

Multiple Pedestrian Tracking in Dense Crowds Combined with Head Tracking


Abstract
:1. Introduction
- Inheriting the work of [7], which only tracks the pedestrians’ heads, we extended the tracked objects to the whole bodies of pedestrians, which are more common in the field of multiobject tracking.
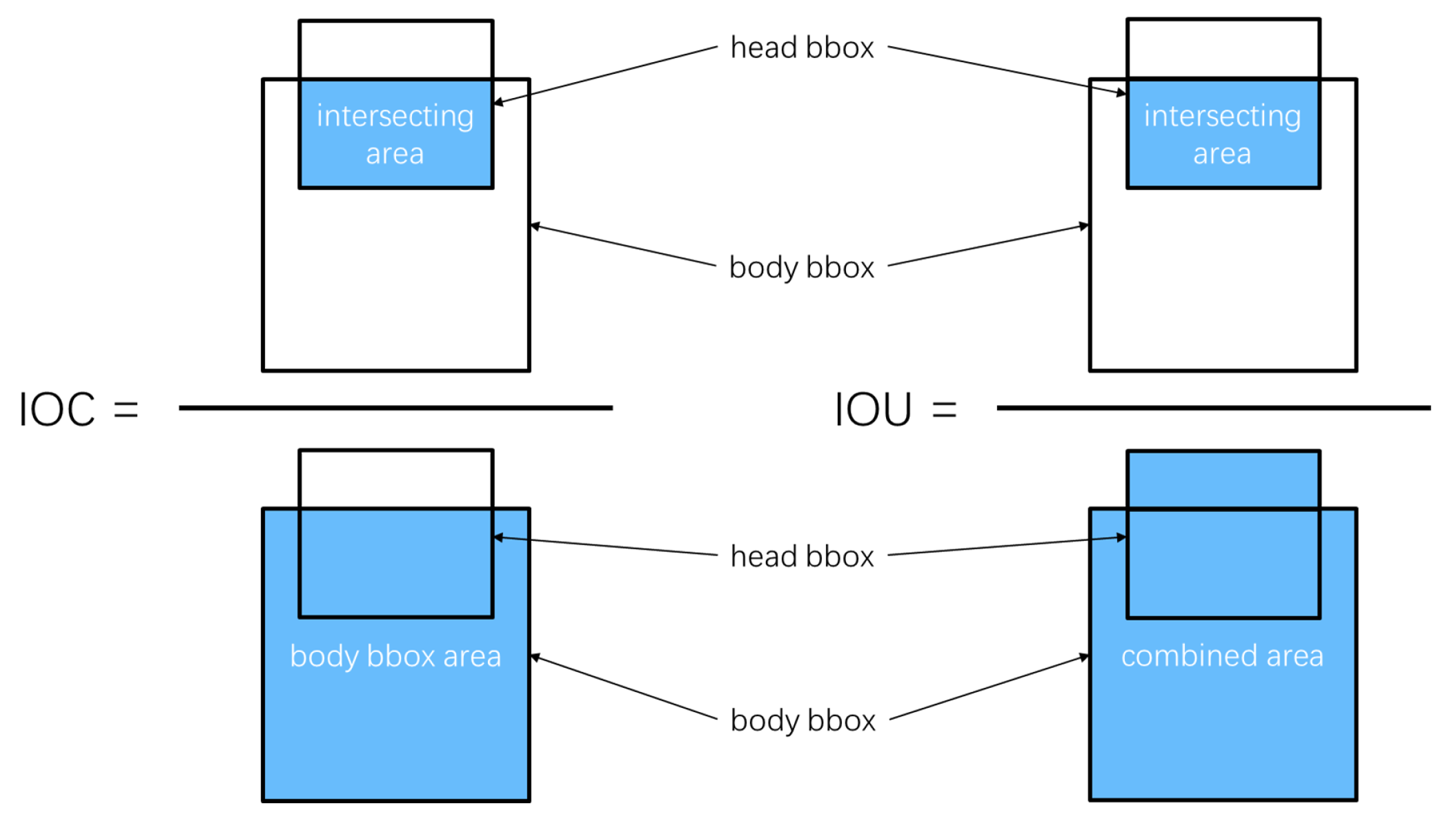
- To accomplish the task of matching pedestrians’ head and body bounding boxes, we proposed a novel bounding box similarity calculation method, Intersection over Containment (IoC), by which, with the help of the Hungarian algorithm, we can efficiently complete the matching work of the head bounding box and the whole-body bounding box belonging to the same pedestrian.
2. Related Work
2.1. Tracking by Detection
