
PIFNet: 3D Object Detection Using Joint Image and Point Cloud Features for Autonomous Driving



Abstract
:1. Introduction
- We designed a new 3D object detection method, PIFNet, by using the fusion of LiDAR and camera sensors. To compensate for the sparsity and the irregularity of point clouds for far objects, camera images can provide rich fine-grained information. The point cloud features and image features are fused to take advantage of the complementary characteristics of these two sensors.
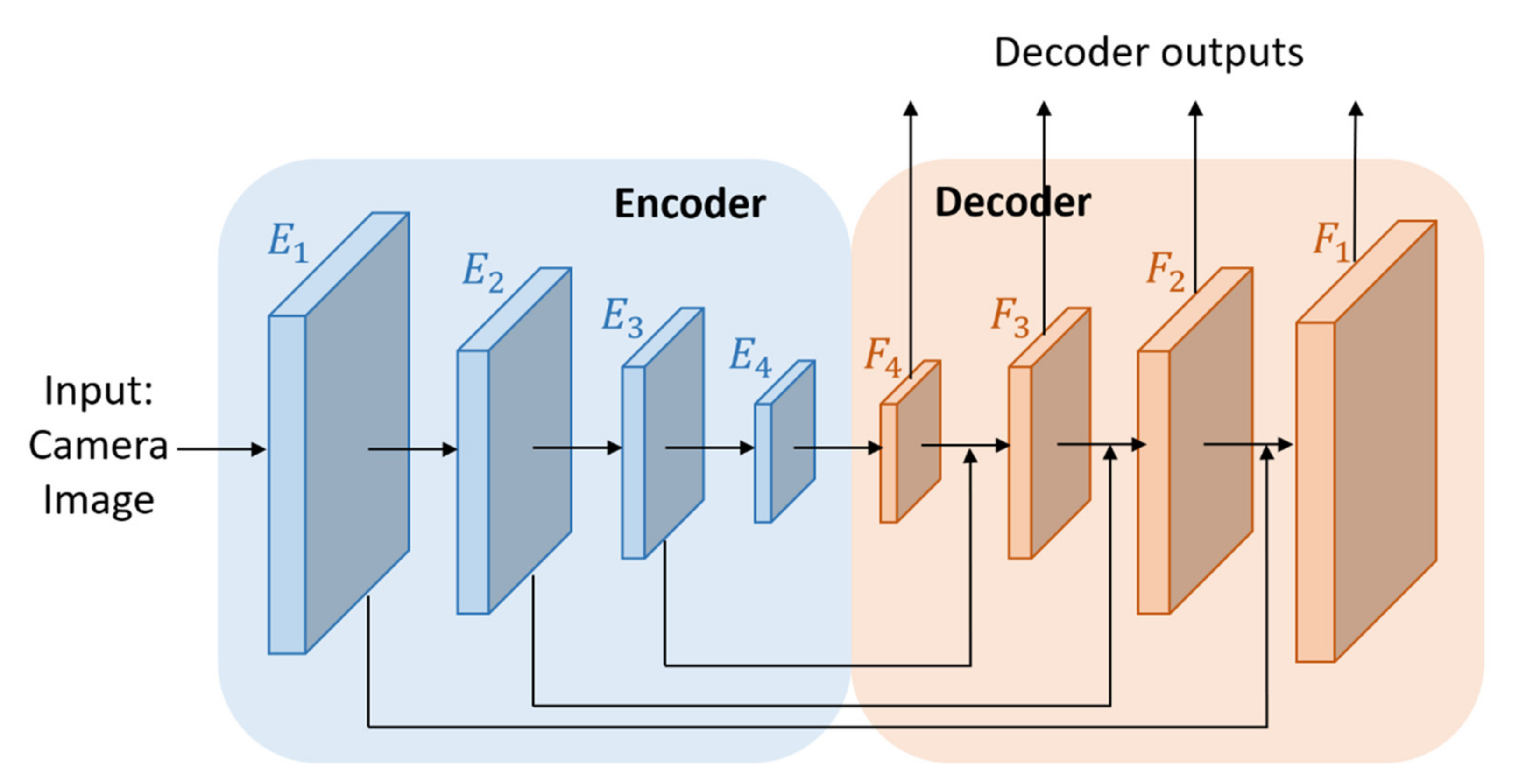
