
Review of Anomaly Detection Algorithms for Data Streams

Abstract
:1. Introduction
- Financial risk management: Data stream anomaly detection is utilized for identifying, analyzing, and predicting credit card fraud, insurance scams, and other fraudulent activities in banking card transactions [5]. Commercial banks also employ data stream anomaly detection methods to analyze real-time exchange rate anomalies, thus preventing substantial financial losses to banks and customers.
- Power grid operations: Data stream anomaly detection is commonly employed to detect anomalies in power scheduling data, ensuring the secure operation of power systems [6].
- Healthcare applications: Data stream anomaly detection is frequently used for detecting abnormal patterns in medical image data, pulse data, blood pressure data, and other streaming healthcare data. These anomalies serve as fundamental indicators for diagnosing abnormal human conditions [7].
- Computer network security: Data stream anomaly detection is typically employed to detect intrusions that violate security policies [8].
- Continuous data influx: Data arrives in a continuous stream, making it costly to perform multiple scans or store all the data. Therefore, algorithms/models are required to operate in resource-constrained environments.
- High data generation rates: Due to this characteristic, relevant algorithms must possess real-time processing and analysis capabilities.
- Data stream dynamics and evolution: Anomalous behaviors in data streams can change over time, rendering traditional static anomaly detection methods inadequate. Data stream anomaly detection algorithms need to be adaptive, capable of automatically learning and adjusting to changes within the data stream, thereby maintaining efficient anomaly detection performance.
2. Data Stream Anomaly Detection: Concepts
2.1. Data Streams
- Data streams are fluid and fast. Fluid means that new data flows in every moment, while fast means that data streams require timely and effective processing, which can be a heavy burden for computers.
- Data streams have temporal properties. Data streams have a temporal sequence, and we can only access data in the data stream in order.
- Data streams are single pass. Due to the temporal nature of the data and the limitation of device storage space, data items in a data stream can usually only be processed once. This also means that the system cannot retain complete information on all data items.
- Data streams have a certain degree of mutation. The data in a data stream may undergo mutation at a certain point due to external factors, resulting in a significant difference compared to the data before mutation. Mutated data streams may cause errors and inaccuracies in research, which can pose significant challenges for researchers [54].
2.2. Anomaly Detection
3. Data Stream Anomaly Detection Algorithm Based on Offline Learning
3.1. Based on Similarity of Data Distribution
3.2. Based on Classification Principle
3.3. Based on Subspace Partitioning
- Data preprocessing: Randomly select some dimensions from the original data to form a random subspace based on the dimensionality of the subspace to be detected.
- Hash mapping: For each vector in the random subspace, use a hash function to map it to a bucket.
- Anomaly point detection: For each bucket, calculate the average value of the vectors in it and use it as the center point of the bucket. Then, calculate the distance between each vector and the center point of the bucket. For vectors with distances exceeding a certain threshold, mark them as anomaly points.
- Return results: Return all the anomaly points as the detection results.
3.4. Based on Deep Learning
- Preprocessing: Convert raw data into spectrograms for better convolutional operations.
- Construct a deep convolutional neural network: Use multiple convolutional, pooling, and fully connected layers to construct a deep convolutional neural network for modeling normal data.
- Train the network: Train the network using normal data and use cross-entropy as the loss function.
- Anomaly detection: For new data, input it into the trained network; calculate its reconstruction error; and if the reconstruction error is greater than a certain threshold, mark it as abnormal data.
- Data preprocessing: The dataset undergoes preprocessing steps such as feature extraction, normalization, and dimensionality reduction to facilitate subsequent model training and testing.
- Autoencoder model construction: A multilayer neural network is built as the autoencoder model. The model consists of an encoder and a decoder. The encoder maps the input data to a hidden representation, while the decoder reconstructs the hidden representation into the original input data.
- Model training: The autoencoder model is trained using data from normal devices as the training set. The training aims to minimize the reconstruction error, which measures the difference between the original input data and the decoder’s output.
- Anomaly detection: The trained autoencoder model is used to detect anomalies in the behavior of unknown devices. If the reconstruction error exceeds a predefined threshold, the device’s behavior is deemed anomalous.
- Transfer learning: For each specific type of device, the intermediate layers are retrained using a dataset from that type of device. This process enables the model to better capture the feature representation of that device type.
- Algorithms based on similarity of data distribution: The advantage of these algorithms is their simplicity and intuitive nature, without the need for labels. They typically rely on the similarity between data samples to determine the degree of anomaly, providing a straightforward interpretation and understanding of anomalies. However, they have limitations in terms of assumptions about data distribution and requirements on data dimensionality. These algorithms often make assumptions about the statistical distribution of data samples, which may not adapt well to complex data scenarios.
- Algorithms based on the classification principle: These algorithms demonstrate a strong generalization ability and scalability. Classification algorithms can learn the normal patterns of data based on available label information, exhibiting a certain degree of generalization to unknown data. They are typically applicable across different data domains and exhibit good scalability. However, they require labeled information and can be challenging to handle in the presence of class imbalance. These algorithms rely on a significant amount of labeled data for model training, which may be difficult or expensive to obtain. Additionally, when the proportion of normal samples to anomaly samples is highly imbalanced, classification algorithms may result in high false positive or false negative rates.
- Algorithms based on subspace partitioning principles: These algorithms can handle high-dimensional data and are suitable for multimodal data. Subspace partitioning algorithms can be applied to multimodal data such as images and videos. They are also capable of processing high-dimensional data and extracting significant feature information. However, they have limitations in terms of data sampling requirements and restrictions on anomaly types. Subspace partitioning principle-based methods typically assume that anomalies in subspaces are linearly separable, making it difficult to handle nonlinear anomalies. Moreover, these algorithms often require data sampling or dimensionality reduction, which may not be suitable for small-sized datasets.
- Algorithms based on deep learning: The advantages of deep learning algorithms include automatic feature learning and advanced feature extraction. Deep learning models can extract high-level features from data, capturing abstract concepts and patterns. They can automatically learn feature representations without the need for manual feature engineering. However, they have requirements for large amounts of data and lack interpretability. Deep learning models typically require a substantial amount of labeled data for training, which can be challenging to obtain. Additionally, the prediction process of deep learning models tends to be black box, making it relatively difficult to interpret the basis of their decisions.
4. Data Stream Anomaly Detection Algorithm Based on Semi-Online Learning
- Offline training combined with batch updating data stream anomaly detection algorithms:
- Based on similarity of data distribution: MiLOF (Memory-Efficient LOF), NETS (NET-Effect-Based Stream Outlier Detection);
- Based on classification principle: EC-SVM (Enhanced One-Class SVM), OW-RF (Optimal Weighted One-class Random Forests);
- Offline training combined with incremental updating data stream anomaly detection algorithms:
- Based on similarity of data distribution: STROM and its variants, MCOD (Micro-cluster-Based Continuous Outlier Detection), pMCOD (Parallel Micro-Cluster-Based Continuous Outlier Detection), DiLOF (Density-Based Incremental LOF), CODS (Contextual Outliers in Data Streams);
- Based on subspace partitioning: iforestASD (Isolation Forest with Adaptive Sub-sampling and Decay), multidimensional stream anomaly detection algorithm based on LSHiforest (Locality-Sensitive Hashing based Isolation Forest).
4.1. Offline Learning Combined with Batch Updating for Data Stream Anomaly Detection
4.1.1. Offline Training Combined with Batch Updating for Data Stream Anomaly Detection Algorithm Based on Similarity of Data Distribution
- MiLOF stores data in a fixed-size sliding window. When a new data point arrives, the oldest data point is removed, and the window slides to the next position.
- MiLOF measures the anomaly degree of each data point using the local outlier factor (LOF), which is calculated by comparing the distance between a data point and its k-nearest neighbors to the average distance of its k-nearest neighbors.
- Traditional LOF requires calculating the k-nearest neighbors for each data point before computing the LOF score. However, this method has a high computational complexity and cannot handle data streams. To solve this problem, MiLOF uses a sampling-based method, which only calculates the k-nearest neighbors on data samples in the sliding window, reducing the computational complexity.
- MiLOF also employs an important optimization technique, which only considers the k-nearest neighbors in the sliding window when calculating the LOF score for each data point. Since the sliding window size is fixed, the k-nearest neighbors of each data point can be pre-calculated and used directly when computing the LOF score.
- Net effect calculation: NETS uses a cell-based cardinality grid data structure to calculate the net impact of expired and new sliding windows.
- Cell-level anomaly detection: For each cell in the cardinality grid, the algorithm returns three types of sets on the basis of its boundary: normal data set, anomaly data set, and undetermined data set. Only the undetermined anomaly data set is passed to the next step.
- Point-level anomaly detection: NETS detects point-level anomaly values by checking each data point in the undetermined cell.
- Return outlier value set.
4.1.2. Offline Training Combined with Batch Updating for Data Stream Anomaly Detection Algorithm Based on Classification Principles
- The original OCSVM algorithm is used to conduct preliminary training on the dataset.
- The collaborative training mechanism is applied to learn low-order features and further improve the model’s performance.
- Anomaly detection is conducted by computing the abnormality score of each sample.
4.2. Offline Learning Combined with Incremental Updating for Data Stream Anomaly Detection
4.2.1. Offline Training Combined with Increment Updating for Data Stream Anomaly Detection Algorithm Based on Similarity of Data Distribution
- The DILOF algorithm first uses the distance-based LOF algorithm to determine the local density of data points and then estimates the global density of data points through density clustering.
- The DILOF algorithm divides the global density into several uniform intervals and uses the minimum and maximum values to represent each interval.
- The DILOF algorithm uses a set of “difference sequences” to store the global density information of all current data points. These difference sequences can be used for incremental outlier detection. For newly arrived data points, the DILOF algorithm first calculates their local density and updates their difference sequences with the new global density information.
