
A Novel Approach for Semantic Extractive Text Summarization

 , , , ,
, , , , 
Abstract
:1. Introduction
2. Background
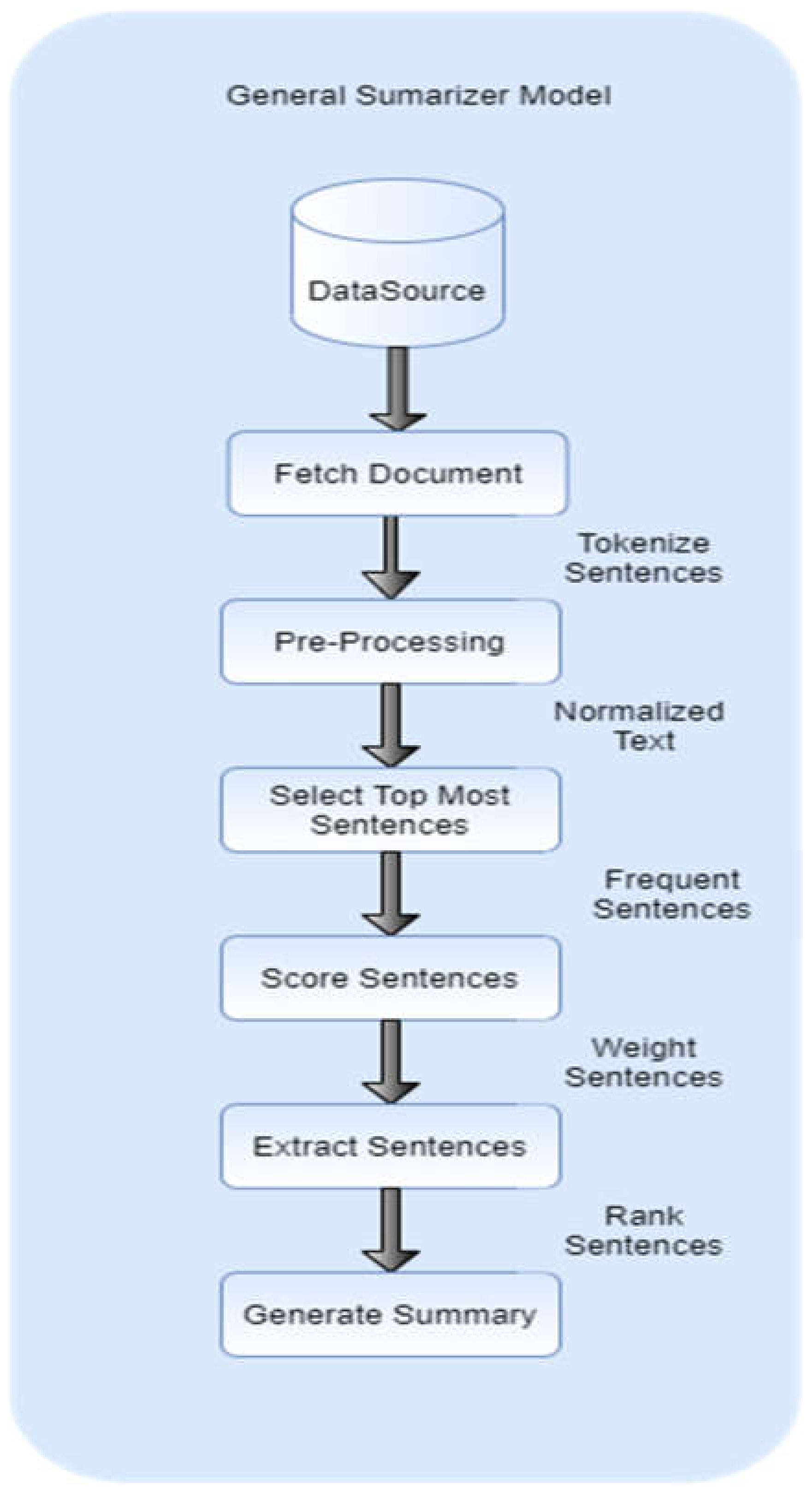
3. Methodology and Experimental Setup
| Algorithm 1: Pseudo-Code |
| Let D → Document S D Sample is a subset of Document D S Sci Sci is list of Sentences that Sample S contains. Sc = {Sc1, Sc2, Sc3,,,,, Scn} |
| Remove Stop Words |
| stop_words = {‘is’,’am’,’are’….} Sc – stop_words = {Sc1, Sc2, Sc3,,,,, Scn} - {‘is’,’am’,’are’….} Sc = {Sc1, Sc2, Sc3,,,,, Scn} set of Sentences that don’t contain stopwords. |
| Generate Bag-of-Words by Mode: |
| Mode = l + h (fm − f1/2fm − f1 − f2) Keywords = fMode(Sc) list of most frequently occurring words contains S. |
| Compute Mean |
| µ = Sc1 + Sc2 + Sc3 + ……. + Scn/n |
| Compute Standard Deviation |
| = |
| Compute Z-Score |
| Z-Score = (Xi − µ)/δ ∀ Sci > Z-Score SPos_Outlier Sci And, Sci < Z-Score SNeg_Outlier Sci. |
| Eliminate Outliers |
| Spos = S − SPos_Outlier Spos SPos_Outlier Sneg = S − Sneg_Outlier Sneg Sneg_Outlier Sents = Spos Sneg |
| Extract Facts from Sample |
| Ext[i] = fextract_dates (S) S is Sample. |
| Extract Sentences Based on Keywords |
| Summ[i] = fFuzzy (Keywords,Sents) Sents is list of all sentences. |
| Generate Summary |
| Summ_all = + (Facts) & (Fuzzy) Summary = fUnique (Summ_all) |
3.1. Data Source
3.2. Preprocessing
3.3. Extract Sentences
3.4. Evaluation Technique
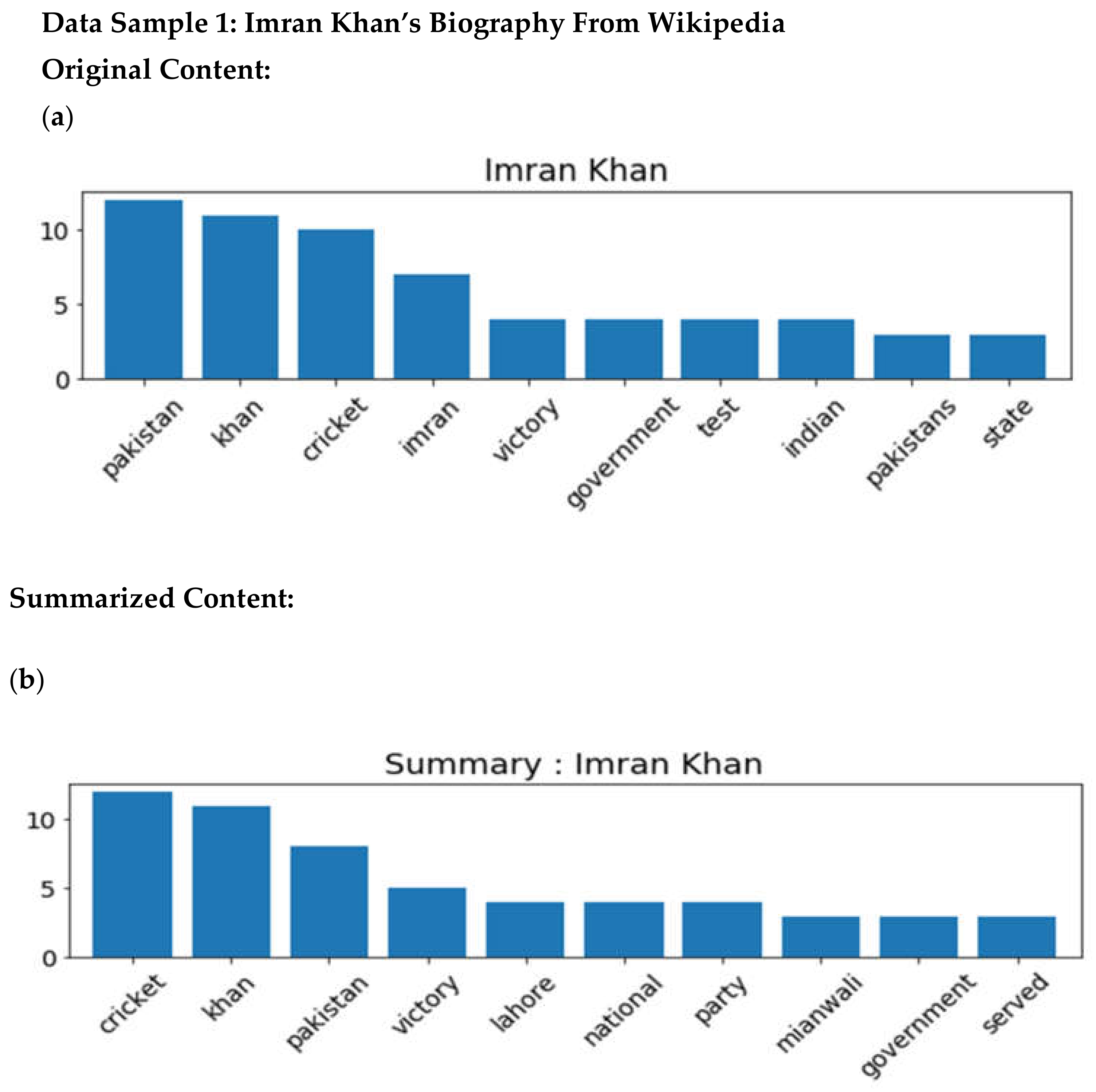
4. Results
5. Conclusions & Future Recommendations
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Qaroush, A.; Abu Farha, I.; Ghanem, W.; Washaha, M.; Maali, E. An efficient single document Arabic text summarization using a combination of statistical and semantic features. J. King Saud Univ. Comput. Inf. Sci. 2019, 33, 677–692. [Google Scholar] [CrossRef]
