
An Object Detection Method Based on Feature Uncertainty Domain Adaptation for Autonomous Driving


Abstract
:1. Introduction
2. Related works
2.1. Adversarial Learning-Based Methods for Domain Adaptation
2.2. Methods Based on Image-to-Image Translation
2.3. Methods Based on Teacher–Student Model
3. Domain Adaptation Object Detection Based on Feature Uncertainty
3.1. Problem Definition
3.2. FUA
3.3. IUA
- A.
- Regression inconsistency
- B.
- Classification inconsistency
3.4. Instance-Level Uncertainty Guidance
| Algorithm 1 Feature Uncertainty Projection |
| Input: ROIs: Output: Uncertainty of ROIs:
|
3.5. Instance-Level Global Discriminator
4. Experimental Analysis
4.1. Experimental Settings
4.2. Experimental Results of Cityscapes to Cityscapes Foggy
4.3. Experimental Results of Cityscapes to Cityscapes Rainy
4.4. Experimental Results of KITTI to KITTI Rainy
4.5. Experimental Results of Phycical Testing Platform
5. Ablation Study
5.1. Effect on IUA Module
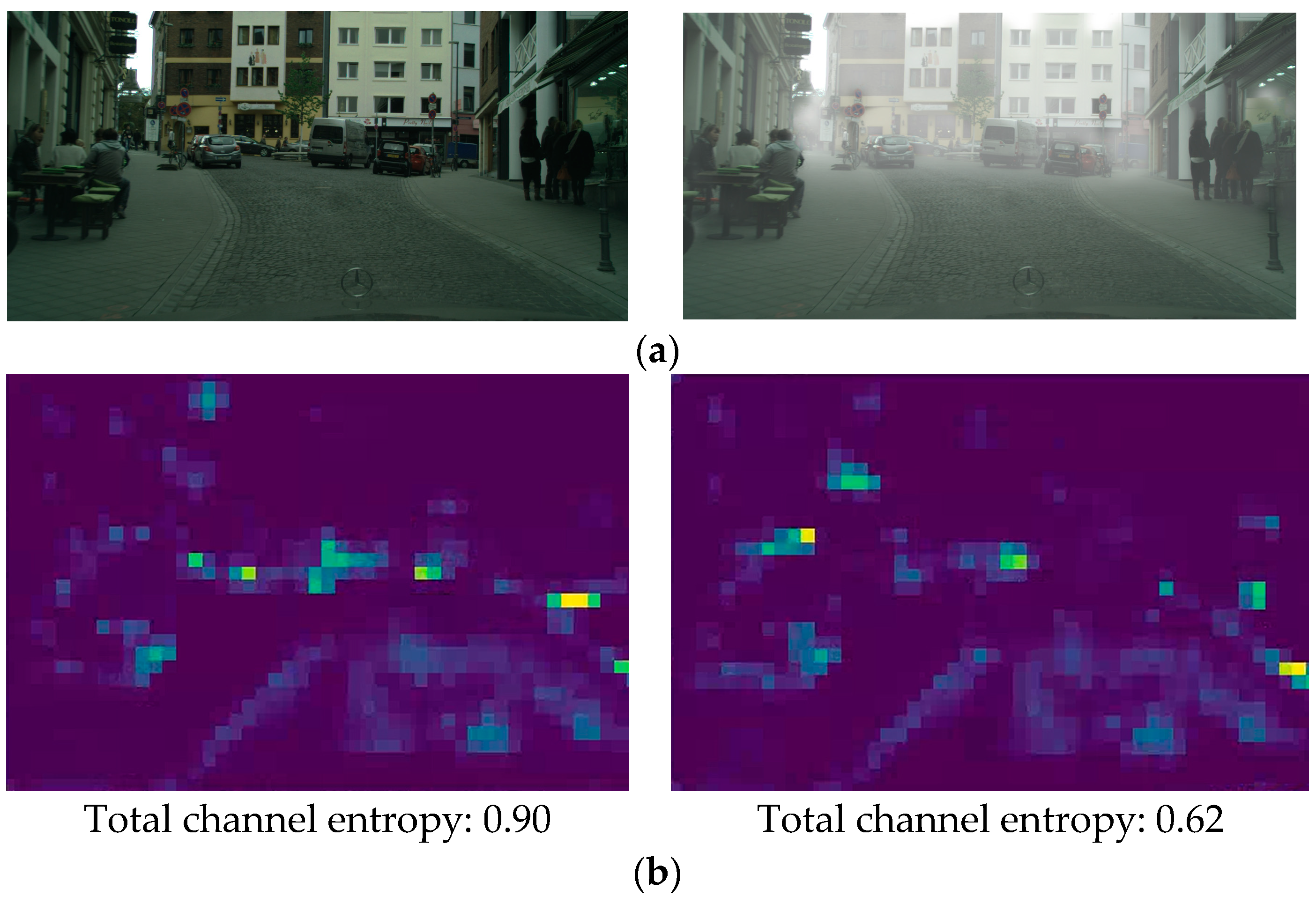
5.2. Visualization of Feature Distribution
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-End Object Detection with Transformers. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 213–229. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer Using Shifted Windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Online. 11–17 October 2021; IEEE: New York, NY, USA; pp. 10012–10022. [Google Scholar]
- Tian, Z.; Shen, C.; Chen, H.; He, T. FCOS: Fully Convolutional One-Stage Object Detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; IEEE: New York, NY, USA, 2019; pp. 9627–9636. [Google Scholar]
- Tao, C.; Cao, J.; Wang, C.; Zhang, Z.; Gao, Z. Pseudo-Mono for Monocular 3D Object Detection in Autonomous Driving. IEEE Trans. Circuits Syst. Video Technol. 2023, 1. [Google Scholar] [CrossRef]
