Abstract
In a great deal of theoretical and applied cognitive and neurophysiological research, it is essential to have more vocabularies with concreteness/abstractness ratings. Since creating such dictionaries by interviewing informants is labor-intensive, considerable effort has been made to machine-extrapolate human rankings. The purpose of the article is to study the possibility of the fast construction of high-quality machine dictionaries. In this paper, state-of-the-art deep learning neural networks are involved for the first time to solve this problem. For the English language, the BERT model has achieved a record result for the quality of a machine-generated dictionary. It is known that the use of multilingual models makes it possible to transfer ratings from one language to another. However, this approach is understudied so far and the results achieved so far are rather weak. Microsoft’s Multilingual-MiniLM-L12-H384 model also obtained the best result to date in transferring ratings from one language to another. Thus, the article demonstrates the advantages of transformer-type neural networks in this task. Their use will allow the generation of good-quality dictionaries in low-resource languages. Additionally, we study the dependence of the result on the amount of initial data and the number of languages in the multilingual case. The possibilities of transferring into a certain language from one language and from several languages together are compared. The influence of the volume of training and test data has been studied. It has been found that an increase in the amount of training data in a multilingual case does not improve the result.
Keywords:
neural networks; extrapolation; concreteness; abstractness; dictionaries; BERT; multilingual space 1. Introduction
The category of concreteness/abstractness (C/A) has been the focus of cognitive research for decades. The problem of representing concrete and abstract objects in the human brain poses a serious challenge to all cognitive science [1]. Concreteness/abstractness is one of the main organizational axes of the mental vocabulary [2].
The main approach to defining these concepts is as follows [3]. Concrete concepts are those that are perceived by the senses. Examples of specific words are cupcake or computer. Abstract concepts are not perceived by the senses—for example, ‘soul’ or ‘trust’. Similar interpretations are found in many works. Thus, in the work [4], the following definition is given: ’abstract nouns are those nouns whose denotata are not part of the concrete physical world and cannot be seen or touched’. A similar definition is offered in [5].
To support all such studies, dictionaries with indices characterizing the degree of concreteness/abstractness of words are required. The dictionary is created by polling native speakers, who are asked to rate the concreteness/abstractness of the given words. For the English language, the first major dictionary of this kind was created in 1981 [6]. It contains nearly 4000 words and is freely available from the psycholinguistic MRC database (https://websites.psychology.uwa.edu.au/school/MRCDatabase/uwa_mrc.htm (accessed on 4 May 2022)). Later, a dictionary of almost 40 thousand words was created [5]. Each word receives at least 25 ratings from respondents on a 5-point scale, which are averaged. In addition to English, a comparable dictionary (30,000 words) was created only for Dutch [7]. An apparent problem is the extraordinary complexity of creating such dictionaries. For the German language, the dictionary [8] contains only 4000 words. A database with 6000 words of concreteness/abstractness ratings for the Croatian language has recently been published [9]. The dictionary for the Russian language [10] currently contains 1000 words and is available at https://kpfu.ru/tehnologiya-sozdaniya-semanticheskih-elektronnyh.html (accessed on 4 May 2022). Similar dictionaries have been created for Italian, Chinese, and some other languages.
Two obvious tasks arise: (1) increasing the size of the dictionaries and (2) creating dictionaries for other languages, which one can try to solve using modern computer technology, extrapolating from existing human estimates. The main idea in extrapolating estimates to previously unappreciated words is to use vector semantics of words built on a large corpus of texts and obtain new estimates based on the semantic proximity of words in the constructed semantic space. This idea has been implemented in several works. To transfer ratings from one language to another, creating a single multilingual semantic space is appropriate. This approach, to the best of our knowledge, has been implemented in two works [11,12].
In this article, we will apply technologies based on neural networks with deep learning to both of the above problems for the first time. The article is devoted to the following research tasks:
- (1)
- Improve the quality of extrapolation of human ratings for concreteness/abstractness by applying deep learning models.
- (2)
- Apply deep learning models to transfer ratings from one language to another and evaluate the quality of ratings obtained in this way.
- (3)
- Evaluate the impact of the size of dictionaries when used as a training set and during cross-language transfer.
- (4)
- Evaluate the possibility of using the data of several languages simultaneously during a cross-lingual transfer of concreteness/abstractness ratings.
The article is organized traditionally. Section 2 provides a literature review. Section 3 describes the data—the vocabularies used and the methods used—and additional training of several types of neural networks based on a transformer architecture [13]. Section 4 describes the results obtained: the extrapolation of ratings with quality assessment. Finally, in Section 5, the conclusions summarize the research results and we discuss plans for further work.
2. Related Works
Research on concreteness/abstractness is conducted broadly from psychology and psycholinguistics to neurophysiology and medicine. A fresh overview can be found in [14]. In neurophysiology, the localization of the concepts of concreteness/abstractness was studied extensively. In many experiments using neuroimaging techniques, it has been shown that concrete and abstract words are represented in different neuroanatomical structures of the brain.
In psychological research, the so-called ’effect of concreteness’ has been established, demonstrating the greater ease of processing specific words in the human mind. Concrete words are better remembered [15], better recognized [16], read faster [17], and learned faster [18]. Dictionary definitions are easier to write and more detailed [19]. Concrete words are easier to associate [20]. The concepts of concreteness and abstractness have been subjects of study in linguistics for a long time. However, recently, with the emergence of large corpora of texts and large lexical ontologies, fundamentally new research ideas and results have appeared. The most interesting is the following. In [21], it is shown that, over time, the degree of specificity of words increases. In [22], it is shown that the density of the set of semantically close words is higher for concrete words compared to abstract ones. In [23], it is noticed that in text corpora, abstract words are more often found together with abstract words and concrete ones with concrete ones. The work [24] compares the categories of concreteness and specificity.
To conduct psychological and neurophysiological experiments, lists of words with estimates of the degree of their concreteness/abstractness are needed. Such lists are created by interviewing native speakers and extrapolating human estimates by machine methods. A significant number of works have been devoted to the development of machine extrapolation methods: [2,25,26,27,28,29,30,31,32,33].
Early work was based on thesauri such as WordNet, with ratings shifted to synonyms. The next step was using vector semantics applicable to large corpora of texts. Rankings for new words were based on the semantic proximity of words in the constructed semantic space [25,28,30,31]. Thus, to create a computer dictionary in any language, a necessary condition is the existence of a large body of texts, based on which vector semantics can be built. Vector semantics was constructed using various methods: Latent Semantic Analysis, the High Dimensional Explorer model [34], the Skipgram vector-embedding model [35], etc.
Evaluation of the quality of machine dictionaries is also of fundamental importance. They are assessed by comparison with human ones with the calculation of the correlation coefficient of the two dictionaries, most often according to Spearman. By far, the best result achieved is the machine dictionary for English of work [36], which has a human correlation coefficient of 0.9. The dictionary is built using fastText technology to build a semantic space and SVM as a classifier. Extrapolation of human estimates is done by cross-validation against a 40,000-word dictionary [5]. In [5], two human dictionaries were compared, and it was found that the correlation coefficient between them was 0.919. It is natural to interpret this value as the maximum possible for machine extrapolation.
In most papers, only one fixed-size dictionary is considered. In [12], three English dictionaries of different sizes are taken, which makes it possible to reveal the dependence of the quality of extrapolation on the size of the dictionary. For dictionaries of size 22,797, 4061, and 3000 words, the correlation scores were 0.887, 0.872, and 0.848, respectively, which clearly indicates a dependence on the size of the dictionary. The larger the dictionary, the more accurate the extrapolation. At the same time, it can be noted that the quality of extrapolation increases significantly with an increase in the size of the dictionary from 3 to 4 thousand; however, a much larger increase of the size to 23 thousand words affects the result to a lesser extent.
