1. Introduction
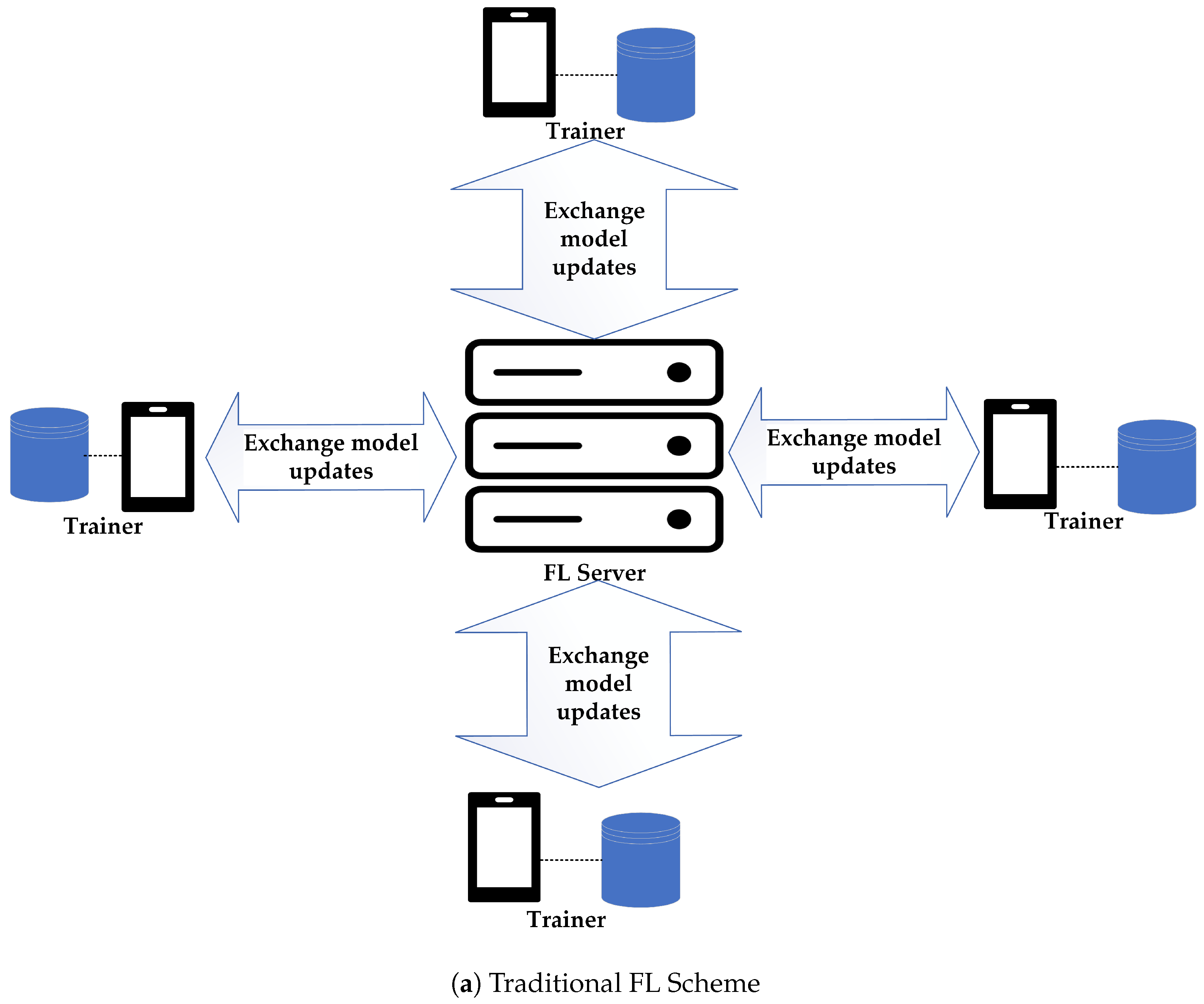
Federated learning (FL) is a method of preserving user privacy during data collection in machine learning. However, traditional FL schemes rely on a centralized server to aggregate model updates, making them vulnerable to security risks, such as data breaches, unauthorized access, and tampering with models [
1]. An example of a data breach is the act of eavesdropping on communication channels during weight and gradient updates [
2,
3]. The effect of such an act can cause loss of privacy, reduced public trust in FL systems, and legal and financial liabilities. Additionally, Sybil attacks, where an attacker creates multiple fake identities, manipulates FL results, and consumes resources, can also hurt the trustability of FL in general. Another set of problems is the reliance on a single central server, which is vulnerable to denial-of-service attacks as the system expands [
4]; moreover, there is a concern regarding the emergence of bad faith actors who may destabilize the system as more people become involved [
1].
