1. Introduction
A gravity piston sampler is an important geological tool that uses its gravity as the driving force to obtain in situ samples. Since the design proposal of the Kullenberg-type gravity sampler in 1947 [
1], it has been widely used for the acquisition of deep-sea ultra-long in situ samples [
2,
3], nearshore sediment samples [
4], and in situ lake sediment samples [
5]. In recent years, due to the research and development of gas hydrate, the acquisition of high-fidelity in situ samples based on a gravity piston sampler [
6,
7,
8] has become a hot research topic. Whether for the acquisition of deep-sea, nearshore, or lake sediments, how to improve the sampling efficiency and ensure continuous and undisturbed sediment samples have been the focus of much research. When sampling with a gravity piston sampler, the length of the installed sampling tube may be different from the actual penetration depth, which could lead to accidents, such as breakage of the sample tube when the size of the sample tube is greater than the penetration depth or failure to obtain the maximum length of a continuous in situ sample [
9] when the size is less than the penetration depth. Therefore, the prediction of penetration depth according to the geological characteristics of the sampling area before the release of the gravity sampler can help improve the safety and efficiency of the sampler.
In previous studies of gravity sampler penetration depth, scholars mainly used force analysis and energy conservation to study analytical solutions. Li et al. [
10] and Du et al. [
9] obtained the analytical solution of the penetration depth equation based on the energy conservation equation through force analysis of the gravity sampler. They verified it with actual offshore sampling data. However, due to the complicated penetration process in the sampling area and problems of recording and operating errors in the real measured data at sea, the measured penetration data were not accurate, and the amount of data was small. To study the penetration process and factors of gravity samplers more accurately and controllably, Du [
11] designed a gravity sampling physical test model in 2014 to address the problem of the small amount of data and lack of accurate data recording of the penetration process, conducted dozens of sets of tests, obtained a large amount of accurately recorded data, and proposed a new analytical solution model based on the tests. In recent years, scholars have also tried to discuss more influencing factors of gravity sampling penetration depth, such as friction coefficient and sediment characteristics [
12,
13]. However, the basic idea of past research was still to use the energy balance of penetration work and friction consumption work to solve the equation to determine the penetration depth, and there has been no substantial breakthrough in the modeling tools but only reduces the error value by parameters with less influencing factors. The complexity of the sampler penetration process, inaccuracies and other factors, and errors caused by human operation remain challenges to be eliminated. Therefore, there is an urgent need to propose a new means to model and study the penetration depth of gravity samplers.
Machine learning, the best-known class of artificial intelligence algorithms, is capable of efficiently approaching a wide range of data problems. Machine learning is divided into two main categories: supervised machine learning and unsupervised machine learning [
14]. Supervised machine learning is used for training data with outcome labels, and unsupervised machine learning filters feature data, clustering without outcome labels. Supervised machine learning is further divided into two types of problems, classification and regression, depending on the result labels. Classification applies to data with a definite outcome, and regression applies to data with an uncertain type of outcome. Machine learning and deep learning techniques have been proven to be robust and promising tools in many geotechnical applications, such as ground motion prediction [
15], soil liquefaction [
16,
17], landslides risk assessment [
18,
19,
20,
21], soil spatial prediction [
22], soil hydraulic properties [
23], geophysical exploration [
24,
25,
26], etc. The above studies show that geological problems with a certain amount of data are well suited to be solved by machine learning methods. As for the gravity sampling penetration depth, it is more appropriate to choose the regression method in supervised machine learning because of its many influencing factors and the characteristic that the penetration depth results in data rather than categories. However, no one has yet conducted a gravity sampling penetration depth study using a machine learning approach. Machine learning methods can be applied to gravity sampling penetration depth studies, and the accuracy of the model predictions is the focus of this paper.
In this context, in this study, we aim to investigate the feasibility and accuracy of machine learning models for calculations of gravity piston sampler penetration depth. More specifically, the MLP neural network model is applied in a gravity sampler penetration depth study by using actual gravity sampling data collected at sea and the physical model test data for training. Moreover, the prediction accuracies of machine learning models of penetration depth of that of various analytical solution models are further compared to investigate the main factors affecting accuracy. The process of machine learning modeling and predicting results from the machine learning model proposed in this paper can provide practical guidance for gravity sampler penetration depth and provide a scientific indication of significance for similar data regression analysis problems in marine engineering geology.