All of the above work was carried out for one language—in most cases, it is English. However, recently, [37] proposed a way to combine several languages in a single semantic space based on English. This is accomplished by using Google-Translate-obtained translations into English of the 10,000 most frequent lexical items in a given language.
The article [12] investigates the cross-lingual transfer of ratings for the Croatian–English language pair; data are presented in the ‘Concreteness and imageability lexicon MEGA.HR-Crossling’ available at http://hdl.handle.net/11356/1187 (accessed on 4 May 2022) [38]. An SVM regression model and deep feedforward neural network were applied, which led to almost the same results. The human dictionaries from [5,9] were used for English and Croatian, respectively. As a result, for the transfer of specificity ratings from English to Croatian, the Spearman correlation coefficient between the transferred ratings and the human ones was 0.724; for the reverse order for transfer, the correlation was 0.791. For other properties of words commonly considered in psychological research, correlation scores are lower. For example, for the imageability property, when transferring from Croatian to English, the Spearman coefficient was only 0.694 [12].
In [11], this approach is applied to the problem of transferring concreteness ratings from English to other languages, as a result of which concreteness/abstractness dictionaries were obtained for 77 languages. For one language, Dutch, an assessment of the quality of the dictionary created in this way was obtained—the Spearman correlation coefficient = 0.76, which is interpreted as a very high result. Correlation coefficients for other languages were not released. A similar approach with automatic translation of words and transfer of ratings was applied to other properties of words—valence, arousal, and dominance—reflecting the emotional coloring of words. Valence, arousal, and dominance word ratings are very important in the task of sentiment analysis of texts, particularly on social networks [39].
Thus, it remains unclear how well transferring estimates from one language to another should work to produce a good dictionary. However, this is important for low-resource languages. High-quality cross-language transfer would make it possible to quickly obtain dictionaries with concrete/abstract ratings without conducting time-consuming and expensive surveys of respondents.
3. Datasets and Methods
3.1. Datasets and Preprocessing
Our research covers datasets in 5 languages: English, German, Dutch, Croatian, and Russian. The dictionaries created by interviewing informants were used, respectively, from the works [5,7,8,9,10].
We study methods for the prediction of C/A ratings only for nouns. Therefore, original dictionaries were filtered: the English dictionary already had a POS tag, the Russian dictionary contained nouns only, and the remaining three dictionaries were filtered using the spaCy library (https://spacy.io (accessed on 4 May 2022)). Sizes of the resulting dictionaries are the following: English (13,802), German (3242), Dutch (15,242), Croatian (1616), and Russian (1000). When extrapolating ratings within one language, 90% of the available ratings are randomly selected as a training set and 10% as a test set.
When transferring ratings from one language to another, the dictionary of the source language is used to train the model, while the dictionary of the target language is used for testing. Considering that all dictionaries have a different volume, the ratings were transferred in two versions—with complete dictionaries and with dictionaries of 1000 words. The most frequent nouns were included in the dictionary in the second case.
3.2. Methods
Transformer-based deep neural network architectures are well known for their effectiveness in different natural language processing problems, including machine translation and text generation [13]. Bidirectional encoder representations from transformers (BERT) recently [40] have disrupted the fields of language modeling and learning representations from unstructured text. Such representations are derived as a result of semi-supervised pre-training on a large corpus, stored as a set of weights of a neural network (usually, hundreds of millions or larger) and later can be used for fine-tuning to solve a down-stream task. In our study, we consider three pre-trained transformer-based neural architectures capable of processing texts in different languages. The selected state-of-the-art multilingual pre-trained models include the following (the checkpoints of the transformer-based models are available at https://huggingface.co (accessed on 4 May 2022)):
- M1: distilled version of multilingual BERT (distil. mBERT) [41],
- M2: base multilingual BERT (mBERT) [40],
- M3: Microsoft’s Multilingual-MiniLM-L12-H384 (MS-MiniLM) [42]
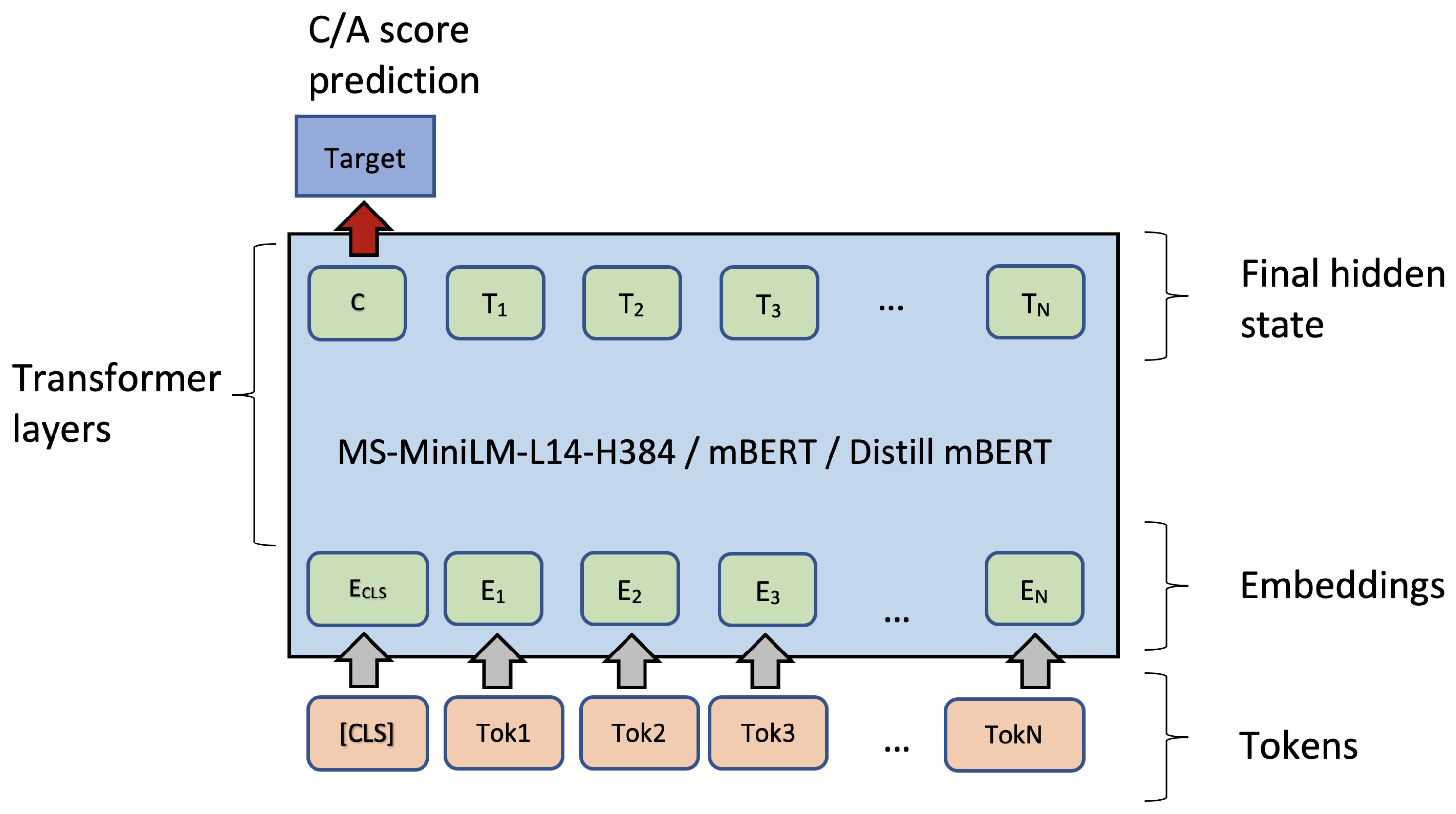
These three multilingual models were pre-trained on masked language modeling tasks and are able to represent text written in many languages. Before applying them in C/A rating prediction for words, we fine-tuned them using a simple architecture (see Figure 1).