- The DILOF algorithm uses the new difference sequences to calculate the LOF scores of data points to determine whether they are local outliers.
- The CODS algorithm adopts the idea of time sliding window. Firstly, the anomaly detection kernel is called in the CPU to detect the data within the sliding window, and the anomaly detection result is fed back to the storage module in the CPU. Then, whenever the window slides, the data points received in each sliding time unit are transferred to the global storage module in the GPU. The anomaly detection kernel is called in the GPU to detect anomalies, and the results are transmitted to the CPU storage module.
- The anomaly detection process performs local clustering for each data stream to obtain the local clustering center of the data stream. Then, the global clustering is constructed using the local clustering centers, and the global clustering center of the data stream is obtained. Finally, the neighboring density of each data point in the principal component is approximately calculated, and the anomaly score is determined by approximating the neighboring density.
- In the anomaly detection kernel, the GPU kernel performs anomaly detection by copying the flow data points from the GPU global memory to the shared memory of the thread block. For each data stream, the thread block executes in parallel to achieve anomaly detection for multiple data streams.
4.2.2. Offline Training Combined with Increment Updating for Data Stream Anomaly Detection Algorithm Based on Subspace Partitioning
- Build the LSHiforest data structure on the basis of historical data points and calculate the anomaly scores of the data points.
- Preprocess the data points collected from all data streams to discover suspicious data points.
- Update the suspicious data points into the LSHiforest data structure and recalculate the anomaly scores for the updated data points.
- Offline training with batch updates: Compared to algorithms that combine offline training with incremental updates, the advantage of offline training with batch updates is that the update frequency is controllable. The frequency of updating the algorithm model can be adjusted according to actual needs, avoiding the computational burden caused by too frequent updates. The disadvantage is poor sensitivity to time. Algorithms based on offline training with batch updates typically have longer update cycles and may not be able to detect the latest anomaly situations in a timely manner.
- The advantage of algorithms based on similarity of data distribution is their ability to adapt well to the statistical characteristics of the data. They are also relatively simple, as well as easy to implement and explain. The disadvantage is that the detection effectiveness relies on assumptions about the data distribution. These algorithms usually assume significant differences in the distribution between anomaly and normal data, but in some cases, the distribution of anomaly data may be similar to normal data.
- The advantage of algorithms based on the classification principle is their flexibility in handling different types of anomalies. By adjusting the settings and thresholds of the classification model, these algorithms can adapt to different types of anomalies, demonstrating a certain level of flexibility. The disadvantage is sensitivity to class imbalance. In situations where anomaly data is scarce, these algorithms are prone to be affected by class imbalance issues, potentially leading to the misclassification of anomaly samples as normal samples.
- Offline training with incremental updates: Compared to algorithms that combine offline training with batch updates, the advantage of offline training with incremental updates is its strong adaptability to new samples. Due to the mechanism of incremental updates, the algorithm can promptly adapt to new samples and concept drift in the data stream, maintaining the accuracy of the model. The disadvantage is the difficulty in updating historical data. The mechanism of incremental updates may pose challenges in updating historical data, especially when there are changes in the model structure, requiring careful handling of the update problem with old data.
- The advantage of algorithms based on similarity of data distribution is their strong interpretability. Similarly, the disadvantage is also reliance on assumptions about the data distribution.
- The advantage of algorithms based on subspace partitioning principles is their ability to better detect high-dimensional data streams and their robustness to anomalous samples. The disadvantage is lower interpretability compared to algorithms based on the similarity of data distribution.
5. Data Stream Anomaly Detection Algorithm Based on Online Learning
- Data stream anomaly detection algorithm based on online shallow learning:
- Based on similarity of data distribution: osPCA (Over-Sampling Principal Components Analysis), OSHULL (Online and Subdivisible Distributed Scaled Convex Hull) algorithm.
- Based on matrix sketch: The deterministic flow update algorithm, the stochastic stream update algorithm, a framework of virtual war room and matrix sketch-based streaming anomaly detection.
- Based on decision trees: HT (Hoeffding Tree), CVFDT (Concept-Adapting Very Fast Decision Tree Learner), HAT (Hoeffding Adaptive Tree), EFDT (Extremely Fast Decision Tree), GAHT (Green Accelerated Hoeffding Tree) algorithms.
- Data stream anomaly detection algorithm based on online deep learning: Ada (adaptive deep log anomaly detector), DAGMM (Deep Autoencoding Gaussian Mixture Model), ARCUS (adaptive framework for online deep anomaly detection under a complex evolving data stream) algorithm, S-DPS (Software Defined Networking-Based DDoS Protection System) framework.
5.1. Data Stream Anomaly Detection Algorithm Based on Online Shallow Learning
5.1.1. Based on Similarity of Data Distribution
- Find the maximum distance from a support point to an edge. As shown in Figure 5, c is the midpoint of V1 and V2, and the data point with the shortest distance to c is the support point. Each edge has one support point, and the maximum distance between these support points and their respective edges is d. When d exceeds a threshold (which is calculated on the basis of the interquartile range of distances between all edges and their support points), it indicates that the area around c is empty.
- To find the pivotal vertex Vi, as shown in Figure 6, first calculate the sum of distances of all edges except for the (V1, V2) edge (the red edges in the figure) as the perimeter p. Meanwhile, locate point c, which is equidistant to V1 and V2 at a distance of p/2. Then, choose the vertex V6 closest to this point as the pivotal vertex.
- Two new convex hulls are generated using V1, V2, support point, and pivot vertex, as shown in Figure 7.
5.1.2. Based on Matrix Sketch
- Data collection and processing: Collect log data from the microservice system and process it into a numerical matrix.
- Matrix sketch calculation: Use matrix sketch technology to convert input data into a low-dimensional representation, reducing computational complexity.
- Cluster center calculation: Use clustering algorithms (such as k-means) to calculate the cluster centers of the matrix sketch.
- Virtual war room construction: Use the cluster centers as nodes to construct the virtual war room.
- Data stream anomaly detection: Map new data points to the nearest cluster center and use distance metrics (such as Euclidean distance) to calculate the distance between the data point and its cluster. If the distance exceeds a predetermined threshold, the data point is considered an anomaly.
5.1.3. Based on Decision Trees
5.2. Data Stream Anomaly Detection Algorithm Based on Online Deep Learning
- Use the autoencoder to reduce and reconstruct the input data to obtain a hidden layer representation.
- Use the Gaussian mixture model to model the hidden layer representation and estimate the probability density of the sample in the mixture model. Determine whether the sample is an anomaly by comparing the probability density of the sample in the mixture model with a pre-set threshold.
- Initialize the model pool with the first batch of data streams, using the model built from the first batch of data.
- Use the model pool for anomaly detection on each subsequent batch of data points and calculate the anomaly scores.
- Assess the reliability of the model pool. If the reliability of the model pool exceeds the reliability threshold, incrementally update the most reliable model in the model pool using the current batch of data. If the reliability is below the reliability threshold, update the model pool by initializing a new model with the current data and recursively merging it with similar old models.
- Return the anomaly score for the current data.
- FC module: Various features are extracted from network traffic data and passed to the AD module for further processing.
- AD module: The AD module utilizes the extracted traffic features to build a model of normal traffic. It continuously monitors the traffic in real time and compares it with the normal model. The AD module typically sets one or more thresholds. If the traffic features exceed or fall below the thresholds, they may be considered anomalous. The threshold values can be adaptively adjusted on the basis of the network environment, historical data, or specific business requirements.
- AM module: Once the anomaly detection module identifies traffic as anomalous, it flags the traffic and notifies the SDN controller or other relevant components. The SDN controller can then take appropriate protection measures, such as traffic redirection, throttling, or diversion, on the basis of the flagged anomalous traffic.
- Algorithms based on online shallow learning: Compared to online deep learning, algorithms based on online shallow learning have the advantage of lower algorithm complexity and relatively simple algorithm environment and equipment requirements. However, they have limited feature representation capability. Shallow learning algorithms typically rely on manually designed feature representation methods, which may not fully capture complex nonlinear features in the data.
- Algorithms based on similarity of data distribution have the advantage of strong interpretability, but they are sensitive to assumptions about the data distribution.
- Algorithms based on matrix sketching have the advantages of low computational cost and good robustness. Matrix sketching can adapt to changes in the data stream through updates and adjustments. However, they are sensitive to parameter selection, such as the size of the matrix sketch and update strategy. Inappropriate parameter choices may result in performance degradation.
- Algorithms based on decision trees have the advantage of being able to adapt to concept drift. They can handle multidimensional features and consider interactions between multiple features during tree construction. However, they are sensitive to imbalanced data distribution and rely on empirical parameter selection. In cases of imbalanced data distribution, decision tree algorithms may perform poorly on minority classes. The selection of parameters such as maximum tree depth and splitting criteria requires experience and trial-and-error.
- Algorithms based on online deep learning: Compared to online shallow learning, algorithms based on online deep learning have the advantages of powerful feature learning capabilities and robustness to noise and outliers. Online deep learning algorithms can automatically learn higher-level, abstract feature representations from raw data, capturing complex patterns and nonlinear relationships in the data more effectively. Through multiple layers of nonlinear transformations and activation functions, they can filter and process noise and outliers to some extent. However, they have high computational complexity, difficulties in hyperparameter tuning, and low interpretability. Online deep learning algorithms typically have numerous hyperparameters and higher computational complexity, especially when dealing with large-scale data, requiring significant time and computational costs. Additionally, the prediction process of online deep learning models is more opaque, making it relatively difficult to explain the basis of the model’s decisions.
6. Algorithm Complexity and Scalability Analysis
6.1. Offline Learning Based Data Stream Anomaly Detection Algorithm
- K-means algorithm:
- Time complexity: O(n∗k∗I∗d), where n is the number of data points, k is the number of clusters, I is the number of iterations, and d is the dimensionality of the data.
- Space complexity: O(n∗d), as it requires storing the feature vectors of all data points.
