
A Framework for Short Video Recognition Based on Motion Estimation and Feature Curves on SPD Manifolds


Abstract
:1. Introduction
- (1)
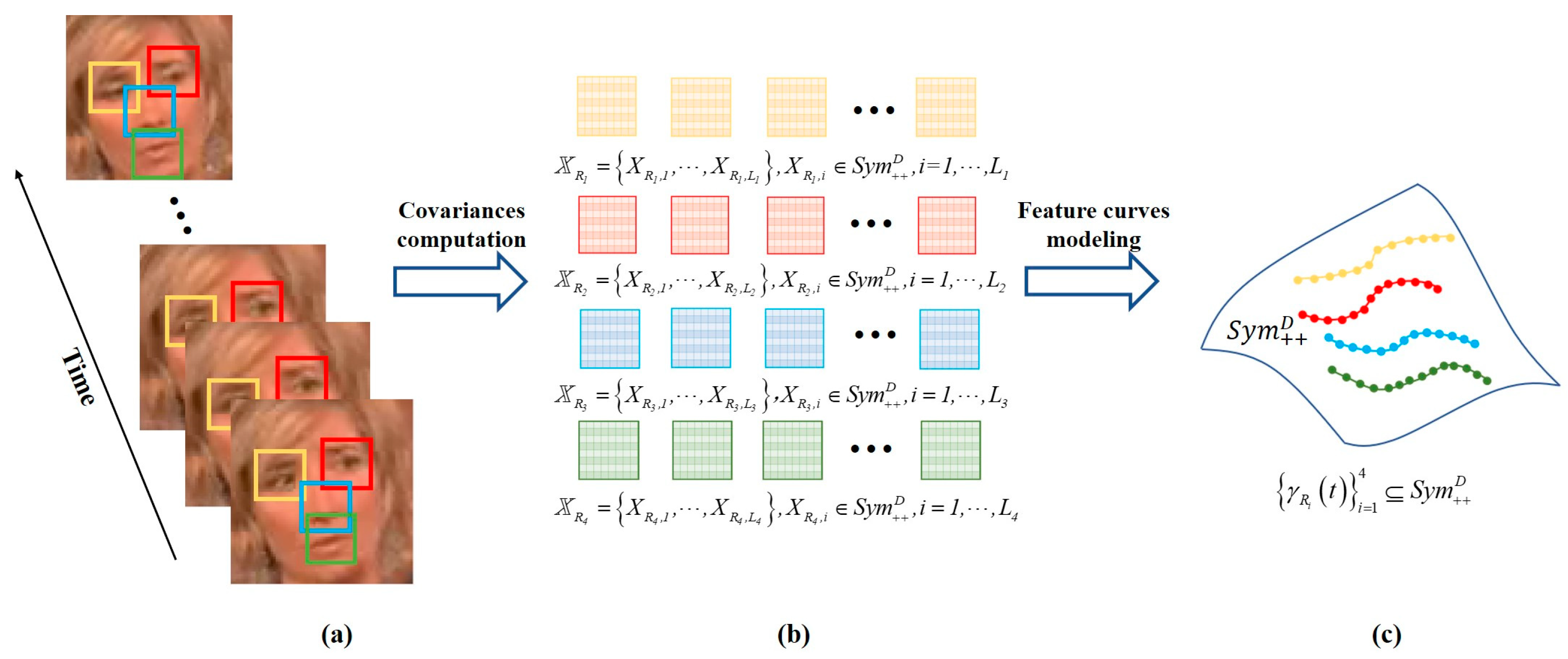
- According to the practical application, a key frame is extracted from the short video to determine the spatial feature blocks (i.e., ROIs) of the target.
- (2)
- Using motion estimation [18] in video encoding, each ROI in the key frame is traced forward, backward, or two-way to string time series of ROIs through the short video. The resulting family of time series of ROIs represent the temporal and spatial feature of short video.
- (3)
- Each ROI is transformed into an SPD matrix by regional covariance descriptor (RCD). Hence, the family of time series of ROIs is transformed into a family of time series of SPD matrices. Each obtained time series of SPD matrices is a curve on the SPD manifold. The family of curves is the feature curves of the short video, which is the basis of short video recognition.