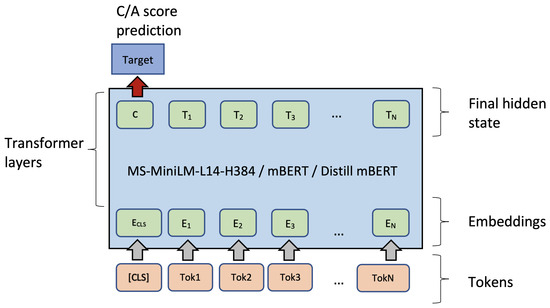
Figure 1.
A schema of fine-tuning of transformer-based pre-trained models. Hidden representation of the [CLS] is used for fine-tuning.
We proposed to fine-tune each of the models on a training subset of words from the expert C/A dictionary with ratings and then test the fine-tuned model on the C/A rating prediction (regression) task. Typically, pre-trained models can be fine-tuned on a classification task using the [CLS] token. In our experimental setup, each word was provided with a real number in the range [1, 5] as a label. Therefore, in fine-tuning, we used concreteness rating prediction as a numeric output (Figure 1). To this end, the loss function and the training dataset should be modified accordingly; we used mean squared error as a loss function. Training sets for each language should be scaled in the following manner: ratings from the dictionary are linearly transformed from a range [1, 5] to a range between 0.0 (‘abstract’) and 1.0 (‘concrete’). On the one hand, this linear transformation does not affect the performance measures (e.g., Pearson’s correlation coefficient is not sensitive to scaling). On the other hand, the training process becomes more stable if target labels are in the [0.0, 1.0] range.
The next step before fine-tuning is setting the maximum input sequence length. We set the maximum length of the sequence to 10 tokens as most of the words should not be longer than ten tokens from BERT’s vocabulary. All other input tokens are padded and are not used in calculating the loss function. During fine-tuning, we use typical settings for learning rate () and batch size (bs = 32). We also use 2 to 4 epochs for fine-tuning, as more epochs led to overfitting on the validation dataset. The architecture is shown in Figure 1. Here, one can see the input sequence that starts with a special [CLS] token along with internal token representations (in ‘Transformer layers’) and the output of a model. This schema is the same for the three models we selected for testing: MS-MiniLM, mBERT, and distill mBERT.
3.3. Single-Language BERT
Furthermore, we apply the single-language (English) BERT model to extrapolate data within a single language. Out of the 40-thousand-word dictionary for English [5], 35 thousand words were chosen as the training set and 4 thousand as the test set. Note that, here, we ignore the POS tag and use the whole dictionary. For fine-tuning of the single-language BERT model, the values of the hyperparameters are (bs = 64, epochs = 16).
4. Results
4.1. Results of Single-Language BERT
The results for English (Table 1) allow us to compare them with the results of other studies. On the test set, Spearman’s correlation coefficient equals 0.910, with 0.920 (Pearson’s correlation, ). Thus, a result was obtained that surpasses the best previous result achieved in the work [36]. Considering the value of the correlation coefficient of 0.919 (according to Spearman’s ) to be the maximum possible, the result of this work is 97.9% of it, and our result is 99% of it. In [36], on the same vocabulary [5], the SVM classifier was used in combination with fastText. Our result confirms the advantages of BERT over previous architectures. Note that without fine-tuning, the results are very low.

Table 1.
Dependence of the quality of approximation on the size of the training set.
We studied the dependence between the quality of extrapolation and the size of the training set. Table 1 presents the correlation coefficients for the same test set of 4000 words and for different sizes of the training set.
Thus, here, we obtained the expected result: the quality of extrapolation correlates with the size of the training set. This is in good agreement with the results of [12]. However, it should be noted that applying BERT on a training set of 1000 words exceeded most of the previously published estimates with significantly larger training set sizes. The result is only 5% worse than the result obtained on 35 thousand words (train set). For low-resource languages, where no such large dictionaries with human ratings are available, the result with a 1000-word dictionary should be assessed as quite acceptable.
In several works, including [11], it has been observed that machine ratings are most different from human ratings for the words that have extreme ratings from respondents. Table 2 shows the words from the predicted ratings with the largest discrepancies between machine and human C/A estimates.
Table 2.
Discrepancy between machine and human estimates (both minimum and maximum differences with respect to MAE).
4.2. Cross-Lingual Transfer of Concreteness Estimates
The presence of good large dictionaries for some languages raises the question of transferring ratings from one language to another. This is possible thanks to the existence of multilingual neural networks pre-trained in several languages simultaneously.
In the first series of calculations, the dictionaries were used entirely. In all models, the hyperparameters bs = 64, 3 epochs were used in all models. The best result was shown by the MS-MiniLM model. Table 3 shows Spearman’s correlation coefficients between ratings transferred from the source language with their values in the target language for three models. Pearson’s coefficients are, on average, 0.01 less. The best-achieved result (for Russian) exceeds the result of work [11].
Table 3.
Spearman’s correlation coefficient for complete dictionaries. Notation: ‘M1’ stands for the distilled multilingual BERT, ‘M2’ stands for the multilingual BERT, ‘M3’ stands for the MS-MiniLM (bold face corresponds to the best model for a language).
For the multilingual BERT model, the results are, on average, almost the same, only slightly lower, but MS-MiniLM provides the absolute best coefficients among all transfers. These are the coefficients for transferring from English and from German to Russian, 0.8 and 0.79, respectively. The results shown by the distilled multilingual BERT model are noticeably worse.