- Mohamed, M.; Oussalah, M. SRL-ESA-TextSum: A text summarization approach based on semantic role labeling and explicit semantic analysis. Inf. Process. Manag. 2019, 56, 1356–1372. [Google Scholar] [CrossRef]
- Khan, A.; Salim, N.; Farman, H.; Khan, M.; Jan, B.; Ahmad, A.; Ahmed, I.; Paul, A. Abstractive Text Summarization based on Improved Semantic Graph Approach. Int. J. Parallel Program. 2018, 46, 992–1016. [Google Scholar] [CrossRef]
- Song, S.; Huang, H.; Ruan, T. Abstractive text summarization using LSTM-CNN based deep learning. Multimed. Tools Appl. 2019, 78, 857–875. [Google Scholar] [CrossRef]
- Sah, S.; Kulhare, S.; Gray, A.; Venugopalan, S.; Prud’Hommeaux, E.; Ptucha, R. Semantic Text Summarization of Long Videos. In Proceedings of the 2017 IEEE Winter Conference on Applications of Computer Vision (WACV), Santa Rosa, CA, USA, 24–31 March 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 989–997. [Google Scholar]
- El-Kassas, W.S.; Salama, C.R.; Rafea, A.A.; Mohamed, H.K. Automatic text summarization: A comprehensive survey. Expert Syst. Appl. 2020, 165, 113679. [Google Scholar] [CrossRef]
- Ma, S.; Sun, X.; Xu, J.; Wang, H.; Li, W.; Su, Q. Improving semantic relevance for sequence-to-sequence learning of chinese social media text summarization. arXiv 2017, arXiv:1706.02459. [Google Scholar]
- Sun, X.; Zhuge, H. Summarization of Scientific Paper through Reinforcement Ranking on Semantic Link Network. IEEE Access 2018, 6, 40611–40625. [Google Scholar] [CrossRef]
- Rahman, N.; Borah, B. Improvement of query-based text summarization using word sense disambiguation. Complex Intell. Syst. 2020, 6, 75–85. [Google Scholar] [CrossRef] [Green Version]
