
FLaMAS: Federated Learning Based on a SPADE MAS



Abstract
:1. Introduction
2. Related Work
3. Multi-Agent Learning Based on Federated Learning
3.1. SPADE
3.2. FLaMAS
- Client Role: its main goal is to receive the input data from the device where it is embedded, train the model and send it to the agent playing the Server role.
- Server Role: Its main function is to be in charge of receiving at each iteration the different trained models of the agents playing the Client role in the system. The agent playing the Server role takes the average of all those models and this new unified model is sent to the different agents playing the Client role.
3.3. Agent Interaction Model
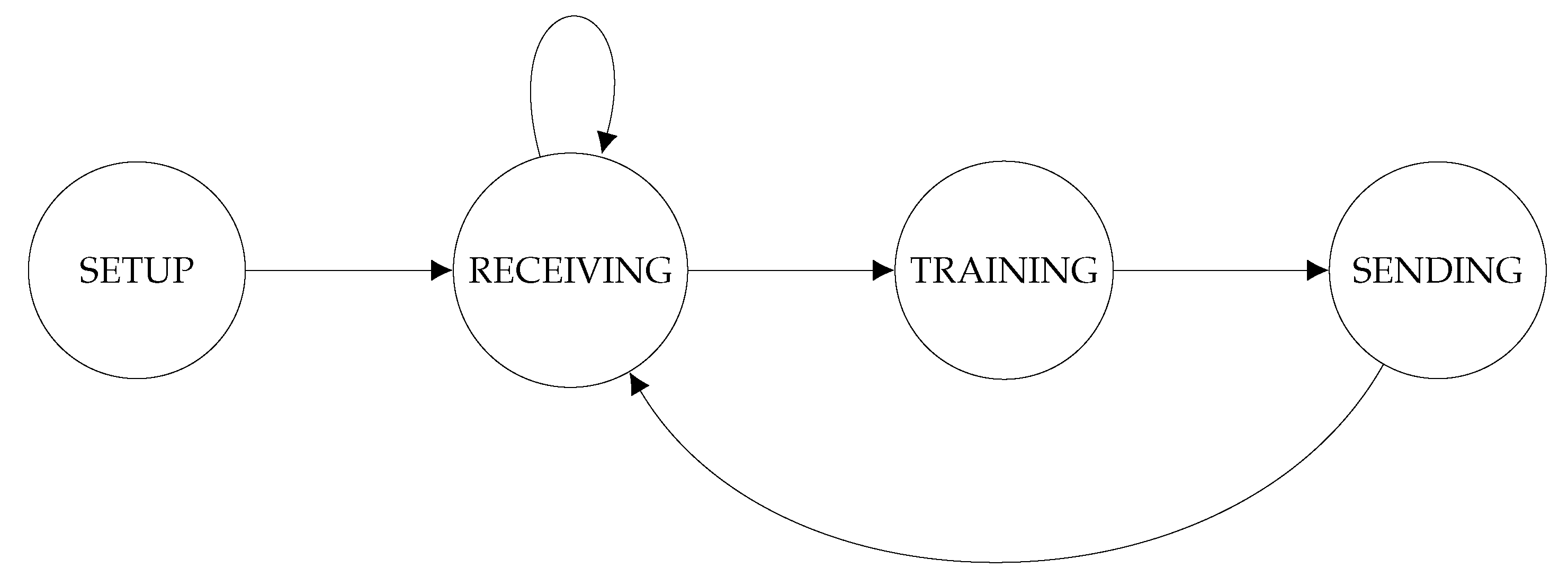
3.3.1. Normal Execution Cycle
- 1.
- SETUP STATE: In this state the agent configures parameters, such as “agent name”, “XMPP Server IP”, “name of the database to train”, and any other configuration parameters required by the developer.
- 2.
- TRAIN STATE: In this state, if the agent is playing the Client role, the training of the deep learning model is performed, and the weights and the losses parameters of the model are extracted. If the agent is playing the Server role, it calculates the average of the weights of the different models received from the Client agents. These weights are then used by the next state.
- 3.
- SEND STATE: This state is responsible for encapsulating the different weights (weights and losses), using the XMPP message structure, and sending them. If the agent is playing a Client role, they will be sent to the Server agent, otherwise, the Server agent will send them to the agents playing the Client role.
- 4.
- RECEIVE STATE: If the agent is playing the Client role, this state receives the message coming from the Server agent, which has the new weights. This same state is in charge of introducing these new weights into the model that is being trained. On the other hand, if the agent is playing the Server role, in this state it has to wait for all the agents playing the Client role, until the Presence state indicates they are active.
- 1.
- The Server agent uses the presence of all the Client agents to wait for the model trained by all the active Client agents.
- 2.
- Each active Client agent trains its model.
- 3.
- Each active Client agent sends its trained model to the Server agent.
- 4.
