3.1. Dataset Creation
This section deals with the design and implementation of machine learning models aimed at detecting HTTP DDoS attacks against network infrastructures. This includes the design of an LSTM RNN algorithm based on six correlated and cooperating layers. Using the nfstream [
79] and TensorFlow APIs, the measured network parameters can be analyzed from the PCAP input files, where a netflow matrix is generated and subsequently analyzed. Based on the various parameters, it is possible to define the input data size, and the number of epochs, which affects the speed at which a given model can be trained using the experimental input data [
80,
81].
3.1.1. Setting up the Environment
Based on the theoretical background and the methodology described above, the first step was to create a system environment in which data collection, data processing and evaluation of the results would take place. The experiment was conducted in two separate environments. The first environment focused on capturing network traffic and storing it in a PCAP data file [
82]. The second environment focused on building and training a machine learning model, which was then implemented in the first environment to validate the results. The technical specifications of the first environment is shown in
Table 2:
The technical specifications of the second environment is shown in
Table 3:
3.1.2. Dataset Design
Choosing the right dataset to build an AI model is the single most important factor influencing the accuracy of a given model. Several types of datasets were selected for use in this paper and were classified into two basic areas, as follows:
The “Normal” dataset consisted of measured samples used to verify the model used for learning. The “Attack” dataset consisted of attack samples that represented samples of inappropriate network traffic in the network under study. The study “A Hybrid Deep Learning-Based Model for Anomaly Detection in Cloud Datacenter Networks [
83]” worked with the same distribution using the DARPA98 dataset [
84]. At the start of the model training phase, both datasets were labeled. The samples were labeled with numerical labels as show on
Table 4, according to the type of attack included in the given samples:
Classifying these attacks into categories improved the focus on a particular attack when building the model. Each label contained several attack forms, focused on that area. The SYN flood attack consisted of the following patterns:
Syn_attack1.pcap—this sample contained a record of an attack directed from a device to a server using the High Orbit Ion Cannon (HOIC) application. The attack sample size was 8.3 MB. The attack was then logged using the Wireshark tool.
Syn_attack2.pcap—this sample contained a SYN attack log, in which multiple machines attacked a server, along with simulation of legitimate traffic. The attack sample size was 14 MB. The attack was then logged using the Wireshark tool.
Syn_attack3.pcap—this sample contained data from the SDN-DDOS-TCP-SYN dataset [
85], created using the mininet generator; it contained the topology of 25 servers independently using the RYU controller. The attack was then logged using the Wireshark tool.
The UDP flood attack consisted of the following samples:
The HTTP type attack consisted of several attack samples and variants: HTTP Flood, Slow Read, Slow Post, Slow Get, HULK attack, and Goldeneye attack.
Most of these attacks were concentrated in a single sample, with multiple devices attacking a single server within a single measurement. The samples used were as follows:
http_attack.pcap—this sample contained a record of an attack against an HTTP server performed using the LOIC system. The attack was performed from a single simulated device against a single HTTP server. The attack sample was 91 MB in size.
HTTPDoSNovember2021.pcapng—this sample contained a record of network traffic generated by infected devices performing an HTTP DDoS attack. The attack sample was 563 MB in size.
HTTPDoSJune2022.pcapng—this sample contained a record of network traffic generated by infected devices performing an HTTP DDoS attack. This was an updated version of the previous sample titled “HTTPDoSNovember2021”. This sample contained updated HTTP server attack methods. The size of this sample was 589 MB.
The SCAN port type attack was chosen to increase the efficiency of the given model. This attack method aims to determine the availability of the services of the attacked server. This attack involves launching a large number of automated attacks against a given organization. In most cases, the attacker first scans the server and only then selects the attack method. Therefore, it was useful to add a dataset dealing with network scanning to the machine learning model. To this end, the following samples were used to build the model:
Scan_nmap—this sample contained a record of network traffic performed by the nmap application; the latter scanned the network containing stations running WEB servers responding on standard (and even non-standard) ports. The web servers used were Apache2 and nginx. The number of servers exposed to this attack was 44, while a network of 255 IP addresses was scanned. The scan log was written by the attacker, so the sample also included attacks against unused IP addresses or IP addresses without HTTP servers. The size of this sample was 7.2 MB.