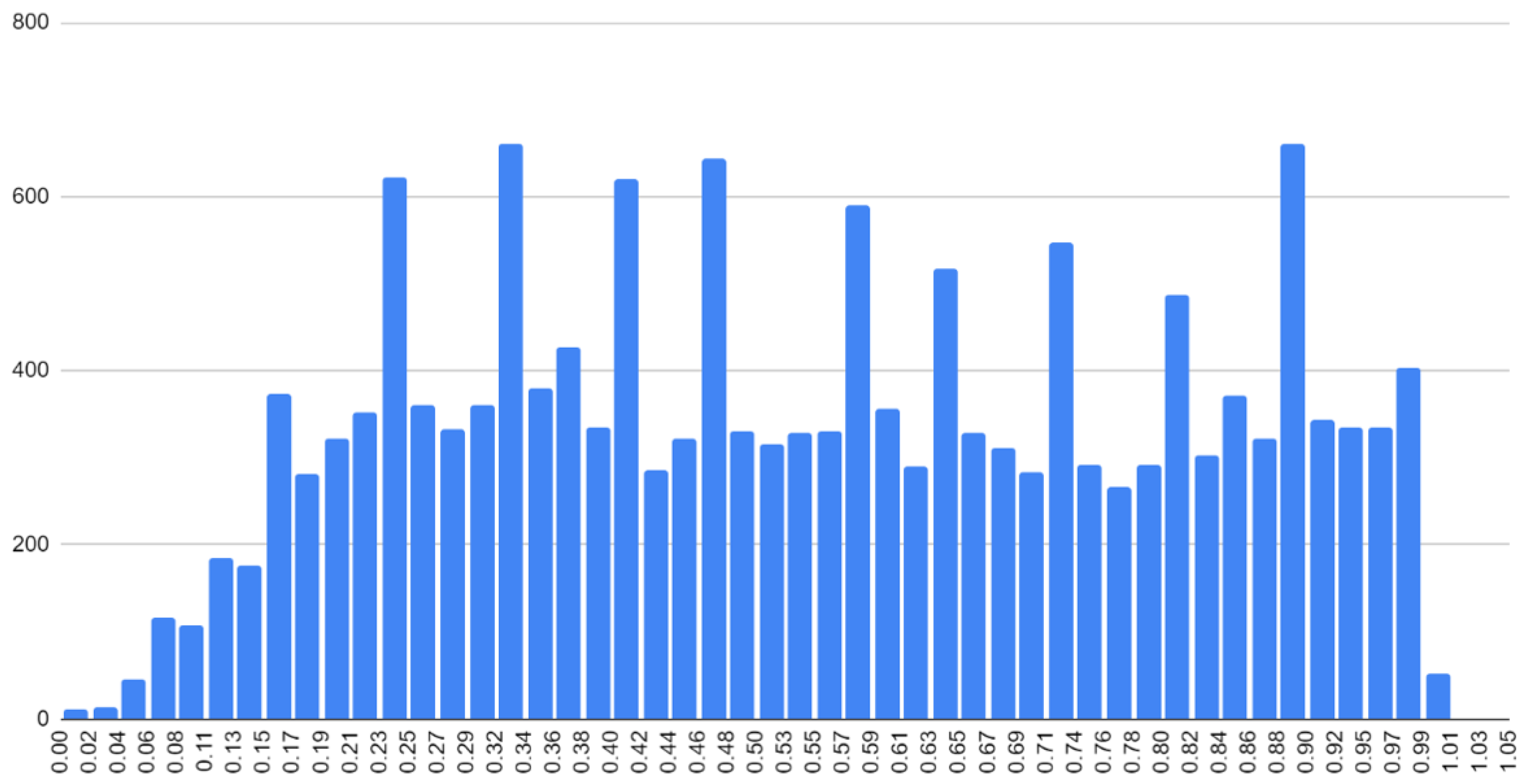
When considering Table 3, it is noteworthy that for different languages, the results differ quite significantly. The hardest-to-obtain rankings are for Dutch and Croatian. In Figure 2 is a histogram of word scores for Dutch.
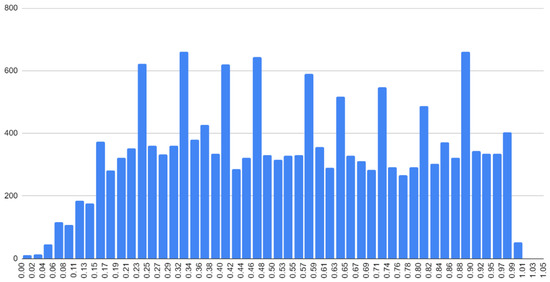
Figure 2.
Histogram of concreteness ratings from Dutch dictionary.
The histogram shape is noticeably different from similar histograms for English and Russian languages. Noteworthy is the non-smooth character of the histogram, with statistically unexplained peaks, which may be a consequence of incorrect post-processing of empirical data or may be due to numerical binning issues or anchoring to discrete levels.
In Table 3, one can see a significant difference between the coefficients when transferred into Russian and from Russian (the average difference is 0.145). One of the possible explanations is that the Russian dictionary contains only 1000 of the most frequent words (nouns) of the language, for which there were a lot of data in the corpora on which the neural networks were pre-trained, and they are better represented in models; for them, it is easier to predict the extrapolated ratings. For other languages, especially English, the dictionaries are much larger and contain more rare words, the ratings for which are more difficult to predict. We then conducted a study of the dependence of the results on the volume of dictionaries.
4.3. Dependence of the Transfer Quality on the Size of Dictionaries
We are interested in the question of how the size of the source dictionary and the target dictionary affects the quality of the transfer. We allocate 1000 most frequent words for each language in dictionaries to do this. Since the dictionary for the Russian language contains only nouns, nouns were chosen for other languages as well. In addition, only in two languages, English and Dutch, dictionaries contain a sufficiently large number (over 1000) of adjectives or verbs.
Thus, to make all languages equal in terms of the size of the word sets used for training and testing, we report results only for nouns. Moreover, our preliminary experiments with adjectives show lower results (correlation is less than 0.6).
Table 4 presents correlation coefficients in 1000-word dictionary to 1000-word transfer. Comparing Table 3 and Table 4 shows that all coefficients except one become higher when a complete dictionary is replaced with a 1000-word dictionary. At first glance, this result seems unnatural, but in the work [43], a similar result was obtained using the material of emotive vocabulary. On a 1000-word dictionary, machine extrapolation of the data gives a better correlation coefficient than on a larger one (a dictionary with 14 thousand words); this is the case for both English and Spanish. A similar result was obtained in [44], also for an emotive vocabulary. However, a direct comparison with the results of these two articles is impossible since both the size of the training set and the test set differ proportionally. In this paper, the difference is not proportional. Therefore, it makes sense to take a closer look at the influence of the size of the source and target dictionaries in our task; we separate these two factors.
Table 4.
Spearman’s correlation coefficient for MS-MiniLM model, 1000-word dictionaries. In the table, p-values for correlation coefficient values are less than 0.01.
