Abstract
Cyberbullying has become more prevalent in online social media platforms. Natural language processing and machine learning techniques have been employed to develop automatic cyberbullying detection models, which are only designed for binary classification tasks that can only detect whether the text contains cyberbullying content. Cyberbullying severity is a critical factor that can provide organizations with valuable information for developing cyberbullying prevention strategies. This paper proposes a hierarchical squashing-attention network (HSAN) for classifying the severity of cyberbullying incidents. Therefore, the study aimed to (1) establish a Chinese-language cyberbullying severity dataset marked with three severity ratings (slight, medium, and serious) and (2) develop a new squashing-attention mechanism (SAM) of HSAN according to the squashing function, which uses vector length to estimate the weight of attention. Experiments indicated that the SAM could sufficiently analyze sentences to determine cyberbullying severity. The proposed HSAN model outperformed other machine-learning-based and deep-learning-based models in determining the severity of cyberbullying incidents.
1. Introduction
With the prevalence of the Internet, social media has become a convenient platform for people to communicate. However, although social media is convenient and beneficial for communication, it has created several problems. In 2017, the Royal Society for Public Health (Royal Society for Public Health (RSPH) is an independent campaigning and educational charity dedicated to improving and protecting the health of people. https://www.rsph.org.uk/, accessed on 31 July 2021) in the UK reported that social networking sites contributed to physical and mental health effects such as anxiety, loneliness, and lack of sleep among nearly 1500 young people. The results of the aforementioned organization also indicated that Instagram is the social media platform most likely to have a negative effect on the mental health of young users and that Snapchat is the most likely platform to make young people feel bullied or neglected. Social media causes psychological damage, and the associated problems are exacerbated by cyberbullying [1,2,3,4,5]. People who communicate using social media are more likely to be victims of abuse or disrespect than those who do not. Therefore, cyberbullying is a critical research issue that requires increased attention in today’s online social media climate.
People on social media platforms often communicate using text-based comments or messages, which have become the primary means of cyberbullying. To manage to cyberbully, studies have combined natural language processing (NLP) and machine learning (ML) to identify automatically whether the text contains cyberbullying content. Specifically, a considerable amount of content on Twitter contains cyberbullying content [6]; thus, a cyberbullying detection technology that covers multiple social media platforms and targets various topics was developed in a previous study [7]. Moreover, numerous studies have indicated that compared with ML, deep learning (DL) has higher effectiveness in automatic cyberbullying detection [8]. However, DL models have rarely been employed in real-world environments because cyberbullying is not well-defined. Various studies have reported inconsistent findings on cyberbullying, which makes it difficult to eradicate cyberbullying effectively.
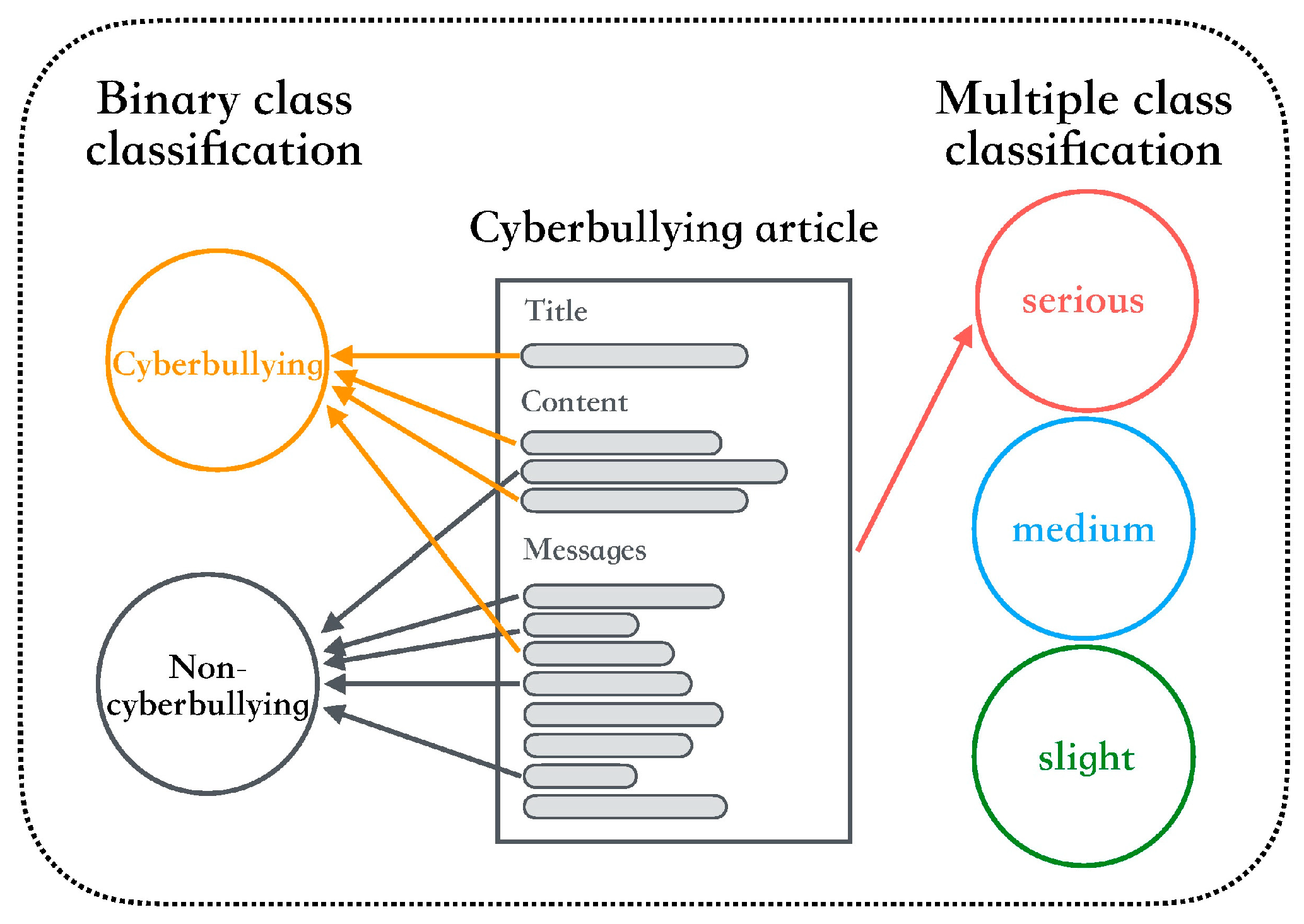
To address the issue of cyberbullying, additional emphasis should be placed on identifying cyberbullying severity. Since researchers have focused on binary classification for cyberbullying, the grading results among various cyberbullying content types differ considerably. Most social media content may be easily tolerated or ignored; however, some content remains sufficiently serious to cause adverse outcomes. In addition, the direct analysis of social media’s content to detect cyberbullying needs some variables such as behavioral patterns, personal factors, and environmental events [9,10,11,12]. These variables are very difficult to clearly define, because different cases have different behaviors. Therefore, there are no effective keywords, sentences, or patterns used to match the content of social media. To prevent cyberbullying incidents, a proposed detection model should be able to take action immediately; however, this feature is difficult to apply in practice. Therefore, if a cyberbullying detection model can classify cyberbullying incidents among different severity levels, the spread and influence of cyberbullying can be effectively prevented. Cyberbullying detection tasks mainly focus on whether text on contains cyberbullying content. Determining the severity of cyberbullying content can assist in avoiding cyberbullying incidents and help victims feel safe. Figure 1 displays the concept of a multi-class cyberbullying classification task. The present study identified the cyberbullying level based on a full dialogue (i.e., title, content, and all comments), because the same sentences may appear within different contexts in different dialogue, which results in varying influences and meanings. Therefore, the cyberbullying level can be obtained more easily when detected using a full dialogue.
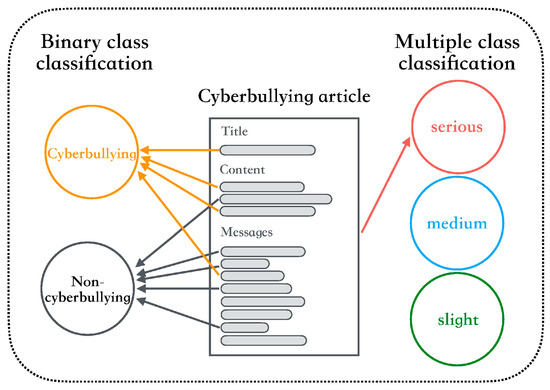
Figure 1.