To counteract the vulnerabilities in traditional FL, as mentioned above, replacing the server with a blockchain as an aggregator has been a solution utilized in multiple works [
5,
6,
7,
8,
9,
10,
11,
12,
13,
14,
15,
16]. References [
5,
11,
12] added incentive mechanisms that encouraged honest parties. References [
6,
7,
8] introduced generic designs for efficient and private FL systems that protect against inference attacks on clients’ model updates by using secure aggregation. References [
10,
13,
14,
15,
16] focused on blockchain infrastructure. These studies leveraged smart contracts, improved consensus algorithms to evaluate participant contributions, and implemented incentive mechanisms within the framework. One common aspect among the mentioned works is the absence of accountability management. During training, trainers might misbehave, and the system cannot differentiate whether a trainer is fully trustworthy until the end. For example, a hacker might gain access to a trainer’s account and use its identity to inject bad updates to the model, while masquerading as a normal, uncompromised account. There is also the unmentioned problem of model leakage during transmission, which can allow attackers to access the data by eavesdropping on the communication channels, or masquerading as a participant in the scheme.
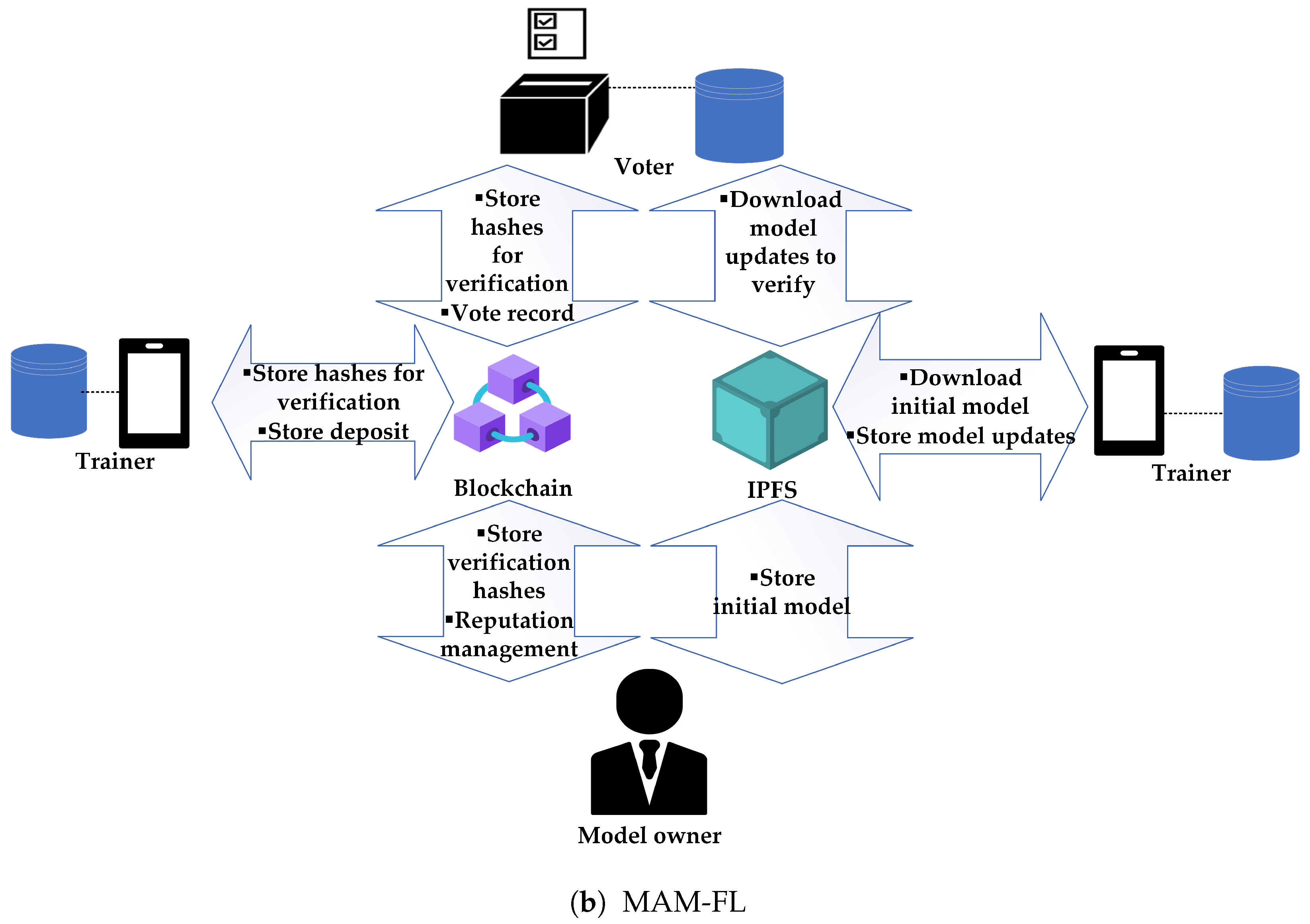
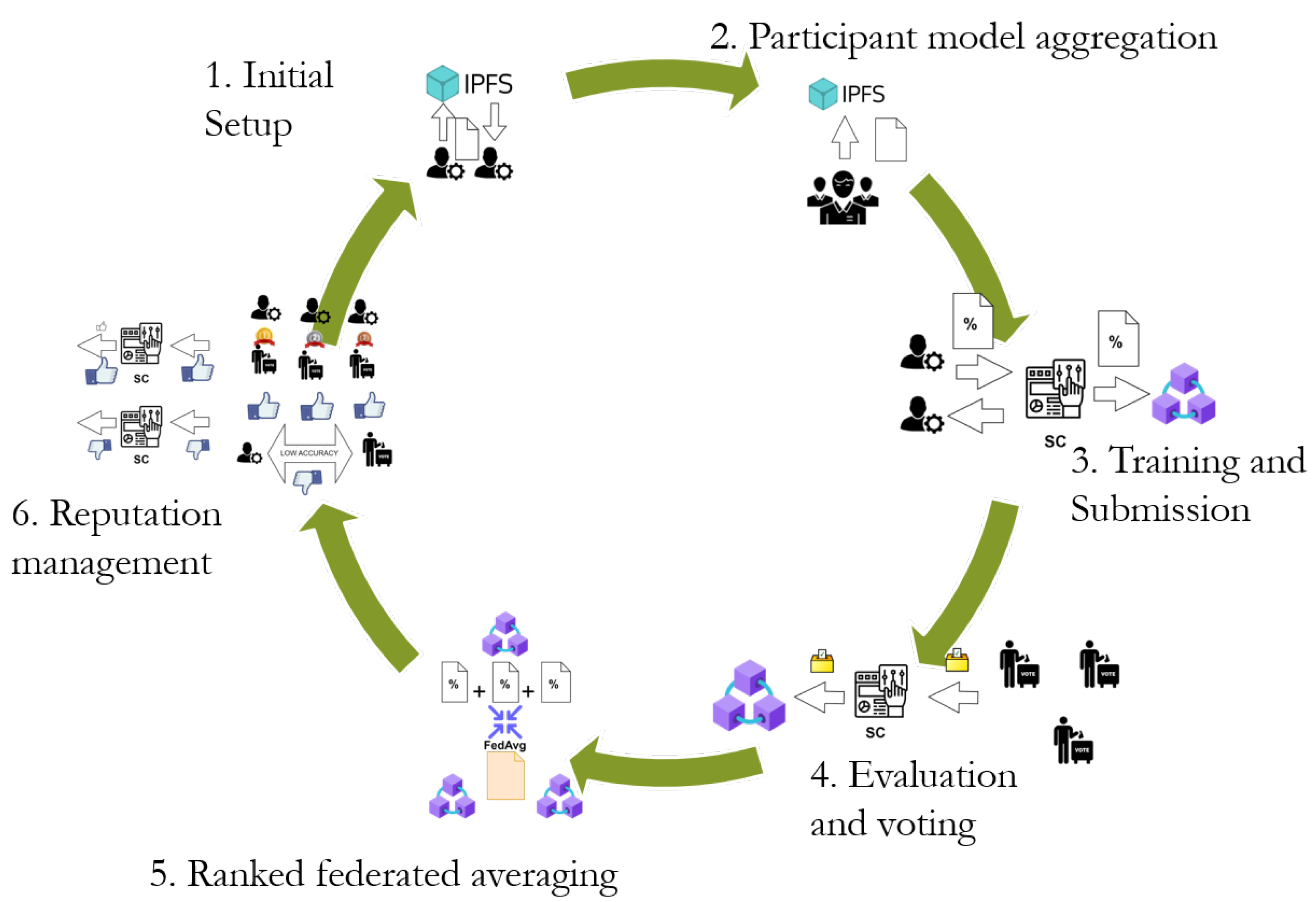
In order to tackle the problems, such as the lack of accountability management, malicious actor prevention, and model leakage, MAM-FL, a scheme that addresses vulnerabilities, is proposed. First, in MAM-FL, signcryption is adopted to prevent model and privacy leakage by providing encryption, signature authentication, and integrity verification. An accountability-checking mechanism is integrated through a party of voters to verify the accuracy claims of trainers. Adding a verifying party will create