1. Introduction
Clustering is one of the basic tasks in machine learning, computer vision and other fields. It aims to assign unlabeled samples to different clusters so that samples in the same cluster are similar to each other while samples in different clusters are as dissimilar as possible [
1]. With the development of deep learning, the need for large-scale labeled datasets is a major obstacle to the application of deep learning in many scenarios. However, manually labeling these datasets is costly and time-consuming. To make better use of unlabeled data, unsupervised clustering has gradually attracted widespread attention. The main research directions of clustering at this stage can be divided into image, text [
2], multi-view clustering [
3,
4] and so on. Among these data, the simplest and most intuitive feeling is image data. Traditional clustering methods, such as k-means [
5], Gaussian mixture model [
6], density peak clustering [
7] and other methods are limited when they meet high-dimensional data, such as images. The reason is the failure of their similarity measures. With the help of fuzzy set theory and its extensions, such as intuitionistic fuzzy sets [
8] and others, many novel similarity measures have emerged and made some progress compared to conventional similarity measures. However, a more intuitive solution attracts attention. These methods [
9,
10] map high-dimensional data into a low-dimensional representation space and perform clustering in the low-dimensional space. These low-dimensional representations are not informative enough, resulting in no significant improvement in the clustering performance. Therefore, image clustering is still a challenging task.
Deep learning has been gradually combined with computer vision. Due to the powerful representation extraction ability of deep neural networks, it has achieved success in the fields of classification [
11,
12], object recognition [
13,
14,
15] and image retrieval [
16]. Many scholars turn their attention to deep clustering [
17]. Deep clustering refers to the process of automatically learning the data representations and guiding clustering through neural networks. Widely used network architecture includes Convolutional Neural Networks [
12,
18], Autoencoders [
19] and Variational Autoencoders [
20]. Following the success of Generative Adversarial Networks [
21], many works [
22,
23,
24,
25] introduced the idea of GANs into representation learning and achieved good results. Combining neural networks with traditional clustering algorithms is an effective solution, which consists of two stages. In the first stage, the neural network captures the low-dimensional representations of the samples. In the second stage, the learned low-dimensional representations are served as the input for traditional clustering methods. Some progress has been made compared to traditional methods.
Recently, many unsupervised deep learning methods have been proposed to learn clustering. By introducing data augmentation, most of the latest methods look into deep clustering from the perspective that the original image and its transformation should share similar semantic clustering assignments [
26,
27,
28]. These methods have achieved some progress on complex natural image datasets. However, the above methods have some limitations: (1) Since generative networks based on autoencoders require pixel-level reconstruction. It is easy to capture redundant image information, such as background, color and other trivial information; (2) These methods only learn class-level representation. However, the instance-level representation could be quite different even if they are assigned to the same cluster since the softmax function is only sensitive to the maximum value. In other words, class-level representation alone is not enough to describe the differences between images belonging to the same cluster.
