
Combining Standard Artificial Intelligence Models, Pre-Processing Techniques, and Post-Processing Methods to Improve the Accuracy of Monthly Runoff Predictions in Karst-Area Watersheds
 ,
,
Abstract
:1. Introduction
2. Study Area and Data Source
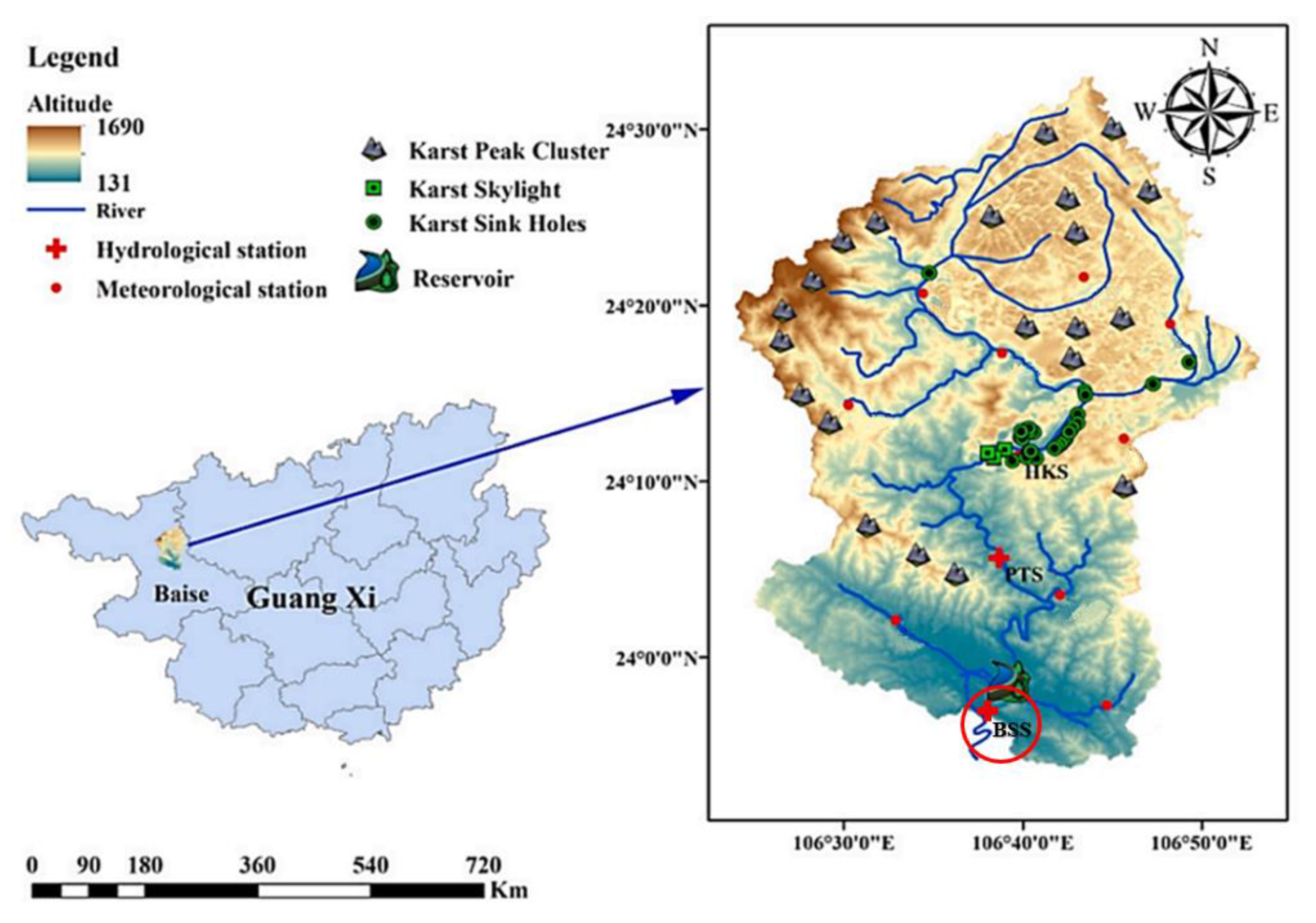
2.1. Study Area
2.2. Data Source
3. Methodology and Comparative Experimental Setup
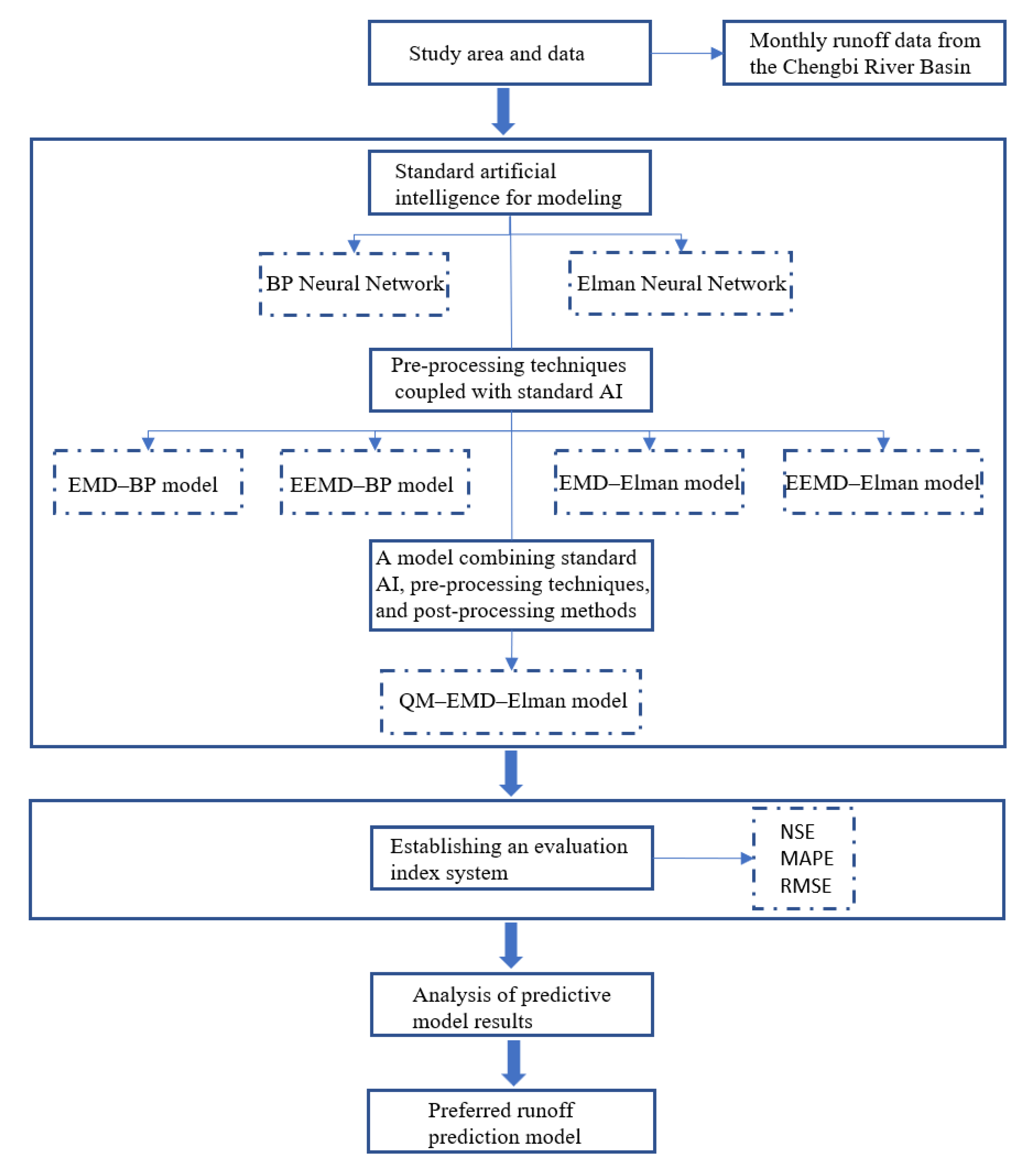
3.1. Methodology
3.1.1. Decomposition Method for Data Pre-Processing
- Empirical Mode Decomposition;
- (1)
- The number of zero-crossing points minus the number of extreme points ≤ 1 for all signals.