a need for trainers to assume responsibility, which provides accountability and ensures consistency in the quality of the model updates. MAM-FL consists of an initial setup, leading up to the creation of the next global model, in which the selected model updates are chosen through the result of ranking the scores in the model updates. Throughout MAM-FL, blockchain and the InterPlanetary File System (IPFS) [
17] act as communication channels to provide reliability and resistance toward single-point-of-failure (SPoF) caused by DDoS attacks and spam, which is a property of a decentralized system. Finally, to motivate participants to join and then perform honestly, a reward system is proposed, which grows proportionately based on the participant’s initial deposit.
The following contributions are provided in this paper:
We address several concerns of traditional federated learning and formulate seven requirements based on existing solutions. We provide reasoning to explain how MAM-FL can fix the problems mentioned in the seven requirements.
Signcryption is integrated into the initial model transmission to provide confidentiality; blockchain provides reliable protection against single points of failure and verifies the integrity of data during communication.
An FL protocol utilizing a voting-based mechanism is proposed. The voting system is combined with a dynamic reputation system that affects the weight of the votes. The purpose is to introduce accountability measures that can detect and prevent malicious actors from jeopardizing the FL ecosystem.
The rest of this paper is organized as follows. First, the definitions are listed in
Section 2. In
Section 3, seven proposed requirements are shown, along with the state-of-the-art blockchain-based FL protocols. MAM-FL protocols are described in
Section 4, and the whole scheme is evaluated in
Section 5. Finally,
Section 6 concludes the whole paper.
