
Incrementally Mining Column Constant Biclusters with FVSFP Tree

Abstract
1. Introduction
- We propose a modified FP tree data structure, namely, a Feature Value Sorting Frequent Pattern (FVSFP) tree, which can be easily maintained;
- We innovatively design a method for mining CCB from FVSFP tree. The mining method is greatly different from the standard frequent pattern mining method [31].
2. Method
2.1. Preprocessing
- Calculate the number of each feature’s possible values, denote as the ith feature value’s size. Finally, a vector [] containing the number of each feature’s possible values can be obtained;
- Transform feature values column-by-column in two steps. The first is to uniquify and sort the feature values of the ith column in ascending order to obtain original feature value vector []. The second step is to transform the ordered unique feature to new feature = where . After transformation, the ith feature values fall in the range of []
2.2. Initial CCB Mining
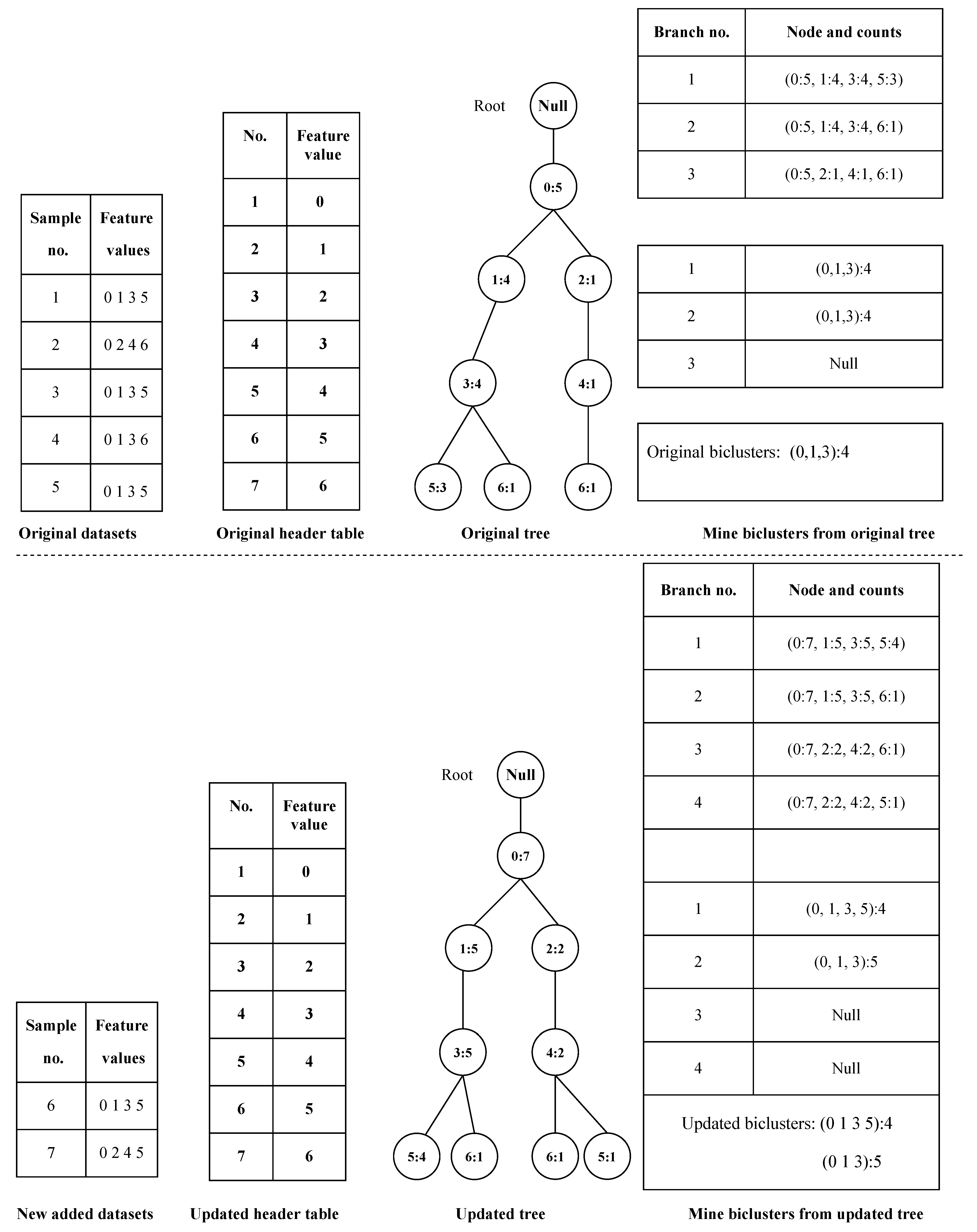
2.2.1. Construction of a Header Table
2.2.2. Initial FVSFP Tree Construction
- *
- Construct the Root node;
- *
- Insert the samples of the original dataset sample-by-sample with Algorithm 1.
| Algorithm 1 Insert sample to FVSFP tree. |
| Require: Initial FVSFP tree, ; Sample, S; Feature number in S, L.