- Duan, K.; Bai, S.; Xie, L.; Qi, H.; Huang, Q.; Tian, Q. CenterNet: Keypoint Triplets for Object Detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Long Beach, CA, USA, 27 October–2 November 2019; IEEE: New York, NY, USA, 2019; pp. 6569–6578. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 21–26 July 2017; IEEE: New York, NY, USA, 2017; pp. 7263–7271. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Springer: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar]
- Tao, C.; He, H.; Xu, F.; Cao, J. Stereo priori RCNN based car detection on point level for autonomous driving. Knowl.-Based Syst. 2021, 229, 107346. [Google Scholar] [CrossRef]
- Hnewa, M.; Radha, H. Object Detection Under Rainy Conditions for Autonomous Vehicles: A Review of State-of-the-Art and Emerging Techniques. IEEE Signal Process. Mag. 2021, 38, 53–67. [Google Scholar] [CrossRef]
- Rothmeier, T.; Huber, W. Performance Evaluation of Object Detection Algorithms Under Adverse Weather Conditions. In Intelligent Transport Systems, from Research and Development to the Market Uptake; Martins, A.L., Ferreira, J.C., Kocian, A., Costa, V., Eds.; Lecture Notes of the Institute for Computer Sciences, Social Informatics and Telecommunications Engineering; Springer International Publishing: Cham, Switzerland, 2021; pp. 211–222. [Google Scholar] [CrossRef]
- Hasirlioglu, S.; Riener, A. Challenges in Object Detection Under Rainy Weather Conditions. In Intelligent Transport Systems, from Research and Development to the Market Uptake; Ferreira, J.C., Martins, A.L., Monteiro, V., Eds.; Springer International Publishing: Cham, Switzerland, 2019; pp. 53–65. [Google Scholar] [CrossRef]
- Ganin, Y.; Ustinova, E.; Ajakan, H.; Germain, P.; Larochelle, H.; Laviolette, F.; Marchand, M.; Lempitsky, V. Domain-Adversarial Training of Neural Networks. J. Mach. Learn. Res. 2016, 17, 1–35. [Google Scholar]
- Saito, K.; Ushiku, Y.; Harada, T. Asymmetric Tri-training for Unsupervised Domain Adaptation. In Proceedings of the 34th International Conference on Machine Learning, PMLR, Sydney, Australia, 6–11 August 2017; pp. 2988–2997. Available online: https://proceedings.mlr.press/v70/saito17a.html (accessed on 1 May 2022).
