
Self-Attentive Moving Average for Time Series Prediction

Abstract
:1. Introduction
- We present a novel learning-based moving average indicator that introduces the self-attention mechanism to adaptively determine the data weight at each time step.
- We use multiple self-attention heads to model the moving average indicators of different scales and use bilinear models to effectively combine them for time series prediction in an end-to-end manner.
- We conduct the experimental evaluation on two real-world datasets and the results demonstrate the effectiveness of our approach.
2. Related Work
3. Methodological Background
4. Method
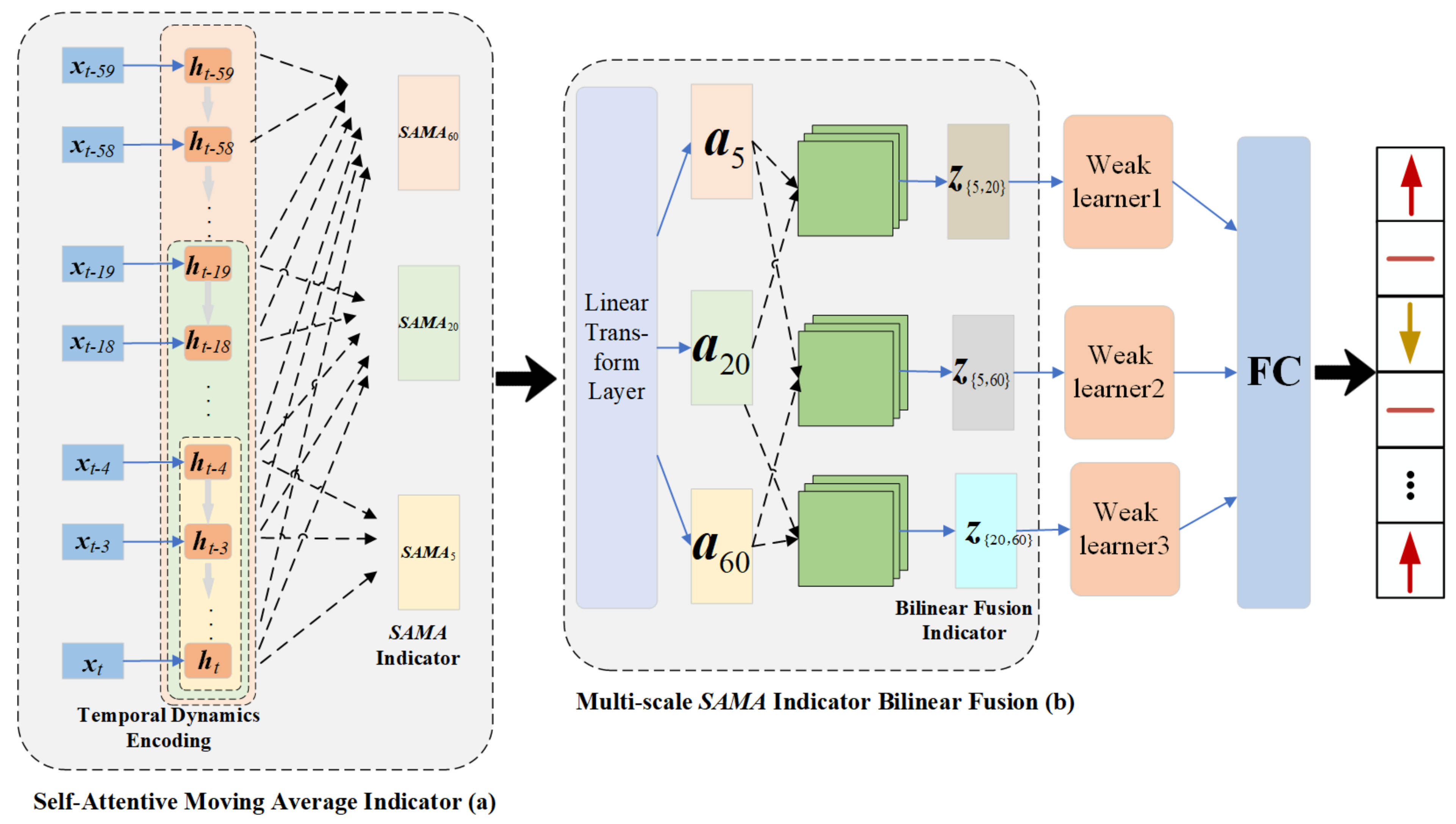
4.1. Time Series Encoding
4.2. Self-Attentive Moving Average
4.3. Multi-Scale Bilinear Fusion
5. Experiments
5.1. Data Collection
5.2. Evaluation Methodology
5.3. Baseline
- : the single-scale indicator is used for time series prediction.