- (4)
- (1)
- Proposing a short video recognition framework feasible for different applications, as well as providing optional strategies for stringing time series of ROIs, constructing RCDs, and providing recognition between families of feature curves.
- (2)
- Different from viewing a video as an image set-based SPD matrix, which ignores the temporal correlation of features across image frames, our framework models each video as a family of feature curves on the SPD manifold, considering both temporal and spatial features of video.
- (3)
- ROI and motion estimation in video encoding are applied in our framework to reduce computational burden due to redundancy across image frames. Compared with using global frame images, ROIs convey more accurate spatial features. Moreover, tracing ROI with motion estimation can effectively reduce the computation of feature detection.
- (4)
- Encoding major spatial features by ROI-based covariance descriptors helps to build SPD geometry and provides a discriminant Riemannian metric for recognition.

2. Preliminaries
2.1. Notation
2.2. The Geometry of SPD Manifold
2.3. Bregman Divergences
2.4. Motion Estimation
3. Related Works
3.1. Modeling of Video as Curve on Riemannian Manifold
3.2. Dynamic Time Warping
4. A Framework for Feature Curves on SPD Manifold
4.1. Formulation of Short Video Recognition
4.2. Stringing Time Series of ROIs Based on Motion Estimation
4.3. Features Curves on SPD Manifold
| Algorithm 1 Computing a Family of Feature Curves on |
| Input: A family of time series of ROIs from video Output: A family of feature Curves /* Compute the SPD matrices of ROIs */ for to for do end /* Compute the geodesic between SPD matrices */ for do as Equation (26) end end Return A Family of feature Curves |
4.4. Rcognition between Famlies of Features Curves
| Algorithm 2 Classification of a Family of Feature Curves on SPD Manifold with Overall Classification Strategy. |
| Input: sample families of feature curves with their corresponding labels of each family, a family of feature curves of query video . Output: Predicted label of /* Compute DTW distances among sample and query feature curves */ for to for to do end end /* Compute average DTW distance matrix */ for to do end /* Testing phase */ KNN classifier using average DTW distance matrix Return Predicted label of |
| Algorithm 3 Classification of a Family of Feature Curves on SPD Manifold with Pre-classification Strategy |
| Input: sample families of feature curves with their corresponding labels of each family, a family of feature curves of query video . Output: Predicted label of query video /* Compute distances among sample and query feature curves */ for to for to do end end /* Testing phase */ for to do KNN classifier using the k-th row of distance matrix end Return Mode of as predicted label of |
5. Application to Face Recognition
6. Comparison Algorithms
6.1. RieCovDs
6.2. AidCovDs
6.3. CERML
6.4. LEML
6.5. SPDML
6.6. SPDSL
6.7. DALG
6.8. Summary
7. Experimental Studies
7.1. Database
7.2. Method Setting
7.3. Result and Analysis
8. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| SPD | Symmetric positive definite; |
| ROI | Region of interest; |
| RCD | Regional covariance descriptor; |
| DTW | Dynamic time warping; |
| DR | Dimensionality reduction; |
| AIRM | Affine invariant Riemannian metric; |
| LEM | Log-Euclidean metric; |
| RKHS | Reproducing kernel Hilbert space; |
| RieCovDs | Riemannian covariance descriptors; |
| AidCovDs | Approximate infinite-dimensional covariance descriptors; |
| CERML | Metric learning methods: cross Euclidean-to-Riemannian metric learning; |
