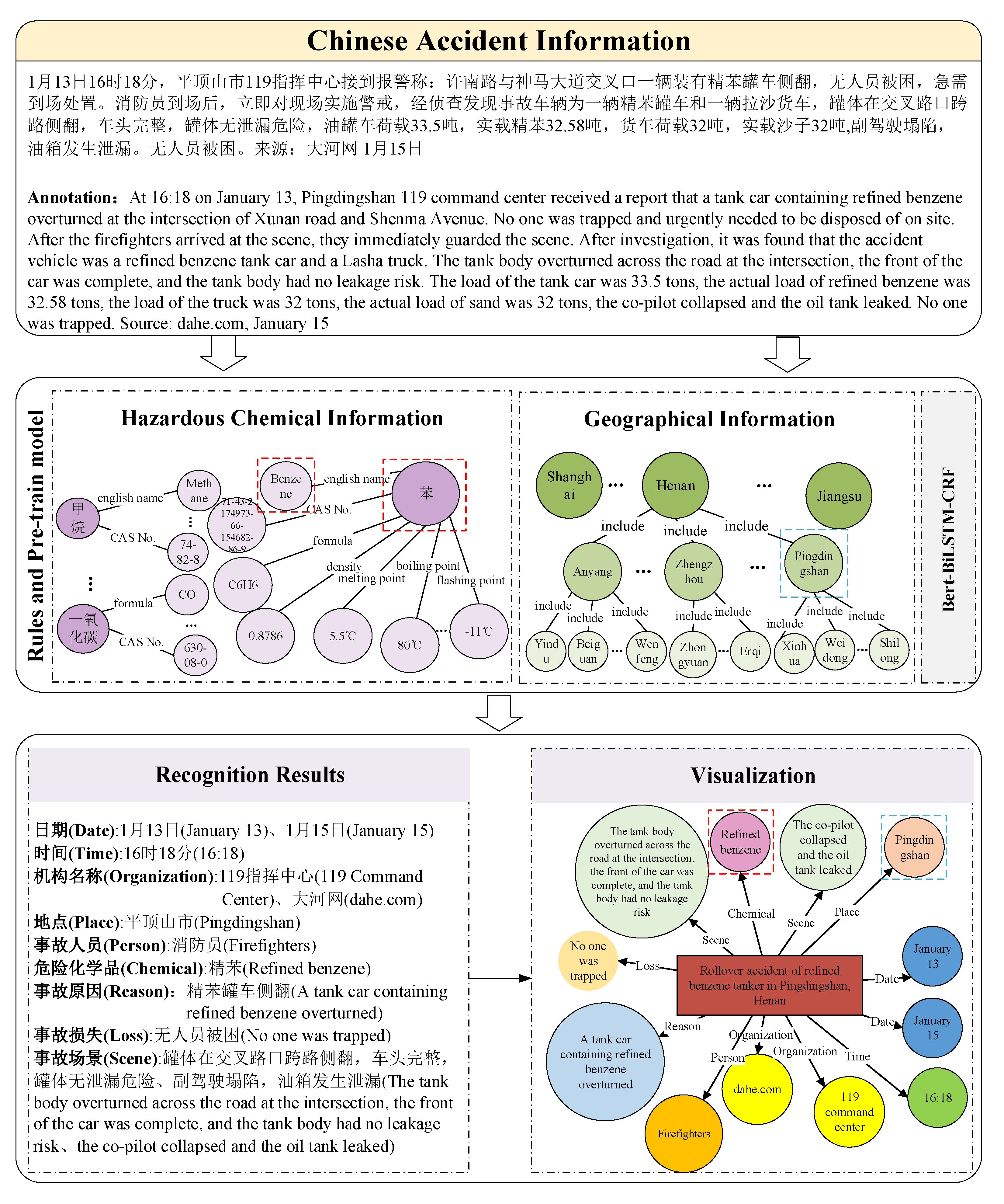
This section introduces a named hazardous-chemical-accident entity recognition approach based on rules and a pre-trained model. Meanwhile, there is a full illustration of the data preprocessing, rule template creation, and Bert-Bi-LSTM-CRF model. The overall hazardous chemical accident entity recognition framework is shown in
Figure 2.
3.1. Rule Templates for the First-Class Entities
The entity recognition based on rule templates mainly includes the following parts: (1) data preprocessing and (2) rule templates design.
In order to analyze hazardous chemical accidents in detail, we collected and integrated accident reports from the open network platform. These reports often have problems such as lack of information, redundancy, and disordered structure. Therefore, raw report texts should be preprocessed using word segmentation, stop word removal, and parts-of-speech tagging in order to match rule templates.