- |: any two scales indicators are simply spliced to make time series prediction.
- ||: the indicators of three different scales are spliced to make time series predictions.
- SMA [41]: the SMA indicator calculates the average value of the time series data during a period of time.
- EMA [42]: the EMA indicator is calculated based on the principle that the weight of the time series data decreases exponentially.
- WMA [43]: the WMA indicator gives predefined weights to different time series data.
- TCN [51]: the model combines CNN and RNN structure. The input sequence of arbitrary length is modeled by causal convolution, expansion convolution and residual joining.
- DA-RNN [26]: the model is based on a recurrent neural network of dual-stage attention. The encoder with an input attention mechanism and the decoder with time attention are used to adaptively extract the input features and select the encoding-related hidden states at all time steps.
- Transformer [9]: the transformer completely relies on the self-attention mechanism to calculate the input and output representations, and obtains the weight of each value by calculating the similarity between the query and the corresponding key.
- LSTM [52]: LSTM models time series through recurrent neural networks and predicts future trends.
5.4. Effectiveness of Multi-Scale SAMA Bilinear Fusion
- Overall, combining multi-scale indicators offers better performance than utilizing one of them alone, leading to, for example, at least 3.19% and 2.85% relative improvements in terms of score on the stock and air quality datasets, respectively. The results suggest the necessity of simultaneously exploiting the indicators of different scales for enhancing time series prediction. In addition, the performance of time series trend prediction by combining the three indicators , , and deteriorates, which may be caused by the following two reasons. The indicator is between the and indicators, which can reflect the fluctuations of time series in the past month. Since the indicator is not sensitive to the short-term fluctuation of the time series and cannot adequately reflect the long-term trend change, some redundant information is introduced when the three indicators are combined for trend prediction, which reduces the accuracy of the prediction. On the other hand, we simply splice the three indicators to obtain a unified representation through the fully connected layer as an excessively simple combination method may lead to performance deterioration.
- It can be seen that the bilinear fusion of , , and achieves the best result among all multi-scale competitors. This may be because could reflect the recent short-term fluctuations of time series: on the contrary, and capture the overall mid-term and long-term dynamics of the past period. In the process of fusion, we interact with the three different indicators and comprehensively consider the dimensions of different scale indicators to better predict the future trend of the time series.
5.5. Performance Comparison
- In most cases, traditional moving average indicators fall considerably behind the deep model-based methods. This highlights the merit of deep learning techniques for time series prediction.
- Among deep sequence models, transformer and our approach are both superior to TCN, DA-RNN, and LSTM. This underlines the benefit of introducing the self-attention mechanism to capture the dynamics of time series. On the other hand, our approach obtains the best results on both datasets. More precisely, it exceeds the transformer by an average of nearly 1.67%, 1.21%, 1.15%, and 1.49% in terms of accuracy, precision, recall, and score, respectively. The results clearly demonstrate the effectiveness of our approach for time series prediction.
