
Text Data Augmentation for the Korean Language


Abstract
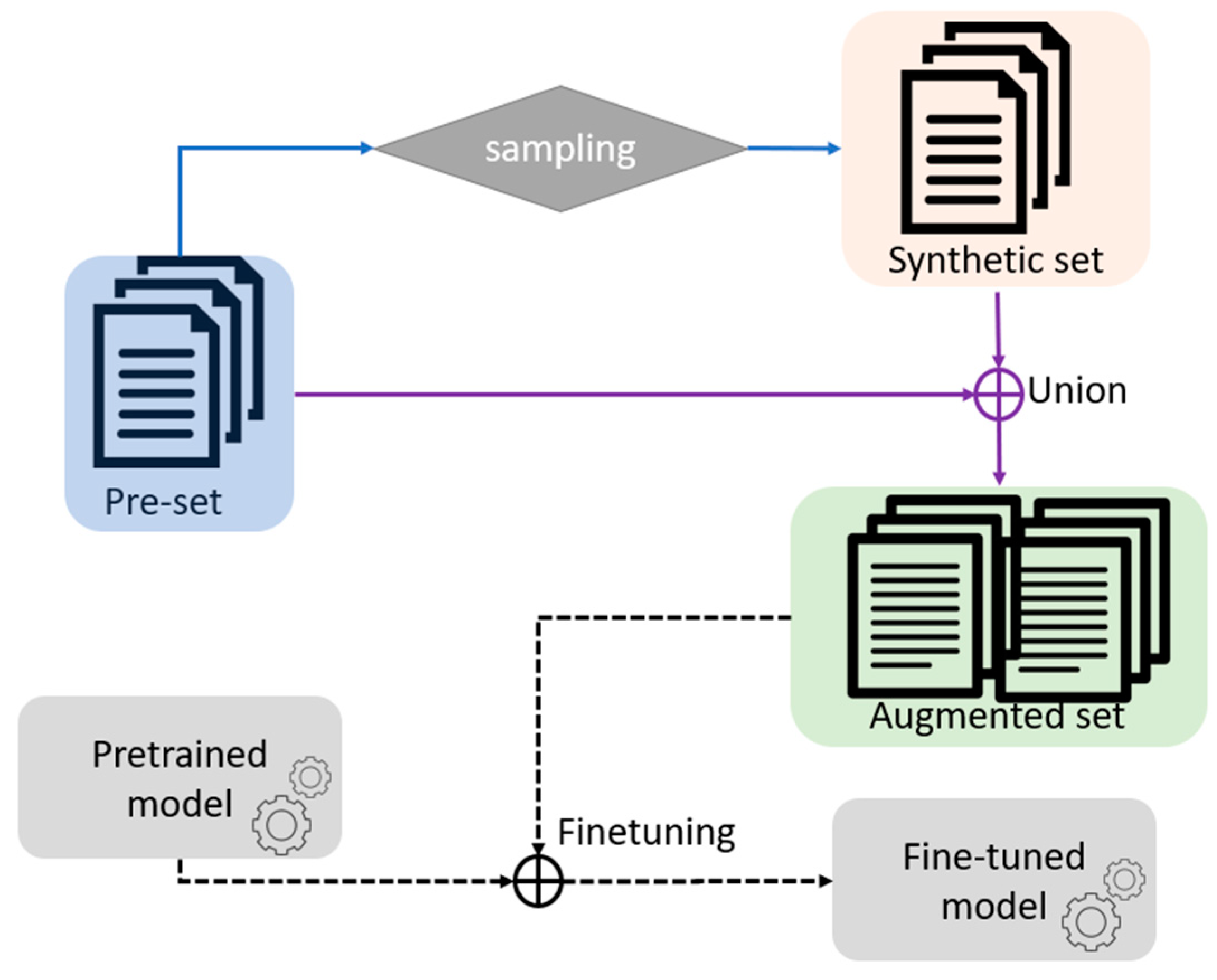
:1. Introduction
- We experiment on the Korean language with two tasks: semantic textual similarity (STS) and natural language inference (NLI). Both are supervised tasks that rely heavily on gold labeling. Also, we show the effect of data augmentation on duplication verification (QDV) and sentiment classification (STC).