- Kurmi, V.K.; Kumar, S.; Namboodiri, V.P. Attending to Discriminative Certainty for Domain Adaptation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–17 June 2019; IEEE: New York, NY, USA, 2019; pp. 491–500. [Google Scholar]
- Saito, K.; Watanabe, K.; Ushiku, Y.; Harada, T. Maximum Classifier Discrepancy for Unsupervised Domain Adaptation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; IEEE: New York, NY, USA, 2018; pp. 3723–3732. [Google Scholar]
- Saha, S.; Zhao, S.; Zhu, X.X. Multitarget Domain Adaptation for Remote Sensing Classification Using Graph Neural Network. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Zhang, J.; Huang, J.; Tian, Z.; Lu, S. Spectral Unsupervised Domain Adaptation for Visual Recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; IEEE: New York, NY, USA, 2022; pp. 9829–9840. [Google Scholar]
- Shrivastava, A.; Shekhar, S.; Patel, V.M. Unsupervised Domain Adaptation Using Parallel Transport on Grassmann Manifold. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision, Steamboat Springs, CO, USA, 24–26 March 2014; pp. 277–284. [Google Scholar]
- Chang, W.-L.; Wang, H.-P.; Peng, W.-H.; Chiu, W.-C. All About Structure: Adapting Structural Information Across Domains for Boosting Semantic Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; IEEE: New York, NY, USA, 2019; pp. 1900–1909. [Google Scholar]
- Tsai, Y.-H.; Hung, W.-C.; Schulter, S.; Sohn, K.; Yang, M.-H.; Chandraker, M. Learning to Adapt Structured Output Space for Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; IEEE: New York, NY, USA, 2018; pp. 7472–7481. [Google Scholar]
- Chen, Y.-H.; Chen, W.-Y.; Chen, Y.-T.; Tsai, B.-C.; Wang, Y.-C.F.; Sun, M. No More Discrimination: Cross City Adaptation of Road Scene Segmenters. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; IEEE: New York, NY, USA, 2017; pp. 1992–2001. [Google Scholar]
- Zhang, P.; Zhang, B.; Zhang, T.; Chen, D.; Wang, Y.; Wen, F. Prototypical Pseudo Label Denoising and Target Structure Learning for Domain Adaptive Semantic Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; IEEE: New York, NY, USA, 2021; pp. 12414–12424. [Google Scholar]
- Zhao, L.; Wang, L. Task-Specific Inconsistency Alignment for Domain Adaptive Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, NV, USA, 18–24 June 2022; IEEE: New York, NY, USA, 2022; pp. 14217–14226. [Google Scholar]
- Chen, Y.; Li, W.; Sakaridis, C.; Dai, D.; Van Gool, L. Domain Adaptive Faster R-CNN for Object Detection in the Wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; IEEE: New York, NY, USA, 2018; pp. 3339–3348. [Google Scholar]
- Saito, K.; Ushiku, Y.; Harada, T.; Saenko, K. Strong-Weak Distribution Alignment for Adaptive Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; IEEE: New York, NY, USA, 2019; pp. 6956–6965. [Google Scholar]
- Zhang, S.; Tuo, H.; Hu, J.; Jing, Z. Domain Adaptive YOLO for One-Stage Cross-Domain Detection. In Proceedings of the 13th Asian Conference on Machine Learning, PMLR, Virtually, 17–19 November 2021; pp. 785–797. [Google Scholar]
- He, Z.; Zhang, L. Multi-Adversarial Faster-RCNN for Unrestricted Object Detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; IEEE: New York, NY, USA, 2019; pp. 6668–6677. [Google Scholar]
- Chen, Y.; Wang, H.; Li, W.; Sakaridis, C.; Dai, D.; Van Gool, L. Scale-Aware Domain Adaptive Faster R-CNN. Int. J. Comput. Vis. 2021, 129, 2223–2243. [Google Scholar] [CrossRef]
