
Image Classification of Pests with Residual Neural Network Based on Transfer Learning

Abstract
:1. Introduction
2. Model
2.1. Convolutional Neural Network
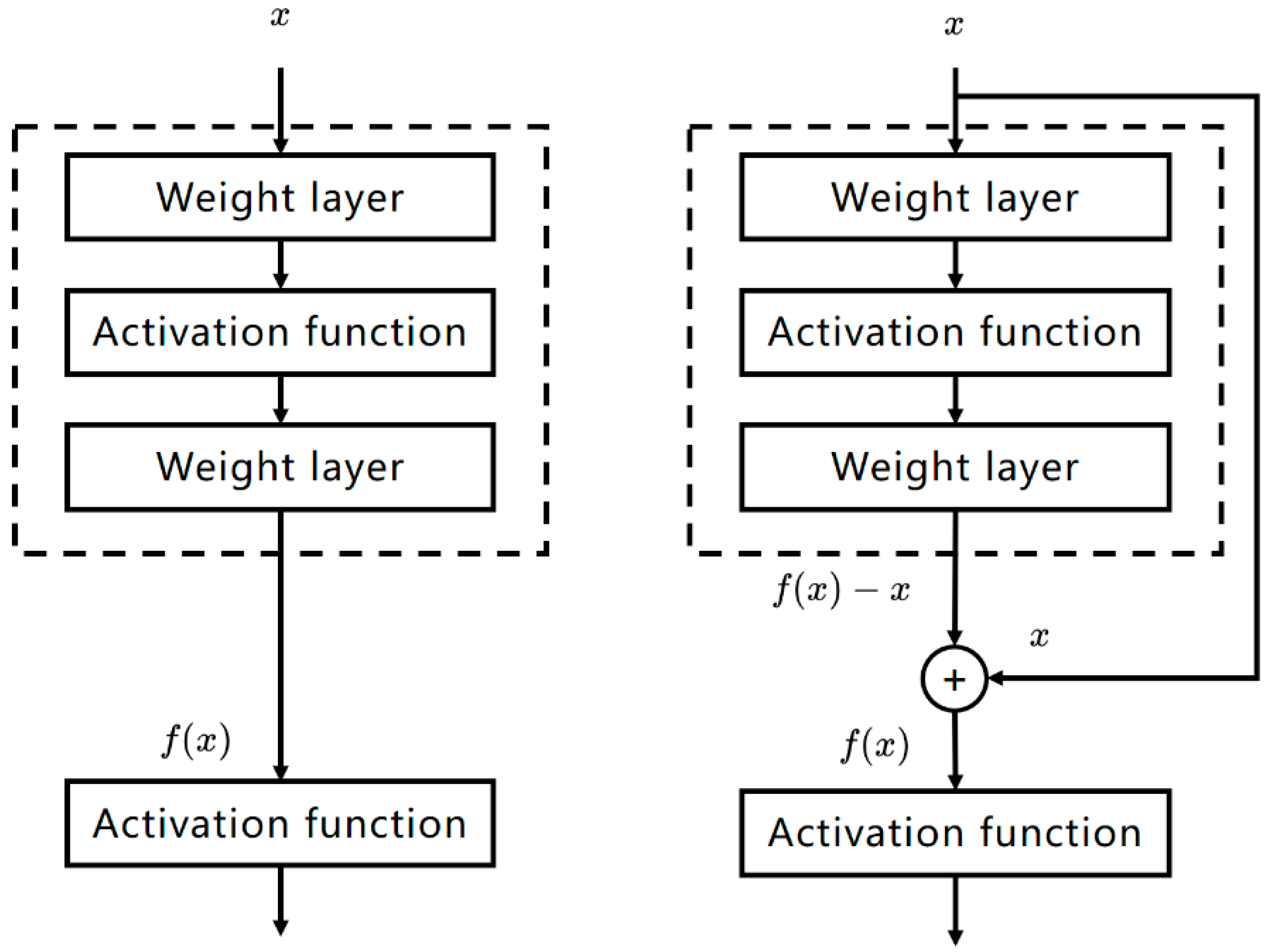
2.2. ResNet
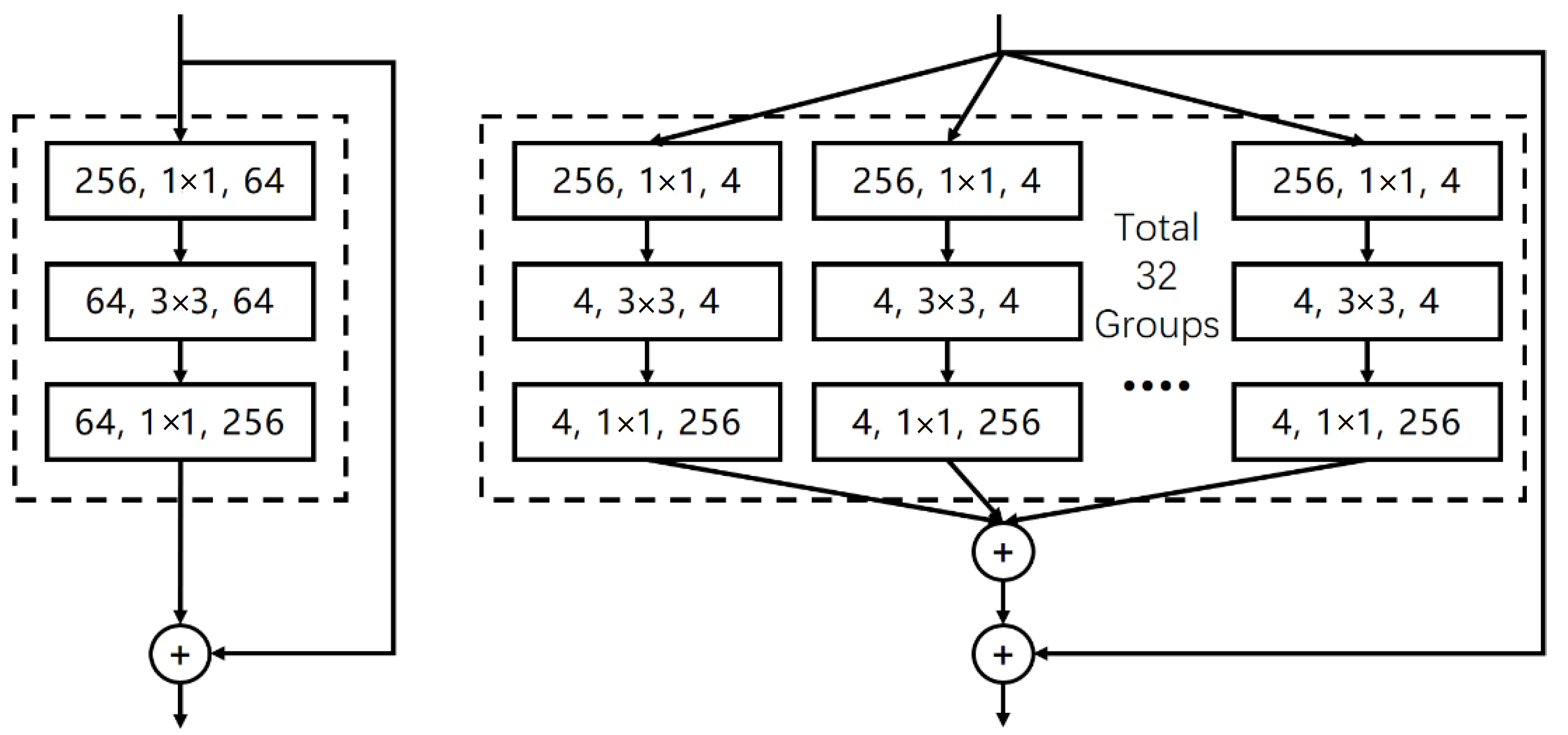
2.3. ResNeXt
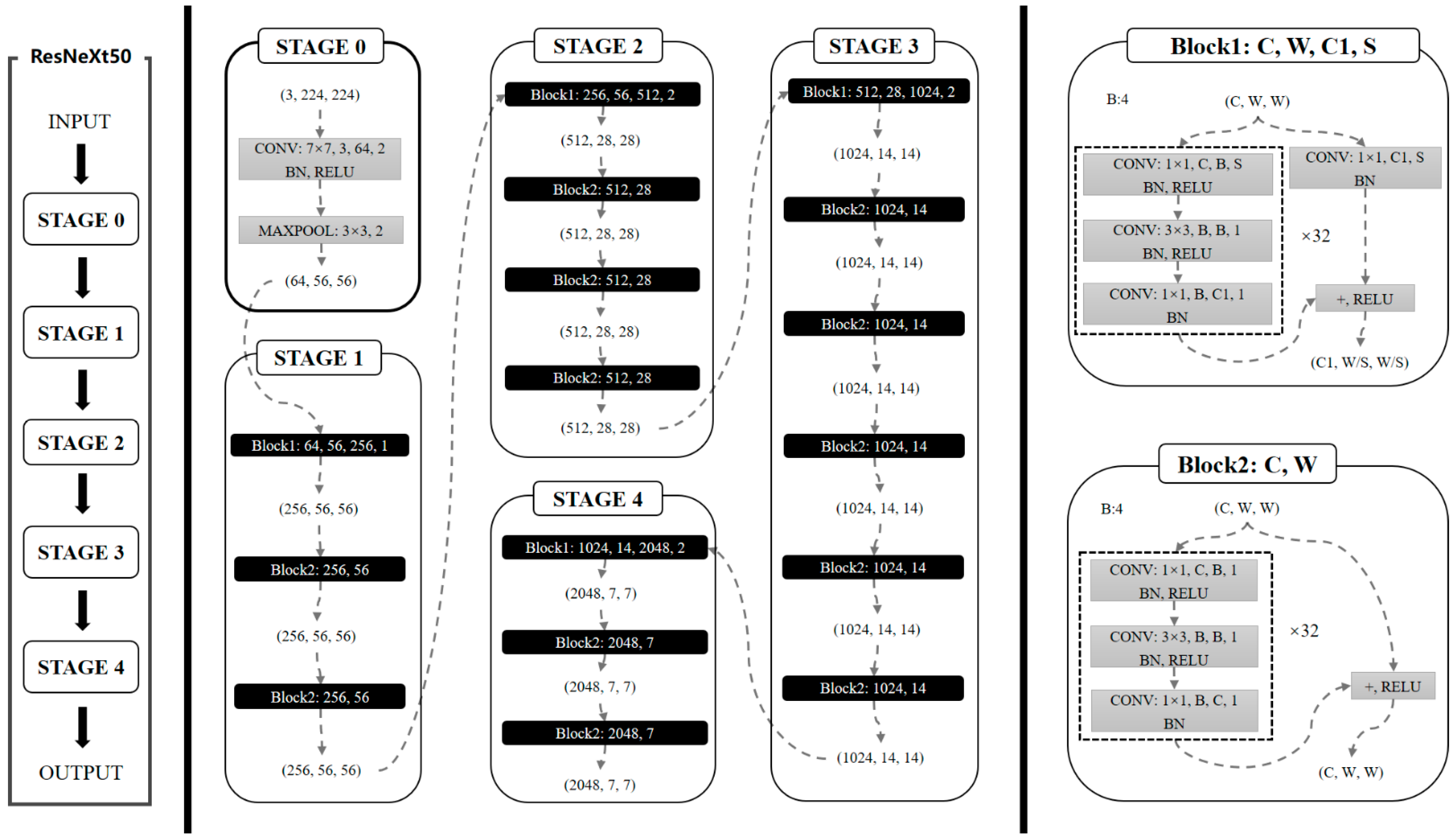
2.4. Model Structure
3. Materials and Methods
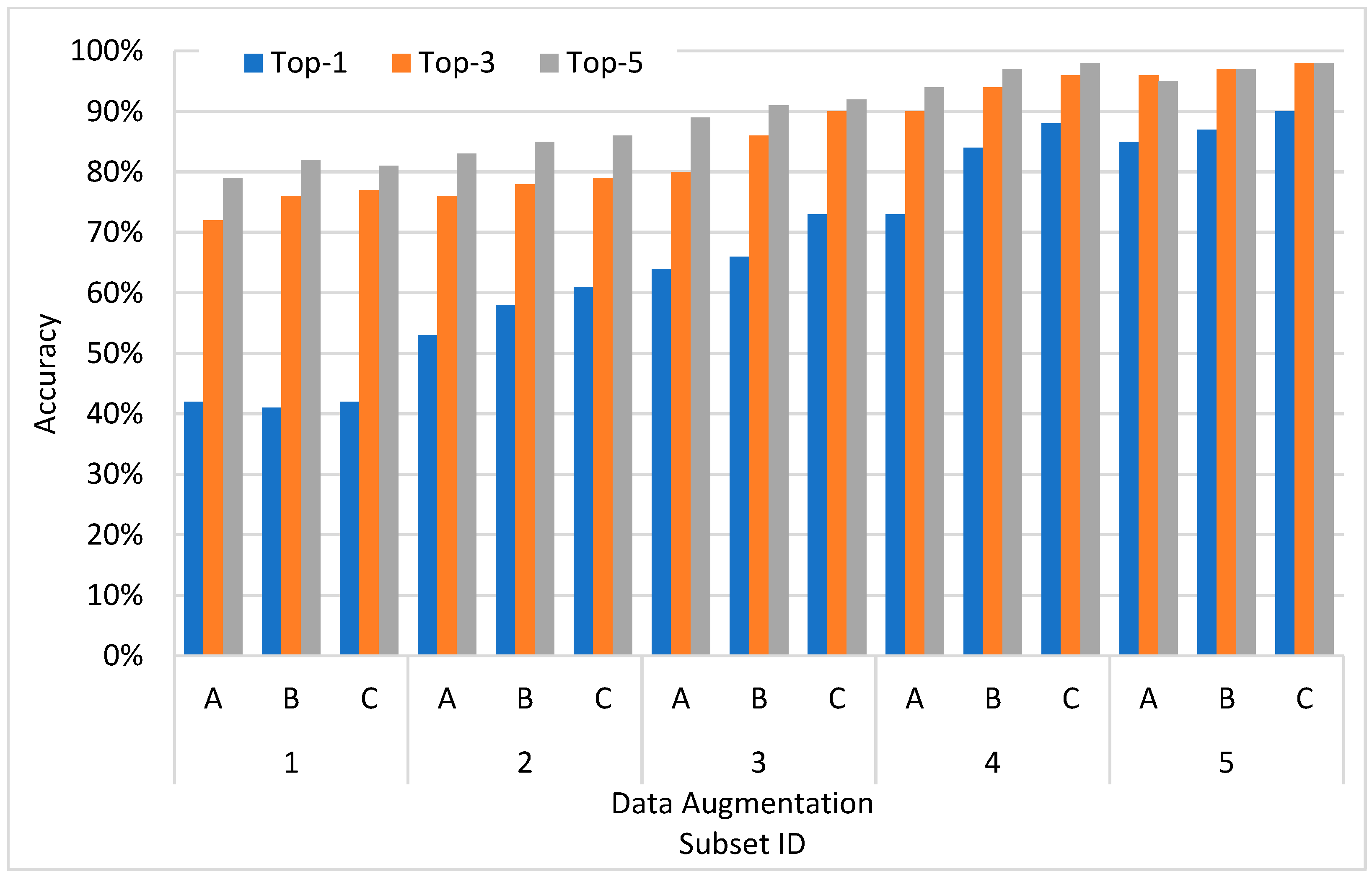
3.1. Dataset
3.2. Transfer Learning
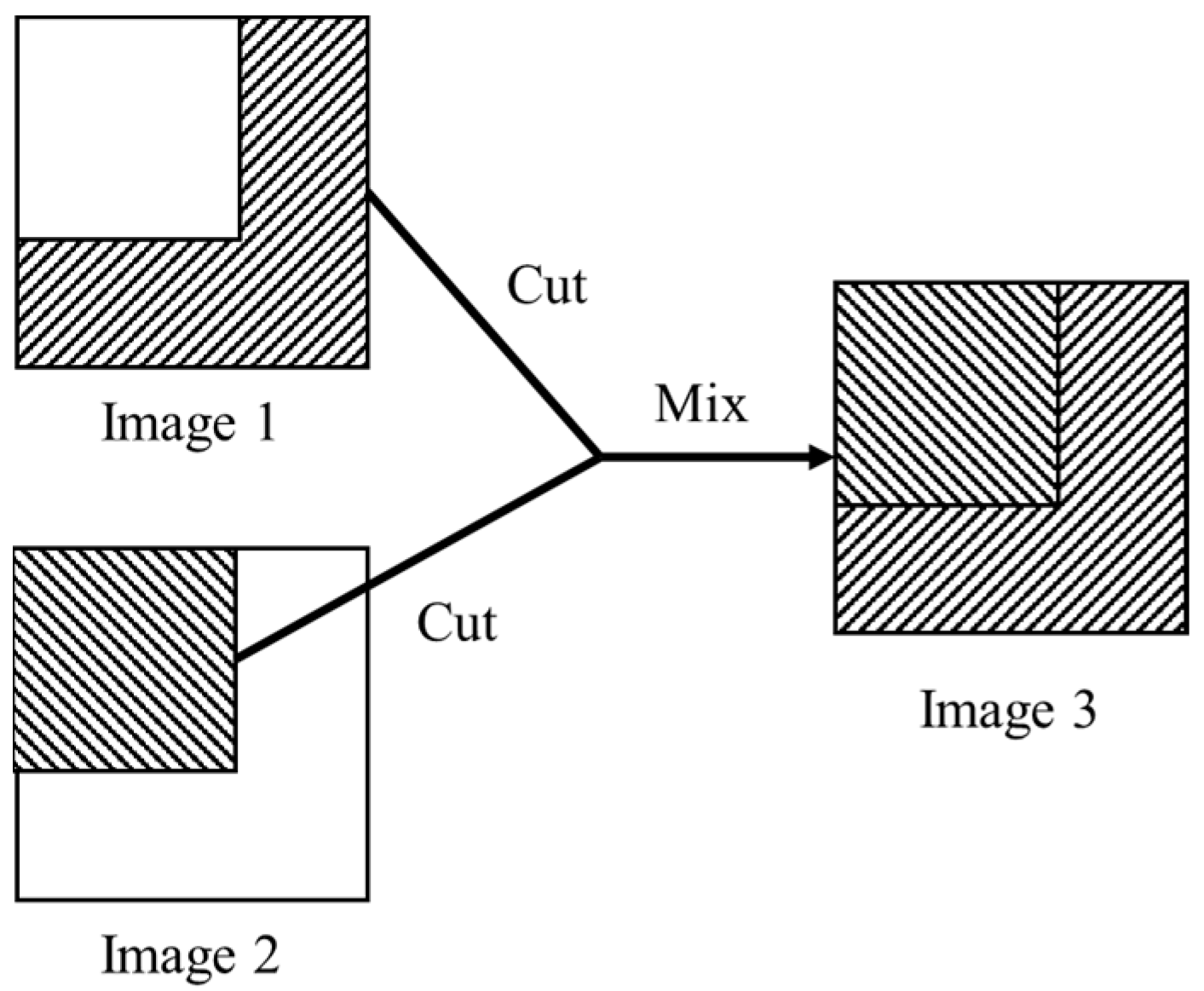
3.3. CutMix
3.4. Model Optimization
4. Results and Discussion
4.1. Results
4.2. Discussion
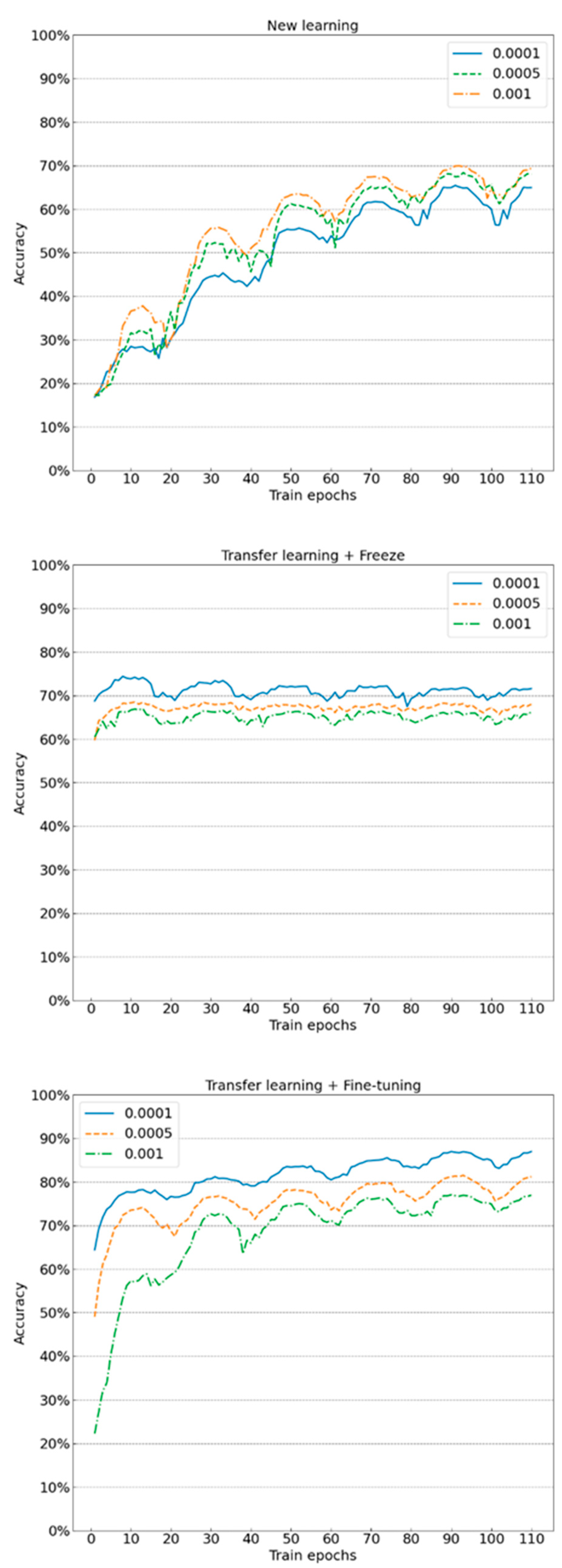
4.2.1. Learning Rate
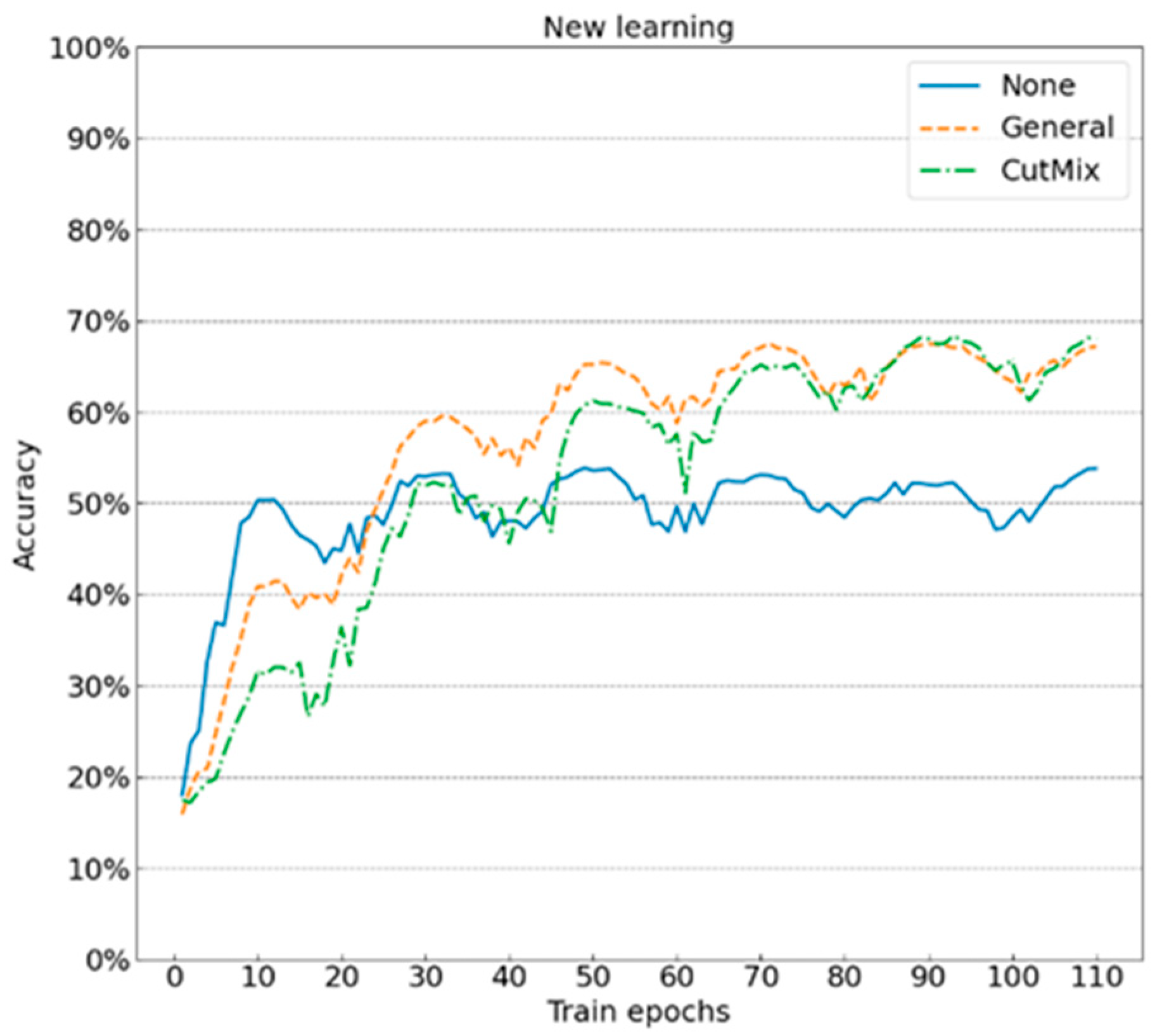
4.2.2. Data Augmentation
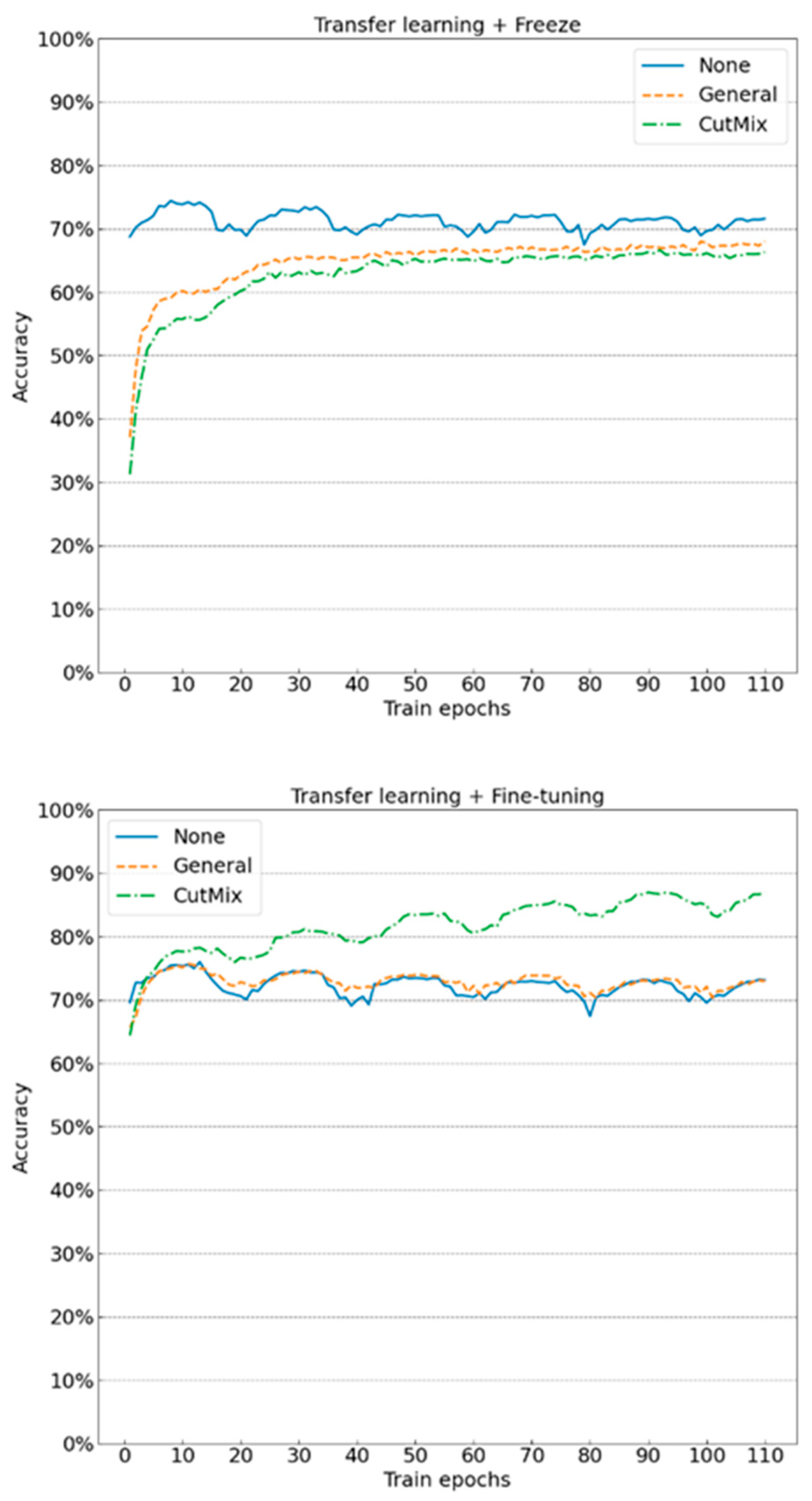
4.2.3. Transfer Learning
5. Conclusions