- Abu Nada, A.M.; Alajrami, E.; Al-Saqqa, A.A.; Abu-Naser, S.S. Arabic Text Summarization Using AraBERT Model Using Extractive Text Summarization Approach. Int. J. Acad. Inf. Syst. Res. IJAISR 2020, 4, 6–9. [Google Scholar]
- Zhong, M.; Liu, P.; Chen, Y.; Wang, D.; Qiu, X.; Huang, X. Extractive summarization as text matching. arXiv 2020, arXiv:2004.08795. [Google Scholar]
- Van Lierde, H.; Chow, T.W. Query-oriented text summarization based on hypergraph transversals. Inf. Process. Manag. 2019, 56, 1317–1338. [Google Scholar] [CrossRef] [Green Version]
- Kanapala, A.; Pal, S.; Pamula, R. Text summarization from legal documents: A survey. Artif. Intell. Rev. 2019, 51, 371–402. [Google Scholar] [CrossRef]
- Muthu, B.; Cb, S.; Kumar, P.M.; Kadry, S.N.; Hsu, C.-H.; Sanjuan, O.; Crespo, R.G. A Framework for Extractive Text Summarization based on Deep Learning Modified Neural Network Classifier. ACM Trans. Asian Low-Resour. Lang. Inf. Process. 2021, 20, 1–20. [Google Scholar] [CrossRef]
- Joshi, A.; Fidalgo, E.; Alegre, E.; Fernández-Robles, L. SummCoder: An unsupervised framework for extractive text summarization based on deep auto-encoders. Expert Syst. Appl. 2019, 129, 200–215. [Google Scholar] [CrossRef]
- Gambhir, M.; Gupta, V. Recent automatic text summarization techniques: A survey. Artif. Intell. Rev. 2017, 47, 1–66. [Google Scholar] [CrossRef]
- Fang, C.; Mu, D.; Deng, Z.; Wu, Z. Word-sentence co-ranking for automatic extractive text summarization. Expert Syst. Appl. 2017, 72, 189–195. [Google Scholar] [CrossRef]
- Moratanch, N.; Chitrakala, S. A survey on extractive text summarization. In Proceedings of the 2017 International Conference on Computer, Communication and Signal Processing (ICCCSP), Chennai, India, 10–11 January 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 1–6. [Google Scholar]