The second part of the dataset consisted of samples used to validate the model. These samples were labeled Label 0 and contained a sample of real network traffic combined with several types of attacks against the HTTP service. The log of real traffic consisted of four samples of network traffic, recorded on a production network at 1 GB per sample, resulting in a total of 4 GB of real network traffic data. The network traffic was logged using the tcpdump application and the output was then saved to a PCAP file.
3.2. Deep Learning
One of the main areas of machine learning research is supervised machine learning. In this type of learning, a model is trained on a labeled dataset to classify new, previously unknown data or to predict outcomes. This approach is commonly used in image and speech recognition or natural language processing. Another important area of research is unsupervised machine learning, which looks for patterns or structures in unlabeled data [
32]. This approach is useful in implementations where machine learning focuses on clustering and dimension reduction. In recent years, deep learning, another machine learning technique, has also gained significant momentum. This approach uses multilayer neural networks with multiple neurons to extract high-level features from the data under study. Deep learning has been particularly successful in image and speech recognition or natural language processing. Machine learning models for image parsing can also be used to analyze network traffic, as machine learning models can interpret data matrices as images, or, alternatively, the data matrices can be defined as mutually independent words. In the study “A Comprehensive Survey on Graph Anomaly Detection with Deep Learning [
87]”, a comprehensive overview of available algorithms for Deep-learning was conducted.
According to the authors of “Machine learning and deep learning [
88]”, Deep learning is typically made up of several hidden layers that are deeply embedded in network architectures. They usually contain twisted neurons. It is, therefore, possible to perform advanced operations with their help, such as convolution.
Deep learning is an aspect of machine learning that is used in image and text processing. It uses several non-linear layers of processing to extract important objects from the data [
89]. Deep learning has now become a method for creating highly accurate systems for classifying objects from data sets. The benefits of deep learning include the following [
73]:
High ability to recognize and classify objects.
Ability to use high performance GPU cards to accelerate performance. Using these methods, it is possible to reduce the training time of a model to a few minutes.
High availability of datasets to build custom models for desired situations.