3. Requirements for Trustability in Federated Learning
First, multiple requirements to satisfy trustability in a federated learning setting are defined. In each requirement, a discussion is made on how the property has partially been met by existing solutions previously researched.
R1 Confidentiality.
Malicious entities can attempt to obtain access to local models and global models by listening to communication channels and then modifying the model data; this involves changing the original owner’s data in the model, claiming the model, and then using it for their own gain. Therefore, this requires a solution that can prevent the model from being inferred by the adversaries. One particular solution involves performing encryption [
24] during the process of aggregating updates and on the original model itself, with a public key encryption scheme, in such a way that outside entities cannot recognize the contents of the data exchange.
R2 Attractiveness.
In FL, the organizer needs to provide a method for consistently recruiting new trainers, as without enough trainers, the resulting global model will not be accurate due to the limited amount of data. Furthermore, having more trainers will increase data diversity, as they will train with different datasets based on their own devices. However, from a trainer’s perspective, engaging in local training imposes a cost on their resources. The workers will most likely not perform the FL tasks in the vanilla FL without the motivation to perform the training. To counter this, one author proposed an incentive system to encourage trainers to join the training, mostly via token-based rewards [
25].
R3 Accountability.
The major problem with a centralized FL model is that it lacks mechanisms to hold each participant accountable in a fair and objective way [
26]. Some trainers can perform training using low-quality datasets on their devices, which can impact the quality of the expected model, and the absence of accountability can be a problem, as this will cause a continuous loop of bad updates from the trainers. The system needs to prepare a solution that can encourage trainers to train with better data while also being capable of detecting and punishing trainers who intentionally manipulate their model accuracy. One author’s solution is to impose a reputation system with levels [
27], combined with the incentive system that rewards trainers based on their reputations. This encourages trainers to exhibit positive behavior and improve their reputations. If a trainer continues to perform honest training without any detected misbehavior, they will receive increased rewards at the end of the training, while dishonest ones are punished. By imposing this rule, trainers cannot easily remove themselves or reduce their participation, since doing so would diminish the tokens they deposited; this responsibility would compel trainers to continue through the process with good behavior.
R4 Reliability.
As the number of trainers increases, a single central server might not have enough capability to handle the communication overhead. Attackers can attempt DDoS (distributed denial-of-service) attacks, which will generate significant overhead for the central server, causing the whole FL system to crash and shut down in the process. The authors of Reference [
28] suggested a committee of nodes that could serve as the replacement for the central aggregator. This committee is selected based on a metric system that takes into account factors such as liveliness (the rate at which a node remains available and is not down) and reputation. The most trustworthy nodes will be more likely to be selected as committee members.
R5 Consistency.
The lack of trainers with stable internet connectivity might hamper the ability to upload complete parts of their updates since an unreliable network cannot guarantee the full transfer of the update parameters. Malicious trainers can also use this method of dropping and rejoining the model training to intentionally submit low-quality updates. All of this will cause the global model to be updated with broken chunks of updates, hampering accuracy. One proposed scheme [
27] imposes a time limit to prevent low-connectivity trainers from sending broken or corrupt updates to the server. This solution attempts to prevent trainers with low connectivity from submitting their updates, which can harm the model’s accuracy because the broken parts are being submitted instead of the whole parts.
R6 Integrity
Model integrity is critical in FL because the accuracy and effectiveness of the machine learning model depend on the quality and reliability of the data used for training. Any tampering or corruption of the data can lead to inaccurate or biased results, which can impact the performance of the model and its ability to make accurate predictions. In an FL environment, data are distributed across multiple devices or clients, and updates are made to the model by aggregating the results of the training performed on each device. As a result, it is essential to ensure that the data used for training are complete, accurate, and consistent across all devices. Blockchain technology can be used as an integrity solution for the federated learning training process by providing a transparent and tamper-proof ledger of all transactions and computations performed during the training process [
20]. By using a blockchain, participants in the federated learning network can record their contributions to the training process, including the models they trained and the data they used. These contributions can be verified by the other participants in the network by using the blockchain, ensuring that all participants are contributing in a fair and transparent manner.
R7 Authentication
Authentication is critical in FL because it ensures that only authorized devices or clients participate in the training process and make updates to the machine learning model. Without authentication, there is a risk of unauthorized access to the data and the model, which can lead to data breaches, theft of intellectual property, and other security issues. In an FL environment, authentication is typically achieved through secure communication protocols, such as transport layer security (TLS) and secure sockets layer (SSL) [
29]. These protocols encrypt the data being transmitted between devices or clients, ensuring that they cannot be intercepted or modified by unauthorized parties. Authentication can also be achieved through the use of digital certificates and public key cryptography. Each device or client can be issued a digital certificate that contains a public key, which is used to verify the identity of the device or client during the authentication process. The device or client can then use the private key to sign the updates it makes to the model, ensuring that they are authentic and cannot be tampered with.