- (2)
- The average value of the upper and lower envelopes is 0 at every point.
- Ensemble Empirical Mode Decomposition;
- (1)
- Adding white noise () to the original signal ():
- (2)
- Adding noise to I, followed by EMD decomposition:
- (3)
- Repeat the above two steps by adding white noise to the original signal and performing EMD decomposition.
- (4)
- After m times of repeated decomposition, the results are mean-valued. The specific operation is to mean-value the same-order IMFs and trend items, respectively, to obtain the final IMF and trend item.
- (5)
- Finally, the actual-signal EEMD decomposition results are obtained:
3.1.2. Standard Artificial Intelligence for Modeling
- BP Neural Network;
- (1)
- Error function definition
- (2)
- Output layer weight change
- (3)
- Implied weight changewhere is the implicit layer weight.
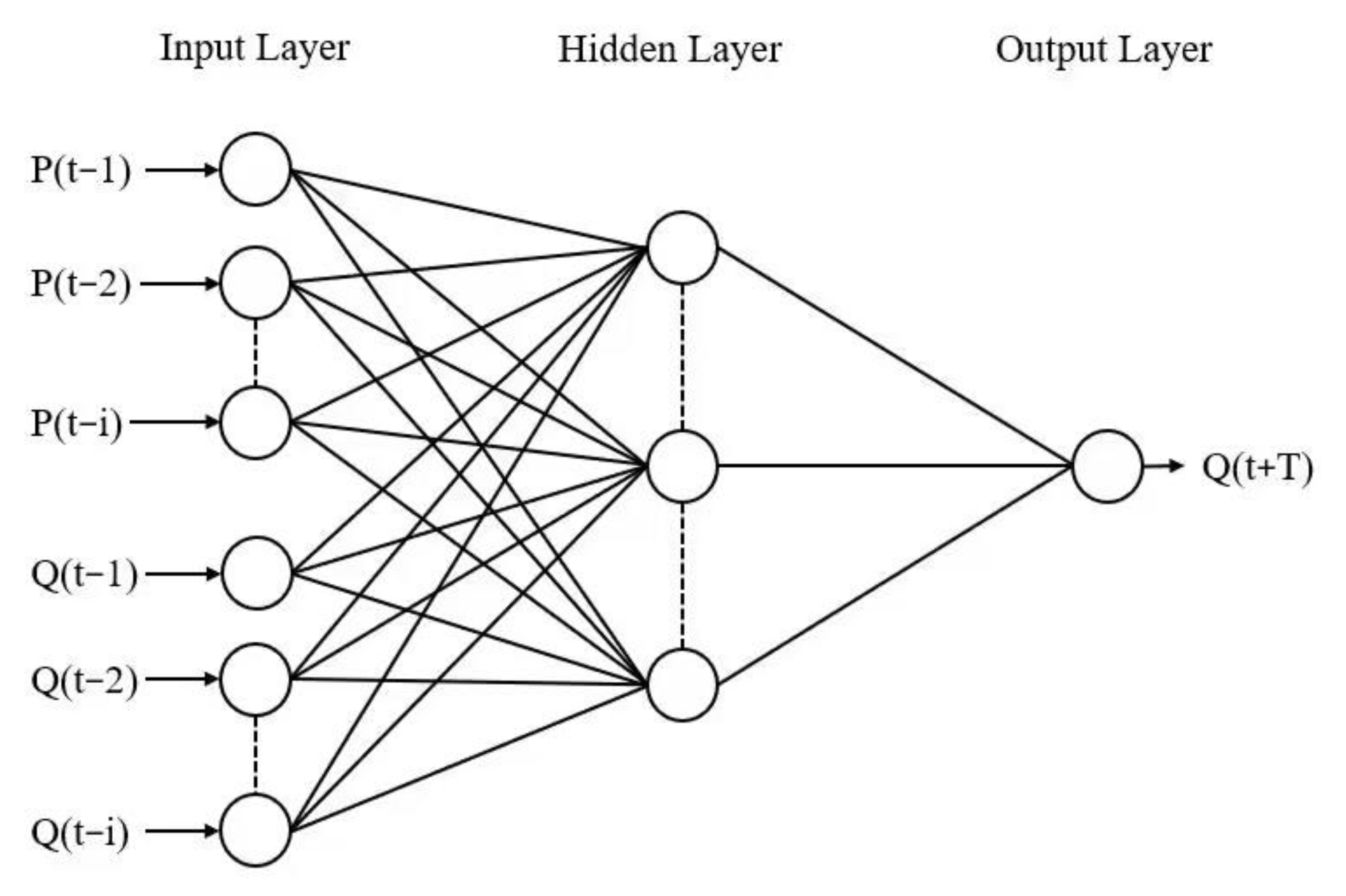
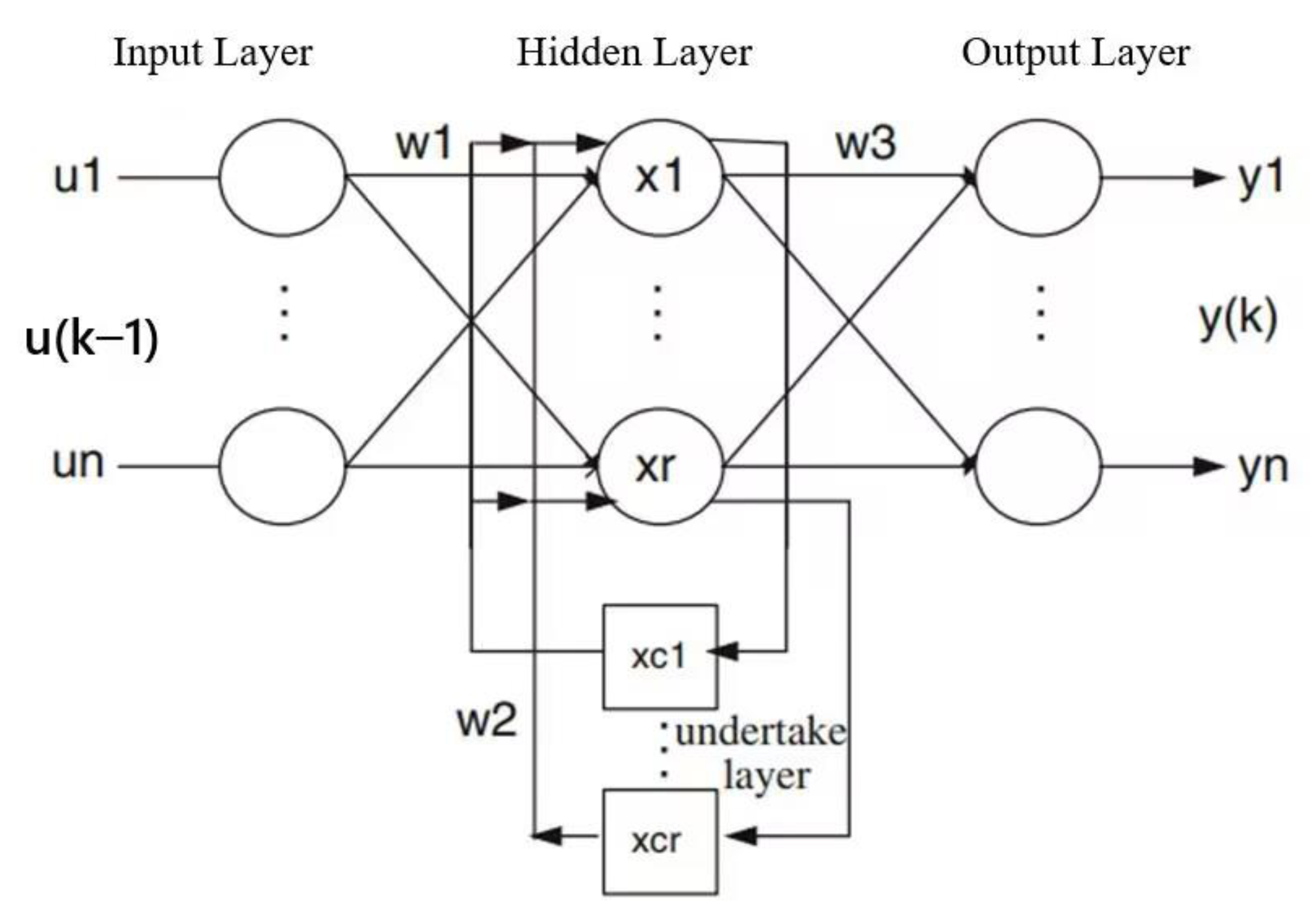
- Elman Neural Network;
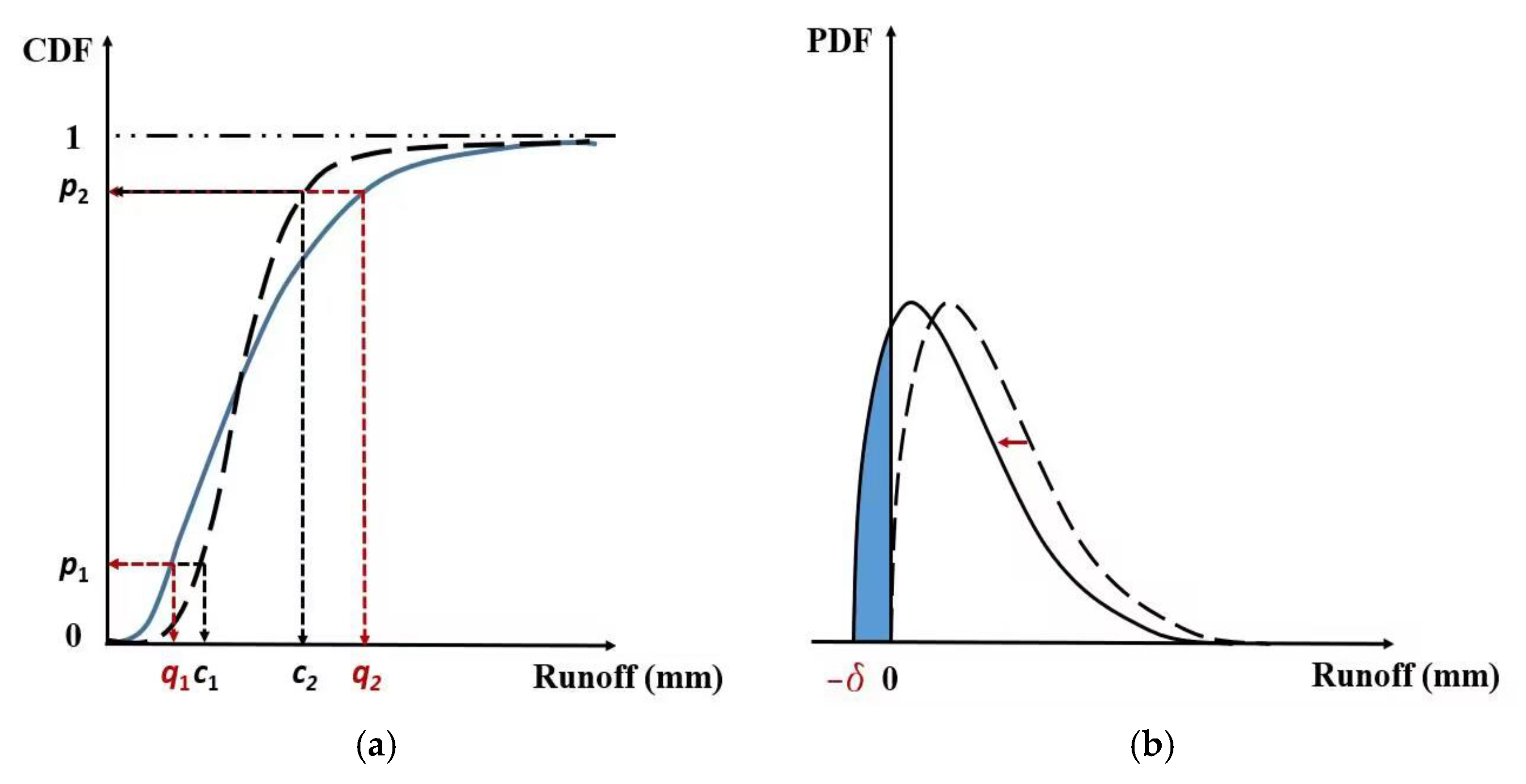
3.1.3. Quantile Mapping for Post-Processing
3.2. Comparative Experimental Setup
3.2.1. Experimental Setup
3.2.2. Evaluation Metrics
4. Results and Analysis
4.1. Performance Investigation of Traditional Models
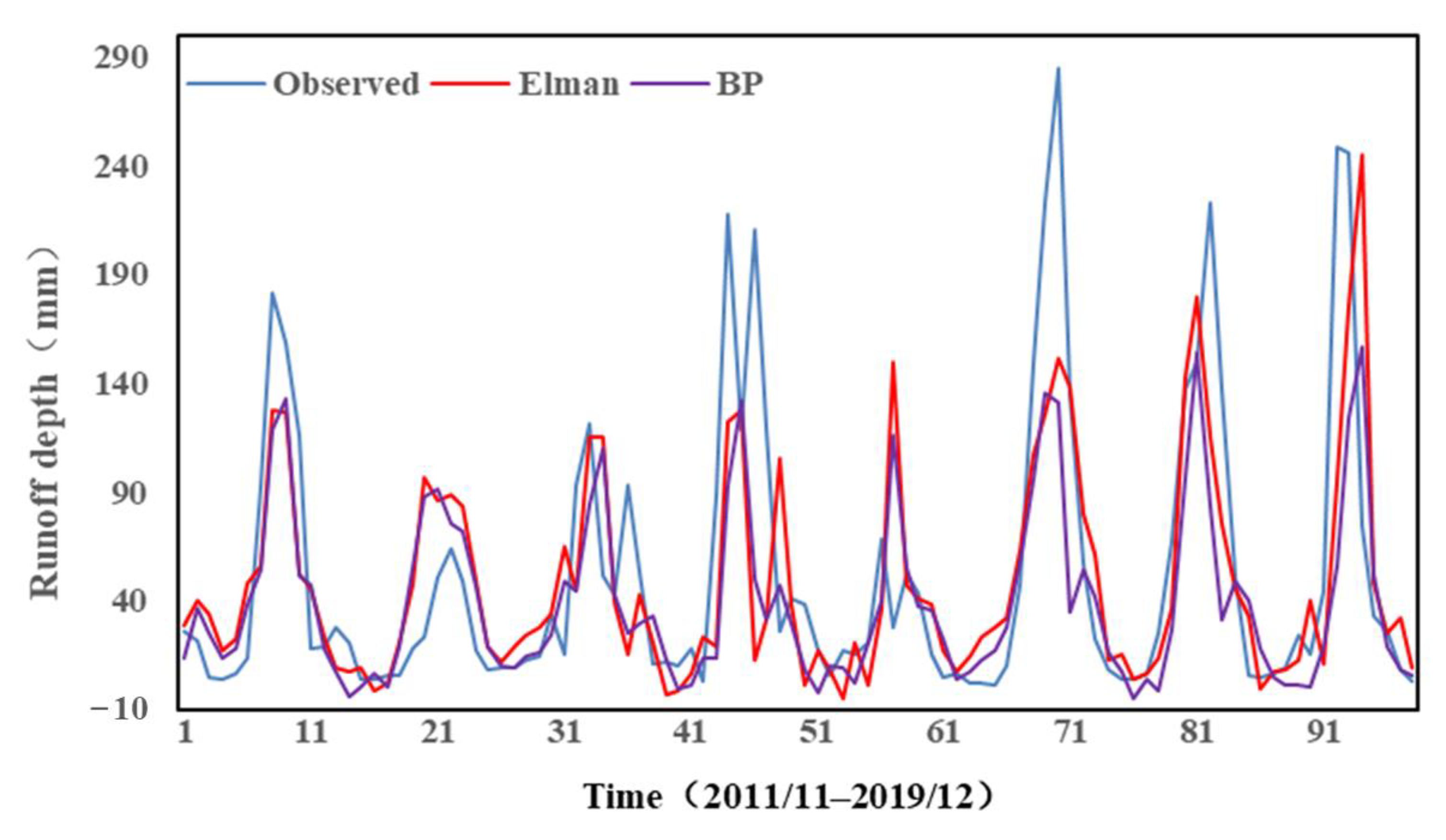
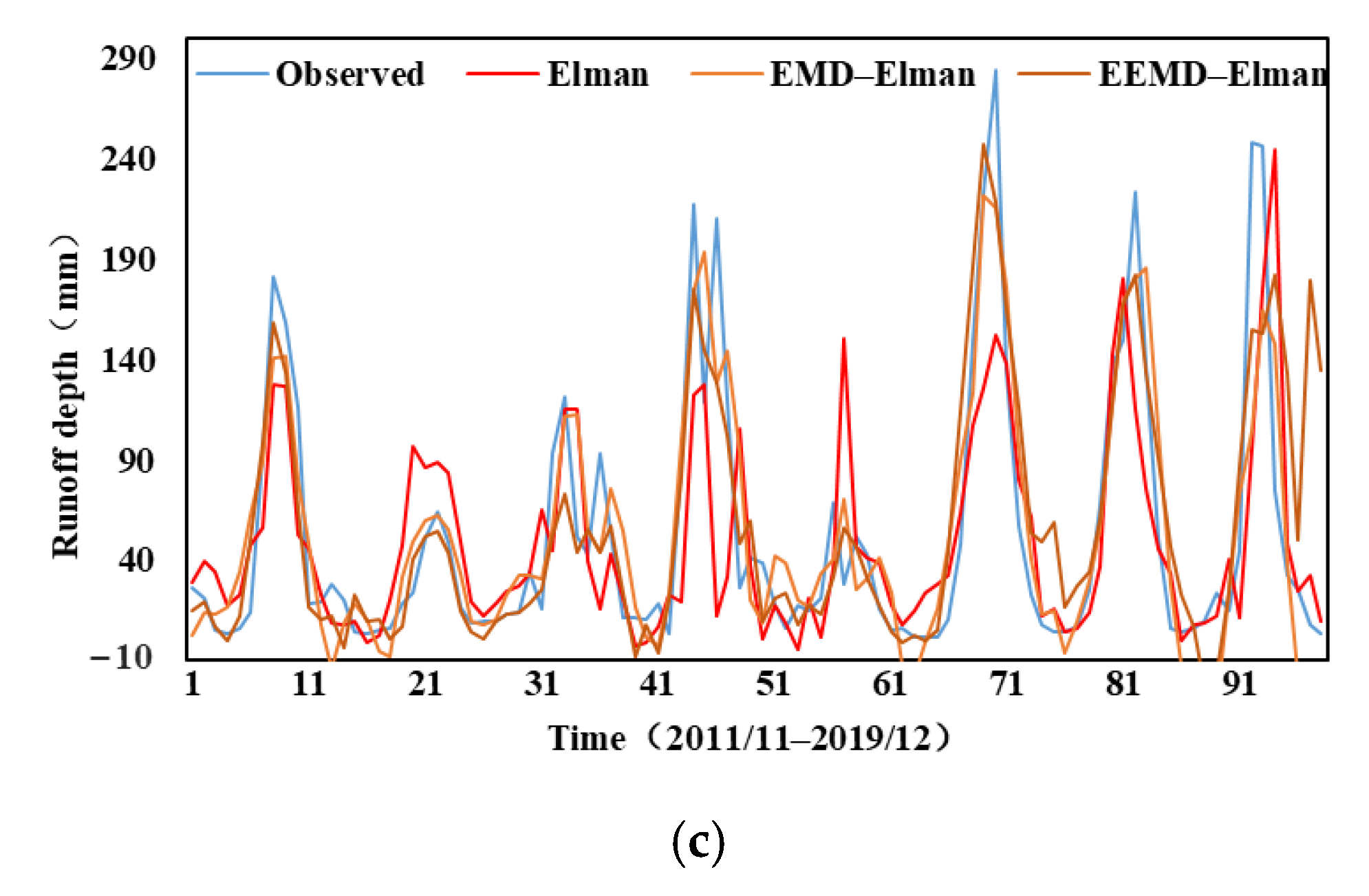
4.1.1. Results of Standard Artificial Intelligence Models
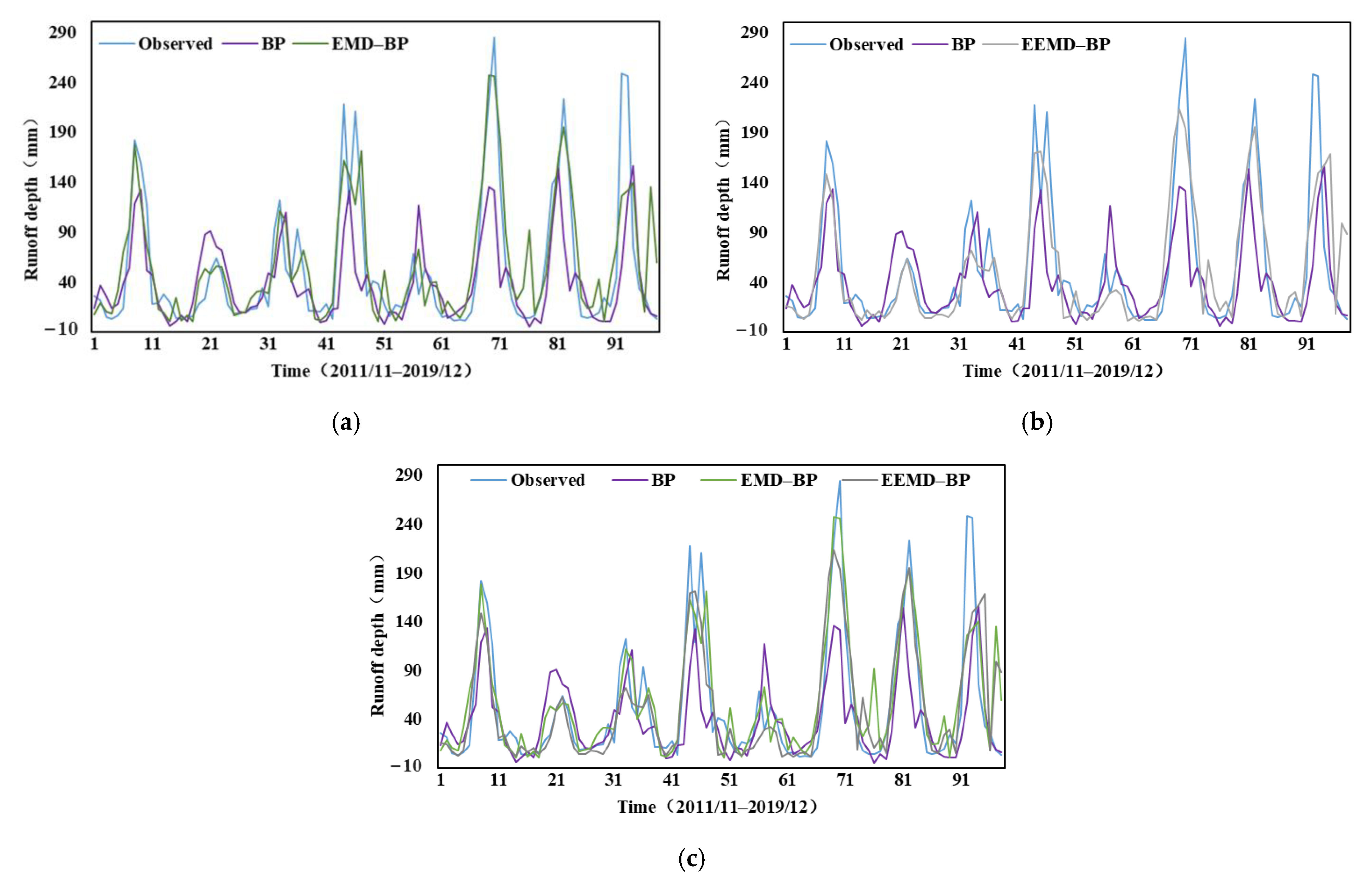
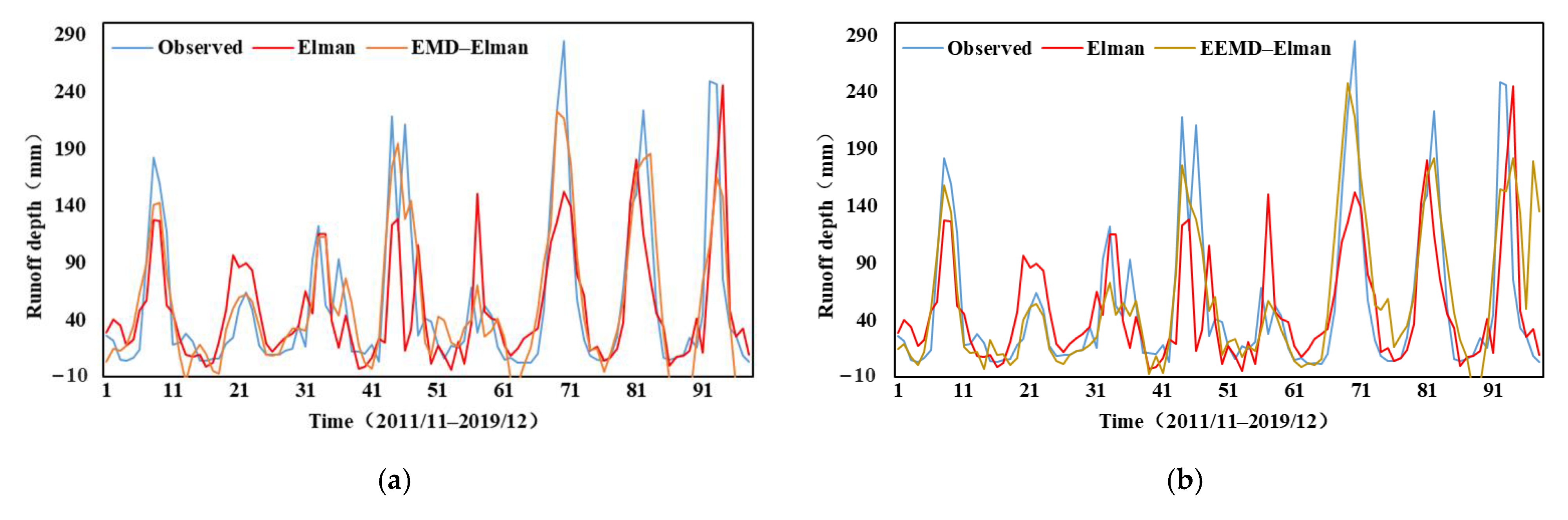
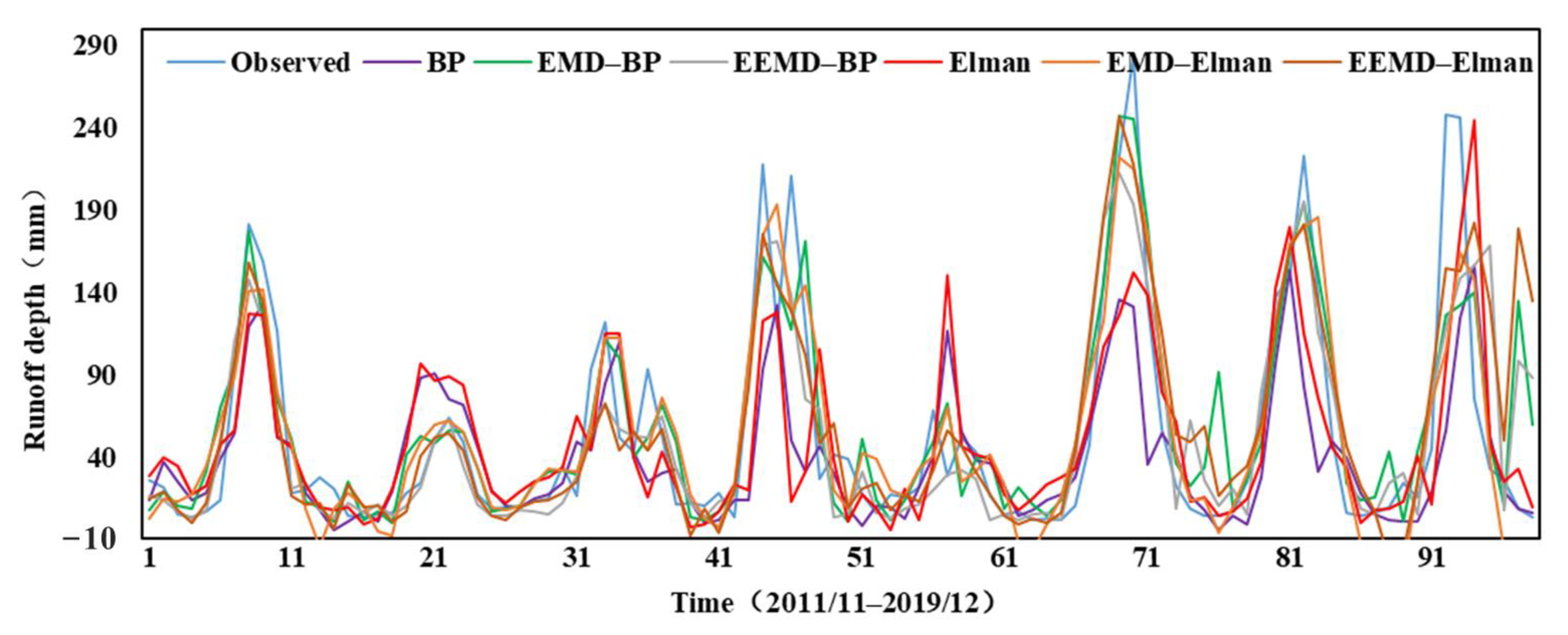
4.1.2. Results of Standard AI Models Combined with Pre-Processing Techniques
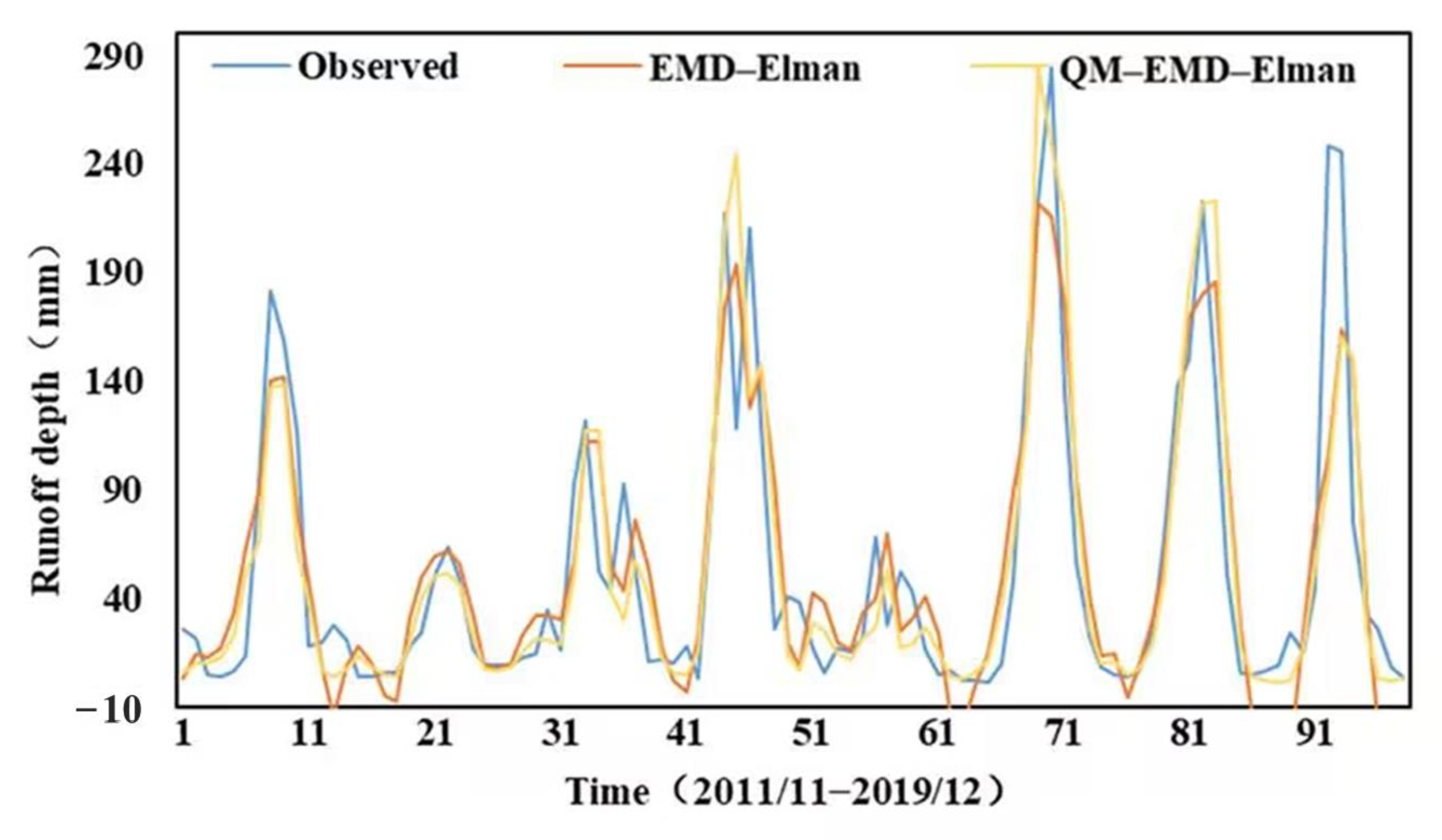
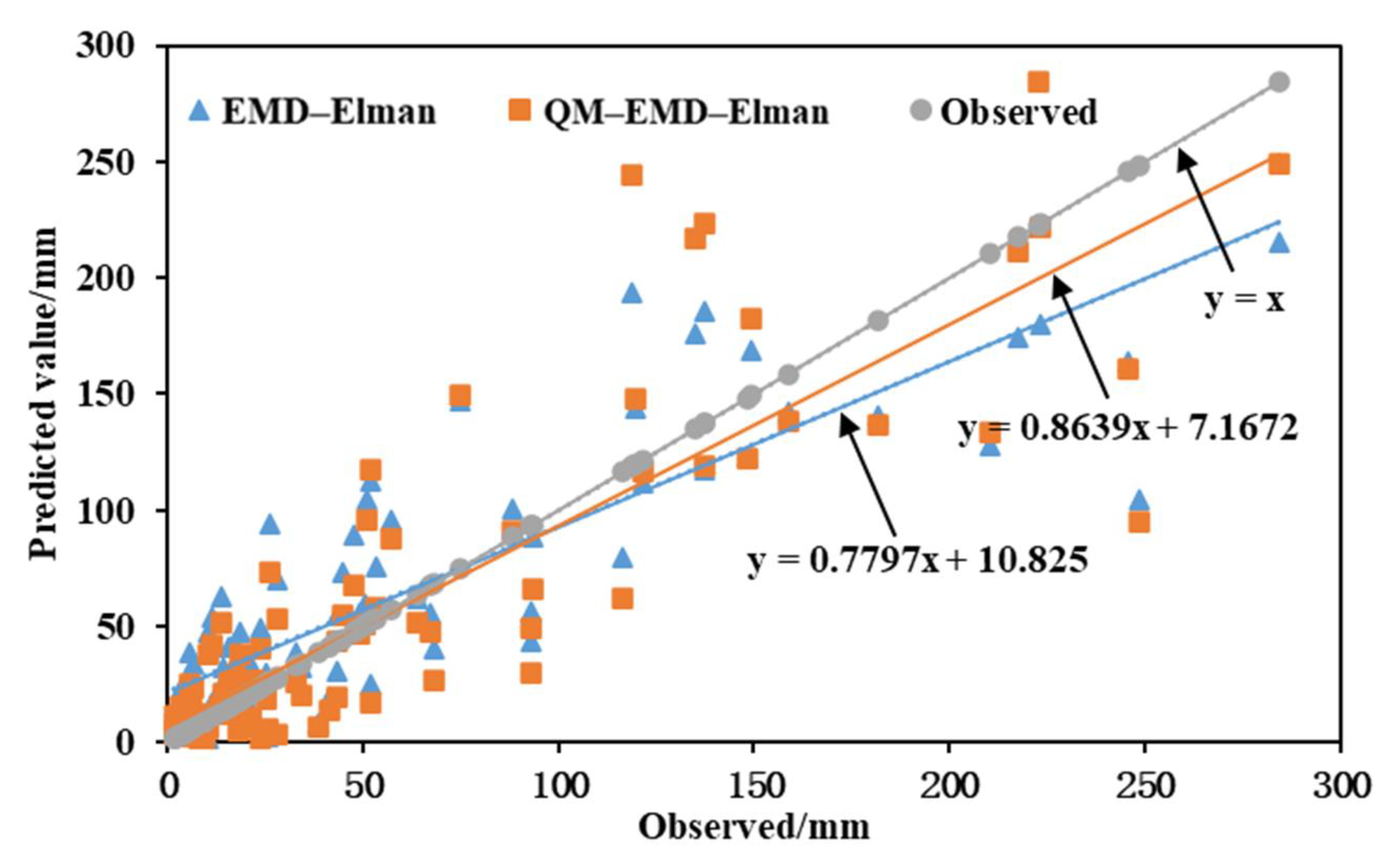
4.2. Performance Investigation of Standard AI Models Combined with Pre-Processing Techniques and Post-Processing Methods
5. Discussion
5.1. Similarities and Differences
5.2. Policy Recommendations
5.3. Innovation, Limitations, and Further Research