Ensure: Updated FVSFP tree,
|
2.2.3. Initial CCB Mining
- *
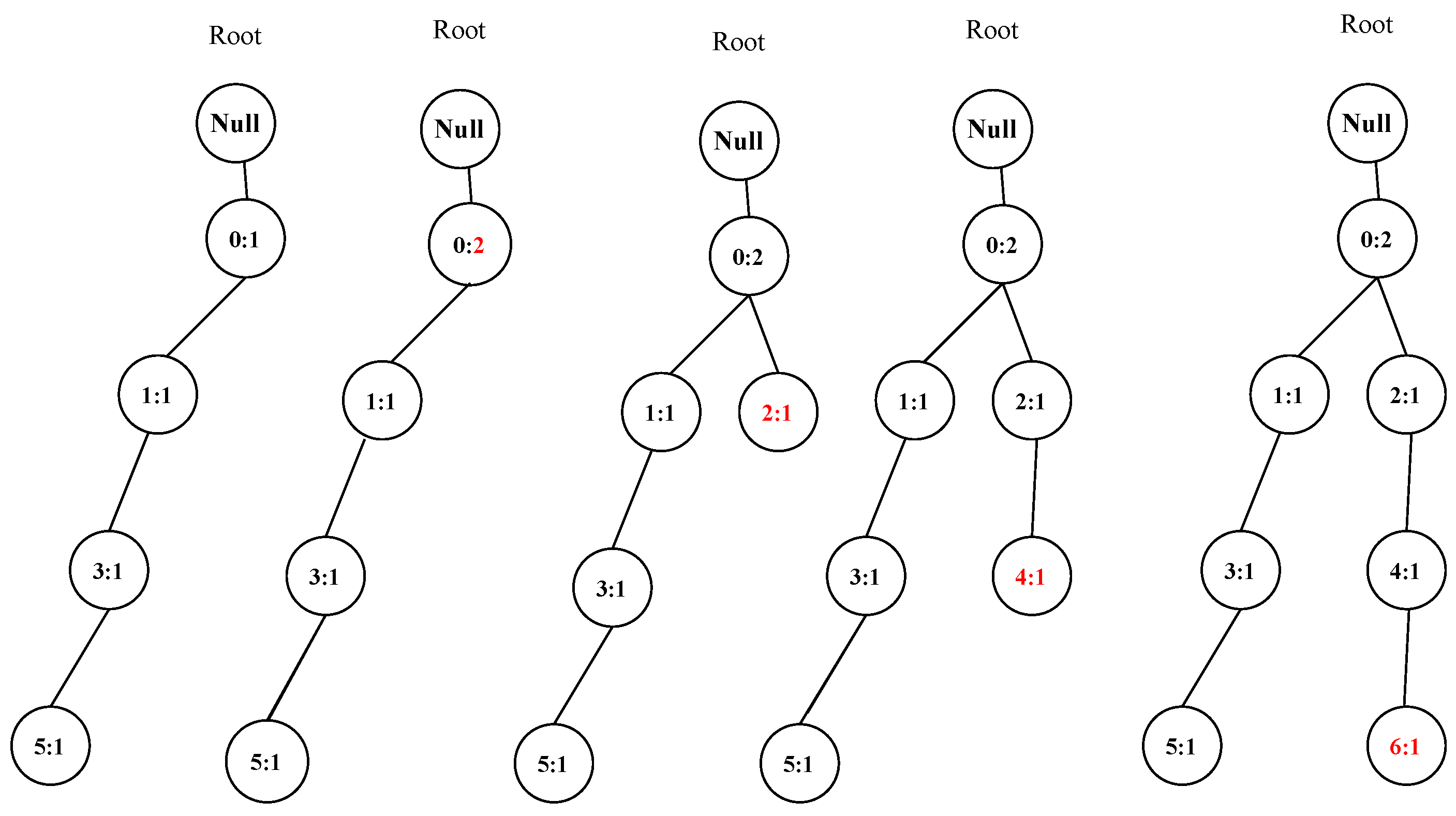
- Find all leaf nodes;
- *
- Find all branches by iteratively combining the whole nodes from the leaf node to the Root node;
- *
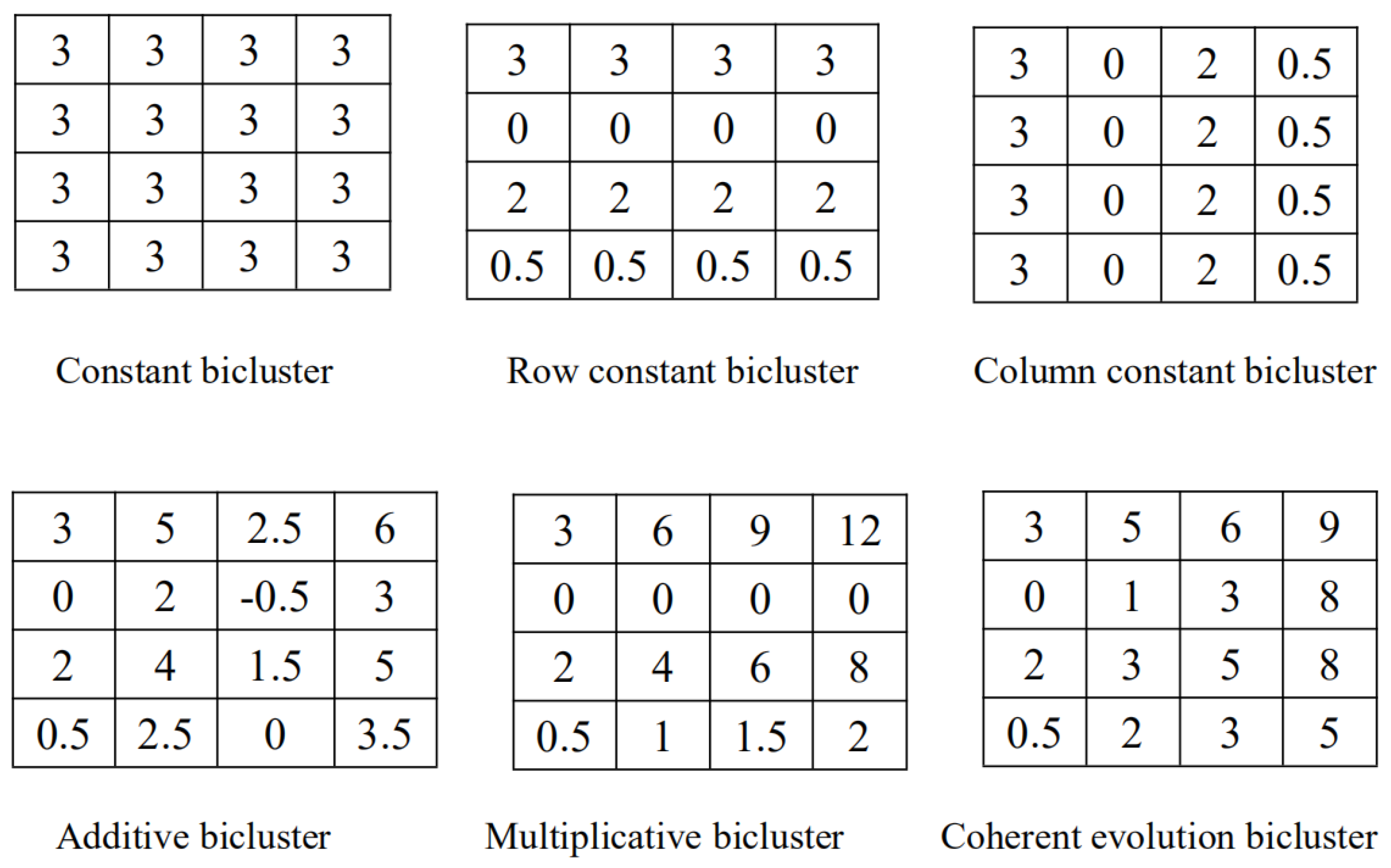
- For each branch, delete the infrequent nodes whose count is less than threshold . Then, find the whole candidate CCBs from each branch with the following steps. (1): Unique the counts of the nodes in the branch to obtain the unique counts array [] where n is the length of the array, means the maximal common counts among the whole nodes in the CCB. For each , calculate the whole nodes whose count is greater than or equal to the , then the volume of the CCB can be obtained by Equation (2). Finally, the bicluster with the biggest volume is selected.Take the first branch (0:5 1:4 3:4 5:3) of the FVSFP tree generated by the original dataset in Figure 2, for instance, to illustrate mining CCB. Suppose the minimal support rate is 0.4, therefore, the minimal supports is 0.4 × 5 = 2, the nodes whose count is less than 2 are unfrequent nodes, no node is unfrequent node, all the four nodes should be preserved. Then, the remaining effective branch becomes (0:5 1:4 3:4 5:3). Unique the counts [3 4 5], because the number of the nodes whose count is no less than 5 is less than 3, therefore remaining valid counts are [3 4]. Two candidate CCBs (shown in Table 3) can be generated, both CCBs have identical volume, but counts are more important than the node number, finally, the optimal CCB (0,1,3):4 is outputted.