- After receiving all the trained models of the active Client agents, the Server agent calculates the average of all the models.
- 5.
- The Server agent sends the average model to each active Client agent.
- 6.
- Each active Client agent deploys the average model received.
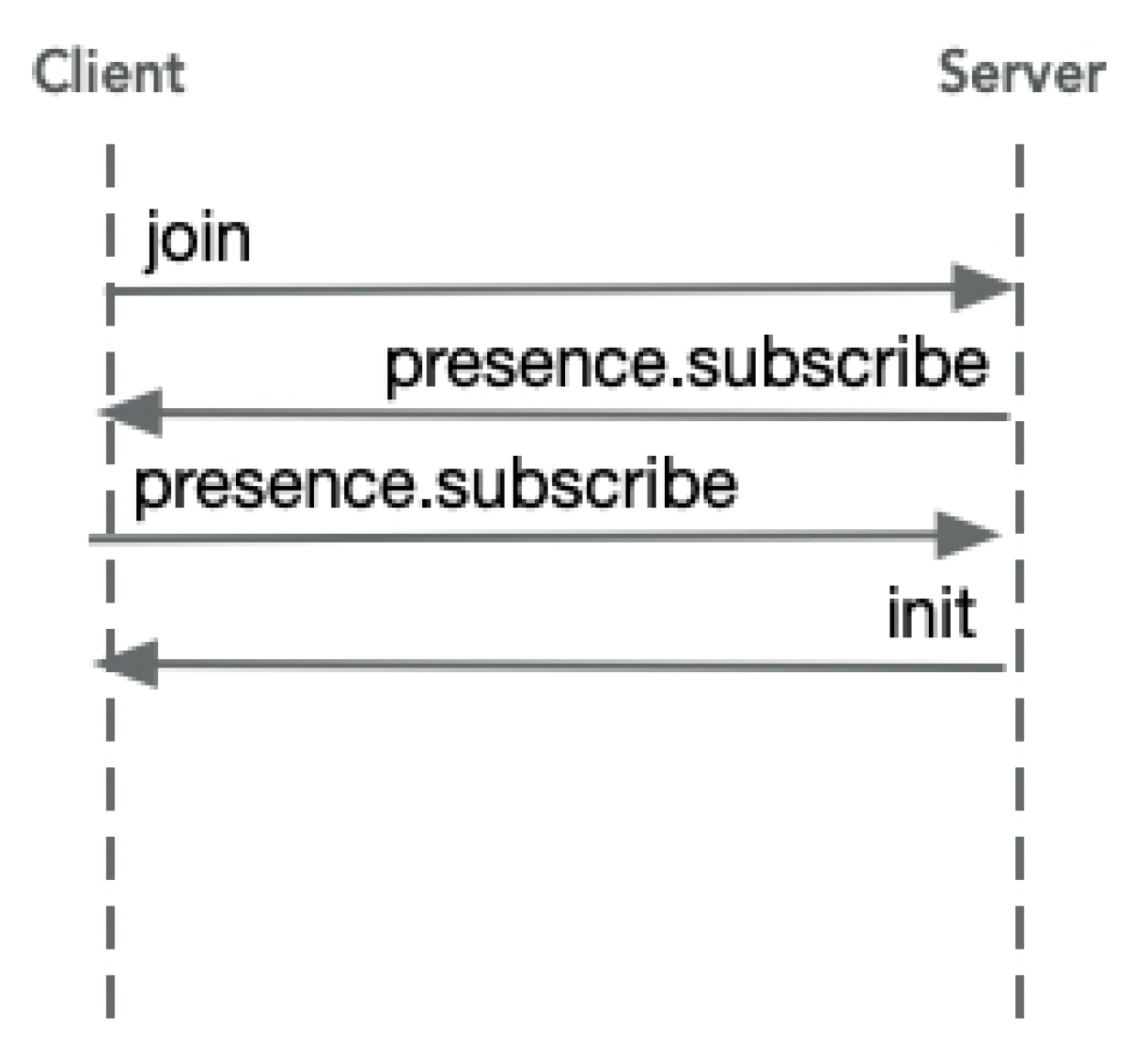
3.3.2. New Agent Entering the System
- 1.
- The new agent sends a message to the agent playing the Server role indicating that it wants to join the system as another Client.
- 2.
- The agent playing the Server role will subscribe to the Presence of the new Client agent.
- 3.
- When the Server agent receive the confirmation of the new agent Presence subscription, it will add it to its clients list for the normal execution cycle.
- 4.
- The Server agent will send the init message with the parameters needed to initialize the model in the Client agent.As the Server agent receives this message, it will begin the other protocol commented above (normal execution cycle) in both agents.
- 1.
- All Client agents that are active in the system (so their Presence would indicate it), will get input data from the environment.
- 2.
- All active Client agents will train their local models.
- 3.
- If the Server agent is active (indicated by its Presence), all active Client agents will send their trained local model parameters to the Server agent.
