
An Intelligent Cluster-Based Routing Scheme in 5G Flying Ad Hoc Networks

 ,
,  and
and
Abstract
:1. Introduction
1.1. FANET
1.2. 5G
1.3. Vertical Clustering
1.4. Our Contributions
- A hybrid framework that enables CC and DCs to handles long- and short-lifetime data, which represents the freshness (or recency) of data, in order to ensure the availability of unexpired data for the local task (i.e., vertical clustering) and the global task (i.e., vertical routing performed over a clustered network) in FANETs under 5G network scenarios.
- A DQN-based vertical routing over a clustered FANET that selects routes across different network planes (or network cells) to enable inter- and intra-plane communications while improving network lifetime, as well as reducing energy consumption and link breakages. Our proposed scheme focuses on route selection, rather than signaling protocol and message structure, in 5G access networks.
1.5. Paper Organization
2. Related Work
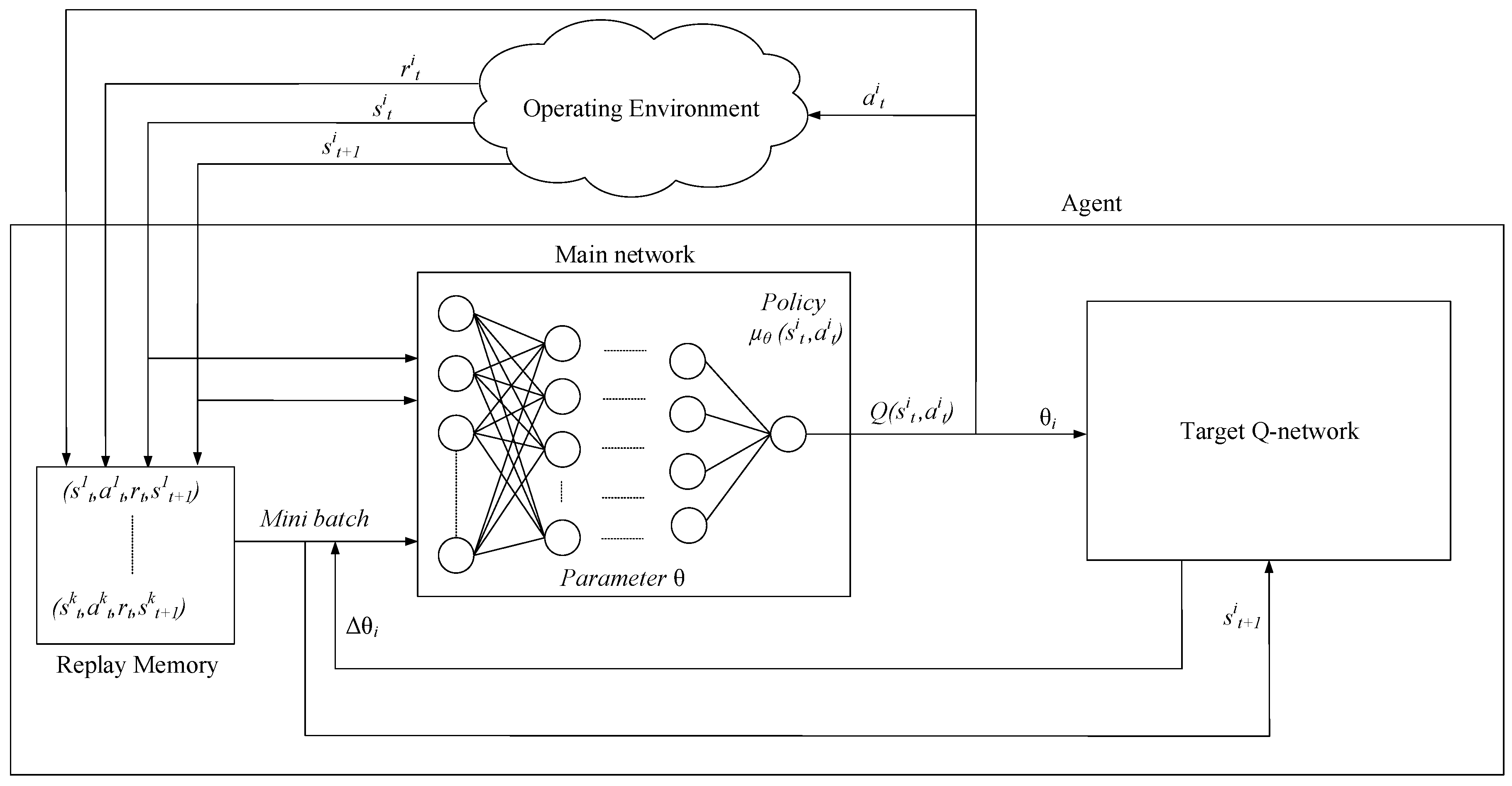
| Algorithm 1: The DQN algorithm. | |
| Complexity | |
| Computational Message Storage | |
| Input: Sequence of state | |
| Output: Action | |
| 1: procedure | |
| 2: Initialize experience replay memory | |
| 3: Initialize main network parameter | |
| 4: for do | |
| 5: Initialize a sequence of state | |
| 6: for do | |
| 7: Select action | |
| 8: Execute action by using the policy | |
| 9: Observe state and delayed reward | |
| 10: Store experience in | |
| 11: Randomly select mini batch of N experiences from | |
| 12: for do | |
| 13: Set target | |
| 14: Update via gradient descent on loss function , | |
| 15 Differentiate the loss function with respect to | |
| 16 | |
| 17: Update after C steps | |
| 18: end for | |
| 19: end for | |
| 20: end for | |
| 21: end procedure |
| Algorithm 2: The RL algorithm. | |
| Complexity | |
| Computational Message Storage | |
| Input: State | |
| Output: Action | |
| 1: procedure | |
| 2: Observe current state | |
| 3: if exploration then | |
| 4: Select a random action | |
| 5: else | |
| 6: Select an action | |
| 7: end if | |
| 8: Receive delayed reward | |
| 9: Update Q-value using Equation (2) | 1 |
| 10: end procedure |
- We consider a DQN-based vertical routing over a clustered FANET that selects routes across different network planes (or network cells) to enable inter- and intra-plane communications while improving network lifetime, as well as reducing energy consumption and link breakages. Our proposed scheme focuses on route selection in 5G access networks, rather than signaling protocol and message structure which have been investigated in the literature [18]. To the best of our knowledge, in the literature, existing routing schemes for FANETs considers the dynamicity of UAVs only [29], and there is lack of investigation in the context of 5G access networks.
- We consider inter- and intra-plane communications. Different network planes have different characteristics, and this has not been considered in route selection. Specifically, in 5G access networks, each network plane consists of UAVs and BSs with different characteristics. For instance, macrocells, picocells, and femtocells have large, medium, and small transmission ranges, so they have high, medium, and low node densities of UAVs, respectively. UAVs can switch from one network plane to another (e.g., from the macro-plane to the pico-plane) based on the relative speed of UAVs and the number of handovers across different network planes. The presence of different network cells is unique as compared to traditional access networks which have a single type of network cell. Therefore, the proposed vertical routing scheme over the clustered network involves different network cells (or network planes), while existing routing schemes for FANETs are only horizontal-based and mainly reduce the average number of hops between the source and destination UAVs [14,15]. By considering different network planes, our proposed framework considers both vertical routing across different network planes and horizontal routing within a network plane. To the best of our knowledge, the effect of different network planes to routing has not been considered in the literature.
- We consider two types of data. Higher dynamicity reduces data lifetime (or freshness) and increases the need to update both CC and DC controllers with new data. Highly dynamic data, such as geographical location, and the moving speed and direction, are generated by UAVs and BSs in FANETs. First, DCs handle the short-lifetime data, which has short expiry due to high dynamicity (i.e., the mobility of UAVs). This data is used for the local task, particularly vertical clustering. Second, CC handles the long-lifetime data has long expiry due to low dynamicity (i.e., residual energy). These data are used for the global task, particularly vertical routing over a clustered network. To the best of our knowledge, the freshness of the data has not been considered in the literature.
- We use DQN-based routing scheme over a clustered network to manage the highly dynamic network in order to ensure scalability. The main research focus of routing schemes in FANETs is to cater for the dynamicity of UAVs, which causes frequent variations in the network topology. The DQN agent is trained to gain the comprehensive knowledge of the environment in order to improve network lifetime.
3. Network Architecture
3.1. Data Lifetime
3.2. Hybrid Framework
4. System Model and Functions
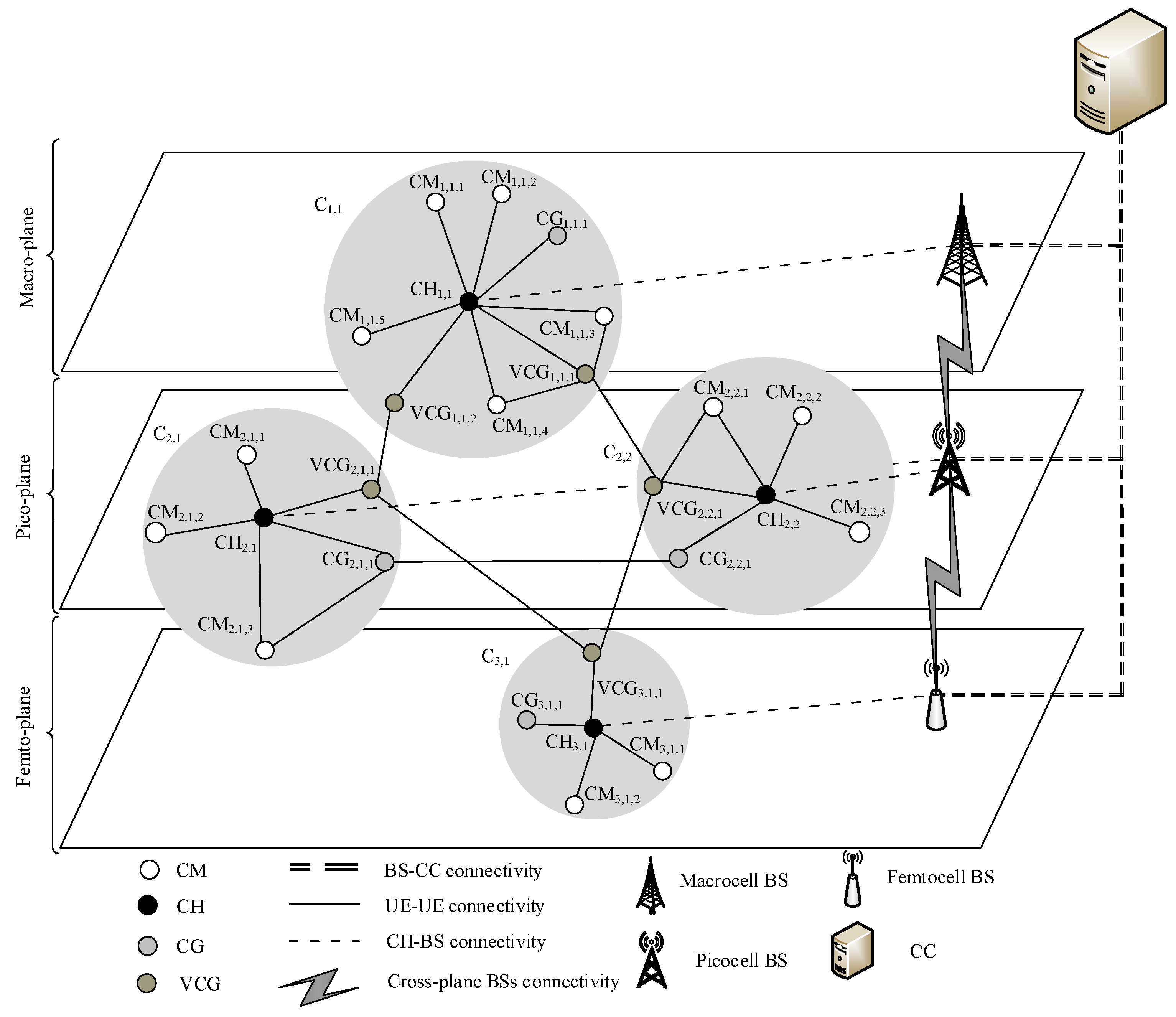
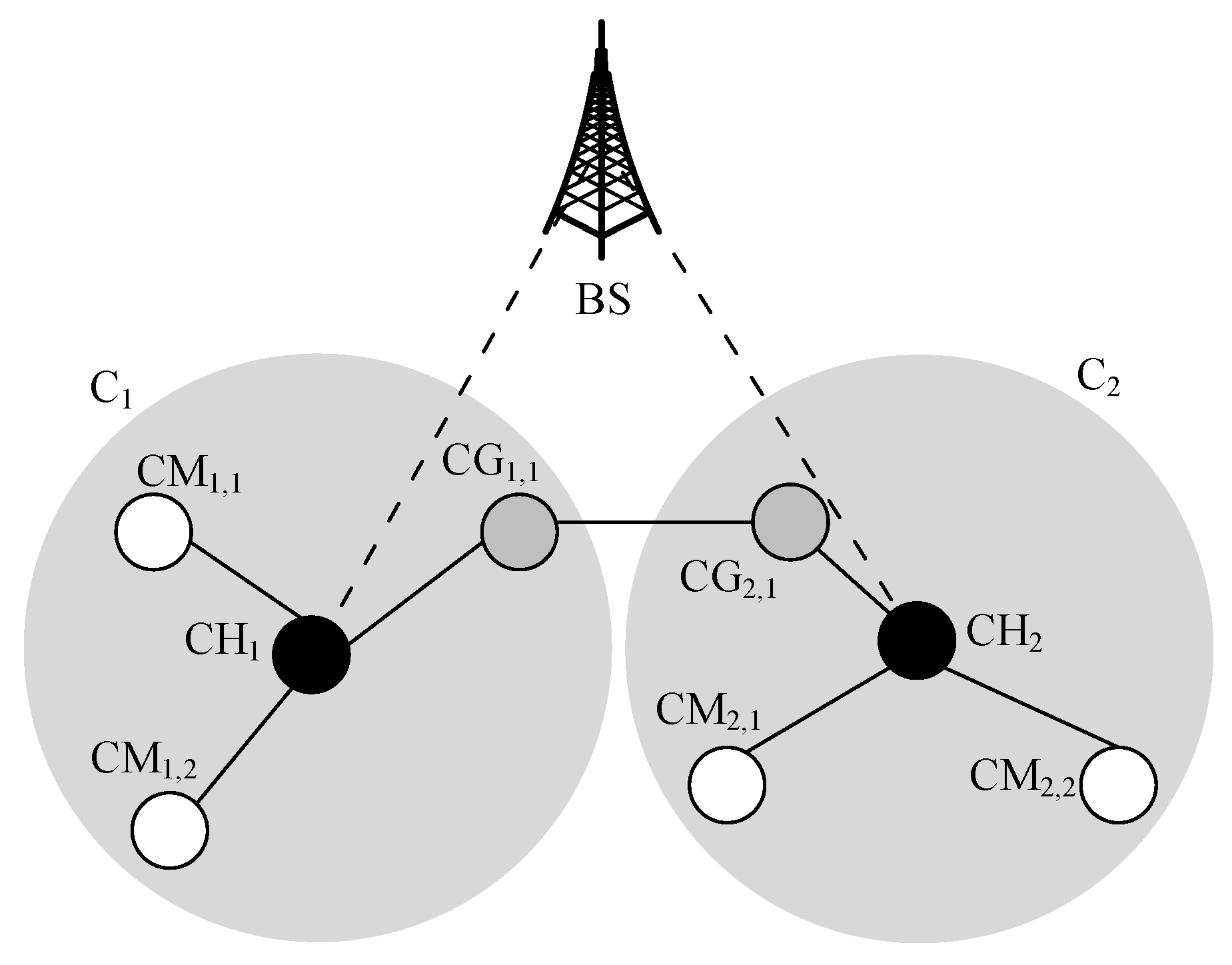
4.1. Vertical Routing
- The next-hop selection is performed over a clustered network, which has improved network stability. This is because our proposed vertical clustering scheme selects nodes with higher LET to serve as VCGs for communication among different clusters across different network planes.
- CHs, which are the distributed entities, make intra-plane decisions to select the next-hop when the source and the destination nodes are from the same network plane. Decisions are made based on the knowledge of the DQN agent. Meanwhile, the DQN agent in CC makes inter-plane decisions to select the next-hop node when the source and the destination nodes are from different network planes. Decisions are based on long-lifetime data (i.e., predictable mobility pattern). Therefore, nodes carrying data can receive forwarding decisions from CHs and CC, while avoiding the delay incurred in receiving forwarding decisions from the CC.
- UAV nodes increase connectivity among clusters. This is because they UAV nodes have a large transmission range due to their elevated lookup angle.