- Compared with other CNNs, the residual CNN can achieve better extraction of pest features. Compared with other research results, it has better classification performance with the average recognition accuracy as high as more than 70%;
- Learning rate has a greater influence than the data augmentation on model training stability. The selection of appropriate learning rate can expedite the model convergence so that the model can approach the optimal solution at a faster speed. When the new learning method is adopted, a larger learning rate should be adopted to expedite the learning speed of the model; when the transfer learning method is adopted, a small learning rate should be adopted to prevent the optimal solution being skipped. If an improper learning rate is selected, the training effect is greatly influenced, and the model even diverges in severe cases;
- It is important to select the right data augmentation. Appropriate data augmentation can help models to better learn sample features and reduce the overfitting problems caused by small datasets. Basic data augmentation should be adopted when new learning is adopted. When the model has no pre-training “knowledge”, an excessively complicated input interference prevents the models from learning basic features; when a combination of transfer learning + fine-tuning is adopted, it is recommended to use more complicated data enhancement (such as CutMix). If the model has pre-trained “knowledge”, strong input interference can help the models learn deep features;
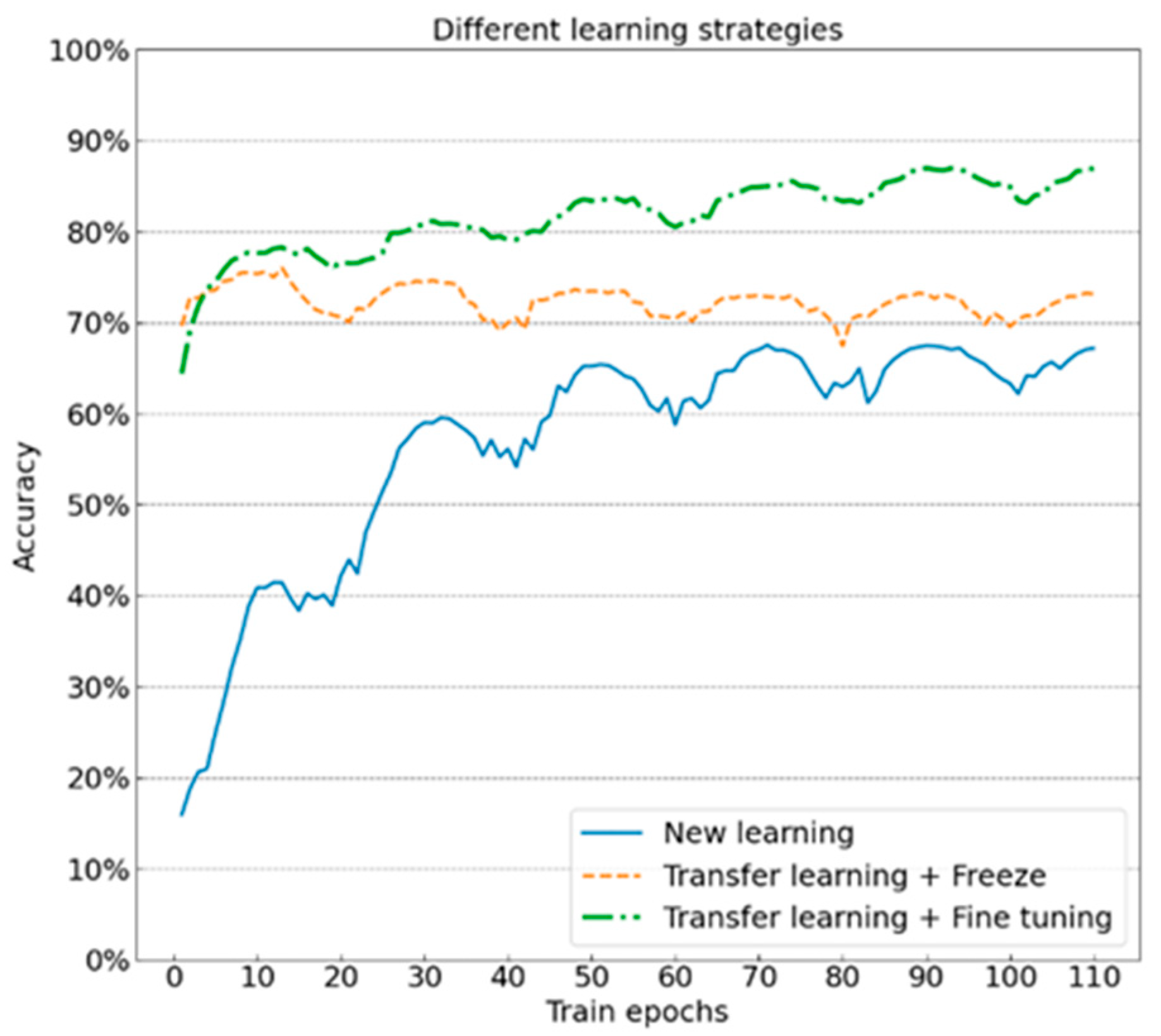
- Transfer learning can help models learn generically featured “knowledge” from other datasets. Learning the target dataset based on this “knowledge” can