2. Applied Machine Learning Model
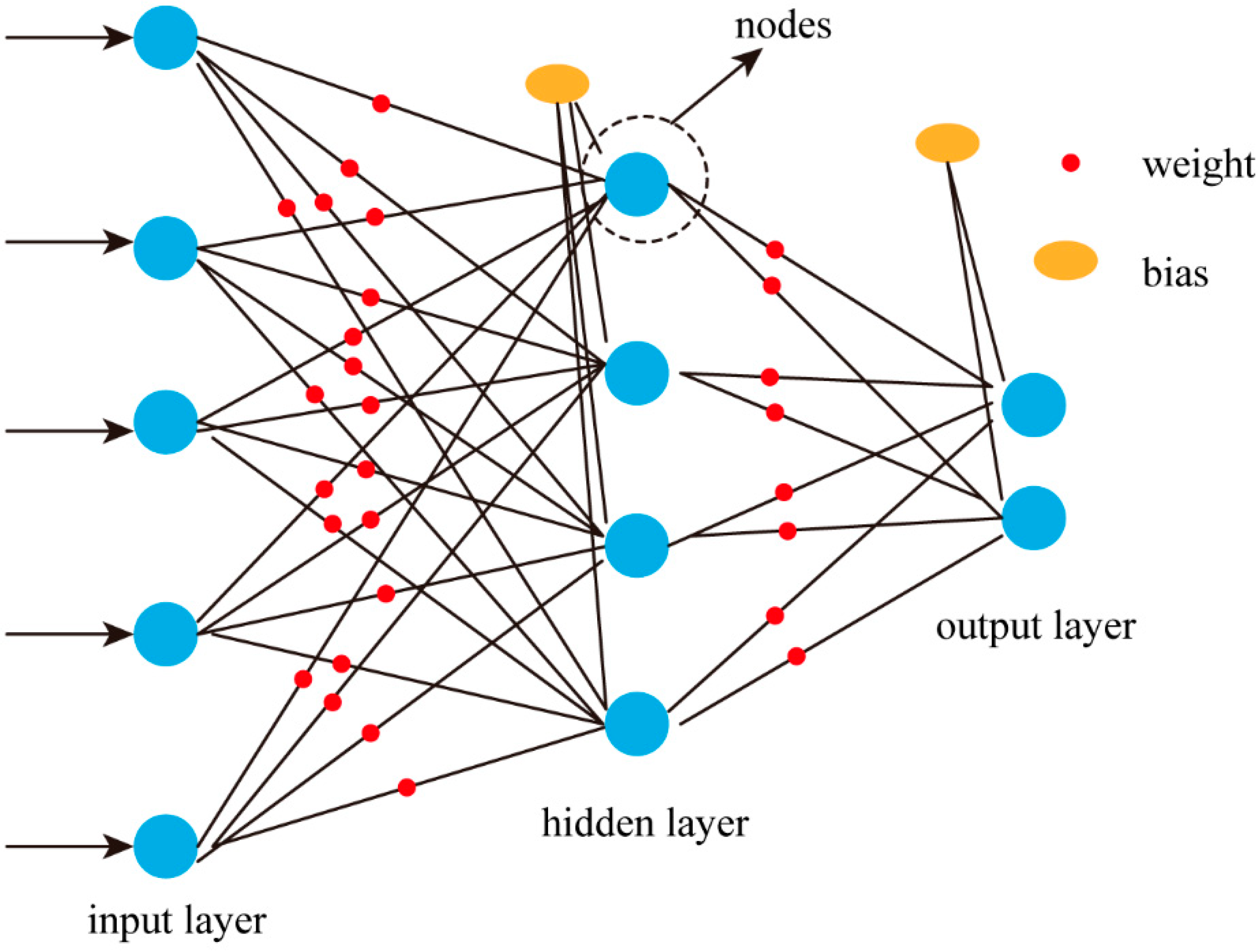
The MLP (multilayer perceptron, also known as artificial neural network) [
27] is a simplified biological model that mimics signal propagation in biological nerves and is also one of the most widely used and studied neural network models. It is also called feedforward (
Figure 1) because the information flows through a function of x, through an intermediate computational process used to define f, and finally to the output, y. There is no feedback connection between the output of the model and the model itself. When feedforward neural networks are extended to include feedback connections, they are called recurrent neural networks. MLP consists of a multilayer neural network in which the input and output layers consist of a single-layer network. The hidden layer can be a single layer or a multi-layer network, and each layer consists of multiple neurons. Each neural network consists of multiple neurons, each neuron is a perceptron, the neurons in each layer are interconnected, and the connections are fully connected. In a nutshell, the structure of a BP neural network [
28] is that the input layers receives a stimulus and passes it to the hidden layers. The output layers compare the results. Suppose the output layer compares the results and is not correct. In that case, it returns to modify the weights of neuron interconnections, also known as the feedforward multilayer network algorithm trained according to the error backpropagation method. Although a large number of new machine learning algorithms have been created, the backpropagation method of BP neural networks is the basis for the vast majority of model training.
A feedforward neural network is mathematically represented as:
where
x is the input parameter;
and
are the weights from input-layer to hidden-layer and weights from hidden-layer to output-layer, respectively;
and
are the deviation parameters;
M is the number of nodes in the hidden layer;
d is the number of nodes in the input layer; and
is the transfer function that performs a nonlinear transformation of the summation input.