- The DQN agent embedded in the CC makes decisions based on state-action values, which represents the long-term reward. Specifically, the action with the highest state-action value is selected. By considering the long-term reward, DQN may not change its selection of actions (or policy) after every single variation in the network. This is because the best possible action may remain optimal from the long-term perspective; specifically, it continues to achieve the highest state-action value compared to the rest of the potential actions. Therefore, nodes carrying real-time data can still select optimal action, which is the forwarding decision, based on its state-action values while avoiding the delay incurred in receiving forwarding decisions from the CC.
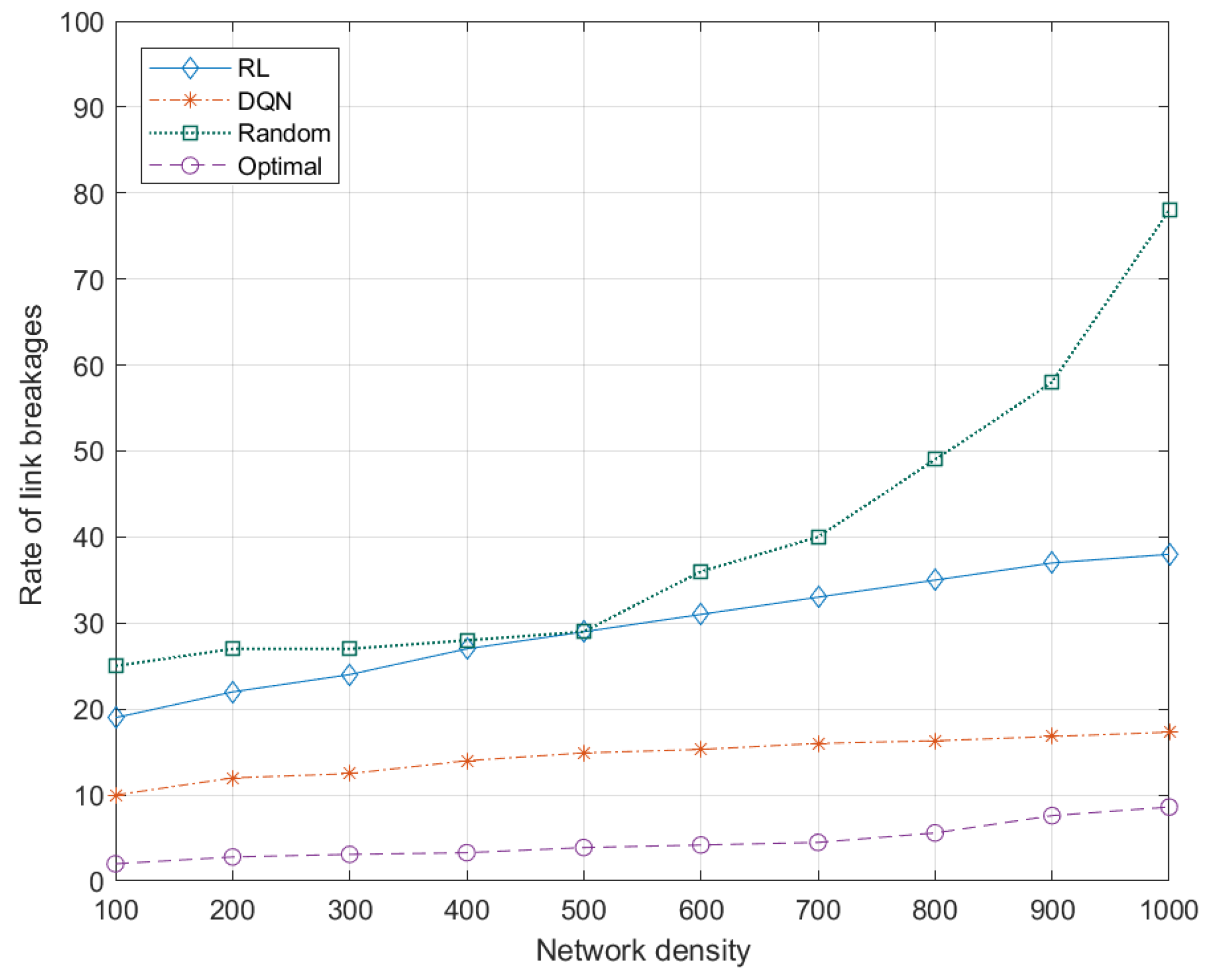
- The DQN agent represents two aspects of mobility, namely speed (which is the short-lifetime data) and direction or predictable mobility paths (which is the long-lifetime data), as the state, and so it learns the predictable mobility patterns of UAV nodes. This helps to reduce the rate of link breakages (i.e., disconnectivity) between nodes.
4.2. DQN-Based Vertical Routing Scheme
4.3. Reinforcement Learning
5. Performance Evaluation, Results, and Discussion
5.1. Simulation Platforms
5.2. Baseline and Optimal Approaches
5.3. Simulation Parameters
5.4. Energy Model
5.5. Performance Measures
5.6. Analysis
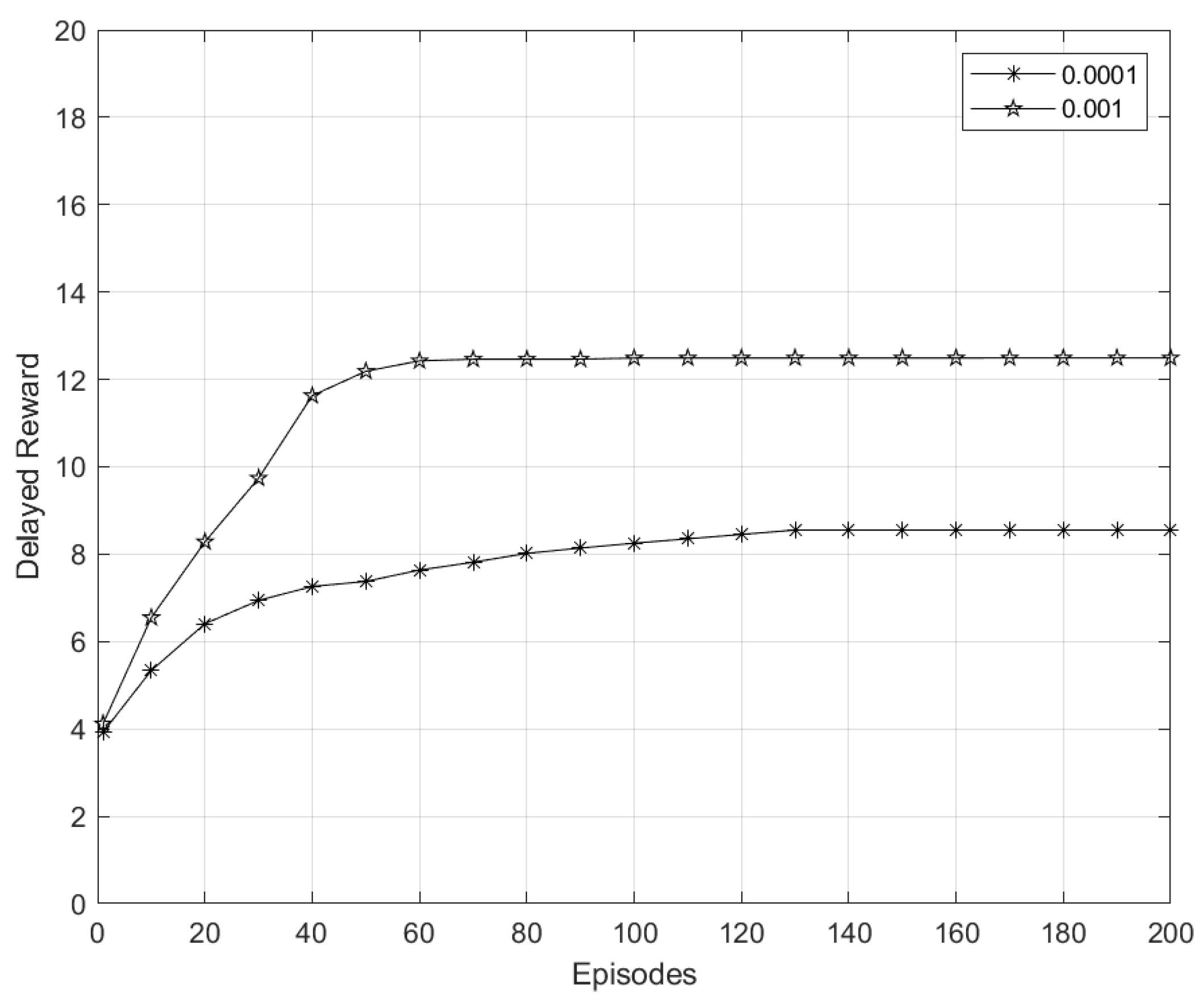
5.6.1. RL
5.6.2. DQN
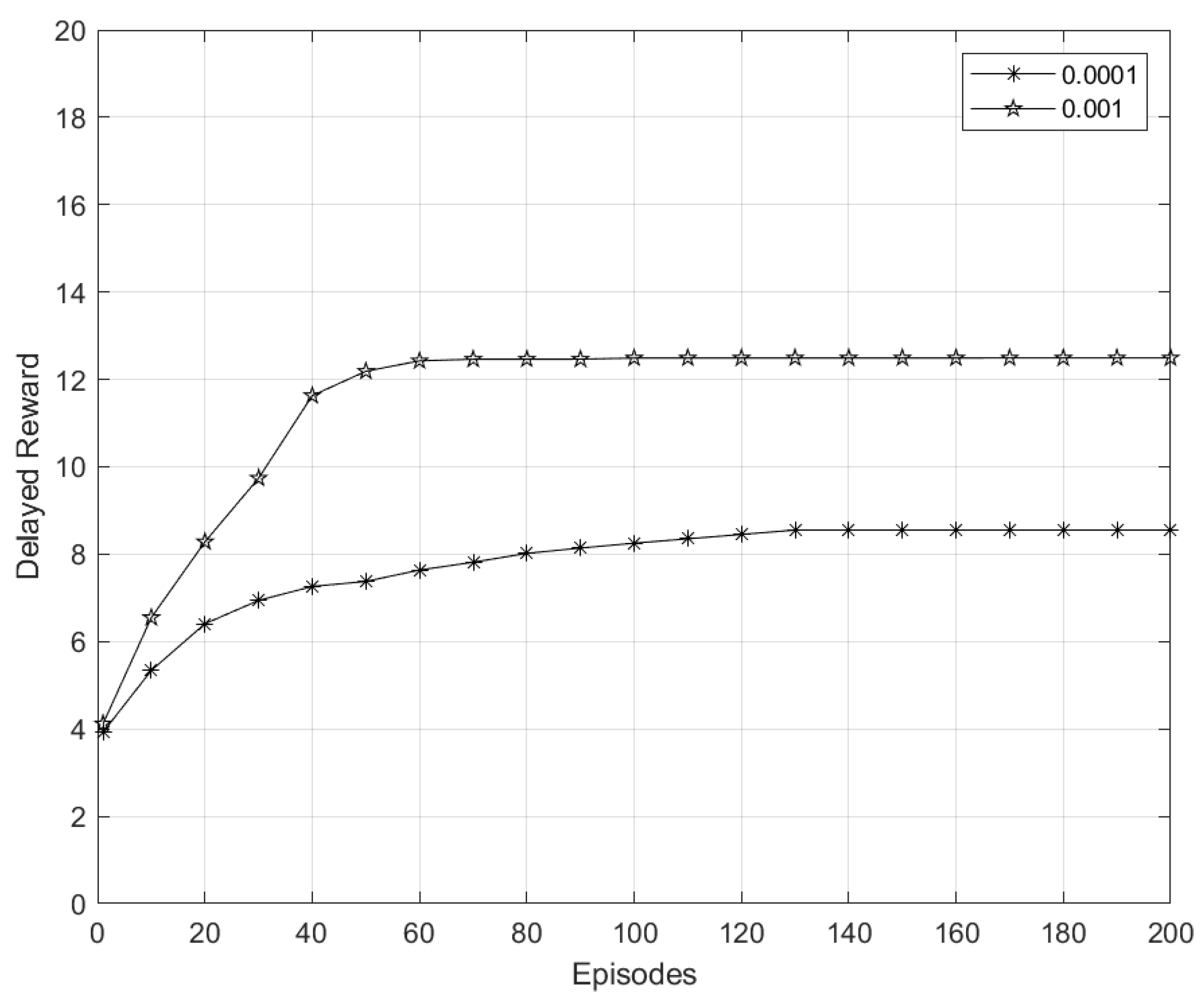
5.6.3. Convergence of DQN Algorithm
5.7. Simulation Results and Discussions
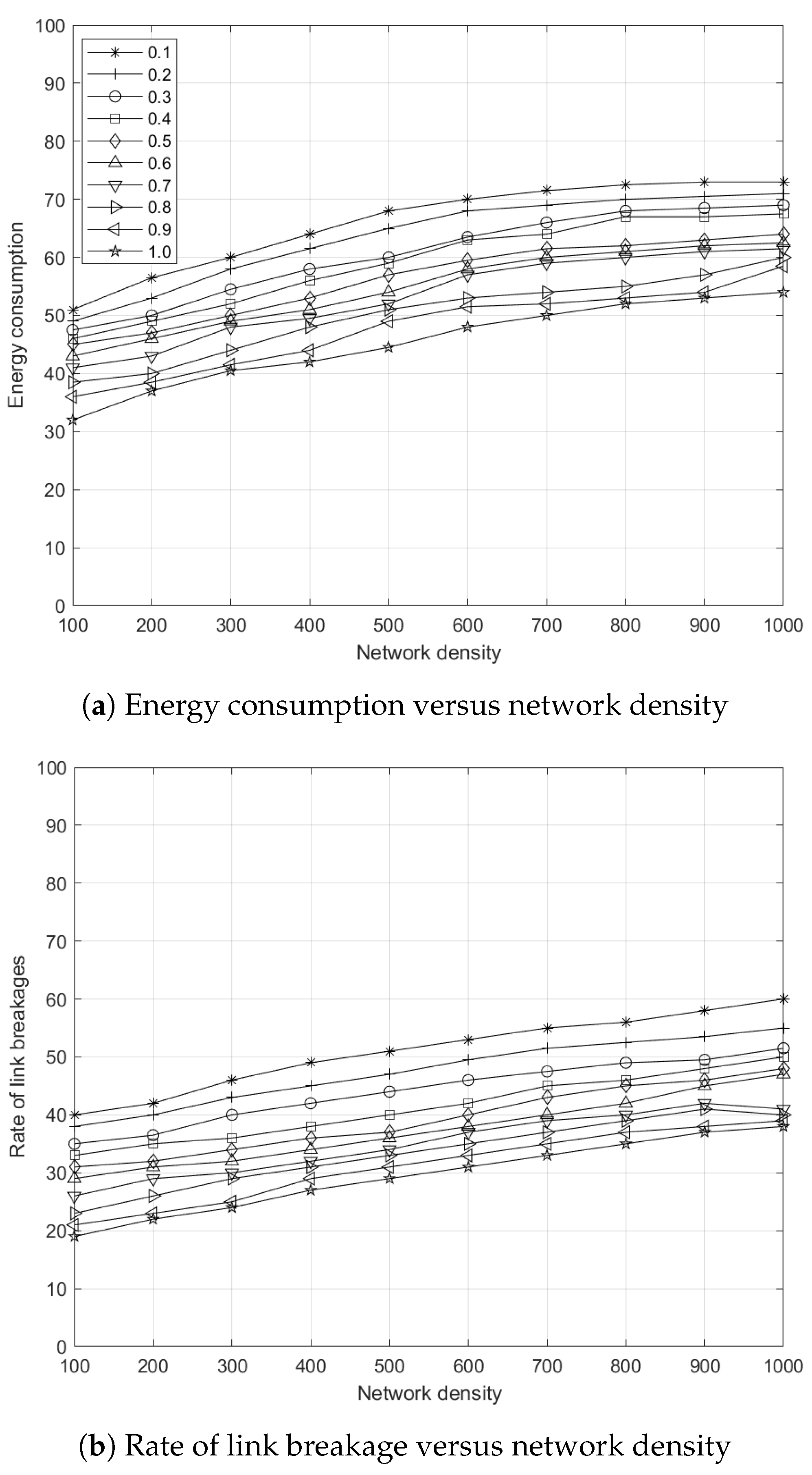
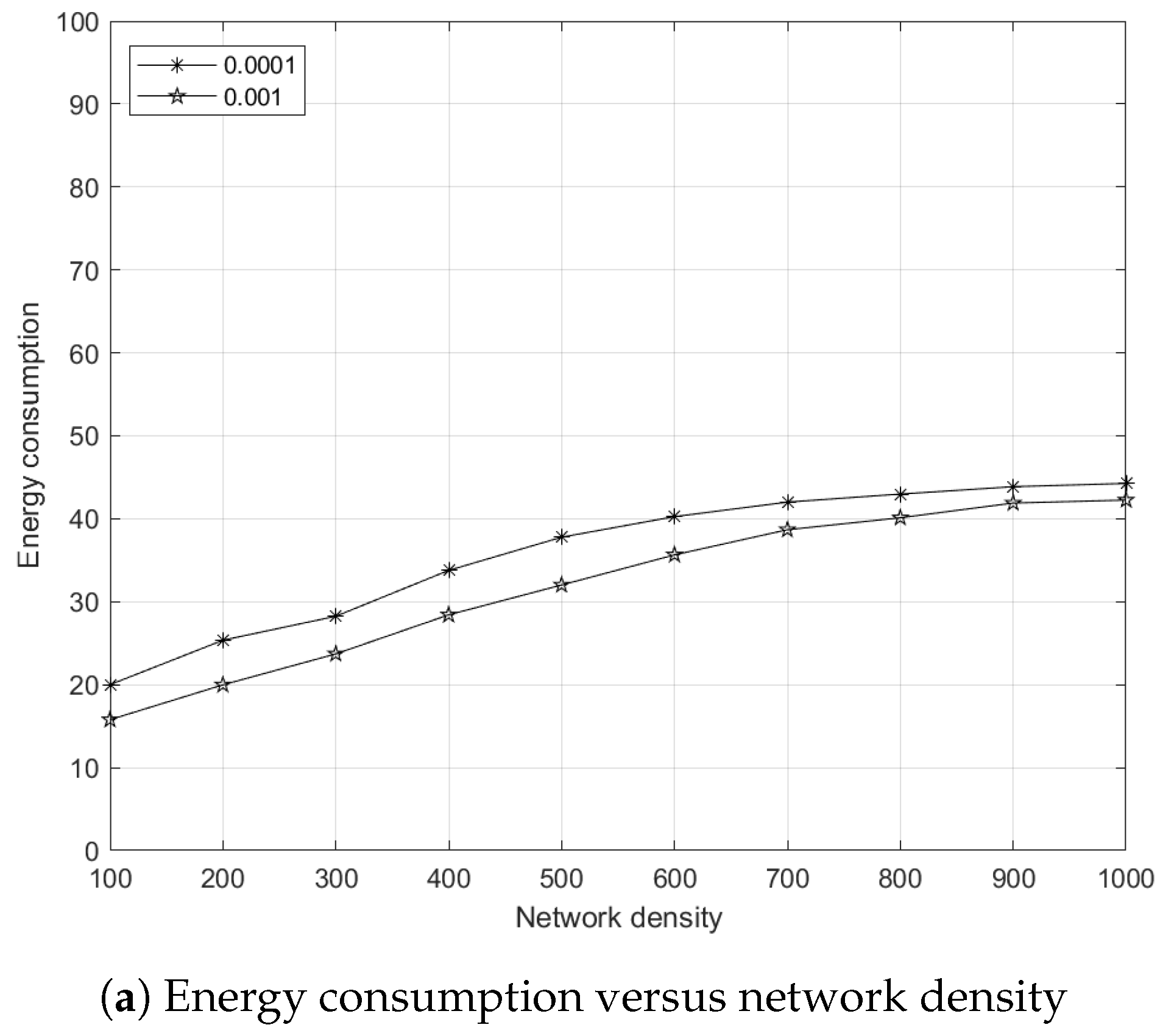
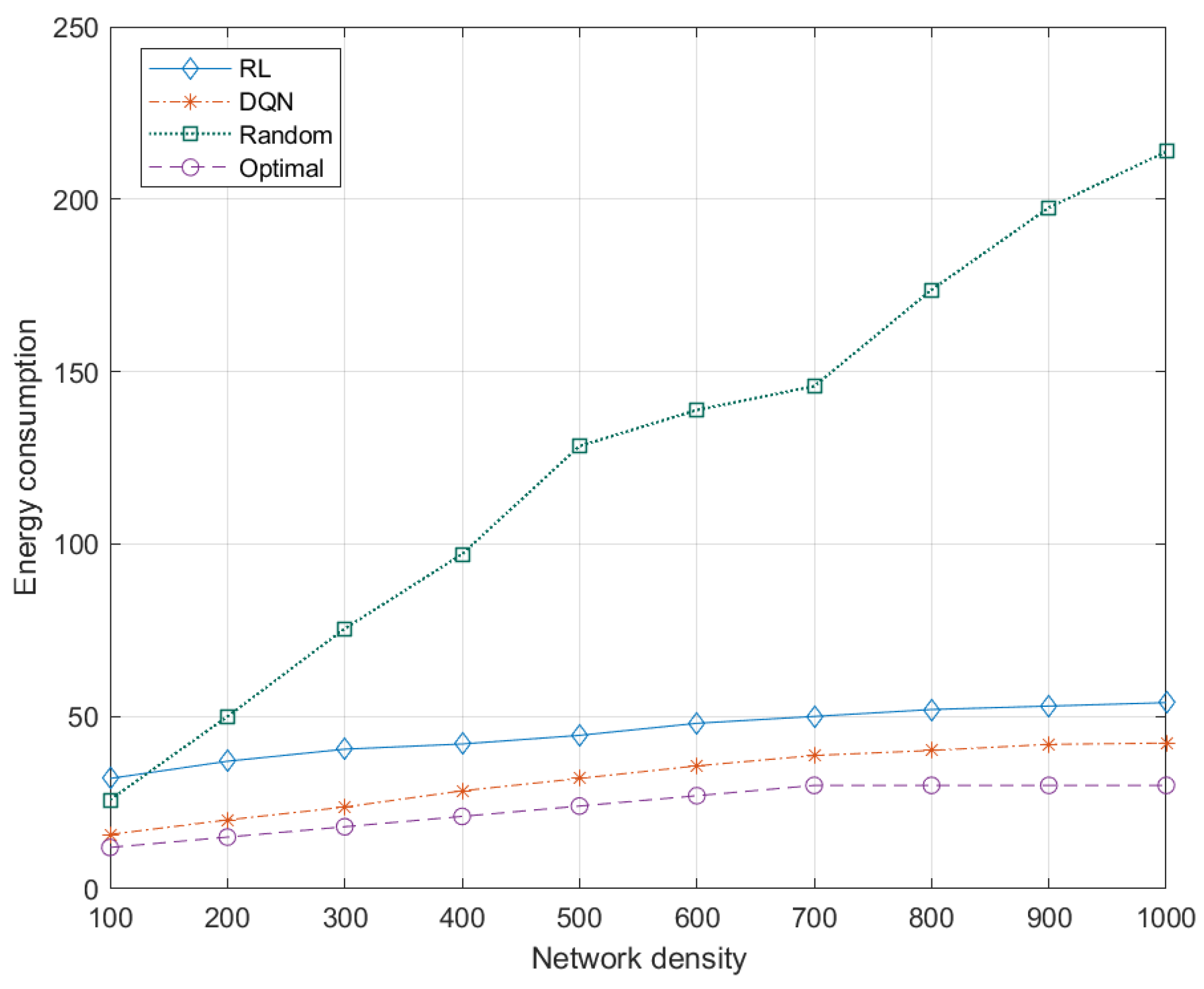
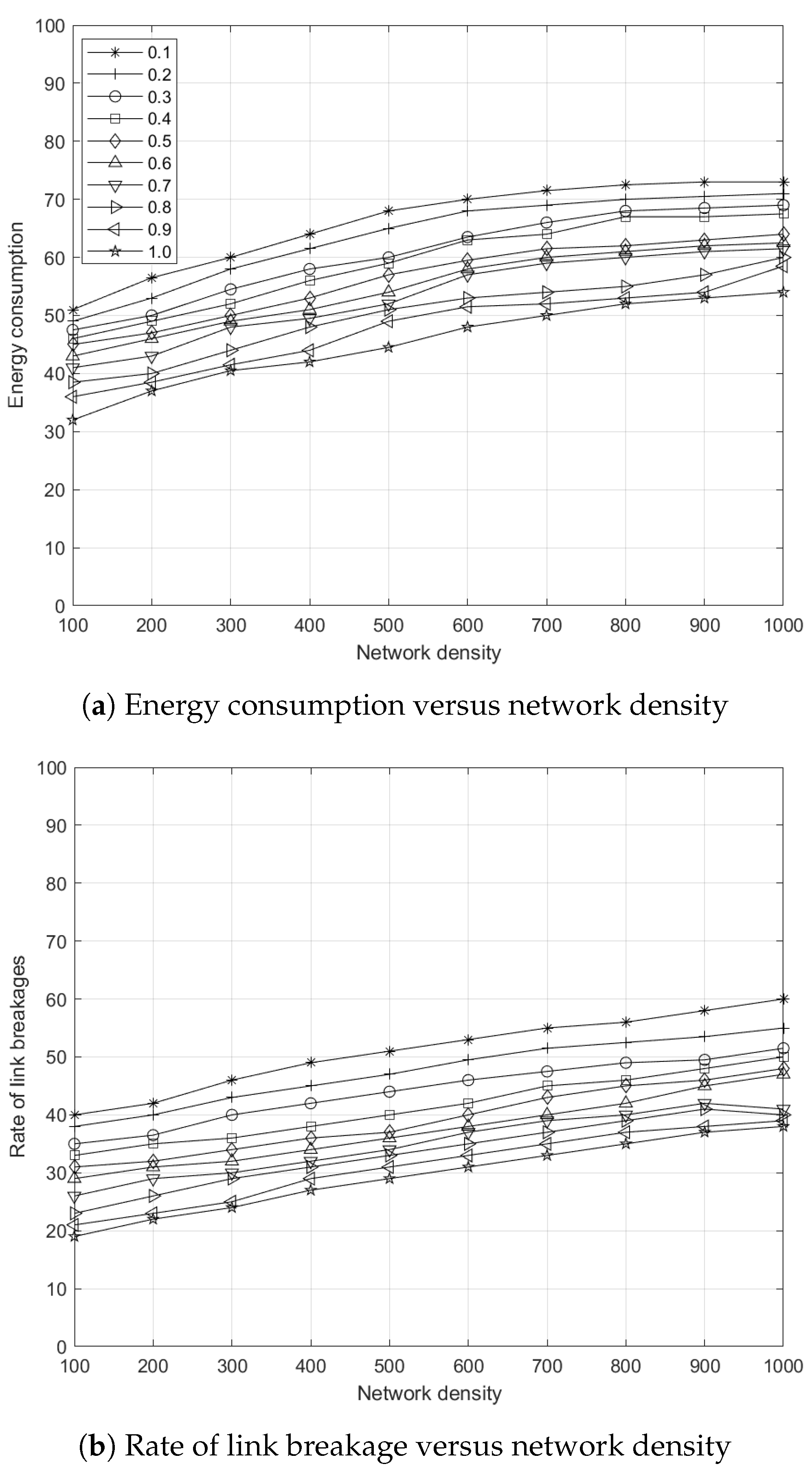
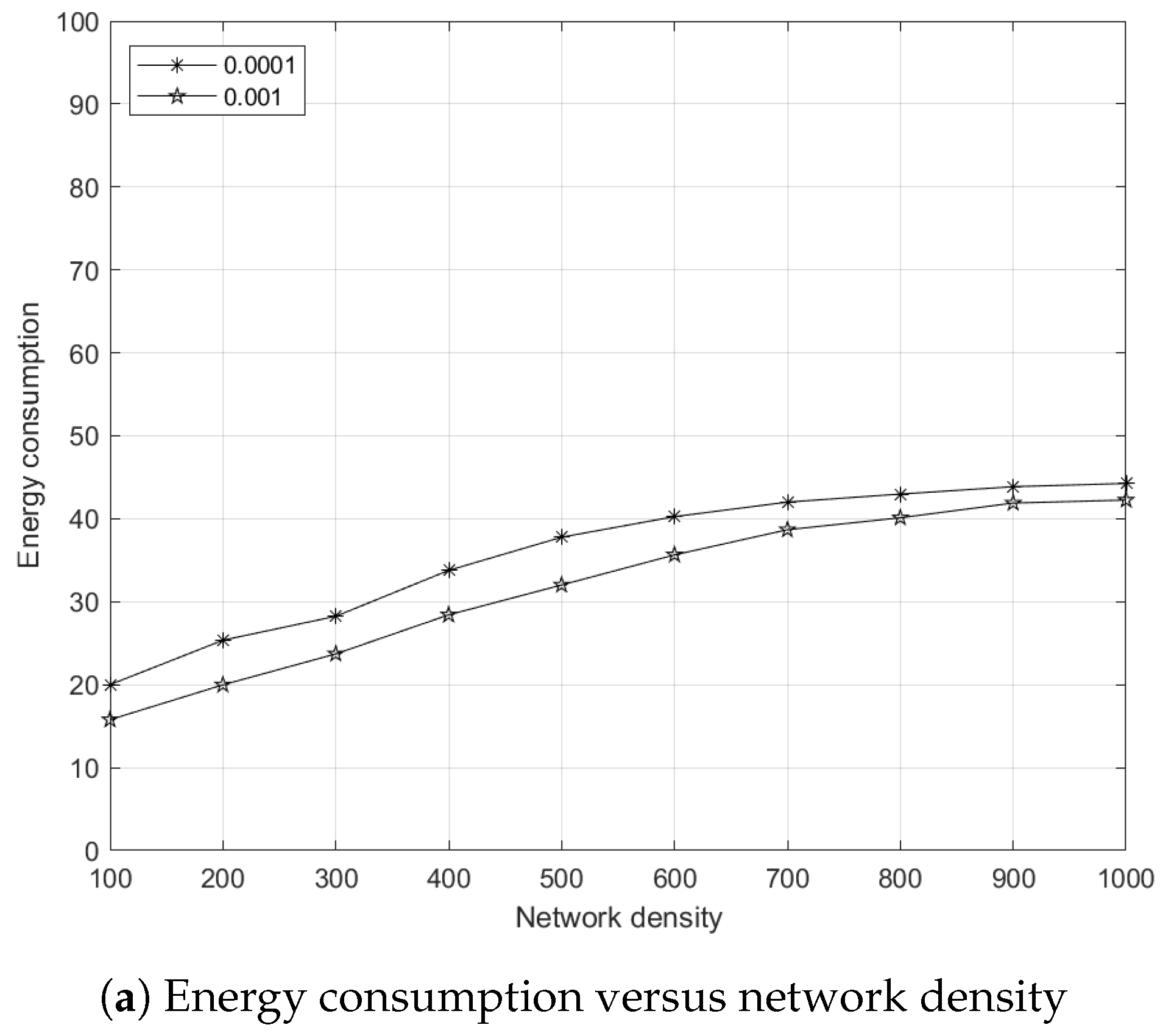
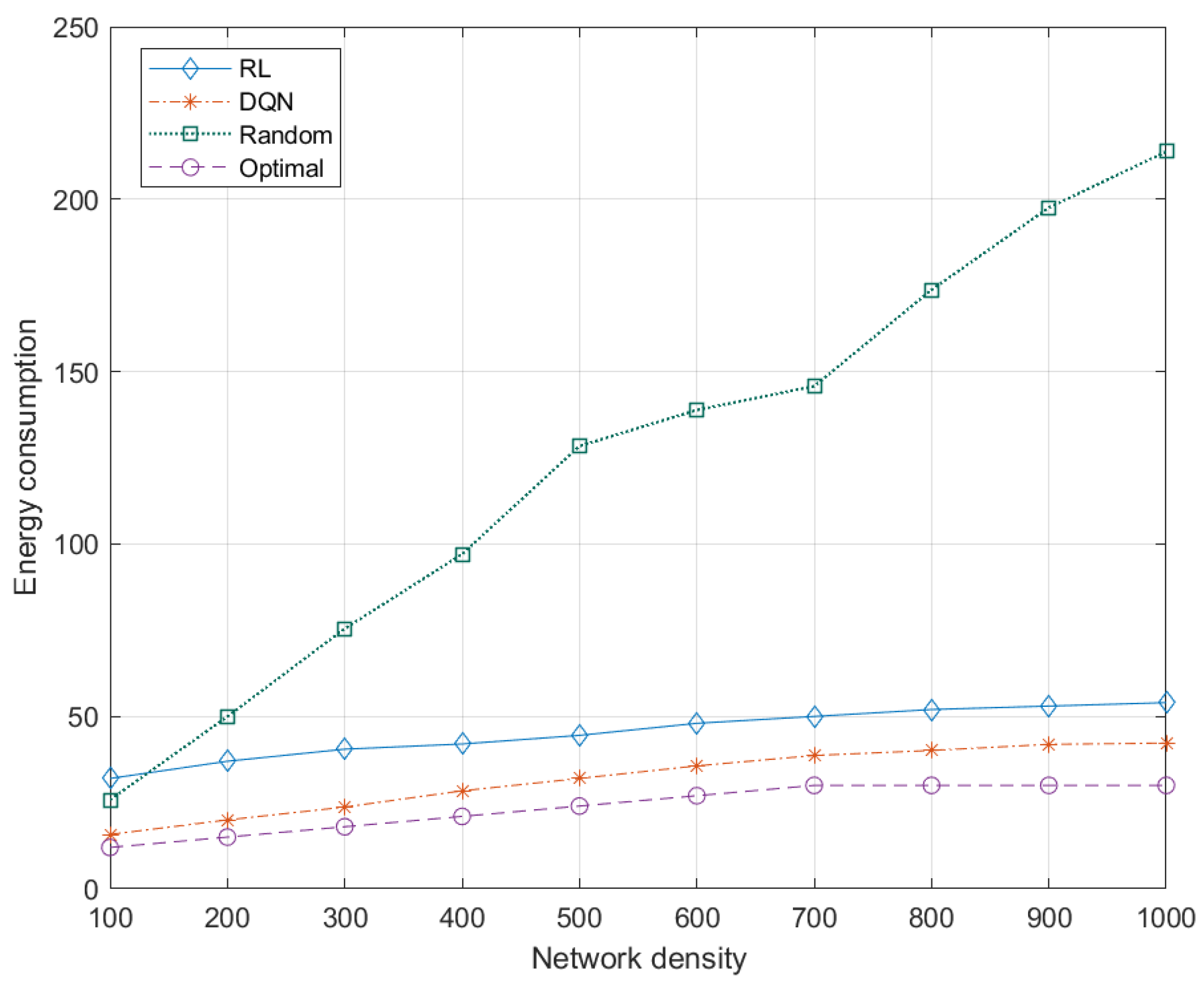
5.7.1. Effects of Network Density to Energy Consumption
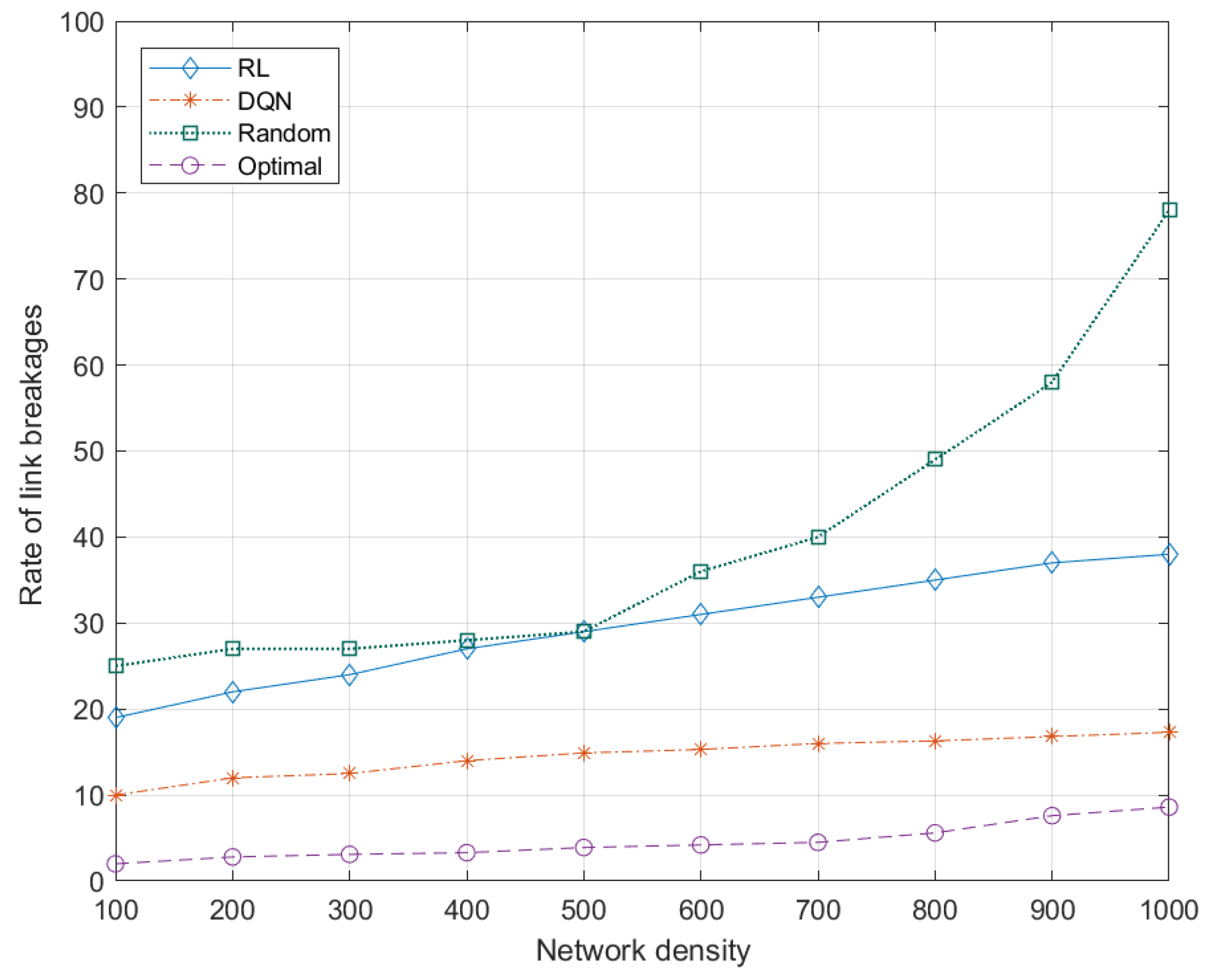
5.7.2. Effects of Network Density to Link Breakages
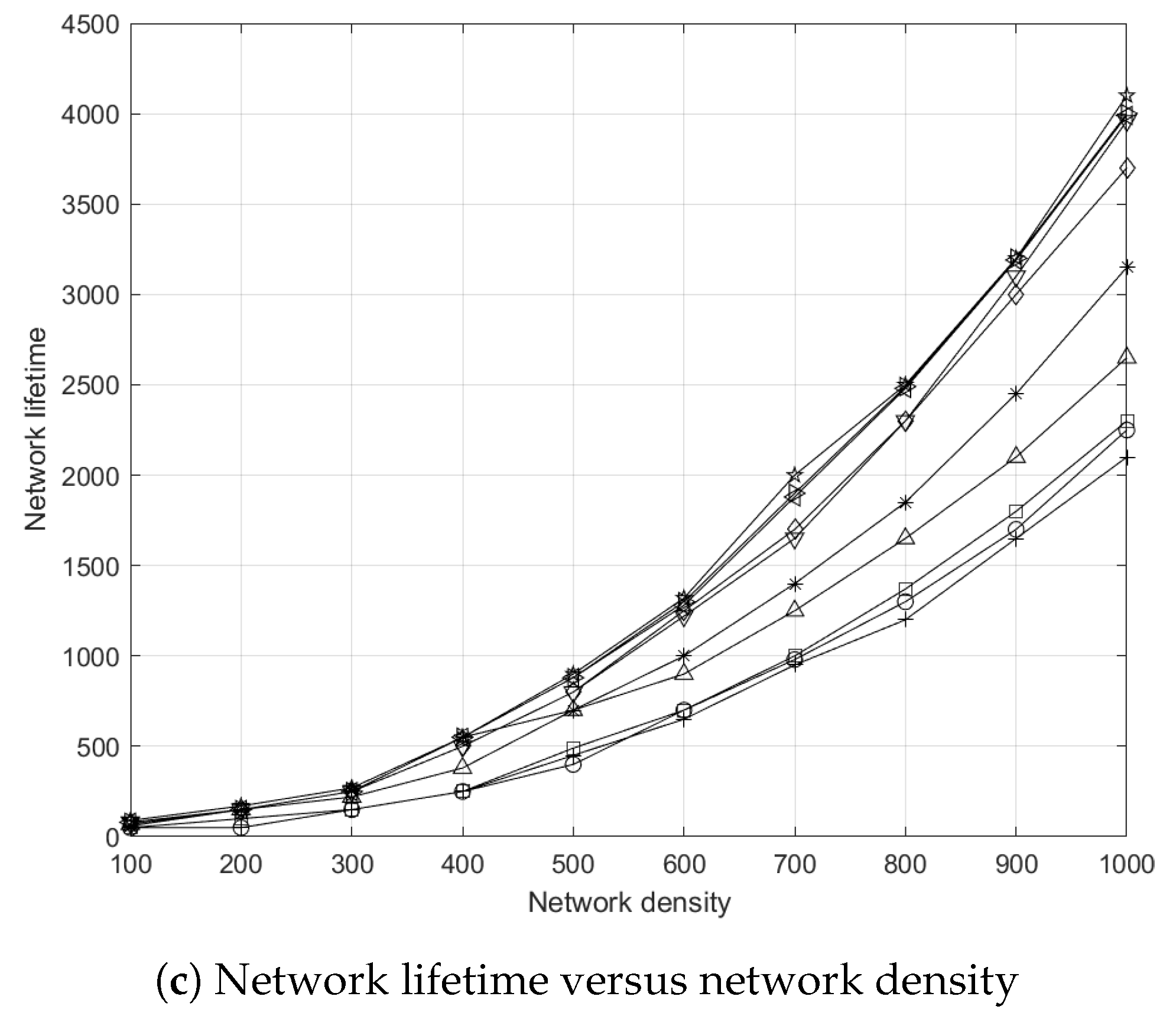
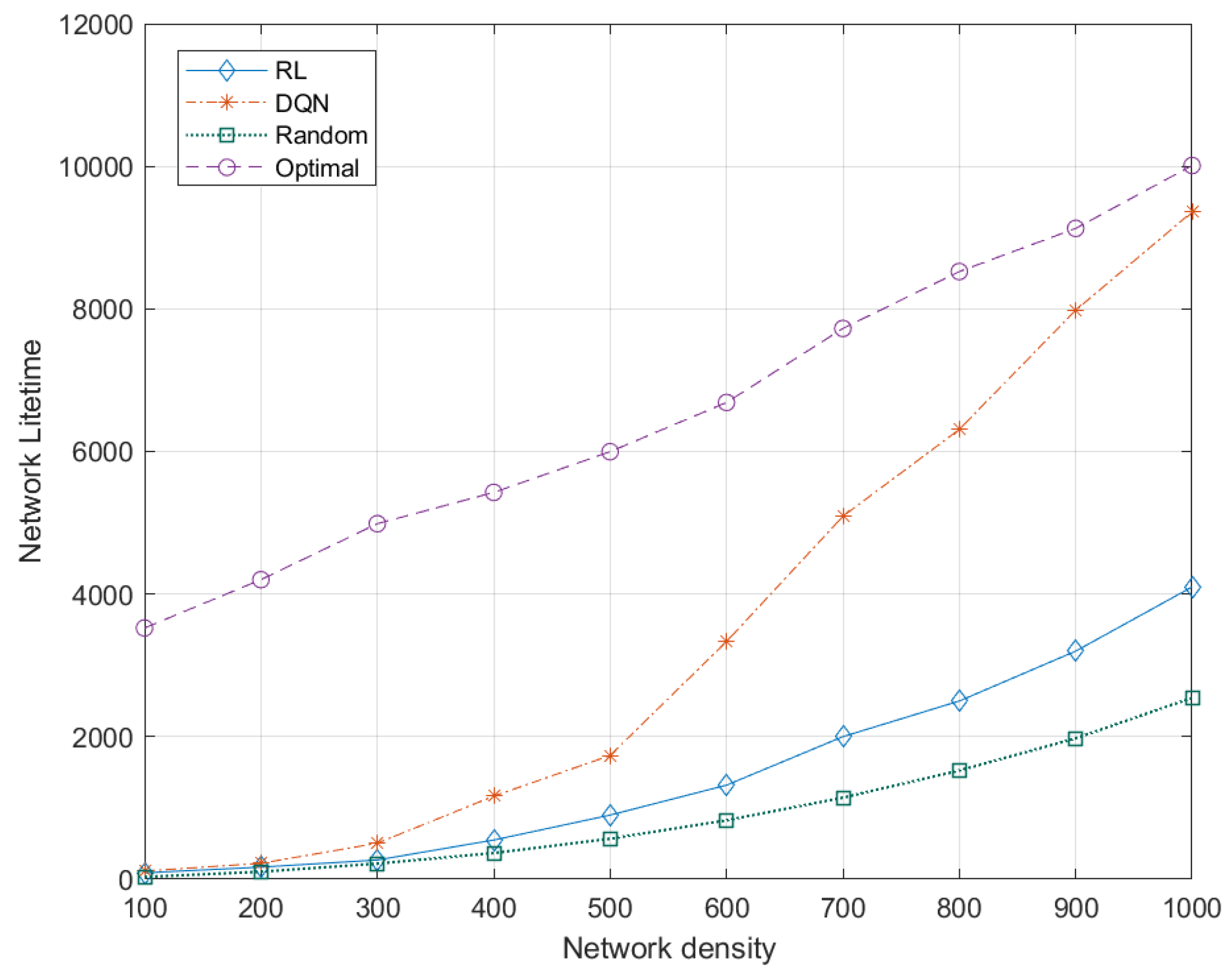
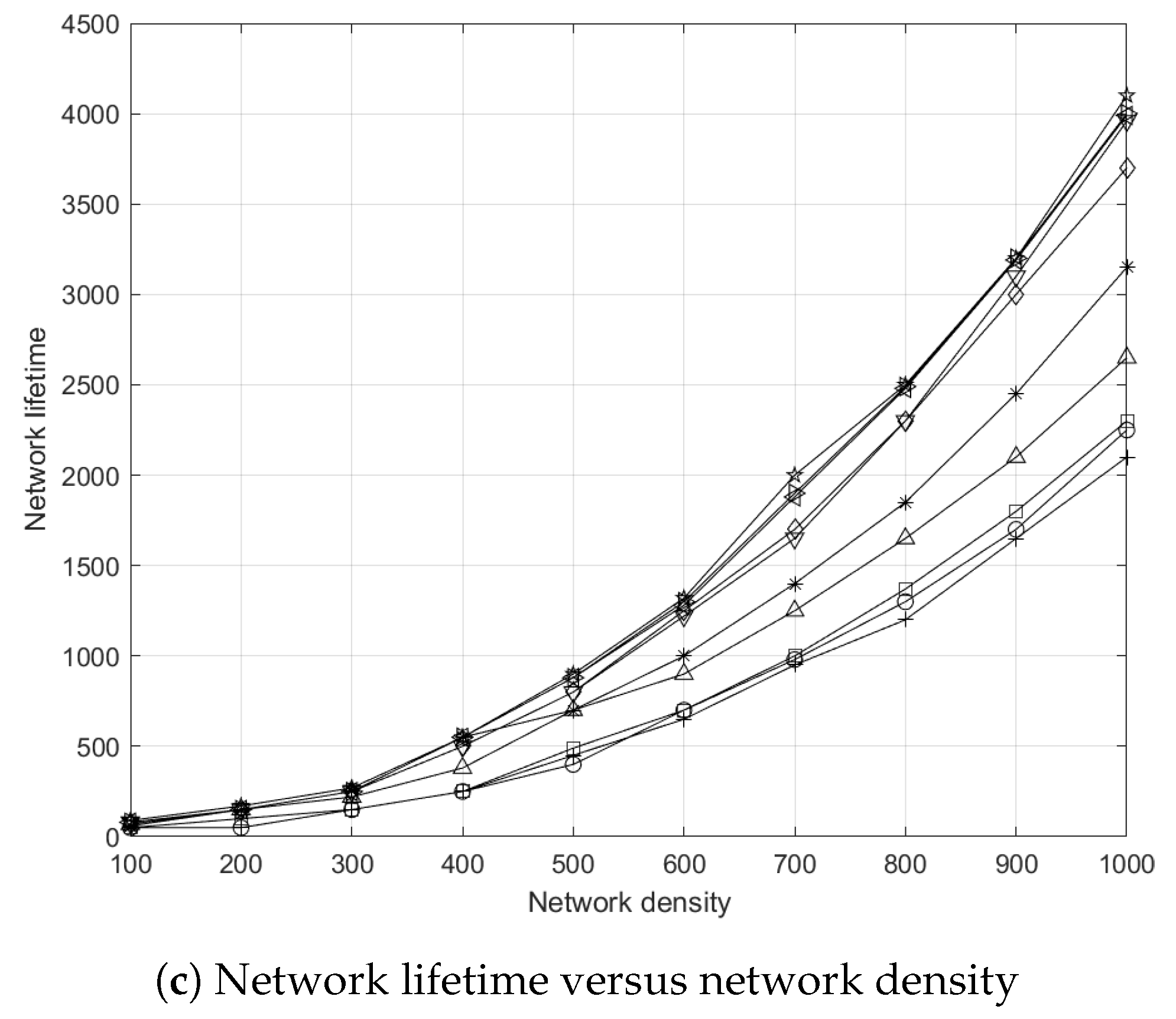
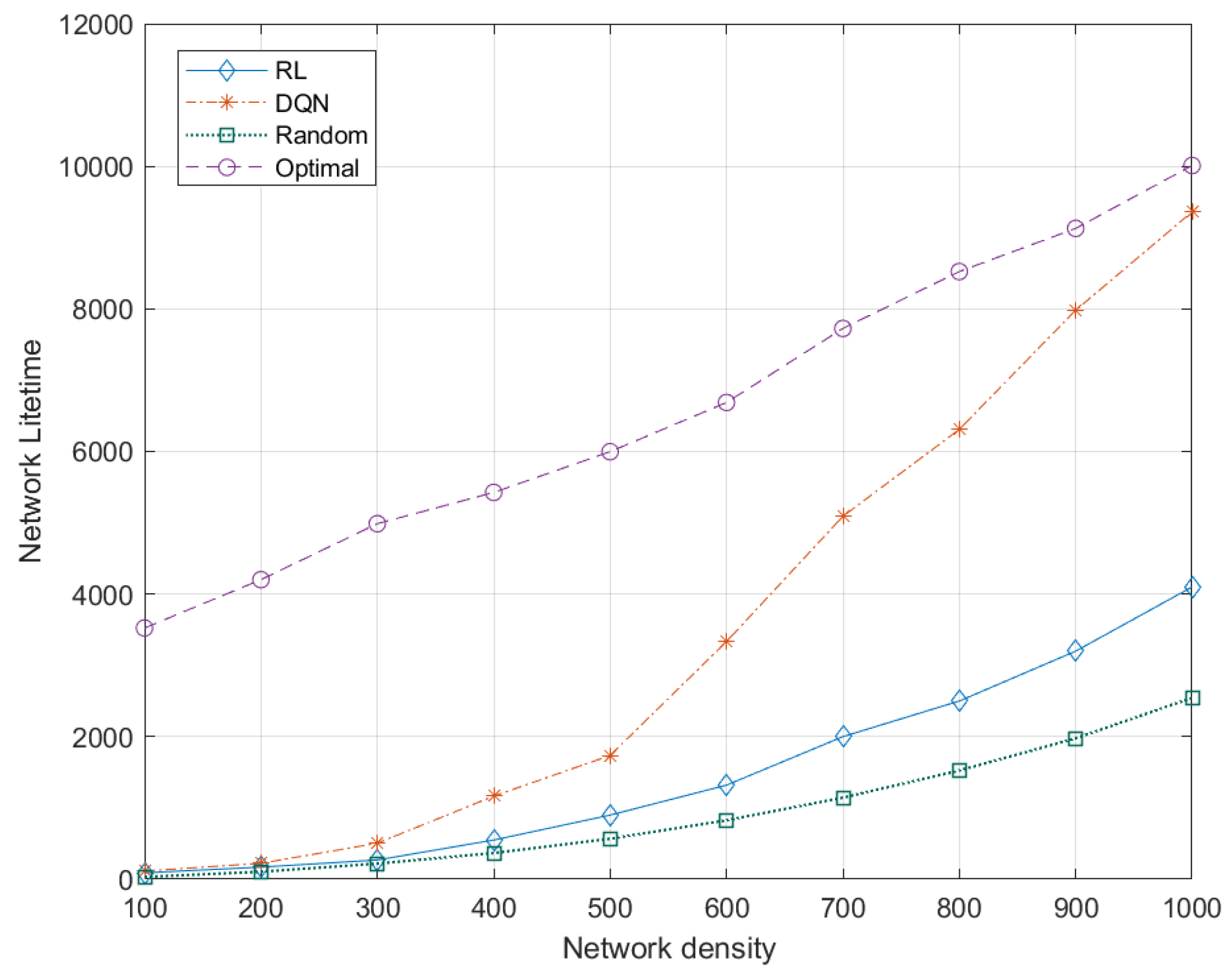
5.7.3. Effects of Network Density to Network Lifetime
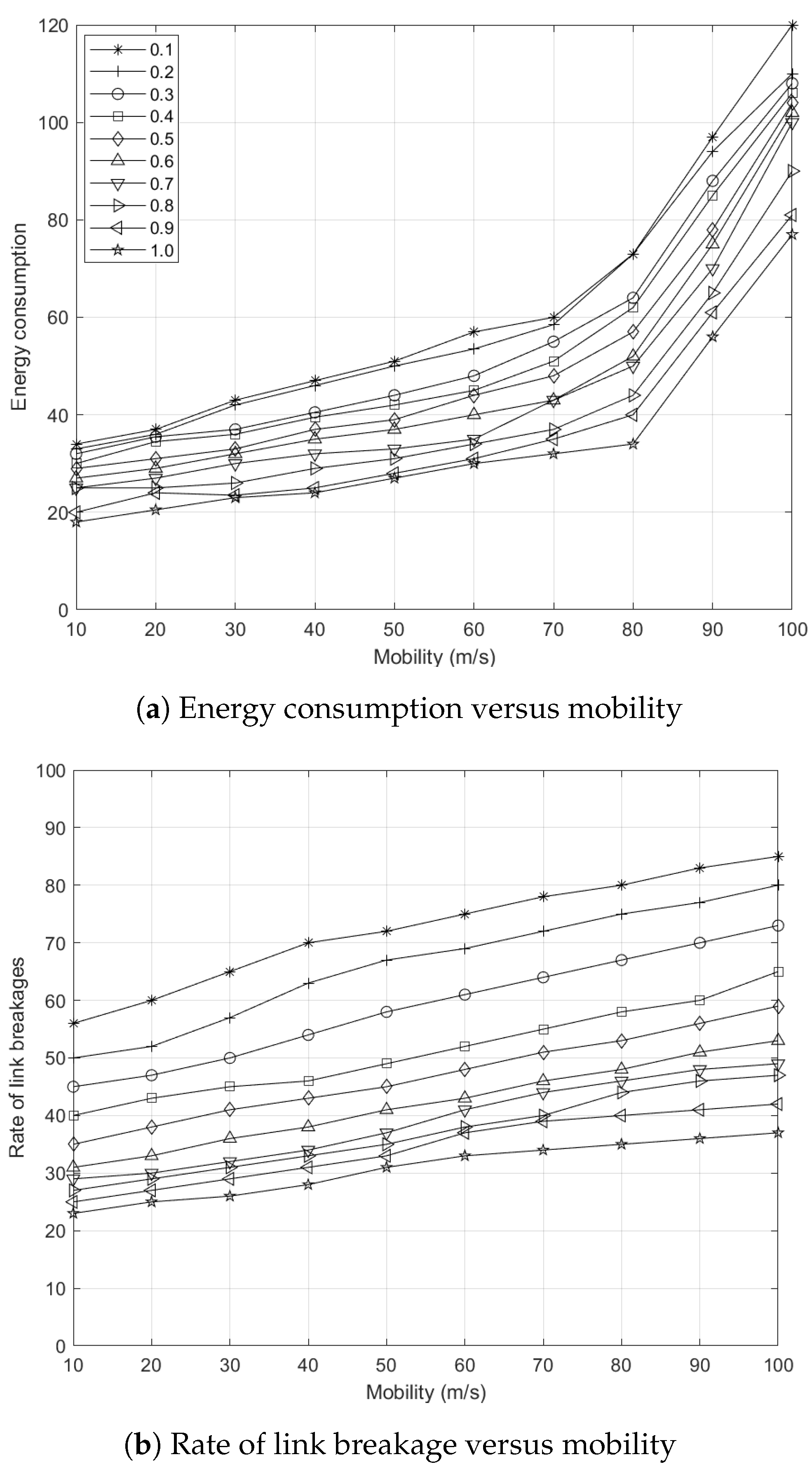
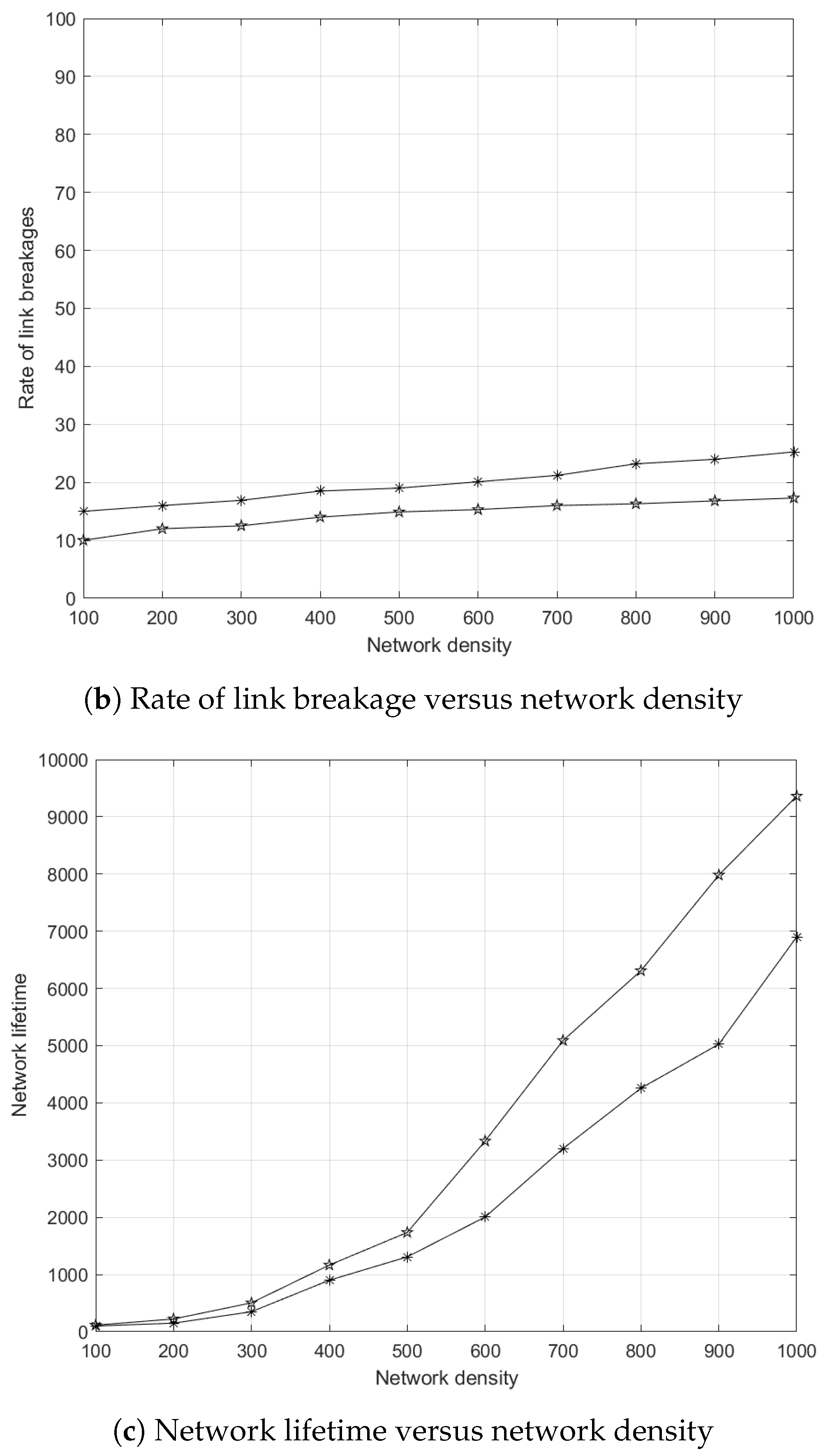
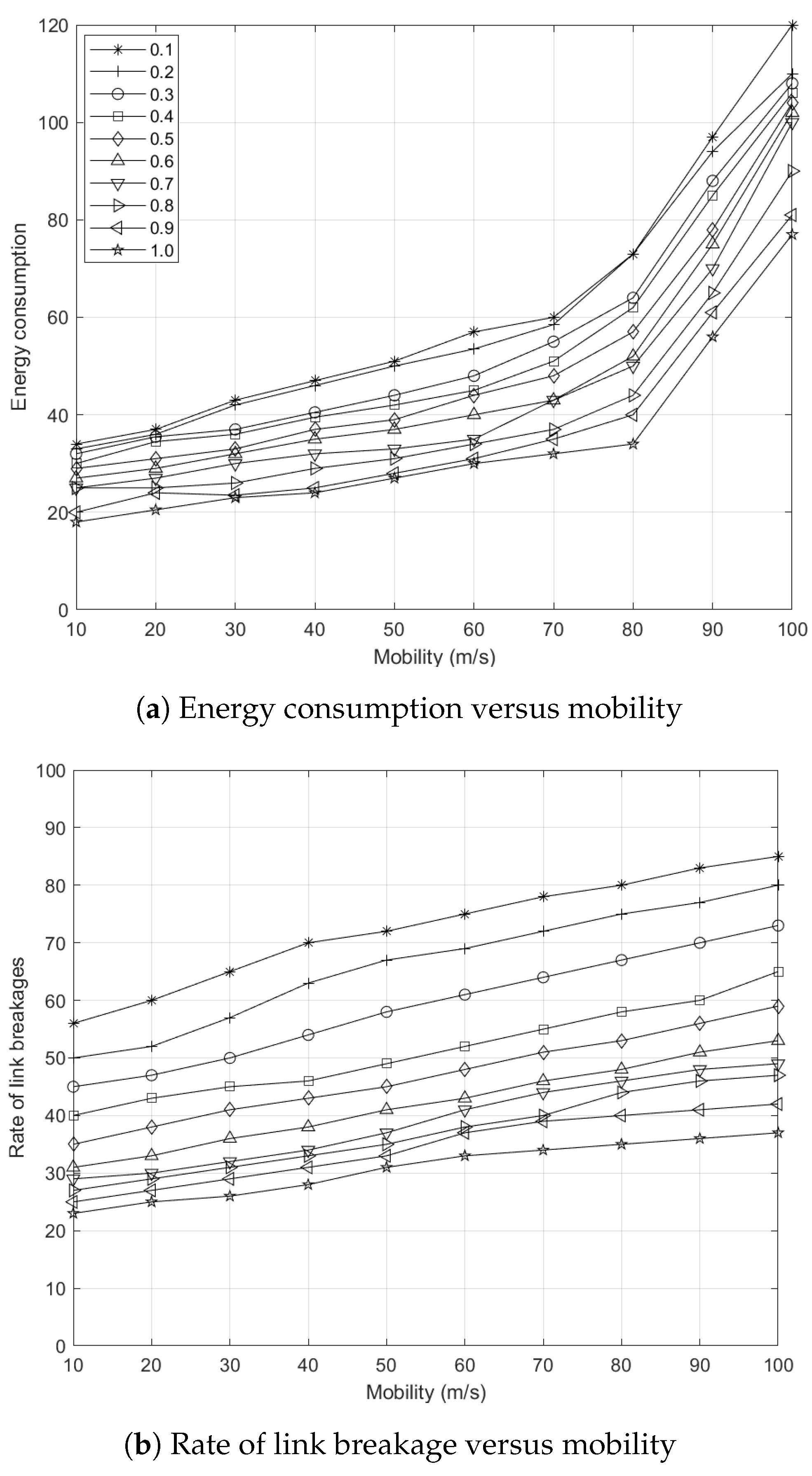
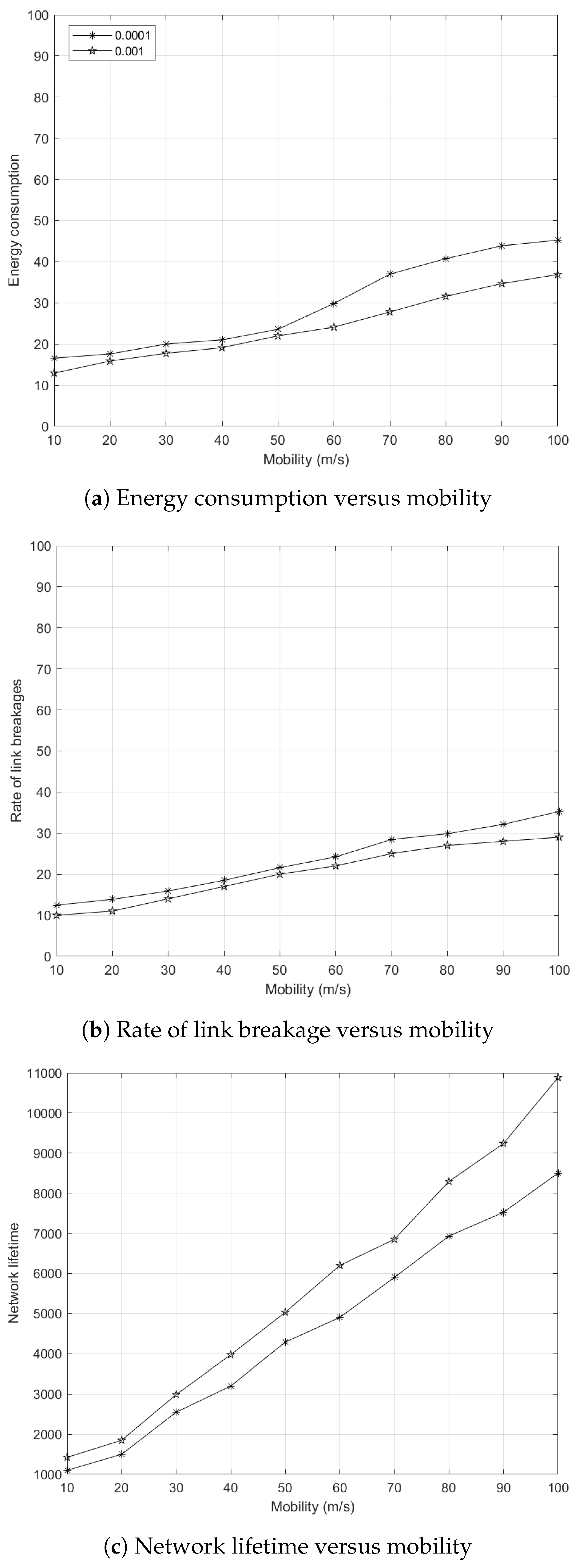
5.7.4. Effects of Node Mobility to Energy Consumption
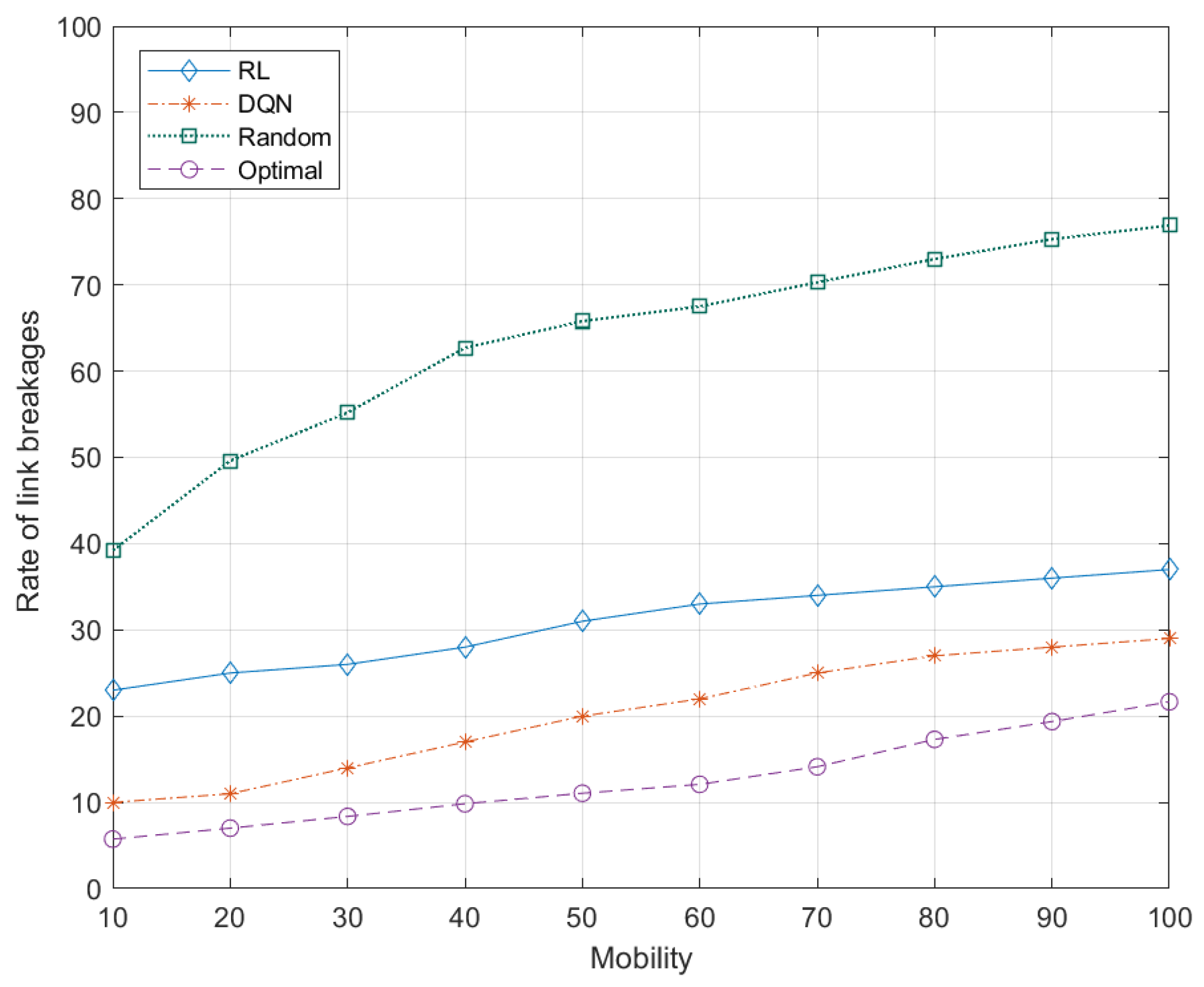
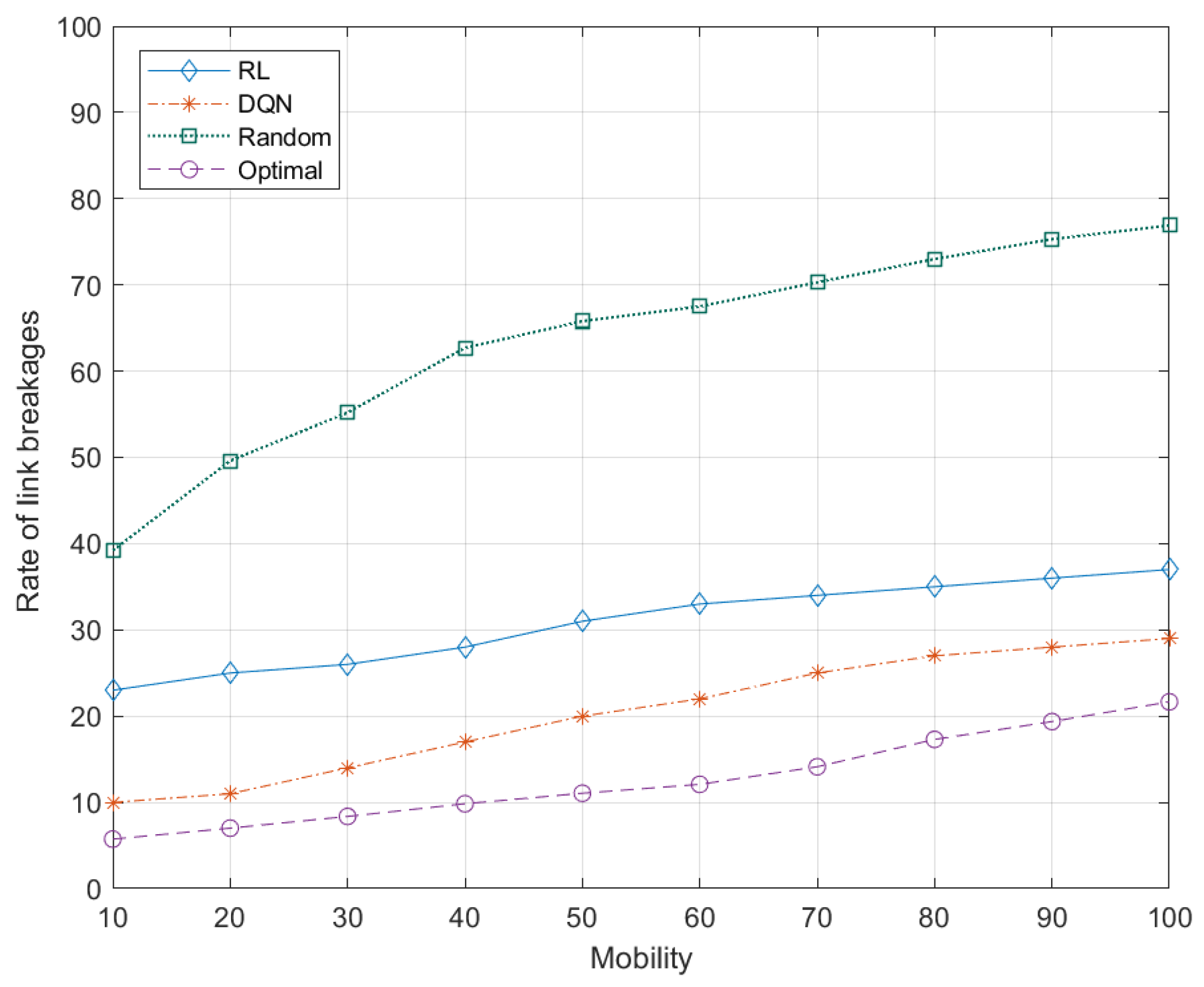
5.7.5. Effects of Node Mobility to Rate of Link Breakages
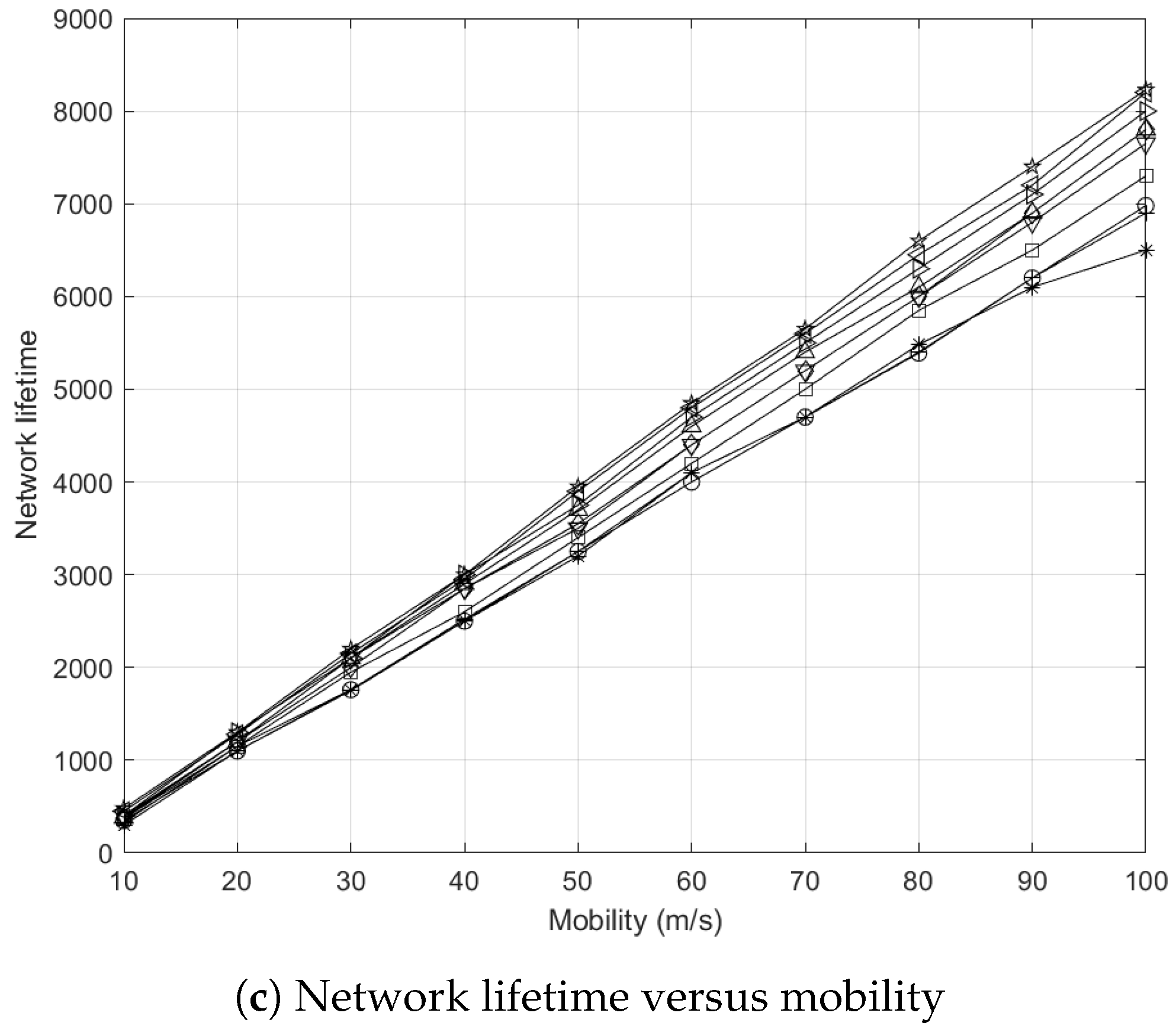
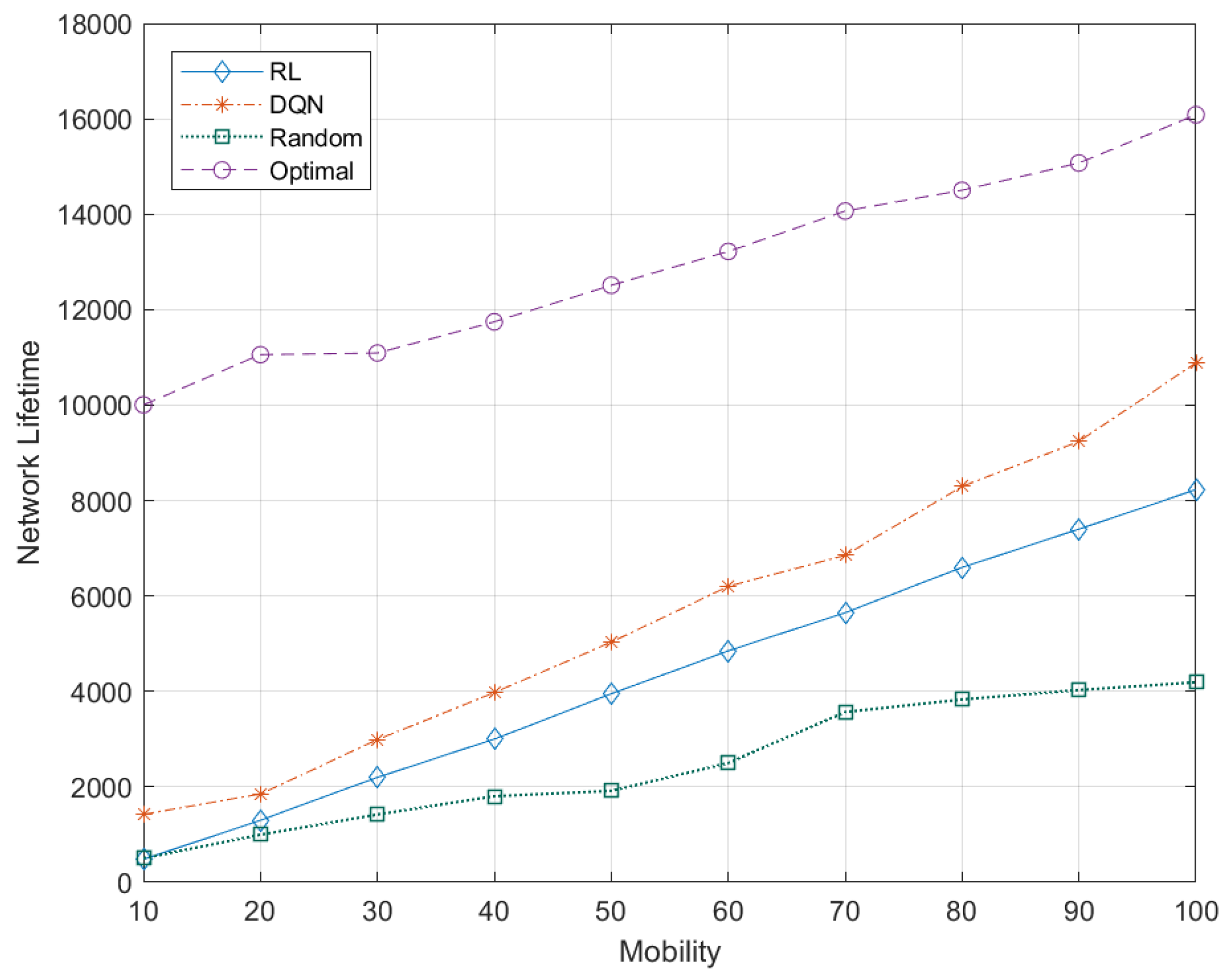
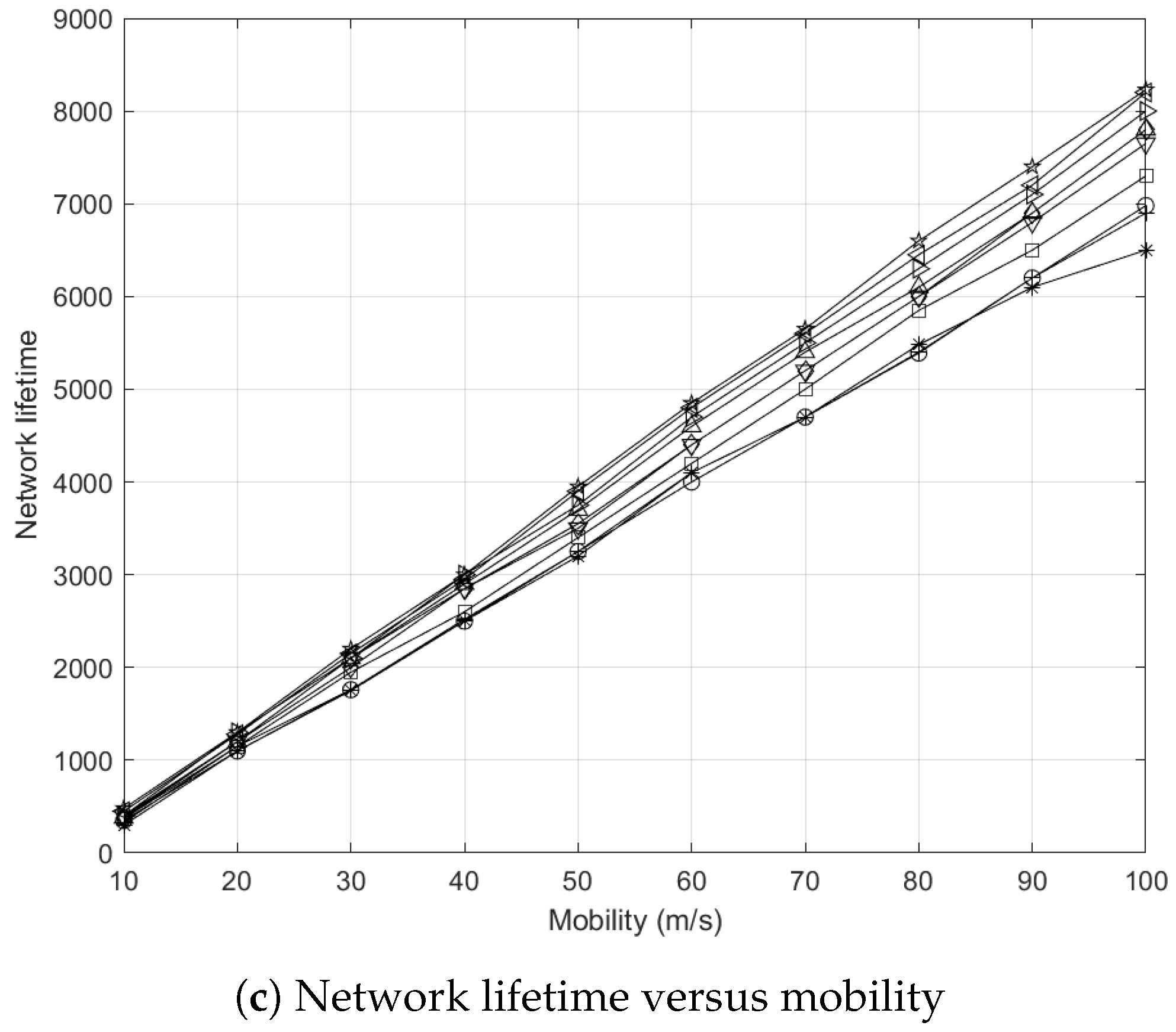
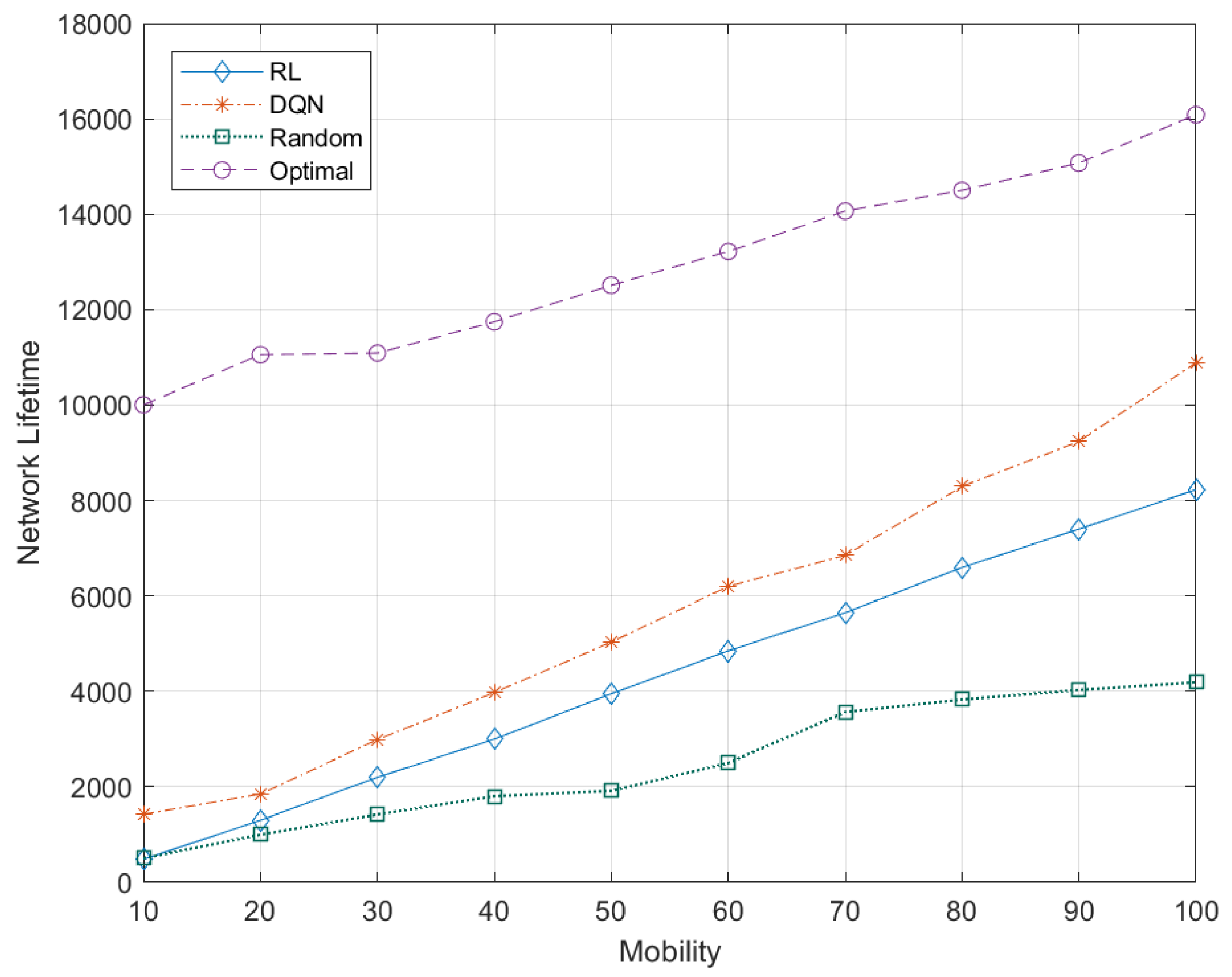
5.7.6. Effects of Node Mobility to Network Lifetime
5.8. Complexity Analysis
6. Conclusions
7. Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| 5G | Fifth generation. |
| CC | Centralized controller. |
| CG | Cluster gateway. |
| CH | Cluster head. |
| CM | Cluster member. |
| D2D | Device-to-device. |
| DC | Distributed controller. |
| DNN | Deep neural network. |
| DQN | Deep Q-network. |
| DRL | Deep reinforcement learning. |
| FANETs | Flying ad hoc networks. |
| LET | Link expiration time. |