- Al-Sabahi, K.; Zuping, Z.; Nadher, M. A Hierarchical Structured Self-Attentive Model for Extractive Document Summarization (HSSAS). IEEE Access 2018, 6, 24205–24212. [Google Scholar] [CrossRef]
- Rossiello, G.; Basile, P.; Semeraro, G. Centroid-Based Text Summarization through Compositionality of Word Embedding. In Proceedings of the MultiLing 2017 Workshop on Summarization and Summary Evaluation across Source Types and Genres, Valencia, Spain, 10 April 2017; pp. 12–21. [Google Scholar]
- Wang, Y.; Afzal, N.; Fu, S.; Wang, L.; Shen, F.; Rastegar-Mojarad, M.; Liu, H. MedSTS: A resource for clinical semantic textual similarity. Comput. Humanit. 2020, 54, 57–72. [Google Scholar] [CrossRef] [Green Version]
- Nasar, Z.; Jaffry, S.W.; Malik, M.K. Textual keyword extraction and summarization: State-of-the-art. Inf. Process. Manag. 2019, 56, 102088. [Google Scholar] [CrossRef]
- Miller, D. Leveraging BERT for extractive text summarization on lectures. arXiv 2019, arXiv:1906.04165. [Google Scholar]
- Patel, D.; Shah, S.; Chhinkaniwala, H. Fuzzy logic based multi document summarization with improved sentence scoring and redundancy removal technique. Expert Syst. Appl. 2019, 134, 167–177. [Google Scholar] [CrossRef]
- Liu, Y.; Lapata, M. Text summarization with pretrained encoders. arXiv 2019, arXiv:1908.08345. [Google Scholar]
- Afsharizadeh, M.; Ebrahimpour-Komleh, H.; Bagheri, A. Query-Oriented Text Summarization Using Sentence Extraction Technique. In Proceedings of the 2018 4th International Conference on Web Research (ICWR), Tehran, Iran, 25–26 April 2018; IEEE: Piscataway, NJ, USA; pp. 128–132.