Cyberbullying severity classification task.
To address the problem of grading the cyberbullying severity for a full dialogue, the current study aimed to (1) establish a Chinese-language cyberbullying severity dataset marked with cyberbullying severity ratings (slight, medium, and serious) based on cyberbullying characteristics identified in full dialogues and (2) develop a cyberbullying severity classification model based on a hierarchical neural network (HAN) [13] that can effectively identify cyberbullying severity level. The model proposed in this paper is the hierarchical squashing-attention network (HSAN), which can automatically determine the severity level of various cyberbullying incidents.
2. Literature Review
This section addresses research issues involving automatic cyberbullying detection systems based on an extensive literature review. A considerable amount of literature on applications of the deep learning approach is also reviewed.
2.1. Cyberbullying
Cyberbullying is bullying conducted using tools or channels such as electronic equipment or communication software. With advances in technology, sources of cyberbullying have become increasingly diverse. Cyberbullying incidents have increased yearly and have attracted increasing attention [14,15]. Currently, the definition of cyberbullying is not clear, because similar contents from multiple sources may represent different opinions and meanings. Patchin and Hinduja [16] defined cyberbullying as the harm intentionally and repetitively caused through electronic media. The basic definition of bullying also includes the characteristics of intent, repetition, and harm. Thus, cyberbullying is the transmission of malicious text messages or images intended to harass others over the Internet [17]. Snakenborg et al. [18] defined cyberbullying as the use of electronic media by individuals or groups to disseminate information about others maliciously and repetitively. Cyberbullying messages are offensive or sexually suggestive and cause the victim to feel afraid or offended. Automatic cyberbullying detection techniques have attracted an increasing amount of attention, particularly in NLP and ML. Automatic cyberbullying detection tasks mainly focus on whether the text contains cyberbullying content [19]. Cyberbullying events [20] involving racial, sexual, and sexual orientation discrimination are the object of cyberbullying classification [21]. In summary, cyberbullying is a crucial topic that requires increased attention. Various types of cyberbullying incidents produce varying degrees of harm. Cyberbullying incident severity may be affected by factors such as incident background or the environment of the people involved [22]. Therefore, the real-time detection and classification of cyberbullying severity can assist the management of real-world cyberbullying problems. Moreover, such detection and classification can enable organizations to use appropriate mitigation techniques based on cyberbullying severity to reduce the number of cyberbullying incidents in real time.
2.2. Machine Learning
Text classification is common in NLP. Numerous studies have focused on sentiment analysis, spam classification, and topic classification. The traditional text classification method uses features generated using a vector space model, such as term frequency-inverse document frequency (TFIDF), to represent a text vector, which is typically a high-dimensional and sparse feature vector that often ignores contextual semantic and word order information [23]. ML algorithms can detect cyberbullying or malicious speech based on the aforementioned features. Most methods use labeled training data for supervised learning. Reynolds et al. [24] collected and labeled data from a website and trained a C4.5 decision tree ML model to achieve an accuracy of 78.5%. Dinakar et al. [25] employed four ML approaches to detect comments related to three sensitive categories (i.e., racial discrimination, sexual bullying, and personal attacks) on YouTube. Dadvar et al. [19] revealed that research on cyberbullying detection has mainly focused on the content of comments and has ignored user background information. Therefore, to mark the bullying type of a comment, a user’s age and comment history should be included. Additional features, such as the frequency of attack words, have been used to improve cyberbullying detection in YouTube comment data when using a support vector machine (SVM) model. Huang et al. [26] used keywords as features to detect cyberbullying content automatically in a Twitter dataset. They improved the detection accuracy by considering user relationships and conducting social network analysis. Zhao et al. [27] used the word embedding method to predefine attack vocabulary and assign weights to cyber features for detecting cyberbullying incidents by using an SVM classifier, which exhibited an excellent performance when using Twitter data. Chatzakou et al. [21] distinguished general, offensive, and cyberbullying users on the basis of cyberbullying repetitiveness and used a random forest classifier to detect cyberbullying incidents whose areas under the curve exceeded 90%. Gutiérrez-Esparza et al. [28] proposed the use of an OneR model to classify situations of cyber aggression on social networks among Spanish-language users in Mexico. Their results indicated that the OneR model classified such situations with greater than 90% accuracy. Cheng et al. [29] considered social networks to include multiple modes of information, such as images, self-introductions, times, and locations. Such information is relevant for obtaining effective cyberbullying detection models constructed using a heterogeneous network of multimodal information.
2.3. Deep Neural Networks
An increasing number of studies on cyberbullying detection have employed DL methods to eliminate the manual feature extraction stage required in traditional ML because no specific or clear characteristics exist for detecting cyberbullying on different platforms. Deep neural networks have been widely applied to address various problems, such as environmental sound classification [30,31], scene parsing [32], large-scale projects construction [33], and near-misses [34]. Al-Ajlan and Ykhlef [6] reviewed studies on cyberbullying detection techniques for Twitter content and determined that most research methods for improving detection efficiency focused on the feature extraction stage without considering the semantics of words; however, language changes over time, and offensive speech is constantly being innovated. Optimizing detection performance by using feature engineering approaches is difficult. Many researchers have adopted NLP approaches and DL methods to solve cyberbullying detection problems with a backpropagation algorithm for deep neural networks to obtain a set of word vectors that learn semantics and grammar by using a corpus.
Accordingly, DL methods have a superior detection performance to traditional ML methods. Another critical model for sequential data is a recurrent neural network (RNN), which has been used to solve numerous NLP tasks. An RNN is a neural network-based model that uses a memory mechanism to remember the last state to the next time step. However, RNNs may exhibit a vanishing gradient problem if the data contain long sequence features. Therefore, Hochreiter and Schmidhuber [35] proposed a new RNN model based on long short-term memory (LSTM), which contains three gates that are used as control mechanisms of the cell (i.e., the forget gate, input gate, and output gate). These gates can manage and predict critical hidden features with long intervals in the time series and overcome the drawbacks of the original RNN. Moreover, Chung et al. [36] proposed the gated recurrent unit (GRU) model to simplify the architecture of LSTM. In their model, the forget and input gates are replaced with the “update gate” to expedite execution and reduce memory consumption. Menini et al. [37] developed a cyberbullying detection system for educators that targeted students’ social network relationships on Instagram and used LSTM to classify offensive messages. Since hate speech is on the rise, identifying whether repeated attacks against the same student have occurred is critical. In summary, RNNs have been employed in numerous studies to extract hidden features from text data effectively. Thus, RNN-based models, such as the simple RNN, GRU, and LSTM models, apply to numerous sequential data classification and regression problems.
Convolutional neural networks (CNNs) are used to retain semantics, eliminate time-consuming feature extraction, and effectively improve classification accuracy. In general, CNN models are used to extract hidden features from an image. In recent years, CNN applied to extract hidden features from text data based on word embeddings, and it can improve performances. This method can also be applied to text for extracting hidden local features of text sequences. Kim [38] proposed that the CNN model can be used to extract hidden features from the text for sentence classification tasks and that word2vec pretrained word vectors can be used as input features for CNN models. CNN uses different numbers of convolution kernels to extract multilevel features from text according to the model weight sharing approach. Moreover, the max-pooling approach has been used to extract critical features, and the SoftMax function has been used to determine the probability that each feature belongs to a certain category. Therefore, the CNNs method has been widely applied in text classification studies. Agrawal and Awekar [7] revealed that current cyberbullying detection technology can only classify bullying speech for a single topic on a specific platform; therefore, these researchers used CNN, LSTM, bidirectional LSTM, and bidirectional LSTM with an attention mechanism to overcome this drawback. The results of the aforementioned authors indicated that DL models can achieve high performance on various topics across multiple social platforms, such as Formspring, Twitter, and Wikipedia. Rosa et al. [8] compared SVMs and logistic regression with three DL methods (i.e., CNN, C-LSTM, and CNN-LSTM) to address text classification issues. Their results indicated that C-LSTM outperformed the other models on the Formspring bullying dataset. However, the combination of a CNN and an RNN also exhibits favorable performance in text classification tasks. Lai et al. [39] proposed a recurrent CNN (RCNN) to obtain semantic word vectors and used max-pooling to extract crucial features for obtaining the entire text vector. The RCNN exhibited a high classification performance. In addition, the bidirectional encoder representations from Transformers (BERT) are a powerful representation learning model, with trainings on two tasks such as masked language modeling and next sentence prediction [40]. BERT belongs to a pretrained model to obtain text representations and to improve performances in the downstream task. Therefore, many researchers use the BERT to be a pretrained model and fine-tune the models in many tasks [41,42].