| QoS | Quality of service. |
| RL | Reinforcement learning. |
| UAVs | Unmanned aerial vehicles. |
| UE | User equipment. |
| VCG | Vertical cluster gateway. |
References
- Huang, X.L.; Ma, X.; Hu, F. Machine learning and intelligent communications. Mob. Netws. Appl. 2018, 23, 68–70. [Google Scholar] [CrossRef] [Green Version]
- Khan, M.F.; Yau, K.-L.A.; Noor, R.M.; Imran, M.A. Survey and taxonomy of clustering algorithms in 5G. J. Netw. Comput. Appl. 2020, 154, 201–221. [Google Scholar] [CrossRef]
- Song, Q.; Jin, S.; Zheng, F.-C. Completion time and energy consumption minimization for UAV-enabled multicasting. IEEE Wirel. Commun. Lett. 2019, 8, 821–824. [Google Scholar] [CrossRef]
- Oubbati, O.; Atiquzzaman, M.; Ahanger, T.; Ibrahim, A. Softwarization of UAV networks: A survey of applications and future trends. IEEE Access 2020, 8, 98073–98125. [Google Scholar] [CrossRef]
- Alzahrani, B.; Oubbati, O.; Barnawi, A.; Atiquzzaman, M.; Alghazzawi, D. UAV assistance paradigm: State-of-the-art in applications and challenges. J. Netw. Comput. Appl. 2020, 166, 102706. [Google Scholar] [CrossRef]
- Oubbati, O.; Mozaffari, M.; Chaib, N.; Lorenz, P.; Atiquzzaman, M.; Jamalipour, A. ECaD: Energy-efficient routing in flying ad hoc networks. Int. J. Commun. Syst. 2019, 32, e4156. [Google Scholar] [CrossRef] [Green Version]
- Kamel, M.; Hamouda, W.; Youssef, A. Ultra-dense networks: A survey. IEEE Commun. Surv. Tutor. 2016, 18, 2522–2545. [Google Scholar] [CrossRef]
- Shaikh, F.S.; Wismüller, R. Routing in multi-hop cellular device-to-device (D2D) networks: A survey. IEEE Commun. Tutor. 2018, 20, 2622–2657. [Google Scholar] [CrossRef]
- Chandrasekhar, V.; Andrews, J.; Gatherer, A. Femtocell networks: A survey. arXiv 2008, arXiv:0803.0952. [Google Scholar] [CrossRef] [Green Version]
- Li, Q.C.; Niu, H.; Papathanassiou, A.T.; Wu, G. 5G network capacity: Key elements and technologies. IEEE Veh. Technol. Mag. 2014, 9, 71–78. [Google Scholar] [CrossRef]
- Jiang, D.; Liu, G. An overview of 5G requirements. In 5G Mobile Communications; Springer: Cham, Switzerland, 2017; pp. 3–26. [Google Scholar]
- Imran, A.; Zoha, A.; Abu-Dayya, A. Challenges in 5G: How to empower SON with big data for enabling 5G. IEEE Netw. 2014, 28, 27–33. [Google Scholar] [CrossRef]
- Habiba, U.; Hossain, E. Auction mechanisms for virtualization in 5G cellular networks: Basics, trends, and open challenges. IEEE Commun. Surv. Tutor. 2018, 20, 2264–2293. [Google Scholar] [CrossRef]
- Yang, Q.; Jang, S.-J.; Yoo, S.-J. Q-learning-based fuzzy logic for multi-objective routing algorithm in flying ad hoc networks. Wirel. Pers. Commun. 2020, 113, 115–138. [Google Scholar] [CrossRef]
- He, C.; Liu, S.; Han, S. A fuzzy logic reinforcement learning-based routing algorithm for flying ad hoc networks. In Proceedings of the IEEE International Conference on Computing, Networking and Communications (ICNC), Big Island, HI, USA, 17–20 February 2020; pp. 987–991. [Google Scholar]
- Bekmezci, I.; Sahingoz, O.K.; Temel, A. Flying ad-hoc networks (FANETs): A survey. Ad Hoc Netws. 2013, 11, 1254–1270. [Google Scholar] [CrossRef]
- Wang, H.; Haitao, Z.; Zhang, J.; Ma, D.; Li, J.; Wei, J. Survey on unmanned aerial vehicle networks: A cyber physical system perspective. IEEE Commun. Surv. Tutor. 2019, 22, 1027–1070. [Google Scholar] [CrossRef] [Green Version]