- Allahyari, M.; Pouriyeh, S.; Assefi, M.; Safaei, S.; Trippe, E.D.; Gutierrez, J.B.; Kochut, K. ext summarization techniques: A brief survey. arXiv 2017, arXiv:1707.02268. [Google Scholar]
- Wang, D.; Liu, P.; Zheng, Y.; Qiu, X.; Huang, X.-J. Heterogeneous graph neural networks for extractive document summarization. arXiv 2020, arXiv:2004.12393. [Google Scholar]
- Ma, S.; Sun, X.; Lin, J.; Wang, H. Autoencoder as assistant supervisor: Improving text representation for chinese social media text summarization. arXiv 2018, arXiv:1805.04869. [Google Scholar]
- Abujar, S.; Hasan, M.; Shahin, M.S.; Hossain, S.A. A Heuristic Approach of Text Summarization for Bengali Documentation. In Proceedings of the 2017 8th International Conference on Computing, Communication and Networking Technologies (ICCCNT), Delhi, India, 3–5 July 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 1–8. [Google Scholar]
- Duari, S.; Bhatnagar, V. sCAKE: Semantic Connectivity Aware Keyword Extraction. Inf. Sci. 2019, 477, 100–117. [Google Scholar] [CrossRef] [Green Version]
- Singh, S. Natural language processing for information extraction. arXiv 2018, arXiv:1807.02383. [Google Scholar]
- Gupta, S.; Gupta, S.K. Abstractive summarization: An overview of the state of the art. Expert Syst. Appl. 2019, 121, 49–65. [Google Scholar] [CrossRef]
- Al-Abdallah, R.Z.; Al-Taani, A. Arabic single-document text summarization using particle swarm optimization algorithm. Procedia Comput. Sci. 2017, 117, 30–37. [Google Scholar] [CrossRef]
- Gao, Y.; Zhao, W.; Eger, S. SUPERT: Towards new frontiers in unsupervised evaluation metrics for multi-document summarization. arXiv 2020, arXiv:2005.03724. [Google Scholar]
- Al-Radaideh, Q.A.; Bataineh, D.Q. A Hybrid Approach for Arabic Text Summarization Using Domain Knowledge and Genetic Algorithms. Cogn. Comput. 2018, 10, 651–669. [Google Scholar] [CrossRef]
- Yousefi-Azar, M.; Hamey, L. Text summarization using unsupervised deep learning. Expert Syst. Appl. 2017, 68, 93–105. [Google Scholar] [CrossRef]
- Saini, N.; Saha, S.; Jangra, A.; Bhattacharyya, P. Extractive single document summarization using multi-objective optimization: Exploring self-organized differential evolution, grey wolf optimizer and water cycle algorithm. Knowl.-Based Syst. 2019, 164, 45–67. [Google Scholar] [CrossRef]
- Lo, K.; Wang, L.L.; Neumann, M.; Kinney, R.; Weld, D.S. S2ORC: The semantic scholar open research corpus. arXiv 2019, arXiv:1911.02782. [Google Scholar]
- Maulud, D.H.; Zeebaree, S.R.; Jacksi, K.; Sadeeq, M.A.; Sharif, K.H. State of art for semantic analysis of natural language processing. Qubahan Acad. J. 2021, 1, 21–28. [Google Scholar] [CrossRef]
- Gao, S.; Chen, X.; Li, P.; Ren, Z.; Bing, L.; Zhao, D.; Yan, R. Abstractive text summarization by incorporating reader comments. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 6399–6406. [Google Scholar]
