
MSPNet: Multi-Scale Strip Pooling Network for Road Extraction from Remote Sensing Images


Abstract
:1. Introduction
- We propose an end-to-end multi-scale strip pooling network (MSPNet) with symmetric encoder–decoder network design for the task of road extraction. This network design can preserve spatial detailed information and therefore optimize the smoothness of roads. In addition, it is also suitable for processing large-scale images.
- We develop a multi-scale strip pooling (MSP) module that utilizes strip pooling layers to aggregate multiple long-range contextual information. The linear features of roads are enhanced within CNN architecture, which thus improves the road connectivity.
- Ablation studies and comparative experiments on a benchmark DeepGlobe data set are performed to verify the effectiveness of our proposed MSPNet.
2. Related Work
2.1. Expert Knowledge-Based Methods
2.2. CNN-Based Methods
3. Materials and Methods
3.1. Dataset
3.2. Evaluation Metrics
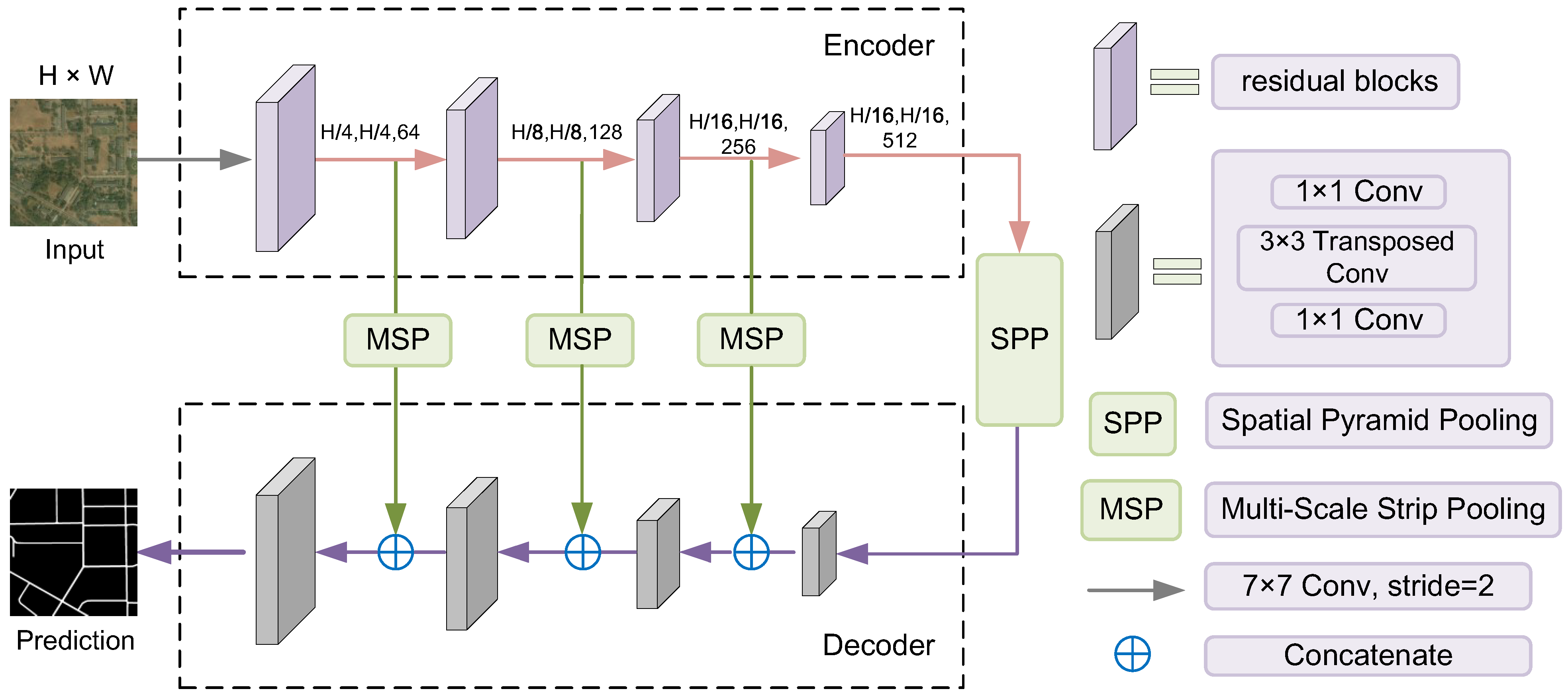
3.3. Network Structure
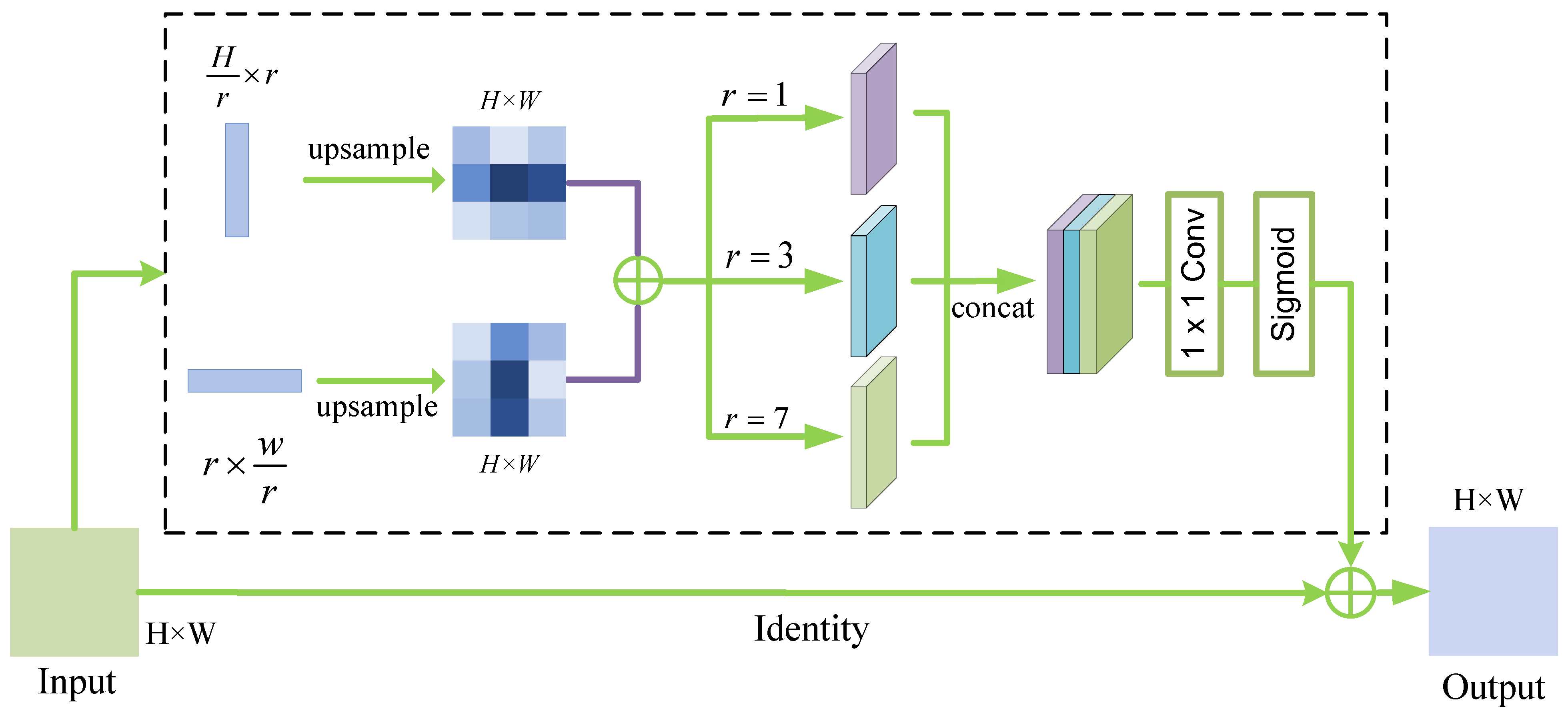
3.4. Multi-Scale Strip Pooling
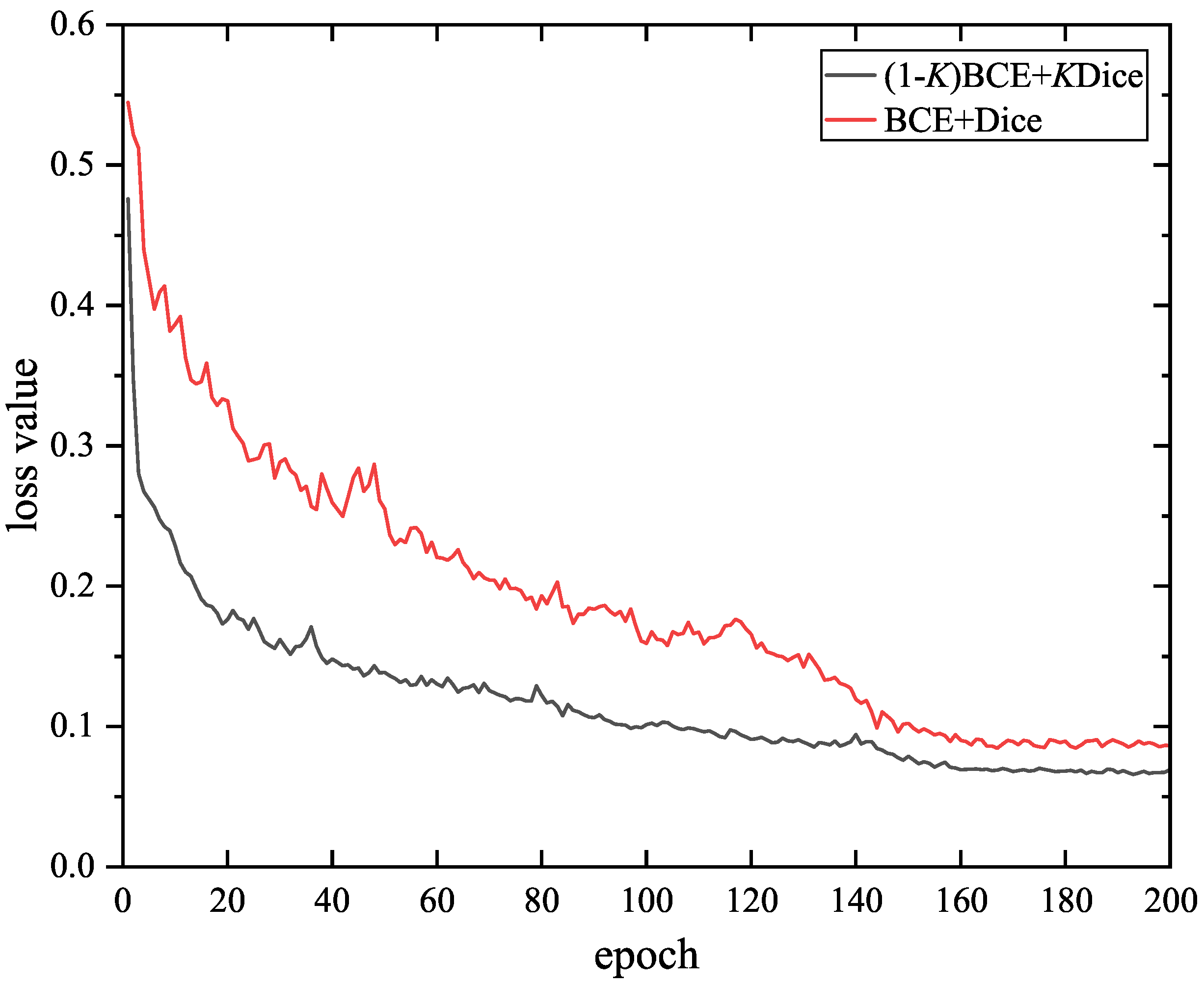
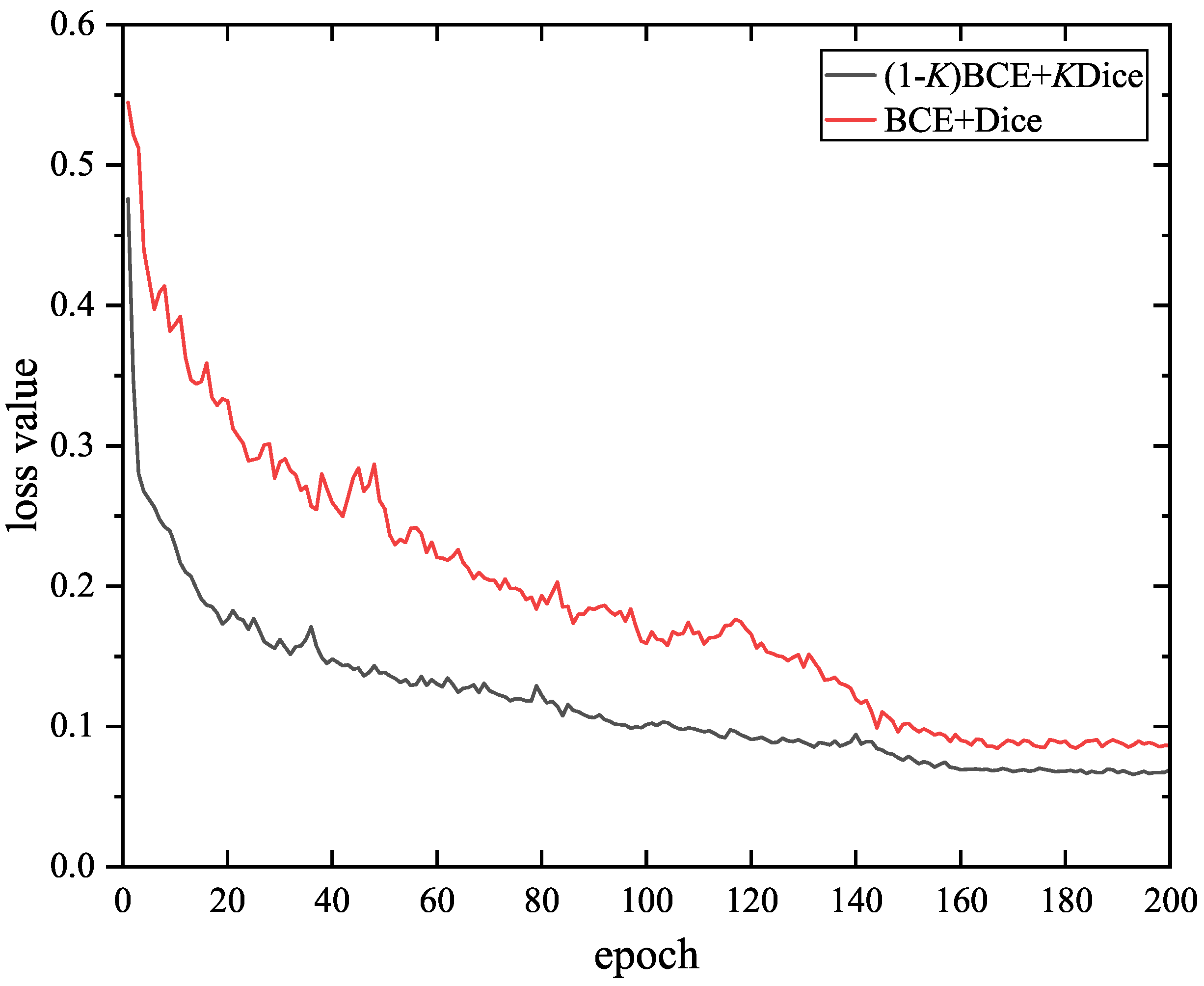
3.5. Loss Function
4. Results
4.1. Implementation Details
4.2. Ablation Experiment
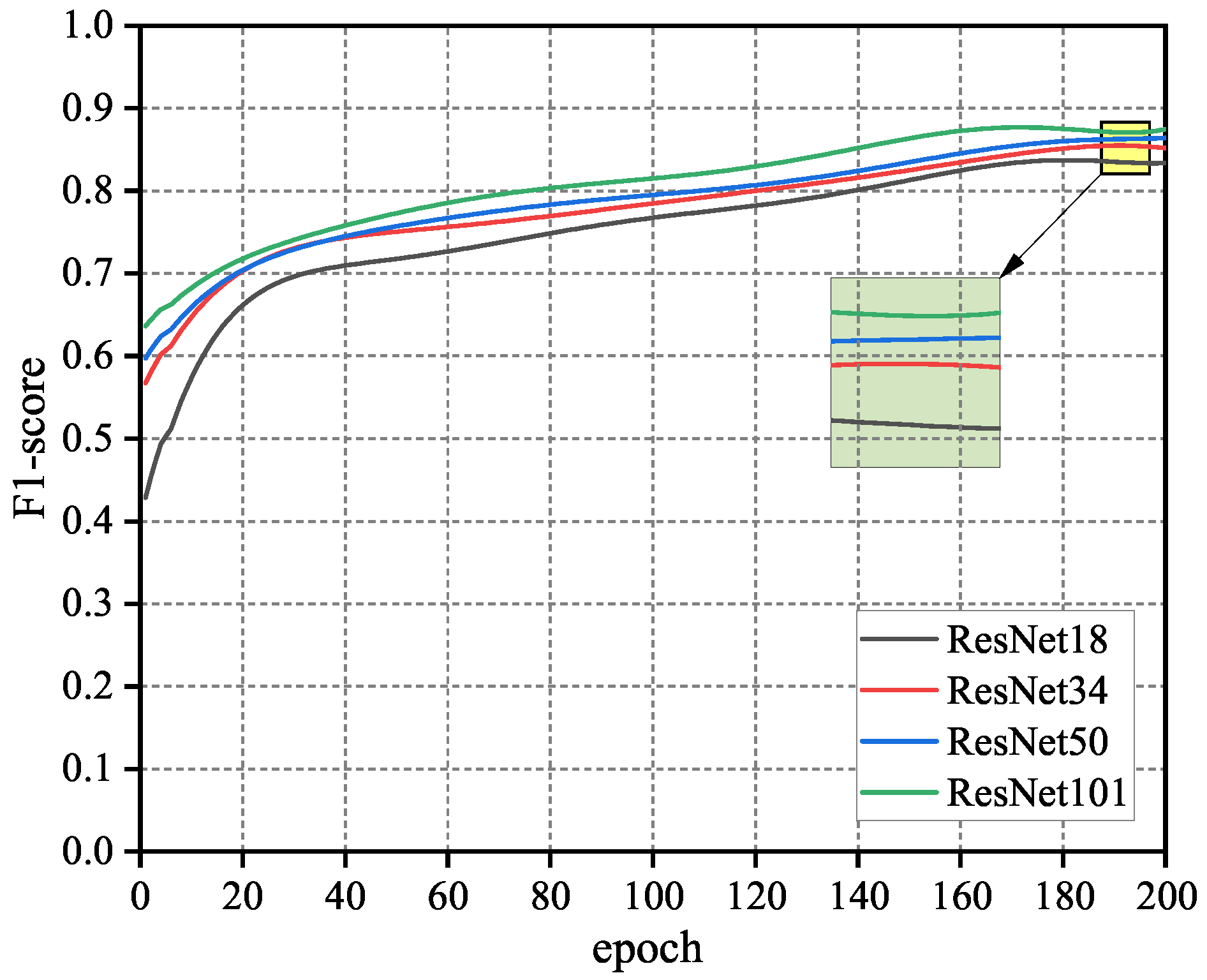
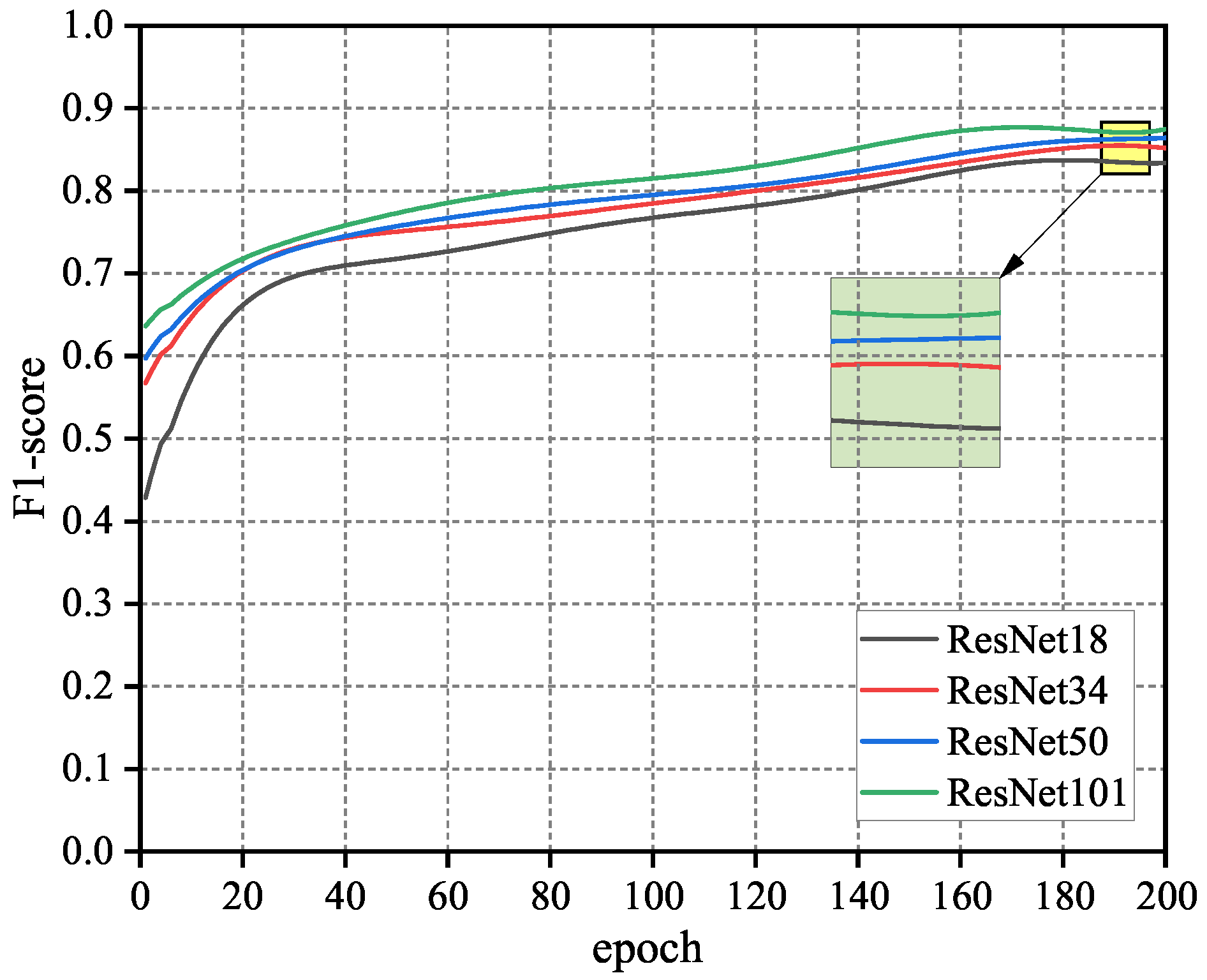