- Khan, M.F.; Yau, K.-L.A.; Noor, R.M.; Imran, M.A. Routing schemes in fanets: A survey. Sensors 2020, 20, 38. [Google Scholar] [CrossRef] [Green Version]
- Chaumette, S.; Laplace, R.; Mazel, C.; Mirault, R.; Dunand, A.; Lecoutre, Y.; Perbet, J.N. Carus, an operational retasking application for a swarm of autonomous UAVs: First return on experience. In Proceedings of the IEEE Military Communications Conference—Milcom, Baltimore, MD, USA, 7–10 November 2011; pp. 2003–2010. [Google Scholar]
- Quaritsch, M.; Kruggl, K.; Wischounig-Strucl, D.; Bhattacharya, S.; Shah, M.; Rinner, B. Networked UAVs as aerial sensor network for disaster management applications. Elektrotechnik Inf. 2010, 127, 56–63. [Google Scholar] [CrossRef]
- Alshbatat, A.I.; Alsafasfeh, Q. Cooperative decision making using a collection of autonomous quad rotor unmanned aerial vehicle interconnected by a wireless communication network. Glob. J. Technol. 2012, 1, 212–218. [Google Scholar]
- Arafat, M.Y.; Moh, S. Location-aided delay tolerant routing protocol in UAV networks for post-disaster operation. IEEE Access 2018, 6, 59891–59906. [Google Scholar] [CrossRef]
- Mekikis, P.V.; Antonopoulos, A.; Kartsakli, E.; Alonso, L.; Verikoukis, C. Communication recovery with emergency aerial networks. IEEE Trans. Consum. Electron. 2017, 63, 291–299. [Google Scholar] [CrossRef]
- Arafat, M.Y.; Moh, S. A survey on cluster-based routing protocols for unmanned aerial vehicle networks. IEEE Access 2018, 7, 498–516. [Google Scholar] [CrossRef]
- Arafat, M.Y.; Moh, S. Routing protocols for unmanned aerial vehicle networks: A survey. IEEE Access 2019, 7, 99694–99720. [Google Scholar] [CrossRef]
- Mkiramweni, M.; Yang, C.; Li, J.; Zhang, W. A survey of game theory in unmanned aerial vehicles communications. IEEE Commun. Surv. Tutor. 2019, 21, 3386–3416. [Google Scholar] [CrossRef]
- Liu, W.; Si, P.; Sun, E.; Li, M.; Fang, C.; Zhang, Y. Green mobility management in UAV-assisted IoT based on dueling DQN. In Proceedings of the IEEE International Conference on Communications (ICC), Shanghai, China, 20–24 May 2019; pp. 1–6. [Google Scholar]
- Xie, J.; Yu, F.; Huang, T.; Xie, R.; Liu, J.; Wang, C.; Liu, Y. A survey of machine learning techniques applied to software defined networking (SDN): Research issues and challenges. IEEE Commun. Surv. Tutor. 2018, 21, 393–430. [Google Scholar] [CrossRef]
- Arafat, M.Y.; Moh, S. Localization and clustering based on swarm intelligence in UAV networks for emergency communications. IEEE Internet Things J. 2019, 6, 8958–8976. [Google Scholar] [CrossRef]
- Arafat, M.Y.; Moh, S. Bio-inspired approaches for energy-efficient localization and clustering in UAV networks for monitoring wildfires in remote areas. IEEE Access 2021, 9, 18649–18669. [Google Scholar] [CrossRef]
- Arafat, M.Y.; Moh, S. A Q-Learning-Based Topology-Aware Routing Protocol for Flying Ad Hoc Networks. IEEE Internet Things J. 2021, 9, 1985–2000. [Google Scholar] [CrossRef]
- Ndiaye, M.; Hancke, G.; Abu-Mahfouz, A. Software defined networking for improved wireless sensor network management: A survey. Sensors 2017, 17, 1031. [Google Scholar] [CrossRef] [PubMed]