2.2. Jointly Learns the Detector and Embedding
2.3. Tracking Method Based on Transformer
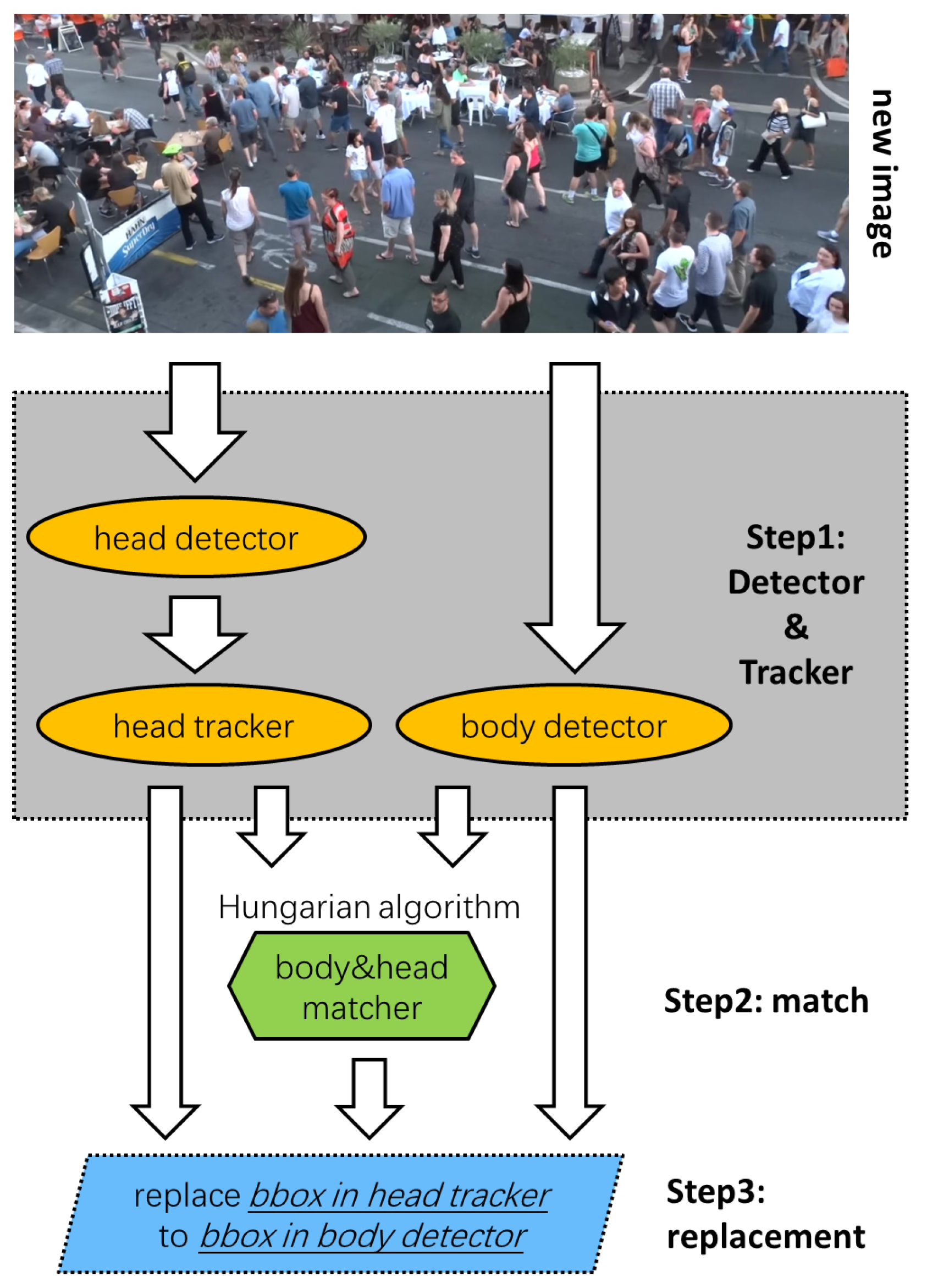
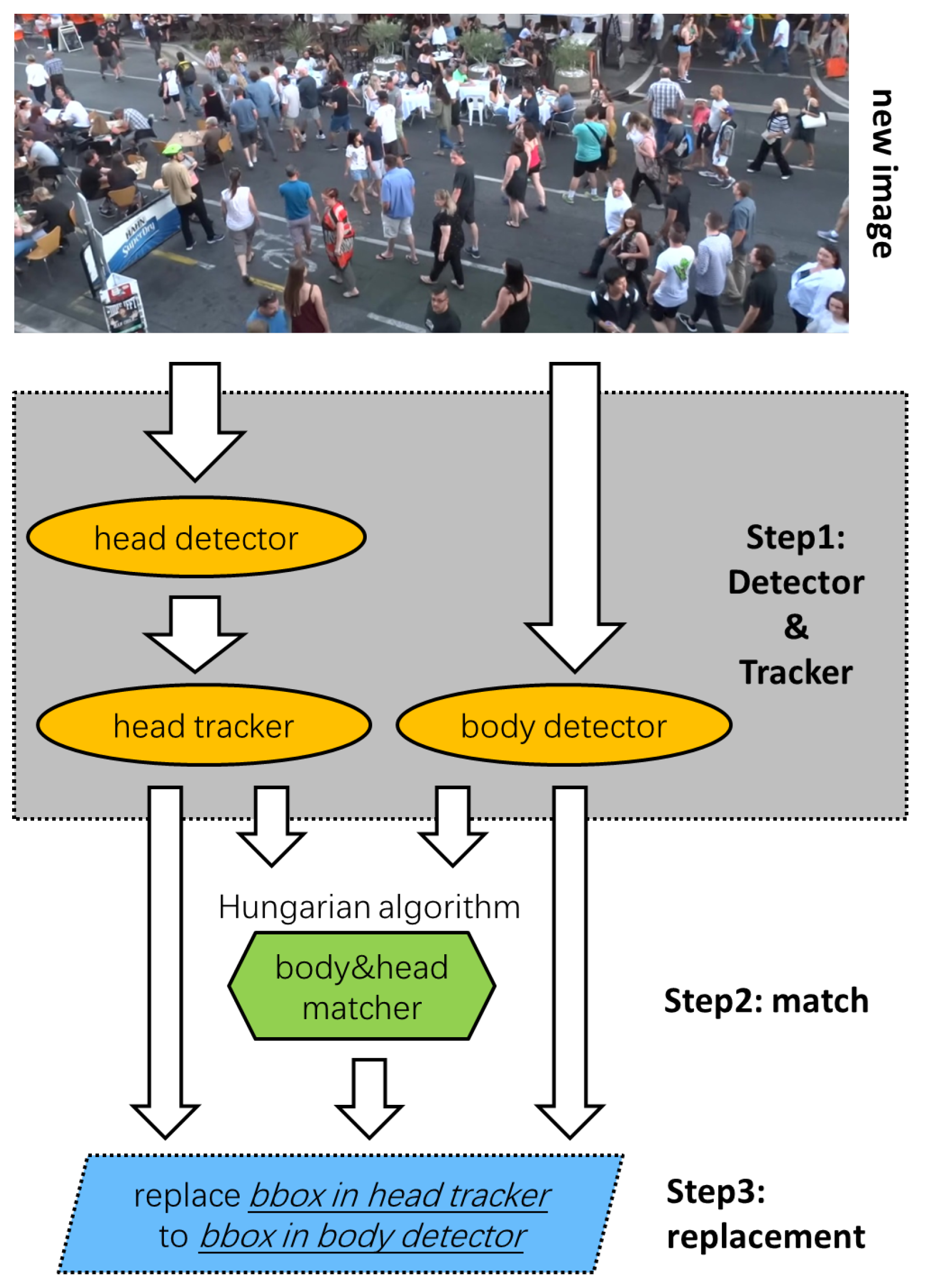
3. Main Architecture
- Step 1
- Detect and track each pedestrian’s head in the current frame, as well as detect each pedestrian’s body.
- Step 2
- Integrate the information above. Specifically, pair the head bounding boxes with the full-body bounding boxes by determining whether they belong to the same pedestrian. If they do, we link these boxes to determine their relationship.
- Step 3
- According to the matching results in Step 2, the head bounding boxes in the head motion tracklets are replaced with the body bounding boxes, thus generating the final desired pedestrian body motion tracklets.