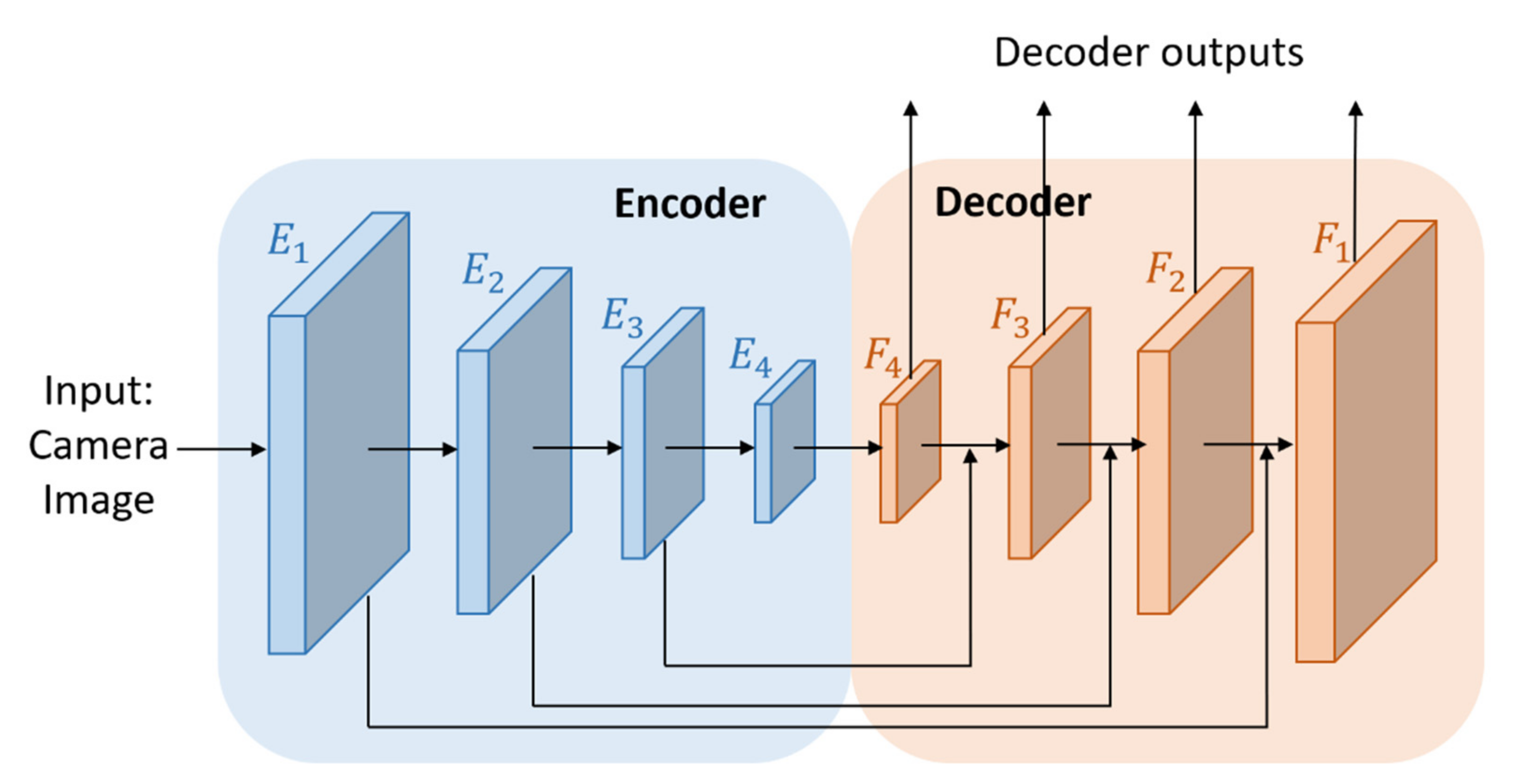
- We developed an Encoder-Decoder Fusion (EDF) network to effectively extract image features. To obtain the multi-scale feature maps, we used multiple-level feature maps. The low-level feature maps have high resolution but poor semantic information whereas the high-level feature maps have low resolution but dense semantic information. By using this EDF module, we can obtain accurate localization information from low-level feature maps and useful semantic classification information from high-level feature maps.