- *
- Delete the identical and subset CCBs. Because the optimal CCBs generated from different branches may be identical, identical CCBs should be deleted. Additionally, some CCBs may be the subsets of other CCBs, the subset CCBs also should be deleted. The maximal common count deleting subset pattern can guarantee that the obtained CCBs are inclusion-maximal.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| CCB No. | Nodes | Least Common Counts () | Volume |
|---|---|---|---|
| 1 | (0, 1, 3, 5) | 3 | 3 × 4 = 12 |
| 2 | (0, 1, 3) | 4 | 4 × 3 = 12 |
2.3. Incremental CCB Mining
2.3.1. Updation of Initial FVSFP Tree
2.3.2. Remining of CCB
3. Experiments
3.1. Experimental Settings
3.2. Experimental Results
3.2.1. Ablation Study
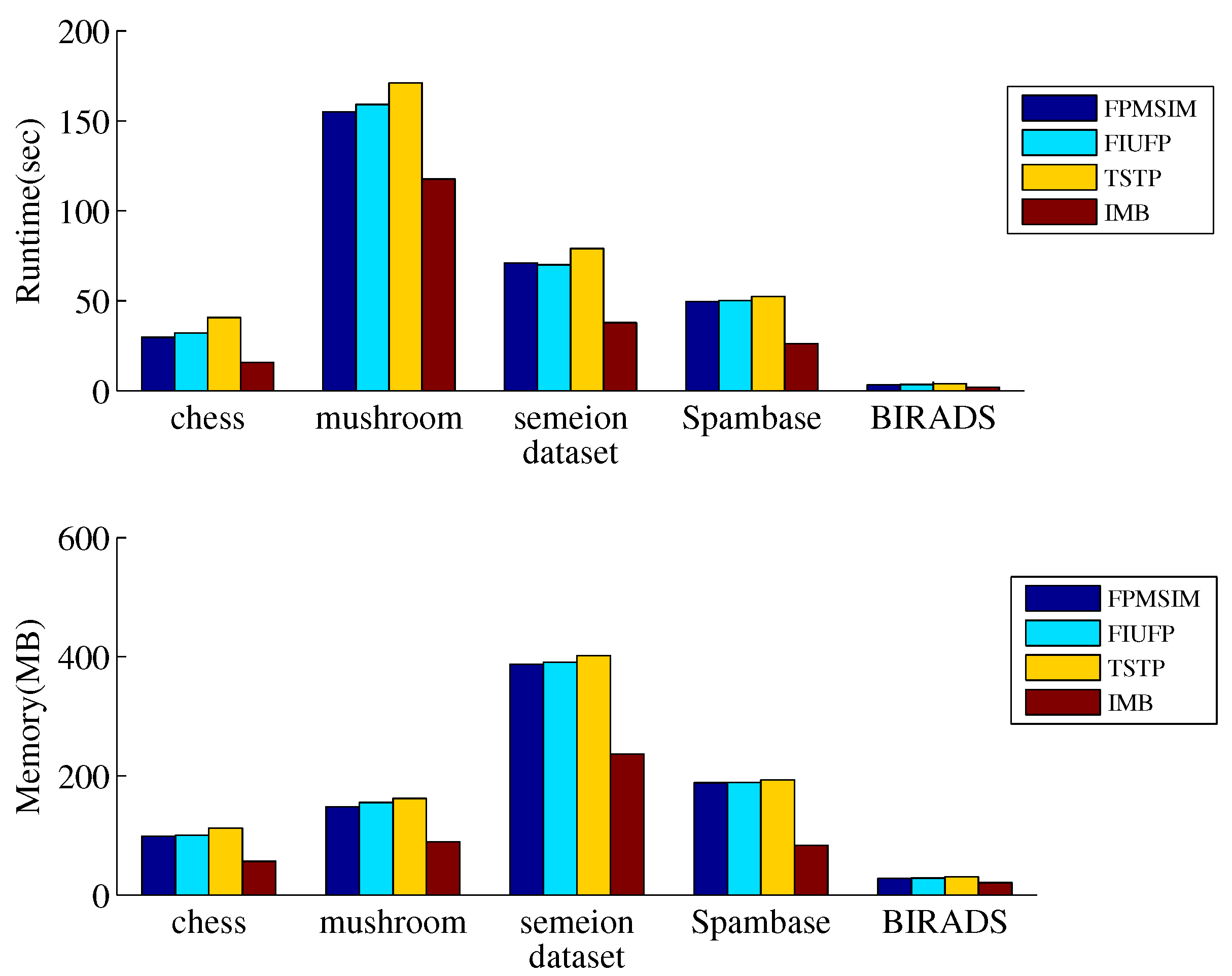
3.2.2. Testing on Chess Dataset
3.2.3. Testing on the Mushroom Dataset
3.2.4. Testing on the Spambase Dataset
3.2.5. Testing on the Semeion Dataset
3.2.6. Testing on the BIRADS Dataset
3.2.7. Testing on the WebDocs Dataset
3.2.8. Comparison with State-of-the-Art Methods
4. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Samir, R.; El-Hennawy, H.; Elbadawy, H. Cluster-Based Multi-User Multi-Server Caching Mechanism in Beyond 5G/6G MEC. Sensors 2023, 23, 996. [Google Scholar] [CrossRef] [PubMed]
- Li, M.; Wang, H.; Long, H.; Xiang, J.; Wang, B.; Xu, J.; Yang, J. Community Detection and Visualization in Complex Network by the Density-Canopy-Kmeans Algorithm and MDS Embedding. IEEE Access 2019, 7, 120616–120625. [Google Scholar] [CrossRef]
- Huang, Q.; Tao, D.; Li, X.; Liew, A. Parallelized Evolutionary Learning for Detection of Biclusters in Gene Expression Data. IEEE/ACM Trans. Comput. Biol. Bioinform. 2012, 9, 560–570. [Google Scholar] [CrossRef] [PubMed]
- Cheng, Y.; Church, G.M. Biclustering of expression data. In Proceedings of the Eighth International Conference on Intelligent Systems for Molecular Biology, San Diego, CA, USA, 19–23 August 2000; pp. 799–808. [Google Scholar]
- Cheng, H. Towards Accurate and Efficient Classification: A Discriminative and Frequent Pattern-Based Approach; Technical Report; University of Illinois: Urbana, IL, USA, 2008. [Google Scholar]
- Huang, Q.; Chen, Y.; Liu, L.; Tao, D.; Li, X. On Combining Biclustering Mining and AdaBoost for Breast Tumor Classification. IEEE Trans. Knowl. Data Eng. 2020, 32, 728–738. [Google Scholar] [CrossRef]
- Huang, Q.; Yang, J.; Feng, X.; Liew, A.W.; Li, X. Automated Trading Point Forecasting Based on Bicluster Mining and Fuzzy Inference. IEEE Trans. Fuzzy Syst. 2020, 28, 259–272. [Google Scholar] [CrossRef]
- Sun, J. Motor Imagery EEG Classification with Biclustering Based Fuzzy Inference. J. Med. Imaging Health Inform. 2020, 10, 1486–1493. [Google Scholar] [CrossRef]
