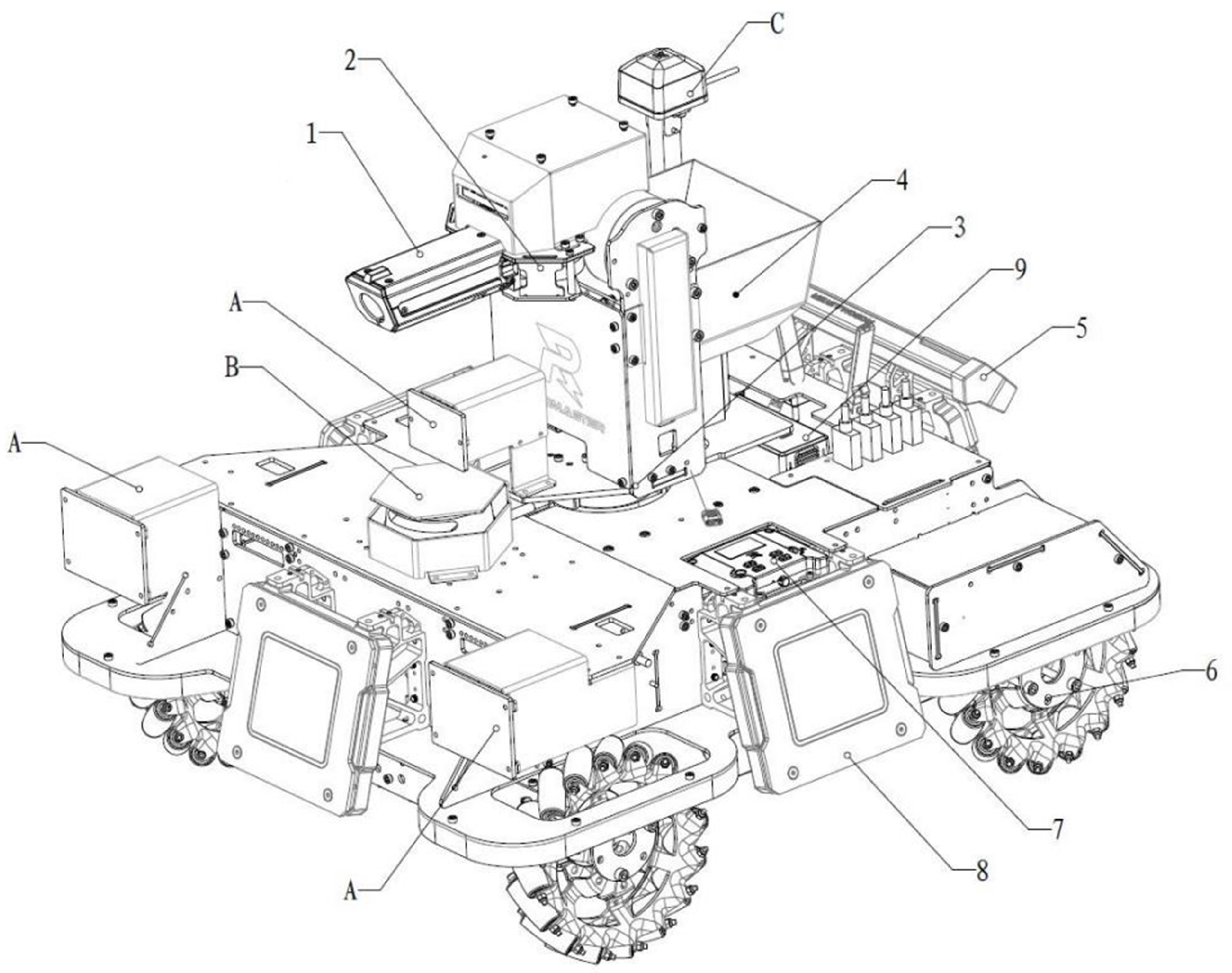
Figure 1.