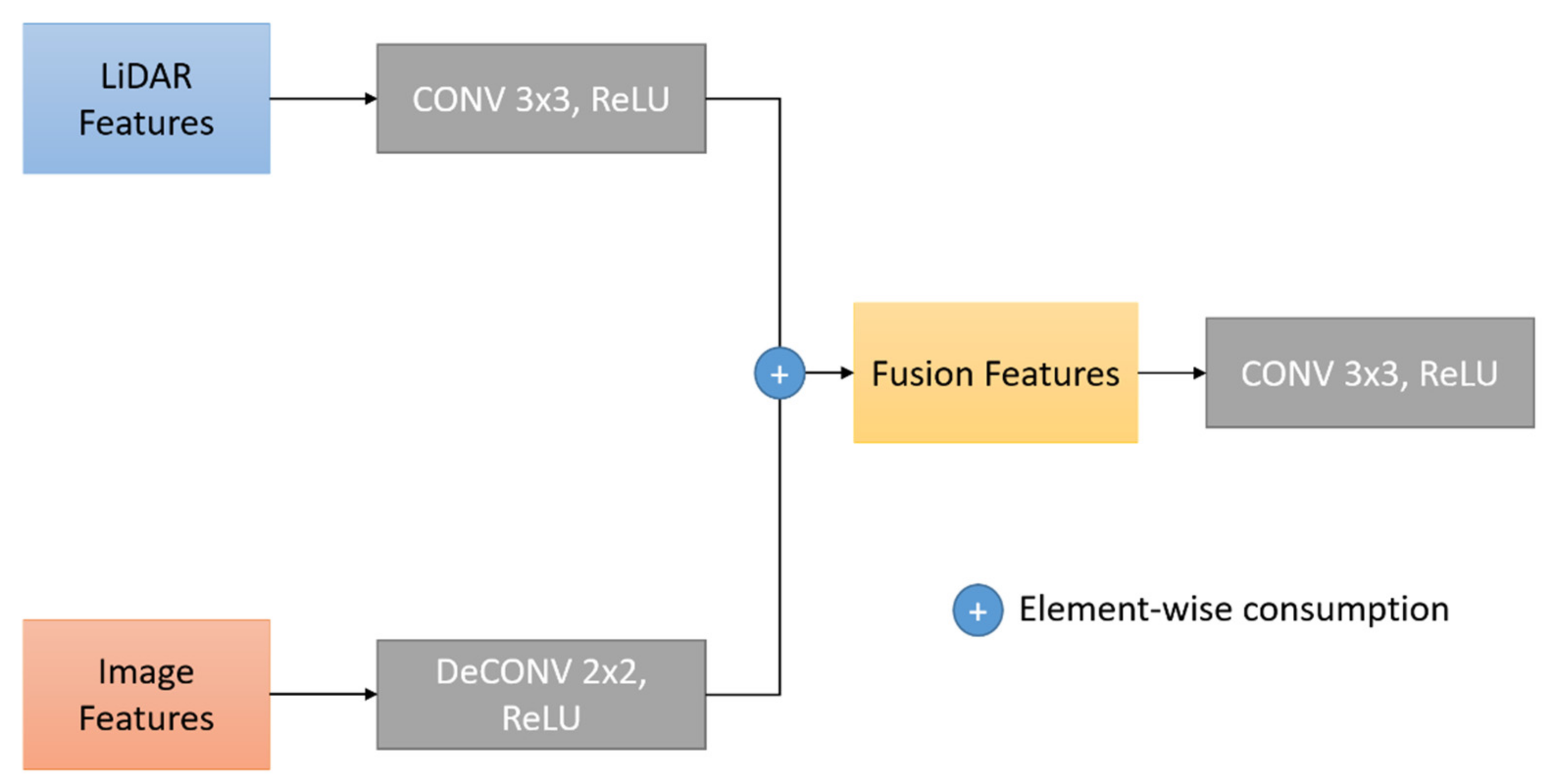
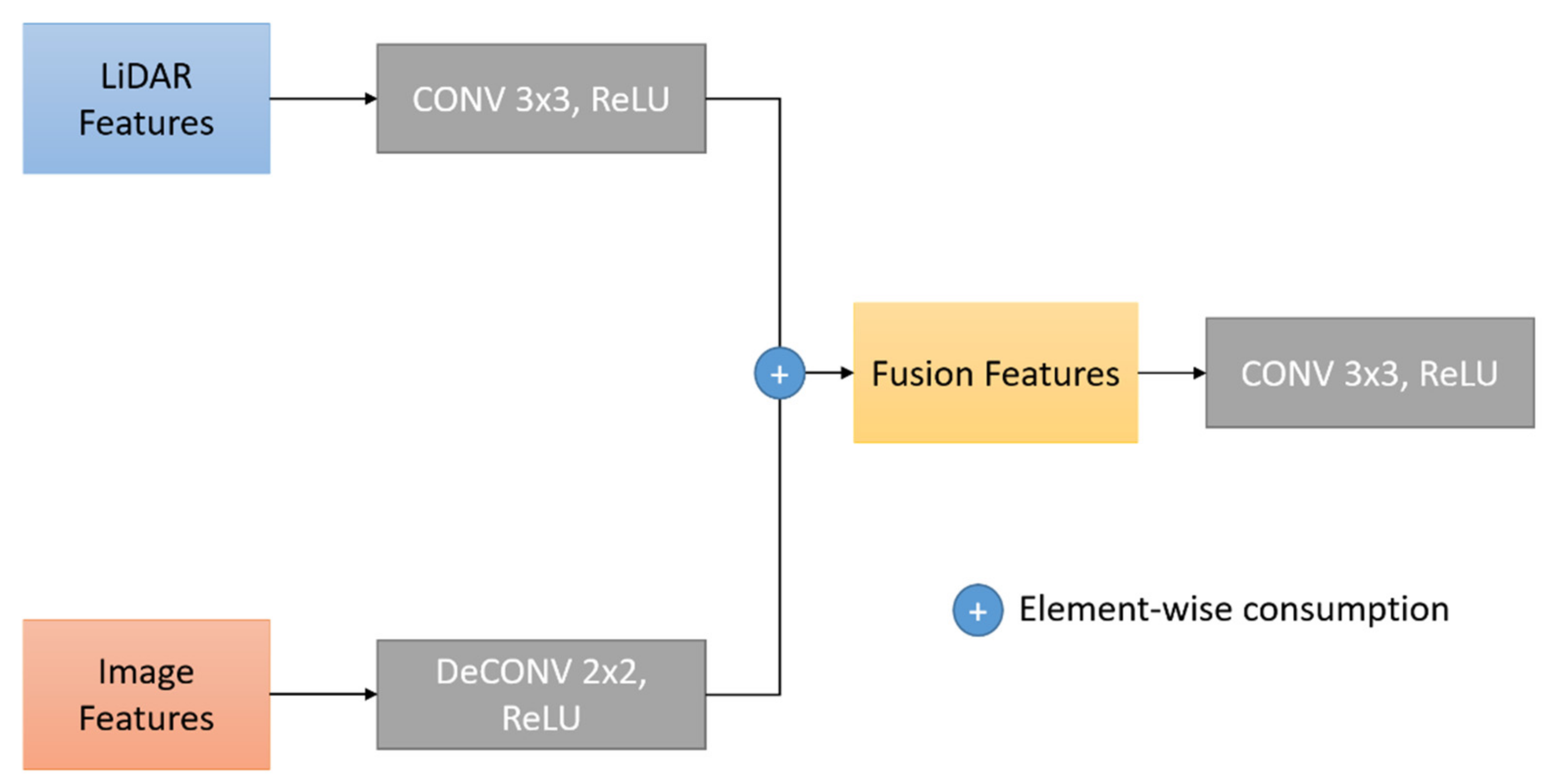
- A fusion module is proposed to integrate the color and texture features from images and the depth information from point clouds. Each intermediate feature map is fed into the fusion module to integrate with its corresponding point-wise features. This module can cope with the irregularity and sparsity of the point cloud features by capitalizing the fine-grained information extracted from images by the EDF module.
- The experiments using our method and several other state-of-the-art methods show that our proposed neural network architecture can produce the best results on average. In particular, on the KITTI dataset, PIFNet achieved 85.16% mAP (the best results) in 3D object detection and 90.96% mAP (second best results) in BEV detection.