- Wei, X.; Yang, H.; Huang, W. A Genetic-Algorithm-Based Optimization Routing for FANETs. Front. Neurorobot. 2021, 15, 81. [Google Scholar] [CrossRef]
- Lee, S.W.; Ali, S.; Yousefpoor, M.S.; Yousefpoor, E.; Lalbakhsh, P.; Javaheri, D.; Rahmani, A.M.; Hosseinzadeh, M. An energy-aware and predictive fuzzy logic-based routing scheme in flying ad hoc networks (fanets). IEEE Access 2021, 9, 129977–130005. [Google Scholar] [CrossRef]
- da Costa, L.A.L.; Kunst, R.; de Freitas, E.P. Q-FANET: Improved Q-learning based routing protocol for FANETs. Comput. Netws. 2021, 198, 108379. [Google Scholar] [CrossRef]
- Hussain, A.; Hussain, T.; Faisal, F.; Ali, I.; Khalil, I.; Nazir, S.; Khan, H.U. DLSA: Delay and Link Stability Aware Routing Protocol for Flying Ad-hoc Networks (FANETs). Wirel. Pers. Commun. 2021, 121, 2609–2634. [Google Scholar] [CrossRef]
- Xing, W.; Huang, W.; Hua, Y. A Boltzmann Machine Optimizing Dynamic Routing for FANETs; Creative Commons: Mountain View, CA, USA, 2021. [Google Scholar]
- Rajoria, S.; Trivedi, A.; Godfrey, W.W. A comprehensive survey: Small cell meets massive MIMO. Phys. Commun. 2018, 26, 40–49. [Google Scholar] [CrossRef]
- Kreutz, D.; Ramos, F.M.; Verissimo, P.; Rothenberg, C.E.; Azodolmolky, S.; Uhlig, S. Software-defined networking: A comprehensive survey. Proc. IEEE 2015, 103, 14–76. [Google Scholar] [CrossRef] [Green Version]
- Ahmad, I.; Namal, S.; Ylianttila, M.; Gurtov, A. Security in software defined networks: A survey. IEEE Commun. Surv. Tutor. 2015, 17, 2317–2346. [Google Scholar] [CrossRef]
- Kobo, H.I.; Abu-Mahfouz, A.M.; Hancke, G.P. A survey on software-defined wireless sensor networks: Challenges and design requirements. IEEE Access 2017, 5, 1872–1899. [Google Scholar] [CrossRef]
- Bailis, P.; Ghodsi, A. Eventual consistency today: Limitations, extensions, and beyond. Queue 2013, 11, 20–33. [Google Scholar] [CrossRef] [Green Version]
- Mohammadi, M.; Al-Fuqaha, A.; Guizani, M.; Oh, J.-S. Semisupervised deep reinforcement learning in support of IoT and smart city services. IEEE Internet Things J. 2017, 5, 624–635. [Google Scholar] [CrossRef] [Green Version]
- Ye, J.; Zhang, C.; Lei, H.; Pan, G.; Ding, Z. Secure UAV-to-UAV systems with spatially random UAVs. IEEE Wirel. Commun. Lett. 2018, 8, 564–567. [Google Scholar] [CrossRef]
- Khan, A.; Aftab, F.; Zhang, Z. BICSF: Bio-inspired clustering scheme for FANETs. IEEE Access 2019, 7, 31446–31456. [Google Scholar] [CrossRef]
- Rasheed, F.; Yau, K.-L.A.; Low, Y.-C. Deep reinforcement learning for traffic signal control under disturbances: A case study on Sunway City, Malaysia. Future Gener. Comput. Syst. 2020, 109, 431–445. [Google Scholar] [CrossRef]
- Sharma, J.; Andersen, P.-A.; Granmo, O.-C.; Goodwin, M. Deep q-learning with q-matrix transfer learning for novel fire evacuation environment. IEEE Trans. Syst. Man Cybern. Syst. 2020, 51, 7363–7381. [Google Scholar] [CrossRef] [Green Version]
- Hussain, F.; Hussain, R.; Anpalagan, A.; Benslimane, A. A new block-based reinforcement learning approach for distributed resource allocation in clustered IoT networks. IEEE Trans. Veh. Technol. 2020, 69, 2891–2904. [Google Scholar] [CrossRef]