Robot platform. The characters and numbers in the diagram represent equipment modules, the details of which are shown below: 1. Referee system speed measurement module SM01. 2. Launch mechanism module. 3. 2-axis gimbal module. 4. ammunition supply module. 5. Referee system light bar module LI01. 6. Power module. 7. Referee System Master Control Module MC02. 8. Referee System Armour Module AM02. 9. TB47S Battery. A. Camera. B. Li-DAR. C. Referee System Positioning Module UW01.
Figure 1.
Robot platform. The characters and numbers in the diagram represent equipment modules, the details of which are shown below: 1. Referee system speed measurement module SM01. 2. Launch mechanism module. 3. 2-axis gimbal module. 4. ammunition supply module. 5. Referee system light bar module LI01. 6. Power module. 7. Referee System Master Control Module MC02. 8. Referee System Armour Module AM02. 9. TB47S Battery. A. Camera. B. Li-DAR. C. Referee System Positioning Module UW01.
Figure 2.
CSPDarknet53 structure. The figure on the left shows the structure of Darknet53, while the figure on the right shows the CSPDarknet53 structure with improvements made to the Darknet53 structure.
Figure 2.
CSPDarknet53 structure. The figure on the left shows the structure of Darknet53, while the figure on the right shows the CSPDarknet53 structure with improvements made to the Darknet53 structure.
Figure 3.
YOLOv4 network structure. CSPDarknet53 is the backbone feature extraction network for YOLOv4. SPP and PANet are enhanced feature extraction networks for YOLOv4. Yolo Head is the detection head of the network. The left side of the figure shows the detailed structure of the backbone feature extraction network.
Figure 3.
YOLOv4 network structure. CSPDarknet53 is the backbone feature extraction network for YOLOv4. SPP and PANet are enhanced feature extraction networks for YOLOv4. Yolo Head is the detection head of the network. The left side of the figure shows the detailed structure of the backbone feature extraction network.
Figure 4.
Ghost module structure. The letter “a” in the figure represents the depth-separable convolution operation.
Figure 4.
Ghost module structure. The letter “a” in the figure represents the depth-separable convolution operation.
Figure 5.
Ghost bottleneck. (Left): Ghost bottleneck with stride = 1; (right): Ghost bottleneck with stride = 2.
Figure 5.
Ghost bottleneck. (Left): Ghost bottleneck with stride = 1; (right): Ghost bottleneck with stride = 2.
Figure 6.
GhostNet network structure. G-bneck represents the Ghost bottleneck.
Figure 6.
GhostNet network structure. G-bneck represents the Ghost bottleneck.
Figure 7.
Improved GhostNet network structure. The improved GhostNet trims the four G-bneck modules, the AvgPool layer, and the FC layer from the original GhostNet.
Figure 7.
Improved GhostNet network structure. The improved GhostNet trims the four G-bneck modules, the AvgPool layer, and the FC layer from the original GhostNet.
Figure 8.
Improved YOLOv4 network structure. The detailed parameters of the improved convolution module are as follows: conv_three_1: conv2d(160,512,1), conv_dw(512,1024), conv2d(1024,512,1); conv_three_2: conv2d(2048,512,1), conv_dw(512,1024), conv2d(1024,512,1); conv_five_1:conv2d (256,128,1), conv_dw(128,256), conv2d(256,128,1), conv_dw(128,256), conv2d(256,128,1); conv_five_2: conv2d(512,256,1), conv_dw(256,512), conv2d(512,256,1), conv_dw(256,512), conv2d(512,256,1); conv_five_3:conv2d(1024,512,1), conv_dw(512,1024), conv2d(1024,512,1), conv_dw(512,1024), conv2d (1024,512,1); conv_five_4:conv2d(512,256,1), conv_dw(256,512), conv2d(512,256,1), conv_dw(256,512), conv2d(512,256,1). The conv2d represents the ordinary convolution and the conv_dw represents the depth-separable convolution.
Figure 8.