2. Related Works
2.1. 3D Object Detection Based on Camera Images
2.2. 3D Object Detection Based on LiDAR
2.3. 3D Object Detection Based on the Fusion of Camera Images and LiDAR Point Clouds
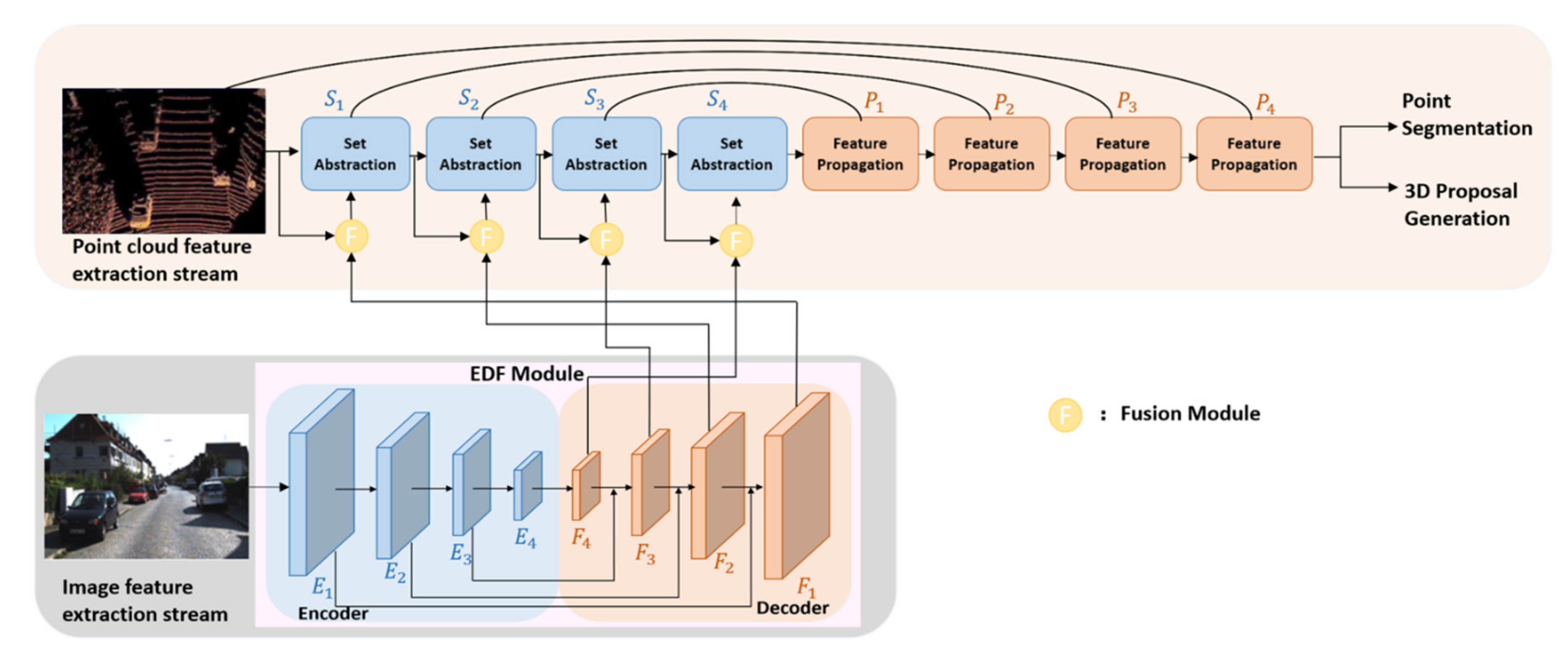
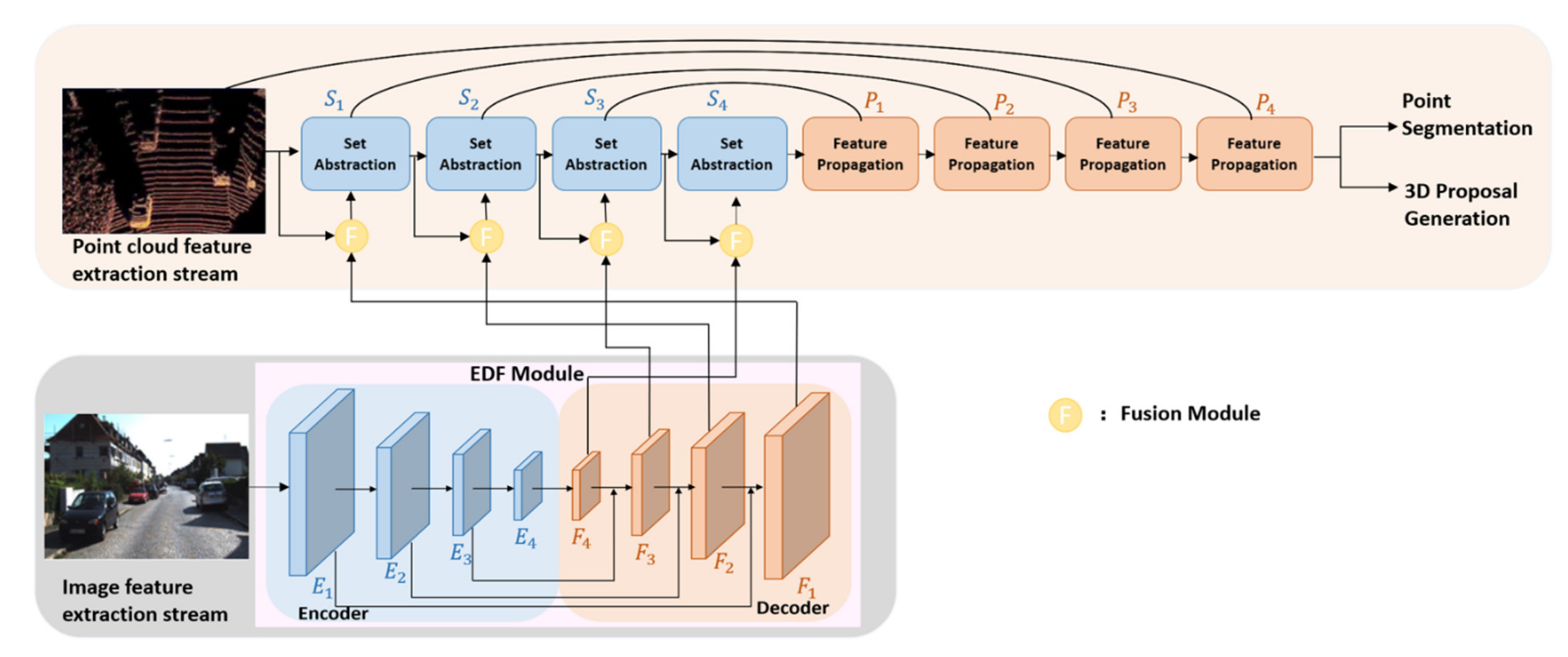
3. Proposed Point-Image Fusion Network (PIFNet)
3.1. Two Stream Network Architecture
3.1.1. Image Feature Extraction Stream
3.1.2. Point Cloud Feature Extraction Stream
3.2. Fusion Module
3.3. Training Loss
4. Experimental Results
4.1. Datasets and Processing Platform
4.2. Implementation Details
4.3. Experiments on KITTI Dataset
4.4. Ablation Study
4.5. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Shuran, S.; Jianxiong, X. Sliding Shapes for 3D object detection in depth images. In Proceedings of the European Conference on Computer Vision—ECCV, Zurich, Switzerland, 5–12 September 2014. [Google Scholar]
- Dominic, Z.W.; Ingmar, P. Voting for voting in online point cloud object detection. In Proceedings of the Robotics: Science and Systems XI, Rome, Italy, 13–17 July 2015. [Google Scholar]
- Feng, G.; Caihong, L.; Bowen, Z. A dynamic clustering algorithm for Lidar obstacle detection of autonomous driving system. IEEE Sens. 2021, 21, 25922–25930. [Google Scholar]
- Shuran, S.; Jianxiong, X. Deep sliding shapes for amodal 3D object detection in RGB-D. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016. [Google Scholar]
- Yang, Z.; Sun, Y.; Liu, S.; Shen, X.; Jia, J. Ipod: Intensive point-based object detector for point cloud. arXiv 2018, arXiv:1812.05276. [Google Scholar]
- Shi, S.; Guo, C.; Jiang, L.; Wang, Z.; Shi, J.; Wang, X.; Li, H. PV-RCNN: Point-voxel feature set abstraction for 3d object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10529–10538. [Google Scholar]
- Shi, S.; Jiang, L.; Deng, J.; Wang, Z.; Guo, C.; Shi, J.; Wang, X.; Li, H. PV-RCNN++: Point-Voxel Feature Set Abstraction With Local Vector Representation for 3D Object Detection. arXiv 2021, arXiv:2102.00463. [Google Scholar]
- Jiajun, D.; Shaoshuai, S.; Peiwei, L.; Wengang, Z.; Yanyong, Z.; Houqiang, L. Voxel R-CNN: Towards high performance voxel-based 3d object detection. arXiv 2020, arXiv:2012.15712. [Google Scholar]
- Wang, Z.; Jia, K. Frustum convnet: Sliding frustums to aggregate local point-wise features for amodal 3d object detection. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Macau, China, 3–8 November 2019; pp. 1742–1749. [Google Scholar]