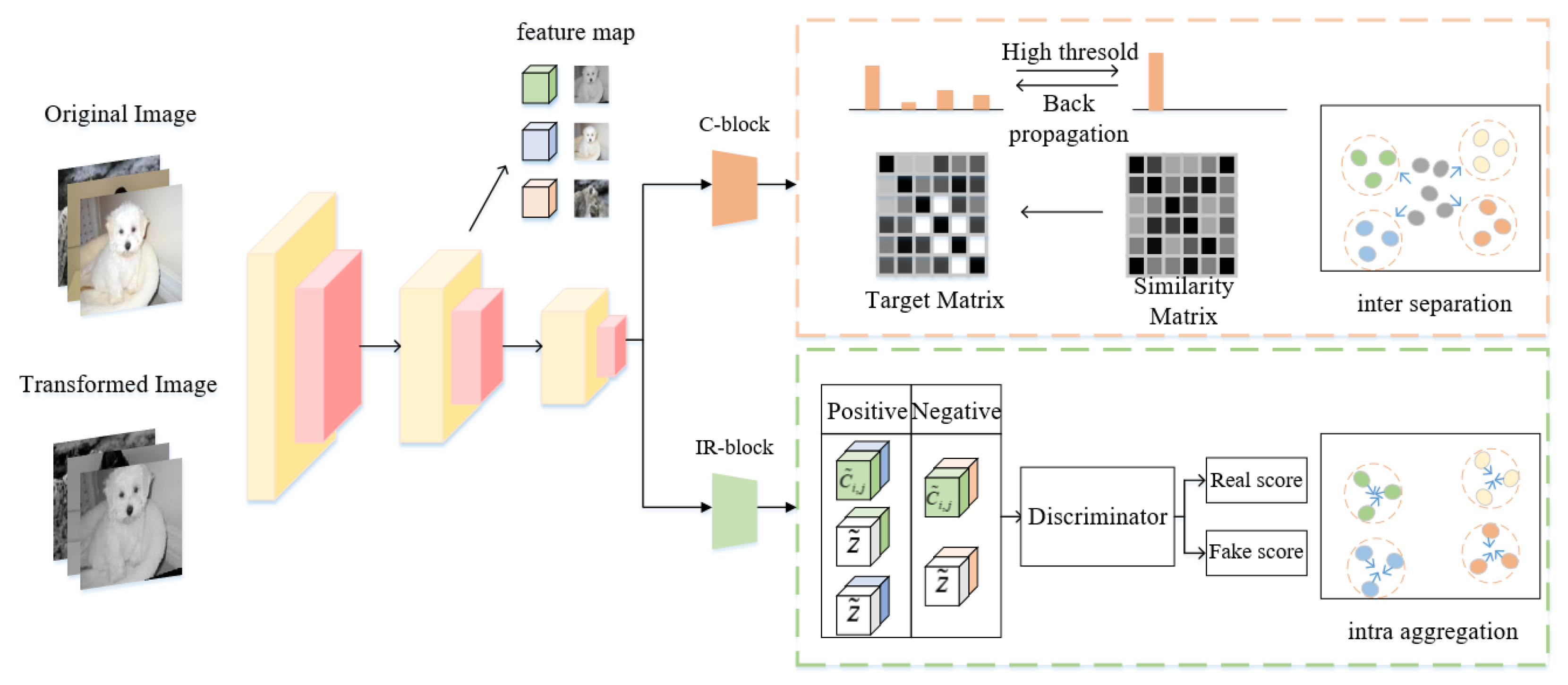
In order to solve the above limitations, this paper proposes a new image clustering model, DCSM. Based on the class-level mapping block (C-block), DCSM adds an instance-level mapping block (IR-block). The two blocks share the same backbone network, and the backbone network acts as an information transmission channel between the two blocks. First, the C-block learns discriminative class-level representation by selecting pairwise similar (dissimilar) samples. Second, errors will occur when constructing similar labels of sample pairs, so select high-confidence cluster-standard samples to correct network parameters because samples with high-confidence predictions are often already assigned to the proper cluster. Third, the proposed extended MI maximizes the MI between the global-local and local-local features of multiple views, forcing the IR block to capture the essential information. This can narrow the intra-class diversities in the representation feature space. Fourth, by introducing the theory of entropy maximization, the probability distribution of clusters is pushed closer to a uniform distribution to solve the trivial solution problem.
In summary, the major contributions of this paper are:
An end-to-end clustering network model is proposed to jointly learn representations and cluster assignments while preventing the network from falling into trivial solutions.
An extended MI method is proposed. It calculates the MI between features from multiple views of the same image, forcing the instance-level feature to capture invariant essential information and thus reducing the intra-class diversities in the representation feature space.
The rest of this paper is organized as follows. In
Section 2, some related works on deep clustering and mutual information are outlined.
Section 3 introduces the proposed method.
Section 4 discusses the experimental results of DCSM, and
Section 5 concludes our proposed method.
