
Unsupervised Domain Adaptation via Stacked Convolutional Autoencoder †

Abstract
1. Introduction
- We explicitly propose a new framework of unsupervised domain adaptation based on a stacked convolutional sparse autoencoder (short for SCSA). There is an obvious distinction between this method and the original method [2,14], which relies on applying the classical structure of the autoencoder to learn representations or integratation of the regularization term into the objective function.
- Our proposed SCSA has two main components in each layer. In the first component, a stacked sparse autoencoder with RICA is introduced for recognition feature learning to reduce the divergence between the source and target domains. In the second component, the convolution and pool layer is utilized to preserve the local relevance of features to achieve enhanced performance.
2. Background Studies
3. Related Work
3.1. Shallow Learning Methods
3.2. Autoencoder-Based Methods
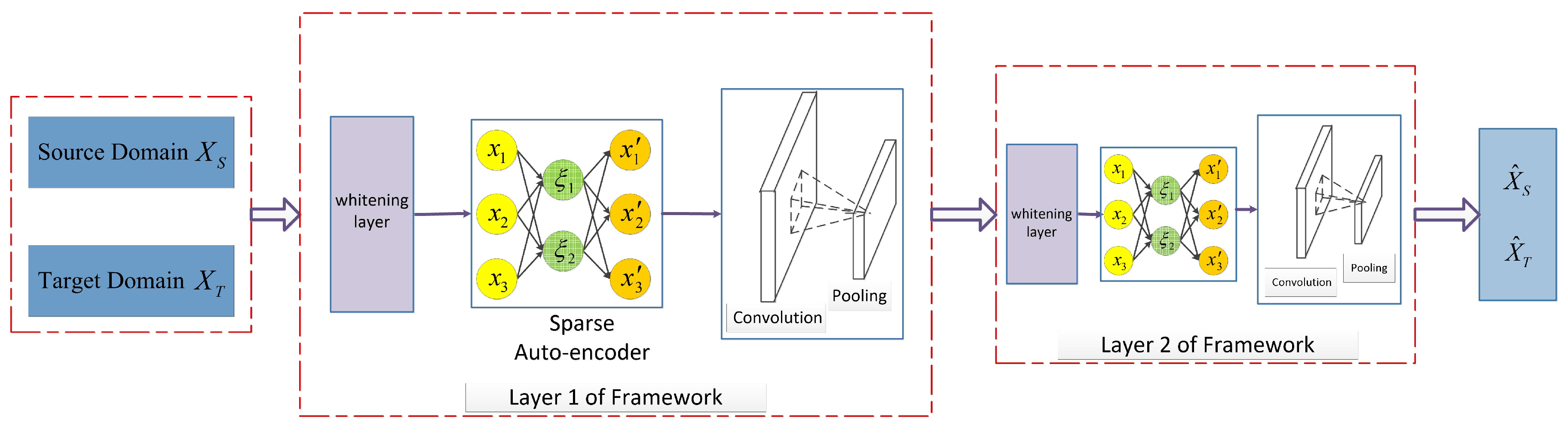
4. Our Proposed Method
4.1. Motivation
4.2. Stacked Sparse Autoencoder
4.3. Convolution and Pool Layer
5. Experiments
5.1. Datasets
5.2. Compared Methods
- The standard classifier without unsupervised domain adaptation technique; we introduced support vector machine (SVM) in the experiments.
- Transfer component analysis (TCA) [13], which aims to project the original data into the common latent feature space via dimension reduction for unsupervised domain adaptation.
- Marginalized stacked denoising autoencoders (mSDA) [19], which are elaborated to learn more abstract and invasive feature representations so that domain integration can be carried out.
- Transfer learning with deep autoencoders (TLDA) [14]. The dual-level autoencoder is designed to learn more transferable features for domain adaptation.
- Transfer learning with manifold regularized autoencoders (TLMRA) [2]. To obtain more abstract representations, the method combines manifold regularization and softmax weight regression.
- Semi-supervised representation learning framework via dual autoencoders (SSRLDA) [1]. The mSDA with adaptation distributions and multi-class marginalized denoising autoencoder are applied to obtain global and local features for unsupervised domain adaptation.