4.2.1. Comparison of Backbone Networks
4.2.2. Influence of Hyper-Parameter K
4.3. Comparison with State-of-the-Art Methods
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 39, 640–651. [Google Scholar] [CrossRef] [Green Version]
- Das, P.; Chand, S. Extracting road maps from high-resolution satellite imagery using refined DSE-LinkNet. Connect. Sci. 2021, 33, 278–295. [Google Scholar] [CrossRef]
- Ding, L.; Bruzzone, L. DiResNet: Direction-Aware Residual Network for Road Extraction in VHR Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2021, 59, 10243–10254. [Google Scholar] [CrossRef]
- Raziq, A.; Xu, A.; Yu, L. Automatic Extraction of Urban Road Centerlines from High-Resolution Satellite Imagery Using Automatic Thresholding and Morphological Operation Method. J. Geogr. Inf. Syst. 2016, 8, 517–525. [Google Scholar] [CrossRef] [Green Version]
- Cheng, G.L.; Zhu, F.Y.; Xiang, S.M.; Wang, Y.; Pan, C.H. Accurate urban road centerline extraction from VHR imagery via multiscale segmentation and tensor voting. Neurocomputing 2016, 205, 407–420. [Google Scholar] [CrossRef] [Green Version]
- Dai, J.; Wang, Y.; Du, Y.; Zhu, T.; Xie, S.; Li, C.; Fang, X. Development and prospect of road extraction method for optical remote sensing image. J. Remote Sens. 2020, 24, 804–823. [Google Scholar]