- Huang, Q.; Wang, T.; Tao, D.; Li, X. Biclustering Learning of Trading Rules. IEEE Trans. Cybern. 2015, 45, 2287–2298. [Google Scholar] [CrossRef]
- Xue, Y.; Li, T.; Chen, J.; Zhao, H.; Zhang, H. A New Customer Segmentation Framework Based on Biclustering Analysis. J. Softw. 2014, 9, 1359–1366. [Google Scholar]
- Huang, Q.; Jin, L.; Tao, D. An unsupervised feature ranking scheme by discovering biclusters. In Proceedings of the 2009 IEEE International Conference on Systems, Man and Cybernetics, San Antonio, TX, USA, 11–14 October 2009; pp. 4970–4975. [Google Scholar] [CrossRef]
- Saini, R.; Mussbacher, G.; Guo, J.L.; Kienzle, J. Machine learning-based incremental learning in interactive domain modelling. In Proceedings of the 25th International Conference on Model Driven Engineering Languages and Systems, Montreal, QC, Canada, 16–21 October 2022; pp. 176–186. [Google Scholar]
- Ditzler, G.; Polikar, R. Incremental Learning of Concept Drift from Streaming Imbalanced Data. IEEE Trans. Knowl. Data Eng. 2013, 25, 2283–2301. [Google Scholar] [CrossRef]
- Lange, S.; Zilles, S. Formal models of incremental learning and their analysis. In Proceedings of the International Joint Conference on Neural Networks, Portland, OR, USA, 20–24 July 2003; Volume 4, pp. 2691–2696. [Google Scholar] [CrossRef]
- Liu, X.; Zheng, L.; Zhang, W.; Zhou, J.; Cao, S.; Yu, S. An evolutive frequent pattern tree-based incremental knowledge discovery algorithm. ACM Trans. Manag. Inf. Syst. (TMIS) 2022, 13, 1–20. [Google Scholar] [CrossRef]
- Xun, Y.; Cui, X.; Zhang, J.; Yin, Q. Incremental frequent itemsets mining based on frequent pattern tree and multi-scale. Expert Syst. Appl. 2021, 163, 113805. [Google Scholar] [CrossRef]
- Huang, Q.; Huang, X.; Kong, Z.; Li, X.; Tao, D. Bi-Phase Evolutionary Searching for Biclusters in Gene Expression Data. IEEE Trans. Evol. Comput. 2019, 23, 803–814. [Google Scholar] [CrossRef]
- Amos, T.; Roded, S.; Ron, S. Discovering statistically significant biclusters in gene expression data. Bioinformatics 2002, 18, S136–S144. [Google Scholar]
- Gu, J.; Liu, J.S. Bayesian biclustering of gene expression data. BMC Genom. 2008, 9, S4. [Google Scholar] [CrossRef]
- Han, J.; Cheng, H.; Xin, D.; Yan, X. Frequent pattern mining: Current status and future directions. Data Min. Knowl. Discov. 2007, 15, 55–86. [Google Scholar] [CrossRef]
- Djenouri, Y.; Belhadi, A.; Djenouri, D.; Lin, J.C.W. Cluster-based information retrieval using pattern mining. Appl. Intell. 2021, 51, 1888–1903. [Google Scholar] [CrossRef]
- Belhadi, A.; Djenouri, Y.; Lin, J.C.W.; Cano, A. A general-purpose distributed pattern mining system. Appl. Intell. 2020, 50, 2647–2662. [Google Scholar] [CrossRef]