5.3. Experiment Settings
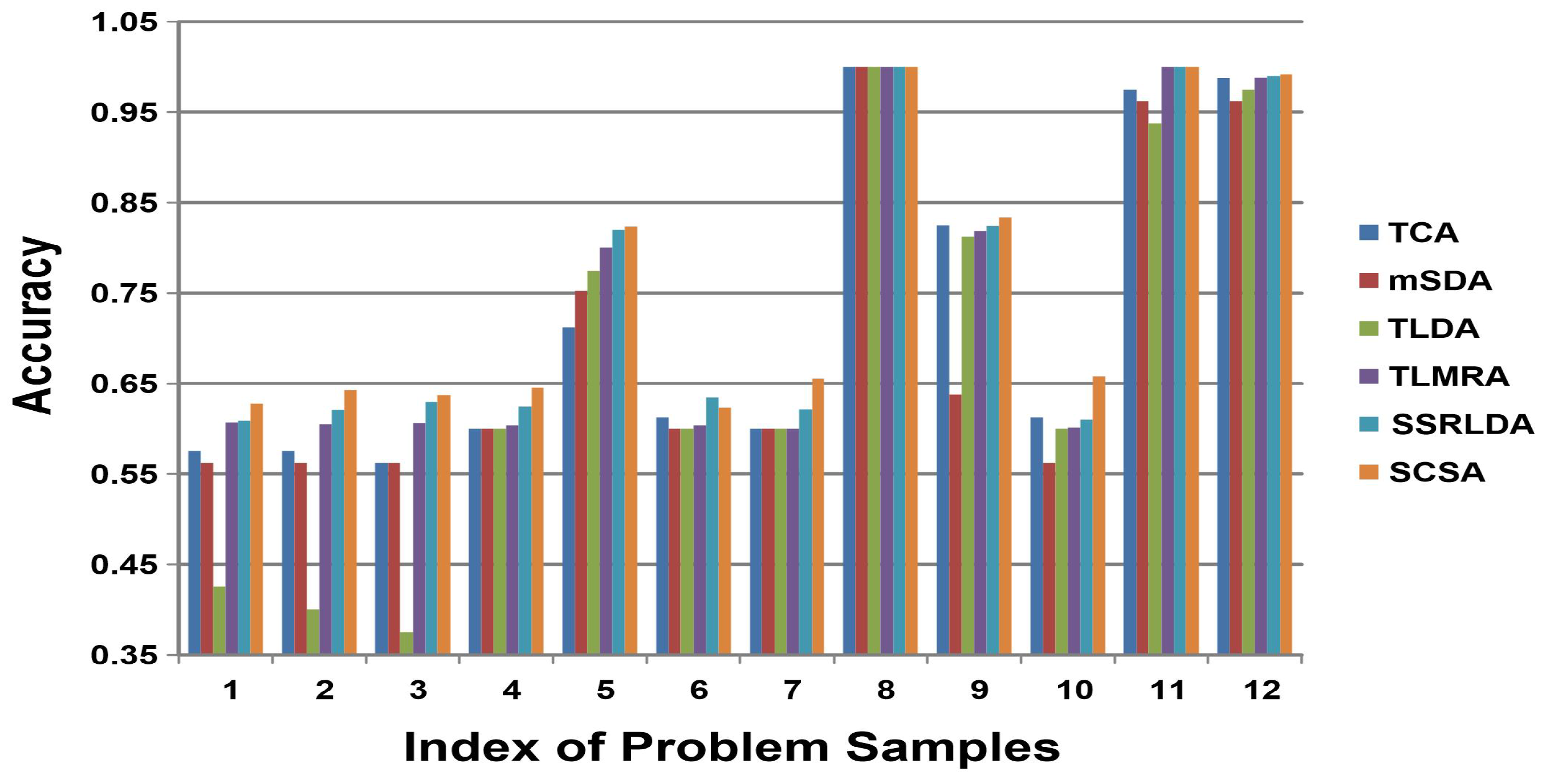
5.4. Experimental Results
- All the domain adaptation methods significantly and consistently outperformed the standard SVM classifier, demonstrating the advantages of the feature-representation method in a broader set of scenarios.
