1. Introduction
With the continuous development of earth observation technologies, increasing numbers of remote sensing satellites have been launched into orbit, which enabled the collection of a myriad of high-resolution remote sensing (HRRS) image data. High-resolution remote sensing images not only exhibit characteristics of rich spectral features, various shapes, and abundant texture features, but also contain significantly clear semantic scene information. Therefore, the classification of remote sensing image scenes is a significant approach for analyzing remote sensing image information, which has attracted considerable research efforts as a key technology for interpreting images and understanding the real world. The classification of high-resolution remote sensing scene data is the basis of several major applications of remote sensing, such as land resource management, natural resource management, and urban planning. Generally, remote sensing scene images (RSSI) reflect widely varying types of objects (including landforms in distinct conditions and buildings with diverse shapes) with complicated features. Hence, the classification of such information remains challenging.
The classification of remote sensing images is hugely dependent on data labeling, in which humans input meaningful labeled data into the training model, and subsequently, such data is further used in feature modeling. However, at present, in the context of expanding applications of such data, the lack of existing pre-labeled remote sensing data becomes a significant obstacle to remote sensing scene classification research, requiring the expenditure of considerable labor and time. Thus, automated generation of marked remote sensing scene data has become practical.
At present, existing methods of data generation have been mainly developed based on generative adversarial networks (GANs). Problems such as distortion and long training times have been reported in the generation of remote sensing scene data using traditional GAN networks and associated variants. Karras et al. [
1] proposed a gradually developed generator and discriminator GAN to generate natural images such as human faces and animals. However, the size of the generated images was limited. Subsequently, it was found that this method could not be applied to RSSIs. Zhao et al. [
2] used pre-trained GAN models to generate natural images under conditions of extremely limited data. This is consistent with the lack of scene data addressed in the present work. However, after experiments, it was found that problems such as distortion persisted. Han et al. [
3] proposed a high-resolution remote sensing scene data generation method based on a Wasserstein GAN network, which solved the problem of distortion to a certain extent. However, the size of the generated data was limited. Pan et al. [
4] proposed a diversified improved GAN with the ability to generate RSSIs. However, due to limitations in computing power and training time, this method nonetheless was unable to learn to generate scene images of sufficient size.
Although generating RSSIs directly is evidently difficult for GAN networks, they perform effectively with respect to texture synthesis tasks. At present, several texture analysis methods have been developed. Among the statistical analysis methods, Sklansky [
5] proposed and applied an approach to describe texture features through autocorrelation function. Weszka et al. [
6] proposed a gray difference histogram statistical method, which was able to describe the spatial organization information of grayscale images. Methods based on the characteristics of texture primitives and their arrangement rules are known as structural analysis methods. For example, Tuceryan and Jain [
7] used this structural analysis method and put forward texture segmentation depending on the Voronoi polygon. Texture analysis based on models assumes that the texture is distributed according to a given model. Spectrum analysis methods are constructed on the multi-scale analysis of texture. For example, Fergusson and Gabor [
8] proposed the Gabor function [
9] as a windowed Fourier-transform method. This approach addressed the deficiency that the classical Fourier transform cannot analyze time and frequency simultaneously. Based on a Markov random field to generate specific texture images and the analysis of image texture features, Efros and Leung [
10] developed a method that could repair a missing image successfully. Zhou et al. [
11] used a GAN to synthesize large-area images with sample texture features based on given small sample textures. Jetchev et al. [
12] proposed a new texture synthesis model based on GAN learning.
In the present work, by extending the input noise distribution space from a single vector to an entire space tensor, a framework with properties that are well-suited for texture synthesis tasks is created, called spatial GAN (SGAN). To the best of our knowledge, the proposed method is the first successful GAN-based texture synthesis method that is completely data-driven.