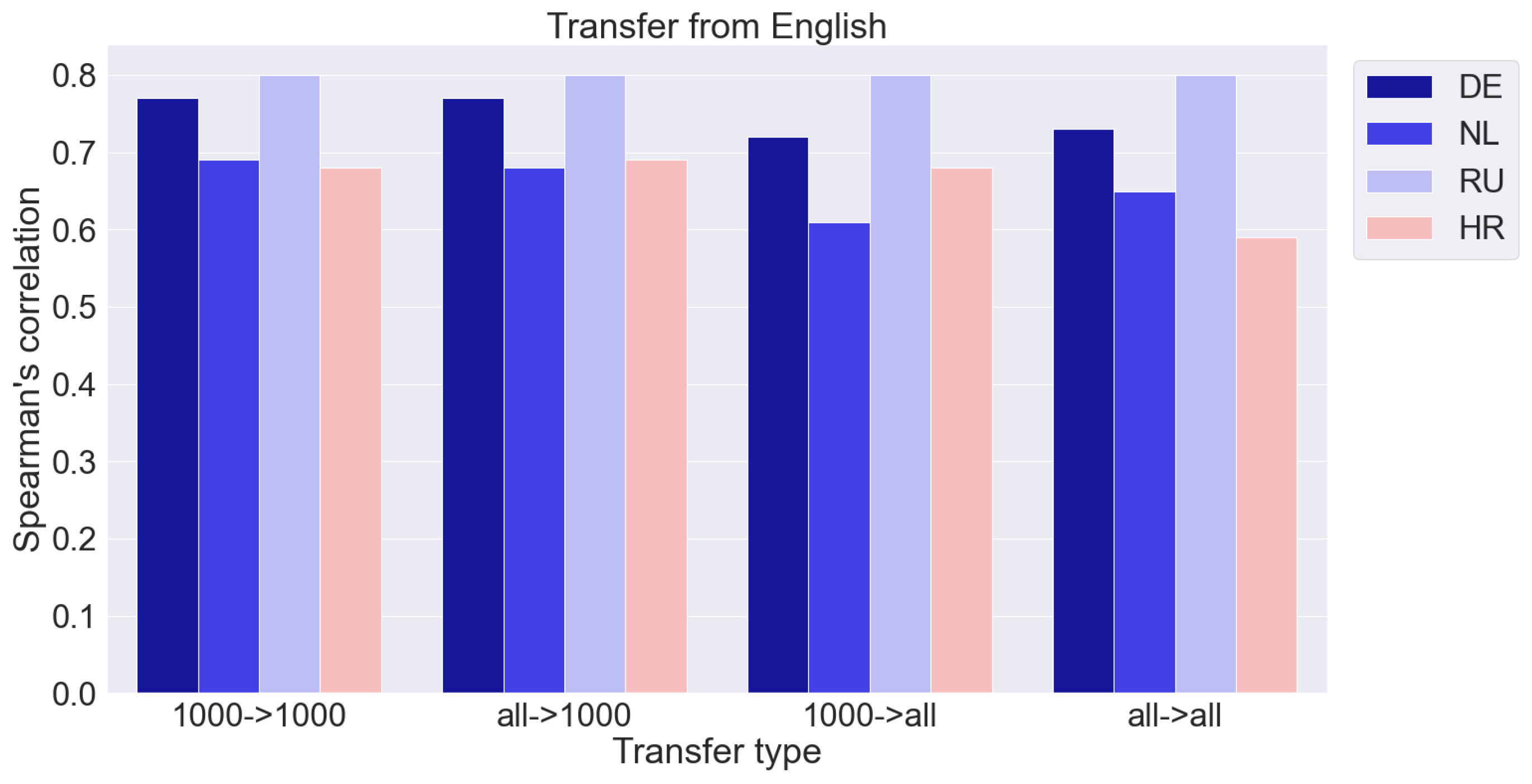
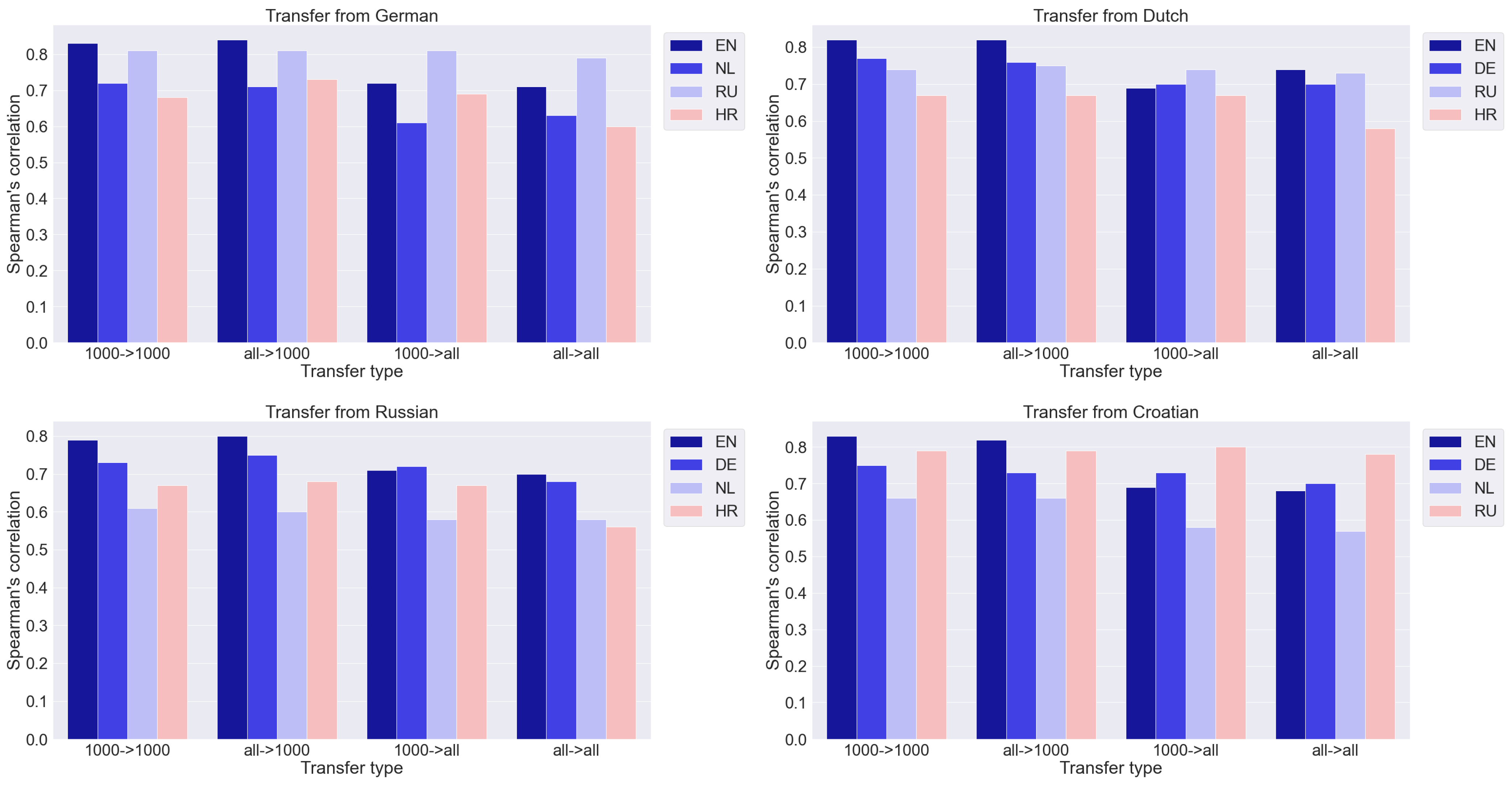
We compare four transfer options: from a dictionary of 1000 words to a dictionary of 1000 words (1000 -> 1000), from a complete dictionary to a dictionary of 1000 words (all -> 1000), from a dictionary of 1000 words to a complete dictionary (1000 -> all ), and from the full dictionary to the full one (all -> all). As mentioned above, the best results are achieved by MS-MiniLM. The results are presented in Figure 3 and Figure 4. The y-axis shows the Spearman correlation coefficient. Numerical data are given in the Appendix A (Table A1, Table A2, Table A3, Table A4, Table A5).
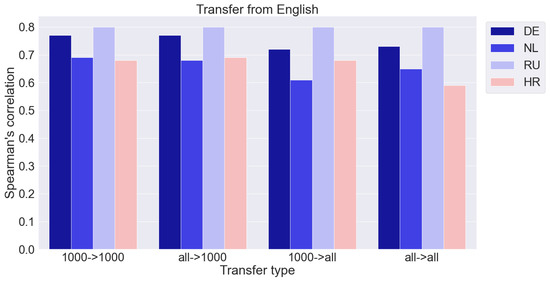
Figure 3.
Results of transfer from English dataset to four other languages with respect to dictionary size (‘all’ corresponds to a full dictionary, ‘1000’ corresponds to dictionary with 1000 words).
