1. Introduction
For many years, hydrogen has been considered an alternative to fossil fuels. Scientists have been aiming to develop an environmentally friendly method to produce hydrogen from biomass by optimizing Anaerobic Digestion (AD) systems [
1]. In the AD process, microorganisms decompose biomass in the absence of oxygen. Through AD, food and animal wastes are recycled to produce hydrogen gas which can be subsequently converted into biogas (methane) [
2,
3].
The utilization of wastewater for hydrogen production through AD is promising as it results in the generation of value-added products and reduces the organic load of the wastewater. For example, Ref.[
4] investigates the evaluation of hydrogen production with microbial consortia. The significant variables are optimized using a central composite design, resulting in two mathematical models. The resulting environmental benefits can be found in the removal of 50% of the COD, which could be further improved with the recovery of the other metabolites produced, mainly acetic and butyric acids.
The Two-Stage Anaerobic Digestion (TSAD), in which the hydrogen and methane production takes place in two separate bioreactors, has several advantages over the conventional single-stage process [
5,
6]. The TSAD permits the selection and the enrichment of different bacteria in each anaerobic digester and increases the stability of the whole process by controlling the acidification phase in the first digester and hence preventing the overloading and/or the inhibition of the methanogenic population in the second digester [
5,
6].
The production of corn starch and starch-derived products results in large amounts of aqueous by-products [
7,
8,
9]. Corn Steep Liquor (CSL) is a concentrated liquid by-product derived from water and used in the initial stage of the corn wet milling process. Globally, large amounts of CSL are produced daily and discharged into waterways. Despite its high nutritional value and relatively low cost, currently, CSL is not widely used internationally as a feedstock in the fermentation industry. This is primarily because most corn producers sell off their products to dry milling operations, where the corn is processed for various corn-derived products such as corn flour.
CSL has been used recently as a substrate for AD [
2]. An experimental study of two-stage anaerobic biodegradation of corn extract has been performed with mesophilic temperatures in both bioreactors. An automatic mode has been implemented using the developed computer system for monitoring and control. The so obtained experimental data are used here to develop a mathematical model.
For many industrially relevant processes, detailed models are not available due to an insufficient understanding of the underlying phenomena. Mathematical models, which naturally could be incomplete and inaccurate to a certain degree, can still be very useful and effective in describing the effects essential for control, optimization, or understanding of the process.
To the best of our knowledge, no mathematical models of TSAD of corn steep liquor have been published in the literature yet.
In this work, a mathematical model of TSAD of corn steep liquor is proposed. Metaheuristic algorithms are considered for model parameter estimation. The main advantage of metaheuristic techniques, which have been proven to be a good alternative to conventional optimization methods, is that they provide a satisfactory solution for a reasonable computational time [
10]. Metaheuristics do not depend on the initial conditions of the model. This advantage allows efficient scanning of a large search space to reach a global extremum.
Two categories of metaheuristics are known: single-based and population-based solution methods [
11]. In addition, some authors [
12,
13] proposed eight different groups—biology-based, physic-based, swarm-based, social-based, music-based, chemistry-based, sport-based, and math-based metaheuristic methods.
Evolutionary algorithms such as Genetic Algorithms (GA) [
14,
15] and Evolution Strategies [
16]; Ant Colony Optimization (ACO) [
17], Simulated Annealing (SA) [
18], Firefly Algorithm (FA) [
19], Artificial Bee Colony (ABC) optimization [
20], Cuckoo Search Algorithm (CS) [
21], etc., are, among many others, some of the examples of classical metaheuristics. Some of the population-based algorithms such as GA, FA and CS could be considered both as biology-based and swarm-based.
Some of the most powerful nature-inspired metaheuristics have been developed and tested for solving different optimization problems. A comprehensive review of metaheuristic algorithms is presented in [
22]. Since optimization is a process of making things as efficient as possible, researchers continuously seek new and modified metaheuristic methods that outperform the existing ones. The application of metaheuristic techniques for solving numerical optimization problems is receiving increasing attention.