A typical RSSI can be divided into two parts. For example, it can be considered that a lake scene image contains two parts. One part represents the element of the scene category, which is the lake in this case, and the other part is the element other than the above, which we refer to as the background. In a lake scene, the background might be grassland, desert, or mountains. First, we apply k-means clustering [
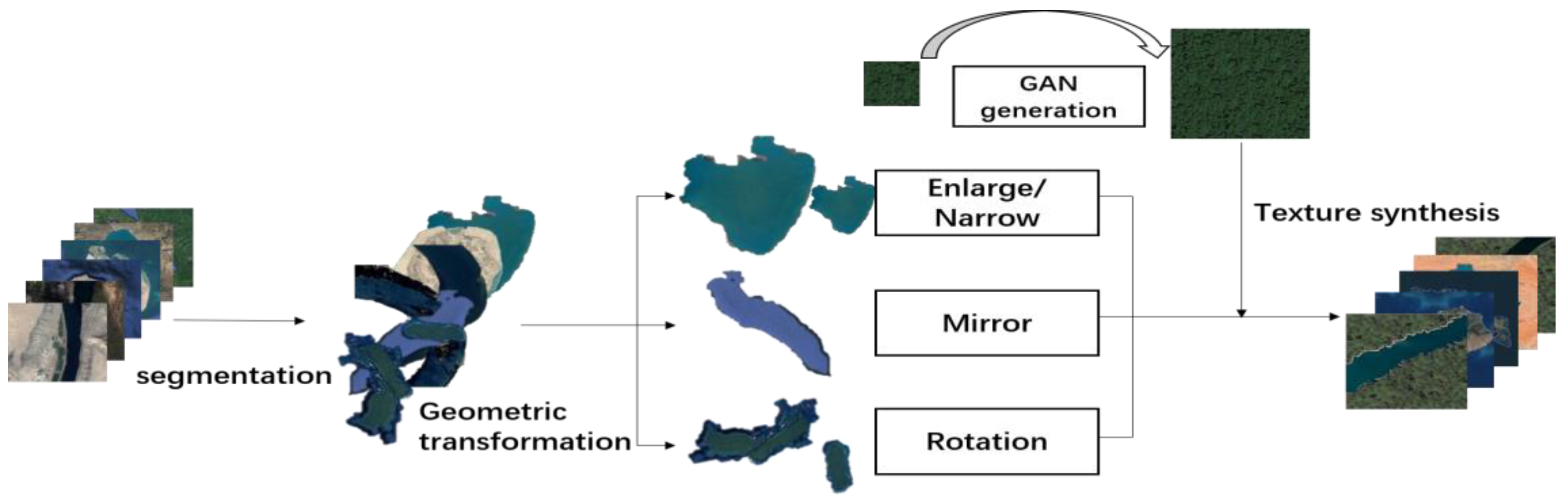
13] to perform scene image segmentation. To address the noise of the image after segmentation, the proposed approach then extracts the elements of the scene geometry characteristic information and translates them into a homogeneous coordinate matrix to apply the techniques originating in computer graphics. After using a simple and complex geometry transform, a complex scene structure is obtained. Simultaneously, we sample the texture features of the elements and use texture synthesis technology to synthesize a large amount of texture feature data based on the collected texture samples. Finally, we fill the texture information back into the reconstructed scene structure, resulting in a new, high-fidelity scene image of increased complexity.
The remainder of this study is organized as follows. In
Section 2 below, we introduce the proposed method, while the results of the experiments are provided in
Section 3.
Section 4 and
Section 5 present our discussion and conclusions and suggests some possible avenues for future research.
2. Materials and Methods
The proposed RSSI generation exhibits a close relationship with the human perception of remote sensing image scenes. Primarily, we divided an RSSI into two parts. One is used to cause the scene image that represents the feature elements of the corresponding scene image category, such as lakes, rivers, islands, etc., while the other part is to cause them to be recognized as the background, except for natural features such as the grassland around the lake, the ocean surrounding the island, etc.
First, we reconstructed the combined feature structure relationship among scene elements through a random transformation of the elements and created a scene element system with diverse and complex structures. Subsequently, we synthesized the texture features of the background with a depth generation algorithm, in order to obtain a scene image with random, complex, and authentic geometry and texture. Compared with the directly generated image, this method uses the depth generation model to construct the spectral information of pixels, which involves a relatively low possibility of distortion.
Figure 1 shows a general overview of the technical roadmap of our method. First, we extracted the geometric polygons of the elements in the original scene image via image segmentation, and subsequently, performed geometric transformations on the obtained polygons through computer graphics. Finally, we used texture synthesis technology to synthesize the texture of the corresponding ground object, and subsequently, merged it into a new RSSI.