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Sterling, S.M.; Ducharne, A.; Polcher, J. The impact of global land-cover change on the terrestrial water cycle. Nat. Clim. Chang. 2013, 3, 385–390. [Google Scholar] [CrossRef]
- Yuan, X.; Ji, B.; Zhang, S.; Tian, H.; Chen, Z. An improved artificial physical optimization algorithm for dynamic dispatch of generators with valve-point effects and wind power. Energy Convers. Manag. 2014, 82, 92–105. [Google Scholar] [CrossRef]
- Li, L.; Tan, X. Big-Data-Driven Intelligent Wireless Network and Use Cases. In Proceedings of the IEEE International Conference on Communications (ICC), Online, 14–23 June 2021. [Google Scholar]
- Hunt, K.M.R.; Matthews, G.R.; Pappenberger, F.; Prudhomme, C. Using a long short-term memory (LSTM) neural network to boost river streamflow forecasts over the western United States. Hydrol. Earth Syst. Sci. 2022, 26, 5449–5472. [Google Scholar] [CrossRef]
- Sharifi, A.; Dinpashoh, Y.; Mirabbasi, R. Daily runoff prediction using the linear and non-linear models. Water Sci. Technol. 2017, 76, 793–805. [Google Scholar] [CrossRef] [PubMed]
- Li, C.; Zhu, L.; He, Z.; Gao, H.; Yang, Y.; Yao, D.; Qu, X. Runoff Prediction Method Based on Adaptive Elman Neural Network. Water 2019, 11, 1113. [Google Scholar] [CrossRef] [Green Version]
- Peng, T.; Zhou, J.; Zhang, C.; Fu, W. Streamflow Forecasting Using Empirical Wavelet Transform and Artificial Neural Networks. Water 2017, 9, 406. [Google Scholar] [CrossRef] [Green Version]
- Yuan, X.; Chen, C.; Lei, X.; Yuan, Y.; Adnan, R.M. Monthly runoff forecasting based on LSTM–ALO model. Stoch. Environ. Res. Risk Assess. 2018, 32, 2199–2212. [Google Scholar] [CrossRef]
- Qu, B.; Zhang, X.; Pappenberger, F.; Zhang, T.; Fang, Y. Multi-Model Grand Ensemble Hydrologic Forecasting in the Fu River Basin Using Bayesian Model Averaging. Water 2017, 9, 74. [Google Scholar] [CrossRef]