A new performance assessment method is discussed in [
23]. It considers the influence of the control parameters on the metaheuristic algorithms. The method is demonstrated for GA. As a result, a better solution than the best reported so far in the literature is detected. Recently, new performance metrics of metaheuristic optimization methods have been proposed in [
24]. The presented results show that the discussed metrics have a good distinctive performance for different algorithms. The best-found algorithm is Differential Evolution (DE). In [
25], an NP-hard problem is solved based on multi-objective Tabu Search (TS), multi-objective variable neighborhood search, and multi-objective particle mass optimization. The presented results show that the performance of multi-objective TS is better than that of other proposed metaheuristic algorithms.
Real-life problems generally exhibit nonlinear constraints and dynamic components. GAs are well-known metaheuristics extremely applicable to problems with such characteristics. They have been well employed in many fields with still growing recognition [
26]. GAs are often used instead of traditional optimization methods. Authors of [
27] proposed a hybrid where the crossover and mutation operators of GA are integrated with the Teaching–Learning-Based Optimization and Particle Swarm Optimization (PSO) algorithms. The elitist strategy is utilized to boost evolutionary efficiency. A hybrid GA-PSO is proposed in [
28] and compared with CS, PSO, GA, and Simulated Annealing. The results of this research indicate that PSO and GA-PSO produce optimal values for all considered objective functions.
So far, their effectiveness and robustness have been demonstrated in the mathematical modelling of fermentation processes. In [
29], GA and the Artificial Bee Colony algorithm are applied to cultivation process modelling. A new approach for simultaneous parameter tuning of the metaheuristics is proposed. An optimization of wheat germ fermentation conditions using an artificial neural network combined with GA is discussed in [
30]. Based on the optimized scheme, a 117% improvement is achieved compared to that of the control group. Authors in [
31] propose GA for optimizing the productivity of the yeast fermentation process. The proposed GA obtains a higher yield production than the conventional open-loop system. A comparison of 8 modifications of GA (simple genetic algorithms and multi-population ones) is presented in [
32] for parameter identification of fed-batch cultivation of
S. cerevisiae. GA with the sequence of mutation, crossover, and selection operators is significantly faster than the other modifications.
Algorithms such as GA can be very useful, but they still have some drawbacks when dealing with multimodal optimization problems [
33]. Some results show that FA outperforms GA and is a powerful algorithm to solve even NP-hard problems [
19,
34,
35]. In [
36], an improved FA is utilized to solve the multi-depot vehicle routing problem with time windows. The work proves FA feasibility and shows that modified FA outperforms other competing algorithms (GA, ACO, TS, etc.) in terms of results and competence. Parameter estimation of a proposed hyperbolastic type-I diffusion process applying FA is presented in [
37]. The low computational cost of FA makes it especially useful for addressing maximum likelihood estimation in diffusion processes. An interesting performance analysis of distance metrics on the exploitation properties and convergence behaviour of FA is presented in [
38]. The optimal algorithm tuning based on unique distance metrics shows a new research area for solving large-scale optimization problems. In [
39], the enhanced FA is hybridized with the CLT-based K-means algorithm to achieve optimal global convergence. The results show that the hybrid FA-K-means clustering method demonstrates statistically significant superiority compared to other advanced hybrid search variants—GA, DE, PSO, and Invasive Weed Optimization.
The CS algorithm attracts attention due to its simplicity and efficiency over GA because of using the Lévy flights instead of isotropic random walks [
40]. Recently proposed CS algorithm [
41] for an energy-efficient robotic mixed-model assembly line balancing problem outperforms GA in terms of obtained objective values. In [
42], the CS algorithm employs theoretical anomaly generated by a single structure and different field data sets to estimate the model parameters. As a result, a rapid convergence of the objective function and the model parameters is observed. In [
43], a technique combining a CS algorithm and a support vector machine is applied in the prognostic staging of oesophageal cancer based on the prognosis index. The proposed algorithm has the highest prediction accuracy compared to six swarm intelligence algorithms, including the ABC algorithm, FA, Gravitational search algorithm, etc., combined with support vector machine learning techniques.
A newly introduced metaheuristic algorithm, Coyote Optimization Algorithm (COA) [
44], adopts an interesting technique to achieve a balance between exploration and exploitation [
45], as well as the robustness and stability of the algorithm [
46]. Binary COA with a hyperbolic transfer function in a wrapper model is applied to a feature selection problem [
47]. The algorithm presents low standard deviations when compared to other metaheuristic algorithms and a great convergence curve. An accurate and stable ultrashort-term wind speed prediction method is achieved using chaotic COA [
48]. The authors of [
49] propose a novel fault diagnosis method in chemical processes based on the Bernoulli shift coyote optimization algorithm. The results demonstrate that the proposed method outperforms other methods in terms of classification accuracy. In [
45], COA is proposed for optimal parameter estimation of a proton exchange membrane fuel cell model. The presented results show the superiority of COA over the other compared methods.