Previous Approaches and Limitations
Several blockchain-based frameworks and protocols, such as BFL [
5], BEAS [
6], BytoChain [
8], DeTrustFL [
9], ModelChain [
13], Twin FL [
14], and SEC-CL [
15] lack incentive mechanisms in their systems, which may cause participants to have no motivation to share their data or model updates with the model’s owner, leading to low participation rates and poor learning performances. Meanwhile, DeepChain [
12] offers blockchain-based FL with incentive- and deposit-based systems; however, it does not integrate a reputation system, which could serve as a vulnerability as attackers can masquerade as trainers.
References [
5,
16] utilized practical Byzantine fault tolerance (PBFT) as an alternative to PoW consensus during training. However, PBFT is limited in that the system cannot tolerate a number of malicious nodes in the network equal to or greater than one-third of the total number of nodes. While the reputation system can enhance the reliability of the system to some extent, there is a lack of external verification of the reputation, such as through a third-party review process.
Reference [
7] proposed a blockchain-based FL framework with differential privacy as encryption. Differential privacy helps protect the privacy of individuals in a dataset by adding random noise to the data or the queries. This noise introduces a trade-off; while providing privacy, it can affect the utility or accuracy of the data analysis [
30].
Reference [
10] proposed a permissioned blockchain-based federated learning method, where incremental updates to an anomaly detection machine learning model are chained together on the distributed ledger. However, this paper focused more on the machine learning model and did not mention much about the importance of incentive mechanisms and other aspects, such as security, accountability, or confidentiality of FL.
Reference [
11] leveraged blockchain-sharding features to enable collaborative model training in a more distributed and trustworthy manner. Blockchain sharding, however, can compromise security and decentralization, as each shard may have fewer nodes and less hash power than the whole network, making it more vulnerable to attacks or collusion.
Reference [
27] proposed a blockchain-based scheme with a leveling system, wherein trainers gain experience and reputation over time, leading to better rewards for their performance. However, since the proposed peer-review system forces each trainer to also act as a reviewer, it can be deemed unreliable due to the necessity of multitasking [
31].
The research conducted by [
32] centered on the integration of FL in a vehicular ad hoc network (VANET) environment. The study assessed the performance of devices, the efficacy of ML and aggregation algorithms, the effects on edge-to-server communication, and resource consumption. However, it did not address the incentive mechanism, confidentiality, and reliability aspects essential for sustaining federated learning.
Reference [
33] introduced the incorporation of local differential privacy and zero-knowledge proof in a blockchain-based FL framework. While this work provides confidentiality using differential privacy and incentives, it does not provide a trust management system to combat malicious actors masquerading as honest workers.
Based on these observations,
Table 1 shows which references satisfied the requirements listed in
Section 3, marked by √, while × is for the unsatisfied ones.
To improve accountability, MAM-FL utilizes a voting-based system to select models for averaging. In the beginning, trainers must first deposit a specific amount of tokens in order to join the network and participate in the training and voting process. This deposit system serves as an added layer of security, as it ensures that clients have a vested interest in the network and are less likely to act maliciously. The added voting mechanism imposes responsibility to both trainers and voters; an honest voter will have a more significant impact on the overall score of the model updates that will be accepted, while a malicious voter can be identified for collaborating with other malicious trainers, and both will be punished together, accordingly.
In addition to the voting and deposit systems, MAM-FL adds a reputation system for participants. This reputation system will track participants’ past behaviors, such as their participation and contribution to the network, as well as any negative actions they may have taken. Clients with higher reputations will more likely be selected for model averaging and receive higher rewards.
Some aspects of importance that previous works have yet to highlight are integrity and authentication. Blockchain has been used as a method to provide incentive systems and FL reliability (e.g., SPoF) but prior studies have not highlighted the immutability of the blockchain as a key feature [
5,
6,
7,
8,
12,
13,
16,
33]. Leveraging the blockchain as a verification mechanism can provide a way to ensure integrity of the data transfer process in federated learning.
5. Experimental and Proposed Scheme Analysis
The experiment was conducted on a machine with Windows 10 as the operating system with an Intel Core(TM) i7-8700K CPU and 32 GB RAM. A Docker container with 2 CPU cores and 2 GB of RAM was utilized to run Ganache. The smart contract was written in the Solidity language and deployed to Ganache using Truffle.
In the experiment, 10 iterations with 30 participants of FL simulations were performed, with the population composed as follows:
20 trainers (10 malicious, 10 non-malicious)
10 voters (3 malicious, 7 non-malicious)
To participate, trainers and voters must initially stake a minimum of 5 million gwei (which is equal to approximately ETH 0.005, which, as of 28 April 2023, was equal to USD 9.58), and will earn rewards that are proportional to their reputations. For example, a participant with x million gwei and y reputation will receive (y/10)% of their current gwei deposit, resulting in a new deposit of gwei for the next iteration. Therefore, maintaining consistent performance and reputation is crucial for participants to maximize their rewards.