Improved YOLOv4 network structure. The detailed parameters of the improved convolution module are as follows: conv_three_1: conv2d(160,512,1), conv_dw(512,1024), conv2d(1024,512,1); conv_three_2: conv2d(2048,512,1), conv_dw(512,1024), conv2d(1024,512,1); conv_five_1:conv2d (256,128,1), conv_dw(128,256), conv2d(256,128,1), conv_dw(128,256), conv2d(256,128,1); conv_five_2: conv2d(512,256,1), conv_dw(256,512), conv2d(512,256,1), conv_dw(256,512), conv2d(512,256,1); conv_five_3:conv2d(1024,512,1), conv_dw(512,1024), conv2d(1024,512,1), conv_dw(512,1024), conv2d (1024,512,1); conv_five_4:conv2d(512,256,1), conv_dw(256,512), conv2d(512,256,1), conv_dw(256,512), conv2d(512,256,1). The conv2d represents the ordinary convolution and the conv_dw represents the depth-separable convolution.
Figure 9.
Example figure of the dataset. There are four objects to be identified in the figure. They are car, base, and watcher, and armor is among the above objects.
Figure 9.
Example figure of the dataset. There are four objects to be identified in the figure. They are car, base, and watcher, and armor is among the above objects.
Figure 10.
Identification renderings. This figure shows the recognition effect of
Figure 9, with rectangular boxes and text indicating the objects to be recognized.
Figure 10.
Identification renderings. This figure shows the recognition effect of
Figure 9, with rectangular boxes and text indicating the objects to be recognized.
Figure 11.
Experimental flowchart. The experimental process is divided into a training process and a testing process. The training process mainly includes the manipulation of the dataset, the tuning of parameters, and the training of the model network. The testing process mainly consists of configuring the equipment and testing.
Figure 11.
Experimental flowchart. The experimental process is divided into a training process and a testing process. The training process mainly includes the manipulation of the dataset, the tuning of parameters, and the training of the model network. The testing process mainly consists of configuring the equipment and testing.
Figure 12.
The convergence curve of the loss function for different models. (a) Represents the loss function plot for the training of our proposed network model. (b) Represents the loss function plot for the training of the YOLOv4 network model. (c) Represents the loss function plot for the training of the YOLOv4_tiny network model. (d) Represents the loss function plot for the training of the yolov4_mobilenetv1 network model. The yolov4_mobilenetv1 means replacing YOLOv4’s backbone feature extraction network with MobileNetv1. (e) Represents the loss function plot for the training of the yolov4_mobilenetv2 network model. The yolov4_mobilenetv2 means replacing YOLOv4’s backbone feature extraction network with MobileNetv2. (f) Represents the loss function plot for the training of the yolov4_mobilenetv3 network model. The yolov4_mobilenetv3 means replacing YOLOv4’s backbone feature extraction network with MobileNetv3.
Figure 12.
The convergence curve of the loss function for different models. (a) Represents the loss function plot for the training of our proposed network model. (b) Represents the loss function plot for the training of the YOLOv4 network model. (c) Represents the loss function plot for the training of the YOLOv4_tiny network model. (d) Represents the loss function plot for the training of the yolov4_mobilenetv1 network model. The yolov4_mobilenetv1 means replacing YOLOv4’s backbone feature extraction network with MobileNetv1. (e) Represents the loss function plot for the training of the yolov4_mobilenetv2 network model. The yolov4_mobilenetv2 means replacing YOLOv4’s backbone feature extraction network with MobileNetv2. (f) Represents the loss function plot for the training of the yolov4_mobilenetv3 network model. The yolov4_mobilenetv3 means replacing YOLOv4’s backbone feature extraction network with MobileNetv3.
Figure 13.
Time performance comparison. The vertical axis indicates the time taken to calculate the mAP value in seconds. The horizontal axis indicates the different devices.
Figure 13.
Time performance comparison. The vertical axis indicates the time taken to calculate the mAP value in seconds. The horizontal axis indicates the different devices.
Figure 14.
FPS test results. The vertical axis indicates the FPS value of the model for real-time detection. The horizontal axis indicates the different devices.
Figure 14.
FPS test results. The vertical axis indicates the FPS value of the model for real-time detection. The horizontal axis indicates the different devices.
Table 1.