- Compared to shallow learning methods, such as TCA, autoencoder-based methods, such as TLDA, TLMRA, and SSRLDA, all achieved superior results in unsupervised domain adaptation, indicating the superiority of deep-learning-based methods in learning transferable and discriminative features across domains. Notably, mSDA achieved comparable performance to TCA, demonstrating that the traditional structure of the autoencoder cannot learn sufficient features. This is why other autoencoder-based methods require improvements in architecture.
- In comparison with mSDA, our SCSA achieved better performance in all tasks for three different datasets, demonstrating the superiority of our framework for exploring different domains compared to autoencoder-based domain adaptation methods.
- By comparison to other autoencoder-based deep methods, such as TLDA and TLMRA, our proposed SCSA achieved better performance for overall tasks in the same target domains and for the same problems. These methods rely on the classical structure of autoencoders (i.e., TLMRA) or the integration of regularization terms into the objective function (i.e., TLDA). The results confirm that our SCSA can explore abstract and distinctive features for domain adaptation.
- For all three experimental datasets, our method was better than SSRLDA. From Figure 2 and Figure 3, it can be seen that our method achieved better results for most tasks in the same target domains and for the same problems. Our SCSA also achieved comparable performance to SSRLDA in other tasks. As a semi-supervised method, our method achieved superior performance for all three image datasets, indicating that the convolution and pooling layer can maintain the local relevance and learn features better for domain adaptation in image datasets.
- Generally, compared with alternative methods, our SCSA achieved the best results in all groups for three different datasets, confirming the effectiveness of our proposed method.
5.5. Analysis of Properties in SCSA
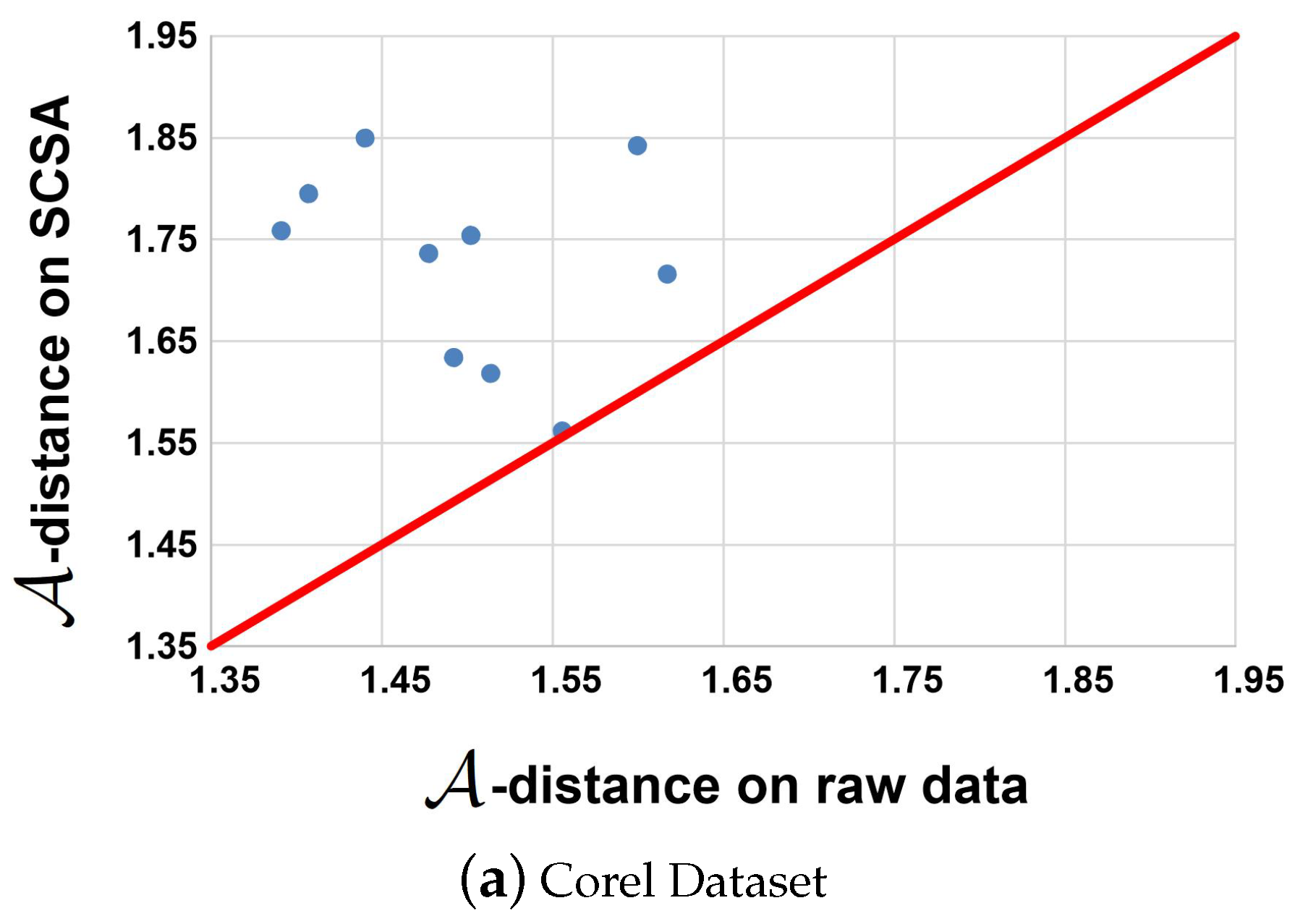
5.6. Transfer Distance
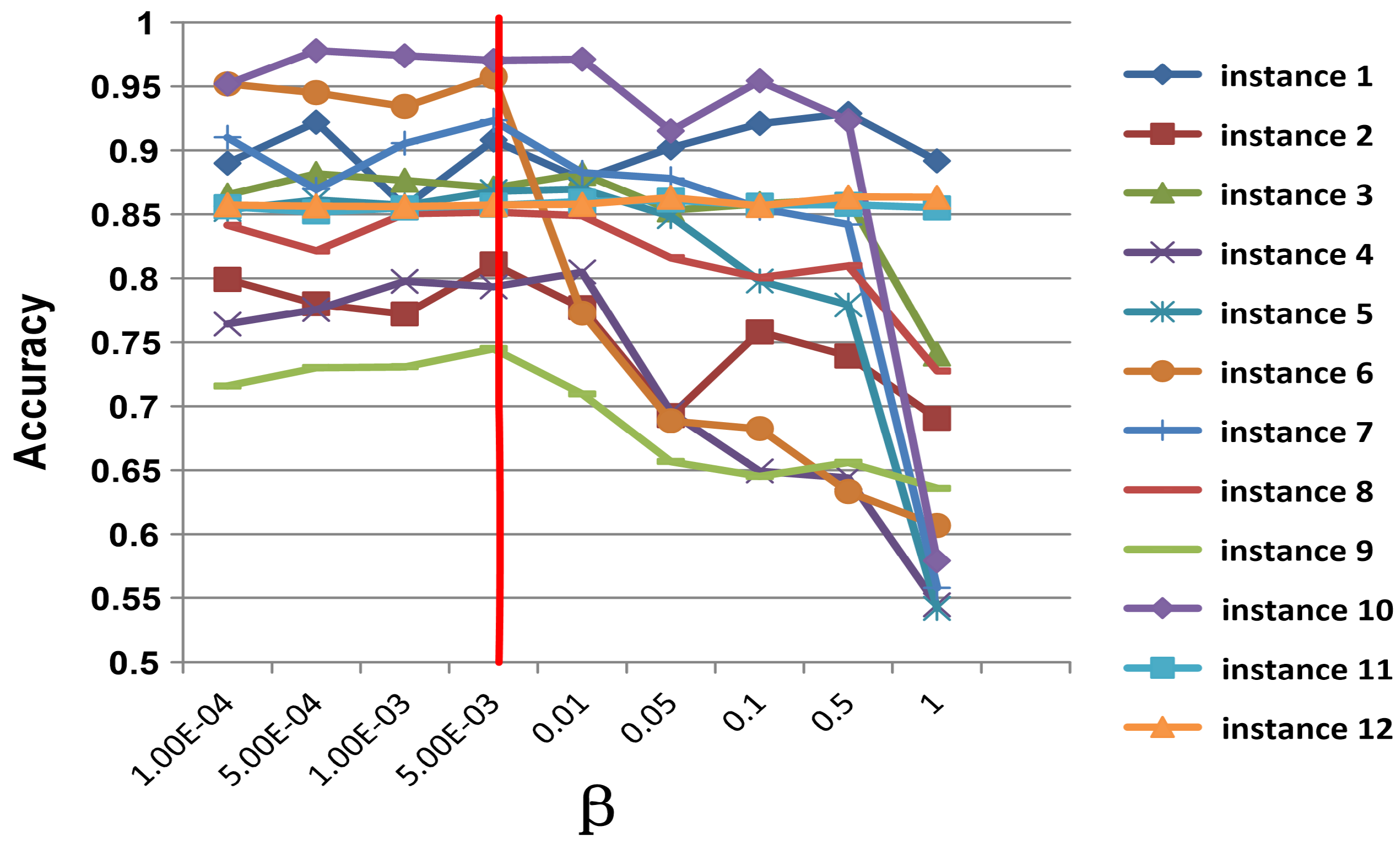
5.7. Parameter Sensitivity
6. Conclusions
Author Contributions
Funding
Informed Consent Statement
Conflicts of Interest
Appendix A
References
- Yang, S.; Wang, H.; Zhang, Y.; Li, P.; Zhu, Y.; Hu, X. Semi-supervised representation learning via dual autoencoders for domain adaptation. Knowl.-Based Syst. 2020, 190, 105161. [Google Scholar] [CrossRef]