- Bogner, K.; Liechti, K.; Zappa, M. Post-Processing of Stream Flows in Switzerland with an Emphasis on Low Flows and Floods. Water 2016, 8, 115. [Google Scholar] [CrossRef] [Green Version]
- Hartmann, A.; Goldscheider, N.; Wagener, T.; Lange, J.; Weiler, M. Karst water resources in a changing world: Review of hydrological modeling approaches. Rev. Geophys. 2014, 52, 218–242. [Google Scholar] [CrossRef]
- Zhou, Q.; Chen, L.; Singh, V.P.; Zhou, J.; Chen, X.; Xiong, L. Rainfall-runoff simulation in karst dominated areas based on a coupled conceptual hydrological model. J. Hydrol. 2019, 573, 524–533. [Google Scholar] [CrossRef]
- Niu, W.-J.; Feng, Z.-K. Evaluating the performances of several artificial intelligence methods in forecasting daily streamflow time series for sustainable water resources management. Sustain. Cities Soc. 2021, 64, 102562. [Google Scholar] [CrossRef]
- Meng, X.; Yin, M.; Ning, L.; Liu, D.; Xue, X. A threshold artificial neural network model for improving runoff prediction in a karst watershed. Environ. Earth Sci. 2015, 74, 5039–5048. [Google Scholar] [CrossRef]
- An, L.; Hao, Y.; Yeh, T.-C.J.; Liu, Y.; Liu, W.; Zhang, B. Simulation of karst spring discharge using a combination of time–frequency analysis methods and long short-term memory neural networks. J. Hydrol. 2020, 589, 125320. [Google Scholar] [CrossRef]
- Siou, L.K.A.; Johannet, A.; Borrell, V.; Pistre, S. Complexity selection of a neural network model for karst flood forecasting: The case of the Lez Basin (southern France). J. Hydrol. 2011, 403, 367–380. [Google Scholar] [CrossRef] [Green Version]
- Mo, C.; Liu, G.; Lei, X.; Zhang, M.; Ruan, Y.; Lai, S.; Xing, Z. Study on the Optimization and Stability of Machine Learning Runoff Prediction Models in the Karst Area. Appl. Sci. 2022, 12, 4979. [Google Scholar] [CrossRef]