5.1. Reputation Progression
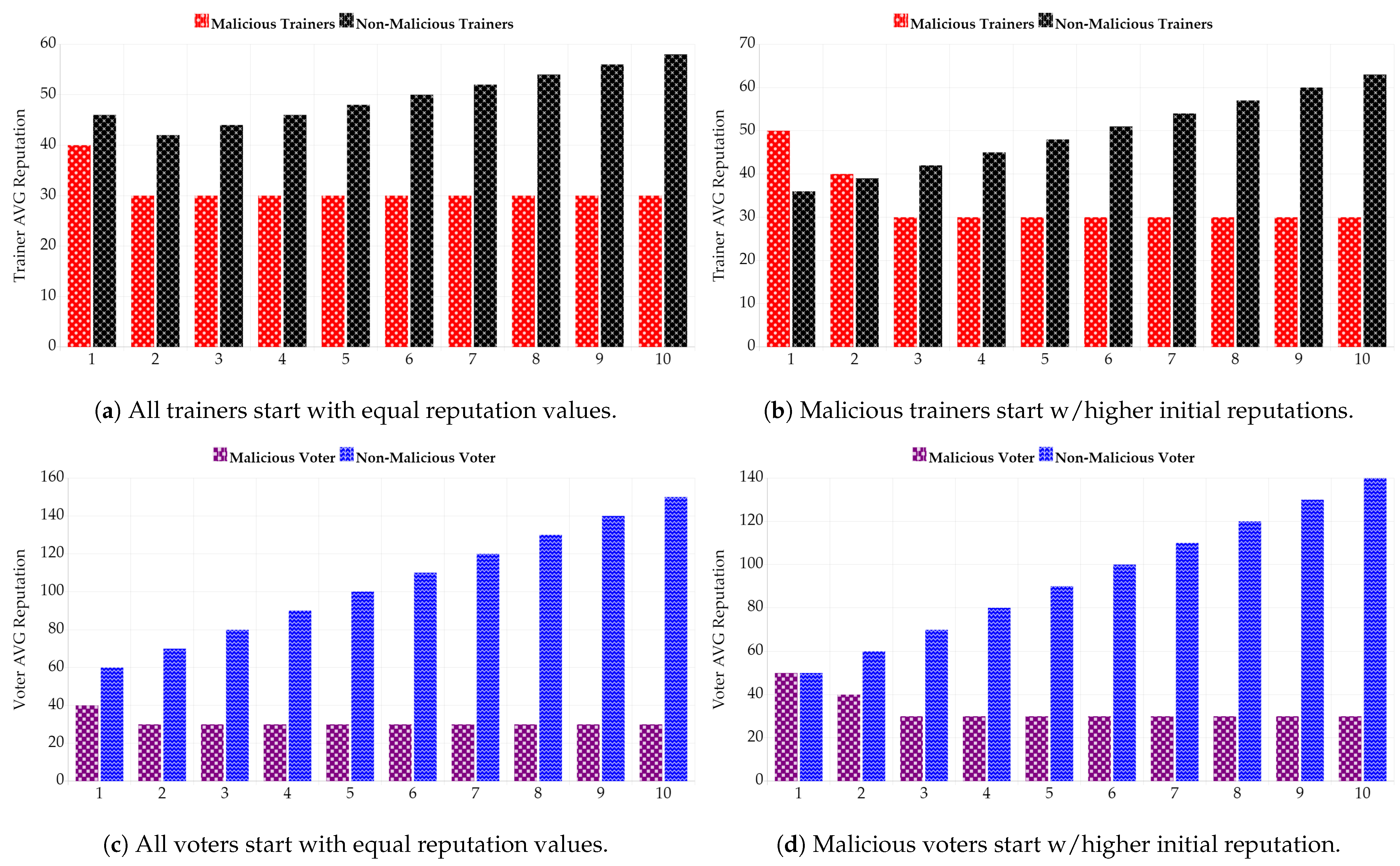
Figure 8a shows that when the same reputations are established for all participants, malicious trainers are immediately banned from participating in their second iteration. There is also a slight decrease in the non-malicious trainer reputation in the second iteration, indicating some honest trainers can still submit low accuracies due to unforeseen circumstances, such as low bandwidth or unstable connectivity. A different parameter test is conducted with malicious trainers, starting with 60 initial reputation values (as opposed to honest ones starting with 40), as depicted in the results in
Figure 8b. The rationale behind this test was to simulate a scenario where collusion had occurred, and the majority of the malicious actors had managed to obtain a higher reputation than the non-malicious ones. Even though the initial collusion might be successful, as reflected by the higher reputation scores, the model update ranking allows for the collusion to be detected over time.
Figure 8c,d similarly depicts malicious voters that have a similar reputation progression to their trainer counterparts. Additionally, the reputation system is designed to identify trainers who submit low-quality updates, typically caused by connectivity issues. Such issues result in submitting broken update chunks that may lead to lower-than-expected accuracy. To ensure model consistency, the system is engineered to select only trainers with stable performance. During the evaluation phase in
Section 4.6, voters detect low-accuracy updates and vote to reject them. The sum of votes with the accept, reject, and negative votes reflects the results of the experiments, demonstrating that the system effectively filters out inconsistent trainers and malicious actors from the FL scheme.