- Zhu, Y.; Xindong, W.; Li, P.; Zhang, Y.; Hu, X. Transfer learning with deep manifold regularized auto-encoders. Neurocomputing 2019, 369, 145–154. [Google Scholar] [CrossRef]
- Wilson, G.; Cook, D.J. A survey of unsupervised deep domain adaptation. ACM Trans. Intell. Syst. Technol. (TIST) 2020, 11, 1–46. [Google Scholar] [CrossRef] [PubMed]
- Yi, Z.; Hu, X.; Zhang, Y.; Li, P. Transfer Learning with Stacked Reconstruction Independent Component Analysis. Knowl.-Based Syst. 2018, 152, 100–106. [Google Scholar]
- Wang, M.; Deng, W. Deep visual domain adaptation: A survey. Neurocomputing 2018, 312, 135–153. [Google Scholar] [CrossRef]
- You, K.; Long, M.; Cao, Z.; Wang, J.; Jordan, M.I. Universal domain adaptation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 2720–2729. [Google Scholar]
- Kang, G.; Jiang, L.; Yang, Y.; Hauptmann, A.G. Contrastive Adaptation Network for Unsupervised Domain Adaptation; IEEE: Piscataway, NJ, USA, 2019; pp. 4893–4902. [Google Scholar]
- Deng, J.; Zhang, Z.; Eyben, F.; Schuller, B. Autoencoder-based Unsupervised Domain Adaptation for Speech Emotion Recognition. IEEE Signal Process. Lett. 2014, 21, 1068–1072. [Google Scholar] [CrossRef]
- Ahn, E.; Kumar, A.; Fulham, M.; Feng, D.; Kim, J. Unsupervised Domain Adaptation to Classify Medical Images Using Zero-Bias Convolutional Auto-Encoders and Context-Based Feature Augmentation. IEEE Trans. Med. Imaging 2020, 39, 2385–2394. [Google Scholar] [CrossRef]
- Pan, S.J.; Yang, Q. A survey on transfer learning. IEEE Trans. Knowl. Data Eng. 2009, 22, 1345–1359. [Google Scholar] [CrossRef]
- Feng, S.; Yu, H.; Duarte, M.F. Autoencoder based sample selection for self-taught learning. Knowl.-Based Syst. 2020, 192, 105343. [Google Scholar] [CrossRef]
- Tzeng, E.; Hoffman, J.; Saenko, K.; Darrell, T. Adversarial discriminative domain adaptation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7167–7176. [Google Scholar]
- Pan, S.J.; Tsang, I.W.; Kwok, J.T.; Yang, Q. Domain adaptation via transfer component analysis. IEEE Trans. Neural Netw. 2011, 22, 199–210. [Google Scholar] [CrossRef]
- Zhuang, F.; Cheng, X.; Luo, P.; Pan, S.J.; He, Q. Supervised representation learning: Transfer learning with deep autoencoders. In Proceedings of the International Joint Conference on Artificial Intelligence, IJCAI, Buenos Aires, Argentina, 25–31 July 2015; pp. 4119–4125. [Google Scholar]
- Yang, S.; Zhang, Y.; Wang, H.; Li, P.; Hu, X. Representation learning via serial robust autoencoder for domain adaptation. Expert Syst. Appl. 2020, 160, 113635. [Google Scholar] [CrossRef]