All deep neural models use large amounts of data, labeled with the expected output of the tasks, and multi-layer neural networks for training. The main advantage of these models is the processing of sequential information, where Hidden Markov models and n-gram language models are used. Traditional neural networks assume that output variables are dependent on input variables [
89]. However, research has shown that this is not always the case and that the data are not always dependent. This fact is addressed by the use of the Recurrent Neural Network (RNN) model, where the recurrent part is the result of the model’s ability to perform the same task for each element of the data sequence [
72]. RNN is capable of modeling sequence data for the needs of similarity recognition and sequence prediction in data. The RNN is built with high-dimensional hidden states that have nonlinear dynamics [
90]. Then, the output of the model is highly dependent on the results of the previous step.
The example in
Figure 4 shows the way in which the RNN model is trained. The data transfer between training iterations is evident. Thus, an RNN can be thought of as a memory model, where the history of the results of each step in previously processed data can be stored indefinitely. Using the model, each of these values is used to predict the next output of the process.
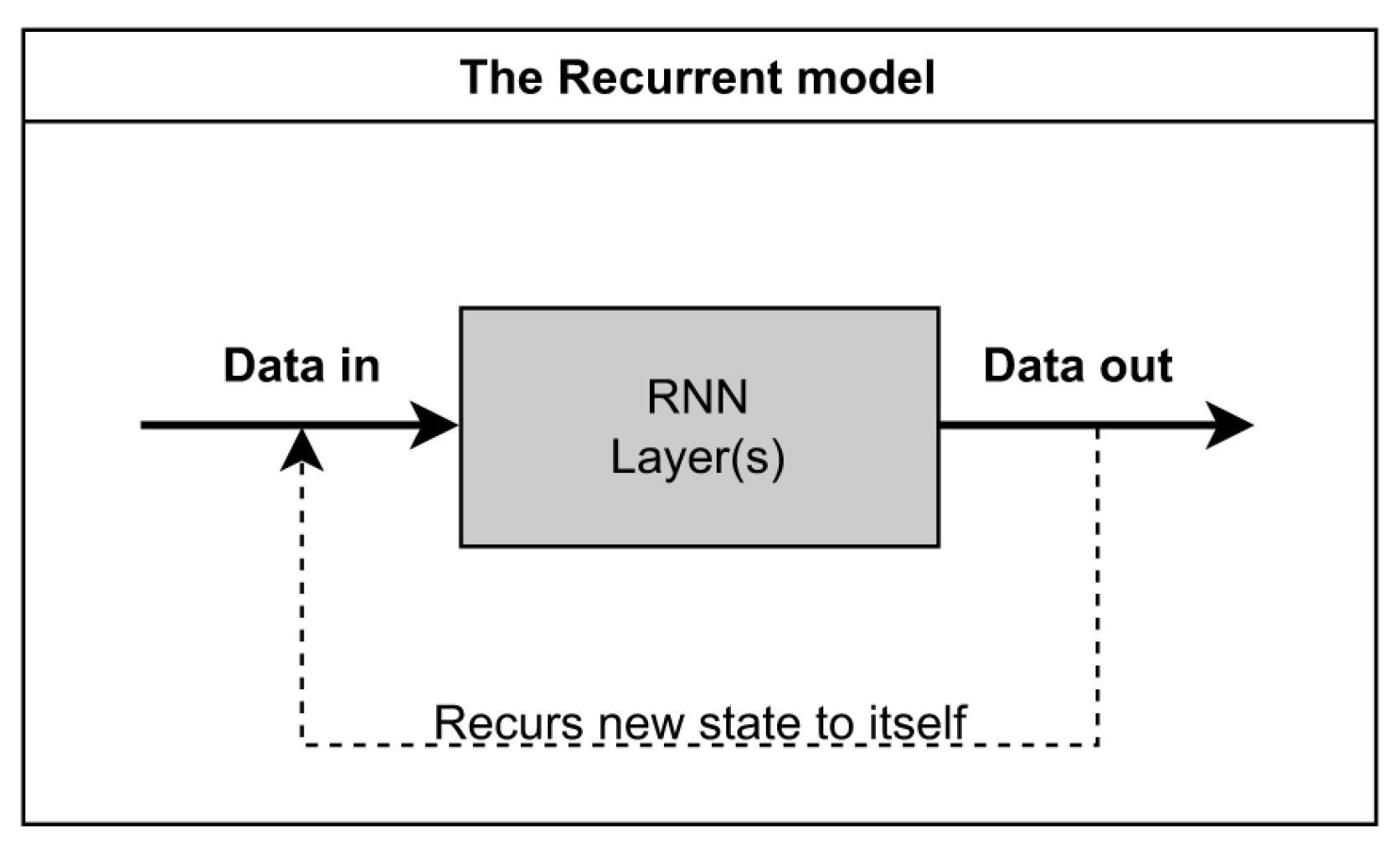
Figure 5 shows a simplified representation of the RNN model, where an iteration block can be represented as an RNN layer. This layer then operates on the input data. The output data from the model is also used in the input calculations. To increase the accuracy, several such layers can be selected in the model to increase the number of iterations.
LSTM RNN machine learning was chosen as the technique for our work because, out of RNN techniques and existing conventional machine learning techniques, LSTM RNN is ranked as the best machine learning technique. This ranking is the result of its ability to learn a longer framework of historical features that enter the algorithm during machine learning training. Unlike other machine learning techniques, LSTM is able to solve the problems associated with a pure RNN with BPTT, by ensuring that the error is kept constant so that the RNN can learn over long time intervals. The RNN LSTM machine learning was able to achieve an accuracy rate of 97.996%, which the older machine learning technique could not achieve [
71].
3.3. TensorFlow
TensorFlow is a flexible library for numerical computation using graphs and data flow. With this library, neural networks and other machine learning models can be programmed and trained in an efficient way [
89]. The underlying algorithms are optimized to use Nvidia CUDA tools, making it possible to achieve high computational parallelism using multiple devices. The TensorFlow library represents data in the form of tensors. Tensors are multidimensional arrays of data that actually flow as graphs from node to node. In fact, such a graph can be described as a three-dimensional matrix, which need not be strictly mathematically defined [
89].