- Scalability: The scalability of the k-means algorithm in data streaming scenarios is relatively poor. It requires traversing all data points and updating cluster centers. For large data streams or high update frequencies, it can result in significant computational and storage overhead.
- KNN algorithm:
- Time complexity: O(n∗m∗d), where n is the number of data points, m is the number of training samples, and d is the dimensionality of the data.
- Space complexity: O(n∗d), as it needs to store the feature vectors of all data points.
- Scalability: The KNN algorithm has relatively poor scalability in data streaming scenarios. It requires traversing all data points and calculating distances. As the data stream increases, the computational and storage overheads keep growing.
- LOF algorithm:
- Time complexity: O(n2∗d), where n is the number of data points, and d is the dimensionality of the data.
- Space complexity: O(n∗d), as it needs to store the feature vectors of all data points.
- Scalability: The LOF algorithm has relatively poor scalability in data streaming scenarios. It requires traversing all data points and calculating distances. As the data stream increases, the computational and storage overheads keep growing.
- OCSVM algorithm:
- Time complexity: O(n2∗d) or O(n3∗d), where n is the number of data points, and d is the dimensionality of the data.
- Space complexity: O(n∗d). It needs to store the kernel matrix.
- Scalability: The traditional OCSVM algorithm has poor scalability in data-streaming scenarios. Since OCSVM is trained on finite samples, each time a new sample arrives, the entire model needs to be retrained, including solving the quadratic programming problem. This leads to increased time and computational resource overheads with growing data, limiting the scalability of OCSVM.
- iForest algorithm:
- Time complexity: O(n∗m∗log(n)), where n is the number of data points, and m is the number of trees. The average time complexity for constructing a single isolation tree is O(n∗log(n)).
- Space complexity: O(n∗m), as it needs to store the input data and the collection of isolation trees.
- Scalability: The iForest algorithm has a time complexity linearly dependent on the number of data points, making it suitable for handling large-scale data. Additionally, the algorithm can be parallelized efficiently on multi-core processors, further enhancing its scalability.
- RS-Hash algorithm:
- Time complexity: O(1). The RS-Hash algorithm is a hash-based fast anomaly detection algorithm. For each incoming data point, it only requires hash computations and comparison operations, resulting in constant time complexity.
- Space complexity: O(m), as it needs to store the hash table and related data structures, where m is the size of the hash table.
- Scalability: The traditional RS-Hash algorithm exhibits good scalability in data streaming scenarios. It only requires simple hash computations and comparison operations for each incoming data point, making it suitable for high-throughput data stream scenarios.
- DeepAnT algorithm:
- Time complexity: Depends on the architecture and number of parameters of the deep neural network. Training deep neural networks usually requires significant computational resources and time, resulting in high time complexity.
- Space complexity: The algorithm needs to store the parameters of the trained deep neural network, and the space complexity is usually high.
- Scalability: The DeepAnT algorithm has relatively poor scalability in data streaming scenarios. The training and inference processes of deep neural networks are typically time-consuming, and as the data stream increases, the computational and storage overheads significantly increase.
- SISVAE algorithm:
- Time complexity: The time complexity of the SISVAE algorithm depends on the structure and training process of the Variational Autoencoder (VAE). Typically, VAE training requires significant computational resources and time, resulting in a high time complexity.
- Space complexity: The algorithm needs to store the parameters of the trained VAE, and its space complexity depends on the network structure and the number of parameters, which is usually high.
- Scalability: The SISVAE algorithm exhibits relatively poor scalability in data-streaming scenarios. The training and inference processes of the VAE are typically time consuming, and as the data stream increases, the computational and storage overheads significantly increase.
- GANomaly algorithm:
- Time complexity: Training Generative Adversarial Networks (GAN) usually requires substantial computational resources and time, resulting in a high time complexity.
- Space complexity: The algorithm needs to store the parameters of the trained generators and discriminators, and the space complexity is usually high.
- Scalability: GANomaly algorithms are relatively less scalable in data streaming scenarios. The training and inference processes of generating adversarial networks are typically time consuming, and as the data stream increases, the computational and storage overheads significantly increase.
- AEAD algorithm:
- Time complexity: Multiple iterations are involved, and each iteration requires passing data through the encoder and decoder. The time complexity depends on the structure and number of parameters of the encoder and decoder and is usually high.
- Space complexity: The Auto-Encoder algorithm needs to store the parameters of the encoder and decoder, and its space complexity depends on the network structure and the number of parameters, which is usually high.
- Scalability: The Auto-Encoder algorithm has good scalability in data streaming scenarios. It can detect anomalies only for new arrivals and does not need to traverse all data points. However, the computation and storage overhead in the training phase may be affected by the model complexity and update frequency.
- The algorithm based on Subspace Partitioning utilizes subspace data structures and has a unique advantage in feature extraction, thus exhibiting the best scalability among the options.
- The algorithm based on the Similarity of Data Distribution has a complexity that is correlated with the statistical characteristics of the data, resulting in relatively good scalability.
- The algorithm based on the Classification Principle typically requires significant computational resources and time for training the classification model, leading to relatively poor scalability.
- The algorithm based on Deep Learning usually involves training and storage issues related to deep neural networks, resulting in the poorest scalability among the types.
6.2. Semi-Online-Learning-Based Data Stream Anomaly Detection Algorithms
- MiLOF algorithm:
- Time complexity: The first stage is to observe the data stream and divide it into several subsets, with a time complexity of O(d∗n), where d is the dimension of the input vector and n is the number of data points. The second stage is to calculate the LOF value of each subset and store it in memory, with a time complexity of O(k∗n∗logn), where k is the maximum number of data points stored in memory. The third stage is to calculate the LOF value of new data points and update the LOF value of subsets, with a time complexity of O(d∗k∗logk). Therefore, the total time complexity of the MiLOF algorithm is O(dn + knlogn + dklogk).
- Space complexity: O(k∗d), the space complexity of the MiLOF algorithm is proportional to the number of data points and the dimension of data points stored in memory.
- Scalability: The MiLOF algorithm has good time complexity and scalability. The algorithm can detect anomalies in real-time data streams and can adapt to datasets of different sizes through batch training.
- NETS algorithm:
- Time complexity: The time complexity of NETS is O((1/a)log(n/a)), where a is the proportion of data points in the micro-cluster and n is the total number of data points.
- Space complexity: The space complexity of NETS is O(d/a), where d is the dimension of non-empty cells in the given window. This is because NETS needs to maintain d-dimensional cells and the neighbor counts of each data point.
- Scalability: The NETS algorithm is highly scalable, even for high-dimensional data streams. In addition, the NETS algorithm can handle multiple data streams and can be extended to different application scenarios.
- EC-SVM algorithm:
- Time complexity: O(n3∗d), where n is the number of training samples and d is the data dimension. The EC-SVM algorithm needs to calculate the kernel matrix and select support vectors and optimize model parameters.
- Space complexity: O(n2∗d), the algorithm needs to store the kernel matrix.
- Scalability: For large-scale datasets and high-dimensional feature spaces, the computational cost of the EC-SVM algorithm is very high, and its scalability is poor. When the sample size and dimension are very large, the algorithm becomes very time consuming, and the memory requirement is also very high.
- Storm algorithm:
- Time complexity: O(N), where N is the amount of data in the sliding window and d is the data dimension. The algorithm processes the data stream using a sliding window, and the window size determines the computational cost of the algorithm.
- Space complexity: O(N), the data window needs to store the data in the sliding window, and the window size determines the storage cost.
- Scalability: The Storm algorithm has good scalability in handling large-scale data streams and scenarios with high real-time requirements. The Storm algorithm uses a sliding window to process data streams, and the algorithm can adapt to continuously incoming new data and perform anomaly detection in real-time or near real-time environments.
- Storm1, 2, 3 algorithms:
- Time complexity: O(log n), where n is the size of the data stream.
- Space complexity: The space complexity is at the level of O(n∗d), where the space complexity of Storm1 is relatively the largest, followed by Storm2, and Storm3 has the smallest space complexity.
- Scalability: The Storm1 algorithm needs to fully store all window objects, so it occupies a lot of memory space, and its scalability is limited. The Storm2 algorithm reduces accuracy but significantly reduces the space it occupies, improving the algorithm’s scalability. The Storm3 algorithm continues the approach of Storm2 and greatly improves the algorithm’s scalability, making it suitable for time- and space-constrained scenarios.
- MCOD algorithm:
- Time complexity: O((1/a)∗log2(n/a)), where a is the proportion of data points in the micro-cluster, and n is the total number of data points.
- Space complexity: O(d∗log(n/a)), where d is the dimension of non-empty cells in the given window.
- Scalability: The MCOD algorithm has relatively low time and space complexity, making it moderately scalable.
- pMCOD algorithm:
- Algorithm complexity: The pMCOD algorithm can process data streams in parallel, and its specific time and space complexity depend on the implementation and characteristics of the dataset. Therefore, the time and space complexity are not mentioned in the corresponding articles. However, it has been proven to be an efficient algorithm with lower complexity than the MCOD algorithm.
- Scalability: The pMCOD algorithm improves scalability by introducing parallelization. It divides the dataset into multiple subsets and processes them simultaneously, thereby improving scalability. The pMCOD algorithm is superior to the MCOD algorithm in terms of time complexity, space complexity, and scalability, and it can effectively handle large datasets.
- DILOF algorithm:
- Time complexity: O(1), the DILOF algorithm uses density-based sampling and a new strategy called “skip scheme” to greatly reduce the time complexity.
- Space complexity: Approximately O(n∗d), where n is the data volume and d is the data dimension.
- Scalability: The DILOF algorithm has good scalability. The detection stage of the DILOF algorithm uses an incremental approach and the skip scheme, which avoids excessive time complexity when updating neighborhood information upon inserting new data points, thereby maintaining high efficiency in processing large amounts of data.