- Xin, J.; Zhang, X.C.; Zhang, Z.Q.; Fang, W. Road Extraction of High-Resolution Remote Sensing Images Derived from DenseUNet. Remote Sens. 2019, 11, 2499. [Google Scholar] [CrossRef] [Green Version]
- Han, Y.B.; Han, P.; Jia, M.L. Road extraction from high resolution remote sensing image via a deep residual and pyramid pooling network. IET Image Process. 2021, 15, 3080–3093. [Google Scholar] [CrossRef]
- Ren, Y.F.; Yu, Y.T.; Guan, H.Y. DA-CapsUNet: A Dual-Attention Capsule U-Net for Road Extraction from Remote Sensing Imagery. Remote Sens. 2020, 12, 2866. [Google Scholar] [CrossRef]
- Fan, K.L.; Li, Y.X.; Yuan, L.; Si, Y.; Tong, L. New Network Based on D-Linknet and Resnext for High Resolution Satellite Imagery Road Extraction. In Proceedings of the IGARSS 2020—2020 IEEE International Geoscience and Remote Sensing Symposium, Waikoloa, HI, USA, 26 September–2 October 2020; pp. 2599–2602. [Google Scholar] [CrossRef]
- Fu, G.; Zhao, H.R.; Li, C.; Shi, L.M. Road Detection from Optical Remote Sensing Imagery Using Circular Projection Matching and Tracking Strategy. J. Indian Soc. Remote Sens. 2013, 41, 819–831. [Google Scholar] [CrossRef]
- Ma, R.G.; Wang, W.X.; Liu, S. Extracting roads based on Retinex and improved Canny operator with shape criteria in vague and unevenly illuminated aerial images. J. Appl. Remote Sens. 2012, 6, 063610. [Google Scholar] [CrossRef] [Green Version]