In summary, many studies have addressed automated cyberbullying detection; however, their definitions of cyberbullying differ. Some studies have detected cyberbullying from only a single sentence; some studies have used an attack vocabulary to match words, and some studies have used supplemental user background information for detecting cyberbullying. According to common cyberbullying characteristics, a pattern of behavior repeated over time is a critical defining factor of cyberbullying, and optimizing detection only by adding features is difficult. However, DL methods have obtained satisfactory performance in several studies and have outperformed various feature engineering approaches. Furthermore, if identification is based on the complete context of an article, high detection accuracy can be achieved.
2.4. Hierarchical Neural Networks
People generally understand a sentence based on its keywords. Moreover, they understand a full article according to its key sentences [31]. Yang et al. [13] combined the attention mechanism with hierarchical hidden feature extraction to classify documents into four layers according to their hierarchical structure. First, the bidirectional GRU obtains each sentence feature, and weighted words are provided by the attention mechanism. The same process is then used to extract hidden features from the document. The attention mechanism uses these features to weigh the sum of important sentences. Finally, the SoftMax function was used to obtain the probability of each class. The attention mechanism can intuitively explain the importance of each word in a sentence and the importance of each sentence in an entire document. The HAN method is superior to methods that do not use a hierarchical extraction process for text classification. Gao et al. [43] combined the HAN architecture with a CNN to develop the Hierarchical Convolutional Attention Networks (HCAN) text classification model. These researchers demonstrated that a CNN can efficiently extract features from proximal words during training processing. Moreover, the attention mechanism is used to capture long-distance semantic relationships in the same manner as an RNN does. To shorten the training time and obtain favorable results, Cheng et al. [44] used the HAN method for cyberbullying detection. In their study, the HAN method outperformed keyword database development and sentiment analysis in cyberbullying detection. RNN, CNN, and hierarchical models have been frequently used to determine semantic relationships in text accurately and obtain favorable results in NLP. The hierarchical text extraction method is similar to human text reading and has obtained superior performance in numerous text classification tasks. Therefore, by adding the “message interval” feature to the HAN architecture, cyberbullying can be accurately identified. However, real-world cyberbullying cases are generally unbalanced. Previously proposed methods are not designed to address imbalanced data and thus exhibit poor performance in real-world cyberbullying detection.
3. Methodology
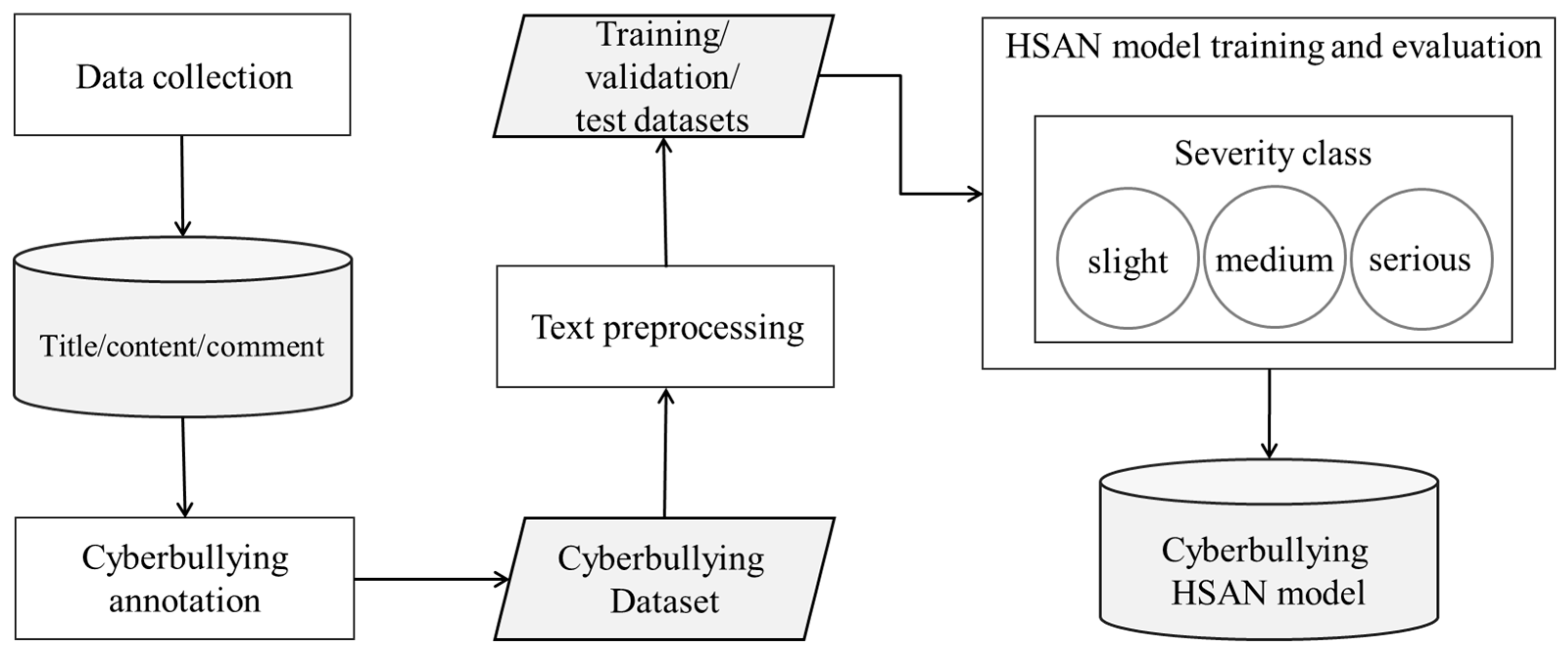
The proposed HSAN technical architecture is described in the following text. The HSAN is an improved version of the HAN in which the attention weight computation by SoftMax function is modified using the squashing function, which is designed according to the squashing function of capsule networks [45]. The squashing-attention mechanism (SAM) uses the length of the vector to estimate the attention weight for each word and each sentence. Figure 2 presents the five processes conducted in the current study: (1) data collection, (2) data labeling and filtering, (3) data preprocessing, (4) HSAN model construction and cyberbullying severity classification, and (5) loss function and model optimization. The details of each process are described in the following text.
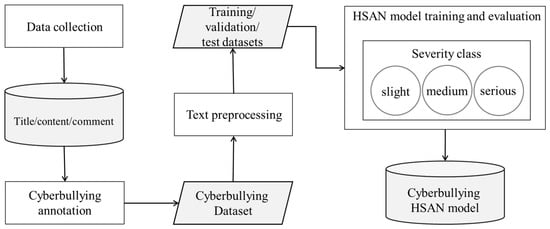
Figure 2.
Flowchart of the proposed HSAN method for cyberbullying severity classification.
3.1. Data Collection
Cyberbullying often involves text that targets individuals on the Internet. For example, the main perpetrator produces cyberbullying content on a post, and other perpetrators supplement the cyberbullying content with additional comments targeting the victim. Determining whether cyberbullying has occurred by simply viewing a message is not possible. Therefore, cyberbullying samples should be collected from interactive dialogues that contain one title, one primary piece of content, and numerous response comments because at least two people must be involved to constitute cyberbullying behavior.
3.2. Cyberbullying Annotation
After data collection with the data crawler, certain content types (e.g., emojis and hyperlinks) were determined to be unsuitable for cyberbullying classification. The detailed processing steps were as follows:
- (1).
- Preliminary filtration: Following cyberbullying characteristics, repetitive content from numerous users was required. A set of dialogues was established with corresponding response comments. Each dialogue required at least twenty corresponding comments in general cases.
- (2).
- Cyberbullying dialogue samples filtration: The cyberbullying dialogue was filtered using the manual method because the goal of this paper is cyberbullying severity.
- (3).
- Feature scoring: Five experts annotated all the cyberbullying dialogues independently following the labeling criteria. Intent, repetition, and aggression toward the victim were the criteria for determining cyberbullying severity. Table 1 summarizes the labeling standards in detail. Each criterion was scored on a scale of 1 (strongly disagree) to 3 (strongly agree). Thus, each dialogue could obtain three possible scores for determining severity level.
- (4).
- Cyberbullying severity labeling: Cyberbullying dialogues were labeled as described in the following text. If more than three experts provided the same score, the mode value was used. Furthermore, to remove outlier scores, the scores provided by the five experts were averaged. Finally, dialogues with scores of 3, 4, and 5 were labeled as “slight,” dialogues with scores of 6 or 7 were labeled as “medium,” and dialogues with scores of 8 or 9 were labeled as “serious.”