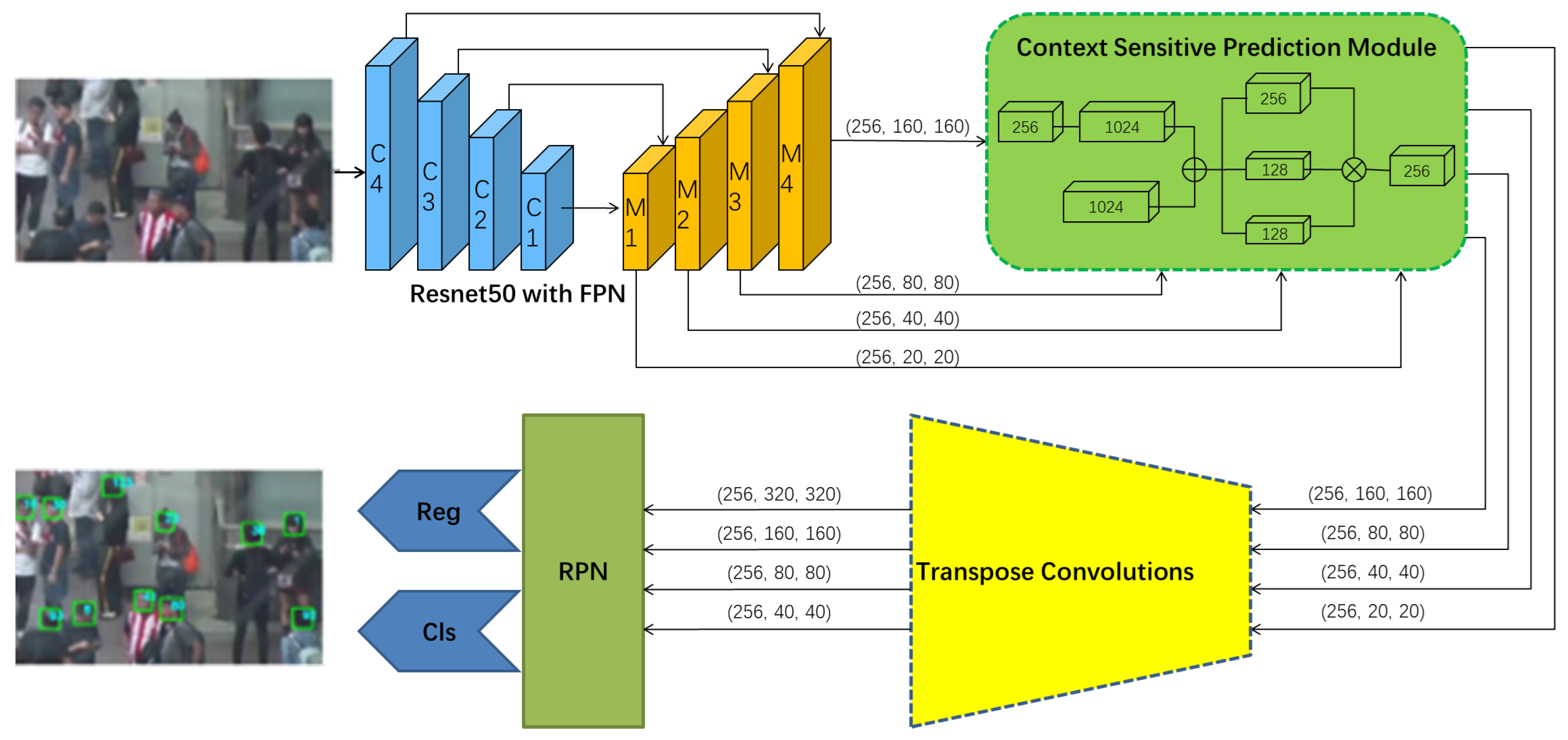
3.1. Detector and Tracker
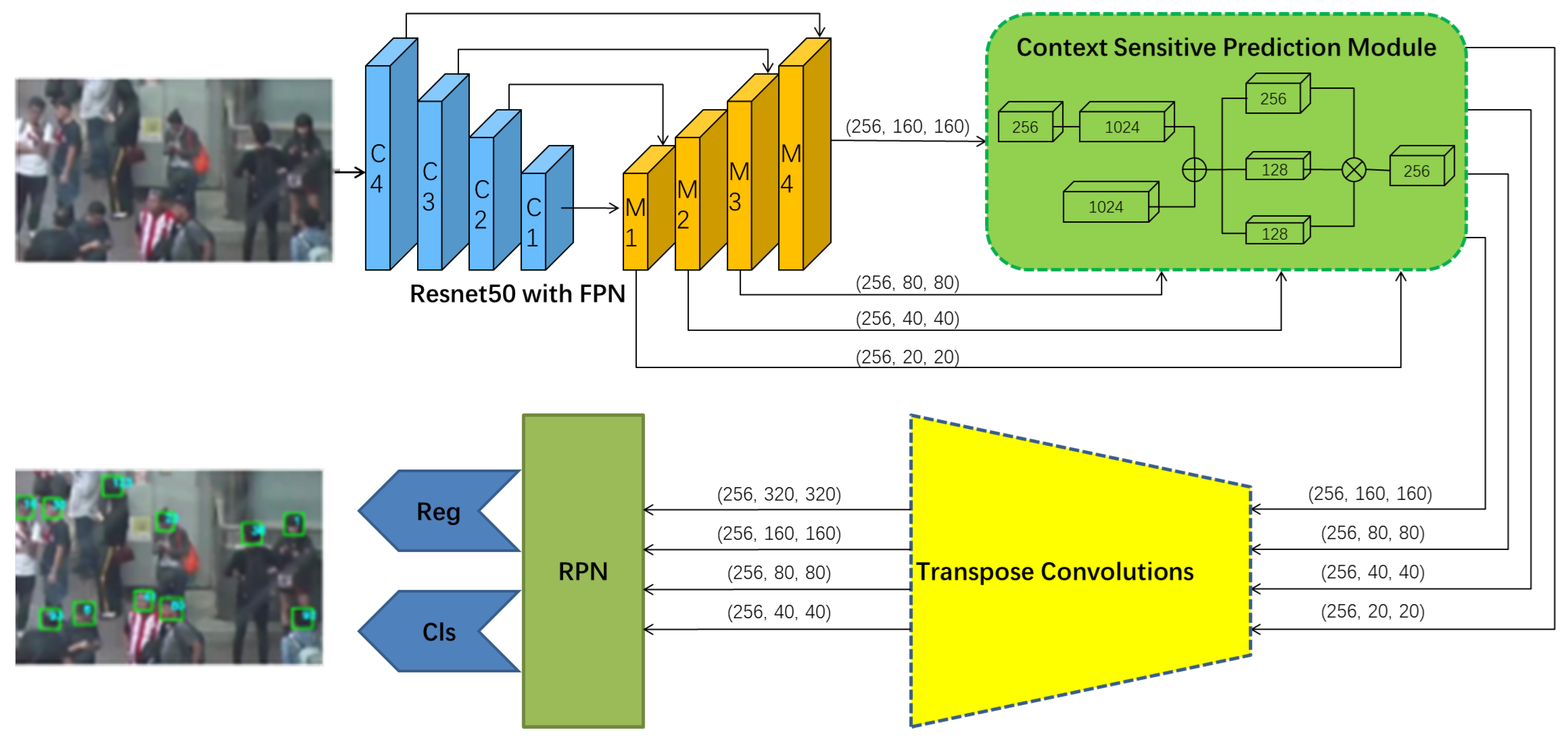
3.1.1. Head Detector
3.1.2. Head Tracker
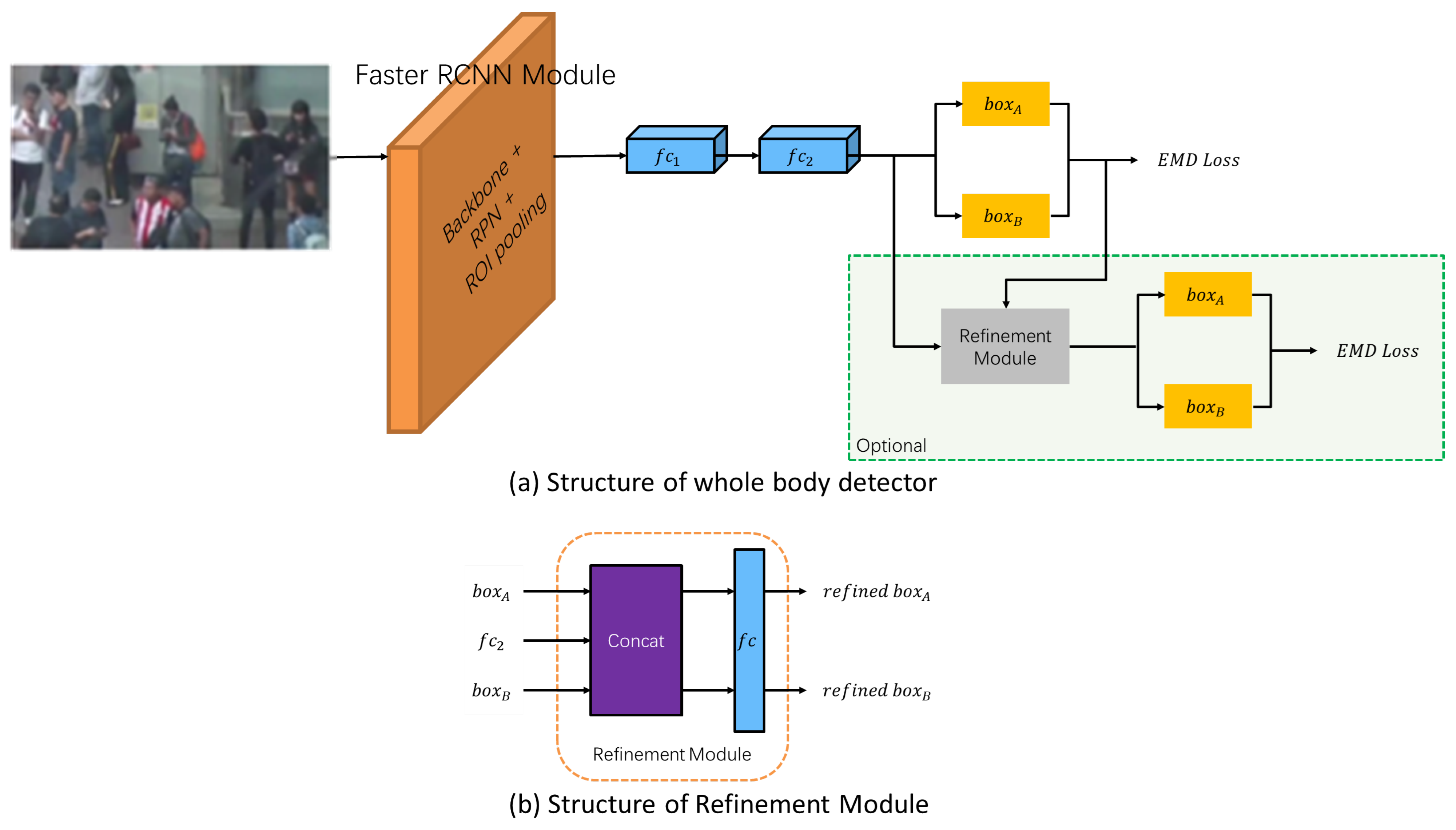
3.1.3. Body Detector
3.2. Match
3.3. Replacement
4. Experiment
4.1. General Settings
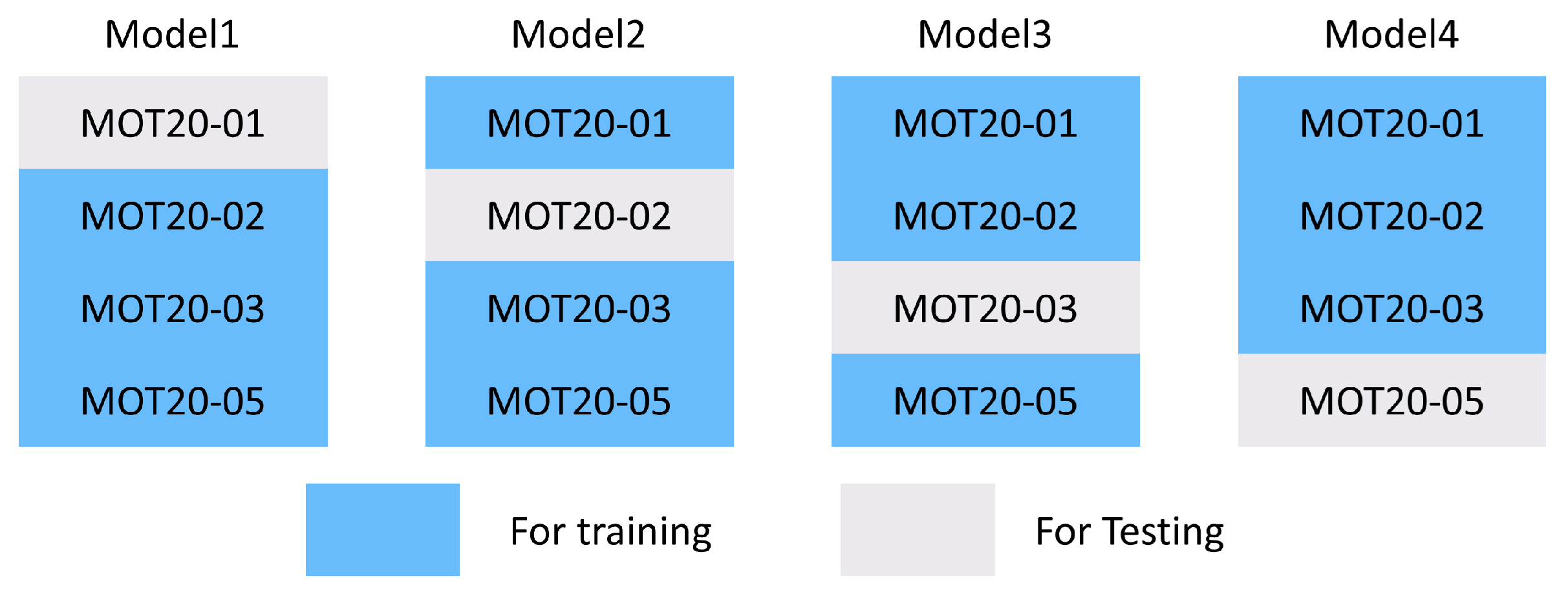
4.1.1. MOT20 Dataset
4.1.2. Metrics
4.1.3. Some Details
4.2. Ablation Study on Match Methods
4.3. Head Detection and Head Tracking Methods
4.4. Body Detection Methods
4.5. Final Results on MOT20
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Bewley, A.; Ge, Z.; Ott, L.; Ramos, F.; Upcroft, B. Simple online and realtime tracking. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 3464–3468. [Google Scholar] [CrossRef] [Green Version]
- Wojke, N.; Bewley, A. Deep Cosine Metric Learning for Person Re-identification. In Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Tahoe, NV, USA, 12–15 March 2018; pp. 748–756. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Y.; Sun, P.; Jiang, Y.; Yu, D.; Weng, F.; Yuan, Z.; Luo, P.; Liu, W.; Wang, X. ByteTrack: Multiobject Tracking by Associating Every Detection Box. arXiv 2021, arXiv:2110.06864. [Google Scholar] [CrossRef]
- Zhang, Y.; Wang, C.; Wang, X.; Zeng, W.; Liu, W. FairMOT: On the Fairness of Detection and Re-Identification in Multiple Object Tracking. Int. J. Comput. Vis. 2021, 129, 3069–3087. [Google Scholar] [CrossRef]
- Chen, L.; Ai, H.; Zhuang, Z.; Shang, C. Real-Time Multiple People Tracking with Deeply Learned Candidate Selection and Person Re-Identification. In Proceedings of the 2018 IEEE International Conference on Multimedia and Expo (ICME), San Diego, CA, USA, 23–27 July 2018; pp. 1–6. [Google Scholar] [CrossRef] [Green Version]
- Bergmann, P.; Meinhardt, T.; Leal-Taixe, L. Tracking Without Bells and Whistles. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar] [CrossRef] [Green Version]
- Sundararaman, R.; De Almeida Braga, C.; Marchand, E.; Pettré, J. Tracking Pedestrian Heads in Dense Crowd. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 3864–3874. [Google Scholar] [CrossRef]
- Dendorfer, P.; Rezatofighi, H.; Milan, A.; Shi, J.; Cremers, D.; Reid, I.; Roth, S.; Schindler, K.; Leal-Taixé, L. MOT20: A benchmark for multi object tracking in crowded scenes. arXiv 2020, arXiv:2003.09003. [Google Scholar] [CrossRef]
- Peng, D.; Sun, Z.; Chen, Z.; Cai, Z.; Xie, L.; Jin, L. Detecting Heads using Feature Refine Net and Cascaded Multi-scale Architecture. arXiv 2018, arXiv:1803.09256. [Google Scholar]
- Shao, S.; Zhao, Z.; Li, B.; Xiao, T.; Yu, G.; Zhang, X.; Sun, J. CrowdHuman: A Benchmark for Detecting Human in a Crowd. arXiv 2018, arXiv:1805.00123 2018. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef] [Green Version]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [Green Version]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal Loss for Dense Object Detection. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2999–3007. [Google Scholar] [CrossRef] [Green Version]
- Sun, P.; Jiang, Y.; Xie, E.; Shao, W.; Yuan, Z.; Wang, C.; Luo, P. What Makes for End-to-End Object Detection? In Proceedings of the 38th International Conference on Machine Learning, Virtual Event, 18–24 July 2021; Meila, M., Zhang, T., Eds.; PMLR: New York, NY, USA, 2021; Volume 139, pp. 9934–9944. [Google Scholar]