2. Related Works
2.1. Related Studies on Data Augmentation
2.2. Korean Corpora and Their Pre-Trained Language Models
3. Data Augmentation
3.1. EDA: Easy Data Augmentation
- Synonym Replacement: The premise here is to randomly select words in the sentence that are neither stop words nor special tokens, and replace each of these words with one of its synonyms at random, i.e., , where is the index of a word replaced by its synonym. The parameter of this premise is the number of selected words , formulated as .
- Random Insertion: The premise here is to randomly select words in the sentence that are neither stop words nor special tokens, and concatenate each of these words with the next word in one of its possible bi-grams, i.e., , where is a bi-gram of the word at position . The parameter of this premise is the number of selected words formulated as .
- Random Swap: The premise here is to randomly select tuples of two words in the sentence and swap their positions where they are not consecutively restricted, i.e., , where are the indices of words whose position is interchanged. The parameter of this premise is the number of selected tuples formulated as .
- Random Deletion: The premise here is to randomly remove selected words with a certain probability in the sentence , i.e., , where is the index of a word that will be deleted. The parameters of this premise are the number of chosen words and the probability of removing them, formulated as .
3.2. Back Translation
4. Experiments and Results
4.1. Dataset
- KorNLI: This dataset is for the natural language inference task, consisting of 950,354 pairs of sentences translated from English. An example’s label is one of three degrees of compatibility, entailment, contradiction, and neutral. The training set size is 942,854, while the development set has a size of 2490, and the test set has a size of 5010. In this study, we created random pre-sets by selecting 3927 samples (0.5%) from the training set.
- KorSTS: This dataset is for the semantic textual similarity task, consisting of 8628 pairs of sentences translated from English. An example’s label ranges from 0 to 5, indicating the magnitude of similarity between two sentences. The training set size is 5749, while the development set has a size of 1500, and the test set has size 1379. In this study, we created random pre-sets by selecting 1725 samples (30%) from the training set.
- NSCM: This dataset is for the sentiment analysis task, consisting of 200 k movie reviews collected by Naver movies. All reviews are shorter than 140 characters and are classified into two categories (0: negative, 1: positive). The training set size is 150 k reviews, while the test set has 50 k reviews. In this study, we created random pre-sets by selecting 3000 sentences (2%) from the training set.
- Question Pair: This dataset is for the duplication-checking task, consisting of 15,000 questions translated from English and arranged as pairs of sentences. The examples are classified into two types (0: no duplicate, 1: duplicated). The training set size is 6136 pairs, while the development set has 682 pairs, and the test set has 758 pairs. In this study, we created random pre-sets by selecting 1840 samples (30%) from the training set.
4.2. Downstream Task Evaluation
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Connor, S.; Khoshgoftaar, T.M. A survey on image data augmentation for deep learning. J. Big Data 2019, 6, 60. [Google Scholar]
- Xie, Q.; Dai, Z.; Hovy, E.; Luong, M.T.; Le, Q.V. Unsupervised Data Augmentation for Consistency Training. Adv. Neural Inf. Processing Syst. 2020, 33, 6256–6268. [Google Scholar]