The known results indicate that metaheuristic techniques, such as GA, FA, CS, and COA, are particularly relevant nowadays, frequently preferred and efficiently used for many optimization problems, especially for model parameters optimization [
29,
31,
37,
42,
45,
50]. Moreover, they have not been employed in parameter estimation of TSAD of corn steep liquor model until now which is the motivation to adapt and apply them to the considered optimization problem.
The presented study focuses on the mathematical modelling of anaerobic biohydrogen production from corn steep liquor and the following anaerobic processing of the methane production under mesophilic conditions in a two-stage process. Model parameters identification is performed based on GA, FA, CS, and COA metaheuristic algorithms.
The specific contributions and innovations of this study are as follows:
For the first time, a structure of nonlinear differential equations of two-stage anaerobic digestion of corn steep liquor is evaluated based on real experimental data.
A new mathematical model of two-stage anaerobic digestion is developed. To our knowledge, no such models have been published so far.
Four metaheuristic algorithms (GA, FA, CS, and COA) are adopted and successfully applied to identify the parameters of the model proposed here.
The developed mathematical model could be used further for process investigation and optimization based on process monitoring and control.
The rest of the paper is organized in the following order.
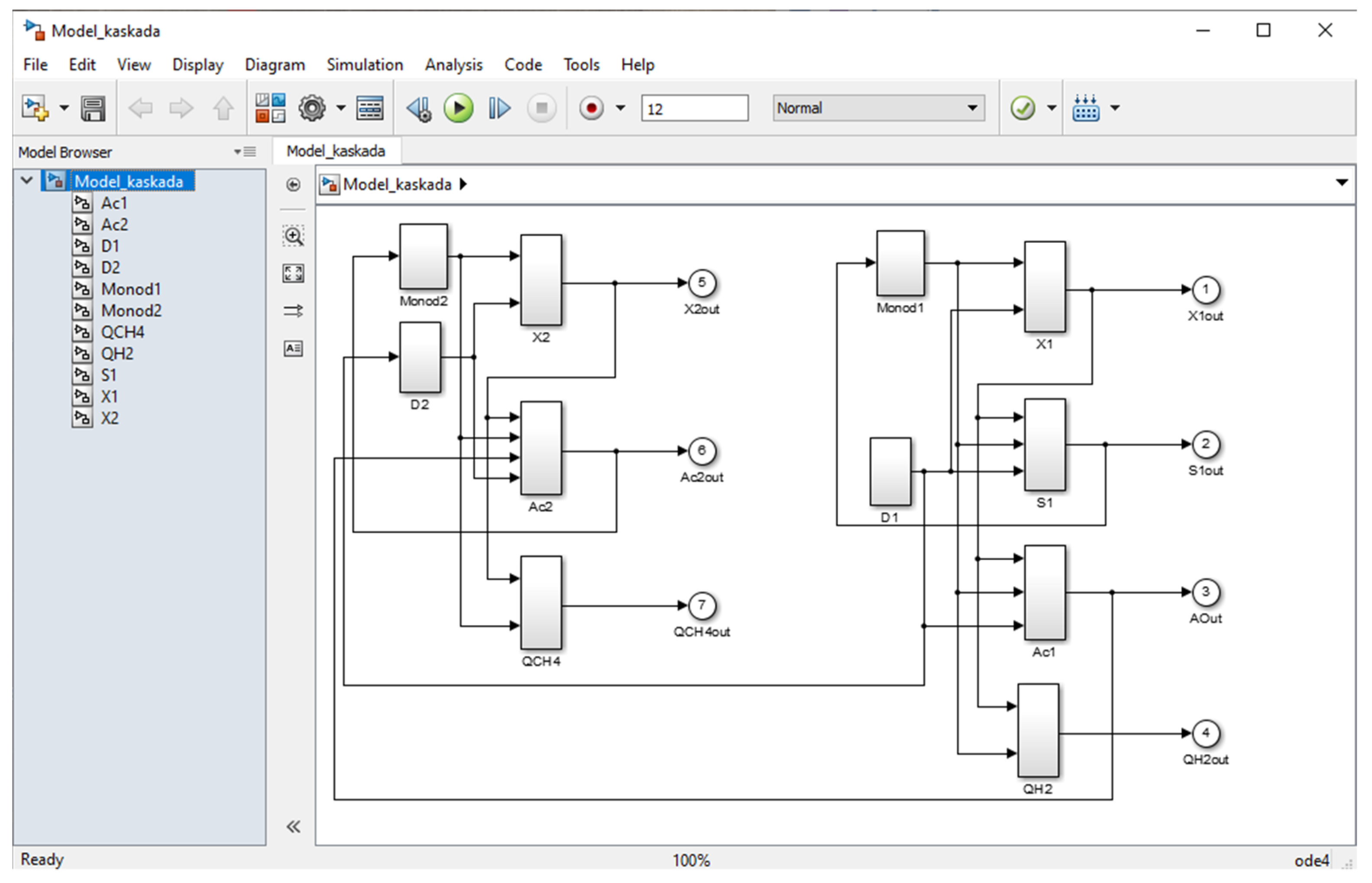
Section 2 presents the proposed mathematical model of a TSAD process and short descriptions of the applied metaheuristic algorithms, namely GA, FA, CS, and COA.
Section 3 presents the numerical results obtained by the model parameters identification. The results of the comparison of the considered metaheuristics are discussed. Conclusions and further investigations are provided in
Section 4.
4. Conclusions and Future Works
In this paper, a new mathematical model of two-stage anaerobic digestion of corn steep liquor has been proposed. The model has been presented as a set of five ordinary differential equations and two algebraic equations, representing seven dependent state variables (substrate concentration () in BR1; microbial biomass concentration in BR1 () and BR2 (); acetate formation in BR1 () and BR2 (); flow rate of the hydrogen () in the gas phase of BR1 and methane flow rate in BR2). The mathematical model consists of nine unknown model parameters divided into two groups, p1 = [ ] and p2 = [ ]. Different metaheuristic algorithms, some of the popular algorithms of the swarm intelligence domain, have been applied to estimate the unknown parameters based on experimental data.
The feasibility of the Genetic algorithm, Firefly algorithm, Cuckoo search algorithm, and Coyote Optimization Algorithm applied to a parameter identification problem has been highlighted. The chosen metaheuristic algorithms have been adapted and implemented here for the first time for parameter estimation of a