greatly improve the model performance. The training time needed for the model to achieve the same classification accuracy is greatly reduced, and the average classification accuracy is improved by 10~20% compared to the new learning model;
- The ability of transfer learning can be better exerted with fine-adjusting pre-training parameters than freezing pre-training parameters. Although the parameters of feature extraction in the transfer model are very close to the optimal solution, the fine-tuning is needed on this basis due to the differences between the datasets. According to the experimental results, the effect of the transfer learning model with fine-tuning or freezing is better than that of new learning, while the effect of the combination of transfer learning + fine-tuning is improved by 8% on average compared to the combination of transfer learning + freezing.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Estruch, J.J.; Carozzi, N.B.; Desai, N.; Duck, N.B.; Warren, G.W.; Koziel, M.G. Transgenic Plants: An Emerging Approach to Pest Control. Nat. Biotechnol. 1997, 15, 137–141. [Google Scholar] [CrossRef] [PubMed]
- Faithpraise, F.; Birch, P.; Young, R.; Obu, J.; Faithpraise, B.; Chatwin, C. Automatic Plant Pest Detection & Recognition Using K-Means Clustering Algorithm & Correspondence Filters. Int. J. Adv. Biotechnol. Res. 2013, 4, 1052–1062. [Google Scholar]
- Samanta, R.K.; Ghosh, I. Tea Insect Pests Classification Based on Artificial Neural Networks. Int. J. Comput. Eng. Sci. 2012, 2, 1–13. [Google Scholar]
- Al-Hiary, H.; Bani-Ahmad, S.; Reyalat, M.; Braik, M.; Alrahamneh, Z. Fast and Accurate Detection and Classification of Plant Diseases. Int. J. Comput. Appl. 2011, 17, 31–38. [Google Scholar] [CrossRef]
- Dyrmann, M.; Karstoft, H.; Midtiby, H.S. Plant Species Classification Using Deep Convolutional Neural Network. Biosyst. Eng. 2016, 151, 72–80. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. In Advances in Neural Information Processing Systems; Curran Associates, Inc.: Lake Tahoe, NV, USA, 2012; Volume 25. [Google Scholar]
- Ning, X.; Duan, P.; Li, W.; Zhang, S. Real-Time 3D Face Alignment Using an Encoder-Decoder Network with an Efficient Deconvolution Layer. IEEE Signal Processing Lett. 2020, 27, 1944–1948. [Google Scholar] [CrossRef]
- CVPR 2017 Open Access Repository. Available online: https://openaccess.thecvf.com/content_cvpr_2017/html/Huang_Densely_Connected_Convolutional_CVPR_2017_paper.html (accessed on 24 March 2022).