4. Experiments
In this section, the effectiveness of DCSM is demonstrated on four image datasets through experiments. Furthermore, five ablation experiments are performed to systematically and comprehensively analyze the developed DCSM model. All experiments are implemented on a PC machine installed in a 64-bit operating system with two Nvidia GeForce GTX 1080 Ti GPUs with 8-GB video memory.
4.1. Datasets
This paper selects four representative image datasets for clustering, including CIFAR10, MNIST, STL-10 and Imagenet10. As a common setting [
29,
35], for each dataset, the training and test sets are jointly used in our experiments. For clarity,
Table 1 reports the details of each dataset, such as the number of categories, the number of samples and so on.
4.2. Evaluation Metrics
For a complete comparison, this paper employs three clustering metrics to evaluate the clustering performance, i.e., Normalized Mutual Information (NMI), Adjusted Rand Index (ARI) and clustering Accuracy (ACC). In addition, these metrics range in [0,1], and higher scores indicate better clustering results.
4.3. Experimental Settings
The backbone network architecture used in our model is VGG, and ReLU activation is used on all hidden layers. The reason why we use ReLU activation is that it overcomes the vanishing gradient problem, allowing models to learn faster and perform better. Both the class-level mapping block and the instance-level mapping block are fully connected networks, and their output layer dimensions are set to 10 and 30, respectively. For the local MI objective, the global representation is concatenated with the feature map at each location. A 1 × 1 convolutional discriminator is then used to score the pair. The network parameters are optimized using Adam [
45], and the learning rate is set to 0.001. The batch size of STL10, ImageNet-10, Cifar10 and MNIST is all 32. The number of training repetitions for each batch of MNIST is 4, and the for rest of the datasets, it is 8. The small perturbations used in the experiments include rotation, shift, color adjustment and so on. The setting of the remaining three hyperparameters is given in
Table 2.
4.4. Compared Methods
In the experiment, both traditional and deep learning-based methods are compared, including K-means, SC, AE, DAE, GAN, DECNN, VAE, DEC [
37], JULE [
34], DAC [
26], DCCM [
27], IIC [
28], ICGAM [
36] and EDCN [
25]. DCSM-oc is a version of our model that uses only class-level map blocks.
4.5. Results and Analysis
In
Table 3, the quantitative clustering results of the compared methods on four image datasets are orderly reported. From
Table 3, our DCSM method consistently achieves superior performance on different datasets, which empirically signifies that DCSM is in a position to cluster data effectively. From further analysis, several tendencies can be observed in
Table 3.
First, the performance of the clustering methods based on deep learning is generally superior to the traditional methods (e.g., K-means, SC). It shows that representation learning is more important than clustering techniques for unsupervised learning.
Second, the methods (e.g., DEC, DAC) of joint representation learning and cluster assignment outperform traditional methods and the representation-based clustering methods. It indicates that clustering and representation learning can promote each other and achieve better performance consequently.
Third, the performance of DCCM and IIC using the data augmentation technique is better than other algorithms. It means that the introduction of the data augmentation technique in unsupervised clustering can help the model to be optimized.
Besides of these common conclusions, our DCSM method outperforms methods that only use class-level representation (e.g., DCSM-oc, DCCM). It means that the clustering performance is related to both class-level representation and instance-level representation.
Figure 2 visualizes the confusion matrix on the MNIST and Imagenet10 datasets.