- Xie, G.S.; Zhang, X.Y.; Yan, S.; Liu, C.L. Hybrid CNN and dictionary-based models for scene recognition and domain adaptation. IEEE Trans. Circuits Syst. Video Technol. 2015, 27, 1263–1274. [Google Scholar] [CrossRef]
- Jaech, A.; Heck, L.; Ostendorf, M. Domain adaptation of recurrent neural networks for natural language understanding. arXiv 2016, arXiv:1604.00117. [Google Scholar]
- Choi, J.; Kim, T.; Kim, C. Self-ensembling with gan-based data augmentation for domain adaptation in semantic segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6830–6840. [Google Scholar]
- Chen, M.; Xu, Z.; Weinberger, K.; Fei, S. Marginalized Denoising Autoencoders for Domain Adaptation. In Proceedings of the ICML, Edinburgh, UK, 26 June– 1 July 2012; pp. 767–774. [Google Scholar]
- Vincent, P.; Larochelle, H.; Lajoie, I.; Bengio, Y.; Manzagol, P.A. Stacked Denoising Autoencoders: Learning Useful Representations in a Deep Network with a Local Denoising Criterion. J. Mach. Learn. Res. 2010, 11, 3371–3408. [Google Scholar]
- Wei, P.; Ke, Y.; Goh, C.K. Deep nonlinear feature coding for unsupervised domain adaptation. In Proceedings of the International Joint Conference on Artificial Intelligence, IJCAI, New York, NY, USA, 9–15 July 2016; pp. 2189–2195. [Google Scholar]
- Zhuang, F.; Cheng, X.; Luo, P.; Pan, S.J.; He, Q. Supervised representation learning with double encoding-layer autoencoder for transfer learning. ACM Trans. Intell. Syst. Technol. (TIST) 2017, 9, 1–17. [Google Scholar] [CrossRef]
- Clinchant, S.; Csurka, G.; Chidlovskii, B. A Domain Adaptation Regularization for Denoising Autoencoders. In Proceedings of the Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), Berlin, Germany, 7–12 August 2016; pp. 26–31. [Google Scholar]
- Yang, S.; Zhang, Y.; Zhu, Y.; Li, P.; Hu, X. Representation learning via serial autoencoders for domain adaptation. Neurocomputing 2019, 351, 1–9. [Google Scholar] [CrossRef]
- Zhu, Y.; Zhou, X.; Li, Y.; Qiang, J.; Yuan, Y. Domain Adaptation with Stacked Convolutional Sparse Autoencoder. In Proceedings of the International Conference on Neural Information Processing, Sanur, Bali, Indonesia, 8–12 December 2021; pp. 685–692. [Google Scholar]
- Ganin, Y.; Lempitsky, V. Unsupervised Domain Adaptation by Backpropagation. In Proceedings of the International Conference on Machine Learning, ICML, Lille France, 6–11 July 2015; pp. 1180–1189. [Google Scholar]
