
Visual Description Augmented Integration Network for Multimodal Entity and Relation Extraction

 ,
, 
Abstract
:1. Introduction
- (1)
- We employ an image description generation approach to extract key information and global summaries from visual content. The introduction of text features generated from image descriptions helps to reduce the modality gap, enhancing the robustness of MNER and MRE tasks.
- (2)
- We propose a Visual Description Augmented Integration Network for MNER and MRE. By adaptively integrating semantic features obtained from image descriptions with the visual features, the model aims to mitigate the error sensitivity caused by irrelevant features.
- (3)
- VDAIN achieves new state-of-the-art results on three public benchmark tests for MNER and MRE. Comprehensive evaluations confirm the practicality and efficacy of the proposed approach.
2. Materials and Methods
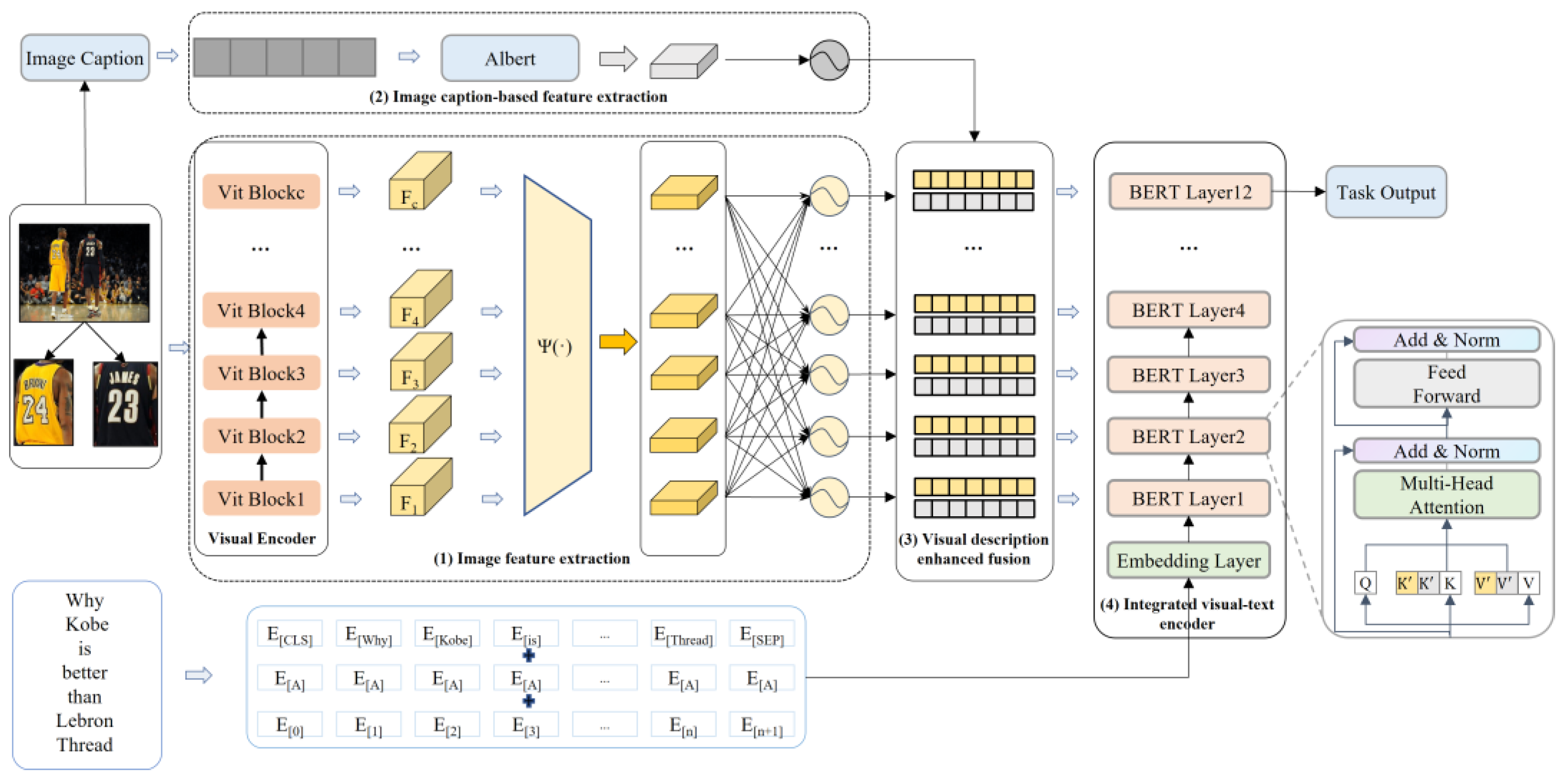
2.1. Image Feature Extraction
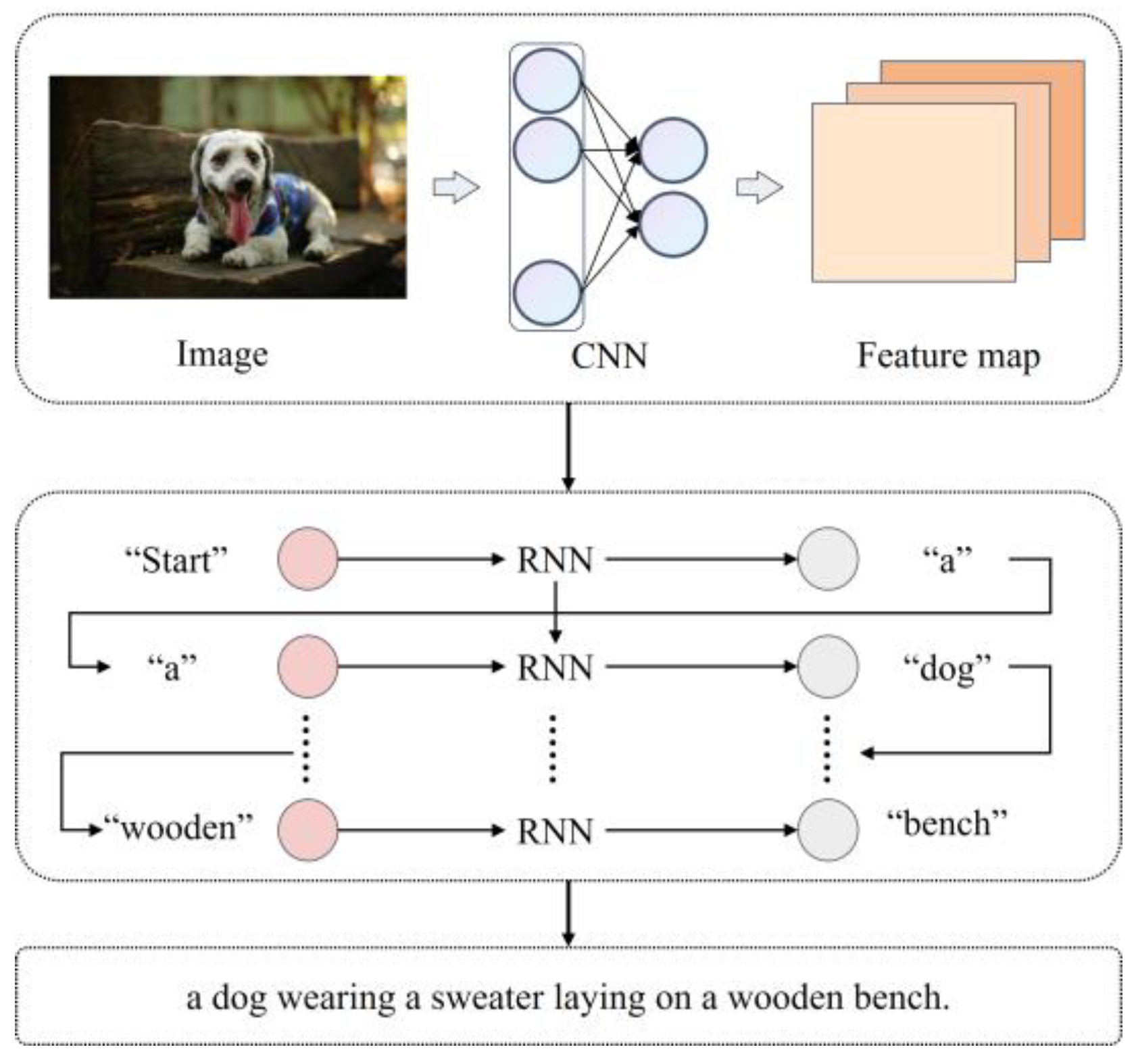
2.2. Image Caption-Based Feature Extraction
2.3. Visual Description Enhanced Fusion
2.4. Integrated Visual-Text Encoder
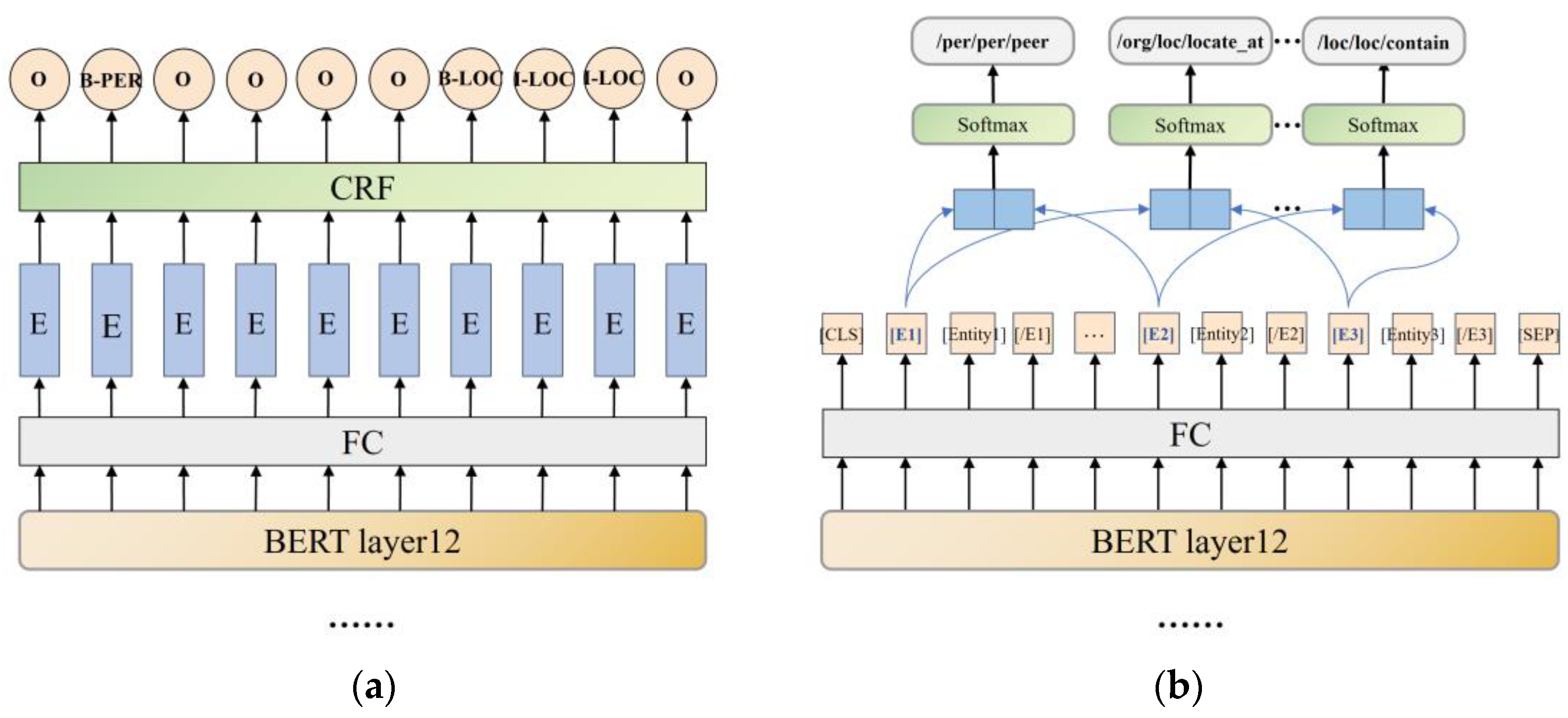
2.5. Classifier
2.5.1. Named Entity Recognition
2.5.2. Relation Extraction