- Zhao, Y.; Liao, W.; Lei, X. Hydrological Simulation for Karst Mountain Areas: A Case Study of Central Guizhou Province. Water 2019, 11, 991. [Google Scholar] [CrossRef] [Green Version]
- Fleury, P.; Plagnes, V.; Bakalowicz, M. Modelling of the functioning of karst aquifers with a reservoir model: Application to Fontaine de Vaucluse (South of France). J. Hydrol. 2007, 345, 38–49. [Google Scholar] [CrossRef]
- Palanisamy, B.; Workman, S.R. Hydrologic Modeling of Flow through Sinkholes Located in Streambeds of Cane Run Stream, Kentucky. J. Hydrol. Eng. 2015, 20, 04014066. [Google Scholar] [CrossRef]
- Nikolaidis, N.; Bouraoui, F.; Bidoglio, G. Hydrologic and geochemical modeling of a karstic Mediterranean watershed. J. Hydrol. 2013, 477, 129–138. [Google Scholar] [CrossRef]
- Sun, S.; Deng, H.; Wang, Q. Simulation and comparative study of two types of Topographic Index model for a homogeneous mountain catchment. Sci. China Earth Sci. 2014, 57, 2089–2099. [Google Scholar] [CrossRef]
- Campbell, C.; Sullivan, S.M. Simulating time-varying cave flow and water levels using the Storm Water Management Model. Eng. Geol. 2002, 65, 133–139. [Google Scholar] [CrossRef]
- Dvory, N.Z.; Ronen, A.; Livshitz, Y.; Adar, E.; Kuznetsov, M.; Yakirevich, A. Quantification of Groundwater Recharge from an Ephemeral Stream into a Mountainous Karst Aquifer. Water 2018, 10, 79. [Google Scholar] [CrossRef] [Green Version]
- Mo, C.; Ruan, Y.; Xiao, X.; Lan, H.; Jin, J. Impact of climate change and human activities on the baseflow in a typical karst basin, Southwest China. Ecol. Indic. 2021, 126, 107628. [Google Scholar] [CrossRef]
- Feng, Z.-K.; Niu, W.-J.; Tang, Z.-Y.; Jiang, Z.-Q.; Xu, Y.; Liu, Y.; Zhang, H.-R. Monthly runoff time series prediction by variational mode decomposition and support vector machine based on quantum-behaved particle swarm optimization. J. Hydrol. 2020, 583, 124627. [Google Scholar] [CrossRef]