- CODS algorithm:
- Algorithm complexity: The CODS algorithm can process data streams in parallel, and its specific time and space complexity depend on the implementation and characteristics of the dataset. Therefore, the time and space complexity are not mentioned in the corresponding articles.
- Scalability: The CODS algorithm has an advantage in scalability. By utilizing the parallel computing capability of GPUs, the algorithm can handle multiple concurrent data streams and perform anomaly detection in a shorter time. Furthermore, with the improvement of GPU computing power, the performance of the algorithm can be further enhanced.
- iForestASD algorithm:
- Time complexity: O(N∗m∗h), where N is the number of data points in the window, m is the number of trees, and h is the average height of the trees. The time complexity of the iForestASD algorithm depends on the number of data points in the window and the number of trees.
- Space complexity: O(N∗m∗d), where d is the data dimension. The space complexity of the iForestASD algorithm is related to the size of the data in the window, the number of trees, and the feature dimension of newly arrived data points.
- Scalability: The iForestASD algorithm has good scalability. The algorithm uses a sliding window approach to handle streaming data, allowing real-time updates of the isolation forest model and calculation of anomaly scores, thus being able to adapt to continuously incoming new data.
- LSHiforest algorithm:
- Algorithm complexity: The time and space complexity of the LSHiforest algorithm are not mentioned in the corresponding articles. However, overall, the algorithm has low complexity and is related to the data volume and data dimension in the window.
- Scalability: The LSHiforest algorithm has good scalability. The algorithm has low complexity and is not sensitive to parameters, making it suitable for scalable anomaly detection.
- In the category of algorithms using offline training combined with incremental updates:
- The algorithm based on subspace partitioning utilizes subspace data structures, providing a unique advantage in feature extraction. Consequently, it exhibits the best scalability among the other three types.
- The algorithm based on the similarity of data distribution has complexity that correlates with the statistical characteristics of the data, resulting in relatively good scalability compared to the other three types.
- In the category of algorithms using offline training combined with batch updates:
- The algorithm based on the similarity of data distribution has complexity that is related to the statistical characteristics of the data, leading to relatively poorer scalability compared to the other three types.
- The algorithm based on the classification principle typically requires more computational resources and time for model training, resulting in the worst scalability among the other three types.
6.3. Online-Learning-Based Data Stream Anomaly Detection Algorithms
- osPCA algorithm:
- Time complexity: O(d2∗k), where d is the dimensionality of the data stream, and k is the number of computed principal components.
- Space complexity: O(d). The algorithm updates the principal directions by copying target instances and does not require storing the entire covariance matrix or dataset.
- Scalability: The scalability of the osPCA algorithm is relatively poor. In large-scale data stream environments, the computational cost of updating the principal directions limits its scalability.
- OSHULL algorithm:
- Time complexity: O(n), where n is the number of normal data points. With new normal data arrivals, the OSHULL algorithm can avoid recomputing the convex hull through online adaptivity.
- Space complexity: O(n/m), where m is the number of nodes. The OSHULL algorithm needs to store convex hull and data point information, so its space complexity is proportional to the size of the dataset. However, the algorithm uses a distributed approach by dividing the dataset into multiple parts, which reduces the storage requirements per node through average allocation.
- Scalability: The OSHULL algorithm has good scalability. The algorithm can adaptively adjust the convex hull, making it capable of handling different types and distributions of data. Additionally, since the dataset can be processed in a distributed manner, the algorithm can be applied to large-scale distributed systems.
- Matrix Sketch-Based Data Stream Anomaly Detection Algorithm:
- Time complexity: The time complexity mainly depends on the size of the matrix sketch and the rate of the data stream. The update and query operations of the matrix sketch are usually constant time complexity (O(1)). Therefore, the time complexity of the algorithm is typically linear or close to linear, i.e., O(n), where n is the size or length of the data stream.
- Space complexity: The matrix sketch is a highly space-efficient data structure that typically requires minimal memory to store the sketch’s state. Therefore, the space complexity of the algorithm is usually constant, i.e., O(1) or O(k), where k is the size of the matrix sketch.
- Scalability: This algorithm generally has good scalability. The operations of the matrix sketch can be parallelized, allowing for easy parallelization of the algorithm to handle large-scale data streams. The size of the matrix sketch can also be adjusted as needed to accommodate different scales of data streams.
- VFDT algorithm:
- Time complexity: O(dvc), where d is the number of attributes, v is the maximum number of values per attribute, and c is the number of classes.
- Space complexity: O(ldv∗c), where l is the number of leaves in the tree.
- Scalability: The VFDT algorithm has good scalability. It employs incremental learning, allowing it to handle large-scale data streams without loading the entire dataset into memory.
- CVFDT algorithm, HAT algorithm:
- Time complexity: In CVFDT and HAT algorithms, for each new sample, the algorithm determines whether to expand the current tree by computing the Hoeffding bound. Therefore, the time complexity of the algorithm is typically approximately constant, i.e., O(1).
- Space complexity: In CVFDT and HAT algorithms, each node only stores relevant statistical information rather than the complete dataset. Therefore, the space complexity of the algorithm is typically approximately constant, i.e., O(1). However, the HAT algorithm incorporates an adaptive sliding window that avoids storing excess window data, resulting in lower space complexity compared to the CVFDT algorithm.
- Scalability: Both CVFDT and HAT algorithms have excellent scalability, maintaining model consistency and accuracy when processing large amounts of data.
- EFDT algorithm, GAHT algorithm:
- Time complexity: Both algorithms have a similar time complexity of O(dvc∗h), where d is the number of attributes, v is the maximum number of values per attribute, c is the number of classes, and h is the maximum depth of the tree. However, the GAHT algorithm incorporates pruning operations, resulting in lower time complexity compared to the EFDT algorithm.
- Space complexity: Both algorithms have a similar space complexity of O(ldv∗c), where l is the number of leaves in the tree. However, the GAHT algorithm incorporates pruning operations, resulting in lower space complexity compared to the EFDT algorithm.
- Scalability: The EFDT algorithm and GAHT algorithm have excellent scalability. The algorithms have low complexity. Additionally, the EFDT algorithm and GAHT algorithm can be combined with other incremental learning algorithms to further improve their scalability and adaptability.
- Online Deep Learning-Based Data Stream Anomaly Detection Algorithm:
- Algorithm complexity: Examples of online deep learning anomaly detection algorithms, such as the ADA algorithm, DAGGM algorithm, ARCUS algorithm, and S-DPS algorithm, generally have variable time and space complexity. Their complexity depends on the type of deep neural network model and the training process, which is typically high.
- Scalability: Online deep learning-based anomaly detection algorithms have overall poor scalability. The training and updating processes of deep neural networks require significant computational resources and time, limiting the scalability of the algorithms. Handling large-scale data streams may require techniques such as distributed computing or model compression to improve scalability.
- Online deep learning algorithms generally have lower scalability compared to online shallow learning algorithms. This is because deep learning algorithms often involve the training and storage of deep neural networks, which adversely affects the scalability of online deep learning algorithms.
- Among online shallow learning algorithms: Those based on matrix sketch algorithms convert data calculations into matrix sketch calculations, providing unique advantages in terms of complexity and scalability. Thus, they have the best scalability. Those based on decision tree algorithms do not require normalization and have unique advantages in feature extraction, resulting in relatively good scalability. Those based on Similarity of Data Distribution algorithms have complexity related to statistical features of the data, requiring normalization and feature extraction steps, resulting in relatively poor scalability compared to the other three categories.
- Offline-learning-based data stream anomaly detection algorithms
- Low scalability: Offline-learning-based algorithms typically require batch processing and model training over the entire dataset, which can pose computational and storage challenges for large-scale datasets or high-speed data streams.
- Difficult to adapt to changes in real time: Since the algorithms are trained offline, they may not adapt to new patterns or changing concepts in the data stream in a timely manner, requiring retraining of the entire model.
- Semi-online-learning-based data stream anomaly detection algorithms:
- High scalability: Semi-online-learning-based algorithms typically adapt to changes in the data stream through batch updates or incremental updates. They can partially utilize previous models or samples, reducing the computational and storage requirements and thus improving scalability.
- Relatively real-time adaptability: The algorithms can adapt to changes in the data stream to some extent through incremental updates or partial retraining, capturing changes in new patterns or concepts.
- Online-learning-based data stream anomaly detection algorithms:
- Highly scalable: Online learning-based algorithms generally have good scalability, enabling real-time processing of large-scale data streams and model updates.
- Real-time adaptability: Since the algorithms learn and update the model gradually on the data stream, they can promptly adapt to changes in the data stream, providing good real-time performance.
7. Application of Data Stream Anomaly Detection Algorithms
7.1. Application Scenarios of Data Stream Anomaly Detection Algorithms
- Algorithm Based on Offline Learning for Data Stream Anomaly Detection
- Significance and value: By using complete historical data for model training, it is possible to obtain relatively accurate anomaly detection models. This algorithm is suitable for scenarios that involve analyzing historical data and detecting anomalies and can be used for post-analysis, investigation, and predicting future abnormal behavior.
- Applicable business scenarios: Business scenarios involving batch data analysis. When data streams arrive in batches and can be processed offline as a whole dataset, an algorithm based on offline learning is a suitable choice. It is applicable for analyzing historical data and detecting anomalies in scenarios such as financial fraud detection and network intrusion detection.
- Algorithm Based on Semi-Online Learning for Data Stream Anomaly Detection
- Significance and value: Semi-online learning algorithms combine the advantages of offline and online learning, providing flexibility and adaptability. These algorithms use historical data for training during the initialization phase and adapt to new anomaly types during subsequent online learning.
- Applicable business scenarios: Business scenarios where data stream properties change slowly. When the properties of a data stream change relatively slowly and the types of anomalies remain stable, an algorithm based on semi-online learning can be trained using historical data during the initialization phase and adapted to new anomaly types during subsequent online learning. It is suitable for scenarios where there is some expectation or prior knowledge of new anomaly types, such as network traffic analysis and equipment failure detection.