- Fu, S.; Yang, F.; Xiao, Y. AI inspired intelligent resource management in future wireless network. IEEE Access 2020, 8, 425–433. [Google Scholar] [CrossRef]
- Atienza, R. Advanced Deep Learning with TensorFlow 2 and Keras: Apply DL, GANs, VAEs, Deep RL, Unsupervised Learning, Object Detection and Segmentation, and More; Packt Publishing Ltd.: Birmingham, UK, 2020. [Google Scholar]
- Menczer, F.; Fortunato, S.; Davis, C.A. A First Course in Network Science; Cambridge University Press: Cambridge, UK, 2020. [Google Scholar]
- Ali, H.; Shahzad, W.; Khan, F.A. Energy-efficient clustering in mobile ad-hoc networks using multi-objective particle swarm optimization. Appl. Soft Comput. 2012, 12, 1913–1928. [Google Scholar] [CrossRef]
- Xie, J.; Wan, Y.; Kim, J.H.; Fu, S.; Namuduri, K. A survey and analysis of mobility models for airborne networks. IEEE Commun. Surv. Tutor. 2014, 16, 1221–1238. [Google Scholar] [CrossRef]
- Khan, M.F.; Yau, K.L.A. Route Selection in 5G-based Flying Ad-hoc Networks using Reinforcement Learning. In Proceedings of the 10th IEEE International Conference on Control System, Computing and Engineering (ICCSCE), Penang, Malaysia, 21–22 August 2020; pp. 23–28. [Google Scholar]
- Aadil, F.; Raza, A.; Khan, M.F.; Maqsood, M.; Mehmood, I.; Rho, S. Energy aware cluster-based routing in flying ad-hoc networks. Sensors 2018, 18, 1413. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Khelifi, F.; Bradai, A.; Singh, K.; Atri, M. Localization and energy efficient data routing for unmanned aerial vehicles: Fuzzy-logic-based approach. IEEE Commun. Mag. 2018, 56, 129–133. [Google Scholar] [CrossRef]
- Sirmollo, C.Z.; Bitew, M.A. Mobility-Aware Routing Algorithm for Mobile Ad Hoc Networks. Wirel. Commun. Mob. Comput. 2021, 2021, 12. [Google Scholar] [CrossRef]
- Mazloomi, N.; Gholipour, M.; Zaretalab, A. Efficient configuration for multi-objective QoS optimization in wireless sensor network. Ad Hoc Netws. 2022, 125, 102730. [Google Scholar] [CrossRef]
- Hussein, W.A.; Ali, B.M.; Rasid, M.F.A.; Hashim, F. Smart geographical routing protocol achieving high QoS and energy efficiency based for wireless multimedia sensor networks. Egypt. Inf. J. 2022, in press. [Google Scholar] [CrossRef]
- Ling, M.H.; Yau, K.-L.A.; Qadir, J.; Ni, Q. A reinforcement learning-based trust model for cluster size adjustment scheme in distributed cognitive radio networks. IEEE Trans. Cogn. Commun. Netw. 2018, 5, 28–43. [Google Scholar] [CrossRef] [Green Version]
- Musavi, M.; Yau, K.-L.A.; Syed, A.R.; Mohamad, H.; Ramli, N. Route selection over clustered cognitive radio networks: An experimental evaluation. Comput. Commun. 2018, 129, 138–151. [Google Scholar] [CrossRef]
- Saleem, Y.; Yau, K.-L.A.; Mohamad, H.; Ramli, N.; Rehmani, M.H. Smart: A spectrum-aware cluster-based routing scheme for distributed cognitive radio networks. Comput. Netws. 2015, 91, 196–224. [Google Scholar] [CrossRef] [Green Version]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef]
- Qiu, C.; Hu, Y.; Chen, Y.; Zeng, B. Deep deterministic policy gradient (DDPG)-based energy harvesting wireless communications. IEEE Internet Things J. 2019, 6, 8577–8588. [Google Scholar] [CrossRef]