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Krollner, B.; Vanstone, B.J.; Finnie, G.R. Financial time series forecasting with machine learning techniques: A survey. In Proceedings of the European Symposium on Artificial Neural Networks, Thessaloniki, Greece, 15–18 September 2010. [Google Scholar]
- Ma, S. A hybrid deep meta-ensemble networks with application in electric utility industry load forecasting. Inf. Sci. 2021, 544, 183–196. [Google Scholar] [CrossRef]
- Campbell, S.D.; Diebold, F.X. Weather forecasting for weather derivatives. J. Am. Stat. Assoc. 2005, 100, 6–16. [Google Scholar] [CrossRef] [Green Version]
- Karevan, Z.; Suykens, J.A. Transductive LSTM for time-series prediction: An application to weather forecasting. Neural Netw. 2020, 125, 1–9. [Google Scholar] [CrossRef] [PubMed]
- Taylor, C.J.; Pedregal, D.J.; Young, P.C.; Tych, W. Environmental time series analysis and forecasting with the Captain toolbox. Environ. Model. Softw. 2007, 22, 797–814. [Google Scholar] [CrossRef]
- Cui, C.; Li, X.; Du, J.; Zhang, C.; Nie, X.; Wang, M.; Yin, Y. Temporal-Relational Hypergraph Tri-Attention Networks for Stock Trend Prediction. arXiv 2021, arXiv:2107.14033. [Google Scholar]
- Chiarella, C.; He, X.Z.; Hommes, C. A dynamic analysis of moving average rules. J. Econ. Dyn. Control 2006, 30, 1729–1753. [Google Scholar] [CrossRef] [Green Version]
- Chiarella, C.; He, X.-Z.; Hommes, C. Moving average rules as a source of market instability. Phys. A Stat. Mech. Appl. 2006, 370, 12–17. [Google Scholar] [CrossRef] [Green Version]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- Lin, T.Y.; RoyChowdhury, A.; Maji, S. Bilinear cnn models for fine-grained visual recognition. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–10 December 2015; pp. 1449–1457. [Google Scholar]
- Tenenbaum, J.B.; Freeman, W.T. Separating style and content with bilinear models. Neural Comput. 2000, 12, 1247–1283. [Google Scholar] [CrossRef]
- Gajbhiye, A.; Winterbottom, T.; Al Moubayed, N.; Bradley, S. Bilinear fusion of Ccommonsense knowledge with attention-based NLI models. In International Conference on Artificial Neural Networks; Springer: Berlin/Heidelberg, Germany, 2020; pp. 633–646. [Google Scholar]
- Shakeel, A.; Tanaka, T.; Kitajo, K. Time-series prediction of the oscillatory phase of EEG signals using the least mean square algorithm-based AR model. Appl. Sci. 2020, 10, 3616. [Google Scholar] [CrossRef]
- Connor, J.T.; Martin, R.D.; Atlas, L.E. Recurrent neural networks and robust time series prediction. IEEE Trans. Neural Netw. 1994, 5, 240–254. [Google Scholar] [CrossRef] [Green Version]
- Whittle, P. Hypothesis Testing in Time Series Analysis; Almqvist & Wiksells boktr.: Solna, Sweden, 1951; Volume 4. [Google Scholar]
- Box, G.E.; Jenkins, G.M.; Reinsel, G.C.; Ljung, G.M. Time Series Analysis: Forecasting and Control; John Wiley & Sons: Hoboken, NJ, USA, 2015. [Google Scholar]
- Chen, S.; Wang, X.; Harris, C.J. NARX-based nonlinear system identification using orthogonal least squares basis hunting. IEEE Trans. Control Syst. Technol. 2007, 16, 78–84. [Google Scholar] [CrossRef] [Green Version]
- Frigola, R.; Rasmussen, C.E. Integrated pre-processing for Bayesian nonlinear system identification with Gaussian processes. In Proceedings of the 52nd IEEE Conference on Decision and Control. IEEE, Firenze, Italy, 10–13 December 2013; pp. 5371–5376. [Google Scholar]