- Meng, E.; Huang, S.; Huang, Q.; Fang, W.; Wu, L.; Wang, L. A robust method for non-stationary streamflow prediction based on improved EMD-SVM model. J. Hydrol. 2018, 568, 462–478. [Google Scholar] [CrossRef]
- Huang, N.E.; Shen, Z.; Long, S.R.; Wu, M.C.; Shih, H.H.; Zheng, Q.; Yen, N.-C.; Tung, C.C.; Liu, H.H. The empirical mode decomposition and the Hilbert spectrum for nonlinear and non-stationary time series analysis. Proc. R. Soc. Lond. Ser. A Math. Phys. Eng. Sci. 1998, 454, 903–995. [Google Scholar] [CrossRef]
- Chang, M.P.J.L.; Roura, E.A.; Font, C.O.; Gilbreath, C.; Oh, E. Applying the Hilbert-Huang decomposition to horizontal light propagation Cn2 data. In Proceedings of the Conference on Advances in Stellar Interferometry, Orlando, FL, USA, 25–30 May 2006. [Google Scholar] [CrossRef] [Green Version]
- Feng, Z.-K.; Niu, W.-J.; Wan, X.-Y.; Xu, B.; Zhu, F.-L.; Chen, J. Hydrological time series forecasting via signal decomposition and twin support vector machine using cooperation search algorithm for parameter identification. J. Hydrol. 2022, 612, 128213. [Google Scholar] [CrossRef]
- Zheng, J.; Cheng, J.; Yang, Y. Partly Ensemble Local Characteristic-Scale Decomposition: A New Noise Assisted Data Analysis Method. Acta Electron. Sin. 2013, 41, 1030–1035. [Google Scholar]
- Wang, W.-C.; Chau, K.-W.; Xu, D.-M.; Chen, X.-Y. Improving Forecasting Accuracy of Annual Runoff Time Series Using ARIMA Based on EEMD Decomposition. Water Resour. Manag. 2015, 29, 2655–2675. [Google Scholar] [CrossRef]
- McClelland, J.L.; Rumelhart, D.E. Distributed memory and the representation of general and specific information. J. Exp. Psychol. Gen. 1985, 114, 159–197. [Google Scholar] [CrossRef] [PubMed]
- Cui, D. Application of Hidden Multilayer BP Neural Network Model in Runoff Prediction. Hydrology 2013, 33, 68–73. [Google Scholar]