- 4.
- The Server agent calculates a de-aggregated global model.
- 5.
- The new global model is sent by the Server agent to the active Client agents, which put it in their systems as the new local model.
4. Experiments
- Input Size: 784 (28 × 28 = 784).
- Hidden Size: 600
- Batch size: 128
- N-Classes: 10
- Model Optimizer: SGD
- Learning Rate: 1 × 10
- First layer (input layer) is a Convolutional 2d, with the following configuration:
- −
- Input channels = 1 (binary image)
- −
- Output channels = 10
- −
- Kernel size = 5
- Second layer (hidden layer) is a Convolutional 2d, with the following configuration:
- −
- Input channels = 10
- −
- Output channels = 20
- −
- Kernel size = 5
- Dropout2d (parameter for reducing the dimensionality of the data at this level) = 0.5
- Third layer (hidden layer) is the first linear layer, with the following configuration:
- −
- Input features = 320
- −
- Output features = 50
- Fourth layer (output layer) is the second linear layer, with the following configuration:
- −
- Input features = 50
- −
- Output features = 10
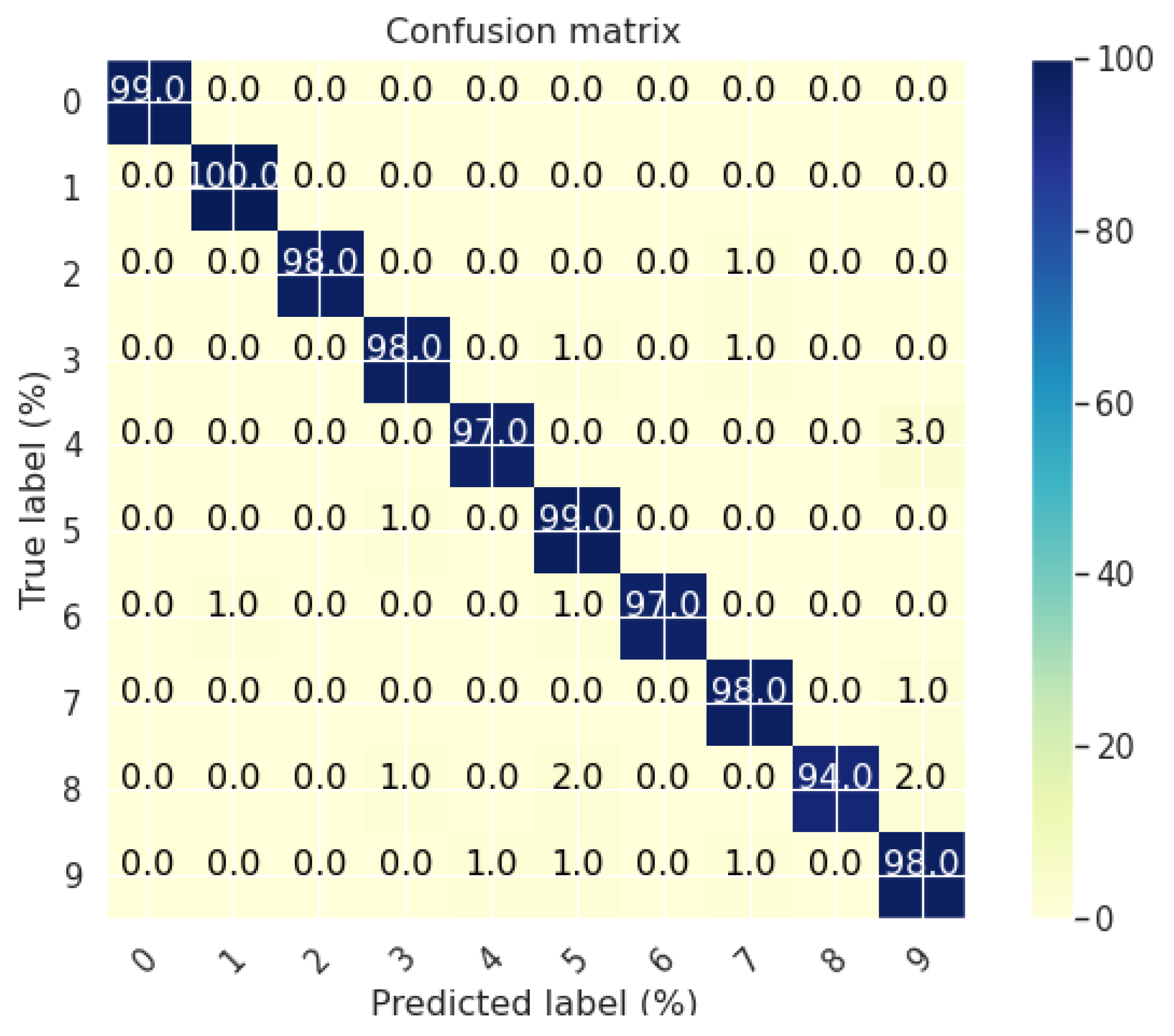
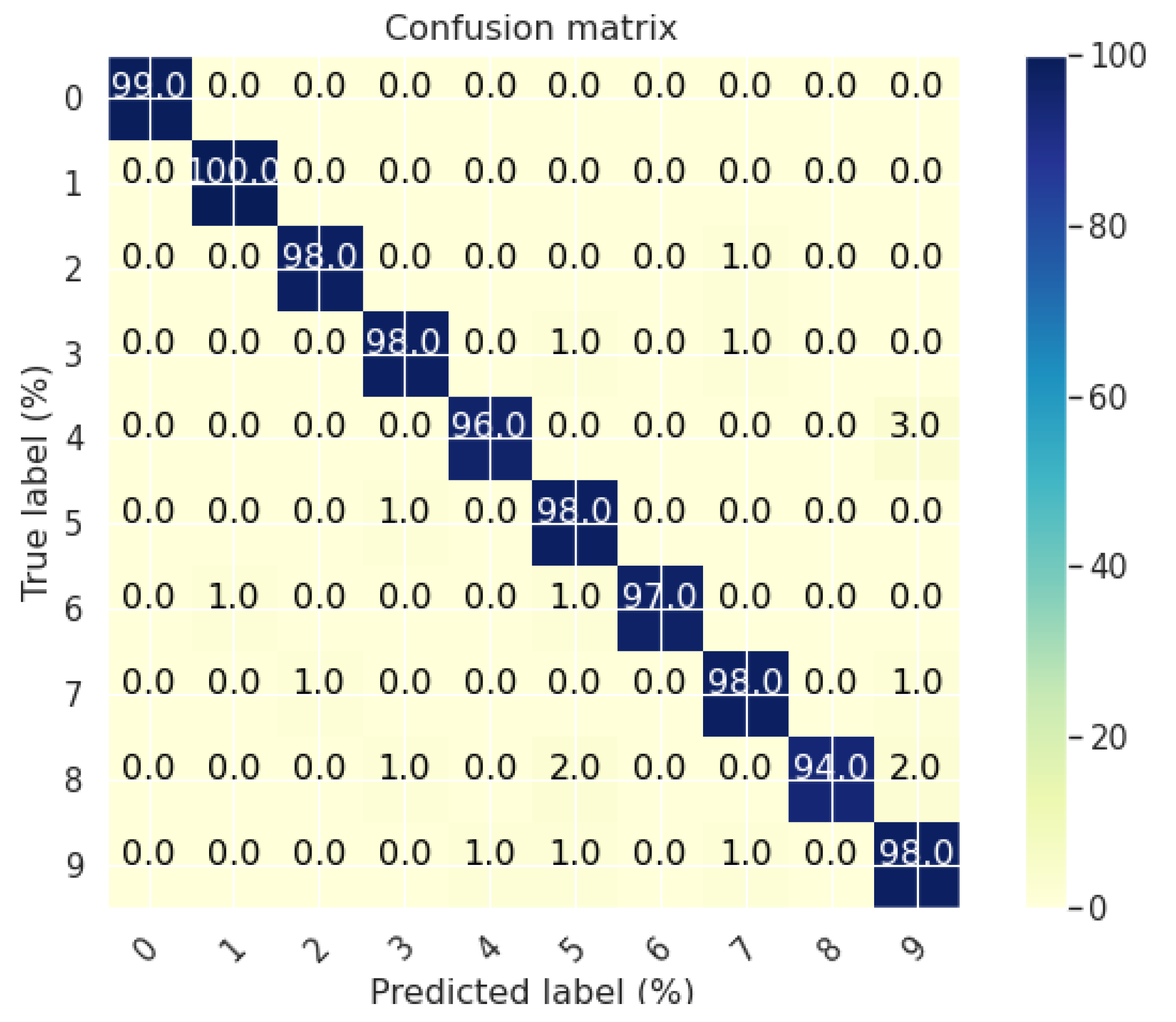
4.1. Experiment 1: Centralized Learning
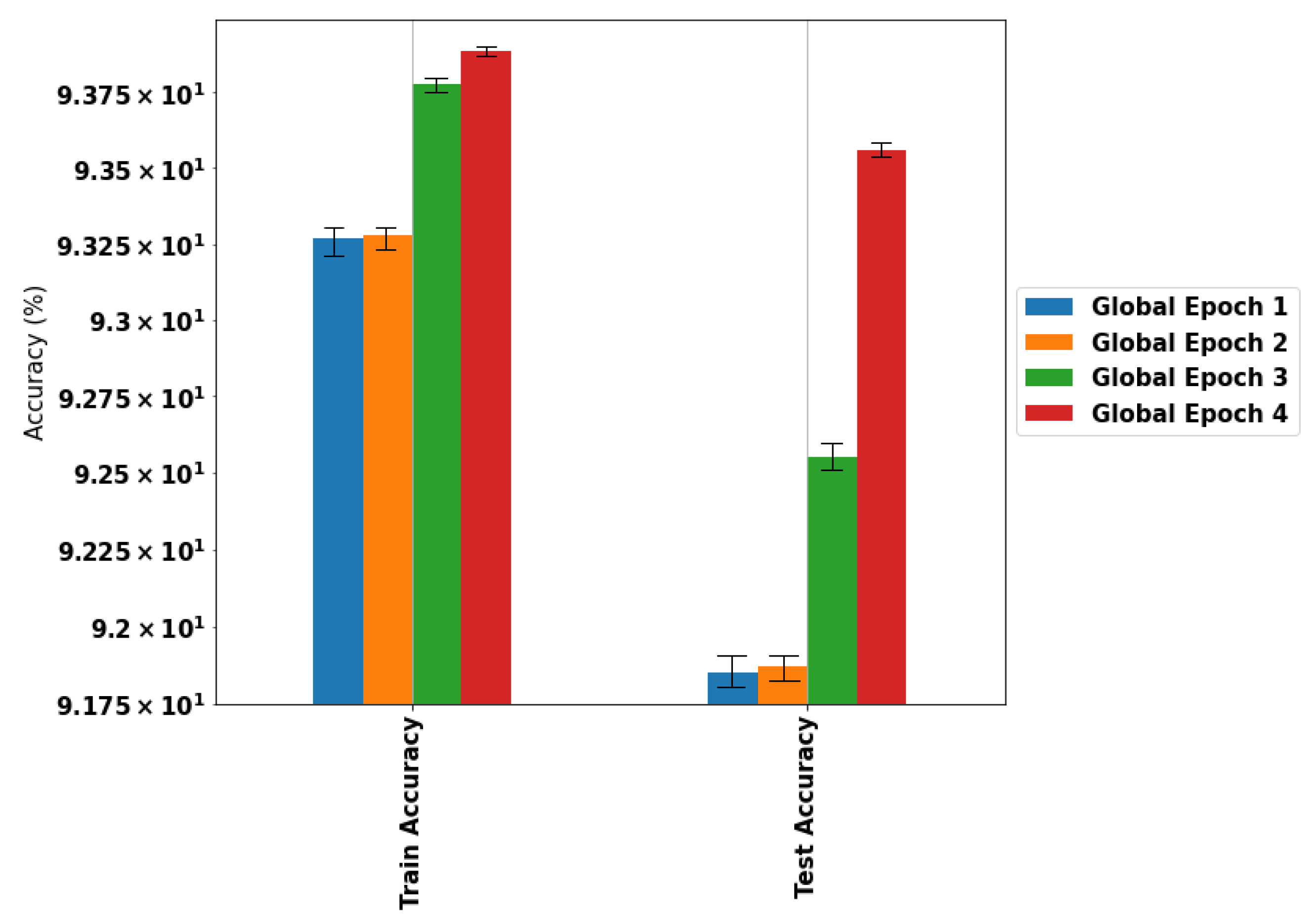
4.2. Experiment 2: Distributed Learning (FlaMas)
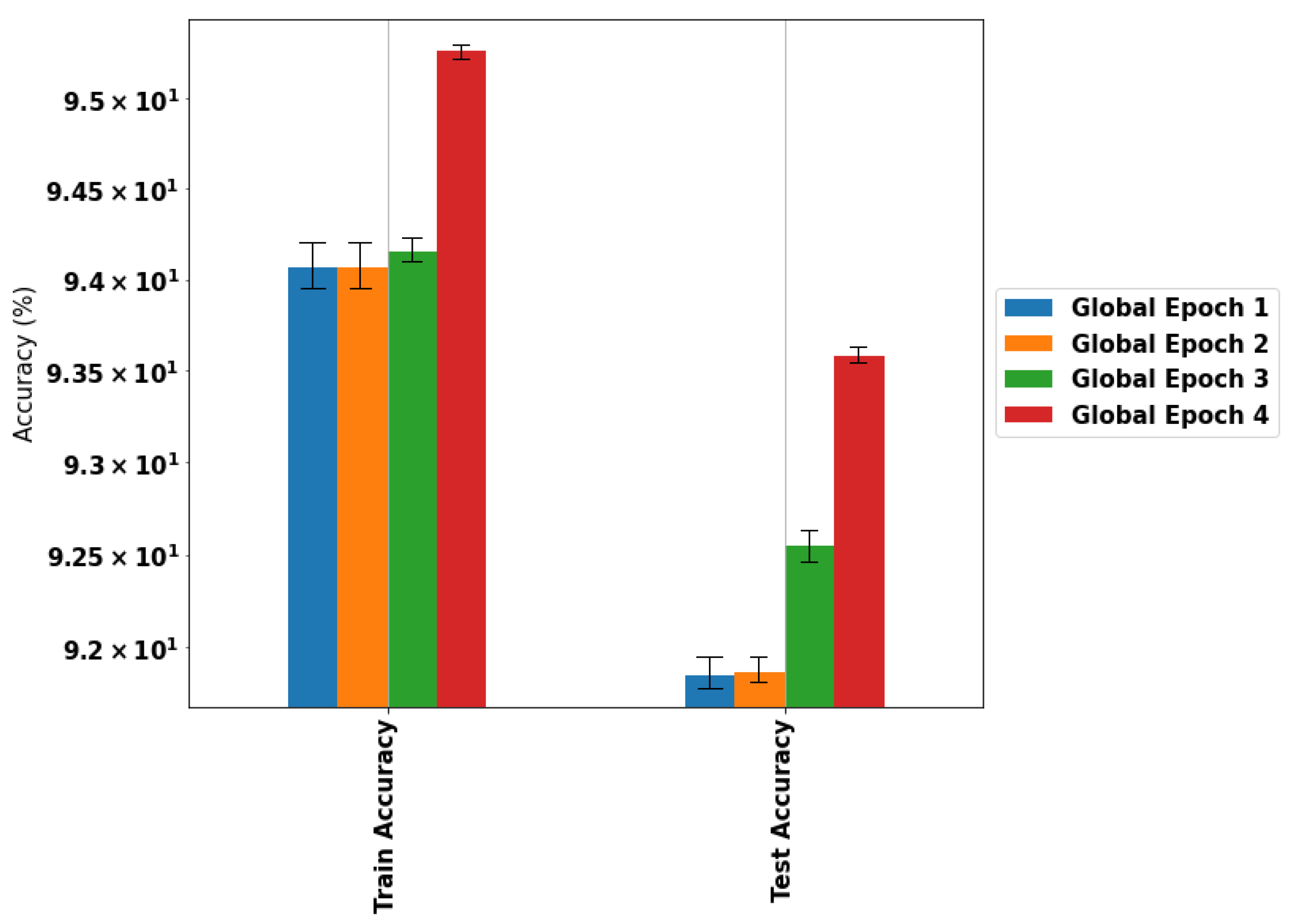