- Wu, J.M.T.; Srivastava, G.; Wei, M.; Yun, U.; Lin, J.C.W. Fuzzy high-utility pattern mining in parallel and distributed Hadoop framework. Inf. Sci. 2021, 553, 31–48. [Google Scholar] [CrossRef]
- Azzam, B.; Harzendorf, F.; Schelenz, R.; Holweger, W.; Jacobs, G. Pattern discovery in white etching crack experimental data using machine learning techniques. Appl. Sci. 2019, 9, 5502. [Google Scholar] [CrossRef]
- Cheung, D.W.; Han, J.; Ng, V.T.; Wong, C.Y. Maintenance of discovered association rules in large databases: An incremental updating technique. In Proceedings of the Twelfth International Conference on Data Engineering, New Orleans, LA, USA, 26 February–1 March 1996; pp. 106–114. [Google Scholar] [CrossRef]
- Li, Y.; Zhang, Z.H.; Chen, W.B.; Min, F. TDUP: An approach to incremental mining of frequent itemsets with three-way-decision pattern updating. Int. J. Mach. Learn. Cybern. 2017, 8, 441–453. [Google Scholar] [CrossRef]
- Lin, C.; Hong, T.; Lu, W. The Pre-FUFP algorithm for incremental mining. Expert Syst. Appl. 2009, 36, 9498–9505. [Google Scholar] [CrossRef]
- Nath, B.; Bhattacharyya, D.K.; Ghosh, A. Incremental association rule mining: A survey. InWiley Interdisciplinary Reviews: Data Mining and Knowledge Discovery; Wiley: Hoboken, NJ, USA, 2013; Volume 3. [Google Scholar]
- Koh, J.L.; Shieh, S.F. An Efficient Approach for Maintaining Association Rules Based on Adjusting FP-Tree Structures. Lect. Notes Comput. Sci. 2004, 2973, 417–424. [Google Scholar]
- Sun, J.; Xun, Y.; Zhang, J.; Li, J. Incremental Frequent Itemsets Mining with FCFP Tree. IEEE Access 2019, 7, 136511–136524. [Google Scholar] [CrossRef]
- Han, J.; Pei, J.; Yin, Y.; Mao, R. Mining frequent patterns without candidate generation: A frequent-pattern tree approach. Data Min. Knowl. Discov. 2004, 8, 53–87. [Google Scholar] [CrossRef]
- Giang, N.; Son, L.; Ngan, T.; Tuan, T.; Phuong, H.; Abdel-Basset, M.; de Macêdo, A.R.L.; de Albuquerque, V.H.C. Novel Incremental Algorithms for Attribute Reduction From Dynamic Decision Tables Using Hybrid Filter-Wrapper With Fuzzy Partition Distance. IEEE Trans. Fuzzy Syst. 2020, 28, 858–873. [Google Scholar] [CrossRef]
- Goethals, B.; Zaki, M. Advances in frequent itemset mining implementations: Introduction to FIMI’03. In Proceedings of the Workshop on FIMI, Melbourne, FL, USA, 19 September 2003. [Google Scholar]
- Thurachon, W.; Kreesuradej, W. Incremental association rule mining with a fast incremental updating frequent pattern growth algorithm. IEEE Access 2021, 9, 55726–55741. [Google Scholar] [CrossRef]
- Sun, J.; Huang, Q. Two stages biclustering with three populations. Biomed. Signal Process. Control. 2023, 79, 104182. [Google Scholar] [CrossRef]





| No. | FP | No. | FP | ||||
|---|---|---|---|---|---|---|---|
| 3 | 0 | 2 | 0.5 | 1 | (3, 0, 2, 0.5):4 | 6 | (3, 0):4 |