- Algorithm Based on Online Learning for Data Stream Anomaly Detection
- Significance and value: Online learning algorithms provide real-time capabilities as they learn directly from data streams, enabling timely detection and handling of new anomalies. This algorithm can be used for real-time monitoring, fault detection, and timely warnings.
- Applicable business scenarios: Business scenarios requiring real-time anomaly detection. When there is a need to detect and respond to anomalies in data streams in real time, and when the properties and types of anomalies in the data stream may change frequently, an algorithm based on online learning is a suitable choice. This algorithm can learn and adapt in real time to changing data and anomaly types. It is applicable in scenarios with high requirements for real-time capabilities, such as smart IoT systems and network security monitoring.
7.2. Significance, Value, and Potential Impact of Using Data Stream Anomaly Detection Algorithms
- Enhanced security and risk reduction: Abnormal behaviors may indicate potential security threats or risk signals. By using data stream anomaly detection algorithms, abnormal behaviors can be detected in a timely manner, thereby improving security and reducing potential risks. For example, in the field of network security, anomaly detection algorithms can be used to identify malicious attacks or abnormal traffic.
- Improved business efficiency: Abnormal behaviors can lead to business interruptions, resource waste, or decreased production efficiency. By monitoring and detecting abnormal behaviors in real time, measures can be taken promptly to address the issues, thus enhancing business efficiency. For example, in manufacturing, anomaly detection algorithms can be used to detect equipment failures or production abnormalities, allowing for timely adjustments to production plans.
- Achieving intelligent decision making and optimization: Anomaly detection algorithms can provide detailed information and insights about abnormal behaviors, supporting intelligent decision making and business optimization. By analyzing patterns and trends in abnormal behavior, underlying causes of potential issues can be identified, and appropriate measures can be taken for improvement and optimization.
- Cost and resource savings: Timely detection and handling of abnormal behaviors can reduce potential losses and costs. Anomaly detection algorithms can help identify anomalous data points, events, or behaviors, thereby reducing resource waste and minimizing the need for manual intervention.
- False positives and false negatives: Unreasonable algorithm selection or parameter settings can result in false positives (misclassifying normal behavior as anomalous) or false negatives (failing to detect true anomalies), affecting normal business operations and the accuracy of decision making.
- Data quality and accuracy: Anomaly detection algorithms require high data quality and accuracy. Issues such as noise, missing data, or incorrect labeling in input data can decrease the accuracy of anomaly detection, thus impacting the performance and results of the algorithm.
- Resource requirements and performance: Different anomaly detection algorithms have varying demands for computational resources, memory, and storage. Some algorithms may be slow in processing large-scale data streams or require high computing resources, which can limit their scalability and performance in practical applications.
- Model training and updating: In offline learning and semi-online learning algorithms, the training and updating processes of models can consume significant time and computational resources. This can pose challenges in large-scale data streams or real-time application scenarios and may result in delays or untimely anomaly detection.
- Interpretability of the algorithm: Some anomaly detection algorithms may be difficult to interpret in terms of their basis and reasoning for classifying anomalies. This can pose challenges in business decision making and problem troubleshooting. In certain industries, such as finance, there is a higher demand for the interpretability of anomaly detection results.
- Data privacy and security: Data stream anomaly detection involves monitoring and analyzing real-time data, raising concerns about user privacy and data security. Ensuring data confidentiality and security are important aspects that require special attention in practical applications.
8. Future Research Directions
8.1. Future Research Directions of the Authors
- According to the paper, all the involved data stream anomaly detection algorithms will be conducted by experiments. With unified data sets, each algorithm will be analyzed qualitatively and quantitatively. On the basis of the analysis, the similarities and differences of algorithms and their practical application scenarios could be reached.
- A new data stream anomaly detection algorithm is proposed on the basis of the Hoeffding tree algorithm. The algorithm has the following features: (1) green and energy efficient; (2) based on online learning; (3) anti-concept drift.
8.2. Future Research Challenges
- Difficulties based on global information settings and partial information settings. The data under the data stream are usually massive and infinite, and it is hard to store all the data in the practical application scenario, which we called global information. Some algorithms use staged data batch processing methods for data streams, or periodically retrain anomaly detection models in order to obtain global information about the input data; as a result, anomaly detection for streaming data could be reached. However, in practical applications where data streams are becoming increasingly massive, global information about the data is becoming increasingly unavailable. Therefore, it is expected that the anomaly detection of the model and the update of the model are performed simultaneously, which is very difficult in real streaming data scenarios.
- On the basis of the difficulty of three parties balance including the speed of data stream, the speed of algorithm operation, and the accuracy. One of the characteristics of data streams is that they are fast. If anomaly detection is to be performed in real time on fast incoming data, it means that the anomaly detection algorithm must also be fast, but it always costs the accuracy of the algorithm. So, the way in which to strike the balance is also one of the difficulties of anomaly detection in data streams.
- The difficulty of the concept drift caused by data flow. Data stream anomaly detection algorithms all work in dynamic environments where data flow continuously. If the data distribution of a data stream is random, it would lead the target concept may change over time. However, most of the existing machine-learning-based work on data stream anomaly detection algorithms assume that the training samples are randomly generated according to some smooth probability distribution. The way in which to optimize the algorithm in the context of streaming data scenarios so that it has the ability to resist concept drift is necessary.
8.3. Future Research Directions
- Real-time processing and learning capabilities. In anomaly detection algorithms for data streams, the ability to detect anomalies in real time or near real time and to update their own models in real time is crucial as data flow continuously. Therefore, on the basis of the idea of online learning and combined with different machine learning models, developing anomaly detection models with more powerful anomaly detection performance is a possible direction. Currently, the literature [62,63] has made some preliminary explorations on this issue. However, more advanced exploration and utilization balancing strategies and more advanced model update rules can be used to design more effective algorithms.
- Purification processing capabilities for data streams. In practical application scenarios of streaming data, data are generally high dimensional, redundant, and even repetitive. Therefore, combining the ideas of undersampling, oversampling, or mixed sampling [41] to preprocess data streams, selecting more valuable data for training anomaly detection models, may make anomaly detection more accurate. Currently, there is little research on this issue, and there is an urgent need to fill this gap.
- Window or incremental methods. On the basis of the idea of sliding windows and incremental processing, by modifying or combining existing batch anomaly detection algorithms, and processing and retaining only the most recent observation values when data streams arrive, storage requirements of devices can be reduced, the computational cost and storage cost of anomaly detection algorithms can be reduced, and the running time of the model can be shortened.
- Dynamic adaptive threshold selection. Generally, anomaly detection methods for data streams set a fixed threshold for anomaly detection. However, the fixed threshold may not be effective for different data distributions or different time periods. Therefore, dynamically selecting an adaptive threshold on the basis of the current data distribution or time period may be a possible direction.
- Interpretability of algorithm models. When solving real-world problems such as data anomaly detection, anomaly detection models often face challenges of mistrust, opacity, and difficulty of improvement. Moreover, in practical applications, it is often not sufficient to only detect anomalies. Especially in critical application areas, it is more desirable to discover the specific reasons for anomalies in order to further address the anomalies. Model interpretation techniques can effectively address the above issues. One important direction for future exploration is how to integrate model interpretation techniques into data stream anomaly detection algorithm models.
- The issue of improving algorithm model energy efficiency. Data stream anomaly detection algorithm models typically require real-time processing and analysis of large-scale data streams. If the algorithm models can enhance energy efficiency, it will reduce the required computational resources and energy consumption. This helps to reduce energy usage, decrease the demand for power supply, and consequently alleviate environmental pressures. Simultaneously, it holds significant importance for businesses and organizations as improving energy efficiency translates to enhancing economic benefits and competitiveness. Recently, the authors of [64] conducted preliminary explorations on the energy efficiency of algorithm models.