The objective of the algorithm is to reduce the error between the computed value and the actual value through a training series, and the error
E can be defined as:
where
p is the total number of training patterns, and
Ep is the error of the
p-th training pattern obtained from the following equation:
where
N is the total number of output nodes,
k is the output of the
k-th output node, and
tk is the target output of the
k-th output node.
After each error is calculated, feedback is propagated forward. The weight values are updated to bring the network closer to the actual expression values until all training data are trained. A set of training data is usually trained several times; each training is called a generation (Epoch), and generally, the training stops when the set parameter conditions are reached.
4. Results
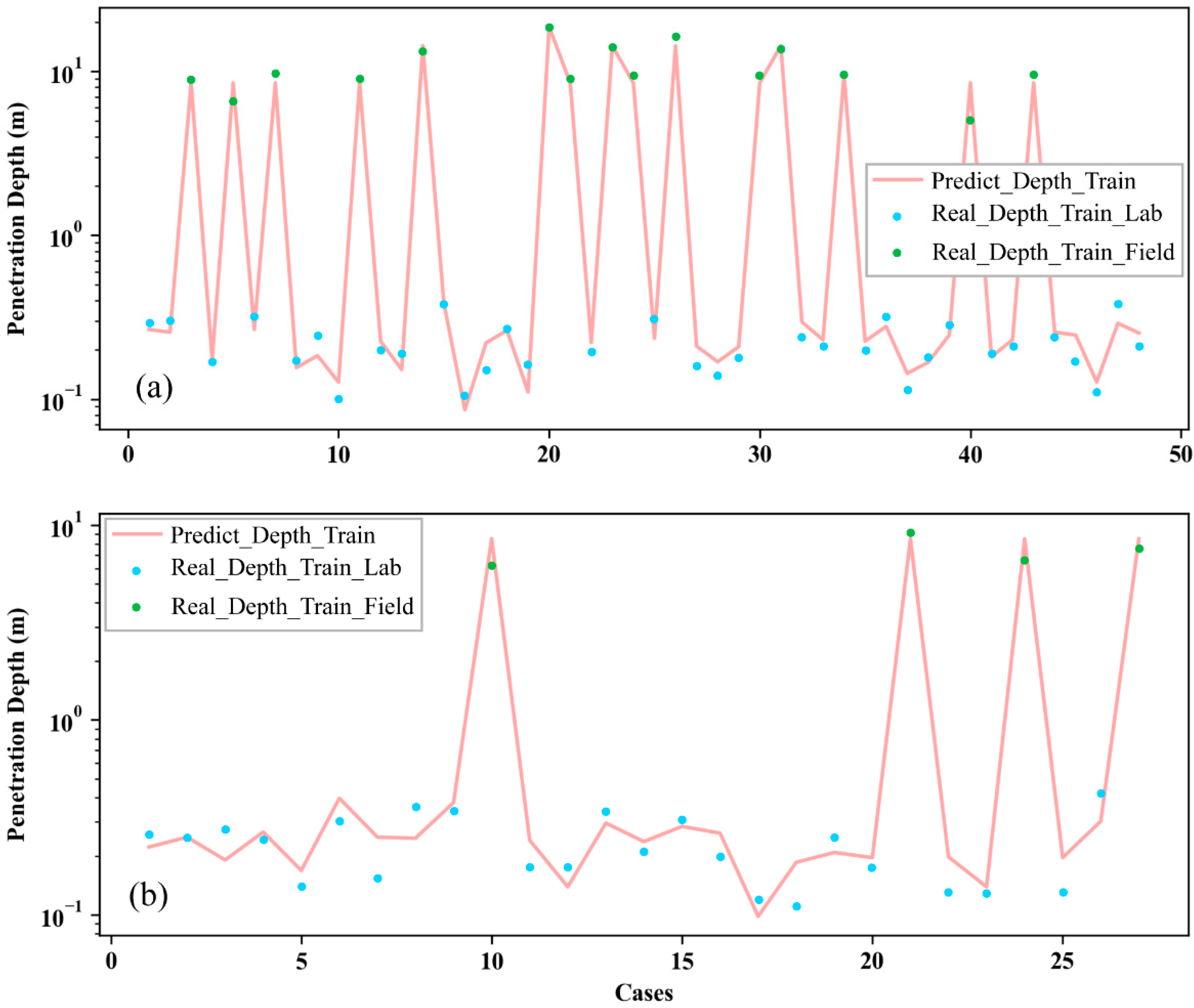
Figure 4 shows the gravity sampler penetration depth prediction results using the training and test sets of the established machine learning model. The results predicted by the model are in good agreement with the actual results in both the training and test sets. As shown in
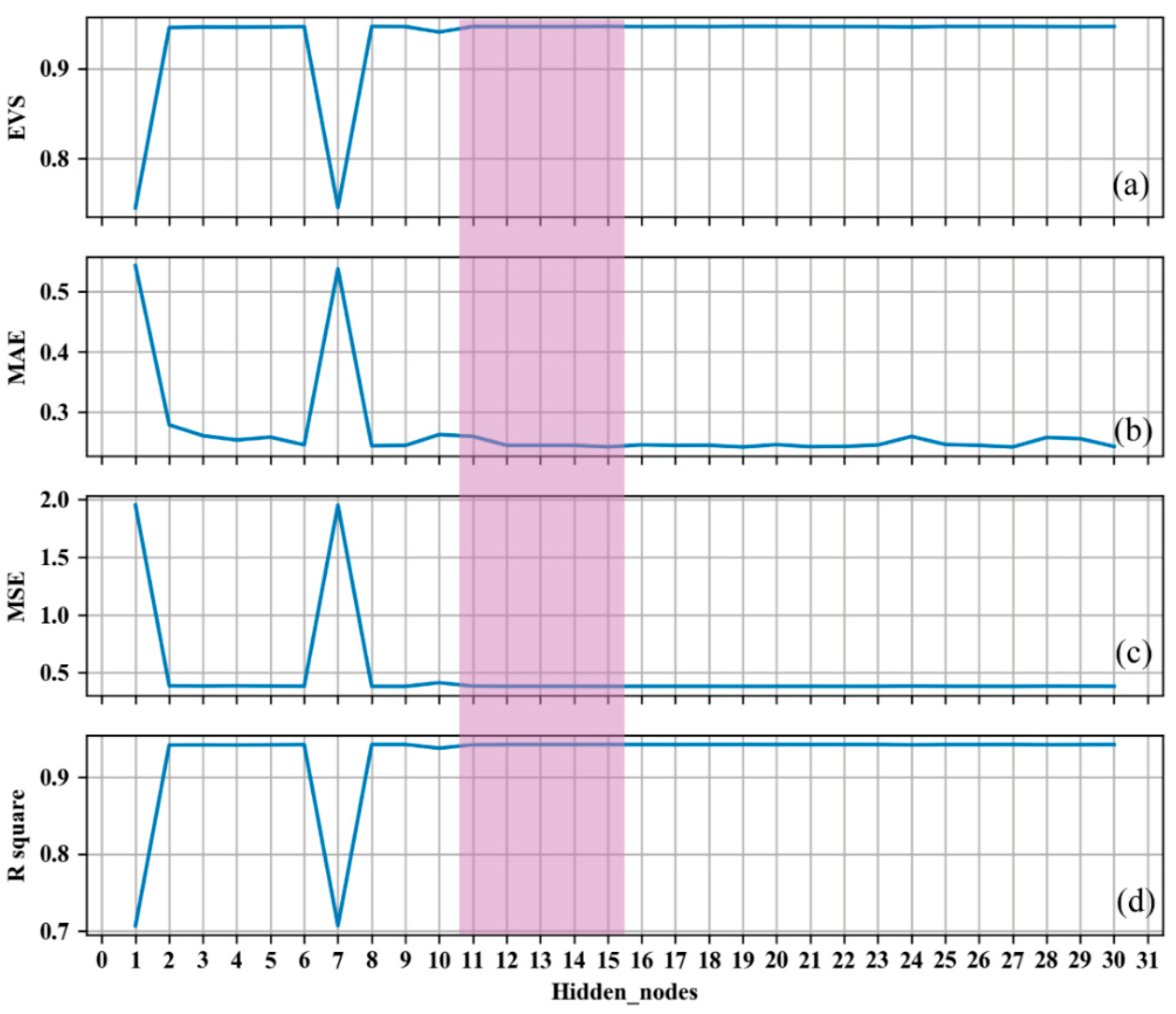
Figure 5, the prediction error is small, despite the significant difference in gravity sampler parameters between the data measured at sea and the physical model tests. The prediction accuracy statistics of the train and test sets are shown in
Table 2. Both datasets showed promising results on all four statistical scales, and the training set results are slightly better than those of the test set.