| 3 | 0 | 2 | 0.5 | 2 | (0, 2, 0.5):4 | 7 | (3, 2):4 |
| 3 | 0 | 2 | 0.5 | 3 | (3, 2, 0.5):4 | 8 | (3, 0.5):4 |
| 3 | 0 | 2 | 0.5 | 4 | (3, 0, 0.5):4 | 9 | (0, 2):4 |
| Matrix | 5 | (3, 0, 2):4 | 10 | (0, 0.5):4 | |||
| 11 | (2, 0.5):4 | ||||||
| Sample No. | Original Feature | |||
| 1 | 0 | 0 | 0 | 0 |
| 2 | 0 | 1 | 1 | 1 |
| 3 | 0 | 0 | 0 | 0 |
| 4 | 0 | 0 | 0 | 1 |
| Original feature value vector | [0] | [0 1] | [0 1] | [0 1] |
| Feature value size | 1 | 2 | 2 | 2 |
| New feature value range | [0] | [1 2] | [3 4] | [5 6] |
| Transfromation (mapping) | 0->0 | 0->1 1->2 | 0->3 1->4 | 0->5 1->6 |
| Sample No. | Transformed Feature | |||
| 1 | 0 | 1 | 3 | 5 |
| 2 | 0 | 2 | 4 | 6 |
| 3 | 0 | 1 | 3 | 5 |
| 4 | 0 | 1 | 3 | 6 |
| Dataset | Division | Sample Counts | Size (KB) | Unique Feature? |
|---|---|---|---|---|
| Original | 1598 | 179 | ||
| chess | Incremental | 1598 | 180 | Yes |
| Whole | 3196 | 359 | ||
| Original | 4062 | 308 | ||
| mushroom | Incremental | 4062 | 312 | Yes |
| Whole | 8124 | 620 | ||
| Original | 797 | 793 | ||
| semeion | Incremental | 796 | 793 | No |
| Whole | 1593 | 1586 | ||
| Original | 2301 | 343 | ||
| Spambase | Incremental | 2300 | 343 | No |
| Whole | 4601 | 686 | ||
| Original | 531 | 30 | ||
| BIRADS | Incremental | 531 | 31 | No |
| Whole | 1062 | 61 |
| Components | Different Combinations of Components | |||
|---|---|---|---|---|
| FVSFP tree | × | × | √ | √ |
| CCB mining | × | √ | × | √ |
| Runtime (s) (mean ± std) | 39.39 ± 0.81 | 25.11 ± 0.93 | 28.72 ± 1.07 | 15.76 ± 0.88 |
| Memory (MB) (mean ± std) | 120.11 ± 1.25 | 79.25 ± 0.87 | 96.72 ± 0.04 | 56.62 ± 0.68 |
| Minimal Support Rate | Methods | Runtime (s) (Mean ± std) | Memory (MB) (Mean ± std) |
|---|---|---|---|
| 0.01 | Incremental | 15.76 ± 0.88 | 56.62 ± 0.68 |
| Batch | 28.72 ± 1.07 | 96.72 ± 0.04 | |
| 0.008 | Incremental | 15.96 ± 0.22 | 57.22 ± 0.13 |
| Batch | 28.60 ± 0.83 | 97.06 ± 0.11 | |
| 0.006 | Incremental | 16.41 ± 1.50 | 57.54 ± 0.08 |
| Batch | 28.94 ± 1.05 | 97.26 ± 0.11 | |
| 0.004 | Incremental | 16.98 ± 0.32 | 58.4 ± 0.14 |
| Batch | 29.71 ± 0.35 | 98.04 ± 0.11 | |
| 0.002 | Incremental | 23.15 ± 1.17 | 59.92 ± 0.24 |
| Batch | 35.06 ± 0.22 | 99.38 ± 0.99 |
| Minimal Support Rate | Methods | Runtime (s) (Mean ± std) | Memory (MB) (Mean ± std) |
|---|---|---|---|
| 0.01 | Incremental | 117.56 ± 4.99 | 89.22 ± 0.08 |
| Batch | 150.6 ± 1.51 | 144.06 ± 1.36 | |
| 0.008 | Incremental | 114.26 ± 5.16 | 97.6 ± 6.17 |
| Batch | 159 ± 2.34 | 145.44 ± 2.80 | |
| 0.006 | Incremental | 119.43 ± 8.52 | 79.4 ± 0.73 |
| Batch | 176.2 ± 10.80 | 147.76 ± 3.15 | |
| 0.004 | Incremental | 122.09 ± 9.43 | 80.18 ± 0.38 |
| Batch | 171.8 ± 9.49 | 147.28 ± 2.43 | |
| 0.002 | Incremental | 115.65 ± 6.90 | 88.68 ± 4.74 |
| Batch | 171.4 ± 5.77 | 149.44 ± 4.80 |