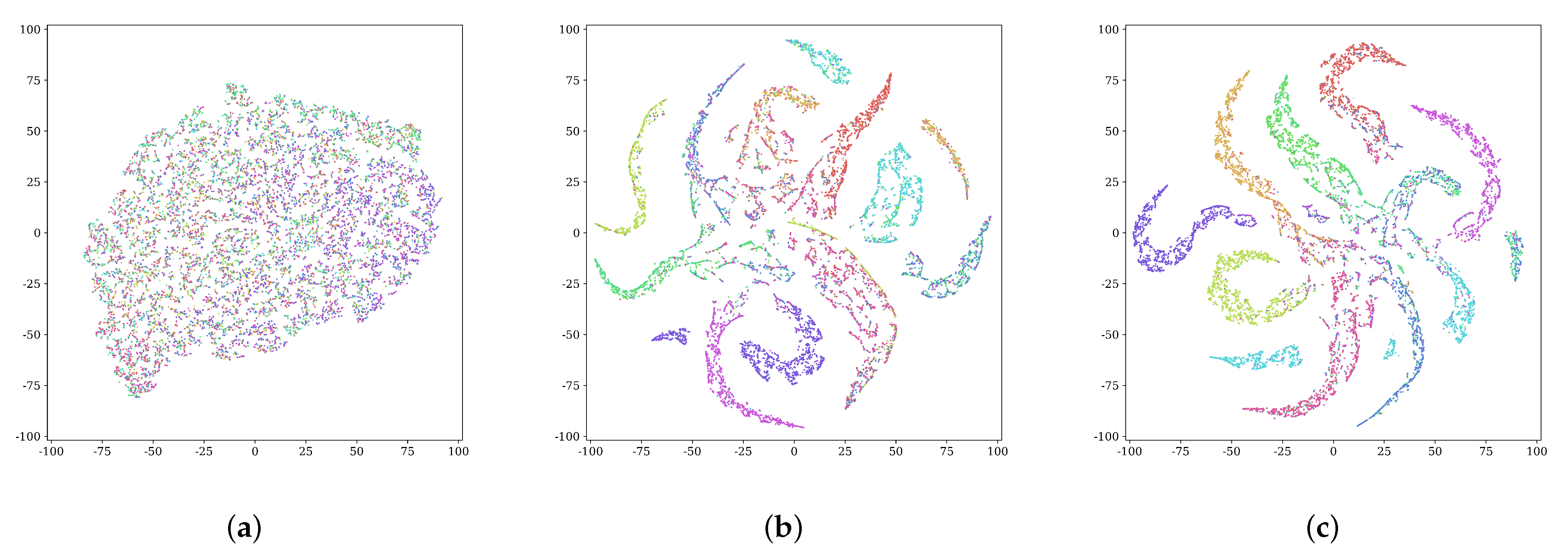
Figure 3 visualizes the class-level representations of the DCSM on the ImageNet10 datasets using t-SNE at the different training stages.
4.6. Ablation Study
In this section, to further verify the performance of our model, five additional ablation experiments are performed.
The influence of different strategies to construct
. The
constructed by the high threshold in DCCM and constructed by the K-means in this paper are used to guide the training of the two identical networks on Stl-10 datasets. The results are shown in
Table 4. It can be seen that our strategy has enough advantages, indicating that K-means is a better alternative solution than the threshold.