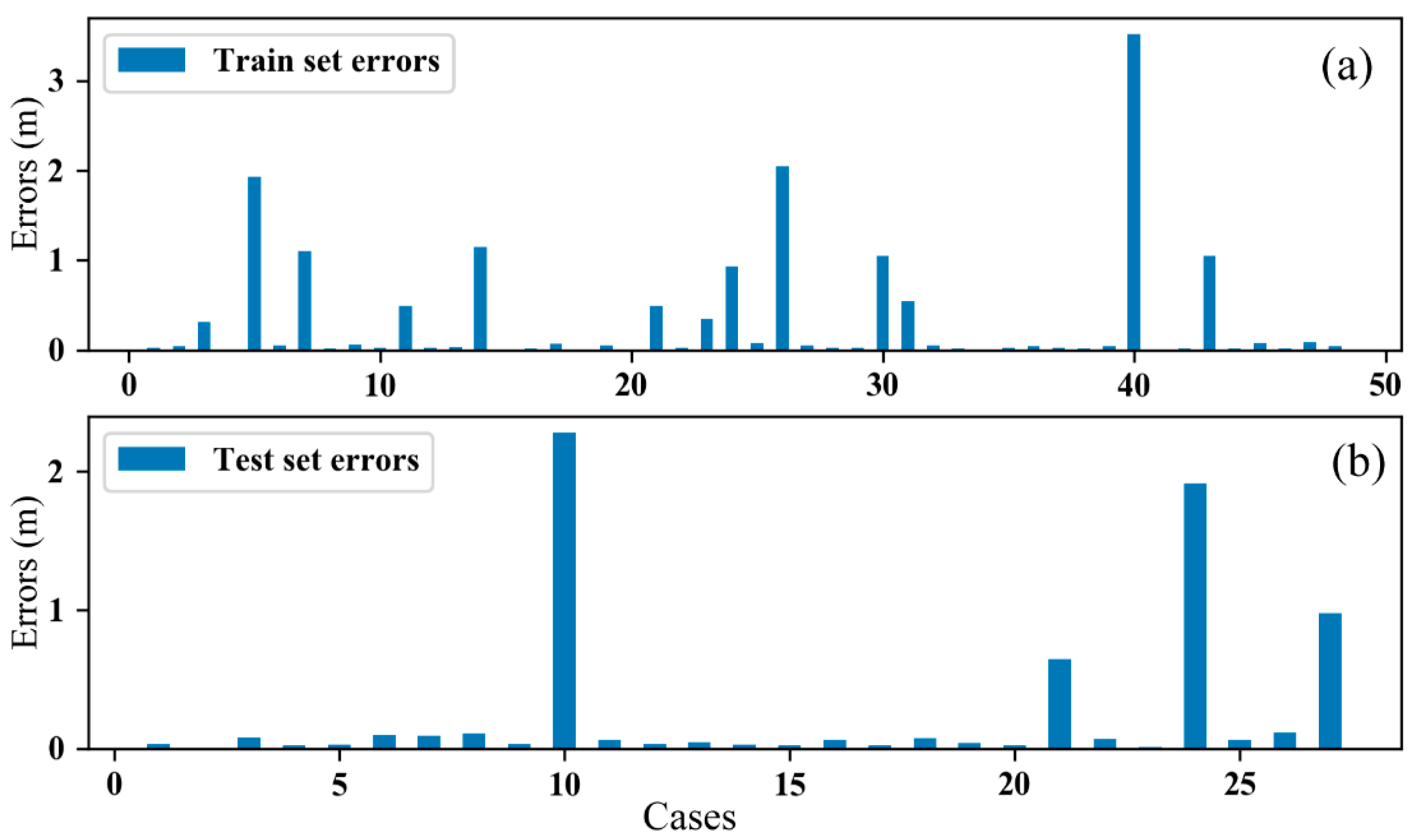
The absolute values of the error between predicted and real penetration depth are shown in
Figure 4. The training set error of most cases is less than 1 m. There are six cases with error values between 1 and 2 m and one case with an error more than 3 m in the train set. As for the test set, 23 cases of 27 are less than 0.5 m, and there are only 2 cases with errors over 1 m. Many factors affect the penetration depth of gravity sampling (geology, marine environment, seafloor topography, etc.). Even if the same sampler is used under the same geological conditions, the depth of each sample is not the same, and the error can reach 2~3 m [
9]. Therefore, numerical model prediction results within 2~3 m are acceptable. The machine learning model used in the paper is exceptionally accurate, as most errors are less than 1 m.
After analyzing the data, we found that the 18 examples with large error values were all data measured at sea. There are two main reasons for this situation: (1) the amount of data of the same type and (2) the error of the data itself. When there are only 19 actual at-sea data point with a slight difference in sampler quality and 56 physical model test data, the model will tend toward the accuracy of the physical model test. Another reason is that human operation and recording errors of at-sea sampling are more significant than those in physical model tests. The high value of the prediction error for the offshore sampling depth is due to the typical machine learning model training problem caused by the relatively small amount of offshore sampling data. In the training process of machine learning models, the accuracy of the model can be increased when the training data sample is large enough. When the training data sample is insufficient, errors tend to be increased. The training data used in this paper are limited due to the difficulty of obtaining data for ocean gravity sampling. The model prediction error will decrease with increased offshore gravity sampling penetration depth data.