- Fu, J.; Zong, L.; Li, Y.; Li, K.; Yang, B.; Liu, X. Model Adaption Object Detection System for Robot. In Proceedings of the 2020 39th Chinese Control Conference (CCC), Shenyang, China, 27–29 July 2020; pp. 3659–3664. [Google Scholar] [CrossRef]
- Cai, Z.; Vasconcelos, N. Cascade R-CNN: Delving Into High Quality Object Detection. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 6154–6162. [Google Scholar] [CrossRef] [Green Version]
- Sun, P.; Zhang, R.; Jiang, Y.; Kong, T.; Xu, C.; Zhan, W.; Tomizuka, M.; Li, L.; Yuan, Z.; Wang, C.; et al. Sparse R-CNN: End-to-End Object Detection with Learnable Proposals. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 14449–14458. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar] [CrossRef]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 936–944. [Google Scholar] [CrossRef] [Green Version]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar] [CrossRef] [Green Version]
- Lu, Z.; Rathod, V.; Votel, R.; Huang, J. RetinaTrack: Online Single Stage Joint Detection and Tracking. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 14656–14666. [Google Scholar] [CrossRef]
- Peng, J.; Wang, C.; Wan, F.; Wu, Y.; Wang, Y.; Tai, Y.; Wang, C.; Li, J.; Huang, F.; Fu, Y. Chained-Tracker: Chaining Paired Attentive Regression Results for End-to-End Joint Multiple-Object Detection and Tracking. arXiv 2020, arXiv:2007.14557. [Google Scholar] [CrossRef]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Liang, C.; Zhang, Z.; Zhou, X.; Li, B.; Zhu, S.; Hu, W. Rethinking the Competition Between Detection and ReID in Multiobject Tracking. IEEE Trans. Image Process. 2022, 31, 3182–3196. [Google Scholar] [CrossRef] [PubMed]
- Liang, C.; Zhang, Z.; Zhou, X.; Li, B.; Hu, W. One More Check: Making “Fake Background” Be Tracked Again. arXiv 2021, arXiv:2104.09441. [Google Scholar] [CrossRef]
- Chu, P.; Wang, J.; You, Q.; Ling, H.; Liu, Z. TransMOT: Spatial-Temporal Graph Transformer for Multiple Object Tracking. arXiv 2021, arXiv:2104.00194. [Google Scholar]
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. YOLOX: Exceeding YOLO Series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]
- Zhou, X.; Wang, D.; Krähenbühl, P. Objects as Points. arXiv 2019, arXiv:1904.07850. [Google Scholar] [CrossRef]
- Wu, J.; Cao, J.; Song, L.; Wang, Y.; Yang, M.; Yuan, J. Track to Detect and Segment: An Online multiobject Tracker. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 12347–12356. [Google Scholar] [CrossRef]
- Zheng, L.; Tang, M.; Chen, Y.; Zhu, G.; Wang, J.; Lu, H. Improving Multiple Object Tracking with Single Object Tracking. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 2453–2462. [Google Scholar] [CrossRef]
- Wang, Y.; Kitani, K.; Weng, X. Joint Object Detection and multiobject Tracking with Graph Neural Networks. In Proceedings of the 2021 IEEE International Conference on Robotics and Automation (ICRA), Xi’an, China, 30 May–5 June 2021; pp. 13708–13715. [Google Scholar] [CrossRef]