- Johnson, M.; Schuster, M.; Le, Q.V.; Krikun, M.; Wu, Y.; Chen, Z.; Thorat, N.; Viégas, F.; Wattenberg, M.; Corrado, G.; et al. Google’s multilingual neural machine translation system: Enabling zero-shot translation. Trans. Assoc. Comput. Linguist. 2017, 5, 339–351. [Google Scholar] [CrossRef] [Green Version]
- Wei, J.; Zou, K. Eda: Easy data augmentation techniques for boosting performance on text classification tasks. arXiv 2019, arXiv:1901.11196. [Google Scholar]
- Kobayashi, S. Contextual augmentation: Data augmentation by words with paradigmatic relations. arXiv 2018, arXiv:1805.06201. [Google Scholar]
- Wu, X.; Lv, S.; Zang, L.; Han, J.; Hu, S. Conditional Bert contextual augmentation. In Proceedings of the International Conference on Computational Science, Faro, Portugal, 12–14 June 2019. [Google Scholar]
- Kumar, V.; Choudhary, A.; Cho, E. Data augmentation using pre-trained transformer models. arXiv 2020, arXiv:2003.02245. [Google Scholar]
- Yang, Y.; Malaviya, C.; Fernandez, J.; Swayamdipta, S.; le Bras, R.; Wang, J.-P.; Bhagavatula, C.; Choi, Y.; Downey, D. Generative Data Augmentation for Commonsense Reasoning. In Findings of the Association for Computational Linguistics: EMNLP 2020; Association for Computational Linguistics: Stroudsburg, PA, USA, 2020; pp. 1008–1025. [Google Scholar]
- Schick, T.; Schütze, H. Generating Datasets with Pretrained Language Models. arXiv 2021, arXiv:2104.07540. [Google Scholar]
- Thakur, N.; Reimers, N.; Daxenberger, J.; Gurevych, I. Augmented SBERT: Data Augmentation Method for Improving Bi-Encoders for Pairwise Sentence Scoring Tasks. arXiv 2020, arXiv:2010.08240. [Google Scholar]
- Schick, T.; Hinrich, S. Few-Shot Text Generation with Natural Language Instructions. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, Punta Cana, Dominican Republic, 7–11 November 2011; Association for Computational Linguistics: Punta Cana, Dominican Republic, 2021; pp. 390–402. [Google Scholar]
- Edunov, S.; Ott, M.; Auli, M.; Grangier, D. Understanding Back-Translation at Scale. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; Association for Computational Linguistics: Brussels, Belgium, 2018; pp. 489–500. [Google Scholar]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Lewis, M.; Liu, Y.; Goyal, N.; Ghazvininejad, M.; Mohamed, A.; Levy, O.; Stoyanov, V.; Zettlemoyer, L. BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension. arXiv 2019, arXiv:1910.13461. [Google Scholar]
- Reimers, N.; Gurevych, I. Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks. arXiv 2019, arXiv:1908.10084. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Reimers, N.; Gurevych, I. Making monolingual sentence embeddings multilingual using knowledge distillation. arXiv 2020, arXiv:2004.09813. [Google Scholar]
- Cho, W.I.; Moon, S.; Song, Y. Open Korean Corpora: A Practical Report. In Proceedings of the Second Workshop for NLP Open Source Software (NLP-OSS); Association for Computational Linguistics: Stroudsburg, PA, USA, 2020; pp. 85–93. [Google Scholar]
- Lee, S.; Jang, H.; Baik, Y.; Park, S.; Shin, H. Kr-bert: A small-scale korean-specific language model. arXiv 2020, arXiv:2008.03979. [Google Scholar]
- Ham, J.; Choe, Y.J.; Park, K.; Choi, I.; Soh, H. KorNLI and KorSTS: New Benchmark Datasets for Korean Natural Language Understanding. In Findings of the Association for Computational Linguistics: EMNLP 2020; Association for Computational Linguistics: Stroudsburg, PA, USA, 2020; pp. 422–430. [Google Scholar]
- Lee, H.; Yoon, J.; Hwang, B.; Joe, S.; Min, S.; Gwon, Y. Korealbert: Pretraining a lite bert model for korean language understanding. In Proceedings of the 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021; pp. 5551–5557. [Google Scholar]