4.3. Experiment 3: Local Learning Effect
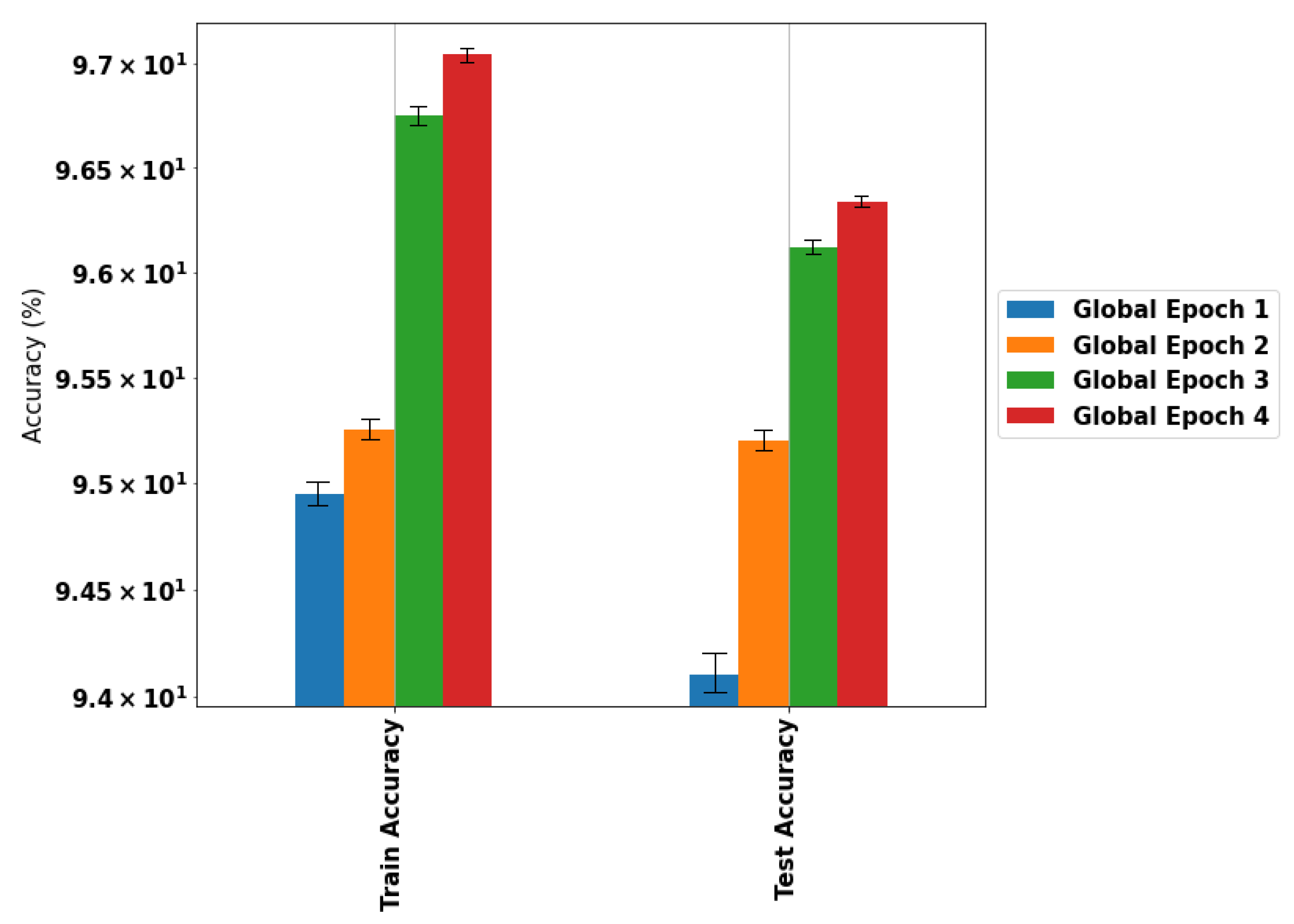
4.4. Experiment 4: Adding New Agents
5. Conclusions and Future Work
Author Contributions
Funding
Conflicts of Interest
References
- Cisco Systems Inc. The Role of Technology in Powering an Inclusive Future; Cisco: San Francisco, CA, USA, 2020. [Google Scholar]
- Ray, P.P. A survey of IoT cloud platforms. Future Comput. Inform. J. 2016, 1, 35–46. [Google Scholar] [CrossRef]
- Voigt, P.; Von dem Bussche, A. The eu general data protection regulation (gdpr). In A Practical Guide, 1st ed.; Springer International Publishing: Cham, Switzerland, 2017; Volume 10, pp. 10–5555. [Google Scholar]
- Goldman, E. An introduction to the california consumer privacy act (CCPA). Santa Clara Univ. Leg. Stud. Res. Pap. 2020. [Google Scholar] [CrossRef]
- Yong, W.; Quan, B. Data privacy law in Singapore: The personal data protection act 2012. Int. Data Priv. Law 2017, 7, 287–302. [Google Scholar]
- Brendan McMahan, H.; Moore, E.; Ramage, D.; Hampson, S.; Agüera y Arcas, B. Communication-efficient learning of deep networks from decentralized data. arXiv 2016, arXiv:1602.056292. [Google Scholar]
- Li, T.; Sahu, A.K.; Talwalkar, A.; Smith, V. Federated learning: Challenges, methods, and future directions. IEEE Signal Process. Mag. 2020, 37, 50–60. [Google Scholar] [CrossRef]