5.2. Reward Gain
The correlation between reward and reputation (
Figure 8a–d and
Figure 9a–d) shows that maintaining reputation is essential to preventing an account ban. As shown in the ten iterations, participants with higher reputation values experience exponential increases in rewards. Compared to the first test with equal reputation values, the malicious participants’ rewards start higher than those of honest ones. However, since the malicious trainer-submitted models are low in quality, their scores are lower than average and are subject to punishment. This results in a decrease in their reputation and leads to them being banned. When participants are banned, their accounts are frozen, temporarily preventing their deposited tokens from being withdrawn. This measure discourages participants from creating multiple accounts, as participants would need to stake tokens again to join. The reward system incentivizes trainers and voters to participate honestly in the schemes, as their rewards directly correlate with their reputations. Moreover, participants have a responsibility to maintain the tokens that they deposited at the start.
5.3. Gas Fee
The following tests were conducted using the Truffle testing library in a local Ganache environment. It has been verified that all of the implemented methods comply with the Ethereum gas limit standard of 30 million per block [
35], rendering them feasible for execution on Ethereum networks. The gas usage values reported in
Table 3 are calculated per unit, with each unit corresponding to a single instance of the method being executed. Each method serves a specific function in the smart contract, such as adding a new participant or updating global accuracy for the next iteration. For instance, “calculateReputation” calculates a participant’s new reputation at the end of an iteration, and “setReputation” is used to update the value in the chain. It is important to note that the total number of transactions required for each method in a federated learning task depends heavily on the number of participating clients.
5.4. Requirement Comparisons Compared to Previous Works
Table 1 in
Section 3 details the extent to which previous works have fulfilled the requirements.
Table 4 shows the property comparison between the proposed scheme and other existing works. The benefits of MAM-FL are directly compared with two selected sources, namely References [
7,
27]. These papers were chosen because they meet most of the requirements compared to the other references.
Confidentiality: Reference [
7] uses differential privacy to maintain the confidentiality of data in federated learning. Differential privacy has an advantage over encryption in that it allows for data sharing and analysis for scientific or social purposes, while protecting the privacy of individual data entries. However, this technique may introduce data errors or uncertainty and conflict with other privacy technologies. Reference [
27] adds a standard model encryption in the FL on the participant keys. While encryption can prevent unauthorized access to data and preserve the exact values, it may limit data usage and analysis and expose the data to re-identification attacks. MAM-FL uses a signcryption scheme to encrypt the initial model, which combines the functionalities of digital signatures and encryptions in a single operation. This is a reasonable trade-off since signcryption provides other requirements that are not available in standard encryption, such as authentication and integrity.
Attractiveness: References [
7,
27] and MAM-FL use rewards to serve as motivation for participants to maintain good behavior and high performance, ensuring the quality and effectiveness of the federated learning process.
Accountability: Both [
27] and MAM-FL require participants to deposit a certain amount of tokens to participate, which creates an additional level of responsibility for the participants to continue the process until they receive their rewards. The risk of losing the stored tokens also adds protection against Sibyl attacks, hindering attackers who create multiple accounts. In Reference [
27], a peer-review system was added, where each trainer acted as a reviewer for the other. However, this system can be unreliable since the trainers have to multitask and may lose focus. In contrast, MAM-FL assigns the roles of verifiers to voters, who contribute to the ranking of accepted model updates. This further helps establish accountability for each participant in the process without overwhelming them with too many tasks.
Reliability: References [
7,
27] and MAM-FL use blockchain, a distributed ledger, to record FL transactions. By nature, blockchain can address SPoF by allowing the participants to maintain a distributed ledger of the FL process, where each block records the model’s updates and other relevant information. However, MAM-FL goes beyond simply integrating the process of each exchange between transmissions by utilizing smart contracts. Because storing model files can be costly, References [
7,
27] and MAM-FL utilize decentralized storage, with IPFS being chosen in this case.
Consistency: Reference [
7] uses differential privacy, where the added noise can make it difficult to achieve convergence of the model across all clients. This is because the noise added to each client’s data can be different, which can lead to inconsistencies in the model’s updates. Reference [
27] uses stage timeout to limit low-bandwidth trainers from submitting broken updates. In MAM-FL, a mechanism is included for tracking the reputation of each trainer based on their performance. Trainers with low reputations may be excluded from the process, ensuring that only high-performing trainers contribute to the model. This helps to protect the consistency of the scheme by weeding out low-performing trainers.