- Atlam, M.; Torkey, H.; El-Fishawy, N.; Salem, H. Coronavirus Disease 2019 (COVID-19): Survival Analysis Using Deep Learning and Cox Regression Model. Pattern Anal. Appl. 2021, 24, 993–1005. [Google Scholar] [CrossRef] [PubMed]
- Salem, H.; Attiya, G.; El-Fishawy, N. Gene Expression Profiles Based Human Cancer Diseases Classification. In Proceedings of the 2015 11th International Computer Engineering Conference (ICENCO), Cairo, Egypt, 29–30 December 2015; pp. 181–187. [Google Scholar]
- Deep Learning|Nature. Available online: https://www.nature.com/articles/nature14539 (accessed on 24 March 2022).
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. In Advances in Neural Information Processing Systems; Curran Associates, Inc.: Montréal, QC, Canada, 2015; Volume 28. [Google Scholar]
- Shelhamer, E.; Long, J.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 640–651. [Google Scholar] [CrossRef] [PubMed]
- Reyes, A.K.; Caicedo, J.C.; Camargo, J.E. Fine-Tuning Deep Convolutional Networks for Plant Recognition. CLEF 2015, 1391, 467–475. [Google Scholar]
- Zhang, H.; He, G.; Peng, J.; Kuang, Z.; Fan, J. Deep Learning of Path-Based Tree Classifiers for Large-Scale Plant Species Identification. In Proceedings of the 2018 IEEE Conference on Multimedia Information Processing and Retrieval (MIPR), Miami, FL, USA, 10–12 April 2018; pp. 25–30. [Google Scholar]
- Wu, X.; Zhan, C.; Lai, Y.-K.; Cheng, M.-M.; Yang, J. IP102: A Large-Scale Benchmark Dataset for Insect Pest Recognition. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 8779–8788. [Google Scholar]
- Xie, C.; Wang, R.; Zhang, J.; Chen, P.; Dong, W.; Li, R.; Chen, T.; Chen, H. Multi-Level Learning Features for Automatic Classification of Field Crop Pests. Comput. Electron. Agric. 2018, 152, 233–241. [Google Scholar] [CrossRef]
- Ayan, E.; Erbay, H.; Varçın, F. Crop Pest Classification with a Genetic Algorithm-Based Weighted Ensemble of Deep Convolutional Neural Networks. Comput. Electron. Agric. 2020, 179, 105809. [Google Scholar] [CrossRef]
- Nanni, L.; Maguolo, G.; Pancino, F. Insect Pest Image Detection and Recognition Based on Bio-Inspired Methods. Ecol. Inform. 2020, 57, 101089. [Google Scholar] [CrossRef] [Green Version]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2017, arXiv:1412.6980. [Google Scholar]
- Deng, L.; Wang, Y.; Han, Z.; Yu, R. Research on Insect Pest Image Detection and Recognition Based on Bio-Inspired Methods. Biosyst. Eng. 2018, 169, 139–148. [Google Scholar] [CrossRef]
- Bollis, E.; Pedrini, H.; Avila, S. Weakly Supervised Learning Guided by Activation Mapping Applied to a Novel Citrus Pest Benchmark. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Seattle, WA, USA, 14–19 June 2020; pp. 310–319. [Google Scholar]
- Ren, F.; Liu, W.; Wu, G. Feature Reuse Residual Networks for Insect Pest Recognition. IEEE Access 2019, 7, 122758–122768. [Google Scholar] [CrossRef]
- Kasinathan, T. Insect Classification and Detection in Field Crops Using Modern Machine Learning Techniques. Inf. Process. Agric. 2021, 12, 446–457. [Google Scholar] [CrossRef]
- Thenmozhi, K.; Srinivasulu Reddy, U. Crop Pest Classification Based on Deep Convolutional Neural Network and Transfer Learning. Comput. Electron. Agric. 2019, 164, 104906. [Google Scholar] [CrossRef]
- Ung, H.T.; Ung, H.Q.; Nguyen, B.T. An Efficient Insect Pest Classification Using Multiple Convolutional Neural Network Based Models. arXiv 2021, arXiv:2107.12189. [Google Scholar]
- Khan, M.K.; Ullah, M.O. Deep Transfer Learning Inspired Automatic Insect Pest Recognition. In Proceedings of the 3rd International Conference on Computational Sciences and Technologies; Mehran University of Engineering and Technology, Jamshoro, Pakistan, 17–19 February 2022; Volume 8. [Google Scholar]
- Nanni, L. High Performing Ensemble of Convolutional Neural Networks for Insect Pest Image Detection. Ecol. Inform. 2022, 67, 101515. [Google Scholar] [CrossRef]
- Yang, X.; Luo, Y.; Li, M.; Yang, Z.; Sun, C.; Li, W. Recognizing Pests in Field-Based Images by Combining Spatial and Channel Attention Mechanism. IEEE Access 2021, 9, 162448–162458. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. arXiv 2015, arXiv:1512.03385. [Google Scholar]
- Xie, S.; Girshick, R.; Dollár, P.; Tu, Z.; He, K. Aggregated Residual Transformations for Deep Neural Networks. arXiv 2017, arXiv:1611.05431. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the Inception Architecture for Computer Vision. arXiv 2015, arXiv:1512.00567. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2015, arXiv:1409.1556. [Google Scholar]