newly proposed nonlinear mathematical model of TSAD of corn steep liquor. To confirm the superiority of some of the algorithms, a comparison between the techniques has been made—using the observed numerical results, graphical results, and statistical analysis.
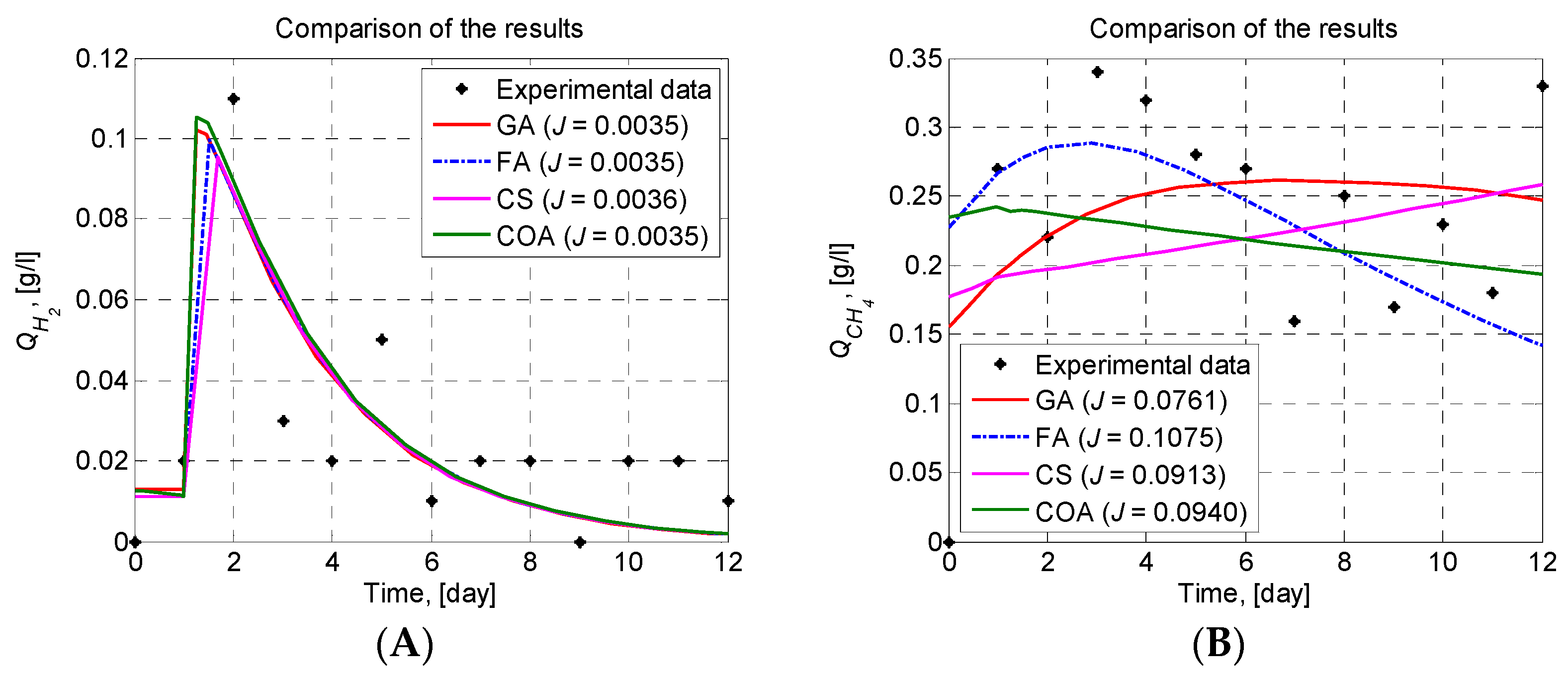
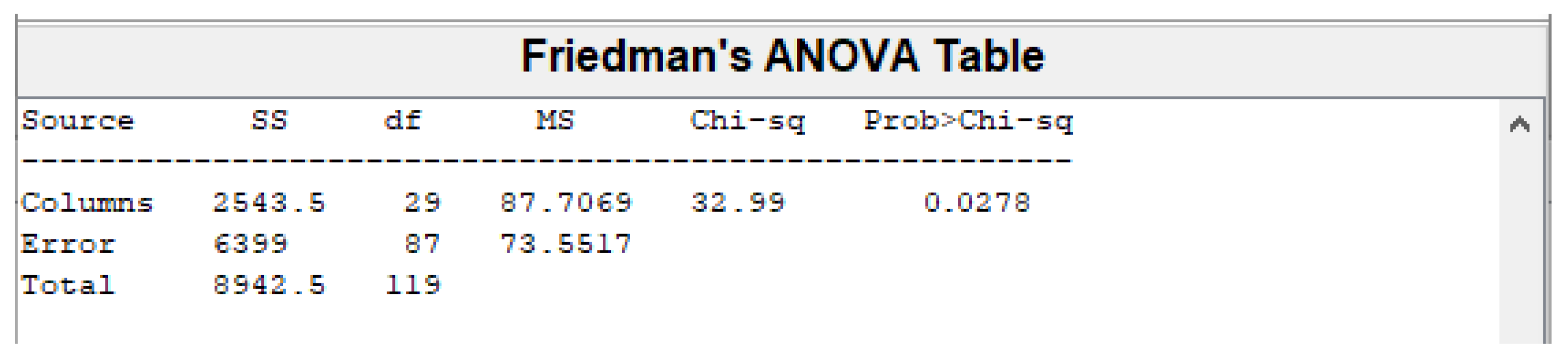
The simulation results of the parameters’ identification of the proposed mathematical models show that GA, FA, CS, and COA techniques can predict the experimental results. The four metaheuristics have achieved similar results in modelling the process dynamics in BR1. In the case of modelling the process dynamics in BR2, the lowest value of the objective function has been achieved by GA (J = 0.0761). A better description of the process dynamics trend, however, has been obtained by FA (J = 0.1075). The observed objective function values of CS and COA are J = 0.0913 and J = 0.0940, respectively. It has been demonstrated that the considered metaheuristics are efficient and are also powerful algorithms for parameter identification of complex nonlinear models. As a result, a mathematical model of TSAD of corn steep liquor with a high degree of accuracy is proposed. The model can be used for a simulation of the process behaviour to gather enough information for planning subsequent laboratory experiments. The mathematical model can also be used to optimize the process based on a designed control system. A good model in control loop synthesis is required to obtain optimal control.