3. Results and Discussion
3.1. Data Set
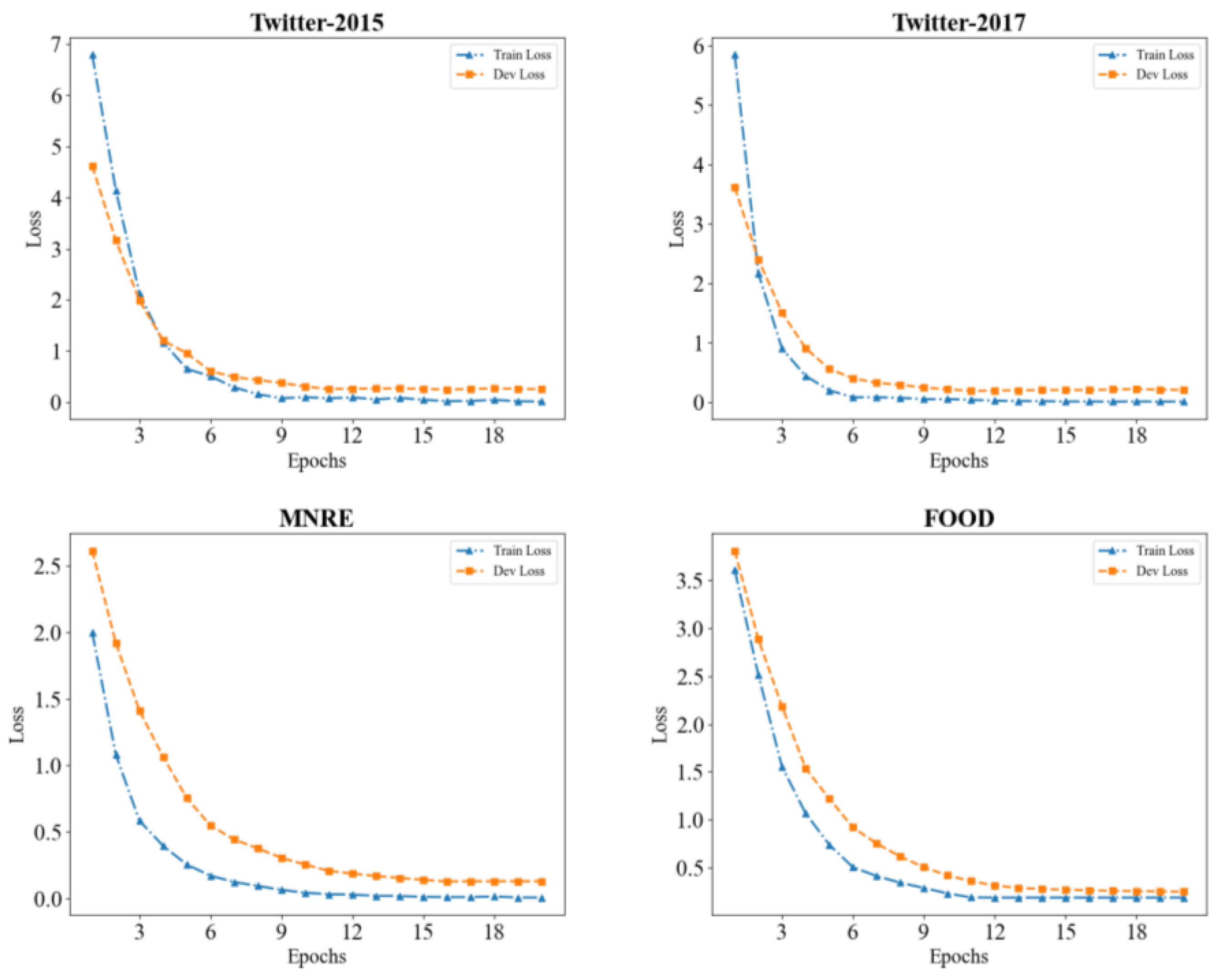
3.2. Experimental Environment
3.3. Experimental Results of MNER and MRE Tasks
- (1)
- Adopting BERT as a text encoder significantly improves the performance of NER and RE tasks compared to traditional BiLSTM and CNN models. For instance, BERT achieves a notable increase in F1 scores on the Twitter datasets. In RE tasks, models with BERT as a text encoder (PURE and MTB) outperform other models (PCNN) with F1 value improvements of 5.37% and 5.73%, respectively. The improvements highlight the importance of pre-trained BERT in NER and RE tasks.