5. Discussion
5.1. Accuracy and Applicability of Machine Learning Model
Machine learning has different characteristics when applied in different fields, and there are many factors that affect the accuracy of machine learning. When machine learning is applied to the field of marine geology, several main factors affect the prediction accuracy:
- (1)
Whether the geological problem is suitable for machine learning models;
Although machine learning models can be applied to many problems, they still cannot solve all problems. Machine learning methods are suitable for solving problems that can be accurately calculated quantitatively; have a large amount of accurate associated research data; and require experience, such as geohazard prediction, weather forecasting, geological phenomenon identification, etc. Some geological problems that do not have associated data or for which the amount of data does not meet machine learning requirements, such as tectonic geology and geological hazard on-site monitoring, are not suitable for machine learning solutions.
- (2)
Whether the selected input factors are complete and representative of the entire geological process;
Due to their complexity, geological problems are often subjected to various internal and external geodynamic effects. For example, there may be more than a dozen factors influencing the evaluation of submarine landslide hazards. However, we do not need to bring all the influencing factors into the model for calculation because there is a specific correlation between many influencing factors (such as wind speed and waves). In addition, having too many influencing factors is not conducive to modeling efficiency. Therefore, when we choose the input parameters of the machine learning model, we need to select several factors with the most significant degree of influence through professional knowledge analysis. Having too many chosen factors is not conducive to data acquisition and modeling efficiency, and having too few factors is not representative of the geologic process.
- (3)
The quality and quantity of the data;
The core objective of machine learning is to obtain the desired patterns from a large amount of available data through numerical methods. Therefore, the quality and quantity of the data itself are essential. When machine learning is applied in data-rich fields, such as the Internet and finance, the amount of data generated per second is several Gs, so there is no data volume problem. However, the geological field does not have a large amount of data related to many issues due to the difficulty and high cost of obtaining data, which are the main reasons for some errors in model prediction results. Like the gravity sampler penetration depth problem studied in this paper, there are only 19 groups of real sampling data from the seafloor. Each data group contains a certain amount of human and environmental errors, so it is challenging to represent the sampling penetration process accurately through the data. Therefore, there must be relative error values in the prediction results.
- (4)
Whether an appropriate machine learning model has been selected to solve the geological problem;
Different machine learning methods can solve the same geological problem, and it is essential to choose a suitable algorithm. Even if the research problem is identified as a specific category of regression, fitting, clustering, etc., each category has multiple algorithms. Furthermore, new machine learning models are being developed all the time.. When it is impossible to determine which algorithm is suitable for a geological problem, more than one should be tried. The appropriate algorithm should be selected through analysis and comparison. In addition, there is no best algorithm—only the algorithm that meets the accuracy needs of the research problem through data, algorithm selection, and model training.