| LEML | Log-Euclidean metric learning; |
| SPDML | SPD manifold learning; |
| SPDSL | SPD similarity learning; |
| DALG | Discriminative analysis for SPD matrices on Lie groups; |
| LG | Lie group. |
References
- Pennec, X.; Fillard, P.; Ayache, N. A Riemannian Framework for Tensor Computing. Int. J. Comput. Vis. 2006, 66, 41–66. [Google Scholar] [CrossRef] [Green Version]
- Arsigny, V.; Fillard, P.; Pennec, X.; Ayache, N. Log-Euclidean metrics for fast and simple calculus on diffusion tensors. Magn. Reason. Med. 2006, 56, 411–421. [Google Scholar] [CrossRef] [PubMed]
- Wang, R.; Guo, H.; Davis, L.S.; Dai, Q. Covariance discriminative learning: A natural and efficient approach to image set classification. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012. [Google Scholar] [CrossRef]
- Vemulapalli, R.; Pillai, J.; Chellappa, R. Kernel Learning for Extrinsic Classification of Manifold Features. In Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013. [Google Scholar]
- Harandi, M.T.; Salzmann, M. Riemannian coding and dictionary learning: Kernels to the rescue. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Huang, Z.; Wang, R.; Shan, S.; Chen, X. Face recognition on large-scale video in the wild with hybrid Euclidean-and-Riemannian metric learning. Pattern. Recognit. 2015, 48, 3113–3124. [Google Scholar] [CrossRef]
- Wang, W.; Wang, R.; Huang, Z.; Shan, S.; Chen, X. Discriminant Analysis on Riemannian Manifold of Gaussian Distributions for Face Recognition with Image Sets. IEEE Trans. Image Process. 2018, 27, 151–163. [Google Scholar] [CrossRef]
- Goh, A.; Vidal, R. Clustering and dimensionality reduction on Riemannian manifolds. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 23–28 June 2008. [Google Scholar] [CrossRef]
- Horev, I.; Yger, F.; Sugiyama, M. Geometry-aware principal component analysis for symmetric positive definite matrices. Mach. Learn. 2017, 106, 493–522. [Google Scholar] [CrossRef] [Green Version]
- Xie, X.; Yu, Z.L.; Gu, Z.; Li, Y. Classification of symmetric positive definite matrices based on bilinear isometric Riemannian embedding. Pattern. Recognit. 2019, 87, 94–105. [Google Scholar] [CrossRef]
- Tuzel, O.; Porikli, F.; Meer, P. Pedestrian detection via classification on Riemannian manifolds. IEEE Trans. Pattern. Anal. Mach. 2008, 30, 1713–1727. [Google Scholar] [CrossRef]
- Tosato, D.; Farenzena, M.; Cristani, M.; Spera, M.; Murino, V. Multi-class classification on Riemannian manifolds for video surveillance. In Proceedings of the 2010 European Conference on Computer Vision, Crete, Greece, 5–11 September 2010. [Google Scholar] [CrossRef]
- Li, P.; Wang, Q.; Zuo, W.; Zhang, L. Log-Euclidean Kernels for Sparse Representation and Dictionary Learning. In Proceedings of the 2013 IEEE International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013. [Google Scholar] [CrossRef] [Green Version]
- Minh, H.Q. Infinite-dimensional Log-Determinant divergences between positive definite Hilbert–Schmidt operators. Positivity 2020, 24, 631–662. [Google Scholar] [CrossRef] [Green Version]
- Jayasumana, S.; Hartley, R.; Salzmann, M.; Li, H.; Harandi, M. Kernel methods on Riemannian manifolds with Gaussian RBF kernels. IEEE Trans. Pattern. Anal. Mach. Intell. 2015, 37, 2464–2477. [Google Scholar] [CrossRef] [Green Version]
- Otberdout, N.; Kacem, A.; Daoudi, M.; Ballihi, L.; Berretti, S. Automatic Analysis of Facial Expressions Based on Deep Covariance Trajectories. IEEE Trans. Neural Netw. Learn. Syst. 2020, 31, 3892–3905. [Google Scholar] [CrossRef] [Green Version]