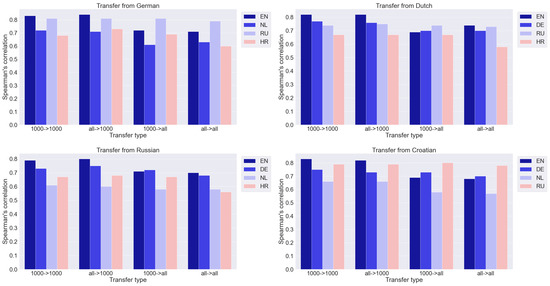
Figure 4.
Results of transfer from different languages.
We consider two separate cases: (A) the size of the source vocabulary is fixed while the target vocabulary changes, and (B) the size of the target vocabulary is fixed while the source is changed.
- A.
- The size of the source vocabulary is fixed while the target vocabulary changes. This is shown in Figure 3 and Figure 4 by moving from the first block of columns to the third and from the second to the fourth. The values of the correlation coefficients in the third and fourth blocks are noticeably smaller than in the first and second, respectively. It is a natural result that an increase in the number of words to which rankings need to be extrapolated leads to a deterioration in quality.
- B.
- The size of the target vocabulary is fixed while the source is changed. This is shown in Figure 3 and Figure 4 by moving from the first block of columns to the second and from the third to the fourth. Increasing the size of the training set of 1000 words to a complete dictionary does not lead to a noticeable improvement in the results. The quality of the ratings obtained due to the transfer can be assessed as sufficiently high. Thus, the quality of the cross-lingual transfer remains practically at the same level. This result is somewhat unexpected. A smaller amount of training data, it would seem, should lead to a deterioration in the results, which we have in the case of extrapolation within one language (Table 1). However, with a cross-lingual transfer, the situation changes, and an increase in the amount of training data does not improve the result. All the information sufficient for the qualitative transfer of ratings from one language to another is already contained in the 1000 most frequent words, and rarer words do not add useful information. Perhaps this is due to the quality of the multilingual semantic space, in which the correspondence between languages is well established for more frequent words and worse for rare ones. However, this issue requires a separate additional study.
The data for the distilled multilingual BERT and multilingual BERT models on 1000-word dictionaries are presented in Appendix A (Table A6 and Table A7). The results of these models, as well as in the previous experiment, turned out to be somewhat worse. For example, the MS-MiniLM model has five coefficients greater than or equal to 0.8, while the distilled multilingual BERT has none at all, and the multilingual BERT has only one. The MS-MiniLM model has no coefficient less than 0.6, while multilingual BERT has three, and distilled multilingual BERT has six such cases.
4.4. Multilingual Transfer
Our next goal is to test the effect of mixing multiple languages in the training set. To compare the results with the previous ones, we form a 1000-word sample, taking 250 words from four languages randomly from 1000 most frequent ones. Next, we extrapolate them to a 1000-word list (the same as in the previous experiment) and calculate the correlation coefficient. The results are shown in Table 5.
Table 5.
Spearman’s correlation coefficient for the MS-MiniLM model (1000-word dictionaries).
The results of using mixed data of four languages in three cases were higher than the arithmetic average of four transfers from each language separately, including for one language—Dutch—noticeably higher. For one language, Croatian, the result remained practically unchanged, and for Russian, it even somewhat worsened.
The results presented in Table 5 do not allow us to come to a conclusion about the advantage of using mixed data from different languages. The improvement in the results in the first three rows of Table 5 takes place in cases where the source data are taken from languages of different structures (different branches of the Indo-European family of languages). It is possible that this factor is essential, but limited data do not yet enable us to draw this conclusion. An improvement is not observed (last two rows of the Table 5) in cases where most of the source data relate to languages of a different branch than the target language.
Other neural network models produce, as described above, the worst result, except for the multilingual BERT model, which, when applied to English, provided the highest correlation coefficient of 0.843.
5. Discussion and Conclusions
Various models and methods have been used to extrapolate human concreteness/ abstractness ratings to obtain large vocabularies: LSA, GloVe, fastText, etc. In this work, the most modern models were used for the first time: BERT, MS-MiniLM. With extrapolation within one language, it was possible to improve all previous assessments of the quality of the dictionary, to bring them to a value of 0.910 according to Spearman (for the English language), with an expected marginal estimate of 0.919. The BERT model can be recommended for the extrapolation of other ratings (valence, etc.) and in other languages. A prerequisite is the pre-training of BERT in a given language or the presence of a large body of texts required for training the model. A human-rated dictionary containing around 1000 words is also in demand.
In the absence of a vocabulary with human ratings for a language, an approach related to transferring ratings from one language, where they already exist, to another can be applied. Previously, this approach was used in combination with the automatic translation of words, thus creating a single semantic space for several languages. The best previously achieved result on this path is 0.76 [11]. The best score that we obtained is 0.843, which is close to the scores in the single-lingual case. Comparison of the results of neural networks of different architectures showed a noticeable advantage of MS-MiniLM.
In addition to the architecture of neural networks, the result is influenced by many other factors analyzed in this article. First of all, these are the sizes of the dictionaries of the source and target languages. In this paper, it is shown that an increase in the training set is important for the one-language case but not essential for the cross-language transfer. A 1000-word vocabulary is sufficient for fine-tuning the models and obtaining a high-quality vocabulary in the target language.
The article is the first to consider the option of transferring from mixed data of several languages to the target language. It turned out that this led to some improvement in the results. It is hypothesized that linguistic diversity in source data may be a favorable factor.
When considering different languages, the hypothesis about the importance of the typological proximity of languages is suggestive. However, it is not confirmed by our data. Russian and Croatian are Slavic languages; the other three are Germanic.
The linguistic affinity of the languages did not provide the best result when transferring from Russian to Croatian and vice versa compared to the Germanic languages. Thus, the main results are as follows:
- (1)
- We presented a deep learning model and applied it in the task of extrapolating human concreteness/abstractness ratings to achieve a result that exceeds those previously published.
- (2)
- The methodology for transferring ratings from one language to another is described; estimates of the quality of the ratings are obtained.
- (3)
- It has been established that dictionaries of 1000 words in size provide a sufficiently high quality of extrapolation when used as a training set; in a cross-language transfer, they give almost the same quality as large dictionaries.
- (4)
- The simultaneous use of data from several languages does not provide a significant improvement in the results of cross-lingual transfer.
- (5)
- The listed results are obtained by considering the data of all languages for which there are sufficiently large dictionaries with human concreteness/abstractness ratings in the public domain.
- (6)
- Summing up, we note that the latest generation neural networks allow us to obtain rating dictionaries of very high quality, providing a radical reduction in labor costs.
Using the described techniques for extrapolating ratings and their cross-lingual transfer can be of practical importance for the rapid construction of dictionaries in low-resource languages. Thus, the significance and usability of the results obtained in the article is that they define a method for the fast and inexpensive construction of a dictionary with concreteness/abstractness ratings of nouns. Our results allow us to claim that:
- to build such a dictionary in any language, it is necessary to apply cross-lingual transfer learning from an already existing dictionary in one of the languages (for example, in English);
- for transferring, it is advisable to use Microsoft’s Multilingual-MiniLM-L12-H384 model, which showed better results compared to BERT and other models;
- in the source language, it is advisable to use a dictionary of 1000 most frequent words.
Author Contributions
V.S. proposed a methodology of the study and carried out supervision and administration of the project. V.I. developed software, carried out experiments and visualization. All authors have read and agreed to the published version of the manuscript.
Funding
This research was supported by the Kazan Federal University Strategic Academic Leadership Program.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Acknowledgments
We thank anonymous reviewers of the manuscript for their valuable comments.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A
Table A1.