Table 1.
Labeling standards for cyberbullying.
Table 1.
Labeling standards for cyberbullying.
| Features | Labeling Rule |
|---|---|
| Intentional | Whether the content is targeted to a specific individual or a group, if so, further determines the number of people covered by the victimizer. The small number belongs to serious, and the larger number belongs to slight. |
| Repeated | The proportion of people attacking the same person in the message, the larger the proportion, the higher the repetition, and the degree of cyberbullying is relatively serious. |
| Aggressive | The content contains personal offensive remarks, belittle others’ personality, body, life, character, etc., or offensive comments on specific characteristics or sexual orientation. |
3.3. Text Preprocessing
This section describes the dataset containing text and labels. Before model training, all text was converted into an index sequence for the HSAN model.
3.3.1. Text Cleaning
The text obtained from the website could contain invalid content, such as hyperlinks, webpage tags, and emoticons. This invalid content was removed in advance. The English text in the data was converted to lowercase to avoid excessively repeated words.
3.3.2. Sentence and Word Segmentation
The proposed model is a hierarchical encoding and prediction process; therefore, all the text in each dialogue was segmented into a set of sentences (including content and comments), and each sentence contained a set of words. In sentence segmentation, sentence text was split using punctuation, including commas, periods, question marks, exclamation marks, semicolons, and new line. Jieba Chinese word segmentation tools (Chinese text segmentation: built to be the best Python Chinese word segmentation module. https://github.com/fxsjy/jieba, accessed on 1 May 2021) were used to split sentences into words.
3.3.3. Text Sequence Generation to Input Data
Before model training, all the text was transformed into dense vectors to obtain indices for representing the corresponding terms. Two terms, namely “PAD” and “UNK”, were used for text encoding processing. “PAD” represents the extra words used to create a dense vector because the feature input of the neural network model required a matrix of batch samples. All the terms in the training set were used to construct a vocabulary dictionary and transform the terms to indices with dense vectors in the training, validation, and test sets. Moreover, an unknown term (not in the vocabulary dictionary) in the validation, and test sets were replaced with the “UNK” term. For example, consider a dialogue consisting of L sentences, where each sentence contains T words. Suppose that w is expressed as a word in a sentence x, where . The sentence of title is , the sentences of content are , and the sentences of comments are . Thus, the total number of sentences is , where C is the number of sentences of content and the M is the number of sentences of comment.
3.4. HSAN Model Building
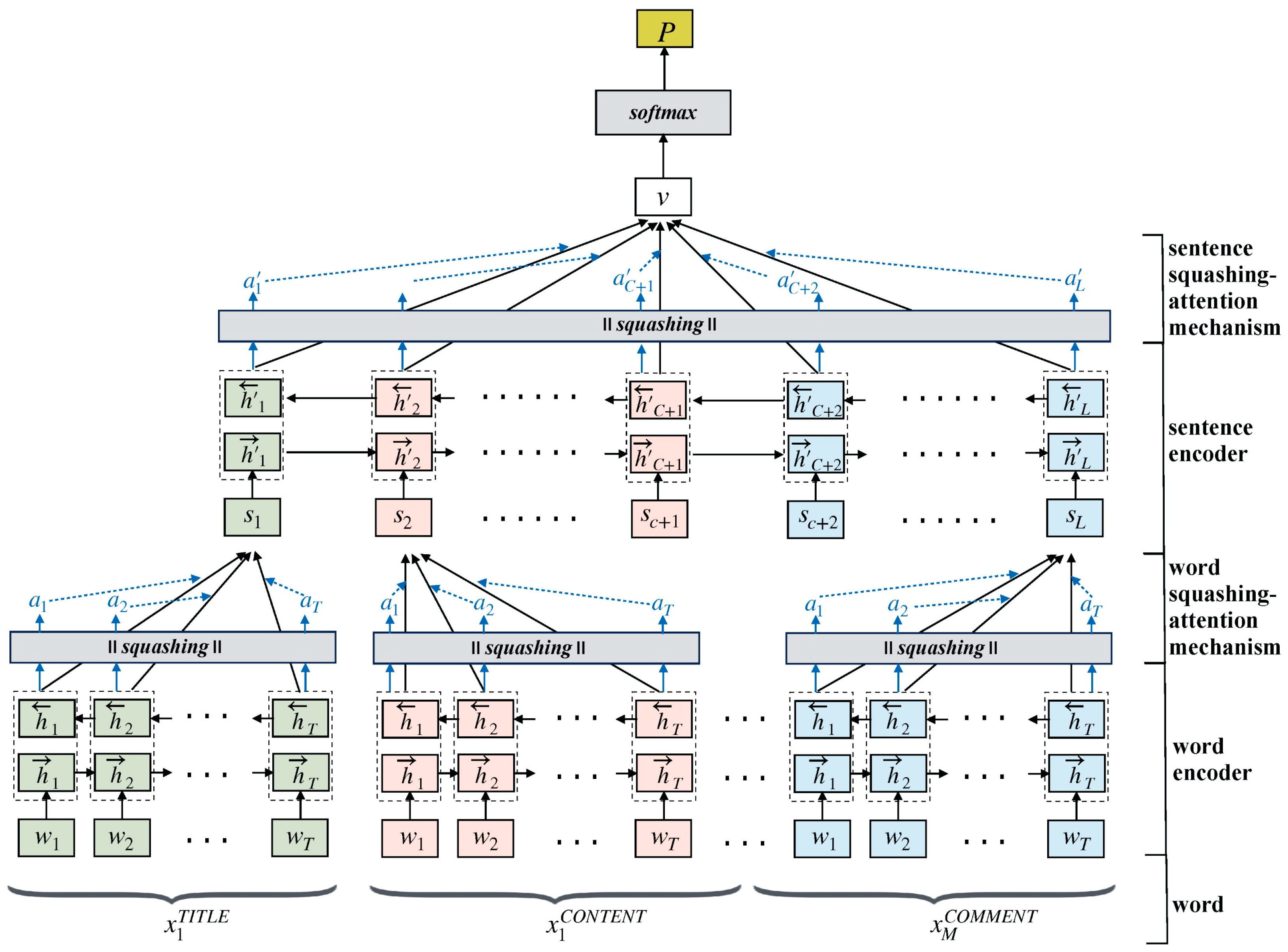
Our proposed HSAN uses a hierarchical text-encoding method to obtain a dialogue-encoding vector. The final hidden feature of the dialogue consists of four parts: (1) a word encoder for extracting hidden word features, (2) a word SAM for applying different attention weights to words, (3) a sentence encoder for extracting hidden features of sentences, and (4) a sentence SAM for applying different attention weights to words. Figure 3 presents the model architecture of the proposed HSAN. The detailed processes of the proposed HSAN are described in the following text.
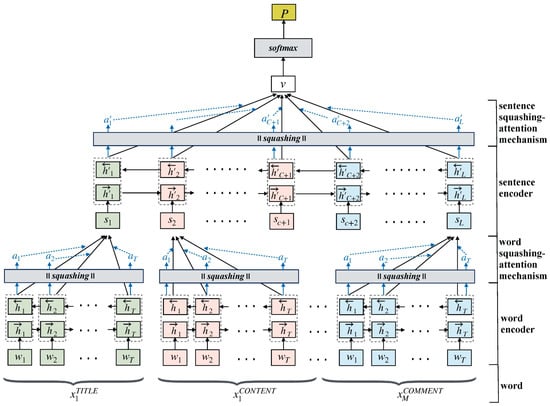
Figure 3.
Proposed HSAN for cyberbullying detection.
3.4.1. Word Encoder
This section describes the three text parts (i.e., title, content, and comments) input into the word encoder. The s is a word’s encoded vector by the word encoder for the three text parts. For example, the encoded title sentence is , the encoded content sentences are , and the encoded comment sentences are :
consists of the word encoding matrix which is used to represent the word of each sentence in the word encoding . The standard bidirectional GRU was used to obtain the hidden features of each word = . The forward indicates reading from the first word to the last word of the sentence, and the backward indicates reading from the last word to the first word.
Therefore, the obtained by connecting and represents the hidden features of the word learned after reading an entire sentence.