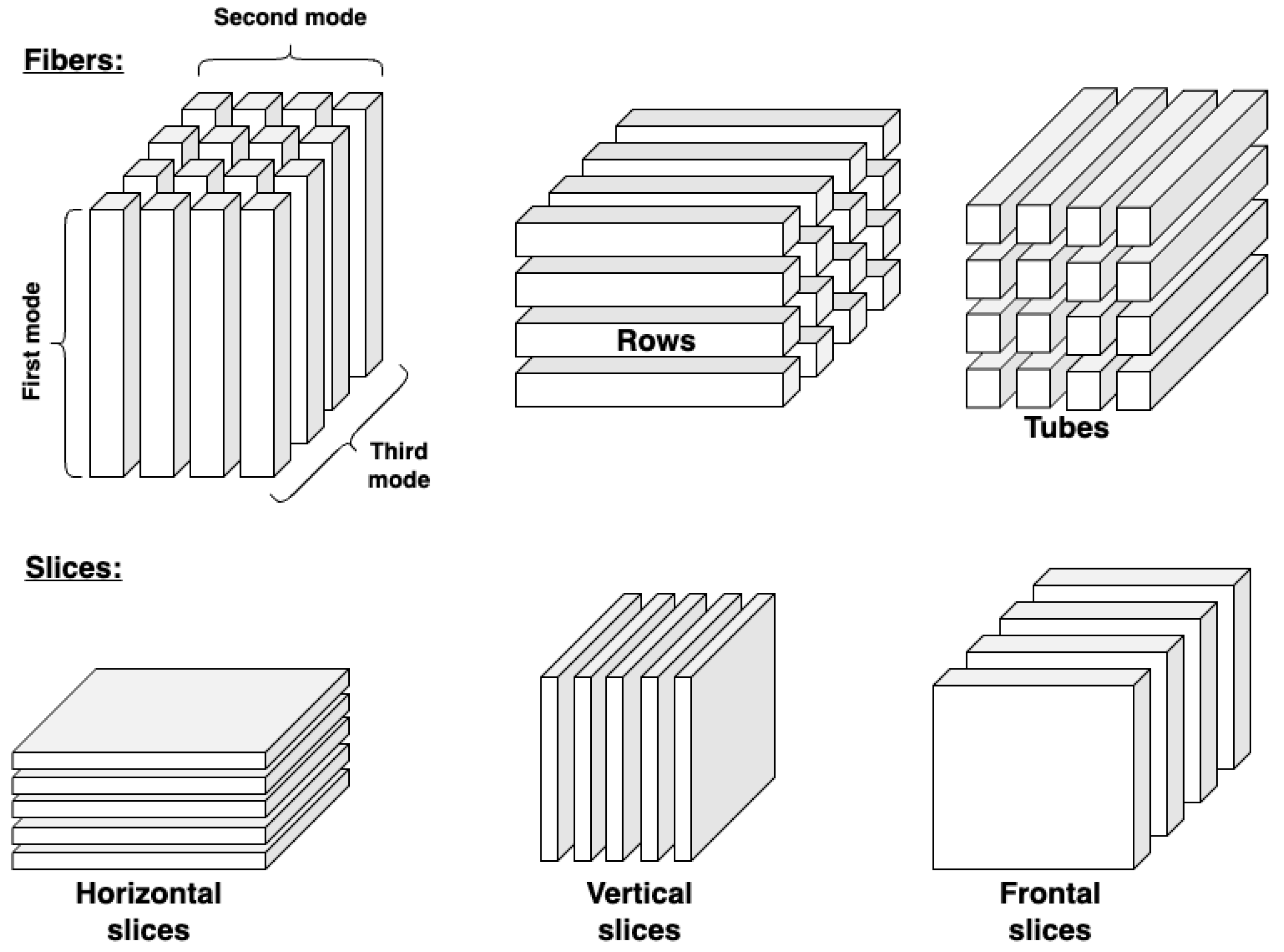
Figure 6 shows a vivisection of a tensor. This tensor has multiple inputs in terms of data selection.
Advantages of the TensorFlow library used in this work:
Great support for different machine learning models and tools for building neural networks.
The ability to generate any graph from the input data. The system is flexible in choosing the sets from which the data is plotted.
The system includes predefined mathematical functions for building neural network models.
Simple support for graphics accelerators is available, which can speed up the training of the model using multiple graphics cards.
It easily supports various operating systems, including Windows, Linux, Android and iOS.
It can be used flexibly for research or easy implementation in a production environment.
Auto-differentiation allows automatic computation of gradient-based machine learning algorithms, such as stochastic gradient descent.
There is support for the development in Python, in both Python 2 and Python 3 versions.
When developing AI models, it is important to consider metrics that focus on the performance and efficiency of the model. Efficiency is highly dependent on high detection rates and low false positive or false negative rates [
91]. However, it is also possible to measure these systems using other methods, such as measuring system power consumption, memory consumption, computational intensity of the models, and other parameters [
92]. The N-level detector is usually evaluated in terms of accuracy, where several terms can be defined [
21]: True Positive (
TP), True Negative (
TN), False Positive (
FP), False Negative (
FN).