- El-Shafai, W.; Almomani, I.; AlKhayer, A. Visualized Malware Multi-Classification Framework Using Fine-Tuned CNN-Based Transfer Learning Models. Appl. Sci. 2021, 11, 6446. [Google Scholar] [CrossRef]
- Yun, S.; Han, D.; Oh, S.J.; Chun, S.; Choe, J.; Yoo, Y. CutMix: Regularization Strategy to Train Strong Classifiers with Localizable Features. arXiv 2019, arXiv:1905.04899. [Google Scholar]
- Duchi, J.; Hazan, E.; Singer, Y. Adaptive Subgradient Methods for Online Learning and Stochastic Optimization. J. Mach. Learn. Res. 2011, 12, 2121–2159. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Related Work | Model | IP102 [16] | D0 [17] |
|---|---|---|---|
| [18] | GAEnesmble | 67.1% | 98.8% |
| [18] | SMPEnsemble | 66.2% | 98.4% |
| [21] | HierarchicalModel | ||
| [19] | SaliencyEnsemble | 61.9% | |
| [22] | Multiple Instance Learning | 60.7% | |
| [18] | SMPEnsemble | 66.2% | 98.4% |
| [16] | DeepFeature | 49.5% | |
| [23] | FR·ResNet | 55.2% | |
| [22] | Inception-V4 | 48.2% | |
| [22] | ResNet50 | 49.4% | |
| [22] | MobileNet-B0 | 53.0% | |
| [22] | DenseNet121 | 61.1% | |
| [22] | EfficientNet-B0 | 60.7% | |
| [17] | Multi-level framework | 89.3% | |
| [24] | CNN | 90.0% | |
| [25] | Deep CNN with augmentation | 96.0% | |
| [26] | Ensemble model | 74.1% | 99.8% |
| [27] | Inception V3 | 81.7% | |
| [27] | VGG19 | 80% | |
| [28] | Ensemble model | 74.11% | |
| [29] | STN-ResNest | 73.29% | |
| Presented Work | ResNeXt-50 (32 × 4d) | 86.9% |
| Group ID | Learning Method | Data Augmentation | Learning Rate | Training Loss | Test Losses | Training Accuracy | Testing Accuracy |
|---|---|---|---|---|---|---|---|
| 1 | New Learning | A | 0.0001 | 0.0172 | 3.4692 | 99.30% | 48.63% |
| 2 | 0.0005 | 0.0146 | 4.5273 | 99.46% | 49.27% | ||
| 3 | 0.0010 | 0.0113 | 4.4682 | 99.59% | 53.78% | ||
| 4 | B | 0.0001 | 0.6247 | 1.4675 | 82.14% | 64.83% | |
| 5 | 0.0005 | 0.4834 | 1.5741 | 84.83% | 66.06% | ||
| 6 | 0.0010 | 0.4653 | 1.5488 | 85.73% | 67.16% | ||
| 7 | C | 0.0001 | 2.3377 | 1.4835 | 47.71% | 60.01% | |
| 8 | 0.0005 | 2.0608 | 1.2979 | 56.50% | 68.11% | ||
| 9 | 0.0010 | 1.9613 | 1.1765 | 57.88% | 69.75% | ||
| 10 | Transfer Learning + Freeze | A | 0.0001 | 0.0040 | 1.8967 | 99.81% | 71.42% |
| 11 | 0.0005 | 0.2828 | 1.3341 | 91.72% | 67.97% | ||
| 12 | 0.0010 | 0.1887 | 1.7385 | 94.43% | 66.24% | ||
| 13 | B | 0.0001 | 1.1873 | 1.1250 | 65.98% | 67.99% | |
| 14 | 0.0005 | 0.9802 | 1.1283 | 70.89% | 68.05% | ||
| 15 | 0.0010 | 0.9170 | 1.1823 | 72.83% | 69.13% | ||
| 16 | C | 0.0001 | 2.4079 | 1.2961 | 47.60% | 66.65% | |
| 17 | 0.0005 | 2.2698 | 1.1673 | 51.19% | 69.01% | ||
| 18 | 0.0010 | 2.2559 | 1.1121 | 51.86% | 70.14% | ||
| 19 | Transfer learning + Fine-tuning | A | 0.0001 | 0.0030 | 1.8918 | 99.85% | 72.64% |
| 20 | 0.0005 | 0.0042 | 2.5541 | 99.82% | 67.27% | ||
| 21 | 0.0010 | 0.0056 | 2.9742 | 99.75% | 63.55% | ||
| 22 | B | 0.0001 | 0.1768 | 1.5413 | 94.22% | 73.86% | |
| 23 | 0.0005 | 0.2522 | 1.5639 | 91.74% | 72.33% | ||
| 24 | 0.0010 | 0.3476 | 1.4343 | 88.96% | 71.99% | ||
| 25 | C | 0.0001 | 1.0959 | 0.5157 | 79.11% | 86.95% | |
| 26 | 0.0005 | 1.2358 | 0.6788 | 75.64% | 81.50% | ||
| 27 | 0.0010 | 1.5114 | 0.7895 | 69.26% | 77.06% |
| Model | Accuracy | Average Precision | Average Recall | Average F1 Score |
|---|---|---|---|---|
| Densenet121 | 81.55% | 78.03% | 73.93% | 75.92% |
| Efficientnet-B0 | 80.28% | 78.75% | 73.66% | 76.12% |
| VGG19 | 78.80% | 78.21% | 74.54% | 76.33% |
| ResNet-50 | 71.20% | 70.06% | 65.39% | 67.64% |
| ResNeSt-50 | 80.28% | 78.47% | 71.47% | 74.81% |
| ResNeXt-50 (32 × 4d) | 86.50% | 84.62% | 85.55% | 85.08% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, C.; Zhen, T.; Li, Z. Image Classification of Pests with Residual Neural Network Based on Transfer Learning. Appl. Sci. 2022, 12, 4356. https://doi.org/10.3390/app12094356
Li C, Zhen T, Li Z. Image Classification of Pests with Residual Neural Network Based on Transfer Learning. Applied Sciences. 2022; 12(9):4356. https://doi.org/10.3390/app12094356
Chicago/Turabian StyleLi, Chen, Tong Zhen, and Zhihui Li. 2022. "Image Classification of Pests with Residual Neural Network Based on Transfer Learning" Applied Sciences 12, no. 9: 4356. https://doi.org/10.3390/app12094356
APA StyleLi, C., Zhen, T., & Li, Z. (2022). Image Classification of Pests with Residual Neural Network Based on Transfer Learning. Applied Sciences, 12(9), 4356. https://doi.org/10.3390/app12094356