- Herumurti, D.; Uchimura, K.; Koutaki, G.; Uemura, T. Urban Road Network Extraction Based on Zebra Crossing Detection From a Very High Resolution RGB Aerial Image and DSM Data. In Proceedings of the 2013 International Conference on Signal-Image Technology and Internet-Based Systems (Sitis), Kyoto, Japan, 2–5 December 2013; pp. 79–84. [Google Scholar] [CrossRef]
- Song, M.J.; Civco, D. Road extraction using SVM and image segmentation. Photogramm. Eng. Remote Sens. 2004, 70, 1365–1371. [Google Scholar] [CrossRef] [Green Version]
- Mei, J.; Li, R.J.; Gao, W.; Cheng, M.M. CoANet: Connectivity Attention Network for Road Extraction from Satellite Imagery. IEEE Trans. Image Process. 2021, 30, 8540–8552. [Google Scholar] [CrossRef] [PubMed]
- Ding, C.; Weng, L.G.; Xia, M.; Lin, H.F. Non-Local Feature Search Network for Building and Road Segmentation of Remote Sensing Image. ISPRS Int. J. Geo-Inf. 2021, 10, 245. [Google Scholar] [CrossRef]
- Mnih, V.; Hinton, G.E. Learning to Detect Roads in High-Resolution Aerial Images. In Proceedings of the Computer Vision—ECCV 2010—11th European Conference on Computer Vision, Heraklion, Crete, Greece, 5–11 September 2010. Part VI. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; Springer: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Chaurasia, A.; Culurciello, E. LinkNet: Exploiting Encoder Representations for Efficient Semantic Segmentation. In Proceedings of the IEEE Visual Communications and Image Processing (VCIP), St. Petersburg, FL, USA, 10–13 December 2017; IEEE: New York, NY, USA, 2017. [Google Scholar]
- Zhou, K.; Xie, Y.; Gao, Z.; Miao, F.; Zhang, L. FuNet: A Novel Road Extraction Network with Fusion of Location Data and Remote Sensing Imagery. ISPRS Int. J. Geo-Inf. 2021, 10, 39. [Google Scholar] [CrossRef]
- Zhang, Z.X.; Liu, Q.J.; Wang, Y.H. Road Extraction by Deep Residual U-Net. IEEE Geosci. Remote Sens. Lett. 2018, 15, 749–753. [Google Scholar] [CrossRef] [Green Version]
- Zhou, L.C.; Zhang, C.; Wu, M. D-LinkNet: LinkNet with Pretrained Encoder and Dilated Convolution for High Resolution Satellite Imagery Road Extraction. In Proceedings of the 2018 IEEE/Cvf Conference on Computer Vision and Pattern Recognition Workshops (Cvprw), Salt Lake City, UT, USA, 18–22 June 2018; pp. 192–196. [Google Scholar] [CrossRef]
- Xie, Y.; Miao, F.; Zhou, K.; Peng, J. HsgNet: A Road Extraction Network Based on Global Perception of High-Order Spatial Information. ISPRS Int. J. Geo-Inf. 2019, 8, 571. [Google Scholar] [CrossRef] [Green Version]
- Li, X.G.; Zhang, Z.; Lv, S.S.; Pan, M.; Ma, Q.; Yu, H.B. Road Extraction from High Spatial Resolution Remote Sensing Image Based on Multi-Task Key Point Constraints. IEEE Access 2021, 9, 95896–95910. [Google Scholar] [CrossRef]