- Fu, Z.; Huang, F.; Ren, K.; Weng, J.; Wang, C. Privacy-Preserving Smart Semantic Search Based on Conceptual Graphs Over Encrypted Outsourced Data. IEEE Trans. Inf. Forensics Secur. 2017, 12, 1874–1884. [Google Scholar] [CrossRef]
- Bharti, S.K.; Babu, K.S. Automatic keyword extraction for text summarization: A survey. arXiv 2017, arXiv:1704.03242. [Google Scholar]
- Huang, L.; Wu, L.; Wang, L. Knowledge graph-augmented abstractive summarization with semantic-driven cloze reward. arXiv 2020, arXiv:2005.01159. [Google Scholar]
- Moradi, M.; Dorffner, G.; Samwald, M. Deep contextualized embeddings for quantifying the informative content in biomedical text summarization. Comput. Methods Programs Biomed. 2020, 184, 105117. [Google Scholar] [CrossRef]
- Cao, M.; Sun, X.; Zhuge, H. The contribution of cause-effect link to representing the core of scientific paper—The role of Semantic Link Network. PLoS ONE 2018, 13, e0199303. [Google Scholar] [CrossRef] [Green Version]
- Sinoara, R.A.; Antunes, J.; Rezende, S. Text mining and semantics: A systematic mapping study. J. Braz. Comput. Soc. 2017, 23, 9. [Google Scholar] [CrossRef]
- Alsaqer, A.F.; Sasi, S. Movie review summarization and sentiment analysis using rapidminer. In Proceedings of the 2017 International Conference on Networks & Advances in Computational Technologies (NetACT), Thiruvananthapuram, India, 20–22 July 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 329–335. [Google Scholar]
- Sahba, R.; Ebadi, N.; Jamshidi, M.; Rad, P. Automatic text summarization using customizable fuzzy features and attention on the context and vocabulary. In Proceedings of the 2018 World Automation Congress (WAC), Stevenson, WA, USA, 3–6 June 2018; IEEE: Piscataway, NJ, USA, 2018. [Google Scholar]
- Mallick, C.; Das, A.K.; Dutta, M.; Das, A.K.; Sarkar, A. Graph-based text summarization using modified TextRank. In Soft Computing in Data Analytics; Springer: Singapore, 2019; pp. 137–146. [Google Scholar]
- Tayal, M.A.; Raghuwanshi, M.M.; Malik, L.G. ATSSC: Development of an approach based on soft computing for text summarization. Comput. Speech Lang. 2017, 41, 214–235. [Google Scholar] [CrossRef]
- Cetto, M.; Niklaus, C.; Freitas, A.; Handschuh, S. Graphene: Semantically-linked propositions in open information extraction. arXiv 2018, arXiv:1807.11276. [Google Scholar]
- Lin, H.; Ng, V. Abstractive summarization: A survey of the state of the art. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 9815–9822. [Google Scholar]
- Alami, N.; Meknassi, M.; En-Nahnahi, N. Enhancing unsupervised neural networks based text summarization with word embedding and ensemble learning. Expert Syst. Appl. 2019, 123, 195–211. [Google Scholar] [CrossRef]
- Kryściński, W.; McCann, B.; Xiong, C.; Socher, R. Evaluating the factual consistency of abstractive text summarization. arXiv 2019, arXiv:1910.12840. [Google Scholar]