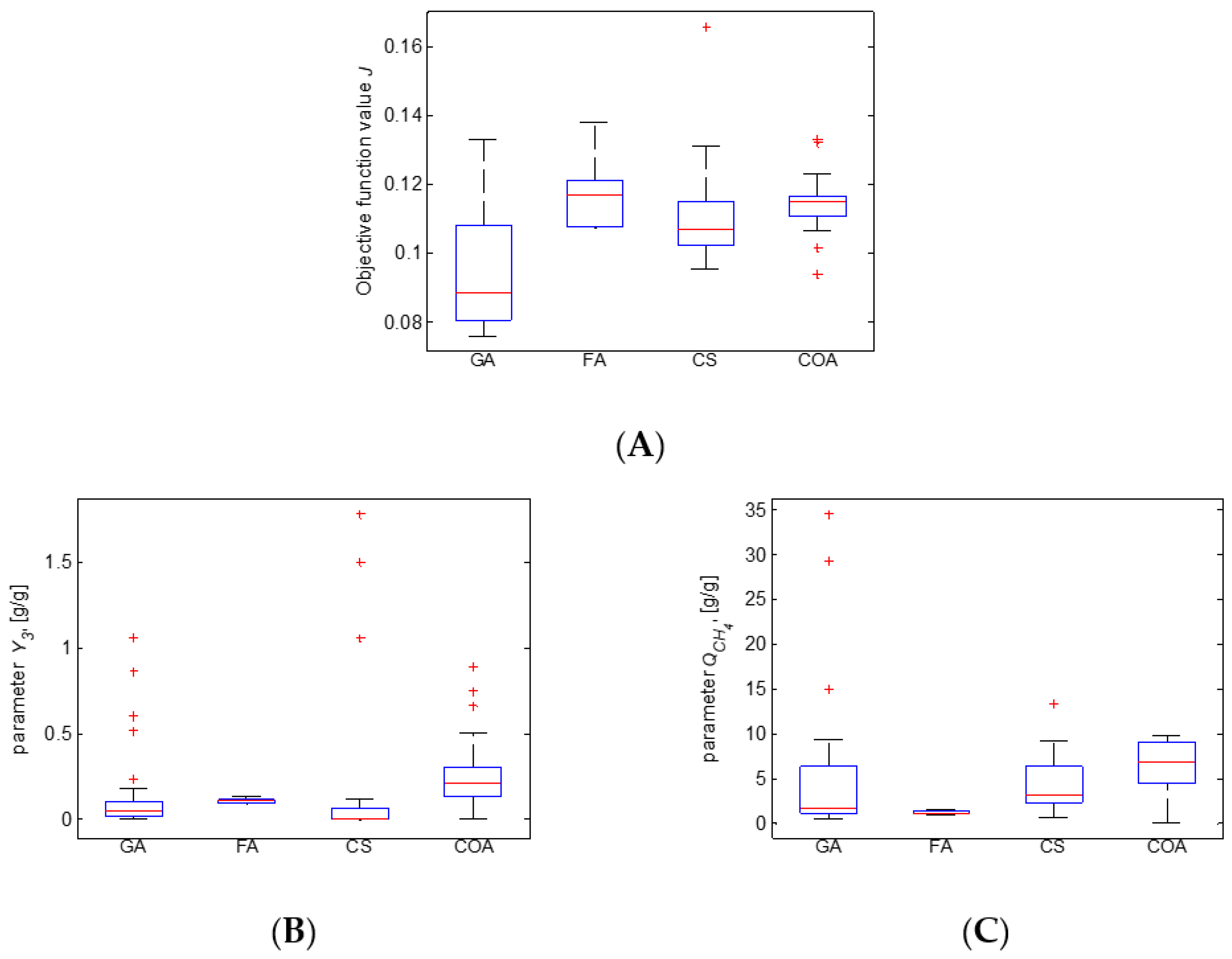
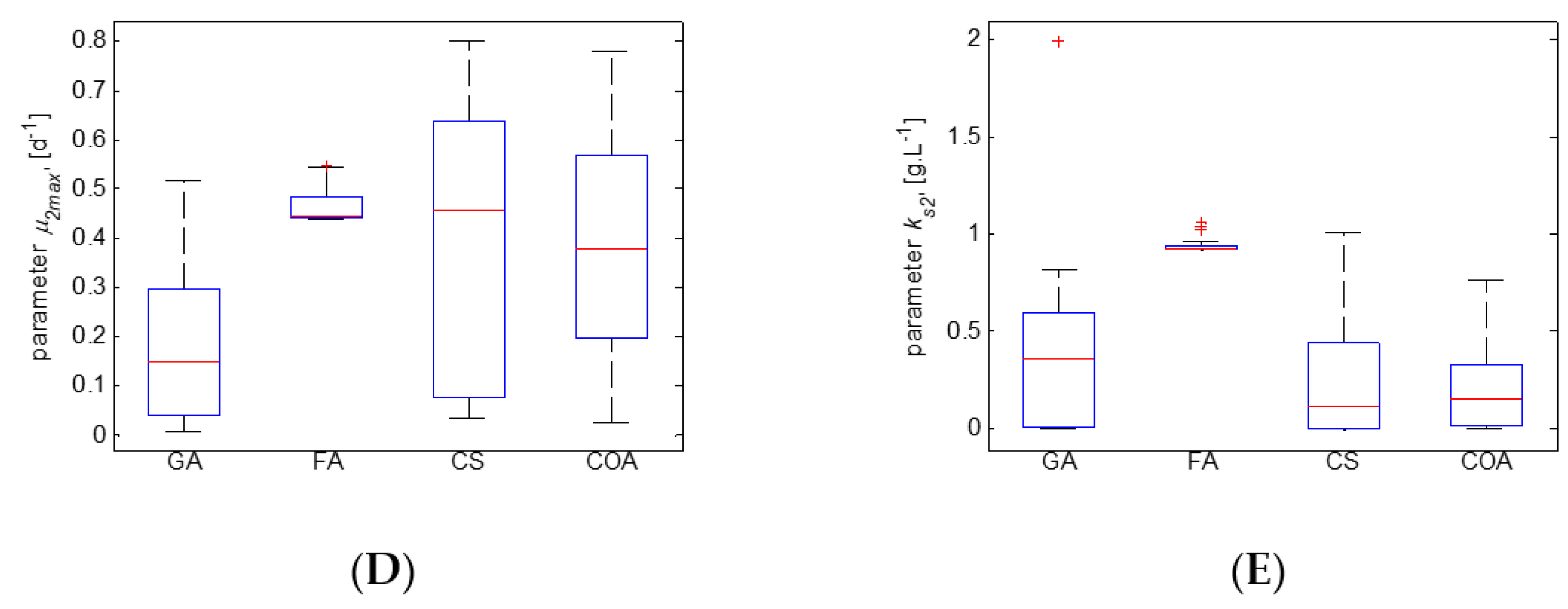
In addition, the numerical results have been compared based on box plots—a standard technique for analysis of the distribution of the obtained model estimates. The statistical results show that the parameter estimates are more easily obtained compared to the parameter estimates and . Such results are interesting, and it is worth conducting further research on the sensitivity of the model parameters to optimize the identification process.
Although some good results have been achieved with the application of the considered metaheuristics, there are still some limitations that need to be improved in future. First, the presence of several sets of raw experimental data is important for model validation. This is crucial, especially in the case of modelling non-linear, time-varying processes with interdependent variables, such as the one considered in this paper. Additional laboratory experiments are planned to be carried out. Second, it is well known that to achieve better performance, the input parameters of metaheuristic algorithms should be adjusted according to the problem domain. A joint set-up procedure [
29] will be applied to the algorithms’ parameters to significantly improve their performance. Finally, the results of the statistical analysis will be used for improving the efficiency of the algorithms. More numerical experiments will be conducted to identify the strengths and weaknesses of the studied metaheuristic algorithms. More powerful hybrid algorithms will be developed with a rapid convergence speed and robustness, as presented in [
63,
64].










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}