- Wei, Y.; Zhang, K.; Ji, S.P. Simultaneous Road Surface and Centerline Extraction From Large-Scale Remote Sensing Images Using CNN-Based Segmentation and Tracing. IEEE Trans. Geosci. Remote Sens. 2020, 58, 8919–8931. [Google Scholar] [CrossRef]
- Demir, I.; Koperski, K.; Lindenbaum, D.; Pang, G.; Huang, J.; Basu, S.; Hughes, F.; Tuia, D.; Raskar, R. Deepglobe 2018: A challenge to parse the earth through satellite images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 172–181. [Google Scholar]
- Henry, C.; Azimi, S.M.; Merkle, N. Road Segmentation in SAR Satellite Images With Deep Fully Convolutional Neural Networks. IEEE Geosci. Remote Sens. Lett. 2018, 15, 1867–1871. [Google Scholar] [CrossRef] [Green Version]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- He, K.M.; Zhang, X.Y.; Ren, S.Q.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef] [Green Version]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Zhao, H.S.; Shi, J.P.; Qi, X.J.; Wang, X.G.; Jia, J.Y. Pyramid Scene Parsing Network. In Proceedings of the 30th IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; IEEE: New York, NY, USA, 2017; pp. 6230–6239. [Google Scholar] [CrossRef] [Green Version]