- Kacem, A.; Daoudi, M.; Amor, B.; Berretti, S.; Alvarez-Paiva, J.C. A Novel Geometric Framework on Gram Matrix Trajectories for Human Behavior Understanding. IEEE Trans. Pattern. Anal. Mach. Intell. 2020, 42, 1–14. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kundo, A. Modified block matching algorithm for fast block motion estimation. In Proceedings of the 2010 International Conference on Signal and Image Processing, Chennai, India, 15–17 December 2010. [Google Scholar] [CrossRef]
- Berndt, D.J. Using dynamic time warping to find patterns in time series. AAAI Workshop Knowl. Discov. Databases 1994, 10, 359–370. [Google Scholar]
- Arsigny, V.; Fillard, P.; Pennec, X.; Ayache, N. Geometric Means in a Novel Vector Space Structure on Symmetric Positive-Definite Matrices. SIAM J. Matrix Anal. Appl. 2007, 29, 328–347. [Google Scholar] [CrossRef] [Green Version]
- Cherian, A.; Sra, S.; Banerjee, A.; Papanikolopoulos, N. Jensen-Bregman logdet divergence with application to efficient similarity search for covariance matrices. IEEE Trans. Pattern. Anal. Mach. Intell. 2013, 35, 2161–2174. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wang, Z.; Vemuri, B.C. An affine invariant tensor dissimilarity measure and its applications to tensor-valued image segmentation. In Proceedings of the 2004 IEEE Conference on Computer Vision and Pattern Recognition, Washington, DC, USA, 27 June–2 July 2004. [Google Scholar] [CrossRef]
- Bonnabel, S.; Sepulchre, R. Riemannian Metric and Geometric Mean for Positive Semidefinite Matrices of Fixed Rank. SIAM J. Matrix Anal. Appl. 2009, 31, 1055–1070. [Google Scholar] [CrossRef] [Green Version]
- Kulis, B.; Sustik, M.A.; Dhillon, I.S. Low-rank kernel learning with Bregman matrix divergences. J. Mach. Learn. Res. 2009, 10, 341–376. [Google Scholar]
- Taheri, S.; Turaga, P.; Chellapa, R. Towards view-invariant expression analysis using analytic shape manifolds. In Proceedings of the 2011 IEEE International Conference on Automatic Face and Gesture Recognition (FG), Santa Barbara, CA, USA, 21–25 March 2011. [Google Scholar] [CrossRef] [Green Version]
- Devanne, M.; Wannous, H.; Berretti, S.; Pala, P.; Daoudi, M.; Bimbo, A. 3-D human action recognition by shape analysis of motion trajectories on Riemannian manifold. IEEE Trans. Cybern. 2015, 45, 1340–1352. [Google Scholar] [CrossRef] [Green Version]
- Tanfous, A.B.; Drira, H.; Amor, B.B. Sparse Coding of Shape Trajectories for Facial Expression and Action Recognition. IEEE Trans. Pattern. Anal. Mach. Intell. 2020, 42, 2594–2607. [Google Scholar] [CrossRef] [Green Version]
- Chakraborty, R.; Singh, V. A geometric framework for statistical analysis of trajectories with distinct temporal spans. In Proceedings of the 2017 IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar] [CrossRef]
- Sanin, A.; Sanderson, C.; Harandi, M.; Lovell, B.C. Spatiotemporal covariance descriptors for action and gesture recognition. In Proceedings of the 2013 IEEE Workshop on Applications of Computer Vision, Clearwater Beach, FL, USA, 15–17 January 2013. [Google Scholar] [CrossRef] [Green Version]
- Wang, Z.; Yan, W.; Oates, T. Time series classification from scratch with deep neural networks: A strong baseline. In Proceedings of the 2017 International Joint Conference on Neural Networks, Anchorage, AK, USA, 14–19 May 2017. [Google Scholar] [CrossRef] [Green Version]
- Deng, H.; Runger, G.; Tuv, E.; Vladimir, M. A time series forest for classification and feature extraction. Inf. Sci. 2013, 239, 142–153. [Google Scholar] [CrossRef] [Green Version]
- Lines, J.; Bagnall, A. Time series classification with ensembles of elastic distance measures. Data Min. Knowl. Discov. 2014, 29, 565–592. [Google Scholar] [CrossRef]