- Cheng, Y.-C.; Qi, W.-M.; Zhao, J. A New Elman Neural Network and Its Dynamic Properties. In Proceedings of the IEEE International Conference on Cybernetic Intelligent Systems (CIS 2008), Chengdu, China, 21–24 September 2008; pp. 261–265. [Google Scholar]
- Ding, S.; Zhang, Y.; Chen, J.; Jia, W. Research on using genetic algorithms to optimize Elman neural networks. Neural Comput. Appl. 2012, 23, 293–297. [Google Scholar] [CrossRef]
- Guo, Q.; Chen, J.; Zhang, X.; Shen, M.; Chen, H.; Guo, S. A new two-stage multivariate quantile mapping method for bias correcting climate model outputs. Clim. Dyn. 2019, 53, 3603–3623. [Google Scholar] [CrossRef]
- Cannon, A.J.; Sobie, S.R.; Murdock, T.Q. Bias Correction of GCM Precipitation by Quantile Mapping: How Well Do Methods Preserve Changes in Quantiles and Extremes? J. Clim. 2015, 28, 6938–6959. [Google Scholar] [CrossRef]
- Knoben, W.J.M.; Freer, J.E.; Woods, R.A. Technical note: Inherent benchmark or not? Comparing Nash–Sutcliffe and Kling–Gupta efficiency scores. Hydrol. Earth Syst. Sci. 2019, 23, 4323–4331. [Google Scholar] [CrossRef] [Green Version]
- Zuo, G.; Luo, J.; Wang, N.; Lian, Y.; He, X. Decomposition ensemble model based on variational mode decomposition and long short-term memory for streamflow forecasting. J. Hydrol. 2020, 585, 124776. [Google Scholar] [CrossRef]
- Yue, Z.; Ai, P.; Xiong, C.; Song, Y.; Hong, M.; Yu, J. Mid- and long-term runoff forecasting based on improved deep belief networks model. J. Hydroelectr. Eng. 2020, 39, 33–46. [Google Scholar]
- Zuo, G.; Luo, J.; Wang, N.; Lian, Y.; He, X. Two-stage variational mode decomposition and support vector regression for streamflow forecasting. Hydrol. Earth Syst. Sci. 2020, 24, 5491–5518. [Google Scholar] [CrossRef]
- GB/T 22482-2008; Standard for Hydrological Information and Hydrological Forecasting. Standardization Administration of China: Beijing, China, 2008; p. 16.