| Minimal Support Rate | Methods | Runtime (s) (Mean ± std) | Memory (MB) (Mean ± std) |
|---|---|---|---|
| 0.01 | Incremental | 26.16 ± 0.98 | 83.12 ± 0.78 |
| Batch | 48.22 ± 109 | 177.17 ± 0.52 | |
| 0.008 | Incremental | 26.99 ± 0.42 | 83.67 ± 0.23 |
| Batch | 48.90 ± 0.89 | 177.86 ± 0.41 | |
| 0.006 | Incremental | 27.39 ± 1.60 | 84.14 ± 0.11 |
| Batch | 49.24 ± 1.45 | 178.66 ± 0.41 | |
| 0.004 | Incremental | 27.84 ± 0.12 | 84.64 ± 0.34 |
| Batch | 49.91 ± 0.25 | 178.95 ± 0.21 | |
| 0.002 | Incremental | 38.05 ± 1.02 | 87.12 ± 0.26 |
| Batch | 60.86 ± 0.32 | 180.48 ± 0.59 |
| Minimal Support Rate | Methods | Runtime (s) (Mean ± std) | Memory (MB) (Mean ± std) |
|---|---|---|---|
| 0.01 | Incremental | 37.76 ± 0.48 | 236.62 ± 3.75 |
| Batch | 67.8 ± 1.48 | 367.48 ± 0.25 | |
| 0.008 | Incremental | 37.77 ± 0.48 | 239.36 ± 0.32 |
| Batch | 67.2 ± 0.44 | 367.62 ± 0.08 | |
| 0.006 | Incremental | 39.16 ± 0.46 | 238.86 ± 1.19 |
| Batch | 68.6 ± 2.07 | 369.26 ± 2.54 | |
| 0.004 | Incremental | 40.91 ± 1.46 | 240.8 ± 4.40 |
| Batch | 70.4 ± 2.07 | 368.84 ± 0.11 | |
| 0.002 | Incremental | 60.92 ± 3.52 | 244.08 ± 3.30 |
| Batch | 90 ± 7.84 | 371.38 ± 0.04 |
| Minimal Support Rate | Methods | Runtime (s) (Mean ± std) | Memory (MB) (Mean ± std) |
|---|---|---|---|
| 0.01 | Incremental | 2.03 ± 0.12 | 20.54 ± 0.13 |
| Batch | 3.19 ± 0.46 | 26.88 ± 0.14 | |
| 0.008 | Incremental | 2.04 ± 0.02 | 21.52 ± 0.14 |
| Batch | 3.27 ± 0.18 | 26.98 ± 0.08 | |
| 0.006 | Incremental | 2.31 ± 0.04 | 19.64 ± 0.23 |
| Batch | 3.65 ± 0.262 | 27.14 ± 0.11 | |
| 0.004 | Incremental | 3.20 ± 0.12 | 21.08 ± 0.13 |
| Batch | 4.20 ± 0.25 | 27.58 ± 0.04 | |
| 0.002 | Incremental | 5.40 ± 0.20 | 20.46 ± 0.13 |
| Batch | 7.62 ± 0.23 | 28.62 ± 0.08 |
| Dataset | Size (KB) | Average Saved Runtime (s) | Average Saved Memory (MB) |
|---|---|---|---|
| BIRADS | 61 | 1.39 | 5.79 |
| chess | 359 | 12.55 | 44.75 |
| mushroom | 620 | 48.8 | 59.78 |
| Spambase | 686 | 22.3 | 54.2 |
| semeion | 1586 | 30.5 | 130.97 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, J.; Wang, X.; Liu, J. Incrementally Mining Column Constant Biclusters with FVSFP Tree. Appl. Sci. 2023, 13, 6458. https://doi.org/10.3390/app13116458
Zhang J, Wang X, Liu J. Incrementally Mining Column Constant Biclusters with FVSFP Tree. Applied Sciences. 2023; 13(11):6458. https://doi.org/10.3390/app13116458
Chicago/Turabian StyleZhang, Jiaxuan, Xueyong Wang, and Jie Liu. 2023. "Incrementally Mining Column Constant Biclusters with FVSFP Tree" Applied Sciences 13, no. 11: 6458. https://doi.org/10.3390/app13116458
APA StyleZhang, J., Wang, X., & Liu, J. (2023). Incrementally Mining Column Constant Biclusters with FVSFP Tree. Applied Sciences, 13(11), 6458. https://doi.org/10.3390/app13116458