- Ding, H.; Trajcevski, G.; Scheuermann, P.; Wang, X.; Keogh, E. Querying and mining of time series data: Experimental comparison of representations and distance measures. VLDB Endow. 2008, 1, 1542–1552. [Google Scholar] [CrossRef] [Green Version]
- Górecki, T.; Łuczak, M. Using derivatives in time series classification. Data Min. Knowl. Discov. 2012, 26, 310–331. [Google Scholar] [CrossRef] [Green Version]
- Bahlmann, C.; Haasdonk, B.; Burkhardt, H. Online handwriting recognition with support vector machines a kernel approach. In Proceedings of the Eighth International Workshop on Frontiers in Handwriting Recognition, Niagra-on-the-Lake, ON, Canada, 6–8 August 2002. [Google Scholar] [CrossRef]
- Cuturi, M. Fast global alignment kernels. In Proceedings of the 28th International Conference on Machine Learning, Bellevue, WA, USA, 28 June–2 July 2011. [Google Scholar]
- Amari, S.; Nagaoka, H. Methods of Information Geometry; Oxford University Press: New York, NY, USA, 2009. [Google Scholar]
- Wasserman, L. All of Statistics: A Concise Course in Statistical Inference; Springer: New York, NY, USA, 2013. [Google Scholar]
- Chen, K.; Ren, J.; Wu, X.; Kittler, J. Covariance descriptors on a Gaussian manifold and their application to image set classification. Pattern. Recognit. 2020, 107, 107463. [Google Scholar] [CrossRef]
- Chen, K.; Wu, X.; Wang, R.; Kittler, J. Riemannian kernel based Nyström method for approximate infinite-dimensional covariance descriptors with application to image set classification. In Proceedings of the 24th International Conference on Pattern Recognition, Beijing, China, 20–24 August 2018. [Google Scholar] [CrossRef] [Green Version]
- Huang, Z.; Wang, R.; Shan, S.; Van Gool, L.; Chen, X. Cross Euclidean-to-Riemannian Metric Learning with Application to Face Recognition from Video. IEEE Trans. Pattern. Anal. Mach. Intell. 2018, 40, 2827–2840. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Huang, Z.; Wang, R.; Shan, S.; Li, X.; Chen, X. Log-Euclidean metric learning on symmetric positive definite manifold with application to image set classification. In Proceedings of the 32nd International Conference on Machine Learning, Lille, France, 6–11 July 2015. [Google Scholar]
- Harandi, M.; Salzmann, M.; Hartley, R. Dimensionality Reduction on SPD Manifolds: The Emergence of Geometry-Aware Methods. IEEE Trans. Pattern. Anal. Mach. Intell. 2018, 40, 48–62. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Huang, Z.; Wang, R.; Li, X.; Liu, W.; Shan, S.; Van Gool, L.; Chen, X. Geometry-Aware Similarity Learning on SPD Manifolds for Visual Recognition. IEEE Trans. Circuits Syst. Video Technol. 2018, 28, 2513–2523. [Google Scholar] [CrossRef] [Green Version]
- Xu, C.; Lu, C.; Gao, J.; Zheng, W.; Wang, T.; Yan, S. Discriminative Analysis for Symmetric Positive Definite Matrices on Lie Groups. IEEE Trans. Circuits Syst. Video Technol. 2015, 25, 1576–1585. [Google Scholar] [CrossRef]
- Faraki, M.; Harandi, M.; Porikli, F. A Comprehensive Look at Coding Techniques on Riemannian Manifolds. IEEE Trans. Neural Netw. Learn. Syst. 2018, 29, 5701–5712. [Google Scholar] [CrossRef]
- Faraki, M.; Harandi, M.; Porikli, F. Approximate infinite-dimensional Region Covariance Descriptors for image classification. In Proceedings of the 2015 IEEE International Conference on Acoustics, Speech and Signal Processing, South Brisbane, Australia, 19–24 April 2015. [Google Scholar] [CrossRef]
- Zhang, L.; Li, H. Incremental Nyström Low-Rank Decomposition for Dynamic Learning. In Proceedings of the Ninth International Conference on Machine Learning and Applications, Washington, DC, USA, 12–14 December 2010. [Google Scholar] [CrossRef]