- Qi, C.R.; Hao, S.; Kaichun, M.; Mo, K.; Guibas, L.J. Pointnet: Deep learning on point sets for 3D classification and segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Qi, C.R.; Yi, L.; Su, H.; Guibas, L.J. Pointnet++: Deep hierarchical feature learning on point sets in a metric space. arXiv 2017, arXiv:1706.02413. [Google Scholar]
- Runzhou, G.; Zhuangzhuang, D.; Yihan, H.; Yu, W.; Sijia, C.; Li, H.; Yuan, L. Afdet: Anchor free one stage 3d object detection. arXiv 2020, arXiv:2006.12671. [Google Scholar]
- Chenhang, H.; Hui, Z.; Jianqiang, H.; Xian-Sheng, H.; Lei, Z. Structure aware single-stage 3d object detection from point cloud. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11873–11882. [Google Scholar]
- Shi, S.; Wang, X.; Li, H. Pointrcnn: 3d object proposal generation and detection from point cloud. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 770–779. [Google Scholar]
- Yang, Z.; Sun, Y.; Liu, S.; Shen, X.; Jia, J. Std: Sparse-to-dense 3d object detector for point cloud. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 1951–1960. [Google Scholar]
- Yan, Y.; Mao, Y.; Li, B. Second: Sparsely embedded convolutional detection. Sensors 2018, 18, 3337. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wang, Y.; Fathi, A.; Kundu, A.; Ross, D.A.; Pantofaru, C.; Funkhouser, T.; Solomon, J. Pillar-based object detection for autonomous driving. In Proceedings of the 16th European Conference of Computer Vision–ECCV, Glasgow, UK, 23–28 August 2020; pp. 18–34. [Google Scholar]
- Shi, S.; Wang, Z.; Wang, X.; Li, H. Part-A2 net: 3d part-aware and aggregation neural network for object detection from point cloud. arXiv 2019, arXiv:1907.03670. [Google Scholar]
- Barrera, A.; Guindel, C.; Beltrán, J.; García, F. BirdNet+: End-to-end 3D object detection in LiDAR Bird’s Eye View. In Proceedings of the IEEE 23rd International Conference on Intelligent Transportation Systems (ITSC), Rhodes, Greece, 20–23 September 2020. [Google Scholar]
- Chen, X.; Kundu, K.; Zhang, Z.; Ma, H.; Fidler, S.; Urtasun, R. Monocular 3d object detection for autonomous driving. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016. [Google Scholar]