3.4.2. Word SAM
A GRU was used to estimate the hidden features for each word; however, each word exhibits different importance to the meaning of the sentence. Thus, a SAM was used to estimate the weight of each hidden feature of a word. If the SAM calculated the weighted sum of the hidden features of each word, the final sentence vector was obtained as follows:
where is a learnable weight, and is used to measure the importance of each word . uses squashing to compress so that its vector length falls between 0 and 1. The length of is used as the importance weight of the word , and the weighted sentence vector is obtained. The squashing-attention used is different from that of previous studies on the attention mechanism. For the weight value, a vector was used as an estimate instead of normalizing the value.
3.4.3. Sentence Encoder
The sentence vector was obtained from the aforementioned word encoder. The bidirectional GRU was used to obtain the hidden features of the sentence =,.
where is obtained by connecting with to represent the hidden features of the th sentence, which constitutes learning of the contextual semantic relationship.
3.4.4. Sentence SAM
A SAM was used to estimate the attention weight of the hidden features of each sentence. If the attention weight of the hidden feature of each sentence was estimated using the SAM, the final text vector was obtained as follows:
where is a learnable weight and is used to measure the importance of the hidden feature of the sentence. Squashing was performed to compress so that its vector length was between 0 and 1. The length of the obtained value was calculated as the importance weight of the sentence . Finally, the hidden features of a dialogue were obtained after the weighting was determined.
3.4.5. Classification of Cyberbullying Severity
The text encoding vector of a dialogue was obtained for the classification of cyberbullying severity. The probability P of cyberbullying severity belonging to a certain class is expressed as follows:
where and are trainable weights and SoftMax is used for probability transformation. The severity levels of the proposed HSAN are classified into three categories: slight, medium, and serious. represent the probabilities of the three categories output by the proposed model. Cross-entropy was used as the loss function to calculate the loss value, and the final loss value is expressed as follows:
where represents the target labels of cyberbully severity; if the label category is , then ; otherwise, . The parameter denotes all the trainable parameters of the proposed HSAN model.
4. Experimental Results
This section describes the experimental data, implemented models, experimental design, and data analysis results.
4.1. Experimental Data
The experimental data (dialogues) were collected from the “gossip” board of the PTT forum (PTT Bulletin Board System: is the largest terminal-based bulletin board system (BBS) based in Taiwan. https://www.ptt.cc/, accessed on 1 January 2021) in Taiwan from January to June 2019. After data preprocessing, 5000 dialogues containing cyberbullying content were selected. All the dialogues were independently annotated for cyberbullying severity labeling by five experts. Table 2 presents the Mean Absolute Error (MAE) used to measure annotation consistency between the final label and label of each annotator. The average MAE of annotation consistency was 0.52.
Table 2.
MAE of the five annotations and the final classification results.
Table 3 presents the details of the number of sentences and words in the three parts of the dialogue. For the title, the mean and mode of words were both 10. For content, the mean of sentences and words was 64 and 5, respectively, and the mode of sentences and words was 100 and 1, respectively. For comment, the mean of sentences and words was 150 and 7, respectively, and the mode of sentences and words was 24 and 1, respectively.
Table 3.
Cyberbullying data statistics.
In total, 1838 samples belonged to the slight category, 1570 belonged to the medium category, and 1592 belonged to the serious category. The 5000 cyberbullying data samples were divided into 3500 training sets samples, 500 verification set samples, and 1000 test set samples in a ratio of 7:1:2. Table 4 presents the experimental data statistics for the three cyberbullying severity labels.
Table 4.
Experimental data statistics.
4.2. Classification Models
In addition to the HSAN, the classification performance of several other models was determined. The proposed HSAN classification model was compared with two machine learning classification algorithms and ten deep learning classification models. All the classification models were rebuilt and trained by this study. The aforementioned models are described in the following text.
- (1).
- HSAN: Proposed model. This model has a hierarchical structure and uses a bidirectional GRU and squashing-attention network to encode text into hidden features. It uses the SoftMax function for classification.
- (2).
- GRU: This model uses a bidirectional GRU to encode text into hidden features. It has a nonhierarchical structure and uses the SoftMax function for classification.
- (3).
- GRU(Soft): This model is similar to the GRU model but includes a soft-attention network.
- (4).
- GRU(Squashing): This model is similar to the GRU model but includes a squashing-attention network.
- (5).
- HAN [13]: This model is a baseline model with a hierarchical structure.
- (6).
- SVM [46]: This baseline model uses the SVM algorithm. It uses TFIDF to transform documents into vectors.
- (7).
- RandomForest [47]: This baseline model uses the random forest algorithm. It uses TFIDF to transform documents into vectors
- (8).
- TextCNN [38]: This model uses word2vec pretraining word embeddings as input and multiple CNN kernels with max-pooling to extract multi-level features from the text.
- (9).
- TextRCNN [39]: This model uses bidirectional LSTM with max-pooling to extract critical features.
- (10).
- DPCNN [48]: This model is known as the deep pyramid CNN. It contains a word-level CNN with max pooling. The amount of collected data is halved to form a pyramid structure.
- (11).
- Transformer [49]: In this model, an encoder and a decoder are constructed through multilayer stacking and used with the self-attention mechanism.
- (12).
- CapsuleNet [45]: This model comprises neurons. In CapsuleNet, dynamic routing of the last layer of category capsules is conducted. A new squashing function is used to compress the vector length of the category, which represents the final category probability.
- (13).
- BERT: The model is known as the BERT classifier. It contains a pretrained BERT model with a final classification layer (linear layer). The study uses three pretrained models such as bert-base-chinese [40], distilbert-base-multilingual-cased [42], and allenai/longformer-base-4096 [41].
4.3. Experimental Design
In the experimental data, we propose that the splitting ratio was 7:1:2 for the training, validation, and test sets. The training set was used to train the model. Hyperparameter tuning was conducted in the validation set to avoid overfitting, and the superior model was selected. The test set was used for comparing the performance of the proposed model and other models. According to the cyberbullying data statistics for the training set, the maximum number of sentences for content and comments was 64 and 146, respectively. The maximum number of words for title, content, and comment was 10. The models’ parameter combinations were used to identify the best model according to the classification performance for the validation set. Table 5 presents the detailed parameter settings of the model.
Table 5.
Parameter settings of the compared models.
4.4. Evaluation Metrics
The current study proposes a multi-class classification task for determining the severity of cyberbullying incidents, which are rated as slight, medium, and serious. Performance evaluation was conducted according to the metrics of precision (), recall (), and F1 () on each label j, and defined as follows:
To evaluate multi-class problems, we used the macro and weighted averaging approaches to compute overall metrics for the three severity labels. The metrics (macro precision), (weighted precision), (macro recall), (weighted recall), (macro F1), (weighted F1), and are defined as follows:
where N denotes the number of all samples and denotes the number of jth labels.
4.5. Classification Performance of the HSAN
Table 6 presents the average results obtained for three evaluation metrics of the HSAN under each severity label. In summary, for the validation set, the , , and values of the HSAN were 64.16%, 61.62, and 62.46%, respectively; for the test set, the , , and values of the HSAN were 61.01%, 58.32%, and 58.94%, respectively. The average recall of the “serious” severity label was lower than that of the other two labels, because the ratios of the samples in the training and validation sets were unbalanced. The number of samples labeled as “serious” constituted a larger proportion of the training set but a smaller proportion of the validation set. Therefore, the unbalanced data affected the classification performance. The aforementioned results were similar to those obtained for the validation set. The average recall of the “serious” severity label was lower than the other two labels, because the distributions of the validation and test sets were the same and the data were unbalanced.
Table 6.
Performance of the HSAN for the three severity labels.