- Tokmakov, P.; Li, J.; Burgard, W.; Gaidon, A. Learning to Track with Object Permanence. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 10840–10849. [Google Scholar] [CrossRef]
- Wang, Q.; Zheng, Y.; Pan, P.; Xu, Y. Multiple Object Tracking with Correlation Learning. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 3875–3885. [Google Scholar] [CrossRef]
- Wojke, N.; Bewley, A.; Paulus, D. Simple Online and Realtime Tracking with a Deep Association Metric. In Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017; pp. 3645–3649. [Google Scholar] [CrossRef] [Green Version]
- Basar, T. A New Approach to Linear Filtering and Prediction Problems. In Control Theory: Twenty-Five Seminal Papers (1932–1981); Wiley-IEEE Press: Hoboken, NJ, USA, 2001; pp. 167–179. [Google Scholar] [CrossRef]
- Khan, J.; Fayaz, M.; Hussain, A.; Khalid, S.; Mashwani, W.; Gwak, J. An Improved Alpha Beta Filter using A Deep Extreme Learning Machine. IEEE Access 2021, PP, 1. [Google Scholar] [CrossRef]
- Khan, J.; Kim, K. A Performance Evaluation of the Alpha-Beta (α-β) Filter Algorithm with Different Learning Models: DBN, DELM, and SVM. Appl. Sci. 2022, 12, 9429. [Google Scholar] [CrossRef]
- Kuhn, H.W. The Hungarian Method for the Assignment Problem. In 50 Years of Integer Programming 1958–2008: From the Early Years to the State-of-the-Art; Jünger, M., Liebling, T.M., Naddef, D., Nemhauser, G.L., Pulleyblank, W.R., Reinelt, G., Rinaldi, G., Wolsey, L.A., Eds.; Springer: Berlin/Heidelberg, Germany, 2010; pp. 29–47. [Google Scholar] [CrossRef] [Green Version]
- Wang, Z.; Zheng, L.; Liu, Y.; Wang, S. Towards Real-Time multiobject Tracking. arXiv 2020, arXiv:1909.12605. [Google Scholar]
- Zhang, Y.; Wang, C.; Wang, X.; Liu, W.; Zeng, W. VoxelTrack: Multi-Person 3D Human Pose Estimation and Tracking in the Wild. IEEE Trans. Pattern Anal. Mach. Intell. 2022. [Google Scholar] [CrossRef]
- Pang, J.; Qiu, L.; Li, X.; Chen, H.; Li, Q.; Darrell, T.; Yu, F. Quasi-Dense Similarity Learning for Multiple Object Tracking. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 164–173. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is All You Need. In Proceedings of the 31st International Conference on Neural Information Processing Systems, NIPS’17, Long Beach, CA, USA, 4–9 December 2017; Curran Associates Inc.: Red Hook, NY, USA, 2017; pp. 6000–6010. [Google Scholar]
- Wang, W.; Xie, E.; Li, X.; Fan, D.P.; Song, K.; Liang, D.; Lu, T.; Luo, P.; Shao, L. Pyramid Vision Transformer: A Versatile Backbone for Dense Prediction without Convolutions. arXiv 2021, arXiv:2102.12122. [Google Scholar] [CrossRef]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer using Shifted Windows. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 9992–10002. [Google Scholar] [CrossRef]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-End Object Detection with Transformers. arXiv 2020, arXiv:2005.12872. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. arXiv 2020, arXiv:2010.11929. [Google Scholar] [CrossRef]
- Chen, M.; Radford, A.; Wu, J.; Jun, H.; Dhariwal, P.; Luan, D.; Sutskever, I. Generative Pretraining From Pixels. In Proceedings of the ICML, Online, 13–18 July 2020. [Google Scholar]