Integrity: In References [
7,
27], there is a lack of mention regarding integrity in FL, which can render the scheme vulnerable to attackers attempting to steal the model and perform modifications. In contrast, MAM-FL provides two methods to preserve integrity. First, to verify the signature of the encrypted model, Equation (
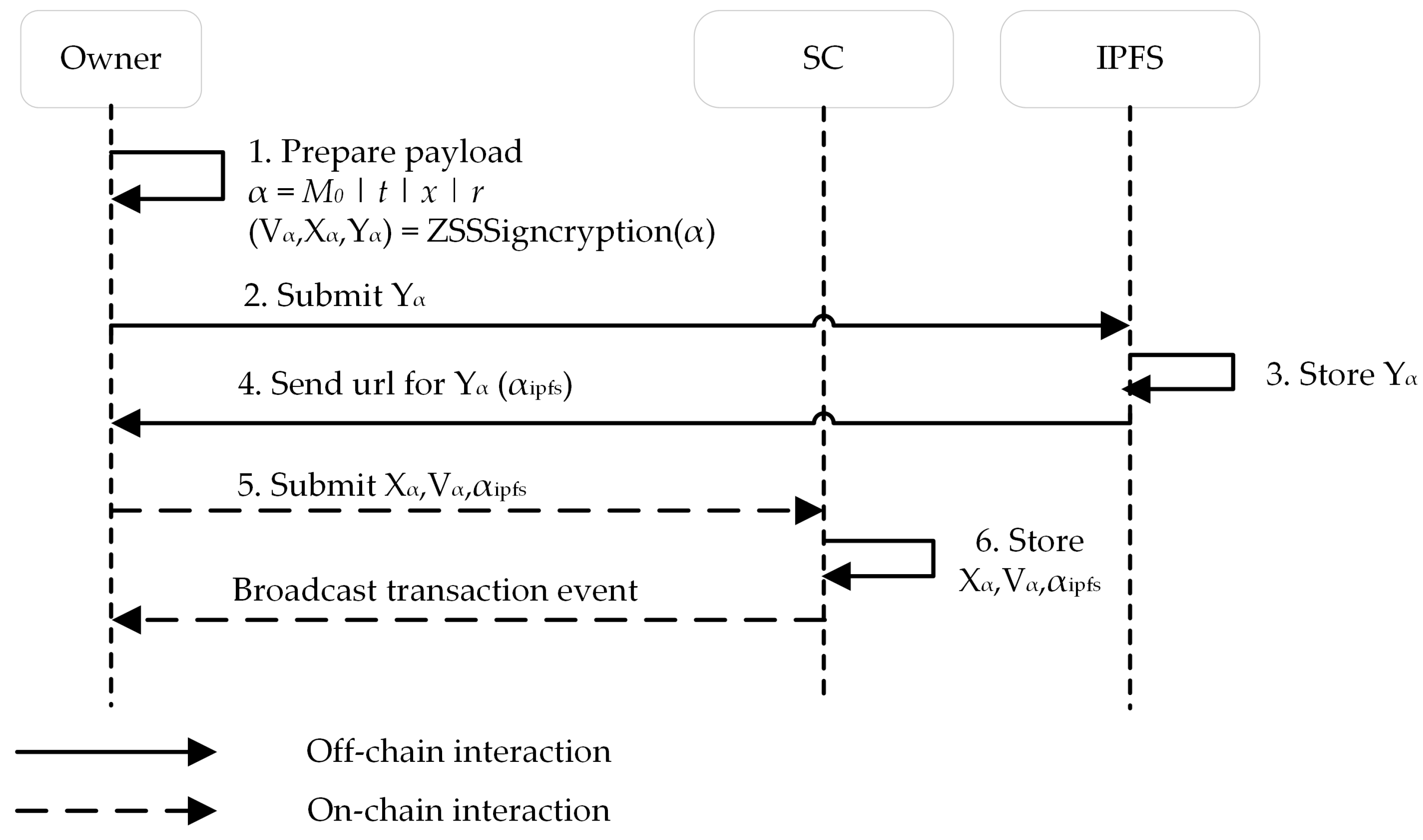
1) requires a hash to be constructed, which will generate a different value if the model has been modified. Second, throughout the process, hashes of the model updates are verified to ensure the integrity of the model updates. The hashes are stored in the blockchain, while the model updates are stored in IPFS, which are then compared to guarantee that the contents are not modified. The added verification prevents data breaches since in the scenario of the stolen model, the contents can be compared to determine if the model is still genuine or not, preserving integrity.
Authentication: In References [
7,
27], the importance of authentication in FL is not mentioned. This introduces a vulnerability, where a malicious party could sabotage the aggregator by distributing fake versions of the model. The validity of the model cannot be determined. To solve such a problem, the MAM-FL uses signcryption to verify the legitimacy of the model, confirming whether the model is sent by the real owner or not.
6. Conclusions and Future Works
This research paper examines the requirements for establishing trust in a federated learning scheme, and identifies seven crucial factors, i.e., confidentiality, attractiveness, accountability, reliability, consistency, integrity, and authentication. The paper proposes MAM-FL, an FL scheme to address the requirements. First, the protocol integrates signcryption to encrypt the initial model to ensure the model’s confidentiality, integrity, and origin authentication. Then, to enhance attractiveness, trainers and voters are guaranteed rewards based on their performance. Next, model updates are ranked and scored based on voter reputation, to address the accountability and consistency in the model updates. Lastly, the FL scheme is integrated with blockchain and IPFS to address single-point-of-failure, providing reliability.
To evaluate the effectiveness of the proposed protocol, experiments were conducted to reduce the number of malicious actors and incentivize honest contributions through a reputation-based reward system. The results demonstrate that the proposed protocol successfully mitigates the impact of malicious actors by using voter credibility to determine their trustworthiness, and the reputation-aware reward system is an attractive incentive for participants. The protocol was also tested in a scenario where malicious participants started with higher initial reputations; it still effectively reduced the number of malicious participants with subsequent iterations.
Future research can focus on measuring the response time of a blockchain-integrated FL scheme with a voting mechanism to determine its scalability. Additionally, since the paper defines that voters vote on all trainers, it can be useful to develop a worker selection algorithm to determine the assignment pairings of trainers and voters.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}