- Sewak, M. Deep q network DQN, double DQN, and dueling DQN. In Deep Reinforcement Learning; Springer: Singapore, 2019; pp. 95–108. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notation | Description |
|---|---|
| Node . | |
| Direction of node where, . | |
| Velocity of node where, . | |
| T | Transmission range. |
| Data lifetime. | |
| Data lifetime threshold. | |
| Coordinates of node in three dimensions, where . | |
| t | Time |
| Distance between two nodes and , where i, . |
| Notation | Description |
|---|---|
| i | Number of agents, where , N. |
| State of an agent i at time t. | |
| Mobility of an agent i at time t. | |
| Residual energy of an agent i at time t. | |
| Residual energy of an agent. | |
| Action of an agent i at time t. | |
| A | Set of possible actions. |
| Action (i.e., a selected next-hop node ) taken based on mobility m and residual energy . | |
| Delayed reward received by an agent i at time t. | |
| State-action pair or Output Q-value. | |
| Policy for the selection of state-action pair Q-value . | |
| Memory for storing the experiences used for training deep neural network. | |
| experiences stored in reply memory . | |
| Learning rate. | |
| Discount factor. | |
| Exploration rate. | |
| Maximum exploration rate. | |
| Minimum exploration rate. | |
| Decaying variable of exploration. from maximum exploration rate to minimum exploration rate . | |
| Desired target function. | |
| Network parameters of the main network. | |
| Network parameters of the target network. | |
| Gradient descent based on a loss function for network parameters . |
| Terminologies | Abbreviations | Functions |
|---|---|---|
| Unmanned aerial vehicle | UAV | UAVs are autonomous, small-sized, lightweight flying nodes moving at high speed at low or high altitudes in a three-dimensional space. |
| Central controller | CC | CC makes decisions and manages global tasks (i.e., vertical routing). |
| Distributed controller | DC | DC makes decisions and manages local tasks (e.g., vertical clustering) in a particular network plane. |
| Cluster head | CH | CH, which serves as the cluster leader, manages and handles cluster-level operations (e.g., routing), and performs intra- and inter-cluster communications. |
| Cluster member | CM | CM, which is associated with a CH, performs intra-cluster communication. |
| Cluster gateway | CG | CG, which is associated with a CH, interacts with neighboring clusters through inter-cluster communication. |
| Vertical cluster gateway | VCG | VCG enables interactions among UAVs in different clusters across different network planes, which is conveniently known as inter-plane communication. |
| Section | Detail |
|---|---|
| Introduction | Section 1 presents the introduction of FANETs, 5G access network, and the structure of vertical clustering in 5G-based FANET. Furthermore, this section contains the distinguishing aspects of our research, contributions, and organizational structure of paper. |
| Network Architecture | Section 2 presents the discussion about core elements of 5G access network (i.e., network planes and controllers). It also presents the discussion on the hybrid framework, functions of controllers, and advantages. It defines the categories of data based on their lifetime, and the significance of fresh data. |