- Li, L.; Fan, Y.; Tse, M.; Lin, K.Y. A review of applications in federated learning. Comput. Ind. Eng. 2020, 149, 106854. [Google Scholar] [CrossRef]
- Nguyen, D.C.; Ding, M.; Pathirana, P.N.; Seneviratne, A.; Li, J.; Poor, H.V. Federated learning for internet of things: A comprehensive survey. IEEE Commun. Surv. Tutor. 2021, 23, 1622–1658. [Google Scholar] [CrossRef]
- Savazzi, S.; Nicoli, M.; Bennis, M.; Kianoush, S.; Barbieri, L. Opportunities of federated learning in connected, cooperative, and automated industrial systems. IEEE Commun. Mag. 2021, 59, 16–21. [Google Scholar] [CrossRef]
- Palanca, J.; Terrasa, A.; Julian, V.; Carrascosa, C. SPADE 3: Supporting the New Generation of Multi-Agent Systems. IEEE Access 2020, 8, 182537–182549. [Google Scholar] [CrossRef]
- Vepakomma, P.; Gupta, O.; Swedish, T.; Raskar, R. Split learning for health: Distributed deep learning without sharing raw patient data. arXiv 2018, arXiv:1812.00564. [Google Scholar]
- Kairouz, P.; McMahan, H.B.; Avent, B.; Bellet, A.; Bennis, M.; Bhagoji, A.N.; Bonawitz, K.; Charles, Z.; Cormode, G.; Cummings, R.; et al. Advances and open problems in federated learning. arXiv 2019, arXiv:1912.04977. [Google Scholar]