Spearman’s correlation coefficients derived by MS-MiniLM model, transfer from English.
Table A1.
Spearman’s correlation coefficients derived by MS-MiniLM model, transfer from English.
| Transfer Type | DE | HR | NL | RU |
|---|---|---|---|---|
| 1000 -> 1000 | 0.77 | 0.68 | 0.69 | 0.80 |
| 1000 -> all | 0.72 | 0.68 | 0.61 | 0.80 |
| all -> 1000 | 0.77 | 0.69 | 0.68 | 0.80 |
| all -> all | 0.73 | 0.59 | 0.65 | 0.80 |
Table A2.
Spearman’s correlation coefficients derived by MS-MiniLM model, transfer from German.
Table A2.
Spearman’s correlation coefficients derived by MS-MiniLM model, transfer from German.
| Transfer Type | EN | HR | NL | RU |
|---|---|---|---|---|
| 1000 -> 1000 | 0.83 | 0.68 | 0.72 | 0.81 |
| 1000 -> all | 0.72 | 0.69 | 0.61 | 0.81 |
| all -> 1000 | 0.84 | 0.73 | 0.71 | 0.81 |
| all -> all | 0.71 | 0.60 | 0.63 | 0.79 |
Table A3.
Spearman’s correlation coefficients derived by MS-MiniLM model, transfer from Dutch.
Table A3.
Spearman’s correlation coefficients derived by MS-MiniLM model, transfer from Dutch.
| Transfer Type | DE | EN | HR | RU |
|---|---|---|---|---|
| 1000 -> 1000 | 0.77 | 0.82 | 0.67 | 0.74 |
| 1000 -> all | 0.70 | 0.69 | 0.67 | 0.74 |
| all -> 1000 | 0.76 | 0.82 | 0.67 | 0.75 |
| all -> all | 0.70 | 0.74 | 0.58 | 0.73 |
Table A4.
Spearman’s correlation coefficients derived by MS-MiniLM model, transfer from Russian.
Table A4.
Spearman’s correlation coefficients derived by MS-MiniLM model, transfer from Russian.
| Transfer Type | DE | EN | HR | NL |
|---|---|---|---|---|
| 1000 -> 1000 | 0.73 | 0.79 | 0.67 | 0.61 |
| 1000 -> all | 0.72 | 0.71 | 0.67 | 0.58 |
| all -> 1000 | 0.75 | 0.80 | 0.68 | 0.60 |
| all -> all | 0.68 | 0.70 | 0.56 | 0.58 |
Table A5.
Spearman’s correlation coefficients derived by MS-MiniLM model, transfer from Croatian.
Table A5.
Spearman’s correlation coefficients derived by MS-MiniLM model, transfer from Croatian.
| Transfer Type | DE | EN | NL | RU |
|---|---|---|---|---|
| 1000 -> 1000 | 0.75 | 0.83 | 0.66 | 0.79 |
| 1000 -> all | 0.73 | 0.69 | 0.58 | 0.80 |
| all -> 1000 | 0.73 | 0.82 | 0.66 | 0.79 |
| all -> all | 0.70 | 0.68 | 0.57 | 0.78 |
Table A6.
Spearman’s correlation coefficients for distilled multilingual BERT model, 1000-word dictionaries.
Table A6.
Spearman’s correlation coefficients for distilled multilingual BERT model, 1000-word dictionaries.
| Source/Target | EN | DE | NL | RU | HR |
|---|---|---|---|---|---|
| EN | - | 0.69 | 0.58 | 0.71 | 0.55 |
| DE | 0.79 | - | 0.57 | 0.72 | 0.55 |
| NL | 0.79 | 0.71 | - | 0.66 | 0.54 |
| RU | 0.75 | 0.66 | 0.45 | - | 0.57 |
| HR | 0.76 | 0.67 | 0.52 | 0.72 | - |
Table A7.
Spearman’s correlation coefficients for multilingual BERT model, 1000-word dictionaries.
Table A7.
Spearman’s correlation coefficients for multilingual BERT model, 1000-word dictionaries.
| Source/Target | EN | DE | NL | RU | HR |
|---|---|---|---|---|---|
| EN | - | 0.78 | 0.63 | 0.76 | 0.63 |
| DE | 0.83 | - | 0.65 | 0.79 | 0.63 |
| NL | 0.79 | 0.77 | - | 0.71 | 0.57 |
| RU | 0.77 | 0.74 | 0.52 | - | 0.62 |
| HR | 0.75 | 0.70 | 0.53 | 0.72 | - |
References
- Borghi, A.M.; Binkofski, F.; Castelfranchi, C.; Cimatti, F.; Scorolli, C.; Tummolini, L. The challenge of abstract concepts. Psychol. Bull. 2017, 143, 263. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Vankrunkelsven, H.; Verheyen, S.; De Deyne, S.; Storms, G. Predicting lexical norms using a word association corpus. In Proceedings of the 37th Annual Conference of the Cognitive Science Society, Pasadena, CA, USA, 22–25 July 2015; pp. 2463–2468. [Google Scholar]
- Spreen, O.; Schulz, R.W. Parameters of abstraction, meaningfulness, and pronunciability for 329 nouns. J. Verbal Learn. Verbal Behav. 1966, 5, 459–468. [Google Scholar] [CrossRef]
- Schmid, H.J. English Abstract Nouns as Conceptual Shells. Engl. Am. Stud. Ger. 2001, 2000, 4–8. [Google Scholar]
- Brysbaert, M.; Warriner, A.B.; Kuperman, V. Concreteness ratings for 40 thousand generally known English word lemmas. Behav. Res. Methods 2014, 46, 904–911. [Google Scholar] [CrossRef] [Green Version]
- Coltheart, M. The MRC psycholinguistic database. Q. J. Exp. Psychol. Sect. A 1981, 33, 497–505. [Google Scholar] [CrossRef]
- Brysbaert, M.; Stevens, M.; De Deyne, S.; Voorspoels, W.; Storms, G. Norms of age of acquisition and concreteness for 30,000 Dutch words. Acta Psychol. 2014, 150, 80–84. [Google Scholar] [CrossRef] [Green Version]
- Köper, M.; Im Walde, S.S. Automatically generated affective norms of abstractness, arousal, imageability and valence for 350,000 german lemmas. In Proceedings of the Tenth International Conference on Language Resources and Evaluation (LREC’16), Portorož, Slovenia, 23–28 May 2016; pp. 2595–2598. [Google Scholar]
- Peti-Stantić, A.; Anđel, M.; Gnjidić, V.; Keresteš, G.; Ljubešić, N.; Masnikosa, I.; Tonković, M.; Tušek, J.; Willer-Gold, J.; Stanojević, M.M. The Croatian psycholinguistic database: Estimates for 6000 nouns, verbs, adjectives and adverbs. Behav. Res. Methods 2021, 53, 1799–1816. [Google Scholar] [CrossRef]
- Akhtiamov, R.; Solovyev, V.; Ivanov, V. Dictionary of abstract and concrete words of the Russian language: A Methodology for Creation and Application. J. Res. Appl. Linguist. 2019, 10, 215–227. [Google Scholar]
- Thompson, B.; Lupyan, G. Automatic estimation of lexical concreteness in 77 languages. In Proceedings of the The 40th Annual Conference of the Cognitive Science Society (COGSCI 2018), Madison, WI, USA, 25–28 July 2018; pp. 1122–1127. [Google Scholar]
- Ljubešić, N.; Fišer, D.; Peti-Stantić, A. Predicting Concreteness and Imageability of Words Within and Across Languages via Word Embeddings. In Proceedings of the Third Workshop on Representation Learning for NLP, Melbourne, Australia, 20–22 July 2018; pp. 217–222. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. arXiv 2017, arXiv:cs.CL/1706.03762. [Google Scholar]
- Solovyev, V. Concreteness/Abstractness Concept: State of the Art. In Advances in Cognitive Research, Artificial Intelligence and Neuroinformatics; Velichkovsky, B.M., Balaban, P.M., Ushakov, V.L., Eds.; Springer International Publishing: Cham, Switzerland, 2021; pp. 275–283. [Google Scholar]