Based on these concepts, the model can be evaluated using different metrics. Based on the aforementioned metrics, designed for the classification component of the detector, it is also possible to perform the analysis globally. Based on the global analysis, the whole system and model is evaluated from the input data, including training, to its output in the resulting system model [
72]. For these purposes, the following parameters can be defined:
Packet Loss Ratio (%)
Normalized Routing Load (Packets)
Average End-End Delay (Seconds)
Average Energy Dissipation (Joules)
Malicious Drop (Packets)
False Detection (%)
Send Buffer Drop (Packets)
When training a model, it is necessary to define how to measure its errors. These errors can be called a loss function, where the goal is to find appropriate parameters that minimize the percentage of errors [
72]. The cross-entropy loss function can be defined as follows [
93]:
Architecture for Dataset Analyses
The network traffic datasets prepared for the purpose of building a model using TensorFlow, were stored in PCAP format. However, this format cannot be used optimally to train a model aimed at finding network traffic anomalies. Therefore, the nfstream framework was used as an intermediate framework for data classification.
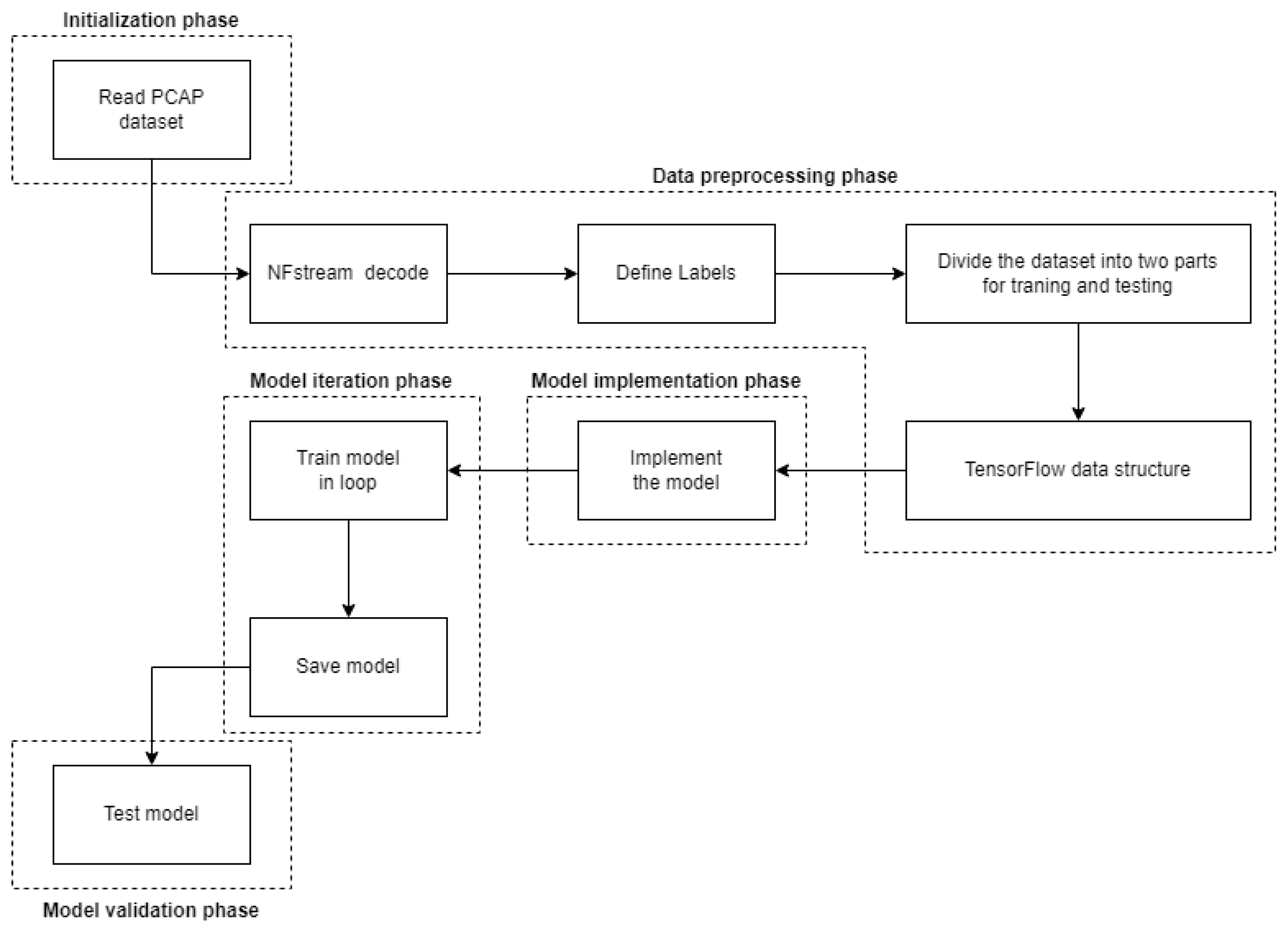
Figure 7 shows the model we used to analyze samples in PCAP format. Pre-processed PCAP files were used as input data, where the NFstream framework allowed the creation of the desired netflow data, which were then tagged with the appropriate labels.