9. Summary and Future Directions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Korycki, Ł.; Cano, A.; Krawczyk, B. Active Learning with Abstaining Classifiers for Imbalanced Drifting Data Streams. In Proceedings of the 2019 IEEE International Conference on Big Data (Big Data), Los Angeles, CA, USA, 9–13 December 2019; IEEE: New York, NY, USA, 2019; pp. 2334–2343. [Google Scholar]
- Bhatia, S.; Jain, A.; Li, P.; Kumar, R.; Hooi, B. MSTREAM: Fast Anomaly Detection in Multi-Aspect Streams. In Proceedings of the Web Conference, Ljubljana, Slovenia, 19–23 April 2021; Volume 2021, pp. 3371–3382. [Google Scholar]
- Zubaroğlu, A.; Atalay, V. Data stream clustering: A review. Artif. Intell. Rev. 2021, 54, 1201–1236. [Google Scholar] [CrossRef]
- Bahri, M.; Bifet, A.; Gama, J.; Gomes, H.M.; Maniu, S. Data stream analysis: Foundations, major tasks and tools. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2021, 11, e1405. [Google Scholar] [CrossRef]
- Habeeb, R.A.A.; Nasaruddin, F.; Gani, A.; Hashem, I.A.T.; Ahmed, E.; Imran, M. Real-time big data processing for anomaly detection: A survey. Int. J. Inf. Manag. 2019, 45, 289–307. [Google Scholar] [CrossRef]
- Himeur, Y.; Ghanem, K.; Alsalemi, A.; Bensaali, F.; Amira, A. Artificial intelligence based anomaly detection of energy consumption in buildings: A review, current trends and new perspectives. Appl. Energy 2021, 287, 116601. [Google Scholar] [CrossRef]
- Barz, B.; Rodner, E.; Garcia, Y.G.; Denzler, J. Detecting regions of maximal divergence for spatio-temporal anomaly detection. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 41, 1088–1101. [Google Scholar] [CrossRef]
- Marteau, P.F. Random partitioning forest for point-wise and collective anomaly detection—Application to network intrusion detection. IEEE Trans. Inf. Secur. 2021, 16, 2157–2172. [Google Scholar] [CrossRef]
- Din, S.U.; Shao, J.; Kumar, J.; Mawuli, C.B.; Mahmud, S.M.H. Data stream classification with novel class detection: A review, comparison and challenges. Knowl. Inf. Syst. 2021, 63, 2231–2276. [Google Scholar] [CrossRef]
- Wang, H.; Bah, M.J.; Hammad, M. Progress in outlier detection techniques: A survey. IEEE Access 2019, 7, 107964–108000. [Google Scholar] [CrossRef]
- Eltanbouly, S.; Bashendy, M.; AlNaimi, N.; Chkirbene, Z.; Erbad, A. Machine Learning Techniques for Network Anomaly Detection: A Survey. In Proceedings of the 2020 IEEE International Conference on Informatics, IoT, and Enabling Technologies (ICIoT), Dawḥah, Qatar, 2–5 February 2020; IEEE: New York, NY, USA, 2020; pp. 156–162. [Google Scholar]
- Taha, A.; Hadi, A.S. Anomaly detection methods for categorical data: A review. ACM Comput. Surv. (CSUR) 2019, 52, 1–35. [Google Scholar] [CrossRef]
- Nassif, A.B.; Talib, M.A.; Nasir, Q.; Dakalbab, F.M. Machine learning for anomaly detection: A systematic review. IEEE Access 2021, 9, 78658–78700. [Google Scholar] [CrossRef]
- Pang, G.; Shen, C.; Cao, L.; Hengel, A.V.D. Deep learning for anomaly detection: A review. ACM Comput. Surv. (CSUR) 2021, 54, 1–38. [Google Scholar] [CrossRef]
- Blázquez-García, A.; Conde, A.; Mori, U.; Lozano, J.A. A review on outlier/anomaly detection in time series data. ACM Comput. Surv. (CSUR) 2021, 54, 1–33. [Google Scholar] [CrossRef]
- Cook, A.A.; Mısırlı, G.; Fan, Z. Anomaly detection for IoT time-series data: A survey. IEEE Internet Things J. 2019, 7, 6481–6494. [Google Scholar] [CrossRef]
- Salechi, M.; Rashidi, L. A survey on anomaly detection in evolving data. ACM SIGKDD Explor. Newsl. 2018, 20, 13–23. [Google Scholar] [CrossRef]
- Souiden, I.; Omri, M.N.; Brahmi, Z. A survey of outlier detection in high dimensional data streams. Comput. Sci. Rev. 2022, 44, 100463. [Google Scholar] [CrossRef]
- Hartigan, J.A.; Wong, M.A. Algorithm AS 136: A k-means clustering algorithm. Appl. Stat. 1979, 28, 100–108. [Google Scholar] [CrossRef]
- Cover, T.; Hart, P. Nearest neighbor pattern classification. IEEE Trans. Inf. Theory 1967, 13, 21–27. [Google Scholar] [CrossRef]
- Breunig, M.M.; Kriegel, H.P.; Ng, R.T.; Sander, J. LOF: Identifying density-based local outliers. ACM SIGMOD Rec. 2000, 16, 93–104. [Google Scholar] [CrossRef]
- Tax, D.M.J.; Duin, R.P.W. Support vector data description. Mach. Learn. 2004, 54, 45–66. [Google Scholar] [CrossRef]
- Liu, F.T.; Ting, K.M.; Zhou, Z.H. Isolation Forest. In Proceedings of the 2008 Eighth IEEE International Conference on Data Mining, Pisa, Italy, 15–19 December 2008; IEEE: New York, NY, USA, 2008; pp. 413–422. [Google Scholar]
- Sathe, S.; Aggarwal, C.C. Subspace Outlier Detection in Linear Time with Randomized Hashing. In Proceedings of the 2016 IEEE 16th International Conference on Data Mining (ICDM), Barcelona, Spain, 12–16 December 2016; IEEE: New York, NY, USA, 2016; pp. 459–468. [Google Scholar]
- Munir, M.; Siddiqui, S.A.; Dengel, A.; Ahmed, S. DeepAnT: A deep learning approach for unsupervised anomaly detection in time series. IEEE Access 2018, 7, 1991–2005. [Google Scholar] [CrossRef]
- Li, L.; Yan, J.; Wang, H.; Jin, Y. Anomaly detection of time series with smoothness-inducing sequential variational auto-encoder. IEEE Trans. Neural Netw. Learn. Syst. 2020, 32, 1177–1191. [Google Scholar] [CrossRef] [PubMed]
- Akcay, S.; Atapour-Abarghouei, A.; Breckon, T.P. Ganomaly: Semi-Supervised Anomaly Detection via Adversarial Training. In Proceedings of the Computer Vision–ACCV 2018, 14th Asian Conference on Computer Vision, Perth, Australia, 2–6 December 2018; Revised Selected Papers, Part III 14. Springer International Publishing: Berlin/Heidelberg, Germany, 2019; pp. 622–637. [Google Scholar]
- Shafiq, U.; Shahzad, M.K.; Anwar, M.; Shaheen, Q.; Shiraz, M.; Gani, A. Transfer Learning Auto-Encoder Neural Networks for Anomaly Detection of DDoS Generating IoT Devices. Secur. Commun. Netw. 2022, 2022, 8221351. [Google Scholar] [CrossRef]
- Salehi, M.; Leckie, C.; Bezdek, J.C.; Vaithianathan, T.; Zhang, X. Fast memory efficient local outlier detection in data streams. IEEE Trans. Knowl. Data Eng. 2016, 28, 3246–3260. [Google Scholar] [CrossRef]
- Yoon, S.; Lee, J.G.; Lee, B.S. NETS: Extremely fast outlier detection from a data stream via set-based processing. Proc. VLDB Endow. 2019, 12, 1303–1315. [Google Scholar] [CrossRef]
- Amer, M.; Goldstein, M.; Abdennadher, S. Enhancing One-Class Support Vector Machines for Unsupervised Anomaly Detection. In Proceedings of the ACM SIGKDD Workshop on Outlier Detection and Description, Chicago, IL, USA, 11 August 2013; pp. 8–15. [Google Scholar]
- Angiulli, F.; Fassetti, F. Detecting distance-based outliers in streams of data. In Proceedings of the Sixteenth ACM Conference on Information and Knowledge Management, Lisbon, Portugal, 6–10 November 2007; pp. 811–820. [Google Scholar]
- Angiulli, F.; Fassetti, F. Distance-based outlier queries in data streams: The novel task and algorithms. Data Min. Knowl. Discov. 2010, 20, 290–324. [Google Scholar] [CrossRef]
- Kontaki, M.; Gounaris, A.; Papadopoulos, N.; Tsichlas, K.; Manolopoulos, Y. Continuous Monitoring of Distance-Based Outliers over Data Streams. In Proceedings of the IEEE 27th International Conference on Data Engineering, Hannover, Germany, 11–16 April 2011; pp. 135–146. [Google Scholar]
- Kontaki, M.; Gounaris, A.; Papadopoulos, N.; Tsichlas, K.; Manolopoulos, Y. Effificient and flflexible algorithms for monitoring distance-based outliers over data streams. Inf. Syst. 2016, 55, 37–53. [Google Scholar] [CrossRef]
- Toliopoulos, T.; Gounaris, A.; Tsichlas, K.; Papadopoulos, A.; Sampaio, S. Continuous outlier mining of streaming data in flink. Inf. Syst. 2020, 93, 101569. [Google Scholar] [CrossRef]
- Na, G.S.; Kim, D.; Yu, H. Dilof: Effective and Memory Efficient Local Outlier Detection in Data Streams. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, London, UK, 19–23 August 2018; pp. 1993–2002. [Google Scholar]
- Borah, A.; Gruenwald, L.; Leal, E.; Panjei, E. A GPU Algorithm for Detecting Contextual Outliers in Multiple Concurrent Data Streams. In Proceedings of the 2021 IEEE International Conference on Big Data (Big Data), Virtual Conference, 15–18 December 2021; pp. 2737–2742. [Google Scholar]