- Liu, R.; Yuan, Z.; Liu, T.; Xiong, Z. End-to-end Lane Shape Prediction with Transformers. In Proceedings of the 2021 IEEE Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 5–8 January 2021; pp. 3693–3701. [Google Scholar] [CrossRef]
- Sun, P.; Cao, J.; Jiang, Y.; Zhang, R.; Xie, E.; Yuan, Z.; Wang, C.; Luo, P. TransTrack: Multiple-Object Tracking with Transformer. arXiv 2020, arXiv:2012.15460. [Google Scholar]
- Meinhardt, T.; Kirillov, A.; Leal-Taixe, L.; Feichtenhofer, C. TrackFormer: Multiobject Tracking with Transformers. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022. [Google Scholar]
- Xu, Y.; Ban, Y.; Delorme, G.; Gan, C.; Rus, D.; Alameda-Pineda, X. TransCenter: Transformers with Dense Queries for Multiple-Object Tracking. arXiv 2021, arXiv:2103.15145. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NA, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef] [Green Version]
- Tang, X.; Du, D.K.; He, Z.; Liu, J. PyramidBox: A Context-Assisted Single Shot Face Detector. In Proceedings of the Computer Vision—ECCV 2018, Munich, Germany, 8–14 September 2018; Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y., Eds.; Springer International Publishing: Cham, Switzerland, 2018; pp. 812–828. [Google Scholar]
- Tang, X.; Du, D.K.; He, Z.; Liu, J. PyramidBox: A Context-assisted Single Shot Face Detector. arXiv 2018, arXiv:1803.07737. [Google Scholar] [CrossRef]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A. Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning. arXiv 2016, arXiv:1602.07261. [Google Scholar] [CrossRef]
- Najibi, M.; Samangouei, P.; Chellappa, R.; Davis, L.S. SSH: Single Stage Headless Face Detector. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 4885–4894. [Google Scholar] [CrossRef] [Green Version]
- Fu, C.Y.; Liu, W.; Ranga, A.; Tyagi, A.; Berg, A.C. DSSD: Deconvolutional Single Shot Detector. arXiv 2017, arXiv:1701.06659. [Google Scholar] [CrossRef]
- Dumoulin, V.; Visin, F. A guide to convolution arithmetic for deep learning. arXiv 2016, arXiv:1603.07285. [Google Scholar] [CrossRef]
- Arulampalam, M.; Maskell, S.; Gordon, N.; Clapp, T. A tutorial on particle filters for online nonlinear/non-Gaussian Bayesian tracking. IEEE Trans. Signal Process. 2002, 50, 174–188. [Google Scholar] [CrossRef] [Green Version]
- Ding, D.; Jiang, Z.; Liu, C. Object tracking algorithm based on particle filter with color and texture feature. In Proceedings of the 2016 35th Chinese Control Conference (CCC), Chengdu, China, 27–29 July 2016; pp. 4031–4036. [Google Scholar] [CrossRef]
- Szegedy, C.; Reed, S.; Erhan, D.; Anguelov, D.; Ioffe, S. Scalable, High-Quality Object Detection. arXiv 2014, arXiv:1412.1441. [Google Scholar] [CrossRef]
- Stewart, R.; Andriluka, M. End-to-end people detection in crowded scenes. arXiv 2015, arXiv:1506.04878. [Google Scholar] [CrossRef]
- Erhan, D.; Szegedy, C.; Toshev, A.; Anguelov, D. Scalable Object Detection Using Deep Neural Networks. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 2155–2162. [Google Scholar] [CrossRef] [Green Version]
- MOT Challenge. Available online: https://motchallenge.net/ (accessed on 23 December 2022).