3.1.1. Data Preprocessing
Word segmentation is the process of splitting a continuous sentence into a number of independent word segments. Word segmentation in Chinese differs from word segmentation in English. While there are distinct word segmentation signals between English words, there are none between Chinese words, making it difficult to separate Chinese words. Several effective word segmentation approaches are currently available, including Jieba, LTP, HanLP, THULAC, and NLPIR. Choosing the right word segmentation tool can considerably increase the accuracy of experimental results. When evaluating the word segmentation performance of various test corpora using the aforementioned approaches, Jieba and HanLP can be seen to perform the best, whereas HanLP requires more training data. As a result, the experimental data corpus uses the Jieba word segmentation tool for word segmentation.
Stop words are commonly used to describe punctuation, conjunctions, and quantifiers that lack any meaningful semantic content. In this experiment, we used a list of common stop words from the stop words list of the Harbin Institute of Technology.
The goal of parts-of-speech tagging is to recognize various types of words. Nouns, in general, contain the most different types of entities. Natural language processing technologies such as Jieba, LTP, and HanLP have parts-of-speech tagging components. However, Jieba’s segmentation of parts-of-speech tagging is more complete than the other two natural language systems. As a result, the parts-of-speech tagging stage, like the word segmentation step, employed Jieba, the natural language processing tool.
3.1.2. Design of Rule Templates
After word segmentation, stop word removal, and parts-of-speech tagging, the relationships between words and parts of speech may be identified. Entities with specific characteristics can be identified based on word construction, context, and part-of-speech information.
Figure 3 depicts the overall process of rule templates identifying entities.
The experiment included nine different types of entity categories. Date and time in a chemical accident report are often noted as a specific day, month, year, or day of a certain month. The most frequent units of time expression are hours, minutes, and precise times. Date and time may generally be recognized by establishing rule templates because they all adhere to a set of preset building criteria.
Part rules satisfied by date and time are shown in
Table 1.
The other two first-class entities can be identified by matching geographic information database and hazardous chemicals database. To date, all the entities of the first-class have been recognized.
3.2. Pre-Trained Model for the Second-Class Entities
For the second-class entities, if the rule template method is still used, the result must be disappointing, as each report on a hazardous chemical accident includes a separate account of the scene and the losses that does not adhere to any established guidelines. This makes it difficult to create rules or causes an incomplete list of rules, which has a negative impact on entity recognition. Based on this, other methods are needed to recognize the second class of entities. The statistical methods not only lead researchers to carry a massive burden, text annotation, but also cause extracted features to lose emotional information from the text itself, resulting in poor entity recognition performance. As a result, we use a deep learning method. Deep neural networks are more suited to dealing with the issue of sparse text features when employed with unstructured and dynamic data, since they can automatically extract meaningful qualities from data. On this foundation, we recognized second-class entities using the Bi-LSTM-CRF model. Instead of manually extracting features, the original data can be analyzed directly utilizing pre-trained word vector technology. The word2vec tool is used to train word vectors in the majority of the neural network models mentioned previously. The two most common training methods are skip–gram and continuous bag of words (CBOW). Skip–gram predicts context words from present words, whereas CBOW predicts context words from current words.
Despite having good text-sequence context-characteristics capturing, Word2Vec still has a large mining space. Word2Vec, GloVe, and other models are constrained by the model’s capacity for representation. The word vectors obtained have high degrees of context co-occurrence, and the impact of word order on meaning has not been fully taken into account. As a result, Google’s Jacob et al. introduced the bidirectional encoder representation BERT model based on the transformer. It employs a deep bidirectional representation pre-trained model, which has a positive effect on the field of natural language processing and can extract semantic information from text at a deeper level. We therefore suggest in this study using the Bert-Bi-LSTM-CRF model to recognize the second-class named entities.
A bidirectional encoder representation from transformers (BERT) layer, bi-directional long short term memory (Bi-LSTM) layer, and conditional random field (CRF) layer are the three layers that make up the entire model, as can be seen in
Figure 4. The BERT layer contains embedded input characters. The Bi-LSTM layer extracts the overall vector features of the text using the word vector features from the BERT layer. The CRF layer is used for output control to make sure that the tag sequence gives the best results possible.
3.2.1. BERT Pre-Trained Language Model
Pre-trained language models have advanced quickly in recent years. Pre-trained models, which primarily have the following two qualities, are crucial for many natural language processing (NLP) tasks: (1) It can be trained using a huge unlabeled text corpus. (2) No particular network structure needs to be created in order to use it for a variety of downstream NLP jobs that are not specific. Selecting one of several predetermined network architectures for fine adjustment can yield good results. According to
Figure 5, the unit sum of three embedded features makes up the coding vector input by the BERT layer (length 512). Token embedding is used to represent words as vectors. The CLS flag, which can be used for later downstream NLP operations, is the first word. Segment embedding is a sentence vector that is used in classification tasks to distinguish between two sentences. Position embeddings serve to represent the position vectors that the Bert model has learned.