- Cristianini, N.; Shawe-Taylor, J.; Elisseeff, A.; Kandola, J.S. On kernel target alignment. In Proceedings of the 2001 Conference and Workshop on Neural Information Processing Systems, Vancouver, BC, Canada, 3–8 December 2001. [Google Scholar]
- Cortes, C.; Mohri, M.; Rostamizadeh, A. Algorithms for learning kernels based on centered alignment. J. Mach. Learn. Res. 2012, 13, 795–828. [Google Scholar] [CrossRef]
- Kim, M.; Kumar, S.; Pavlovic, V.; Rowley, H. Face tracking and recognition with visual constraints in real-world videos. In Proceedings of the 2008 IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 23–28 June 2008. [Google Scholar] [CrossRef] [Green Version]
- Li, Y.; Wang, R.; Shan, S.; Chen, X. Hierarchical hybrid statistic-based video binary code and its application to face retrieval in TV-series. In Proceedings of the 2015 IEEE International Conference and Workshops on Automatic Face and Gesture Recognition, Ljubljana, Slovenia, 4–8 May 2015. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Database | ||
|---|---|---|---|
| YTC [51] | ICT-BBT [52] | ICT-PB [52] | |
| Ours—Jeffrey | 44.50% | 65.40% | 36.83% |
| Ours—LEM | 62.67% | 73.20% | 48.60% |
| Ours—Stein | 79.00% | 86.80% | 71.17% |
| Ours—AIRM | 82.33% | 87.80% | 68.20% |
| Method | Spatial Features | Database | ||
|---|---|---|---|---|
| YTC [51] | ICT-BBT [52] | ICT-PB [52] | ||
| Ours—Jeffrey | Regional | 36.33% | 57.60% | 37.50% |
| Global | 38.33% | 67.80% | 22.50% | |
| Combination | 44.50% | 65.40% | 36.83% | |
| Ours—LEM | Regional | 50.33% | 64.00% | 40.67% |
| Global | 67.33% | 79.60% | 47.33% | |
| Combination | 62.67% | 73.20% | 48.60% | |
| Ours—Stein | Regional | 73.00% | 76.80% | 61.83% |
| Global | 76.00% | 92.60% | 65.67% | |
| Combination | 79.00% | 86.80% | 71.17% | |
| Ours—AIRM | Regional | 69.50% | 75.00% | 59.83% |
| Global | 76.83% | 82.00% | 62.50% | |
| Combination | 82.33% | 87.80% | 68.20% |
| Method | Database | ||
|---|---|---|---|
| YTC [51] | ICT-BBT [52] | ICT-PB [52] | |
| RieCovDs—AIRM [39] | 69.33% | 66.65% | 58.33% |
| RieCovDs—LEM [39] | 69.63% | 68.60% | 56.67% |
| AidCovDs—AIRM [40] | 73.94% | 54.90% | 61.67% |
| AidCovDs—LEM [40] | 77.12% | 61.10% | 57.67% |
| LEML [42] | 74.00% | 78.20% | 49.33% |
| SPDML—AIRM [43] | 74.67% | 78.20% | 52.00% |
| SPDML—Jeffery [43] | 75.00% | 79.20% | 52.33% |
| SPDSL—LEM [44] | 78.33% | 75.20% | 55.31% |
| SPDSL—AIRM [44] | 80.50% | 72.40% | 57.50% |
| DALG [45] | 78.67% | 86.89% | 56.83% |
| CERML [41] | 82.63% | 85.00% | 66.77% |
| Ours—Stein | 79.00% | 86.80% | 71.17% |
| Ours—AIRM | 82.33% | 87.80% | 68.20% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, X.; Liu, S.; Ma, Z. A Framework for Short Video Recognition Based on Motion Estimation and Feature Curves on SPD Manifolds. Appl. Sci. 2022, 12, 4669. https://doi.org/10.3390/app12094669
Liu X, Liu S, Ma Z. A Framework for Short Video Recognition Based on Motion Estimation and Feature Curves on SPD Manifolds. Applied Sciences. 2022; 12(9):4669. https://doi.org/10.3390/app12094669
Chicago/Turabian StyleLiu, Xiaohe, Shuyu Liu, and Zhengming Ma. 2022. "A Framework for Short Video Recognition Based on Motion Estimation and Feature Curves on SPD Manifolds" Applied Sciences 12, no. 9: 4669. https://doi.org/10.3390/app12094669
APA StyleLiu, X., Liu, S., & Ma, Z. (2022). A Framework for Short Video Recognition Based on Motion Estimation and Feature Curves on SPD Manifolds. Applied Sciences, 12(9), 4669. https://doi.org/10.3390/app12094669