The NFstream framework is a fast python module that provides fast, optimal and flexible data structures designed for analyzing ONLINE or OFFLINE network traffic. This framework is designed to provide a basic building block for network traffic analysis using NDPI classification and using established machine learning models. The advantage is the fast creation and structured reproducibility of the data in sub-applications for research purposes. Another advantage is the ability to perform deep packet analysis, which allows the detection fingerprinting of applications in network traffic, such as TLS, SSH, DHCP, HTTP etc. Network traffic analysis using nfstream was performed with the following parameters:
streamer = NFStreamer(source=file_path, statistical_analysis=True,
n_dissections=200)
The options we enabled included the following:
statistical_analysis—post-mortem flow statistical analysis. This option allows the storage of statistical data from measured network traffic, such as the amount of packets transmitted, minimum and maximum packet size, and other metrics
n_dissections—the number of packets to analyze when detecting L7 protocols with NDPI. The default size is 20, which is insufficient for measurement purposes and the number of packets analyzed must be increased to improve accuracy.
Once these data had been processed and saved in CSV format, an additional column was added to contain the given LABEL of the desired sample.
3.4. Building the Model
The idea behind this work was to use sequential information, which, using traditional neural networks, assumes that all inputs and outputs of the model are independent of each other. Therefore, we used RNN recurrent neural networks, as these perform training for each element independently, while the result is strictly dependent on the previous results [
32]. The basic step in building the model was to unify the data used in the training process. We stored the data converted using nfstream in separate CSV files containing NETFLOW records with the labels added. These records may also contain, in multiple files, different data, produced by the nfstream application. Then, we extracted uniform data from these records and normalized them to have the same number of parameters for each flow solution. If a parameter was missing in any of the samples, the application added the predefined value, i.e., 0. In this way, we ensured that the model building process would work with equally sized matrices of data, thus eliminating the potential risk of inaccuracy or miscalculation. When building the model, we used the following data from the nfstream application:
"src_port","dst_port",
"src2dst_packets", "src2dst_bytes",
"dst2src_packets", "dst2src_bytes",
"src2dst_min_ps","src2dst_mean_ps", "src2dst_stddev_ps", "src2dst_max_ps",
"dst2src_min_ps", "dst2src_mean_ps", "dst2src_stddev_ps","dst2src_max_ps",
"src2dst_min_piat_ms", "src2dst_mean_piat_ms", "src2dst_stddev_piat_ms",
"src2dst_max_piat_ms", "dst2src_min_piat_ms", "dst2src_mean_piat_ms",
"dst2src_stddev_piat_ms","dst2src_max_piat_ms",
"src2dst_syn_packets", "src2dst_cwr_packets", "src2dst_ece_packets",
"src2dst_urg_packets","src2dst_ack_packets", "src2dst_psh_packets",
"src2dst_rst_packets","src2dst_fin_packets",
"dst2src_syn_packets", "dst2src_cwr_packets","dst2src_ece_packets",
"dst2src_urg_packets", "dst2src_ack_packets","dst2src_psh_packets",
"dst2src_rst_packets", "dst2src_fin_packets","src_port","dst_port"
Figure 8 shows the algorithm of the code. It can be divided into five main phases as shown on
Table 5:
The initialization phase of the program defines the parameters required by the algorithm, as well as defining the constants required for the subsequent steps of the code. In this phase, we also stored the necessary datasets, which served as model training and validation data, respectively. In the data pre-processing phase, the uniform samples were loaded and categorized into the desired form. The next phase was the model implementation phase, where the implementation of the fivelayer RNN algorithm model took place. In this phase, the weights and biases specified for the model nodes were randomly generated. This was followed by the implementation of the training algorithm, where the algorithm was trained on the required data. This phase depended on the iteration phase, where the learning process was repeated after a certain number of iterations in order to train the given model more accurately. The functionality of the model was then verified. Using test functions, the model was loaded and subjected to test data, comparing the accuracy of the untrained model used in the data analysis process. Parameters on
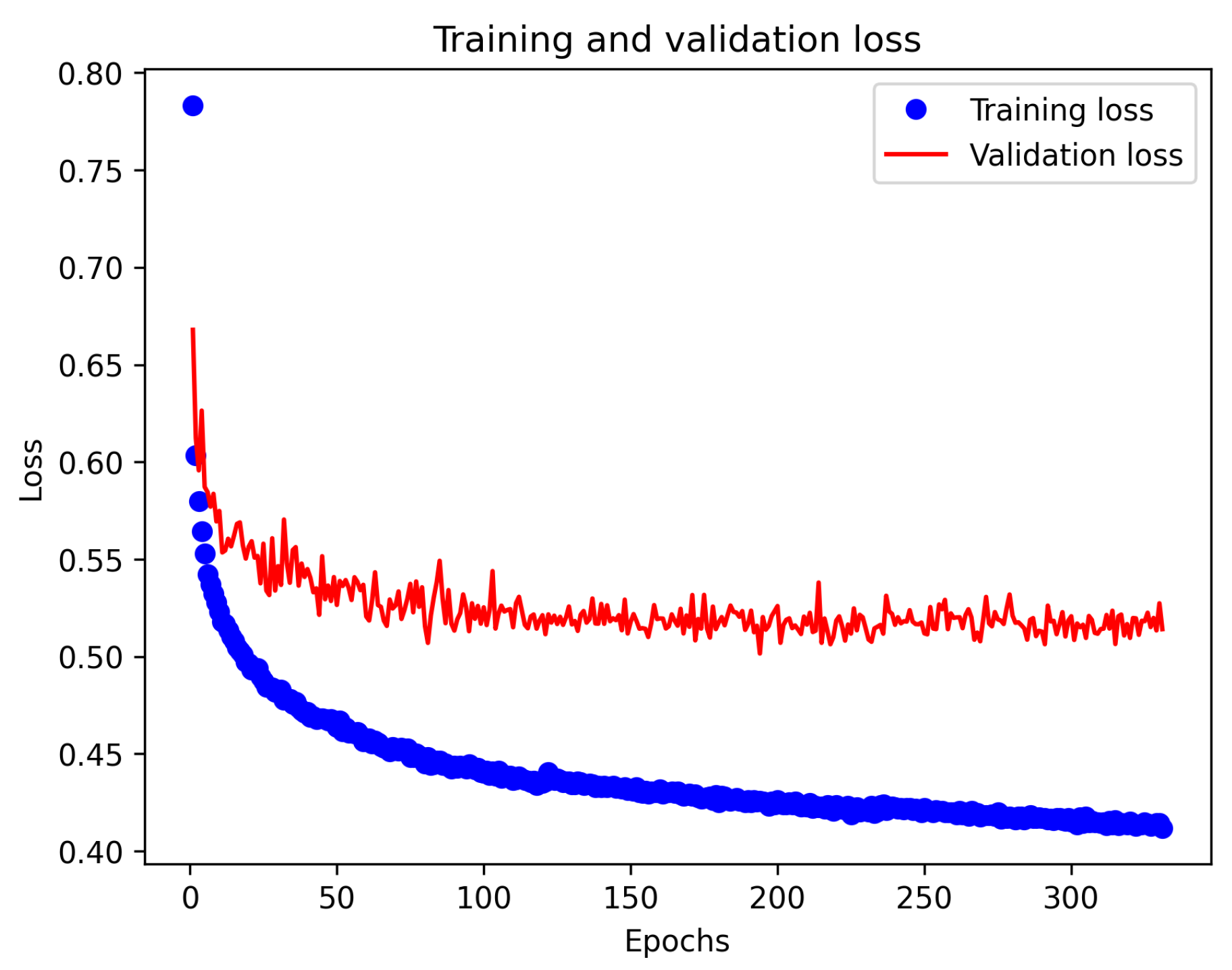
Table 6 were used to train the experimental model:














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}