- Bin, X.; Zhenzhong, C. Multi-level fusion based 3d object detection from monocular images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Chen, X.; Kundu, K.; Zhu, Y.; Ma, H.; Fidler, S.; Urtasun, R. 3d object proposals using stereo imagery for accurate object class detection. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 1259–1272. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Peiliang, L.; Xiaozhi, C.; Shaojie, S. Stereo R-CNN based 3D Object Detection for Autonomous Driving. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Liang, M.; Yang, B.; Chen, Y.; Hu, R.; Urtasun, R. Multi-task multi-sensor fusion for 3d object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 7345–7353. [Google Scholar]
- Liang, M.; Yang, B.; Wang, S.; Urtasun, R. Deep continuous fusion for multi-sensor 3d object detection. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 641–656. [Google Scholar]
- Ku, J.; Mozifian, M.; Lee, J.; Harakeh, A.; Waslander, S.L. Joint 3d proposal generation and object detection from view aggregation. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 1–8. [Google Scholar]
- Huang, T.; Liu, Z.; Chen, X.; Bai, X. Epnet: Enhancing point features with image semantics for 3D object detection. In Proceedings of the European Conference on Computer Vision—ECCV, Glasgow, UK, 23–28 August 2020; pp. 35–52. [Google Scholar]
- Pang, S.; Morris, D.; Radha, H. CLOCs: Camera-LiDAR object candidates fusion for 3D object detection. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NV, USA, 24 Octomber–24 January 2020; pp. 10386–10393. [Google Scholar]
- Yoo, J.H.; Kim, Y.; Kim, J.; Choi, J.W. 3D-CVF: Generating joint camera and lidar features using cross-view spatial feature fusion for 3d object detection. In Proceedings of the 16th European Conference of Computer Vision–ECCV, Glasgow, UK, 23–28 August 2020; pp. 720–736. [Google Scholar]
- Charles, R.Q.; Wei, L.; Chenxia, W.; Hao, S.; Leonidas, J.G. Frustum PointNets for 3D Object Detection from RGB-D Data. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 918–927. [Google Scholar]
- Chen, X.; Ma, H.; Wan, J.; Li, B.; Xia, T. Multi-view 3d object detection network for autonomous driving. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Meyer, G.P.; Charland, J.; Hegde, D.; Laddha, A.; Vallespi-Gonzalez, C. Sensor fusion for joint 3D object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015. [Google Scholar]
- Geiger, A.; Lenz, P.; Urtasun, R. Are we ready for autonomous driving? The KITTI vision benchmark suite. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 16–21 June 2012. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