- Tian, T.; Chu, Z.; Hu, Q.; Ma, L. Class-Wise Fully Convolutional Network for Semantic Segmentation of Remote Sensing Images. Remote Sens. 2021, 13, 3211. [Google Scholar] [CrossRef]
- Hou, Q.; Zhang, L.; Cheng, M.M.; Feng, J. Strip Pooling: Rethinking Spatial Pooling for Scene Parsing. In Proceedings of the CVPR, Seattle, WA, USA, 14–19 June 2020. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lin, Y.E.; Xu, D.Y.; Wang, N.; Shi, Z.; Chen, Q.X. Road Extraction from Very-High-Resolution Remote Sensing Images via a Nested SE-Deeplab Model. Remote Sens. 2020, 12, 2985, Erratum in Remote Sens. 2021, 13, 783. [Google Scholar] [CrossRef]
- Li, J.; Liu, Y.; Zhang, Y.N.; Zhang, Y. Cascaded Attention DenseUNet (CADUNet) for Road Extraction from Very-High-Resolution Images. Isprs Int. J. Geo-Inf. 2021, 10, 329. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Settings | #Params | F1-Score |
|---|---|---|
| Backbone (with ResNet18) | 80 M | 81.79% |
| Backbone (with ResNet34) | 118 M | 84.51% |
| Backbone (with ResNet50) | 830 M | 84.92% |
| Backbone (with ResNet101) | 902 M | 85.14% |
| Settings | MIoU | F1-Score |
|---|---|---|
| BCE + Dice | 85.26% | 83.76% |
| ( a) BCE + K a Dice | 86.74% | 84.51% |
| Methods | OA (%) | IoU (%) | F1 (%) |
|---|---|---|---|
| FCN | 96.52 | 60.51 | 74.85 |
| ResUNet | 97.45 | 62.74 | 77.89 |
| D-LinkNet | 97.61 | 64.24 | 78.56 |
| CADUNet [37] | / | 66.38 | 78.75 |