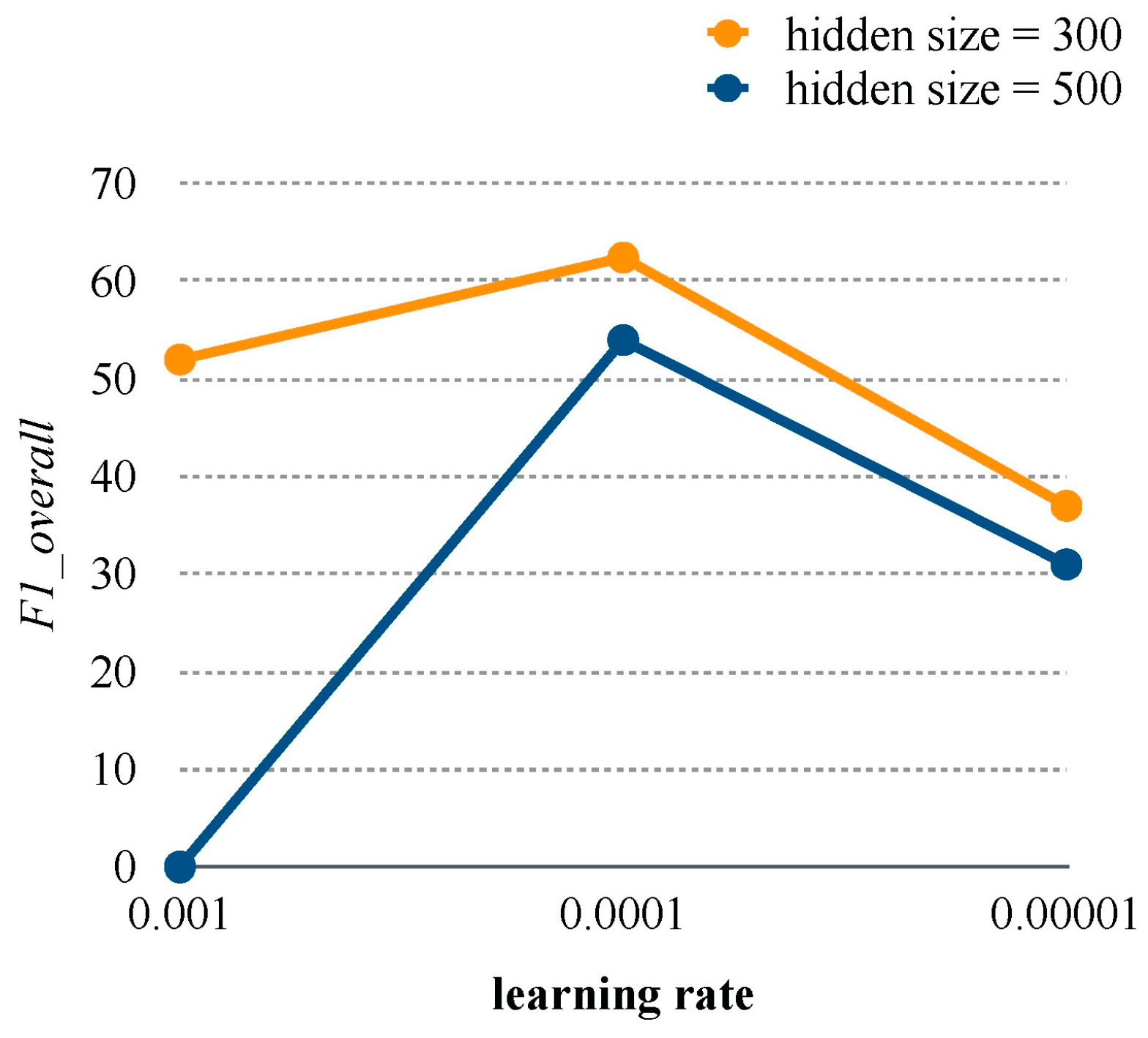
4.6. Comparison of Learning Rates and Hidden Sizes
The values under the six parameter combinations of hidden size and learning rate in the validation set for the HSAN are presented in Figure 4. The value of 0.0001 represents the optimal learning rate, and the value of 300 represents the optimal hidden size and word embedding size according to .
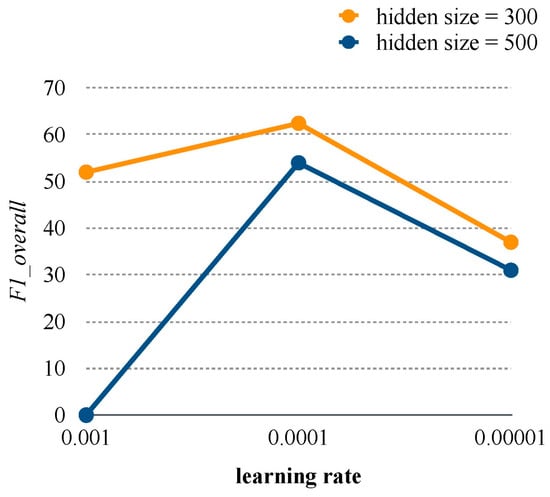
Figure 4.
The validation set results for the HSAN under different learning rates and hidden layer sizes.
4.7. Evaluation of Hierarchical Structure Versus Non-Hierarchical Structure
The current study compared the performance for the validation set between the squashing function in the HSAN and the SoftMax function in the HAN. The results indicate that the squashing function in the attention mechanism can achieve superior classification performance to the SoftMax function in the HAN (e.g., the squashing function had an 11.87% higher value than the SoftMax function did). In addition, the paper also applies the squashing-attention to the non-hierarchical model, such as the GRU(Squashing) model, the difference between GRU(Soft) and GRU(Squashing) in the is 5.82%, the difference between HSAN and GRU(Soft) in is 6.25%, and the different between HSAN and GRU in is 26.54%. Table 7 presents a comparison between the hierarchical and nonhierarchical structures when using the squashing-attention and soft-attention networks.
Table 7.
Evaluation of the hierarchical and nonhierarchical structures.
4.8. Comparison of the HSAN with Other Models
Table 8 presents the evaluation results for all classification models in the test set. The HSAN model was superior to the two traditional ML models and nine DL models evaluated, with the being 58.94% by SHAN model. The labeling ratios of the training, validation and test datasets were unbalanced, and the labeling ratio of the training set versus the validation and test sets was inverted. Therefore, the measurement was used to evaluate other models on the test dataset. The performance of six models such as the TextCNN, TextRCNN, DPCNN, Transformer, CapsuleNet, and the HAN models were similar but not superior to those of the HSAN. The differences compared to the HSAN model in those six models in the values were 0.37%, 0.41%, 0.87%, 8.37%, 22.9%, and 3.98%. To compare with the three BERT classifiers (such as bert-base-chinese, distilbert-base-multilingual-cased, and allenai/longformer-base-4096) that our proposed HSAN model also obtains better performances, the differences in the were 6.59%, 4.94%, and 14.45%, respectively. The longformer pretrained model supports sequences of length up to 4096 words, but cannot obtain a better classification performance. In another hand, the HSAN model also outperforms machine learning models such as SVM and RandomForest, which the difference in the are 6.44% and 15.78%, respectively. In summary, the TextCNN model has the smaller difference in the compared with HSAN, and CapsuleNet has a larger difference in the . In addition, the TextRCNN model outperforms the BERT and Transformer models. A reason is that the TextRCNN has considered all words (average 1380 words) of the input content (Lai et al., 2015); in this case, the pretrained BERT model has only considered 512 tokens (words) which is not enough to cover the whole input content (i.e., average 1380 words in a cyberbullying document). Therefore, the pretrained BERT model applied to the cyberbullying problem with the long document is not obtained the effective learning, because most of the words are not covered.
Table 8.
Performance of HSAN with other popular models.
4.9. Comparison of the HSAN with Other Models on Other Public Datasets
In this section, we attempt to evaluate our proposed model, which learns the classification task of the English language. There are four public datasets with the English language to evaluate our proposed HSAN performances. All datasets use the under-sampling to reduce samples with random sample 10% data. The IMDB Review dataset was released by Mass et al. [50], and it belongs to a binary classification task that has 25000 training samples, 25000 testing samples, and balanced data. The Yahoo Answer dataset was released by Zhang et al. [51]; it belongs to a ten-class classification task that has 1,400,000 training samples, 60,000 testing samples, and balanced data. The Yelp Review Polarity dataset was released by Zhang et al. [51], and it belongs to a binary classification task that has 560,000 training samples, 38,000 testing samples, and balanced data. The Amazon Review Polarity dataset was released by Zhang et al. [51], and it belongs to a binary classification task that has 3,600,000 training samples, 400,000 testing samples, and balanced data. Table 9 presents the evaluation results for HAN and HSAN classification models in the test set. Overall, the HSAN model was superior to the HAN model on four datasets. Therefore, the proposed squashing-attention mechanism also can improve the classification performance in the English language.
Table 9.
Performance on four public datasets with the English language.