- (2)
- Incorporating image information significantly enhances the performance of NER and RE tasks. Multimodal methods generally perform better than pure text methods in these tasks. In NER tasks, GVATT employs image information and achieves a 6.38% and 5.56% increase in overall F1 values compared to BiLSTM-CRF on two datasets. Meanwhile, AdaCAN demonstrates improvements of 6.27% and 5.84%. In RE tasks, adding image modality with UMT and UMGT results in a 2.24% and 4.07% increase in F1 values compared to the single modality PURE. The improvements further confirm that integrating visual and textual information can generally improve the performance of NER and RE models, emphasizing the importance of combining visual and textual information.
- (3)
- By adopting a visual description augmented integration mechanism to reduce image noise and adaptively integrate visual features into BERT, the performance of the VDAIN method is significantly improved. In the two tables, our model outperforms methods such as UMT and MEGA, which employ shallow attention alignment, particularly achieving notable progress in the MNRE task. The finding emphasizes the importance of eliminating irrelevant visual noise and multimodal information fusion strategies. It may be the challenge of optimizing the integration of visual and textual information to enhance the performance of multimodal methods across various tasks.
- (4)
- Introducing image descriptions is more effective in extracting key image information and reducing modality gaps. We find that models using visual features combined with image descriptions to generate semantic features perform significantly better than HVPNet and MEGA, which only utilize visual features. VDAIN attains state-of-the-art results on all three datasets, showcasing the efficacy of our approach. Specifically, compared to the second-ranked HVPNet model, VDAIN shows a 0.48% increase in overall F1 scores on the Twitter-2015 dataset, a 0.91% increase on the Twitter-2017 dataset, and a 0.69% increase on the MNRE dataset. The experimental findings suggest that incorporating image description generation allows the model to capture essential image information and reduce modality gaps.
- (5)
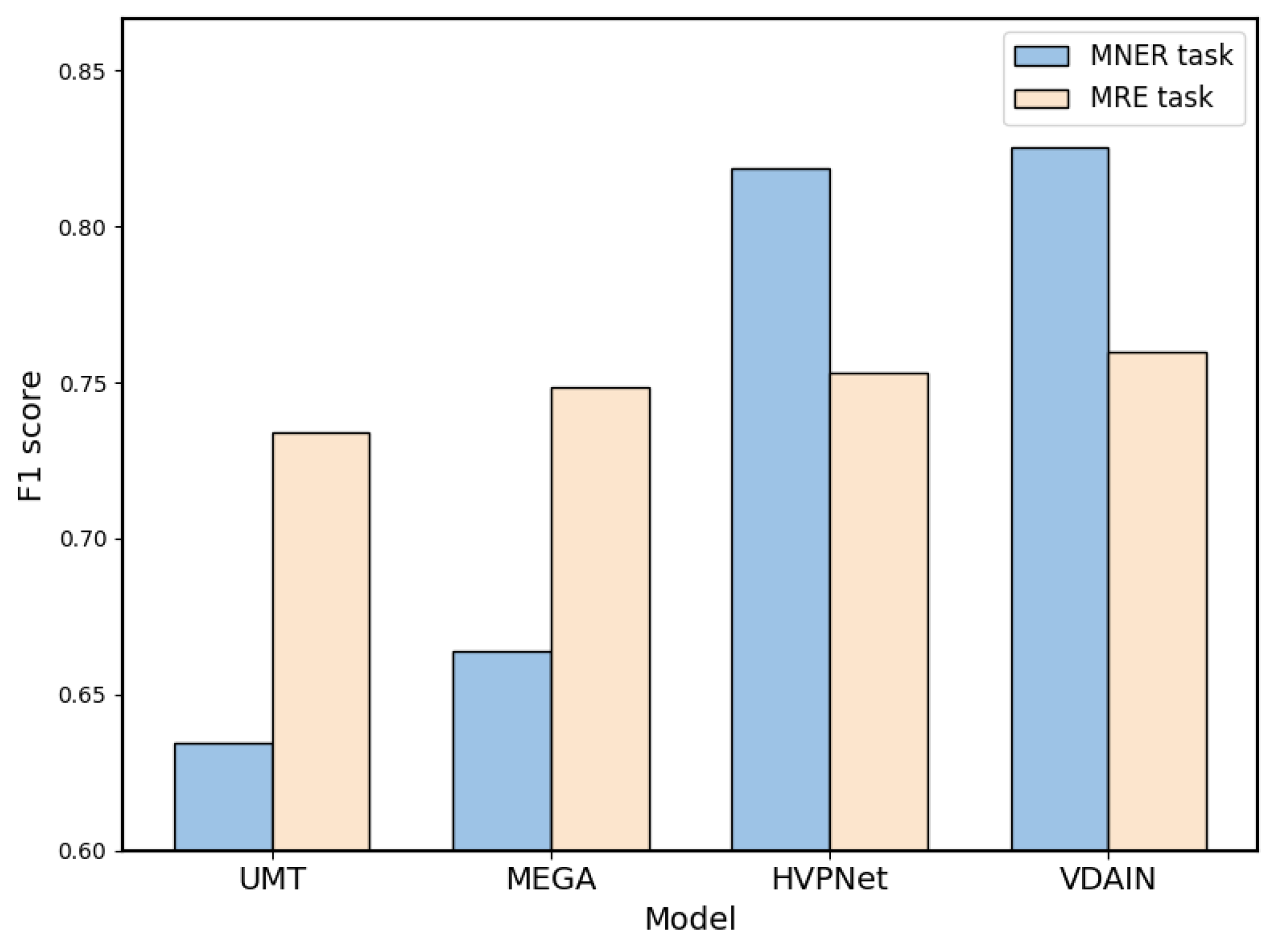
- Figure 5 illustrates the performance of various models in terms of F1 score when solely utilizing datasets related to food safety. For this study, we selected data on the theme of food safety from three publicly available datasets and constructed a new dataset named FOOD datasets. We compared our model, VDAIN, with four other models: UMT, MEGA, and HVPNet. The results demonstrated that VDAIN outperforms the other multimodal models. This further validates the efficacy of our proposed method in entity recognition and relation extraction from food safety-related data on social media. Notably, despite the smaller volume of the FOOD datasets, our model still manages to enhance its performance under low-resource conditions.