- Sener, O.; Song, H.O.; Saxena, A.; Savarese, S. Learning transferrable representations for unsupervised domain adaptation. Adv. Neural Inf. Process. Syst. 2016, 29, 1–9. [Google Scholar]
- Farahani, A.; Voghoei, S.; Rasheed, K.; Arabnia, H.R. A brief review of domain adaptation. Adv. Data Sci. Inf. Eng. 2021, 877–894. [Google Scholar]
- Zhang, X.; Yu, F.X.; Chang, S.F.; Wang, S. Deep transfer network: Unsupervised domain adaptation. arXiv 2015, arXiv:1503.00591. [Google Scholar]
- Mingsheng, L.; Han, Z.; Jianmin, W.; Jordan, M.I. Unsupervised Domain Adaptation with Residual Transfer Networks. In Proceedings of the Advances in Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; Volume 29, pp. 1–9. [Google Scholar]
- Pinheiro, P.O. Unsupervised Domain Adaptation With Similarity Learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 8004–8013. [Google Scholar]
- Long, M.; Cao, Z.; Wang, J.; Jordan, M.I. Conditional adversarial domain adaptation. Adv. Neural Inf. Process. Syst. 2018, 31, 1647–1657. [Google Scholar]
- Pei, Z.; Cao, Z.; Long, M.; Wang, J. Multi-adversarial domain adaptation. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; pp. 877–894. [Google Scholar]
- Zhang, T.; Wang, D.; Chen, H.; Zeng, Z.; Guo, W.; Miao, C.; Cui, L. BDANN: BERT-based domain adaptation neural network for multi-modal fake news detection. In Proceedings of the 2020 international joint conference on neural networks (IJCNN), Glasgow, UK, 19–24 July 2020; pp. 1–8. [Google Scholar]
- Guo, X.; Li, B.; Yu, H. Improving the Sample Efficiency of Prompt Tuning with Domain Adaptation. arXiv 2022, arXiv:2210.02952. [Google Scholar]
- Chen, Y.; Song, S.; Li, S.; Yang, L.; Wu, C. Domain space transfer extreme learning machine for domain adaptation. IEEE Trans. Cybern. 2019, 49, 1909–1922. [Google Scholar] [CrossRef] [PubMed]
- He, Y.; Tian, Y.; Liu, D. Multi-view transfer learning with privileged learning framework. Neurocomputing 2019, 335, 131–142. [Google Scholar] [CrossRef]
- Chen, M.; Zhao, S.; Liu, H.; Cai, D. Adversarial-Learned Loss for Domain Adaptation. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 3521–3528. [Google Scholar]
- Wang, Y.; Qiu, S.; Ma, X.; He, H. A prototype-based SPD matrix network for domain adaptation EEG emotion recognition. Pattern Recognit. 2021, 110, 107626. [Google Scholar] [CrossRef]
- Liu, F.; Lu, J.; Zhang, G. Unsupervised heterogeneous domain adaptation via shared fuzzy equivalence relations. IEEE Trans. Fuzzy Syst. 2018, 26, 3555–3568. [Google Scholar] [CrossRef]