- Park, S.H.; Lee, J.H.; Song, J.W.; Park, T.S. Forecasting change directions for financial time series using hidden markov model. In Proceedings of the International Conference on Rough Sets and Knowledge Technology, Gold Coast, Australia, 14–16 July 2009; pp. 184–191. [Google Scholar]
- Kim, K.J. Financial time series forecasting using support vector machines. Neurocomputing 2003, 55, 307–319. [Google Scholar] [CrossRef]
- Mellit, A.; Pavan, A.M.; Benghanem, M. Least squares support vector machine for short-term prediction of meteorological time series. Theor. Appl. Climatol. 2013, 111, 297–307. [Google Scholar] [CrossRef]
- Hong, B.W. Deep Learning Based on Fourier Convolutional Neural Network Incorporating Random Kernels. Electronics 2021, 10, 2004. [Google Scholar]
- Diaconescu, E. The use of NARX neural networks to predict chaotic time series. Wseas Trans. Comput. Res. 2008, 3, 182–191. [Google Scholar]
- Bengio, Y.; Simard, P.; Frasconi, P. Learning long-term dependencies with gradient descent is difficult. IEEE Trans. Neural Netw. 1994, 5, 157–166. [Google Scholar] [CrossRef]
- Cho, K.; Van Merriënboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning phrase representations using RNN encoder-decoder for statistical machine translation. arXiv 2014, arXiv:1406.1078. [Google Scholar]
- Qin, Y.; Song, D.; Chen, H.; Cheng, W.; Jiang, G.; Cottrell, G. A dual-stage attention-based recurrent neural network for time series prediction. arXiv 2017, arXiv:1704.02971. [Google Scholar]
- Li, S.; Jin, X.; Xuan, Y.; Zhou, X.; Chen, W.; Wang, Y.X.; Yan, X. Enhancing the locality and breaking the memory bottleneck of transformer on time series forecasting. Adv. Neural Inf. Process. Syst. 2019, 32, 5243–5253. [Google Scholar]
- Fahim, S.R.; Sarker, M.R.I.; Arifuzzaman, M.; Hosen, M.S.; Sarker, S.K.; Das, S.K. A novel approach to fault diagnosis of high voltage transmission line-a self attentive convolutional neural network model. In Proceedings of the 2020 IEEE Region 10 Symposium (TENSYMP), Dhaka, Bangladesh, 5–7 June 2020; pp. 1329–1332. [Google Scholar]
- Jin, X.B.; Zheng, W.Z.; Kong, J.L.; Wang, X.Y.; Zuo, M.; Zhang, Q.C.; Lin, S. Deep-Learning Temporal Predictor via Bidirectional Self-Attentive Encoder–Decoder Framework for IOT-Based Environmental Sensing in Intelligent Greenhouse. Agriculture 2021, 11, 802. [Google Scholar] [CrossRef]
- Kang, Z.; Xu, H.; Hu, J.; Pei, X. Learning dynamic graph embedding for traffic flow forecasting: A graph self-attentive method. In Proceedings of the 2019 IEEE Intelligent Transportation Systems Conference (ITSC), Auckland, New Zealand, 27–30 October 2019; pp. 2570–2576. [Google Scholar]
- Wu, T.; Wang, X.; Qiao, S.; Xian, X.; Liu, Y.; Zhang, L. Small perturbations are enough: Adversarial attacks on time series prediction. Inf. Sci. 2022, 587, 794–812. [Google Scholar] [CrossRef]
- Zheng, W.; Hu, J. Multivariate Time Series Prediction Based on Temporal Change Information Learning Method. IEEE Trans. Neural Netw. Learn. Syst. 2022; Early Access. [Google Scholar] [CrossRef]
- Ding, F.; Luo, C. Interpretable cognitive learning with spatial attention for high-volatility time series prediction. Appl. Soft Comput. 2022, 117, 108447. [Google Scholar] [CrossRef]
- Thakur, A.; Kumar, S.; Tiwari, A. Hybrid model of gas price prediction using moving average and neural network. In Proceedings of the 1st International Conference on Next Generation Computing Technologies, Dehradun, India, 4–5 September 2015; pp. 735–737. [Google Scholar]
- Mo, Z.; Tao, H. A model of oil price forecasting based on autoregressive and moving average. In Proceedings of the International Conference on Robots & Intelligent System, Zhangjiajie, China, 27–28 August 2016; pp. 22–25. [Google Scholar]
