-50 | Standalone | 36.6 | 38.5 | 38.6 | 38.8 | 39.0 | 38.8 | +2.4 |
| YOLOv3 | MMDetection | 36.4 | 38.9 | 39.0 | 39.3 | 39.4 | 39.3 | +3.0 |
| SSD 512 | MMDetection | 34.1 | 37.3 | 37.4 | 37.7 | 37.7 | 37.5 | +3.6 |
| Large objects | ||||||||
| Faster R-CNN, ResNet-50 C4 1x | Detectron2 | 48.7 | 52.4 | 52.8 | 53.1 | 53.1 | 53.2 | +4.5 |
| Faster R-CNN ResNet-101 C4 3x | Detectron2 | 55.9 | 57.2 | 57.3 | 58.0 | 58.0 | 58.1 | +2.2 |
| Faster R-CNN, ResNeXt-101 FPN 3x | Detectron2 | 54.9 | 56.3 | 56.7 | 57.0 | 57.2 | 57.2 | +2.3 |
| RetinaNet, ResNet-50 FPN 1x | Detectron2 | 48.3 | 50.3 | 50.7 | 51.5 | 51.1 | 51.2 | +3.2 |
| RetinaNet, ResNet-101 FPN 3x | Detectron2 | 52.2 | 53.6 | 53.7 | 54.2 | 54.1 | 54.4 | +2.2 |
| Cascade Mask R-CNN, ResNet-50 FPN 1x | Detectron2 | 54.8 | 54.8 | 55.0 | 55.5 | 55.4 | 55.4 | +0.7 |
| Mask R-CNN ResNet-50 FPN 1x | Detectron2 | 49.9 | 52.8 | 53.1 | 53.4 | 53.7 | 53.6 | +3.8 |
| Mask R-CNN ResNeXt-101 FPN 3x | Detectron2 | 56.7 | 57.7 | 58.4 | 58.8 | 58.8 | 58.5 | +2.1 |
| DETR, ResNet-50 | Standalone | 51.5 | 52.1 | 52.3 | 52.7 | 52.7 | 52.6 | +1.2 |
| YOLOv3 | MMDetection | 43.6 | 44.1 | 44.3 | 44.7 | 44.9 | 44.7 | +1.3 |
| SSD 512 | MMDetection | 44.9 | 47.0 | 47.2 | 47.7 | 47.8 | 47.4 | +2.9 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hurtik, P.; Vajgl, M.; Hynar, D. BBRefinement: A Universal Scheme to Improve the Precision of Box Object Detectors. Appl. Sci. 2022, 12, 3402. https://doi.org/10.3390/app12073402
Hurtik P, Vajgl M, Hynar D. BBRefinement: A Universal Scheme to Improve the Precision of Box Object Detectors. Applied Sciences. 2022; 12(7):3402. https://doi.org/10.3390/app12073402
Chicago/Turabian StyleHurtik, Petr, Marek Vajgl, and David Hynar. 2022. "BBRefinement: A Universal Scheme to Improve the Precision of Box Object Detectors" Applied Sciences 12, no. 7: 3402. https://doi.org/10.3390/app12073402
APA StyleHurtik, P., Vajgl, M., & Hynar, D. (2022). BBRefinement: A Universal Scheme to Improve the Precision of Box Object Detectors. Applied Sciences, 12(7), 3402. https://doi.org/10.3390/app12073402