- Schwanenflugel, P.J.; Akin, C.; Luh, W.M. Context availability and the recall of abstract and concrete words. Mem. Cogn. 1992, 20, 96–104. [Google Scholar] [CrossRef] [Green Version]
- Fliessbach, K.; Weis, S.; Klaver, P.; Elger, C.E.; Weber, B. The effect of word concreteness on recognition memory. NeuroImage 2006, 32, 1413–1421. [Google Scholar] [CrossRef] [PubMed]
- Schwanenflugel, P.J.; Shoben, E.J. Differential context effects in the comprehension of abstract and concrete verbal materials. J. Exp. Psychol. Learn. Mem. Cogn. 1983, 9, 82. [Google Scholar] [CrossRef]
- Mestres-Missé, A.; Münte, T.F.; Rodriguez-Fornells, A. Mapping concrete and abstract meanings to new words using verbal contexts. Second Lang. Res. 2014, 30, 191–223. [Google Scholar] [CrossRef]
- Sadoski, M.; Kealy, W.A.; Goetz, E.T.; Paivio, A. Concreteness and imagery effects in the written composition of definitions. J. Educ. Psychol. 1997, 89, 518. [Google Scholar] [CrossRef]
- De Groot, A.M. Representational aspects of word imageability and word frequency as assessed through word association. J. Exp. Psychol. Learn. Mem. Cogn. 1989, 15, 824. [Google Scholar] [CrossRef]
- Snefjella, B.; Généreux, M.; Kuperman, V. Historical evolution of concrete and abstract language revisited. Behav. Res. Methods 2019, 51, 1693–1705. [Google Scholar] [CrossRef] [Green Version]
- Reilly, M.; Desai, R.H. Effects of semantic neighborhood density in abstract and concrete words. Cognition 2017, 169, 46–53. [Google Scholar] [CrossRef]
- Naumann, D.; Frassinelli, D.; im Walde, S.S. Quantitative semantic variation in the contexts of concrete and abstract words. In Proceedings of the Seventh Joint Conference on Lexical and Computational Semantics, New Orleans, LA, USA, 5–6 June 2018; pp. 76–85. [Google Scholar]
- Ivanov, V.; Solovyev, V. The Relation of Categories of Concreteness and Specificity: Russian Data. Comput. Linguist. Intellect. Technol. 2021, 20, 349–357. [Google Scholar]
- Bestgen, Y.; Vincze, N. Checking and bootstrapping lexical norms by means of word similarity indexes. Behav. Res. Methods 2012, 44, 998–1006. [Google Scholar] [CrossRef]
- Hollis, G.; Westbury, C.; Lefsrud, L. Extrapolating human judgments from skip-gram vector representations of word meaning. Q. J. Exp. Psychol. 2017, 70, 1603–1619. [Google Scholar] [CrossRef]
- Mandera, P.; Keuleers, E.; Brysbaert, M. How useful are corpus-based methods for extrapolating psycholinguistic variables? Q. J. Exp. Psychol. 2015, 68, 1623–1642. [Google Scholar] [CrossRef] [PubMed]
- Recchia, G.; Louwerse, M.M. Reproducing affective norms with lexical co-occurrence statistics: Predicting valence, arousal, and dominance. Q. J. Exp. Psychol. 2015, 68, 1584–1598. [Google Scholar] [CrossRef] [PubMed]
- Turney, P.D.; Littman, M.L. Unsupervised learning of semantic orientation from a hundred-billion-word corpus. arXiv 2002, arXiv:cs/0212012. [Google Scholar]
- Westbury, C.F.; Shaoul, C.; Hollis, G.; Smithson, L.; Briesemeister, B.B.; Hofmann, M.J.; Jacobs, A.M. Now you see it, now you don’t: On emotion, context, and the algorithmic prediction of human imageability judgments. Front. Psychol. 2013, 4, 991. [Google Scholar] [CrossRef] [Green Version]
- Bestgen, Y. Building Affective Lexicons from Specific Corpora for Automatic Sentiment Analysis. In Proceedings of the Sixth International Conference on Language Resources and Evaluation (LREC’08), Marrakech, Morocco, 28–30 May 2008. [Google Scholar]
- Feng, S.; Cai, Z.; Crossley, S.; McNamara, D.S. Simulating human ratings on word concreteness. In Proceedings of the Twenty-Fourth International FLAIRS Conference, Palm Beach, FL, USA, 18–20 May 2011. [Google Scholar]
- Turney, P.D.; Littman, M.L. Measuring Praise and Criticism: Inference of Semantic Orientation from Association. ACM Trans. Inf. Syst. 2003, 21, 315–346. [Google Scholar] [CrossRef] [Green Version]
- Shaoul, C.; Westbury, C. Exploring lexical co-occurrence space using HiDEx. Behav. Res. Methods 2010, 42, 393–413. [Google Scholar] [CrossRef]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient estimation of word representations in vector space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- Charbonnier, J.; Wartena, C. Predicting word concreteness and imagery. In Proceedings of the 13th International Conference on Computational Semantics-Long Papers, Gothenburg, Sweden, 23–27 May 2019; pp. 176–187. [Google Scholar]
- Smith, S.L.; Turban, D.H.; Hamblin, S.; Hammerla, N.Y. Offline bilingual word vectors, orthogonal transformations and the inverted softmax. arXiv 2017, arXiv:1702.03859. [Google Scholar]
- Ljubešić, N. Concreteness and imageability lexicon MEGA.HR-Crossling. In Slovenian Language Resource Repository CLARIN.SI.; Jožef Stefan Institute: Ljubljana, Slovenia, 2018. [Google Scholar]
- Cheng, Y.Y.; Chen, Y.M.; Yeh, W.C.; Chang, Y.C. Valence and Arousal-Infused Bi-Directional LSTM for Sentiment Analysis of Government Social Media Management. Appl. Sci. 2021, 11, 880. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Sanh, V.; Debut, L.; Chaumond, J.; Wolf, T. DistilBERT, a distilled version of BERT: Smaller, faster, cheaper and lighter. arXiv 2019, arXiv:1910.01108. [Google Scholar]
- Wang, W.; Wei, F.; Dong, L.; Bao, H.; Yang, N.; Zhou, M. MiniLM: Deep Self-Attention Distillation for Task-Agnostic Compression of Pre-Trained Transformers. arXiv 2020, arXiv:cs.CL/2002.10957. [Google Scholar]
- Buechel, S.; Hahn, U. Word emotion induction for multiple languages as a deep multi-task learning problem. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, New Orleans, LA, USA, 1–6 June 2018; Volume 1, pp. 1907–1918. [Google Scholar]
- Sedoc, J.; Preoţiuc-Pietro, D.; Ungar, L. Predicting emotional word ratings using distributional representations and signed clustering. In Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics, Valencia, Spain, 3–7 April 2017; Volume 2, pp. 564–571. [Google Scholar]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).