| Method | Modality | 3D Detection | BEV Detection | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Easy | Mod. | Hard | mAP | Easy | Mod. | Hard | mAP | ||
| Point RCNN | L | 86.96 | 75.64 | 70.70 | 77.77 | 92.13 | 87.39 | 82.72 | 87.41 |
| Fast Point R-CNN | L | 85.29 | 77.40 | 70.24 | 77.76 | 90.87 | 87.84 | 80.52 | 86.41 |
| PV-RCNN | L | 90.25 | 81.43 | 76.82 | 82.83 | 94.98 | 90.65 | 86.14 | 90.59 |
| Voxel RCNN | L | 90.90 | 81.62 | 77.06 | 83.19 | - | - | - | - |
| MV3D | L + R | 74.97 | 63.63 | 54.00 | 64.20 | 86.62 | 78.93 | 69.80 | 78.45 |
| F-Point Net | L + R | 82.19 | 69.79 | 60.59 | 70.85 | 91.17 | 84.67 | 74.77 | 83.54 |
| MMF | L + R | 88.40 | 77.43 | 70.22 | 78.68 | 93.67 | 88.21 | 91.99 | 91.29 |
| EPNet | L + R | 89.81 | 79.28 | 74.59 | 81.22 | 94.22 | 88.47 | 83.69 | 88.79 |
| PIFNet (Ours) | L + R | 92.53 | 83.03 | 79.92 | 85.16 | 95.89 | 89.08 | 87.91 | 90.96 |
| Methods | Running Time (s/frame) |
|---|---|
| MV3D | 0.36 |
| F-Point Net | 0.17 |
| MMF | 0.08 |
| PIFNet (Ours) | 0.21 |
| Method | Modality | 3D Detection | BEV Detection | ||||
|---|---|---|---|---|---|---|---|
| Easy | Mod. | Hard | Easy | Mod. | Hard | ||
| PIFNet + Fusion | L + R | 89.22 | 81.79 | 79.15 | 91.73 | 87.41 | 87.00 |
| PIFNet + EDF | L + R | 91.45 | 82.28 | 79.46 | 93.01 | 87.96 | 87.13 |
| PIFNet + Fusion + EDF | L + R | 92.53 | 83.03 | 79.92 | 95.89 | 89.08 | 87.91 |
| #Fusion Modules | 3D Detection mAP | Training Time (Hour) |
|---|---|---|
| 3 | 83.43 | 51 |
| 4 | 85.16 | 73 |
| 5 | 85.21 | 116 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zheng, W.; Xie, H.; Chen, Y.; Roh, J.; Shin, H. PIFNet: 3D Object Detection Using Joint Image and Point Cloud Features for Autonomous Driving. Appl. Sci. 2022, 12, 3686. https://doi.org/10.3390/app12073686
Zheng W, Xie H, Chen Y, Roh J, Shin H. PIFNet: 3D Object Detection Using Joint Image and Point Cloud Features for Autonomous Driving. Applied Sciences. 2022; 12(7):3686. https://doi.org/10.3390/app12073686
Chicago/Turabian StyleZheng, Wenqi, Han Xie, Yunfan Chen, Jeongjin Roh, and Hyunchul Shin. 2022. "PIFNet: 3D Object Detection Using Joint Image and Point Cloud Features for Autonomous Driving" Applied Sciences 12, no. 7: 3686. https://doi.org/10.3390/app12073686
APA StyleZheng, W., Xie, H., Chen, Y., Roh, J., & Shin, H. (2022). PIFNet: 3D Object Detection Using Joint Image and Point Cloud Features for Autonomous Driving. Applied Sciences, 12(7), 3686. https://doi.org/10.3390/app12073686