- Bernardin, K.; Stiefelhagen, R. Evaluating Multiple Object Tracking Performance: The CLEAR MOT Metrics. J. Image Video Process. 2008, 2008, 246309. [Google Scholar] [CrossRef] [Green Version]
- Rezatofighi, H.; Tsoi, N.; Gwak, J.; Sadeghian, A.; Reid, I.; Savarese, S. Generalized Intersection Over Union: A Metric and a Loss for Bounding Box Regression. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 658–666. [Google Scholar] [CrossRef] [Green Version]
- Luiten, J.; Osep, A.; Dendorfer, P.; Torr, P.; Geiger, A.; Leal-Taixé, L.; Leibe, B. HOTA: A Higher Order Metric for Evaluating multiobject Tracking. Int. J. Comput. Vis. 2021, 129, 1–31. [Google Scholar] [CrossRef] [PubMed]
- Sun, Z.; Peng, D.; Cai, Z.; Chen, Z.; Jin, L. Scale Mapping and Dynamic Re-Detecting in Dense Head Detection. In Proceedings of the 2018 25th IEEE International Conference on Image Processing (ICIP), Athens, Greece, 7–10 October 2018; pp. 1902–1906. [Google Scholar] [CrossRef]
- Shen, W.; Qin, P.; Zeng, J. An Indoor Crowd Detection Network Framework Based on Feature Aggregation Module and Hybrid Attention Selection Module. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision Workshop (ICCVW), Seoul, Republic of Korea, 27–28 October 2019; pp. 82–90. [Google Scholar]
- Bochinski, E.; Senst, T.; Sikora, T. Extending IOU Based multiobject Tracking by Visual Information. In Proceedings of the 2018 15th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Auckland, New Zealand, 27–30 November 2018; pp. 1–6. [Google Scholar] [CrossRef]
- Liu, S.; Huang, D.; Wang, Y. Adaptive NMS: Refining Pedestrian Detection in a Crowd. arXiv 2019, arXiv:1904.03629. [Google Scholar] [CrossRef]
- Bodla, N.; Singh, B.; Chellappa, R.; Davis, L.S. Soft-NMS – Improving Object Detection With One Line of Code. arXiv 2017, arXiv:1704.04503. [Google Scholar] [CrossRef]
- Huang, X.; Ge, Z.; Jie, Z.; Yoshie, O. NMS by Representative Region: Towards Crowded Pedestrian Detection by Proposal Pairing. arXiv 2020, arXiv:1704.04503. [Google Scholar] [CrossRef]
- Ban, Y.; Ba, S.; Alameda-Pineda, X.; Horaud, R. Tracking Multiple Persons Based on a Variational Bayesian Model. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2016; Volume 9914, pp. 52–67. [Google Scholar] [CrossRef]
- Baisa, N.L. Occlusion-robust online multiobject visual tracking using a GM-PHD filter with CNN-based re-identification. J. Vis. Commun. Image Represent. 2021, 80, 103279. [Google Scholar] [CrossRef]
- Urbann, O.; Bredtmann, O.; Otten, M.; Richter, J.P.; Bauer, T.; Zibriczky, D. Online and Real-Time Tracking in a Surveillance Scenario. arXiv 2021, arXiv:2106.01153. [Google Scholar]
- Nishimura, H.; Komorita, S.; Kawanishi, Y.; Murase, H. SDOF-Tracker: Fast and Accurate Multiple Human Tracking by Skipped-Detection and Optical-Flow. arXiv 2021, arXiv:2106.14259. [Google Scholar] [CrossRef]
- Elias, P.; Macko, M.; Sedmidubsky, J.; Zezula, P. Tracking subjects and detecting relationships in crowded city videos. Multimed. Tools Appl. 2022, 23–30. [Google Scholar] [CrossRef]
- Online multiobject Tracking Based on Salient Feature Selection in Crowded Scenes. Available online: https://motchallenge.net/method/MOT=2947&chl=13 (accessed on 23 December 2022).