- Hansun, S.; Kristanda, M.B. Performance analysis of conventional moving average methods in forex forecasting. In Proceedings of the International Conference on Smart Cities, Automation & Intelligent Computing Systems, Yogyakarta, Indonesia, 8–10 November 2017; pp. 11–17. [Google Scholar]
- Hansun, S. H-WEMA: A New Approach of Double Exponential Smoothing Method. Telkomnika 2016, 14, 772. [Google Scholar] [CrossRef] [Green Version]
- Hansun, S. Brown’s Weighted Exponential Moving Average Implementation in Forex Forecasting. Telkomnika 2017, 15, 1425–1432. [Google Scholar] [CrossRef] [Green Version]
- Hansun, S. A new approach of moving average method in time series analysis. In Proceedings of the International Conference on New Media Studies, New York, NY, USA, 23–27 February 2013; pp. 1–4. [Google Scholar]
- Nakano, M.; Takahashi, A.; Takahashi, S. Generalized exponential moving average (EMA) model with particle filtering and anomaly detection. Expert Syst. Appl. 2017, 73, 187–200. [Google Scholar] [CrossRef]
- Ellis, C.A.; Parbery, S.A. Is smarter better? A comparison of adaptive, and simple moving average trading strategies. Res. Int. Bus. Financ. 2005, 19, 399–411. [Google Scholar] [CrossRef]
- Lawrance, A.; Lewis, P. An exponential moving-average sequence and point process (EMA1). J. Appl. Probab. 1977, 14, 98–113. [Google Scholar] [CrossRef]
- Zhuang, Y.; Chen, L.; Wang, X.S.; Lian, J. A weighted moving average-based approach for cleaning sensor data. In Proceedings of the 27th International Conference on Distributed Computing Systems, Toronto, QC, Canada, 25–29 June 2007; p. 38. [Google Scholar]
- Wei, W.W. Time series analysis. In The Oxford Handbook of Quantitative Methods in Psychology; Oxford Handbooks Online: New York, NY, USA, 2006; Volume 2. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Hao, Y.; Chu, H.H.; Ho, K.Y.; Ko, K.C. The 52-week high and momentum in the Taiwan stock market: Anchoring or recency biases? Int. Rev. Econ. Financ. 2016, 43, 121–138. [Google Scholar] [CrossRef]
- Feng, F.; He, X.; Wang, X.; Luo, C.; Liu, Y.; Chua, T.S. Temporal relational ranking for stock prediction. ACM Trans. Inf. Syst. 2019, 37, 1–30. [Google Scholar] [CrossRef] [Green Version]
- Feng, F.; Chen, H.; He, X.; Ding, J.; Sun, M.; Chua, T.S. Enhancing stock movement prediction with adversarial training. arXiv 2018, arXiv:1810.09936. [Google Scholar]
- Kwon, D.H.; Kim, J.B.; Heo, J.S.; Kim, C.M.; Han, Y.H. Time series classification of cryptocurrency price trend based on a recurrent LSTM neural network. J. Inf. Process. Syst. 2019, 15, 694–706. [Google Scholar]
- Xu, M.; Fralick, D.; Zheng, J.Z.; Wang, B.; Tu, X.M.; Feng, C. The differences and similarities between two-sample t-test and paired t-test. Shanghai Arch. Psychiatry 2017, 29, 184. [Google Scholar]
- Bai, S.; Kolter, J.Z.; Koltun, V. An empirical evaluation of generic convolutional and recurrent networks for sequence modeling. arXiv 2018, arXiv:1803.01271. [Google Scholar]
- Nelson, D.M.; Pereira, A.C.; de Oliveira, R.A. Stock market’s price movement prediction with LSTM neural networks. In Proceedings of the International Joint Conference on Neural Networks, Anchorage, AK, USA, 14–19 May 2017; pp. 1419–1426. [Google Scholar]
- Khalil, M.I.; Kim, R.; Seo, C.Y. Challenges and Opportunities of Big Data. J. Platf. Technol. 2020, 8, 3–9. [Google Scholar]