- Rahman, K.J.; Ahmed, F.; Akhter, N.; Hasan, M.; Amin, R.; Aziz, K.E.; Islam, A.M.; Mukta, M.S.H.; Islam, A.N. Challenges, applications and design aspects of federated learning: A survey. IEEE Access 2021, 9, 124682–124700. [Google Scholar] [CrossRef]
- Kholod, I.; Yanaki, E.; Fomichev, D.; Shalugin, E.; Novikova, E.; Filippov, E.; Nordlund, M. Open-Source Federated Learning Frameworks for IoT: A Comparative Review and Analysis. Sensors 2021, 21, 167. [Google Scholar] [CrossRef] [PubMed]
- Khan, L.U.; Saad, W.; Han, Z.; Hossain, E.; Hong, C.S. Federated learning for internet of things: Recent advances, taxonomy, and open challenges. IEEE Commun. Surv. Tutor. 2021, 23, 1759–1799. [Google Scholar] [CrossRef]
- Zhang, T.; Gao, L.; He, C.; Zhang, M.; Krishnamachari, B.; Avestimehr, S. Federated Learning for Internet of Things: Applications, Challenges, and Opportunities. arXiv 2021, arXiv:2111.07494. [Google Scholar]
- Singh, S.; Rathore, S.; Alfarraj, O.; Tolba, A.; Yoon, B. A framework for privacy-preservation of IoT healthcare data using Federated Learning and blockchain technology. Future Gener. Comput. Syst. 2021, 129, 380–388. [Google Scholar] [CrossRef]
- Lu, Y.; Huang, X.; Dai, Y.; Maharjan, S.; Zhang, Y. Blockchain and federated learning for privacy-preserved data sharing in industrial IoT. IEEE Trans. Ind. Inform. 2019, 16, 4177–4186. [Google Scholar] [CrossRef]