Configuration parameters for the robot controller. (The robot controller is the CPU of the robot and provides various interfaces to connect different external devices and handle the associated computing operations).
Table 1.
Configuration parameters for the robot controller. (The robot controller is the CPU of the robot and provides various interfaces to connect different external devices and handle the associated computing operations).
| Name | Processor | System | Memory | GFLOPS |
|---|
| Manifold 2-G | NVIDIA Jetson TX2 | Ubuntu 18.04 | 8 GB 128 bit | 1260 |
| Dell OptiPlex 3060 | Intel(R) Pentium(R) Gold G5400T CPU@ 3.10 GHz | Windows 10 | 16 GB 64 bit | 99.2 |
Table 2.
YOLOv4 validity experiment results.
Table 2.
YOLOv4 validity experiment results.
| Algorithms | mAP (0.5) | Model Size/MB | Flops |
|---|
| YOLOv4 | 88.63% | 244 | 30.17 GB |
| SSD | 57.36% | 92.6 | 31.35 GB |
| YOLOv5x | 68.52% | 333 | 109 GB |
Table 3.
Data augmentation experiment results.
Table 3.
Data augmentation experiment results.
| Algorithms | mAP ( 0.5) | mAP (0.75) |
|---|
| yolov4_RMLight_ADD | 86.84% | 50.91% |
| yolov4_RMLight | 81.35% | 44.80% |
Table 4.
The experimental results of improving the effectiveness of the enhanced feature extraction network.
Table 4.
The experimental results of improving the effectiveness of the enhanced feature extraction network.
| Algorithms | mAP (0.5) | Model Size/MB | Parameter Quantity/Million |
|---|
| yolov4_RMLight_ADD | 86.84% | 42.50 | 10.80 |
| yolov4_RMLight_ADD_0 | 70.31% | 145 | 38.38 |
Table 5.
The experimental results for improving the effectiveness of the backbone feature extraction network.
Table 5.
The experimental results for improving the effectiveness of the backbone feature extraction network.
| Algorithms | mAP (0.5) | Model Size/MB | Flops |
|---|
| yolov4_RMLight_ADD | 86.84% | 42.50 | 3.53 GB |
| yolov4_mobilenetv1 | 79.46% | 51.10 | 5.27 GB |
| yolov4_mobilenetv2 | 79.68% | 46.60 | 4.08 GB |
| yolov4_mobilenetv3 | 79.68% | 46.60 | 3.80 GB |
| yolov4_resnet50 | 65.36% | 127 | 33.68 GB |
| yolov4_vgg16 | 66.93% | 90 | 23.94 GB |
Table 6.
Accuracy results for different detection models.
Table 6.
Accuracy results for different detection models.
| Algorithms | Precision | Recall | mAP (0.5) | mAP (0.75) | F1 |
|---|
| yolov4_RMLight_ADD | 88.89% | 87.12% | 86.84% | 50.91% | 88.00% |
| YOLOv4 | 88.63% | 89.48% | 89.07% | 49.20% | 89.40% |
| YOLOv4_tiny | 57.92% | 56.28% | 57.50% | 44.92% | 57.00% |
| Eifficientdet-d0 | 78.83% | 53.27% | 57.85% | 51.99% | 56.20% |
| YOLOv5n | 75.72% | 63.37% | 66.48% | 52.07% | 67.20% |
| YOLOv5s | 75.88% | 65.47% | 68.20% | 52.35% | 69.00% |
Table 7.
Performance results for different detection models.
Table 7.
Performance results for different detection models.
| Algorithms | Model Size/MB | Parameter Quantity/Million | Flops |
|---|
| yolov4_RMLight_ADD | 42.50 | 10.80 | 3.53 G |
| YOLOv4 | 244 | 64.36 | 30.17 G |
| YOLOv4_tiny | 22.25 | 6.06 | 3.47 G |
| Eifficientdet-d0 | 15 | 3.87 | 2.55 G |
| YOLOv5n | 6.95 | 1.88 | 2.33 G |
| YOLOv5s | 27.1 | 7.28 | 8.53 G |
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}