- Vimal, S.; Robinson, Y.H.; Kaliappan, M.; Pasupathi, S.; Suresh, A. Q Learning MDP Approach to Mitigate Jamming Attack Using Stochastic Game Theory Modelling with WQLA in Cognitive Radio Networks. J. Platf. Technol. 2021, 9, 3–14. [Google Scholar]
- Vimal, S.; Jesuva, A.S.; Bharathiraja, S.; Guru, S.; Jackins, V. Reducing Latency in Smart Manufacturing Service System Using Edge Computing. J. Platf. Technol. 2021, 9, 15–22. [Google Scholar]
- Labrinidis, A.; Jagadish, H.V. Challenges and opportunities with big data. Proc. VLDB Endow. 2012, 5, 2032–2033. [Google Scholar] [CrossRef]
- Zhuang, Y.T.; Wu, F.; Chen, C.; Pan, Y.H. Challenges and opportunities: From big data to knowledge in AI 2.0. Front. Inf. Technol. Electron. Eng. 2017, 18, 3–14. [Google Scholar] [CrossRef]
- Boulesteix, A.L.; Binder, H.; Abrahamowicz, M.; Sauerbrei, W. On the necessity and design of studies comparing statistical methods. Biom. J. Biom. Z. 2017, 60, 216–218. [Google Scholar] [CrossRef]


{kind=link}
| Method | Related Work |
|---|---|
| Statistical model | [13,14,15,16,37,38,39,40] |
| Traditional machine learning model | [17,18,19,20,21] |
| Deep RNN model | [4,23,24,25,26,31,32,33] |
| Deep self-attention model | [27,28,29,30] |
| Method | Stock Dataset | |||
|---|---|---|---|---|
| Accuracy | Precision | Recall | ||
| 42.13% | 41.44% | 41.08% | 39.58% | |
| 42.63% | 41.98% | 41.56% | 40.10% | |
| 42.68% | 41.89% | 41.50% | 39.81% | |
| ∣ | 42.71% | 42.17% | 41.59% | 39.90% |
| ∣ | 42.76% | 42.20% | 41.65% | 40.27% |
| ∣ | 42.71% | 42.00% | 41.63% | 40.39% |
| ∣∣ | 42.75% | 42.13% | 41.61% | 40.12% |
| (, , ) | 42.82% | 42.41% | 41.98% | 41.38% |
| Method | Air Quality Dataset | |||
|---|---|---|---|---|
| Accuracy | Precision | Recall | ||
| 69.66% | 46.22% | 46.35% | 46.26% | |
| 67.86% | 45.03% | 45.39% | 45.20% | |
| 69.40% | 45.88% | 45.73% | 45.74% | |
| ∣ | 68.83% | 45.65% | 45.78% | 45.69% |
| ∣ | 70.15% | 46.55% | 46.94% | 46.67% |
| ∣ | 69.78% | 46.19% | 45.81% | 45.86% |
| ∣∣ | 69.40% | 45.88% | 46.01% | 45.94% |
| (, , ) | 71.64% | 47.45% | 47.75% | 47.58% |
| Method | Stock Dataset | Air Quality Dataset | ||||||
|---|---|---|---|---|---|---|---|---|
| Accuracy | Precision | Recall | Accuracy | Precision | Recall | |||
| SMA | 39.23% | 35.83% | 37.12% | 29.89% | 67.92% | 45.98% | 44.27% | 44.00% |
| EMA | 39.26% | 37.25% | 37.09% | 29.51% | 67.91% | 44.91% | 44.43% | 44.46% |
| WMA | 39.98% | 38.02% | 37.92% | 30.11% | 69.03% | 45.64% | 45.37% | 45.40% |
| TCN | 40.90% | 38.89% | 39.24% | 33.91% | 66.42% | 44.05% | 44.40% | 44.15% |
| DA-RNN | 40.82% | 39.62% | 39.17% | 34.21% | 67.16% | 44.84% | 43.28% | 43.17% |
| LSTM | 41.93% | 40.58% | 40.43% | 37.46% | 68.73% | 45.59% | 45.70% | 45.61% |
| Transformer | 41.97% | 41.53% | 41.12% | 39.89% | 69.16% | 45.92% | 46.32% | 46.10% |
| Ours | 42.82% | 42.41% | 41.98% | 41.38% | 71.64% | 47.45% | 47.75% | 47.58% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Su, Y.; Cui, C.; Qu, H. Self-Attentive Moving Average for Time Series Prediction. Appl. Sci. 2022, 12, 3602. https://doi.org/10.3390/app12073602
Su Y, Cui C, Qu H. Self-Attentive Moving Average for Time Series Prediction. Applied Sciences. 2022; 12(7):3602. https://doi.org/10.3390/app12073602
Chicago/Turabian StyleSu, Yaxi, Chaoran Cui, and Hao Qu. 2022. "Self-Attentive Moving Average for Time Series Prediction" Applied Sciences 12, no. 7: 3602. https://doi.org/10.3390/app12073602
APA StyleSu, Y., Cui, C., & Qu, H. (2022). Self-Attentive Moving Average for Time Series Prediction. Applied Sciences, 12(7), 3602. https://doi.org/10.3390/app12073602