3.4. Ablation Study
3.4.1. Analysis of the Effectiveness of Image Caption Generation
3.4.2. Analysis of the Effectiveness of Visual Description Augmented Integration Network
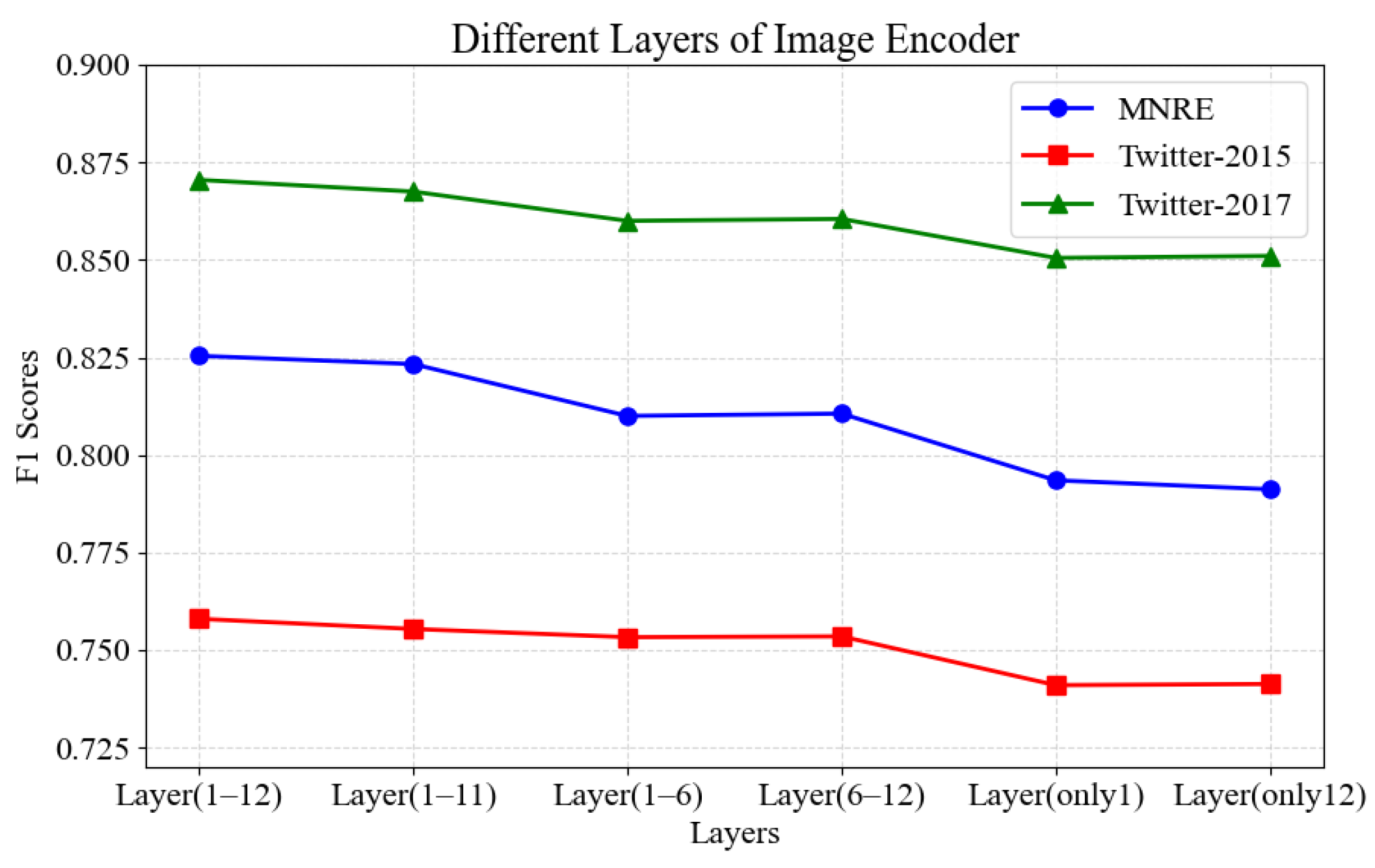
3.4.3. Analysis of the Effectiveness of Utilizing Various Layers of Image Encoder
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Koklu, M.; Cinar, I.; Taspinar, Y.S. Classification of rice varieties with deep learning methods. Comput. Electron. Agric. 2021, 187, 106285. [Google Scholar] [CrossRef]
- Valdés, A.; Álvarez-Rivera, G.; Socas-Rodríguez, B.; Herrero, M.; Ibáñez, E.; Cifuentes, A.J.A.C. Foodomics: Analytical opportunities and challenges. Anal. Chem. 2021, 94, 366–381. [Google Scholar] [CrossRef] [PubMed]
- Kong, J.; Wang, H.; Wang, X.; Jin, X.; Fang, X.; Lin, S. Multi-stream hybrid architecture based on cross-level fusion strategy for fine-grained crop species recognition in precision agriculture. Comput. Electron. Agric. 2021, 185, 106134. [Google Scholar] [CrossRef]
- Kong, J.; Wang, H.; Yang, C.; Jin, X.; Zuo, M.; Zhang, X.J.A. A spatial feature-enhanced attention neural network with high-order pooling representation for application in pest and disease recognition. Agriculture 2022, 12, 500. [Google Scholar] [CrossRef]
- Schütze, H.; Manning, C.D.; Raghavan, P. Introduction to Information Retrieval; Cambridge University Press: Cambridge, UK, 2008; Volume 39. [Google Scholar]
- Jin, X.-B.; Wang, Z.-Y.; Kong, J.-L.; Bai, Y.-T.; Su, T.-L.; Ma, H.-J.; Chakrabarti, P. Deep Spatio-Temporal Graph Network with Self-Optimization for Air Quality Prediction. Entropy 2023, 25, 247. [Google Scholar] [CrossRef] [PubMed]
- Nadeau, D.; Sekine, S.J.L.I. A survey of named entity recognition and classification. Lingvisticae Investig. 2007, 30, 3–26. [Google Scholar] [CrossRef]
- Jin, X.-B.; Wang, Z.-Y.; Gong, W.-T.; Kong, J.-L.; Bai, Y.-T.; Su, T.-L.; Ma, H.-J.; Chakrabarti, P. Variational Bayesian Network with Information Interpretability Filtering for Air Quality Forecasting. Mathematics 2023, 11, 837. [Google Scholar] [CrossRef]
- Kong, J.-L.; Fan, X.-M.; Jin, X.-B.; Su, T.-L.; Bai, Y.-T.; Ma, H.-J.; Zuo, M. BMAE-Net: A Data-Driven Weather Prediction Network for Smart Agriculture. Agronomy 2023, 13, 625. [Google Scholar] [CrossRef]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient estimation of word representations in vector space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- Pennington, J.; Socher, R.; Manning, C.D. Glove: Global vectors for word representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1532–1543. [Google Scholar]
- Huang, Z.; Xu, W.; Yu, K. Bidirectional LSTM-CRF models for sequence tagging. arXiv 2015, arXiv:1508.01991. [Google Scholar]
- Ma, X.; Hovy, E. End-to-end sequence labeling via bi-directional lstm-cnns-crf. arXiv 2016, arXiv:1603.01354. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 5998–6008. [Google Scholar]
- Zheng, Y.Y.; Kong, J.L.; Jin, X.B.; Wang, X.Y.; Zuo, M. CropDeep: The Crop Vision Dataset for Deep-Learning-Based Classification and Detection in Precision Agriculture. Sensors 2019, 19, 1058. [Google Scholar] [CrossRef] [PubMed]
- Yang, Z.; Dai, Z.; Yang, Y.; Carbonell, J.; Salakhutdinov, R.R.; Le, Q.V. Xlnet: Generalized autoregressive pretraining for language understanding. Adv. Neural Inf. Process. Syst. 2019, 32, 5754–5764. [Google Scholar]
- Lan, Z.; Chen, M.; Goodman, S.; Gimpel, K.; Sharma, P.; Soricut, R. Albert: A lite bert for self-supervised learning of language representations. arXiv 2019, arXiv:1909.11942. [Google Scholar]
- Liu, W.; Zhou, P.; Zhao, Z.; Wang, Z.; Ju, Q.; Deng, H.; Wang, P. K-bert: Enabling language representation with knowledge graph. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 2901–2908. [Google Scholar]