Bidirectional encoder representation from transformers’ (Bert) network architecture adopts a multi-layer transformer structure. It uses an attention mechanism instead of conventional recurrent neural networks (RNNs) and convolutional neural networks (CNNs) to convert the distance between two words at any position into one. This effectively handles the challenge of long-term dependence in the process of feature extraction. The BERT network structure is shown in
Figure 6, where
,
, …,
are the input vectors of the model;
,
, …,
are output vectors of the model; and
is the transformer module.
Bert is a multi-task model including two self-supervised tasks: masked language model (MLM) and next sentence prediction (NSP).
A masked language model (MLM) describes the process of masking some words from the input corpus during the training stage, for example, “refined benzene tanker side [mask]”, and then predicting the masked words based on context. In the experiment of BERT, 15% of the words in training samples were randomly masked. Sentences will be fed into the model repeatedly in order to learn model parameters. However, these words will not always be hidden. Specifically, 80% of the words will be replaced with masked characters, 10% will retain the original characters, and the rest 10% will be replaced with any other words. It is because that if a character in a sentence is 100% masked, some unregistered words will appear when tuning the model. The reason for adding random characters is that the transformer structure maintains a distributed representation of each input character.
The purpose of the next sentence prediction (NSP) is to determine whether sentence B is the following of sentence A. If sentence B is the following of sentence A, it outputs “is next”, otherwise it outputs “not next”. Taking “[CLS] refined benzene tank car rollover [SEP] no one is trapped” for example, the output result of NSP is “is next”. While “[CLS] refined benzene tank car rollover [SEP] actual load of sand is 32 tons”, the output result is “not next”. Two consecutive sentences chosen at random from the parallel corpus serve as the training data. The two sentences that were extracted from them have a 50% chance of remaining, proving that they are related contextually. Another 50% chance suggests that sentence B was chosen at random from the corpus and does not relate to sentence A contextually.
3.2.2. Bi-LSTM Model
Recurrent Neural Network (RNN) is frequently utilized in the named entity recognition (NER) task to solve such sequence annotation issues. It is challenging for the model to acquire the properties of medium long-term dependence when the sequence length is too long, as the gradient would vanish. The Long Short Term Memory (LSTM) is a significant advance over the conventional RNN. It introduces a gating mechanism to regulate information input and output and a memory unit to learn which data should be remembered and lost during training.Therefore, LSTM can better capture long-distance dependencies and further learn the semantic feature information in the text.
At time t, the long short term memory (LSTM) model is made up of the following components: the input word
, the cell state
, the temporary cell state
, the hidden layer state
, the forget gate
, the input gate
, and the output gate
. Equations (
1)–(
7) show the calculation formulas for each of them.
Figure 7 depicts the LSTM model’s frame diagram.
Output Gate:
where sigmoid, tanh and Softmax are activation functions of nonlinear neural network,
represents input characteristics of current network,
U represents weight matrix of three gates, and
b represents bias term of three gates.
Forget gate determines how much the unit state of the last moment is retained to the current moment . Input gate determines how much of the current network input is saved to the unit state . Output gate controls how much the unit state outputs to the current output value of the long short term memory (LSTM). The final output consists of the current cell state , the current output value , and the current prediction obtained by the softmax function.
A one-way long short term memory (LSTM) model, however, is unable to process context data concurrently. The bidirectional long short term memory (Bi-LSTM) proposed by Graves et al. [
26] takes forward and backward LSTM for each word sequence, combining the output simultaneously. As a result, it contains both forward and backward information for each moment.
Figure 8 depicts its model structure.
3.2.3. CRF Model
The bidirectional long short term memory (Bi-LSTM) is effective at handling long-distance text information in the named entity recognition task, but it struggles with the dependency between adjacent tags. Bi-LSTM’s drawbacks can be remedied by conditional random field (CRF), which can obtain an ideal prediction sequence through the relationship between adjacent labels. CRF reasoning layer is thus added following the Bi-LSTM network layer.
Conditional random field is a distribution model of conditional probability , which is used to predict another set of output sequence Z given a set of input sequence Y.
In a given training set Y and the corresponding marking sequence Z, K characteristic functions
needs to learn the model parameter
of linear CRF and conditional probability
.
is the generalization factor. The conditional probability
and model parameter
satisfies the relationship shown in Equation (
8):
According to Equation (
8), given the conditional probability
of the conditional random field and an observation sequence
, the sequence y satisfying the maximum of
can be found. Sentence level sequence features can be fully utilized by conditional random field (CRF) models to combine contextual information. Some limitations are applied to the label prediction of the sequence label results in order to ensure the reliability of the output label. This means that the label result cannot contain the beginning of a person entity (B-Person) followed by the inside of a chemical entity (I-Chemical). The output results may be in the wrong sequence if we simply use the bidirectional long short term memory (Bi-LSTM) layer since the Bi-LSTM model can only learn character-level features and lacks feature analysis at the complete sentence level. In other words, B-person may be followed by I-chemical. Similar issues can be avoided by adding a CRF reasoning layer after the Bi-LSTM network layer. Additionally, during data training, the CRF layer can automatically learn these constraints.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}