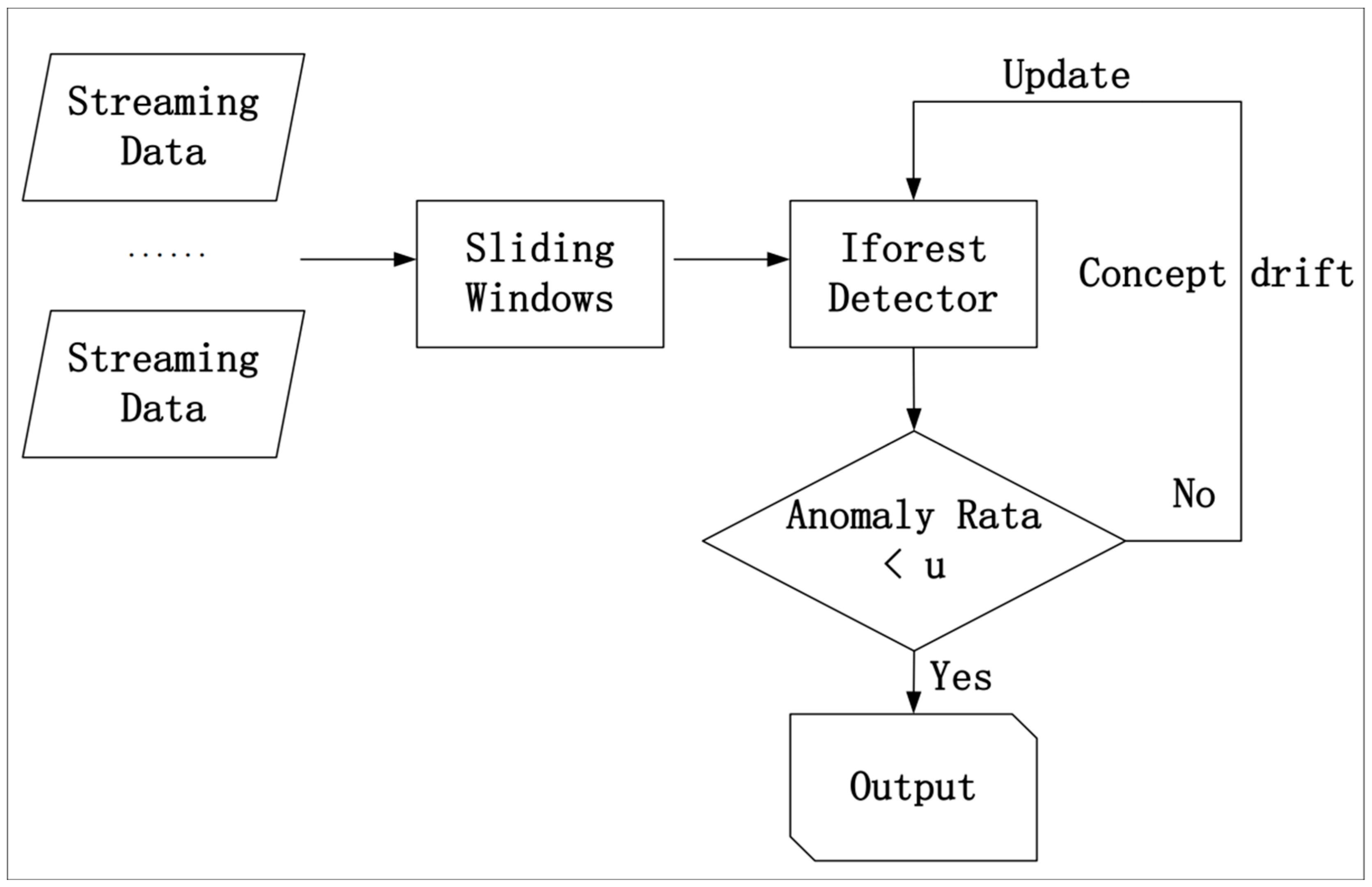
- Ding, Z.; Fei, M. An anomaly detection approach based on isolation forest algorithm for streaming data using sliding window. IFAC Proc. Vol. 2013, 46, 12–17. [Google Scholar] [CrossRef]
- Sun, H.; He, Q.; Liao, K.; Sellis, T.; Guo, L.; Zhang, X.; Shen, J.; Chen, F. Fast Anomaly Detection in Multiple Multi-Dimensional Data Streams. In Proceedings of the 2019 IEEE International Conference on Big Data (Big Data), Los Angeles, CA, USA, 9–13 December 2019; IEEE: New York, NY, USA, 2019; pp. 1218–1223. [Google Scholar]
- Lee, Y.J.; Yeh, Y.R.; Wang YC, F. Anomaly detection via online oversampling principal component analysis. IEEE Trans. Knowl. Data Eng. 2012, 25, 1460–1470. [Google Scholar] [CrossRef]
- Novoa-Paradela, D.; Fontenla-Romero, O.; Guijarro-Berdiñas, B. Online Learning for Anomaly Detection via Subdivisible Convex Hulls. In Proceedings of the 2020 International Joint Conference on Neural Networks (IJCNN), Glasgow, UK, 19–24 July 2020; IEEE: New York, NY, USA, 2020; pp. 1–8. [Google Scholar]
- Huang, H.; Kasiviswanathan, S.P. Streaming anomaly detection using randomized matrix sketching. Proc. VLDB Endow. 2015, 9, 192–203. [Google Scholar] [CrossRef]
- Chen, H.; Chen, P.; Yu, G. A framework of virtual war room and matrix sketch-based streaming anomaly detection for microservice systems. IEEE Access 2020, 8, 43413–43426. [Google Scholar] [CrossRef]
- Hulten, G.; Spencer, L.; Domingos, P. Mining Time-Changing Data Streams. In Proceedings of the Seventh ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 26–29 August 2001; pp. 97–106. [Google Scholar]
- Bifet Figuerol, A.C.; Gavaldà Mestre, R. Adaptive Parameter-Free Learning from Evolving Data Streams; UPC Universitat Politècnica de Catalunya: Barcelona, Spain, 2009. [Google Scholar]
- Manapragada, C.; Webb, G.I.; Salehi, M. Extremely Fast Decision Tree. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, London, UK, 19–23 August 2018; pp. 1953–1962. [Google Scholar]
- Garcia-Martin, E.; Bifet, A.; Lavesson, N.; König, R.; Linusson, H. Green Accelerated Hoeffding Tree. arXiv 2022, arXiv:2205.03184. [Google Scholar]
- Sahoo, D.; Pham, Q.; Lu, J.; Hoi, S.C. Online Deep Learning: Learning Deep Neural Networks on the Fly. In Proceedings of the 27th International Joint Conference on Artificial Intelligence, Stockholm, Sweden, 13–19 July 2018; AAAI Press: Washington, DC, USA, 2018; pp. 2660–2666. [Google Scholar]
- Yuan, Y.; Adhatarao, S.S.; Lin, M.; Yuan, Y.; Liu, Z.; Fu, X. Ada: Adaptive Deep Log Anomaly Detector. In Proceedings of the IEEE INFOCOM 2020—IEEE Conference on Computer Communications, Virtual, 6–9 July 2020; IEEE: New York, NY, USA; pp. 2449–2458. [Google Scholar]
- Zong, B.; Song, Q.; Min, M.R.; Cheng, W.; Lumezanu, C.; Cho, D.; Chen, H. Deep Autoencoding Gaussian Mixture Model for Unsupervised Anomaly Detection. In Proceedings of the International Conference on Learning Representations, Vancouver, VA, Canada, 30 April–3 May 2018. [Google Scholar]
- Yoon, S.; Lee, Y.; Lee, J.G.; Lee, B.S. Adaptive Model Pooling for Online Deep Anomaly Detection from a Complex Evolving Data Stream. In Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, Washington, DC, USA, 14–18 August 2022; pp. 2347–2357. [Google Scholar]
- Mahmood, H.; Mahmood, D.; Shaheen, Q.; Akhtar, R.; Changda, W. S-DPs: An SDN-based DDoS protection system for smart grids. Secur. Commun. Netw. 2021, 2021, 6629098. [Google Scholar] [CrossRef]
- Agrahari, S.; Singh, A.K. Concept drift detection in data stream mining: A literature review. J. King Saud Univ. Comput. Inf. Sci. 2022, 34, 9523–9540. [Google Scholar] [CrossRef]
- Tellis, V.M.; D’Souza, D.J. Detecting Anomalies in Data Stream Using Efficient Techniques: A Review. In Proceedings of the 2018 International Conference on Control, Power, Communication and Computing Technologies (ICCPCCT), Kannur, India, 23–24 March 2018; IEEE: New York, NY, USA, 2018; pp. 296–298. [Google Scholar]
- Hinton, G.E.; Salakhutdinov, R.R. Reducing the dimensionality of data with neural networks. Science 2006, 313, 504–507. [Google Scholar] [CrossRef]
- Zhang, X.; Dou, W.; He, Q.; Zhou, R.; Leckie, C.; Kotagiri, R.; Salcic, Z. LSHiForest: A Generic Framework for Fast Tree Isolation Based Ensemble Anomaly Analysis. In Proceedings of the 2017 IEEE 33rd International Conference on Data Engineering (ICDE), Los Angeles, CA, USA, 9–12 December 2017; pp. 983–994. [Google Scholar]
- Liberty, E. Simple and Deterministic Matrix Sketching. In Proceedings of the 19th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Chicago, IL, USA, 11–14 August 2013; pp. 581–588. [Google Scholar]
- Halko, P.G.N.; Martinsson, J.; Tropp, A. Finding Structure with Randomness: Probabilistic Algorithms for Constructing Approximate Matrix Decompositions. SIAM Rev. 2011, 4, 53. [Google Scholar] [CrossRef]
- Sahoo, D.; Pham, Q.; Lu, J.; Hoi, S.C. Online deep learning: Learning deep neural networks on the fly. arXiv 2017, arXiv:1711.03705. [Google Scholar]
- Cho, K.; Van Merriënboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning phrase representations using rnn encoder-decoder for statistical machine translation. arXiv 2014, arXiv:1406.1078. [Google Scholar]
- Alrawashdeh, K.; Purdy, C. Fast Hardware Assisted Online Learning Using Unsupervised Deep Learning Structure for Anomaly Detection. In Proceedings of the 2018 International Conference on Information and Computer Technologies (ICICT), Dekalb, IL, USA, 23–25 March 2018; IEEE: New York, NY, USA; pp. 128–134. [Google Scholar]
- Steenwinckel, B.; De Paepe, D.; Hautte, S.V.; Heyvaert, P.; Bentefrit, M.; Moens, P.; Dimou, A.; Bossche, B.V.D. FLAGS: A methodology for adaptive anomaly detection and root cause analysis on sensor data streams by fusing expert knowledge with machine learning. Future Gener. Comput. Syst. 2021, 116, 30–48. [Google Scholar] [CrossRef]
- Khan, M.K.; Shiraz, M.; Shaheen, Q.; Butt, S.A.; Akhtar, R.; Khan, M.A.; Changda, W. Hierarchical routing protocols for wireless sensor networks: Functional and performance analysis. J. Sens. 2021, 2021, 7459368. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithm Type | Algorithm Name and Reference | Advantages | Disadvantages |
|---|---|---|---|
| Based on offline learning | K-means [19]; KNN [20]; LOF [21]; OCSVM [22]; IForest [23]; RS-Hash [24]; DeepAnT [25]; SISVAE [26]; GANomaly [27]; AEAD [28] | Using all available historical data for model training, therefore achieving better performance in anomaly detection. | Cannot handle new data patterns; cannot handle real-time streaming data; requires manual tuning. |
| Based on semi-online learning | MiLOF [29]; NETS [30]; EC-SVM [31]; Storm [32]; Storm1, 2, 3 [33]; MCOD [34,35]; pMCOD [36]; DILOF [37]; CODS [38]; iForestASD [39]; LSHiforest [40]; | Compared with offline learning algorithms, it can adapt to changes in data distribution and save computation time; compared with online learning algorithms, it can use more complex models and algorithms. | The performance of the algorithm depends on the segmentation method of the data stream and the update frequency of the algorithm model. |
| Based on online learning | osPCA [41]; OSHULL [42]; The deterministic flow update algorithm [43]; The stochastic stream update algorithm [43]; A framework of virtual war room and matrix sketch-based streaming anomaly detection [44]; VFDT [45]; CVFDT [46]; HAT [47]; EFDT [48]; GAHT [49]; ADA [50]; DAGMM [51]; ARCUS [52]; S-DPS [53] | Real-time and fast detection of anomalies; ability to adapt to changes in data distribution; low storage cost. | The algorithm is simple but less accurate, and there is instability in real-time processing. |
| Algorithm Type | Algorithm Name and Reference | Advantages | Disadvantages |
|---|---|---|---|
| Based on similarity of data distribution | K-means [19]; KNN [20]; LOF [21] | The detection performance is better for data streams with slowly changing distribution characteristics and high interpretability. | The algorithm requires strict assumptions about the data distribution; there is a “curse of dimensionality” problem for high-dimensional data. |