- Tang, Y.; Tran, C.; Li, X.; Chen, P.-J.; Goya, N.; Chaudhary, V.; Gu, J.; Fan, A. Multilingual translation with extensible multilingual pretraining and fine-tuning. arXiv 2020, arXiv:2008.00401. [Google Scholar]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. Roberta: A robustly optimized bert pretraining approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Lan, Z.; Chen, M.; Goodman, S.; Gimpel, K.; Sharma, P.; Soricut, R. Albert: A lite bert for self-supervised learning of language representations. arXiv 2019, arXiv:1909.11942. [Google Scholar]
- Clark, K.; Luong, M.-T.; Le, Q.V.; Manning, C.D. Electra: Pre-training text encoders as discriminators rather than generators. arXiv 2020, arXiv:2003.10555. [Google Scholar]


{kind=link}
| Model/Task | SKT-koBERT 1 | SKT-GPT2 2 | KrBERT 3 | ENLIPLE-v2 4 | KoELECTRA-Base-v3 5 | BERT-Base 6 |
|---|---|---|---|---|---|---|
| Pretrained language model | ||||||
| Pretrained dataset | 25 M sentences | 40 GB of text | 20 M sentences | 174 M sentences | 180 M sentences | 100 GB of text |
| Pretrained topic | Wikipedia | Wikipedia | Wikipedia + news | Wikipedia + news | News comments | Reviews + blog |
| Tokenizer | Sentence Piece | character BPE | Bidirectional WordPiece | WordPiece | WordPiece | WordPiece |
| Vocab size (word) | 8 K | 51 K | 16 K | 32 K | 30 K | 42 K |
| Finetuned dataset (downstream task) | ||||||
| NSCM (Sentiment analysis) 7 | 90.10 | 93.3 | 89.84 | 90.63 | 90.87 | |
| koSTS (Semantic textual similarity) 8 | 79.64 | 78.4 | 84.75 | 85.53 | 84.31 | |
| KorQuad (Question- answering) 9 | 80.27 | 89.18 | 91.77 | 93.45 | 89.45 | |
| KorNER (Named entity recognition) 10 | 86.11 | 64.50 | 88.11 | 87.27 | ||
| KorNLI (Natural language inference) 11 | 79.00 | 83.21 | 82.24 | 82.32 | ||
| Methods | Augmented Example | Translation |
|---|---|---|
| Original | 한 남자가 자전거를 타고 있다 | A man is riding a bicycle |
| SR | Ex1: 한 남자가 사이클를 타고 있다 Ex2: 한 아드님가 자전거를 타고 있다 | Ex1: A man is riding a cycle Ex2: A child is riding a bicycle |
| RI | Ex1: 한 국한 남자가 자전거를 타고 있다 Ex2: 한 남자가 자전거를 타고 범위 있다 | Ex1: A local man is riding a bicycle Ex2: A man is riding a bicycle and has a range |
| RS | EX1: 한 남자를 자전거가 타고 있다 Ex2: 한 남자가 자전거 타고를있다 | Ex1: A bicycle is riding a man Ex2: A man riding a bicycle |
| RD | Ex1: 한 남자 자전거를 타고 있다 Ex2: 남자 자전거를 타고 있다 | Ex1: A man riding a bicycle Ex2: Man is riding a bicycle |
| BT | 한 남자가 자전거를 타는 것입니다 | A man is riding a bicycle |
| Dataset | Full Training Dataset | Pre-Dataset | Augmented Dataset | |
|---|---|---|---|---|
| EDA | Back Translation | |||
| KorNLI | 83.21 | 71.27 | 73.93 | 72.81 |
| KorSTS | 84.75 | 81.70 | 81.54 | 81.99 |
| Dataset | Full Training Dataset | Pre-Dataset | Augmented Dataset | |
|---|---|---|---|---|
| EDA | Back Translation | |||
| KorNLI | 82.24 | 71.25 | 73.49 | 72.13 |
| Question Pair | 95.25 | 94.19 | 94.85 | 93.13 |
| KorSTS | 85.53 | 81.67 | 82.54 | 83.86 |
| NSCM | 90.63 | 86.32 | 86.40 | 85.60 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Vu, D.T.; Yu, G.; Lee, C.; Kim, J. Text Data Augmentation for the Korean Language. Appl. Sci. 2022, 12, 3425. https://doi.org/10.3390/app12073425
Vu DT, Yu G, Lee C, Kim J. Text Data Augmentation for the Korean Language. Applied Sciences. 2022; 12(7):3425. https://doi.org/10.3390/app12073425
Chicago/Turabian StyleVu, Dang Thanh, Gwanghyun Yu, Chilwoo Lee, and Jinyoung Kim. 2022. "Text Data Augmentation for the Korean Language" Applied Sciences 12, no. 7: 3425. https://doi.org/10.3390/app12073425
APA StyleVu, D. T., Yu, G., Lee, C., & Kim, J. (2022). Text Data Augmentation for the Korean Language. Applied Sciences, 12(7), 3425. https://doi.org/10.3390/app12073425