5.2. Comparison of Different Penetration Depth Models
To demonstrate the accuracy of the gravity sampler penetration depth machine learning model developed in this paper, three other t analytic solution models, defined as AS1 [
9], AS2 [
11], and AS3 [
10], were used for computation and comparison. The 75 groups of gravity sampling data analyzed in this paper were computed using machine learning models and three other analytical solution models. The penetration depths calculated by the four models were analyzed in comparison to the actual penetration depths obtained using statistical methods (
MSE,
MAE,
EVS, and
R2) mentioned in
Section 3.2.
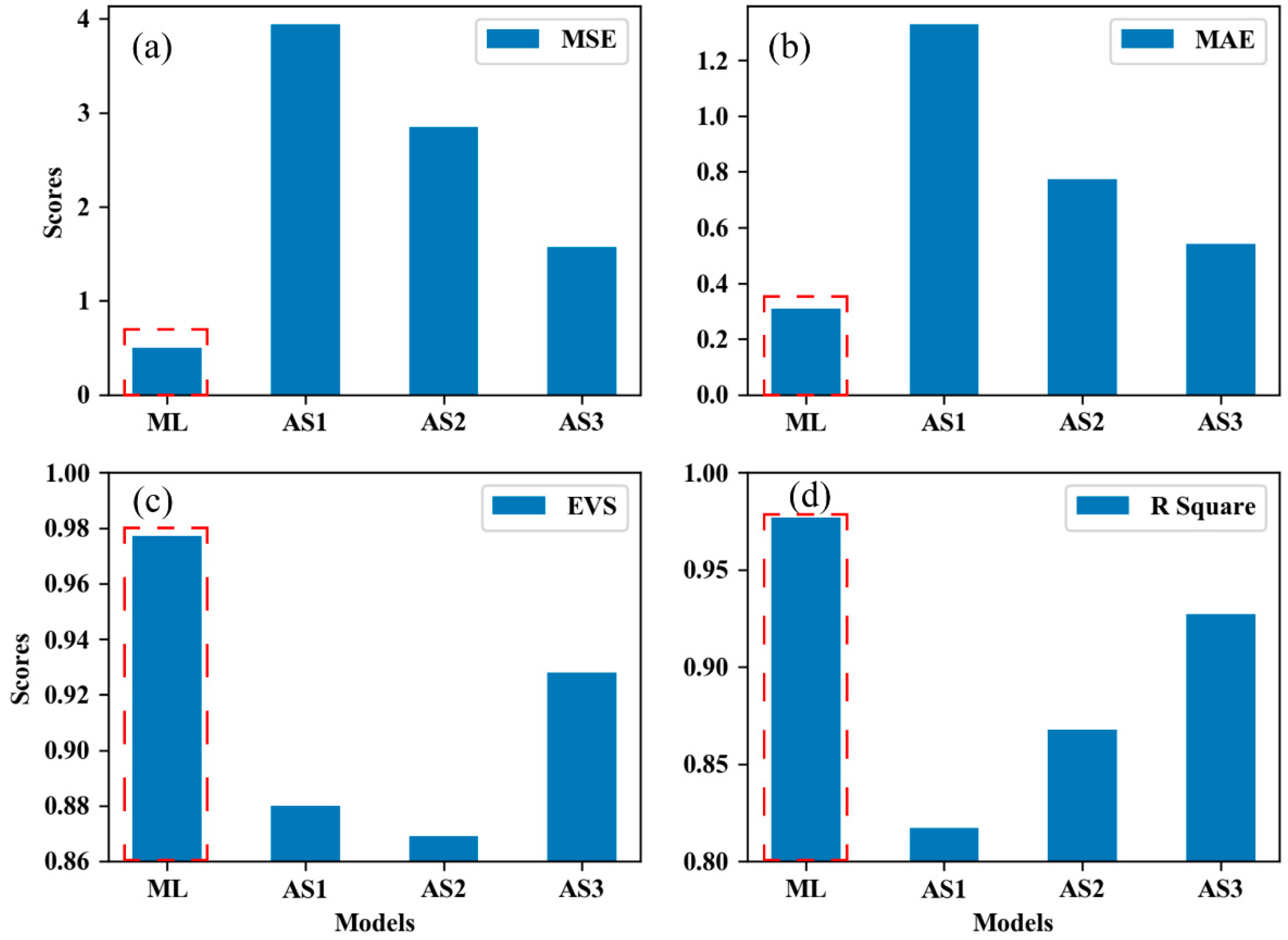
The comparison results of the accuracy of different gravity sampling penetration depth prediction models are demonstrated in
Table 3 and
Figure 6. It well known that smaller
MSE and
MAE and larger
EVS and
R2 values indicate more accurate prediction results. In terms of statistical metrics, the ML model yields the lowest
MSE and
MAE and the highest
EVS and
R2 values. As for the other three analytic solution models, AS3 performs best on
MSE,
MAE, and
EVS, and AS2 performs best on
R2. Therefore, the accuracy of the four models is: ML > AS3 > AS2 > AS1. Moreover, the performance of the machine learning model is clearly and substantially ahead of that of the other analytical solution models.
The prediction accuracy of machine learning models is much higher than that of various analytical solution models because the two computational methods employ very different processes. The traditional analytical solution model mainly analyzes the force of the gravity sampler penetration process, derives the energy of each component and process, and solves the equation according to energy conservation. This way of solving the energy conservation equation presents the following problems: (1) the calculation of each process is approximated, leading to the existence of certain errors; (2) there is a certain abbreviation in the calculation process, for example, AS2 does not consider the cutter head cutting work; and (3) because it involves sliding friction work between the sampling tube and the sediment, cutting work, and other processes, the calculation requires the estimation and approximation of the friction coefficient and other parameters, so it is difficult to calculate accurately. The machine learning model only needs to establish the numerical relationship between the input parameters and the penetration depth directly through continuous training and backpropagation based on the data, skipping the complex and extensive approximation process of various forces and energy calculations. Therefore, the prediction results of machine learning models are more accurate.
In addition, because solving the energy conservation equation contains the physical meaning of numerous sampler penetration processes, many process parameters are required, such as the inner wall friction coefficient, outer wall friction coefficient, cutter head cutting coefficient, and other difficult-to-determine parameters. This status quo leads to numerous estimates for the modeling of the conventional analytical solution, which increases the complexity of the computational process and the error of the prediction results. In contrast, the machine learning model only requires a few critical influencing parameters to directly connect with the penetration depth. The computational parameters used in this model can be obtained before sampling. No parameter valuation is required, which significantly reduces the complexity of the model calculation and improves the prediction accuracy. Overall, the machine learning algorithm is superior to traditional analytical solution models in predicting the penetration depth of gravity samplers, both in terms of the accuracy of the model prediction results and the scientific nature of the computational process.