4.10. Discussion
The current study used the popular online PTT forum in Taiwan as the experimental data source to detect cyberbullying incidents in dialogue and determine their severity on three levels. According to the experimental results, compared with the HAN, the SAM in the HSAN reduced the severity of cyberbullying by 3.98% on the test dataset. When the SAM was applied to nonhierarchical structures in our experiments, the performance of the GRU(Squashing) model outperformed the GRU(Soft) model. Three BERT classifiers have a word length limitation which cannot cover very large content, such as multiple sentences in cyberbullying dialogue. Although using the longformertations model (input 4096 words) also cannot obtain improvement. In addition, the three experimental datasets were unbalanced. The training set contained larger samples related to the “serious” severity label than the other two labels, but in the test set, the “serious” severity label had fewer samples. The SAM improved the classification performance for the “serious” severity label in the inverse status. Cyberbullying cases are ubiquitous on social media; therefore, company owners and other stakeholders should play positive roles and advocate for increased corporate social responsibility. Companies can also further improve Internet content protection policies by establishing complaint and consultation channels for cyberbullying to help victims quickly obtain resources from possible partners, such as the Institute of Watch Internet Network, which facilitates the organization and implementation of extensive online public safety programs.
5. Conclusions
The HSAN model is proposed in this paper for the automatic detection of the severity of cyberbullying incidents in online dialogues on social media and the classification of cyberbullying severity. The paper has created a novel dataset for detecting that includes three levels for the severity of cyberbullying incidents, and it helped the social worker to collect their attention on cyberbullying cases. Our proposed HSAN model also has improved classification in the three-level cyberbullying problem. In addition, the proposed HSAN model can provide researchers to implement classification detection in a format of multiple sentences in threaded discussion. The results of the current study indicate that compared with the soft-attention mechanism, the SAM provided superior attention weight estimation results. In addition, implementing hierarchical networks for sentence- and word-level classification is suitable for hidden feature extraction and prediction in cyberbullying dialogues. For precisely estimating attention weight, the HSAN model applied higher attention weight to cyberbullying sentences than the HAN model did. Therefore, the HSAN model exhibited superior performance to the HAN model in the cyberbullying severity classification task. The three-level HSAN model had an value of 58.94% and outperformed the other eight prediction models. Furthermore, the experimental data was unbalanced, which resulted in the training set data having the highest number of “serious” severity labels; however, the number of samples in validation and test sets had the lowest proportions, which resulted in relatively poor model prediction for the “serious” category. Cyberbullying may occur in the form of pictures or videos; however, the current study did not account for these two factors, because text represents most cyberbullying cases on social media platforms.
In the future, the word embeddings in the HSAN model can be replaced with a pretrained Bidirectional Encoder Representations from Transformers (BERT)-based model. Since the BERT model has the restriction of sentence length, BERT could not obtain the effective features from the long length content, because the truncation approach is used to a fixed sentence length which is 512 tokens. However, the pretrained BERT model was formed with a considerable amount of textual data, and it is possible to get more precise semantic information. Therefore, the pretrained BERT model is used to replace the word encoder in the proposed model, because the maximum length (number of words) of a sentence in our experimental data is 28, so the pretrained BERT model may benefit the cyberbullying dataset. Moreover, a sentiment analysis can be used to extract additional sentimental features from text, because many negative words or sentences generated by a cyberbully may be used to present evidence of cyberbullying to someone other than the original victim.
Author Contributions
Conceptualization, J.-L.W. and C.-Y.T.; methodology, J.-L.W. and C.-Y.T.; software, J.-L.W. and C.-Y.T.; validation, J.-L.W. and C.-Y.T.; formal analysis, C.-Y.T.; investigation, J.-L.W.; resources, J.-L.W. and C.-Y.T.; data curation, J.-L.W. and C.-Y.T.; writing—original draft preparation, J.-L.W. and C.-Y.T.; writing—review and editing, J.-L.W.; visualization, C.-Y.T.; supervision, J.-L.W.; project administration, J.-L.W.; funding acquisition, J.-L.W. All authors have read and agreed to the published version of the manuscript.
Funding
This research was partially supported by the Ministry of Science and Technology, Taiwan (Grant numbers: MOST-107-2218-E-031-002-MY2, MOST-109-2221-E-031-003, and MOST 110-2221-E-031-004).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable as no human contact or tissue were involved.
Data Availability Statement
Data of the study are available through contact with the corresponding author.
Conflicts of Interest
The authors declare that they have no conflict of interest.
References
- Bastiaensens, S.; Vandebosch, H.; Poels, K.; Van Cleemput, K.; Desmet, A.; De Bourdeaudhuij, I. ‘Can I afford to help?’ How affordances of communication modalities guide bystanders’ helping intentions towards harassment on social network sites. Behav. Inf. Technol. 2013, 34, 425–435. [Google Scholar] [CrossRef]
- Gulzar, M.A.; Ahmad, M.; Hassan, M.; Rasheed, M.I. How social media use is related to student engagement and creativity: Investigating through the lens of intrinsic motivation. Behav. Inf. Technol. 2021, 40, 1–11. [Google Scholar] [CrossRef]
- Ioannou, A.; Blackburn, J.; Stringhini, G.; De Cristofaro, E.; Kourtellis, N.; Sirivianos, M. From risk factors to detection and intervention: A practical proposal for future work on cyberbullying. Behav. Inf. Technol. 2018, 37, 258–266. [Google Scholar] [CrossRef]
- Lin, L.Y.; Sidani, J.E.; Shensa, A.; Radovic, A.; Miller, E.; Colditz, J.B.; Hoffman, B.L.; Giles, L.M.; Primack, B.A. Association between social media use and depression among U.S. young adults. Depress. Anxiety 2016, 33, 323–331. [Google Scholar] [CrossRef] [PubMed]
- Son, J.-E.; Lee, S.-H.; Cho, E.-Y.; Kim, H.-W. Examining online citizenship behaviours in social network sites: A social capital perspective. Behav. Inf. Technol. 2016, 35, 730–747. [Google Scholar] [CrossRef]
- Al-Ajlan, M.A.; Ykhlef, M. Optimized Twitter cyberbullying detection based on deep learning. In Proceedings of the 21st Saudi Computer Society National Computer Conference (NCC), Riyadh, Saudi Arabia, 25–26 April 2018; pp. 1–5. [Google Scholar] [CrossRef]
- Agrawal, S.; Awekar, A. Deep learning for detecting cyberbullying across multiple social media platforms. In Advances in Information Retrieval; Springer: Berlin/Heidelberg, Germany, 2018; pp. 141–153. [Google Scholar] [CrossRef] [Green Version]
- Rosa, H.; Matos, D.M.; Ribeiro, R.; Coheur, L.; Carvalho, J.P. A “Deeper” look at detecting cyberbullying in social networks. In Proceedings of the 2018 International Joint Conference on Neural Networks, Rio de Janeiro, Brazil, 8–13 July 2018; pp. 1–8. [Google Scholar] [CrossRef]
- Whittaker, E.; Kowalski, R.M. Cyberbullying via social media. J. School Violence 2015, 14, 11–29. [Google Scholar] [CrossRef]
- Lowry, P.; Zhang, J.; Wang, C.; Siponen, M. Why Do Adults Engage in Cyberbullying on Social Media? An Integration of Online Disinhibition and Deindividuation Effects with the Social Structure and Social Learning Model. Inf. Syst. Res. 2016, 27, 962–986. [Google Scholar] [CrossRef] [Green Version]
- Chapin, J. Adolescents and Cyber Bullying: The Precaution Adoption Process Model. Educ. Inf. Technol. 2014, 21, 719–728. [Google Scholar] [CrossRef]
- Hood, M.; Duffy, A.L. Understanding the relationship between cyber-victimisation and cyber-bullying on social network sites: The role of moderating factors. Personal. Individ. Differ. 2018, 133, 103–108. [Google Scholar] [CrossRef] [Green Version]