- Zhu, X.; Pang, J.; Yang, C.; Shi, J.; Lin, D. Adapting Object Detectors via Selective Cross-Domain Alignment. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–17 June 2019; IEEE: New York, NY, USA, 2019; pp. 687–696. [Google Scholar]
- Zhang, H.; Luo, G.; Li, J.; Wang, F.-Y. C2FDA: Coarse-to-Fine Domain Adaptation for Traffic Object Detection. IEEE Trans. Intell. Transp. Syst. 2022, 23, 12633–12647. [Google Scholar] [CrossRef]
- Zhang, D.; Li, J.; Xiong, L.; Lin, L.; Ye, M.; Yang, S. Cycle-Consistent Domain Adaptive Faster RCNN. IEEE Access 2019, 7, 123903–123911. [Google Scholar] [CrossRef]
- Zhu, J.-Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired Image-To-Image Translation Using Cycle-Consistent Adversarial Networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; IEEE: New York, NY, USA, 2017; pp. 2223–2232. [Google Scholar]
- Hsu, H.-K.; Yao, C.H.; Tsai, Y.H.; Hung, W.C.; Tseng, H.Y.; Singh, M.; Yang, M.H. Progressive Domain Adaptation for Object Detection. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Snowmass Village, CO, USA, 1–5 March 2020; IEEE: New York, NY, USA, 2020; pp. 749–757. [Google Scholar]
- Chen, C.; Zheng, Z.; Ding, X.; Huang, Y.; Dou, Q. Harmonizing Transferability and Discriminability for Adapting Object Detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; IEEE: New York, NY, USA, 2020; pp. 8869–8878. [Google Scholar]
- Tarvainen, A.; Valpola, H. Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results. In Advances in Neural Information Processing Systems; Curran Associates, Inc.: Red Hook, NY, USA, 2017. [Google Scholar]
- Deng, J.; Li, W.; Chen, Y.; Duan, L. Unbiased Mean Teacher for Cross-Domain Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; IEEE: New York, NY, USA, 2021; pp. 4091–4101. [Google Scholar]
- Zhou, Q.; Feng, Z.; Gu, Q.; Cheng, G.; Lu, X.; Shi, J.; Ma, L. Uncertainty-aware consistency regularization for cross-domain semantic segmentation. Comput. Vis. Image Underst. 2022, 221, 103448. [Google Scholar] [CrossRef]
- Kim, T.; Jeong, M.; Kim, S.; Choi, S.; Kim, C. Diversify and Match: A Domain Adaptive Representation Learning Paradigm for Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–17 June 2019; IEEE: New York, NY, USA, 2019; pp. 12456–12465. [Google Scholar]
- Zhao, G.; Li, G.; Xu, R.; Lin, L. Collaborative Training Between Region Proposal Localization and Classification for Domain Adaptive Object Detection. In Computer Vision—ECCV 2020; Vedaldi, A., Bischof, H., Brox, T., Frahm, J.-M., Eds.; Springer International Publishing: Cham, Switzerland, 2020; pp. 86–102. [Google Scholar]
- Su, P.; Wang, K.; Zeng, X.; Tang, S.; Chen, D.; Qiu, D.; Wang, X. Adapting Object Detectors with Conditional Domain Normalization. In Computer Vision—ECCV 2020; Vedaldi, A., Bischof, H., Brox, T., Frahm, J.-M., Eds.; Springer International Publishing: Cham, Switzerland, 2020; pp. 403–419. [Google Scholar]
- Zheng, Y.; Huang, D.; Liu, S.; Wang, Y. Cross-domain Object Detection through Coarse-to-Fine Feature Adaptation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; IEEE: New York, NY, USA, 2020; pp. 13766–13775. [Google Scholar]