- Xu, J.; Gan, Z.; Cheng, Y.; Liu, J. Discourse-aware neural extractive text summarization. arXiv 2019, arXiv:1910.14142. [Google Scholar]
- Wei, H.; Ni, B.; Yan, Y.; Yu, H.; Yang, X.; Yao, C. Video Summarization via Semantic Attended Networks. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32. [Google Scholar]
- Hu, J.; Li, S.; Yao, Y.; Yu, L.; Yang, G.; Hu, J. Patent Keyword Extraction Algorithm Based on Distributed Representation for Patent Classification. Entropy 2018, 20, 104. [Google Scholar] [CrossRef] [Green Version]
- Goularte, F.B.; Nassar, S.M.; Fileto, R.; Saggion, H. A text summarization method based on fuzzy rules and applicable to automated assessment. Expert Syst. Appl. 2019, 115, 264–275. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Features | LexRank | Edmonson | LSA | TextRank | Kl-Divergence | Proposed |
|---|---|---|---|---|---|---|
| Redundancy | ✔ | ✔ | ✔ | ✔ | ✔ | × |
| Semantics | ✔ | × | ✔ | × | × | ✔ |
| Events/Dates | × | × | × | × | × | ✔ |
| Chronological Order | × | × | × | × | × | ✔ |
| CR/RR Balancing | × | × | × | × | × | ✔ |
| Topic | Original Words Length | LSA Words Length | CR Ratio % | LEX Words Length | CR Ratio % | KL Words Length | CR Ratio % | Text Words Length | CR Ratio % | Proposed Summarizers Words Length | CR Ratio % |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Imran Khan | 67,455 | 1887 | 27.98 | 1819 | 26.98 | 909 | 13.48 | 2909 | 43.13 | 7928 | 11.75 |
| COVID-19 | 72,424 | 2217 | 30.62 | 1936 | 26.74 | 861 | 11.90 | 3014 | 41.62 | 2121 | 2.92 |
| Pakistan | 116,125 | 1693 | 14.58 | 1585 | 13.65 | 7277 | 6.28 | 3116 | 26.84 | 6605 | 5.68 |
| Taj Mahal | 29,015 | 16,227 | 55.92 | 15,205 | 52.40 | 11,384 | 39.23 | 18,531 | 63.86 | 3700 | 12.75 |
| Tsunami | 34,132 | 21,745 | 63.70 | 17,752 | 52 | 6610 | 19.36 | 21,250 | 62.25 | 2416 | 7.07 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Waseemullah; Fatima, Z.; Zardari, S.; Fahim, M.; Andleeb Siddiqui, M.; Ibrahim, A.A.A.; Nisar, K.; Naz, L.F. A Novel Approach for Semantic Extractive Text Summarization. Appl. Sci. 2022, 12, 4479. https://doi.org/10.3390/app12094479
Waseemullah, Fatima Z, Zardari S, Fahim M, Andleeb Siddiqui M, Ibrahim AAA, Nisar K, Naz LF. A Novel Approach for Semantic Extractive Text Summarization. Applied Sciences. 2022; 12(9):4479. https://doi.org/10.3390/app12094479
Chicago/Turabian StyleWaseemullah, Zainab Fatima, Shehnila Zardari, Muhammad Fahim, Maria Andleeb Siddiqui, Ag. Asri Ag. Ibrahim, Kashif Nisar, and Laviza Falak Naz. 2022. "A Novel Approach for Semantic Extractive Text Summarization" Applied Sciences 12, no. 9: 4479. https://doi.org/10.3390/app12094479
APA StyleWaseemullah, Fatima, Z., Zardari, S., Fahim, M., Andleeb Siddiqui, M., Ibrahim, A. A. A., Nisar, K., & Naz, L. F. (2022). A Novel Approach for Semantic Extractive Text Summarization. Applied Sciences, 12(9), 4479. https://doi.org/10.3390/app12094479