- Zhang, Z.; Han, X.; Liu, Z.; Jiang, X.; Sun, M.; Liu, Q. ERNIE: Enhanced language representation with informative entities. arXiv 2019, arXiv:1905.07129. [Google Scholar]
- Von Däniken, P.; Cieliebak, M. Transfer Learning and Sentence Level Features for Named Entity Recognition on Tweets. In Proceedings of the NUT@EMNLP, 2017, Copenhagen, Denmark, 7 September 2017. [Google Scholar]
- Xie, J.; Zhang, K.; Sun, L.; Su, Y.; Xu, C. Improving NER in Social Media via Entity Type-Compatible Unknown Word Substitution. In Proceedings of the ICASSP 2021–2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021; pp. 7693–7697. [Google Scholar]
- Soares, L.B.; FitzGerald, N.; Ling, J.; Kwiatkowski, T. Matching the blanks: Distributional similarity for relation learning. arXiv 2019, arXiv:1906.03158. [Google Scholar]
- Yamada, I.; Asai, A.; Shindo, H.; Takeda, H.; Matsumoto, Y. LUKE: Deep contextualized entity representations with entity-aware self-attention. arXiv 2020, arXiv:2010.01057. [Google Scholar]
- Moon, S.; Neves, L.; Carvalho, V. Multimodal named entity recognition for short social media posts. arXiv 2018, arXiv:1802.07862. [Google Scholar]
- Zhang, Q.; Fu, J.; Liu, X.; Huang, X. Adaptive co-attention network for named entity recognition in tweets. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Arshad, O.; Gallo, I.; Nawaz, S.; Calefati, A. Aiding intra-text representations with visual context for multimodal named entity recognition. In Proceedings of the 2019 International Conference on Document Analysis and Recognition (ICDAR), Sydney, Australia, 20–25 September 2019; pp. 337–342. [Google Scholar]
- Yu, J.; Jiang, J.; Yang, L.; Xia, R. Improving multimodal named entity recognition via entity span detection with unified multimodal transformer. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020. [Google Scholar]
- Wu, Z.; Zheng, C.; Cai, Y.; Chen, J.; Leung, H.-f.; Li, Q. Multimodal representation with embedded visual guiding objects for named entity recognition in social media posts. In Proceedings of the 28th ACM International Conference on Multimedia, Seattle, WA, USA, 12–16 October 2020; pp. 1038–1046. [Google Scholar]
- Chen, D.; Li, Z.; Gu, B.; Chen, Z. Multimodal named entity recognition with image attributes and image knowledge. In Proceedings of the Database Systems for Advanced Applications: 26th International Conference, DASFAA 2021, Taipei, Taiwan, 11–14 April 2021; Part II 26. pp. 186–201. [Google Scholar]
- Zheng, C.; Wu, Z.; Wang, T.; Cai, Y.; Li, Q. Object-aware multimodal named entity recognition in social media posts with adversarial learning. IEEE Trans. Multimed. 2020, 23, 2520–2532. [Google Scholar] [CrossRef]
- Xu, B.; Huang, S.; Sha, C.; Wang, H. MAF: A General Matching and Alignment Framework for Multimodal Named Entity Recognition. In Proceedings of the Fifteenth ACM International Conference on Web Search and Data Mining, Tempe, AZ, USA, 21–25 February 2022; pp. 1215–1223. [Google Scholar]
- Chen, X.; Zhang, N.; Li, L.; Yao, Y.; Deng, S.; Tan, C.; Huang, F.; Si, L.; Chen, H. Good Visual Guidance Makes A Better Extractor: Hierarchical Visual Prefix for Multimodal Entity and Relation Extraction. arXiv 2022, arXiv:2205.03521. [Google Scholar]
- Li, L.H.; Yatskar, M.; Yin, D.; Hsieh, C.-J.; Chang, K.-W. Visualbert: A simple and performant baseline for vision and language. arXiv 2019, arXiv:1908.03557. [Google Scholar]
- Li, G.; Duan, N.; Fang, Y.; Gong, M.; Jiang, D. Unicoder-vl: A universal encoder for vision and language by cross-modal pre-training. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 11336–11344. [Google Scholar]
- Li, X.; Yin, X.; Li, C.; Zhang, P.; Hu, X.; Zhang, L.; Wang, L.; Hu, H.; Dong, L.; Wei, F. Oscar: Object-semantics aligned pre-training for vision-language tasks. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Part XXX 16. pp. 121–137. [Google Scholar]