6. Conclusions
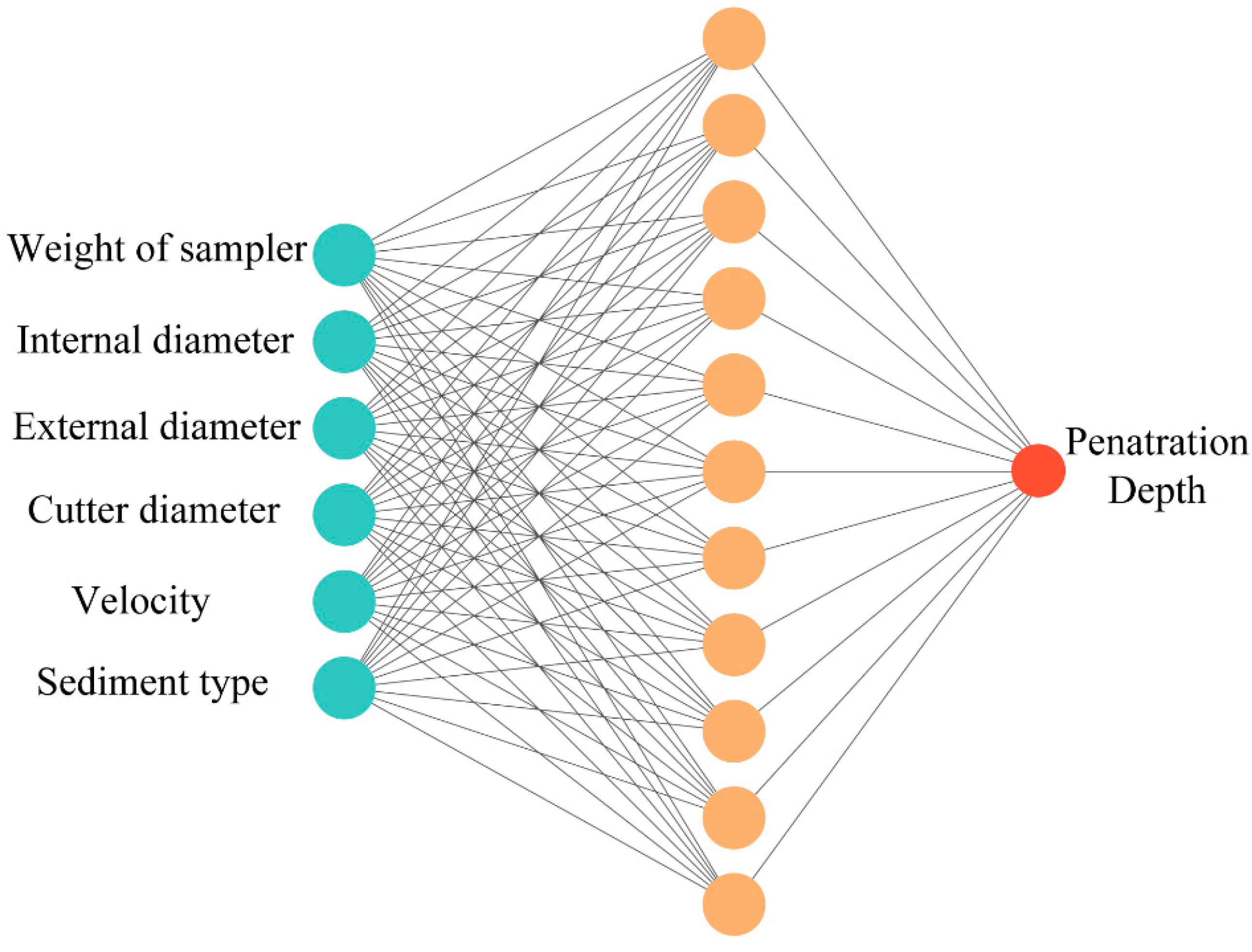
In this study, a machine learning model using an MLP neural network was applied to predict the penetration depth of a gravity corer. A database of 75 gravity corer penetration depths from both real sampling at sea and physical model test data was used to generate the datasets for modeling, considering six penetration depth factors. The models were validated using the MSE, MAE, EVS, and R-square methods. The results show that the proposed machine learning model achieved great accuracy in predicting the gravity corer penetration depth (test set accuracy: EVS = 0.95, MAE = 0.26, MSE = 0.38, R2 = 0.94). Furthermore, in this study, we used three analytical solution models of gravity corer penetration depth to predict the same cases. The results show that the machine learning model is superior to the traditional analytical solution models in terms of both the accuracy of the prediction results and the scientific nature of the computational process. Thus, it can be reasonably concluded that the proposed machine learning model can be used to achieve better penetration depth prediction. However, many factors affect the accuracy of the machine learning model: problem type, selection of influential factors, quality and quantity of data, and selection of machine learning models. Therefore, it is better to collect more high-quality data and select a moderate machine learning model and influential factors to obtain a more accurate machine learning model.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}