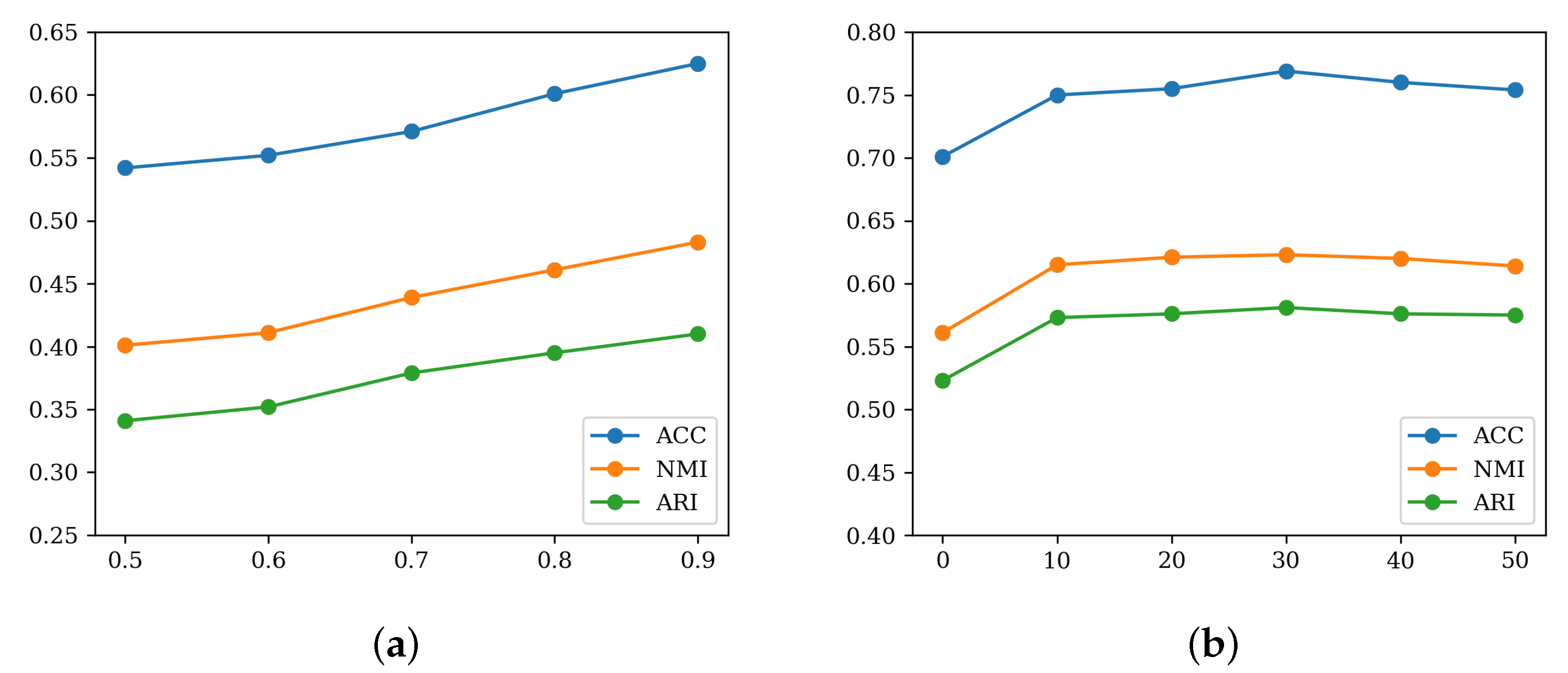
Impact of threshold. The clustering performance of STL-10 datasets under different thresholds in Equation (
2) is displayed in
Figure 4a. For STL-10, the clustering performance increases gradually as the threshold increases. It indicates that the correct rate of the selected cluster-standard samples is also gradually increasing.
The dimensional impact of
. As shown in
Figure 4b, varying the dimension of
z from 10 to 50 does not affect the clustering performance much. However, when the dimension of
z becomes 0, which means that the network only learns class-level representations, the performance drops a lot. The reason is that class-level representation alone is not enough to describe the differences between images belonging to the same cluster. A good clustering model should assign data to clusters to keep inter-group similarity low while maintaining high intra-group similarity.
The sensitivity of the model to mutual information. For convenience, the mutual information loss
is divided into two parts: the global-local MI
and the local-local MI
. To comprehensively examine the effect of global-local and local-local MI on the clustering performance of the model,
was changed to
and
, respectively. The experimental results are shown in
Table 5. From the results, the two parts of MI have similar performances in improving the clustering performance. It also proves our proposed extended mutual information is reasonable.
The impact of each part. In the case of the combination of each part, the clustering performance is shown in
Table 6. Due to the lack of
loss, the network will have unstable results, so the maximum entropy loss is not removed in this part. It can be found that it is very effective to use cluster-standard samples to correct the network parameters.







{kind=link}
{kind=link}
{kind=link}
{kind=link}