- Radford, A.; Kim, J.W.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Sastry, G.; Askell, A.; Mishkin, P.; Clark, J. Learning transferable visual models from natural language supervision. In Proceedings of the International conference on machine learning, Virtual, 18–24 July 2021; pp. 8748–8763. [Google Scholar]
- Lu, J.; Batra, D.; Parikh, D.; Lee, S. Vilbert: Pretraining task-agnostic visiolinguistic representations for vision-and-language tasks. Adv. Neural Inf. Process. Syst. 2019, 32. [Google Scholar]
- Luo, Y.; Ji, J.; Sun, X.; Cao, L.; Wu, Y.; Huang, F.; Lin, C.-W.; Ji, R. Dual-level collaborative transformer for image captioning. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 2–9 February 2021; pp. 2286–2293. [Google Scholar]
- Veličković, P.; Cucurull, G.; Casanova, A.; Romero, A.; Lio, P.; Bengio, Y. Graph attention networks. arXiv 2017, arXiv:1710.10903. [Google Scholar]
- Xu, T.; Zhang, P.; Huang, Q.; Zhang, H.; Gan, Z.; Huang, X.; He, X. Attngan: Fine-grained text to image generation with attentional generative adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 1316–1324. [Google Scholar]
- Devlin, J.; Gupta, S.; Girshick, R.; Mitchell, M.; Zitnick, C.L. Exploring nearest neighbor approaches for image captioning. arXiv 2015, arXiv:1505.04467. [Google Scholar]
- Faghri, F.; Fleet, D.; Kiros, J.; Fidler, S.V. Improving visual-semantic embeddings with hard negatives. arXiv 2017, arXiv:1707.05612. [Google Scholar]
- Vinyals, O.; Toshev, A.; Bengio, S.; Erhan, D. Show and tell: A neural image caption generator. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3156–3164. [Google Scholar]
- Anderson, P.; He, X.; Buehler, C.; Teney, D.; Johnson, M.; Gould, S.; Zhang, L. Bottom-up and top-down attention for image captioning and visual question answering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6077–6086. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28, 91–99. [Google Scholar] [CrossRef] [PubMed]
- Wang, C.; Shen, Y.; Ji, L. Geometry Attention Transformer with position-aware LSTMs for image captioning. Expert Syst. Appl. 2022, 201, 117174. [Google Scholar] [CrossRef]
- Tang, S.; Wang, Y.; Kong, Z.; Zhang, T.; Li, Y.; Ding, C.; Wang, Y.; Liang, Y.; Xu, D. You Need Multiple Exiting: Dynamic Early Exiting for Accelerating Unified Vision Language Model. arXiv 2022, arXiv:2211.11152. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Loshchilov, I.; Hutter, F.J. Decoupled weight decay regularization. In Proceedings of the 7th International Conference on Learning Representations (ICLR), New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Taspinar, Y.S.; Koklu, M.; Altin, M. Classification of flame extinction based on acoustic oscillations using artificial intelligence methods. Case Stud. Therm. Eng. 2021, 28, 101561. [Google Scholar] [CrossRef]
- Zeng, D.; Liu, K.; Chen, Y.; Zhao, J. Distant supervision for relation extraction via piecewise convolutional neural networks. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal, 17–21 September 2015; pp. 1753–1762. [Google Scholar]
- Zhong, Z.; Chen, D. A frustratingly easy approach for entity and relation extraction. arXiv 2020, arXiv:2010.12812. [Google Scholar]
- Lu, D.; Neves, L.; Carvalho, V.; Zhang, N.; Ji, H. Visual attention model for name tagging in multimodal social media. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics, Melbourne, Australia, 15–20 July 2018; Volume 1: Long Papers. pp. 1990–1999. [Google Scholar]
- Zheng, C.; Wu, Z.; Feng, J.; Fu, Z.; Cai, Y. Mnre: A challenge multimodal dataset for neural relation extraction with visual evidence in social media posts. In Proceedings of the 2021 IEEE International Conference on Multimedia and Expo (ICME), Shenzhen, China, 5–9 July 2021; pp. 1–6. [Google Scholar]