2.1. Extraction of Remote Sensing Scene Image Elements Based on k-Means Clustering
The k-means clustering algorithm is a conventional clustering method that uses space efficiently. Clustering methods divide data into several groups. Based on the defined measurement standard, the data in a given group is more similar to other groups of data. The calculation of similarity involves detecting the distance between the data object and the cluster center. The closest distance to the cluster center is divided among the cluster. The procedure is given as follows. First, randomly select k objects that initially represent the average or center of the cluster. Each other object is allocated to the nearest cluster according to its distance from the center of each cluster. Then, calculate the average value of each cluster again to find the center of the cluster, and reorder the clusters accordingly. This process is repeated until the criterion function converges. The time complexity of this algorithm is , where n is the number of all objects, k is the number of clusters, and t is the number of iterations.
In this study, we used a k-means clustering method to segment remotely sensed scene images. We inputted the image as a matrix into the algorithm, specified the parameter k for clustering (that is, segmentation) and finally, achieved the purpose of extracting elements in the scene.
The proposed method uses the k-means clustering method to segment scene images. A set of RSSIs is input into the algorithm, and subsequently, the separated images are obtained. However, these images still cannot be used to extract the elements in the RSSIs. This is because both the background part and the element part that are divided contain some noise data, which are expressed as dense or washed-out blobs or obstructions in the image. Therefore, to extract the elements through the segmented image, we must first preprocess it.
2.2. Element Geometric Transformation
After the image segmentation, we obtained the geometric features of each element in the corresponding scene image. These geometric features can be used to demonstrate the structural relationship between various elements in RSSIs and to generate RSSIs.
In order to generate a new RSSI that is distinct from the original RSSIs, it is necessary to transform the geometric features of the extracted elements for the purpose of reconstructing the entire RSSI. The transformation that we performed involves enlargement, reduction, translation, and symmetry (on both X- and Y-axes). To complete the mathematical description of feature transformation, we first abstracted the extracted feature as a polygon. We used a homogeneous coordinate matrix P to record the coordinates of each vertex counterclockwise from a vertex of the polygon. Assuming the coordinates of each vertex of a polygon to be
, respectively, in the counterclockwise direction, the corresponding homogeneous coordinate matrix is given by
Subsequently, we defined a 3 × 3 geometric transformation matrix , which is used for geometric transformation of polygons. The transformation matrices of the geometric transformation were implemented as follows.
Enlargement and reduction were given by
where
and
represent the proportion of enlargement and reduction. When
and
are greater than 1, the operation is enlargement. When
and
are less than 1, the operation is reduction.
The translation operation was performed as follows.
where
and
represent the translation distance of features in
and
directions.
Counterclockwise rotation was performed as follows.
where
is the counterclockwise rotation angle of the element.
Clockwise rotation was performed as follows.
where
is the counterclockwise rotation angle of the element.
The
X-axis symmetry transformation is given by
While
Y-axis symmetry is given by
Assuming that the coordinates of each vertex of the transformed polygon are
, consequently, the homogeneous coordinate matrix P composed of them is given by
After we perform these basic geometric transformations, we can compound these basic geometric transformations, and the corresponding geometric transformation formula is given by
Then, is used to choose the corresponding transformation matrix according to the transformation needed. The significance of the formula is that the geometric transformation represented by matrix is carried out first, and on this basis, the geometric transformation represented by matrix is carried out, and so on.
After the transformation, we could obtain the new structure of the reconstructed RSSI, which lays the foundation for the next section.
2.3. Texture Synthesis of RSSI Based on GAN Network
In a typical GAN network [
14], the generator network maps randomly generated noise data, such as Gaussian noise, to fake samples. The discriminator network must receive real data samples (to discriminate between data samples) or fake samples. The generator is then trained to cheat the discriminator. Simultaneously, the discriminator also needs to be trained to be able to overcome the generator. Generally, the competition between the generator and the discriminator enables the generator to generate enough samples to deceive the discriminator, and the discriminator can better distinguish between true samples and constructed samples. The min-max objective function of the game between the generator
and the discriminator
is given by
where
and
are the real data distribution, real sample and model distribution, respectively. Fake samples can be represented as
,
, where the input
of the generator is sampled from a simple noise distribution, such as a spherical Gaussian distribution. If the optimization and training of the discriminator are after the generator updates the parameters, then the minimization of the
divergence between
and
is the minimization value function.
divergence is an important indicator of the similarity between two probability distributions based on Kullback–Leibler (
) divergence.
in GAN can be calculated as follows.
where
is defined as
Both
and
are assumed to be absolutely continuous and admit densities.