- Yan, Y.; Li, W.; Wu, H.; Min, H.; Tan, M.; Wu, Q. Semi-Supervised Optimal Transport for Heterogeneous Domain Adaptation. In Proceedings of the International Joint Conference on Artificial Intelligence, IJCAI, Stockholm, Sweden, 13–19 July 2018; Volume 7, pp. 2969–2975. [Google Scholar]
- Luo, Y.; Wen, Y.; Liu, T.; Tao, D. Transferring knowledge fragments for learning distance metric from a heterogeneous domain. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 41, 1013–1026. [Google Scholar] [CrossRef]
- Glorot, X.; Bordes, A.; Bengio, Y. Domain adaptation for large-scale sentiment classification: A deep learning approach. In Proceedings of the International Conference on Machine Learning, Bellevue, WA, USA, 28 June–2 July 2011; pp. 513–520. [Google Scholar]
- Nikisins, O.; George, A.; Marcel, S. Domain Adaptation in Multi-Channel Autoencoder based Features for Robust Face Anti-Spoofing. In Proceedings of the 2019 International Conference on Biometrics (ICB), Crete, Greece, 4–7 June 2019; pp. 1–8. [Google Scholar]
- Zhu, Y.; Wu, X.; Li, Y.; Qiang, J.; Yuan, Y. Self-Adaptive Imbalanced Domain Adaptation With Deep Sparse Autoencoder. IEEE Trans. Artif. Intell. 2022, 1–12. [Google Scholar] [CrossRef]
- Oquab, M.; Bottou, L.; Laptev, I.; Sivic, J. Learning and transferring mid-level image representations using convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1717–1724. [Google Scholar]
- Hoffman, J.; Guadarrama, S.; Tzeng, E.S.; Hu, R.; Donahue, J.; Girshick, R.; Darrell, T.; Saenko, K. LSDA: Large scale detection through adaptation. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 3536–3544. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1440–1448. [Google Scholar]
- Murray, N.; Perronnin, F. Generalized max pooling. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 2473–2480. [Google Scholar]
- Boureau, Y.L.; Ponce, J.; LeCun, Y. A theoretical analysis of feature pooling in visual recognition. In Proceedings of the ICML, Haifa, Israel, 21–24 June 2010; pp. 111–118. [Google Scholar]
- Li, X.; Armagan, E.; Tomasgard, A.; Barton, P. Stochastic pooling problem for natural gas production network design and operation under uncertainty. AIChE J. 2011, 57, 2120–2135. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. In Proceedings of the ICNIPS, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- Jin, X.; Zhuang, F.; Xiong, H.; Du, C.; Luo, P.; He, Q. Multi-task Multi-view Learning for Heterogeneous Tasks. In Proceedings of the ACM International Conference on Conference on Information and Knowledge Management, Shanghai, China, 3–7 November 2014; pp. 441–450. [Google Scholar]