| Based on classification principle | OCSVM [22] | Strong generalization and high scalability. | Sensitive to noise, prone to false positives; requires labeled anomalies; detection results are limited by the degree of balance between positive and negative samples. |
| Based on subspace partitioning | IForest [23]; RS-Hash [24] | For high-dimensional data, there is no “curse of dimensionality” issue, and there is no need to select features for anomaly detection. | The detection performance is poor for small sample data; the interpretability is low. |
| Based on deep learning | DeepAnT [25]; SISVAE [26]; GANomaly [27]; AEAD [28] | It can automatically learn feature representations, avoiding the subjectivity of manually defining features. | Requires a large amount of data and computational resources and has poor interpretability. |
| Algorithm Type | Algorithm Name and Reference | Advantages | Disadvantages |
|---|---|---|---|
| Offline training combined with batch updates | MiLOF [29]; NETS [30]; EC-SVM [31] | Fixed batch updates can take into account global changes in the dataset, resulting in more accurate models. | Weak sensitivity to time and slow response to novel anomalies. |
| Offline training combined with incremental updates | Storm [33]; Storm1, 2, 3 [34]; MCOD [35,36]; pMCOD [37]; DILOF [38]; CODS [39]; iForestASD [40]; LSHiforest [57] | Each new data point updates the model parameters, resulting in low computational complexity, making it suitable for situations with large data volumes or high data flow rates. | It is difficult to obtain the global distribution of the entire dataset, which may lead to the inaccuracy of the model. |
| Algorithm Type | Algorithm Name and Reference | Advantages | Disadvantages |
|---|---|---|---|
| Based on similarity of data distribution | MiLOF [29]; NETS [30] | Adaptation to statistical properties of data and algorithm simplicity. | For different data distributions, suitable models should be selected for modeling. |
| Based on classification principle | EC-SVM [31] | Classifier output can be used as the anomaly detection score, which facilitates comparison with other anomaly detection algorithms. | To adapt to different datasets, appropriate classifiers need to be selected and tuned. The training results can be affected by imbalanced data distribution. |
| Algorithm Type | Algorithm Name and Reference | Advantages | Disadvantages |
|---|---|---|---|
| Based on similarity of data distribution | Storm [32]; Storm1, 2, 3 [33]; MCOD [34,35]; pMCOD [36]; DILOF [37]; CODS [38] | High interpretability. | When the data distribution exhibits a significant shift, the detection performance will decrease. |
| Based on subspace partitioning | iForestASD [39]; LSHiforest [40] | It is easier to handle high-dimensional data streams, and it is resistant to concept drift. | Low interpretability. |
| Algorithm Type | Algorithm Name and Reference | Advantages | Disadvantages |
|---|---|---|---|
| Online shallow learning | osPCA [41]; OSHULL [42]; The deterministic flow update algorithm [43]; The stochastic stream update algorithm [43]; A framework of virtual war room and matrix sketch-based streaming anomaly detection [44]; VFDT [45]; CVFDT [46]; HAT [47]; EFDT [48]; GAHT [49]; | Strong interpretability, fast computation speed, and strong controllability over anomaly detection. | The detection performance is limited by the data distribution and cannot capture complex abnormal patterns. |
| Online deep learning | ADA [50]; DAGMM [51]; ARCUS [52]; S-DPS [53]; | Adaptable to various data distributions and capable of learning more complex patterns. | High computational complexity and poor interpretability. |
| Algorithm Type | Algorithm Name and Reference | Advantages | Disadvantages |
|---|---|---|---|
| Based on similarity of data distribution | osPCA [41]; OSHULL [42]; | High interpretability. | The detection performance is limited by the data distribution. |
| Based on matrix sketch | The deterministic flow update algorithm [43]; The stochastic stream update algorithm [43]; A framework of virtual war room and matrix sketch-based streaming anomaly detection [44] | Low memory footprint, less sensitive to outliers. | There may be some errors when processing very sparse data. |
| Based on decision trees | VFDT [45]; CVFDT [46]; HAT [47]; EFDT [48]; GAHT [49] | It can adapt to concept drift and changes in the data stream. | Can handle high-dimensional data. |
| Algorithm Type | Algorithm Name and Reference |
|---|---|
| Based on offline learning | Low scalability, difficult to adapt to changes in real time |
| Based on semi-online learning | High scalability, relatively real-time adaptability |
| Based on online learning | Highly scalable, with real-time adaptability |
| Algorithm Type | Algorithm Name and Reference | Time Complexity | Space Complexity | Scalability |
|---|---|---|---|---|
| Based on similarity of data distribution | K-means [19] | O(n∗k∗I∗d) | O(n∗d) | Overall better |
| KNN [20] | O(n∗m∗d) | O(n∗d) | ||
| LOF [21] | O(n2∗d) | O(n∗d) | ||
| Based on classification principle | OCSVM [22] | O(n2∗d) − O(n3∗d) | O(n∗d) | Overall poor |
| Based on subspace partitioning | Iforest [23] | O(n∗m∗log(n)) | O(n∗m) | Overall very good |
| RS-Hash [24] | O(1) | O(m) | ||
| Based on deep learning | DeepAnT [25]; SISVAE [26]; GANomaly [27]; AEAD [28] | _ | _ | Overall very poor |
| Algorithm Type | Algorithm Type (Subtype) | Algorithm Name and Reference | Time Complexity | Space Complexity | Scalability |
|---|---|---|---|---|---|
| Offline training combined with batch updates | Based on similarity of data distribution | MiLOF [29] | O(N∗d) | O(N∗d) | Overall poor |
| NETS [30] | O(log n∗d) | O(n∗d) | |||
| Based on classification principle | EC-SVM [31] | O((1/a)∗log2(n/a)) | O(d∗log(n/a)) | Overall very poor | |
| Offline training combined with incremental updates | Based on similarity of data distribution | Storm [32] | - | - | Overall better |
| Storm1, 2, 3 [33] | O(1) | O(n∗d) | |||
| MCOD [34,35] | - | - | |||
| pMCOD [36] | O(N∗d) | O(N∗d) | |||
| DILOF [37] | O(log n∗d) | O(n∗d) | |||
| CODS [38] | O((1/a)∗log2(n/a)) | O(d∗log(n/a)) | |||
| Based on subspace partitioning | iForestASD [39] | O(N∗m∗h) | O(N∗m∗d) | Overall very good | |
| LSHiforest [40] | - | - |
| Algorithm Type | Algorithm Type (Subtype) | Algorithm Name and Reference | Time Complexity | Space Complexity | Scalability |
|---|---|---|---|---|---|
| Online shallow learning | Based on similarity of data distribution | osPCA [41]; | O(d2∗k) | O(d) | Overall poor |
| OSHULL [42]; | O(n) | O(n/m) | |||
| Based on matrix sketch | The deterministic flow update algorithm [43]; The stochastic stream update algorithm [43]; A framework of virtual war room and matrix sketch-based streaming anomaly detection [44] | O(1)-O(n) | O(1)-O(k) | Overall very good | |
| Based on decision trees | VFDT [45]; | O(d∗v∗c) | O(l∗d∗v∗c) | Overall better | |
| CVFDT [46]; | O(1) | O(1) | |||
| HAT [47]; | |||||
| EFDT [48]; | O(d∗v∗c∗h) | O(l∗d∗v∗c) | |||
| GAHT [49] | |||||
| Online deep learning | ADA [50]; | - | - | Overall very poor | |
| DAGMM [51]; | |||||
| ARCUS [52]; | |||||
| S-DPS [53]; | |||||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lu, T.; Wang, L.; Zhao, X. Review of Anomaly Detection Algorithms for Data Streams. Appl. Sci. 2023, 13, 6353. https://doi.org/10.3390/app13106353
Lu T, Wang L, Zhao X. Review of Anomaly Detection Algorithms for Data Streams. Applied Sciences. 2023; 13(10):6353. https://doi.org/10.3390/app13106353
Chicago/Turabian StyleLu, Tianyuan, Lei Wang, and Xiaoyong Zhao. 2023. "Review of Anomaly Detection Algorithms for Data Streams" Applied Sciences 13, no. 10: 6353. https://doi.org/10.3390/app13106353
APA StyleLu, T., Wang, L., & Zhao, X. (2023). Review of Anomaly Detection Algorithms for Data Streams. Applied Sciences, 13(10), 6353. https://doi.org/10.3390/app13106353