- Chen, Y.; Qin, X.; Wang, J.; Yu, C.; Gao, W. Fedhealth: A federated transfer learning framework for wearable healthcare. IEEE Intell. Syst. 2020, 35, 83–93. [Google Scholar] [CrossRef] [Green Version]
- Savazzi, S.; Nicoli, M.; Rampa, V. Federated learning with cooperating devices: A consensus approach for massive IoT networks. IEEE Internet Things J. 2020, 7, 4641–4654. [Google Scholar] [CrossRef] [Green Version]
- Hard, A.; Rao, K.; Mathews, R.; Ramaswamy, S.; Beaufays, F.; Augenstein, S.; Eichner, H.; Kiddon, C.; Ramage, D. Federated learning for mobile keyboard prediction. arXiv 2018, arXiv:1811.03604. [Google Scholar]
- McMahan, B.; Ramage, D. Federated Learning: Collaborative Machine Learning without Centralized Training Data. Google A Blog. 2017. Available online: https://ai.googleblog.com/2017/04/federated-learning-collaborative.html (accessed on 10 March 2022).
- Peterson, D.; Kanani, P.; Marathe, V. Private federated learning with domain adaptation. arXiv 2019, arXiv:1912.06733. [Google Scholar]
- Palanca, J.; Rincon, J.; Julian, V.; Carrascosa, C.; Terrasa, A. Developing IoT Artifacts in a MAS Platform. Electronics 2022, 11, 655. [Google Scholar] [CrossRef]