| DSE-LinkNet [3] | / | 69.57 | 76.73 |
| HsgNet [24] | / | / | 82.90 |
| SE-Deeplab | 98.12 | 71.86 | 82.57 |
| MSPNet (ours) | 98.71 | 73.64 | 84.51 |
| Methods | FLOPS (Gbps) | Interfence (s) |
|---|---|---|
| FCN | 97.47 | 0.097 |
| ResUNet | 191.36 | 0.145 |
| D-LinkNet | 84.51 | 0.123 |
| SE-Deeplab | 223.65 | 0.176 |
| MSPNet(ours) | 100.49 | 0.106 |
| Data Augmentation | IoU (%) | F1 (%) |
|---|---|---|
| ✕ | 73.26 | 84.07 |
| ✓ | 73.64 | 84.51 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Qu, S.; Zhou, H.; Zhang, B.; Liang, S. MSPNet: Multi-Scale Strip Pooling Network for Road Extraction from Remote Sensing Images. Appl. Sci. 2022, 12, 4068. https://doi.org/10.3390/app12084068
Qu S, Zhou H, Zhang B, Liang S. MSPNet: Multi-Scale Strip Pooling Network for Road Extraction from Remote Sensing Images. Applied Sciences. 2022; 12(8):4068. https://doi.org/10.3390/app12084068
Chicago/Turabian StyleQu, Shenming, Huafei Zhou, Bo Zhang, and Shengbin Liang. 2022. "MSPNet: Multi-Scale Strip Pooling Network for Road Extraction from Remote Sensing Images" Applied Sciences 12, no. 8: 4068. https://doi.org/10.3390/app12084068
APA StyleQu, S., Zhou, H., Zhang, B., & Liang, S. (2022). MSPNet: Multi-Scale Strip Pooling Network for Road Extraction from Remote Sensing Images. Applied Sciences, 12(8), 4068. https://doi.org/10.3390/app12084068