- Zhang, D.; Wei, S.; Li, S.; Wu, H.; Zhu, Q.; Zhou, G. Multi-modal graph fusion for named entity recognition with targeted visual guidance. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 2–9 February 2021; pp. 14347–14355. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Entity Type | Twitter-2015 | Twitter-2017 | ||||
|---|---|---|---|---|---|---|
| Train | Dev | Test | Train | Dev | Test | |
| Person | 2217 | 552 | 1816 | 2943 | 626 | 621 |
| Location | 2091 | 522 | 1697 | 731 | 173 | 178 |
| Organization | 927 | 247 | 839 | 1674 | 375 | 395 |
| Miscellaneous | 931 | 220 | 720 | 701 | 150 | 157 |
| Total | 6166 | 1541 | 5072 | 6049 | 1324 | 1351 |
| Num of sentence | 4000 | 1000 | 3257 | 3273 | 723 | 723 |
| Statistics | MNRE | FOOD |
|---|---|---|
| Number of Word | 172,000 | 11,000 |
| Number of Sentence | 14,796 | 1525 |
| Number of Instance | 10,089 | 805 |
| Number of Entity | 20,178 | 1670 |
| Number of Relation | 31 | 7 |
| Number of Image | 10,089 | 928 |
| Modality | Model | Twitter-2015 | Twitter-2017 | ||||
|---|---|---|---|---|---|---|---|
| P% | R% | F1% | P% | R% | F1% | ||
| Text | BiLSTM-CRF | 68.14 | 61.09 | 64.42 | 79.42 | 73.43 | 76.31 |
| CNN-BiLSTM-CRF | 66.24 | 68.09 | 67.15 | 80.00 | 78.76 | 79.37 | |
| BERT | 68.30 | 74.61 | 71.32 | 82.19 | 83.72 | 80.95 | |
| Text + Image | GVATT | 73.96 | 67.90 | 70.80 | 83.41 | 80.38 | 81.87 |
| AdaCAN | 72.75 | 68.74 | 70.69 | 84.16 | 80.24 | 82.15 | |
| GVATT-BERT-CRF | 69.15 | 74.46 | 71.70 | 83.64 | 84.38 | 84.01 | |
| AdaCAN-BERT-CRF | 69.87 | 74.59 | 72.15 | 85.13 | 83.20 | 84.10 | |
| UMT | 71.84 | 74.61 | 73.20 | 85.08 | 85.27 | 85.18 | |
| SMKG-Attention-CRF | 74.78 | 71.82 | 73.27 | 85.14 | 85.40 | 85.95 | |
| HVPNet | 73.87 | 76.82 | 75.32 | 85.84 | 87.93 | 86.87 | |
| VDAIN | 74.22 | 77.45 | 75.80 | 88.00 | 87.55 | 87.78 | |
| Modality | Model | MNRE | |||
|---|---|---|---|---|---|
| Acc% | P% | R% | F1% | ||
| Text | PCNN | 72.67 | 62.85 | 49.69 | 55.49 |
| MTB | 72.73 | 64.46 | 57.81 | 60.86 | |
| PURE | 73.05 | 64.50 | 58.19 | 61.22 | |
| Text + Image | VisualBERT | 69.22 | 57.15 | 59.48 | 58.30 |
| BERT + SG | 74.09 | 62.95 | 62.65 | 62.80 | |
| UMT | 74.49 | 62.93 | 63.88 | 63.46 | |
| UMGF | 76.31 | 64.38 | 66.23 | 65.29 | |
| MEGA | 76.15 | 64.51 | 68.44 | 66.41 | |
| HVPNet | 90.95 | 83.64 | 80.78 | 81.85 | |
| VDAIN | 93.92 | 82.44 | 81.25 | 82.54 | |
| Model | F1% | ||
|---|---|---|---|
| Twitter-2015 | Twitter-2017 | MNRE | |
| VDAIN | 75.80 | 87.78 | 82.54 |
| NoCap | 75.28 | 86.42 | 79.84 |
| NoObj | 75.60 | 87.34 | 81.97 |
| Model | F1% | ||
|---|---|---|---|
| Twitter-2015 | Twitter-2017 | MNRE | |
| VDAIN | 75.80 | 87.78 | 82.54 |
| Direct | 74.75 | 85.87 | 79.38 |
| Concatenate | 74.92 | 85.91 | 78.75 |
| Random | 74.38 | 85.79 | 79.56 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zuo, M.; Wang, Y.; Dong, W.; Zhang, Q.; Cai, Y.; Kong, J. Visual Description Augmented Integration Network for Multimodal Entity and Relation Extraction. Appl. Sci. 2023, 13, 6178. https://doi.org/10.3390/app13106178
Zuo M, Wang Y, Dong W, Zhang Q, Cai Y, Kong J. Visual Description Augmented Integration Network for Multimodal Entity and Relation Extraction. Applied Sciences. 2023; 13(10):6178. https://doi.org/10.3390/app13106178
Chicago/Turabian StyleZuo, Min, Yingjun Wang, Wei Dong, Qingchuan Zhang, Yuanyuan Cai, and Jianlei Kong. 2023. "Visual Description Augmented Integration Network for Multimodal Entity and Relation Extraction" Applied Sciences 13, no. 10: 6178. https://doi.org/10.3390/app13106178
APA StyleZuo, M., Wang, Y., Dong, W., Zhang, Q., Cai, Y., & Kong, J. (2023). Visual Description Augmented Integration Network for Multimodal Entity and Relation Extraction. Applied Sciences, 13(10), 6178. https://doi.org/10.3390/app13106178