- McMahan, B.; Moore, E.; Ramage, D.; Hampson, S.; y Arcas, B.A. Communication-efficient learning of deep networks from decentralized data. In Proceedings of the Artificial Intelligence and Statistics, PMLR, Fort Lauderdale, FL, USA, 20–22 April 2017; pp. 1273–1282. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Experiment 1 | Experiment 2 | Experiment 3 | Experiment 4 | |||
|---|---|---|---|---|---|---|
| 3.1 | 3.2 | 3.3 | ||||
| Accuracy (%) | 95 | 96.5 | 93.56 | 93.58 | 96.49 | 97.1 |
| Training Time (minutes) | ≈5 | ≈3 | ≈1 | ≈3 | ≈7 | ≈10 |
| N-Global Epochs | 20 | 5 | 4 | 4 | 4 | 4 |
| Mean (%) | 94.69 | 95.10 | 94.68 | 94.93 | 94.95 | 95.05 |
| Variance | 1.17 | 0.52 | 1.16 | 0.83 | 0.78 | 0.58 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rincon, J.; Julian, V.; Carrascosa, C. FLaMAS: Federated Learning Based on a SPADE MAS. Appl. Sci. 2022, 12, 3701. https://doi.org/10.3390/app12073701
Rincon J, Julian V, Carrascosa C. FLaMAS: Federated Learning Based on a SPADE MAS. Applied Sciences. 2022; 12(7):3701. https://doi.org/10.3390/app12073701
Chicago/Turabian StyleRincon, Jaime, Vicente Julian, and Carlos Carrascosa. 2022. "FLaMAS: Federated Learning Based on a SPADE MAS" Applied Sciences 12, no. 7: 3701. https://doi.org/10.3390/app12073701
APA StyleRincon, J., Julian, V., & Carrascosa, C. (2022). FLaMAS: Federated Learning Based on a SPADE MAS. Applied Sciences, 12(7), 3701. https://doi.org/10.3390/app12073701