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Cut A | Patch | CutB | MOTA↑ | MOTP↑ | IDF1↑ | Idsw↓ | HOTA↑ |
|---|---|---|---|---|---|---|---|
| −20% | 5px | 35px | 55.07 | 78.55 | 52.18 | 4342 | 41.11 |
| −15% | 5px | 35px | 55.04 | 78.54 | 52.16 | 4347 | 41.10 |
| −25% | 5px | 35px | 55.06 | 78.56 | 52.19 | 4354 | 41.11 |
| −20% | 0px | 35px | 54.99 | 78.56 | 52.15 | 4383 | 41.09 |
| −20% | 10px | 35px | 55.09 | 78.53 | 52.18 | 4318 | 41.11 |
| −20% | 5px | 30px | 54.81 | 78.55 | 52.04 | 4322 | 41.00 |
| −20% | 5px | 40px | 55.02 | 78.54 | 52.16 | 4348 | 41.08 |
| Method | MOTA↑ | IDF1↑ | HOTA↑ |
|---|---|---|---|
| ED | 37.89 | 34.46 | 34.52 |
| LD | 51.47 | 46.83 | 39.68 |
| IoC(Ours) | 55.07 | 52.18 | 41.12 |
| Method | Precision% | Recall% | F1 |
|---|---|---|---|
| FasterRCNN [12] | 87 | 80 | 0.83 |
| RFCN+FRN [9] | 91 | 84 | 0.87 |
| SMD [69] | 93 | 90 | 0.91 |
| HSFA2Net [70] | 94 | 92 | 0.93 |
| TraPeHat(ours) | 95 | 93 | 0.94 |
| Method | MOTA↑ | IDEucl↑ | IDF1↑ | MT↑ | ML↓ | ID Sw↓ |
|---|---|---|---|---|---|---|
| SORT [1] | 46.4 | 58.0 | 48.4 | 49 | 216 | 649 |
| V_IOU [71] | 53.4 | 34.3 | 35.4 | 80 | 182 | 1890 |
| Tracktor++ [6] | 58.9 | 31.8 | 38.5 | 125 | 117 | 3474 |
| TraPeHat(ours) | 63.6 | 60.3 | 57.1 | 146 | 93 | 892 |
| Method | AP/% | MR−2/% |
|---|---|---|
| Crowd Human Benchmark [10] | 85.0 | 50.4 |
| Adaptive NMS [72] | 84.7 | 49.7 |
| Soft-NMS [73] | 88.2 | 42.9 |
| PBM [74] | 89.3 | 43.3 |
| TraPeHat(ours) | 90.7 | 41.4 |
| Video Sequence | MOTA↑ | MOTP↑ | HOTA↑ | IDF1↑ | MT↑ | ML↓ | FP↓ | FN↓ | ID Sw↓ | |
|---|---|---|---|---|---|---|---|---|---|---|
| MOT20-04 | 70.71 | 80.85 | 54.27 | 67.15 | 45 | 3 | 4724 | 2556 | 39 | |
| MOT20-06 | 68.94 | 81.05 | 47.38 | 55.76 | 162 | 8 | 4554 | 25,771 | 364 | |
| Testing Set | MOT20-07 | 53.05 | 76.98 | 40.48 | 55.19 | 117 | 147 | 5127 | 58,201 | 564 |
| MOT20-08 | 52.25 | 78.45 | 39.18 | 49.37 | 248 | 202 | 7166 | 126,087 | 3375 | |
| OVERALL | 55.07 | 78.55 | 41.12 | 52.18 | 572 | 360 | 21,571 | 212,615 | 4342 | |
| Algorithm | MOTA↑ | HOTA↑ | IDF1↑ | MT↑ | ML↓ | FP↓ | FN↓ | ID Sw↓ |
|---|---|---|---|---|---|---|---|---|
| OVBT17 [75] | 40.00 | 30.50 | 37.80 | 141 | 374 | 23,368 | 282,949 | 4210 |
| SORT20 [1] | 42.70 | 36.10 | 45.10 | 208 | 326 | 27,521 | 264,694 | 4470 |
| GMPHD_Rd20 [76] | 44.70 | 35.60 | 43.50 | 293 | 274 | 42,778 | 236,116 | 7492 |
| IOU_KMM [77] | 46.50 | 40.40 | 49.40 | 371 | 371 | 57,517 | 214,777 | 4509 |
| FlowTracker [78] | 46.70 | 35.60 | 42.40 | 345 | 249 | 54,732 | 217,371 | 3352 |
| BBT [79] | 46.80 | 35.80 | 42.20 | 312 | 289 | 35,014 | 236,176 | 3880 |
| SFS [80] | 50.80 | 32.70 | 41.10 | 341 | 251 | 50,139 | 220,932 | 3503 |
| TraPeHat(ours) | 55.10 | 41.10 | 52.20 | 572 | 360 | 21,571 | 212,615 | 4342 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Qi, Z.; Zhou, M.; Zhu, G.; Xue, Y. Multiple Pedestrian Tracking in Dense Crowds Combined with Head Tracking. Appl. Sci. 2023, 13, 440. https://doi.org/10.3390/app13010440
Qi Z, Zhou M, Zhu G, Xue Y. Multiple Pedestrian Tracking in Dense Crowds Combined with Head Tracking. Applied Sciences. 2023; 13(1):440. https://doi.org/10.3390/app13010440
Chicago/Turabian StyleQi, Zhouming, Mian Zhou, Guoqiang Zhu, and Yanbing Xue. 2023. "Multiple Pedestrian Tracking in Dense Crowds Combined with Head Tracking" Applied Sciences 13, no. 1: 440. https://doi.org/10.3390/app13010440
APA StyleQi, Z., Zhou, M., Zhu, G., & Xue, Y. (2023). Multiple Pedestrian Tracking in Dense Crowds Combined with Head Tracking. Applied Sciences, 13(1), 440. https://doi.org/10.3390/app13010440