- He, R.-R.; Chen, Y.; Huang, Q.; Pan, Z.-W.; Liu, Y. Predictability of Monthly Streamflow Time Series and its Relationship with Basin Characteristics: An Empirical Study Based on the MOPEX Basins. Water Resour. Manag. 2020, 34, 4991–5007. [Google Scholar] [CrossRef]
- Sapankevych, N.I.; Sankar, R. Time Series Prediction Using Support Vector Machines: A Survey. IEEE Comput. Intell. Mag. 2009, 4, 24–38. [Google Scholar] [CrossRef]
- Stevanović, Z. Karst waters in potable water supply: A global scale overview. Environ. Earth Sci. 2019, 78, 662. [Google Scholar] [CrossRef]
- Liu, D.; Ge, L.; Xu, Y.; Zhang, S.; Chiang, Y. Flood prediction by multi-hydrological models with forecasting ability analysis. J. Zhejiang Univ. Eng. Sci. 2021, 55, 1010–1018. [Google Scholar]
- Liu, J.; Li, T.; Fu, J.; Wu, N. Criteria algorithm for smart substation recorder starting based on BP & Elman neural network. Power Syst. Prot. Control 2014, 42, 110–115. [Google Scholar]
- Zhao, X.-H.; Chen, X. Auto Regressive and Ensemble Empirical Mode Decomposition Hybrid Model for Annual Runoff Forecasting. Water Resour. Manag. 2015, 29, 2913–2926. [Google Scholar] [CrossRef]
- Sibtain, M.; Li, X.; Bashir, H.; Azam, M.I. A Hybrid Model for Runoff Prediction Using Variational Mode Decomposition and Artificial Neural Network. Water Resour. 2021, 48, 701–712. [Google Scholar] [CrossRef]
- Parvaze, S.; Khan, J.N.; Kumar, R.; Allaie, S.P. Temporal flood forecasting for trans-boundary Jhelum River of Greater Himalayas. Arch. Meteorol. Geophys. Bioclimatol. Ser. B 2021, 144, 493–506. [Google Scholar] [CrossRef]
- Jin, J.; Shu, Z.; Chen, M.; Wang, G.; Sun, Z.; He, R. Meteo-hydrological coupled runoff forecasting based on numerical weather prediction products. Adv. Water Sci. 2019, 30, 316–325. [Google Scholar]
- Chitsaz, N.; Azarnivand, A.; Araghinejad, S. Pre-processing of data-driven river flow forecasting models by singular value decomposition (SVD) technique. Hydrol. Sci. J. 2016, 61, 2164–2178. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Classification | Name | Author | Improvements | Advantages and Disadvantages |
|---|---|---|---|---|
| Lumped hydrological model | Xin’anjiang | Zhao et al. [18] | The conversion of surface flow to underground flow in karst areas of Central Guizhou Province was simulated. | Advantages: The Xin’anjiang model is simple in structure and fast in calculation. The Tank model overcomes to some extent the problems caused by turbulent flow in karst basins. Disadvantages: These models generally use empirical or lumped generalizations to describe runoff processes, the physical meaning of the parameters in the models is not clear, and the groundwater conditions in hydrological simulations using these models for karst basins may not match reality. |
| Tank | Fleury et al. [19] | Used three interconnected tanks to represent the spatial layer structure of the karst water-bearing medium and simulated groundwater at different velocity. Application to Fontaine de Vaucluse (southern France). | ||
| Distributed hydrological model | SWAT | Palanisamy et al. [20] | The sinkhole diameter function was developed based on the flow through the sinkhole orifices in the streambed of the Kentucky karst basin. The function was added to the SWAT model to form a karst SWAT model. | Advantages: easy acquisition of data and high calculation efficiency. Ability to simulate different hydrological processes in large complex basins using spatial information provided by GIS and RS. Disadvantages: The SWAT model is difficult to use for short-term hydrological simulations; the model is based on the properties of loose media, which does not represent the characteristics of karst basins well; and there are limitations in the hydrological simulation of karst basins. |
| Nikolaidis et al. [21] | Modified the input flows to the SWAT model for deep groundwater. | |||
| TOPMODEL | Sun et al. [22] | Used the TOPMODEL model to carry out simulations of two topographic index models for homogeneous mountainous regions in the Suomo Basin. | Advantages: the model can be used for calculations in watersheds where no information is available, with a simple structure and fewer parameters. Disadvantages: due to complex topography in karst areas, karst water systems generated by the DEM model may not match reality. | |
| SWMM | Campbell et al. [23] | Used SWMM to simulate the flow process of water in karst in Stephens gap cave. | Advantages: It reflect a more realistic process of the flood waves through the pipeline. Disadvantages: SWMM is sensitive to the geometric features of the pipeline, and when applied to karst basins, it does not take into account the water exchange between the pipeline and the aquifer; and the physical mechanism needs to be improved. | |
| HEC-HMS | Dvory et al. [24] | Used the reservoir unit method to simulate the stagnation of water flow in karst basins. | Advantages: The model has good accuracy and is able to take into account subsurface changes in the study area, and is suitable for the simulation of runoff processes over short time periods. Disadvantages: Need to add the karst storage unit, and simulation results are unstable. |
| Model | NSE | MAPE (%) | RMSE (mm) | PPTS (10) |
|---|---|---|---|---|
| BP | 0.49 | 83.35 | 45.46 | 4.69 |
| Elman | 0.43 | 108.36 | 50.00 | 4.37 |
| Model | NSE | MAPE (%) | RMSE (mm) | PPTS (10) |
|---|---|---|---|---|
| BP | 0.49 | 84.35 | 45.46 | 4.69 |
| EMD–BP | 0.71 | 160.74 | 34.32 | 2.39 |
| EEMD–BP | 0.70 | 117.01 | 36.08 | 2.51 |
| Elman | 0.43 | 108.36 | 50.00 | 4.37 |
| EMD–Elman | 0.72 | 138.53 | 42.76 | 2.40 |
| EEMD–Elman | 0.65 | 166.75 | 38.99 | 2.27 |
| Model | NSE | MAPE (%) | RMSE (mm) | PPTS (10) |
|---|---|---|---|---|
| EMD–Elman | 0.72 | 138.53 | 42.76 | 2.40 |
| QM–EMD–Elman | 0.73 | 74.57 | 34.60 | 2.36 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mo, C.; Jiang, C.; Lei, X.; Lai, S.; Deng, Y.; Cen, W.; Sun, G.; Xing, Z. Combining Standard Artificial Intelligence Models, Pre-Processing Techniques, and Post-Processing Methods to Improve the Accuracy of Monthly Runoff Predictions in Karst-Area Watersheds. Appl. Sci. 2023, 13, 88. https://doi.org/10.3390/app13010088
Mo C, Jiang C, Lei X, Lai S, Deng Y, Cen W, Sun G, Xing Z. Combining Standard Artificial Intelligence Models, Pre-Processing Techniques, and Post-Processing Methods to Improve the Accuracy of Monthly Runoff Predictions in Karst-Area Watersheds. Applied Sciences. 2023; 13(1):88. https://doi.org/10.3390/app13010088
Chicago/Turabian StyleMo, Chongxun, Changhao Jiang, Xingbi Lei, Shufeng Lai, Yun Deng, Weiyan Cen, Guikai Sun, and Zhenxiang Xing. 2023. "Combining Standard Artificial Intelligence Models, Pre-Processing Techniques, and Post-Processing Methods to Improve the Accuracy of Monthly Runoff Predictions in Karst-Area Watersheds" Applied Sciences 13, no. 1: 88. https://doi.org/10.3390/app13010088