Based on the work of Zhou et al. and Efros et al. on texture synthesis, we used a GAN to synthesize the texture of each element extracted. The texture synthesis technology in this section is based on the work of Efros and Zhou. We sampled the surface texture of rivers, forests, grasslands, and oceans in RSSIs and selected a big number of typical surface texture samples as the input of texture synthesis. When performing texture synthesis, we selected a total of 100 texture samples from five categories, including rivers, lakes, seas, meadows, and forests, representing the typical characteristics of the corresponding category. These five classes of samples were taken from rivers, lakes, ocean forests, and grasslands.
Figure 2 is an example of our selection of samples.
2.4. Scene Data Generation Quality Assessment
After obtaining the generated scene images, we evaluated the classification accuracy of the generated images. Firstly, a visual discrimination method was used to judge the generated images with the naked eye, and they were compared with the images directly generated by other generated adversarial networks. Secondly, the three conventional convolutional neural networks (CNN)-ALEX-NET [
15], VGG-NET [
16], and RES-NET [
17] were used to carry out classification experiments on the data sets of NWPU-RESISC45 [
18]. Then, the generated scene images were classified. In total, 60 images from each of the 5 categories were added to the original data set to form an enhanced data set, and classification experiments were carried out on the enhanced data set. In addition, we also conducted a separate classification experiment on the scene images generated by the proposed approach.
4. Discussion
We conducted extensive experiments on the public NWPU-REISC45 HRRS data set to justify the effectiveness and feasibility of the proposed method and obtained the expected results. As for the classification ability of CNNs on the scene images, it was found that the classification accuracy of all the methods was reduced. For the reduction in the accuracy in the comparison experiments between the original data set and the enhanced data set, we think that after adding the data generated by our proposed method, the complexity of the data set increased and the separability decreased. Additionally, for the classification experiment of the generated data, we think that this is because the amount of data used in this experiment is small, which leads to insufficient model training. All in all, the complexity of the enhanced data set was increased, and our proposed method partially solves the accuracy saturation issues of those public scene data sets.
With respect to the classes for data generation, we selected the classes that contain elements that are more blocky and whose textures are smooth. This means it is difficult to apply to those classes that do not meet the requirements above.
While performing the data generation experiments, we noticed that ethical awareness is of great importance to concern. With the artificial intelligence, especially the deep fake technology so developed, great convenience has been brought to us. Meanwhile, these technologies have also raised great ethical concerns. The generation and recognition technology of face images has caused the violation of privacy and the theft of personal information. In the field of remote sensing images, law enforcement of satellite images and land use approval are also facing similar challenges. The ethical issues of artificial intelligence in the field of remote sensing still need careful research and thinking.
5. Conclusions
In this study, to solve the problems of small sample size in a remote sensing scene data set, as well as simple scene structure and distortion caused by direct generation, a scene reconstruction method was proposed based on random element transformation and GAN-based texture synthesis. This method can be applied to generate remote sensing scene data set with labels, in which the random transformation of elements can be used to reconstruct the scene structure and the texture synthesis can be used to fill the spectrum of the reconstructed scene. Experimental results demonstrate that the RSSI generated by our method achieved a better visual effect than a GAN model. In addition, the performance of CNN classifiers was reduced on the enhanced data set, which is partly attributed to the complexity of the generated samples. Our work can generate a large number of scene images with complex structures and high fidelity. Thus, the existing remote sensing scene data sets can be expanded, alleviating the accuracy saturation issues. In addition, pre-trained classification models for RSSIs can also be constructed based on the enhanced data sets.
In the future, we expect to generate more images with complex scene structures and realistic descriptions, to promote the development of scene image generation in remote sensing.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}