- Ben-David, S.; Blitzer, J.; Crammer, K.; Pereira, F. Analysis of representations for domain adaptation. Adv. Neural Inf. Process. Syst. 2007, 19, 137–145. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Domain1 | Domain2 | Domain3 | Domain4 | |
|---|---|---|---|---|
| Number of Positive Instances | 1000 | 1000 | 1000 | 1000 |
| Number of Negative Instances | 1000 | 1000 | 1000 | 1000 |
| Feature | 900 | 900 | 900 | 900 |
| Data Sets | Configurations | |
|---|---|---|
| Corel Data Set | Kernel Size | 11 × 11 × 3 |
| Maps Number | 1000 | |
| Pool Type | max | |
| Pool Size | 12 × 12 | |
| ImageNet Dataset | Kernel Size | 10 × 10 × 3 |
| Maps Number | 500 | |
| Pool Type | max | |
| Pool Size | 24 × 24 | |
| Leaves Dataset | Kernel Size | 6 × 6 × 3 |
| Maps Number | 800 | |
| Pool Type | mean | |
| Pool Size | 3 × 3 | |
| SVM | TCA | mSDA | TLDA | TLMRA | SSRLDA | SCSA |
|---|---|---|---|---|---|---|
| ImageNet Data Set | ||||||
| 62.6 ± 0.9 | 75.6 ± 1.1 | 77.6 ± 1.2 | 83.6 ± 1.1 | 88.9 ± 1.1 | 89.1 ± 0.7 | 89.3 ± 0.9 |
| Corel Data Set | ||||||
| 52.9 ± 0.8 | 76.5 ± 0.7 | 73.4 ± 0.6 | 80.2 ± 0.6 | 84.5 ± 0.5 | 84.9 ± 0.6 | 85.1 ± 0.4 |
| Leaves Data Set | ||||||
| 60.0 ± 0.4 | 72.0 ± 0.5 | 70.1 ± 0.4 | 67.5 ± 0.4 | 73.6 ± 0.7 | 75.0 ± 0.5 | 76.2 ± 0.6 |
| Without RICA | With RICA | |
|---|---|---|
| ImageNet Data Set | ||
| 89.0 ± 0.7 | 89.3 ± 0.9 | |
| Corel Data Set | ||
| 84.8 ± 0.5 | 85.1 ± 0.4 | |
| Leaves Data Set | ||
| 74.1 ± 0.5 | 76.2 ± 0.6 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhu, Y.; Zhou, X.; Wu, X. Unsupervised Domain Adaptation via Stacked Convolutional Autoencoder. Appl. Sci. 2023, 13, 481. https://doi.org/10.3390/app13010481
Zhu Y, Zhou X, Wu X. Unsupervised Domain Adaptation via Stacked Convolutional Autoencoder. Applied Sciences. 2023; 13(1):481. https://doi.org/10.3390/app13010481
Chicago/Turabian StyleZhu, Yi, Xinke Zhou, and Xindong Wu. 2023. "Unsupervised Domain Adaptation via Stacked Convolutional Autoencoder" Applied Sciences 13, no. 1: 481. https://doi.org/10.3390/app13010481
APA StyleZhu, Y., Zhou, X., & Wu, X. (2023). Unsupervised Domain Adaptation via Stacked Convolutional Autoencoder. Applied Sciences, 13(1), 481. https://doi.org/10.3390/app13010481