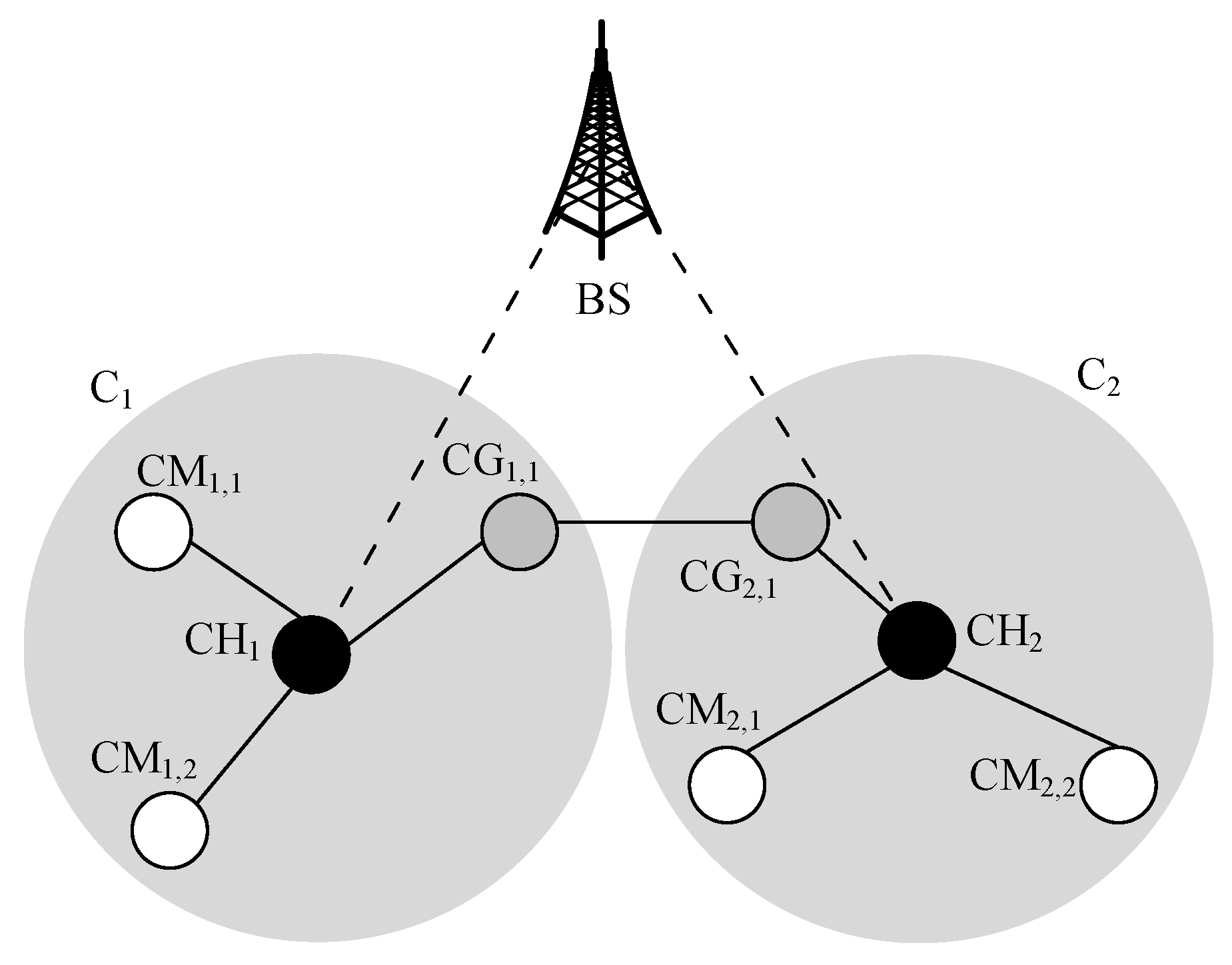
| System Model and Functions | Section 3 presents the traditional clustering approach, routing mechanism, and cluster maintenance. It presents a detailed discussion of vertical routing based on a use case scenario as shown in Figure 1. Furthermore, it presents DQN-based vertical routing, the three main components of DQN, and the DQN algorithm as shown in Algorithm 1. It also presents the discussion and algorithm of reinforcement learning as shown in Algorithm 2. |
| Performance Evaluation, Results and Discussion | Section 4 presents a detailed discussion of the implementation of research, baseline approaches, ranges of important parameters, energy models, the selection of various performance measures, the analysis of RL and DQN approaches based on learning rate, the convergence of proposed schemes, and a comprehensive discussion of simulation results. Furthermore, it presents a complexity analysis including its parameters. |
| Conclusion and Future Work | Section 5 presents the significant research outcomes and the future research direction. |
| Network Plane | Characteristics | ||
|---|---|---|---|
| Node Density (Percentage of UAVs) | Node Mobility (Meters per Second) | Transmission Range (Meters) | |
| Macrocell | 45% | 66.7–100 | 10–500 |
| Picocell | 35% | 33.4–66.6 | 10–300 |
| Femtocell | 20% | 0–33.3 | 10–100 |
| Parameters | RL | DQN |
|---|---|---|
| Batch size | - | 32 |
| Episodes z | 1001 | 1001 |
| Transmission Range (m) | 500 | 500 |
| Grid size (km) | 1 | 1 |
| Energy for transmission () | 2 | 2 |
| Energy for reception () | 1 | 1 |
| Speed (m/s) | 10–100 | 10–100 |
| Network density | 100–1000 | 100–1000 |
| Replay memory size | - | 2000 |
| Discount factor | 0.95 | 0.95 |
| Learning rate | 0.1–1.0 | 0.0001–0.001 |
| Exploration rate | 1.0 | 1.0 |
| Minimum exploration rate | - | 0.001 |
| Maximum exploration rate | - | 1.0 |
| Decaying variable | - | 0.995 |
| Data lifetime threshold | z | z |
| Parameter | Description |
|---|---|
| Number of states. | |
| Number of actions for each state. | |
| Number of rewards for each state-action pair . | |
| Number of agents in a network. | |
| Number of neighboring agents of an agent in a network. | |
| Training complexity. | |
| Hidden layer complexity. |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Khan, M.F.; Yau, K.-L.A.; Ling, M.H.; Imran, M.A.; Chong, Y.-W. An Intelligent Cluster-Based Routing Scheme in 5G Flying Ad Hoc Networks. Appl. Sci. 2022, 12, 3665. https://doi.org/10.3390/app12073665
Khan MF, Yau K-LA, Ling MH, Imran MA, Chong Y-W. An Intelligent Cluster-Based Routing Scheme in 5G Flying Ad Hoc Networks. Applied Sciences. 2022; 12(7):3665. https://doi.org/10.3390/app12073665
Chicago/Turabian StyleKhan, Muhammad Fahad, Kok-Lim Alvin Yau, Mee Hong Ling, Muhammad Ali Imran, and Yung-Wey Chong. 2022. "An Intelligent Cluster-Based Routing Scheme in 5G Flying Ad Hoc Networks" Applied Sciences 12, no. 7: 3665. https://doi.org/10.3390/app12073665
APA StyleKhan, M. F., Yau, K.-L. A., Ling, M. H., Imran, M. A., & Chong, Y.-W. (2022). An Intelligent Cluster-Based Routing Scheme in 5G Flying Ad Hoc Networks. Applied Sciences, 12(7), 3665. https://doi.org/10.3390/app12073665