- Yang, Z.; Yang, D.; Dyer, C.; He, X.; Smola, A.; Hovy, E. Hierarchical attention networks for document classification. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, San Diego, CA, USA, 12–17 June 2016; pp. 1480–1489. [Google Scholar] [CrossRef] [Green Version]
- Li, Q. New bottle but old wine: A research of cyberbullying in schools. Comput. Hum. Behav. 2007, 23, 1777–1791. [Google Scholar] [CrossRef]
- Selkie, E.M.; Kota, R.; Chan, Y.-F.; Moreno, M. Cyberbullying, Depression, and Problem Alcohol Use in Female College Students: A Multisite Study. Cyberpsychol. Behav. Soc. Netw. 2015, 18, 79–86. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Patchin, J.W.; Hinduja, S. Bullies Move Beyond the Schoolyard. Youth Violence Juv. Justice 2006, 4, 148–169. [Google Scholar] [CrossRef]
- Mason, K.L. Cyberbullying: A preliminary assessment for school personnel. Psychol. Sch. 2008, 45, 323–348. [Google Scholar] [CrossRef]
- Snakenborg, J.; Van Acker, R.; Gable, R.A. Cyberbullying: Prevention and Intervention to Protect Our Children and Youth. Prev. Sch. Fail. Altern. Educ. Child. Youth 2011, 55, 88–95. [Google Scholar] [CrossRef]
- Dadvar, M.; Trieschnigg, D.; Ordelman, R.; Jong, F.D. Improving cyberbullying detection with user context. In Lecture Notes in Computer Science Advances in Information Retrieval; Springer: Cham, Switzerland, 2013; pp. 693–696. [Google Scholar] [CrossRef] [Green Version]
- Kasim, H.; Riadi, I. Detection of cyberbullying on social media using data mining techniques. Int. J. Comput. Sci. Inf. Secur. 2017, 15, 244–250. [Google Scholar]
- Chatzakou, D.; Kourtellis, N.; Blackburn, J.; Cristofaro, E.D.; Stringhini, G.; Vakali, A. Mean birds: Detecting aggression and bullying on Twitter. In Proceedings of the 2017 International ACM Web Science Conference, Troy, NY, USA, 25–28 June 2017; pp. 13–22. [Google Scholar] [CrossRef] [Green Version]
- Hinduja, S.; Patchin, J.W. Bullying, Cyberbullying, and Suicide. Arch. Suicide Res. 2010, 14, 206–221. [Google Scholar] [CrossRef]
- Qin, P.; Xu, W.; Guo, J. A novel negative sampling based on TFIDF for learning word representation. Neurocomputing 2015, 177, 257–265. [Google Scholar] [CrossRef]
- Reynolds, K.; Kontostathis, A.; Edwards, L. Using machine learning to detect cyberbullying. In Proceedings of the 2011 10th International Conference on Machine Learning and Applications and Workshops, Honolulu, HI, USA, 18–21 December 2011; pp. 241–244. [Google Scholar] [CrossRef] [Green Version]
- Dinakar, K.; Reichart, R.; Lieberman, H. Modeling the detection of textual cyberbullying. In Proceedings of the Fifth International AAAI Conference on Weblogs and Social Media, Barcelona, Spain, 17–21 July 2011; pp. 11–17. [Google Scholar]
- Huang, Q.; Singh, V.K.; Atrey, P.K. Cyber bullying detection using social and textual analysis. In Proceedings of the 3rd International Workshop on Socially-Aware Multimedia, Orlando, FL, USA, 7 November 2014; pp. 3–6. [Google Scholar] [CrossRef]
- Zhao, R.; Zhou, A.; Mao, K. Automatic detection of cyberbullying on social networks based on bullying features. In Proceedings of the 17th International Conference on Distributed Computing and Networking, Singapore, 4–7 January 2016; pp. 1–6. [Google Scholar] [CrossRef]
- Gutiérrez-Esparza, G.O.; Vallejo-Allende, M.; Hernández-Torruco, J. Classification of Cyber-Aggression Cases Applying Machine Learning. Appl. Sci. 2019, 9, 1828. [Google Scholar] [CrossRef] [Green Version]
- Cheng, L.; Li, J.; Silva, Y.N.; Hall, D.L.; Liu, H. XBully: Cyberbullying detection within a multi-modal context. In Proceedings of the Twelfth ACM International Conference on Web Search and Data Mining, Melbourne, Australia, 11–15 February 2019; pp. 339–347. [Google Scholar] [CrossRef]
- Zhang, Z.; Xu, S.; Zhang, S.; Qiao, T.; Cao, S. Attention based convolutional recurrent neural network for environmental sound classification. Neurocomputing 2020, 453, 896–903. [Google Scholar] [CrossRef]
- Liu, F.; Zheng, L.; Zheng, J. HieNN-DWE: A hierarchical neural network with dynamic word embeddings for document level sentiment classification. Neurocomputing 2020, 403, 21–32. [Google Scholar] [CrossRef]
- Jin, X.; Lan, C.; Zeng, W.; Zhang, Z.; Chen, Z. CASINet: Content-Adaptive Scale Interaction Networks for scene parsing. Neurocomputing 2020, 419, 9–22. [Google Scholar] [CrossRef]
- Tian, D.; Li, M.; Shi, J.; Shen, Y.; Han, S. On-site text classification and knowledge mining for large-scale projects construction by integrated intelligent approach. Adv. Eng. Informatics 2021, 49, 101355. [Google Scholar] [CrossRef]
- Fang, W.; Luo, H.; Xu, S.; Love, P.E.; Lu, Z.; Ye, C. Automated text classification of near-misses from safety reports: An improved deep learning approach. Adv. Eng. Informatics 2020, 44, 101060. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Chung, J.; Gulcehre, C.; Cho, K.H.; Bengio, Y. Empirical evaluation of gated recurrent neural networks on sequence modeling. In Proceedings of the NIPS 2014 Workshop on Deep Learning, Montreal, QC, Canada, 12 December 2014. [Google Scholar]
- Menini, S.; Moretti, G.; Corazza, M.; Cabrio, E.; Tonelli, S.; Villata, S. A system to monitor cyberbullying based on message classification and social network analysis. In Proceedings of the Third Workshop on Abusive Language Online, Florence, Italy, 1 August 2019; pp. 105–110. [Google Scholar] [CrossRef]
- Kim, Y. Convolutional neural networks for sentence classification. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing, Doha, Qatar, 25–29 October 2014; pp. 1746–1751. [Google Scholar]
- Lai, S.; Xu, L.; Liu, K.; Zhao, J. Recurrent convolutional neural networks for text classification. In Proceedings of the Twenty-Ninth AAAI Conference on Artificial Intelligence, Austin, TX, USA, 25–30 January 2015; pp. 2267–2273. [Google Scholar]
- Devlin, J.; Chang, M.; Lee, K.; Toutanova, K. BERT: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 North American Chapter of the Association for Computational Linguistics-Human Language Technologies, Minneapolis, MN, USA, 2–7 June 2019; pp. 4171–4186. [Google Scholar] [CrossRef]
- Beltagy, I.; Peters, M.E.; Cohan, A. Longformer: The long-document transformer. arXiv preprint 2020, arXiv:abs/2004.05150. [Google Scholar]
- Sanh, V.; Debut, L.; Chaumond, J.; Wolf, T. DistilBERT, a distilled version of BERT: Smaller, faster, cheaper and lighter. arXiv preprint 2019, arXiv:abs/1910.01108. [Google Scholar]
- Gao, S.; Ramanathan, A.; Tourassi, G. Hierarchical convolutional attention networks for text classification. In Proceedings of the Third Workshop on Representation Learning for NLP, Melbourne, Australia, 20 July 2018; pp. 11–23. [Google Scholar] [CrossRef] [Green Version]
- Cheng, L.; Guo, R.; Silva, Y.; Hall, D.; Liu, H. Hierarchical attention networks for cyberbullying detection on the Instagram social network. In Proceedings of the 2019 SIAM International Conference on Data Mining, Calgary, AB, Canada, 2–4 May 2019; pp. 235–243. [Google Scholar] [CrossRef] [Green Version]
- Sabour, S.; Frosst, N.; Hinton, G.E. Dynamic routing between capsules. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 3856–3866. [Google Scholar]
- Boser, B.E.; Guyon, I.; Vapnik, V.N. A training algorithm for optimal margin classifiers. In Proceedings of the Fifth Annual Workshop on Computational Learning Theory, Pittsburgh, PA, USA, 27–29 July 1992; pp. 144–152. [Google Scholar] [CrossRef]
- Ho, T.K. The random subspace method for constructing decision forests. IEEE Trans. Pattern Anal. Mach. Intell. 1998, 20, 832–844. [Google Scholar] [CrossRef] [Green Version]
- Johnson, R.; Zhang, T. Deep pyramid convolutional neural networks for text categorization. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics, Vancouver, BC, Canada, 30 July–4 August 2017; pp. 562–570. [Google Scholar] [CrossRef] [Green Version]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- Maas, A.L.; Daly, R.E.; Pham, P.T.; Huang, D.; Ng, A.Y.; Potts, C. Learning word vectors for sentiment analysis. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics, Portland, OR, USA, 19–24 June 2011; pp. 142–150. [Google Scholar]
- Zhang, X.; Zhao, J.; LeCun, Y. Character-level convolutional networks for text classification. In Proceedings of the 2015 Advances in Neural Information Processing Systems, Montreal, QC, USA, 7–12 December 2015; pp. 649–658. [Google Scholar]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).