- Zhang, Y.; Wang, Z.; Mao, Y. RPN Prototype Alignment for Domain Adaptive Object Detector. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 12425–12434. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Person | Rider | Car | Truck | Bus | Train | Motor | Bicycle | mAP |
|---|---|---|---|---|---|---|---|---|---|
| FRCNN [1] | 24.2 | 28.5 | 34.6 | 10.1 | 25.6 | 4.0 | 11.7 | 20.9 | 20.0 |
| DA [25] | 25.0 | 31.0 | 40.5 | 22.1 | 35.3 | 20.2 | 27.1 | 20.0 | 27.6 |
| SWDA [26] | 29.9 | 42.3 | 43.5 | 24.5 | 36.2 | 32.6 | 30.0 | 35.3 | 34.3 |
| MAF [28] | 28.2 | 39.5 | 43.9 | 23.8 | 39.9 | 33.3 | 29.2 | 33.9 | 34.0 |
| DAM [39] | 30.8 | 40.5 | 44.3 | 27.2 | 38.4 | 34.5 | 28.4 | 32.2 | 34.6 |
| CST [40] | 32.7 | 44.4 | 50.1 | 21.7 | 45.6 | 25.4 | 30.1 | 36.8 | 35.9 |
| CDN [41] | 35.8 | 45.7 | 50.9 | 30.1 | 42.5 | 29.8 | 30.8 | 36.5 | 36.6 |
| CFFA [42] | 43.2 | 37.4 | 52.1 | 34.7 | 34.0 | 46.9 | 29.9 | 30.8 | 38.6 |
| RPNPA [43] | 33.3 | 45.6 | 50.5 | 30.4 | 43.6 | 42.0 | 29.7 | 36.8 | 39.0 |
| FUDA (Ours) | 43.9 | 49.1 | 53.9 | 28.4 | 41.8 | 31.6 | 28.2 | 45.0 | 40.2 |
| Target | 36.2 | 46.5 | 55.8 | 34.0 | 53.1 | 40.2 | 36.0 | 36.4 | 42.3 |
| Methods | Person | Rider | Car | Truck | Bus | Train | Motor | Bicycle | mAP |
|---|---|---|---|---|---|---|---|---|---|
| FRCNN [1] | 22.3 | 23.8 | 30.6 | 15.3 | 28.9 | 15.3 | 18.1 | 31.6 | 23.2 |
| DA [25] | 31.5 | 33.1 | 46.2 | 29.8 | 38.5 | 26.2 | 31.7 | 26.1 | 32.9 |
| SWDA [26] | 33.8 | 46.4 | 48.3 | 29.7 | 38.9 | 35.2 | 38.2 | 31.3 | 37.7 |
| FUDA (Ours) | 38.4 | 48.2 | 56.9 | 35.1 | 42.8 | 39.6 | 35.2 | 40.3 | 42.1 |
| Target | 44.2 | 53.8 | 58.3 | 41.7 | 49.6 | 45.7 | 42.4 | 47.2 | 47.9 |
| Methods | Car | Pedestrian | Cyclist | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Easy | Mod. | Hard | Easy | Mod. | Hard | Easy | Mod. | Hard | mAp | |
| FRCNN [1] | 58.9 | 34.7 | 32.0 | 33.5 | 26.3 | 19.6 | 43.2 | 39.4 | 31.8 | 35.5 |
| DA [25] | 62.7 | 55.1 | 40.8 | 39.6 | 25.1 | 24.3 | 56.2 | 50.1 | 48.4 | 44.7 |
| SWDA [26] | 69.1 | 60.7 | 51.9 | 43.1 | 39.6 | 31.3 | 62.4 | 56.0 | 50.8 | 51.7 |
| Ours | 73.4 | 62.8 | 57.3 | 40.3 | 35.3 | 32.7 | 68.7 | 61.3 | 53.2 | 53.9 |
| Methods | Person | Rider | Car | Truck | Bus | Train | Motor | Bicycle | mAP |
|---|---|---|---|---|---|---|---|---|---|
| DA | 25.0 | 31.0 | 40.5 | 22.1 | 35.3 | 20.2 | 27.1 | 20.0 | 27.7 |
| FUA | 28.3 | 39.4 | 51.6 | 28.8 | 39.2 | 32.4 | 31.5 | 28.2 | 34.9 |
| FUA + IUA | 43.9 | 49.1 | 53.9 | 28.4 | 41.8 | 31.6 | 28.2 | 45.0 | 40.2 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhu, Y.; Xu, R.; Tao, C.; An, H.; Sun, Z.; Lu, K. An Object Detection Method Based on Feature Uncertainty Domain Adaptation for Autonomous Driving. Appl. Sci. 2023, 13, 6448. https://doi.org/10.3390/app13116448
Zhu Y, Xu R, Tao C, An H, Sun Z, Lu K. An Object Detection Method Based on Feature Uncertainty Domain Adaptation for Autonomous Driving. Applied Sciences. 2023; 13(11):6448. https://doi.org/10.3390/app13116448
Chicago/Turabian StyleZhu, Yuan, Ruidong Xu, Chongben Tao, Hao An, Zhipeng Sun, and Ke Lu. 2023. "An Object Detection Method Based on Feature Uncertainty Domain Adaptation for Autonomous Driving" Applied Sciences 13, no. 11: 6448. https://doi.org/10.3390/app13116448
APA StyleZhu, Y., Xu, R., Tao, C., An, H., Sun, Z., & Lu, K. (2023). An Object Detection Method Based on Feature Uncertainty Domain Adaptation for Autonomous Driving. Applied Sciences, 13(11), 6448. https://doi.org/10.3390/app13116448