
End-to-End Mispronunciation Detection and Diagnosis Using Transfer Learning




Abstract
1. Introduction
- (1)
- We explore the use of the pretrained model wav2vec2.0 for MDD tasks, especially under different configurations for low resource MDD;
- (2)
- We propose an effective text–audio gate control module to effectively leverage the linguistic information from text modality. It can enforce the model to align textual information to the most related acoustic regions while ignoring irrelevant parts automatically;
- (3)
- To further unleash the power of prior text, we refine the loss to bridge the learning objective gap between phoneme recognition and MDD by explicitly discriminating the probability of reference and annotation sequences. Conducting experiments on the L2-Arctic dataset confirm the effectiveness of our proposals.
2. Related Work
2.1. Technical Basis
2.2. Previous Methods for MDD
3. Methodology
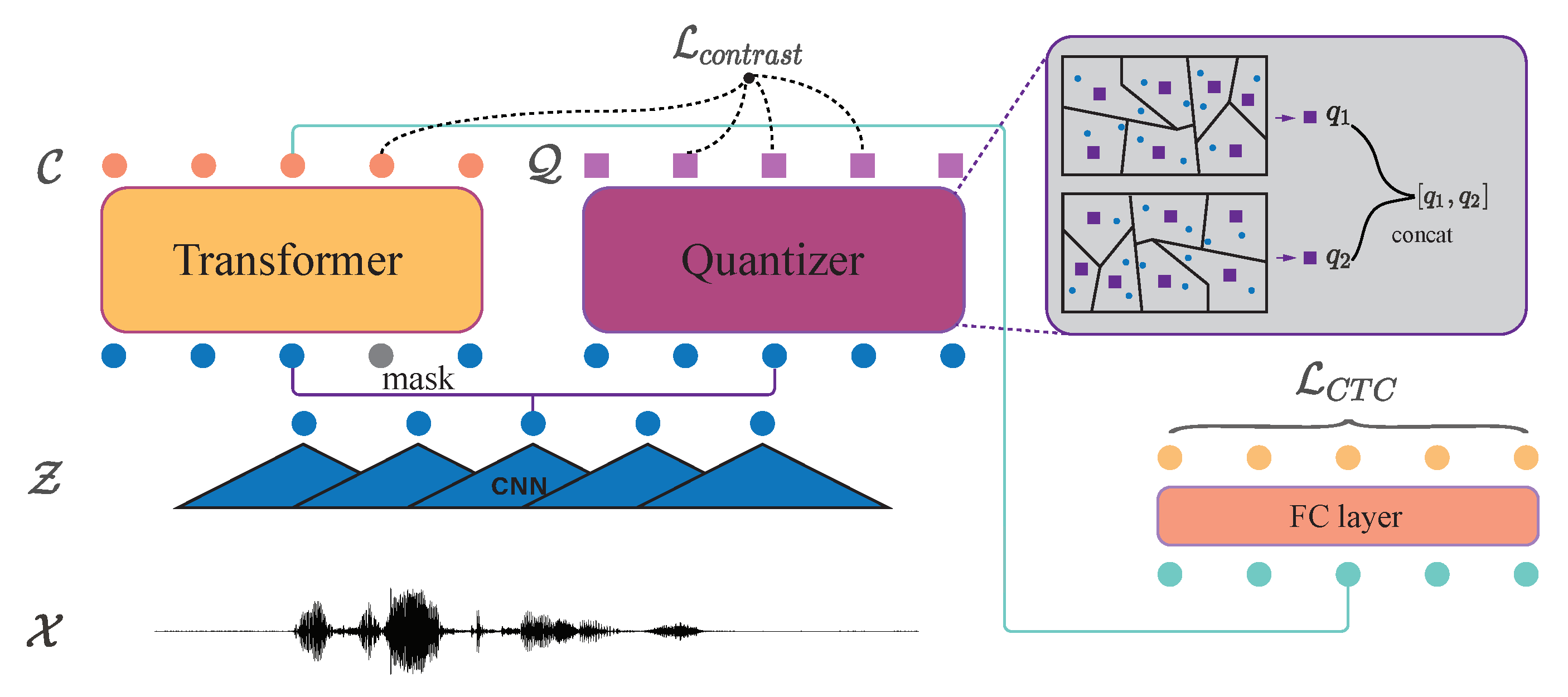
3.1. Fine-Tuning Wav2vec2.0 for MDD
3.2. Enhanced MDD by Textual Information
3.2.1. The Framework of Enhanced MDD
3.2.2. Textual Modulation Gate
3.3. Contrastive Learning
4. Experiments and Results
4.1. Speech Corpora
4.2. Experimental Setup
4.2.1. Examination of Pretrained Model and Data Configuration
- Default For this configuration, we merely use the training data from the L2-arctic corpus. The way of data partition for training and testing is consistent with [19] where the data of six speakers (NJS, TLV, TNI, TXHC, YKWK, ZHAA) are held as the test subset while the rest data of other 18 speakers are merged to build the training subset. Moreover, a development set is created by by randomly selecting 20% sentences from each speaker of the training subset. There is no overlap between the training and developing set.
- −33% This configuration is designed to explore the feasibility of the pretrained model for ultra-low resource MDD. To this end, we reduce 33% of training data for each language by randomly excluding six speakers from the Default training set.
- −66% Similar to the −33% configuration, we further reduce 33% of training data for each language by randomly excluding another six speakers from the −33% training set. In this case, only one speaker is kept for each of the six languages of non-native speakers.
- +TIMIT This configuration is to explore the effectiveness of incorporating the native English data. Here, the original training subset of TIMIT corpus is merged into the Default training set.
4.2.2. Examination of Textual Modulation Gate
4.3. Performance Evaluation
4.4. Experimental Results
4.4.1. Comparison with Different Amounts and Types of Training Data
4.4.2. Comparison with Conventional Methods
4.4.3. Using Textual Modulation Gate and Contrastive Learning
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Witt, S.M.; Young, S.J. Phone-level pronunciation scoring and assessment for interactive language learning. Speech Commun. 2000, 30, 95–108. [Google Scholar] [CrossRef]
- Hu, W.; Qian, Y.; Soong, F.K. A new DNN-based high quality pronunciation evaluation for computer-aided language learning (CALL). In Proceedings of the Interspeech, Lyon, France, 25–29 August 2013; pp. 1886–1890. [Google Scholar]
- Zheng, J.; Huang, C.; Chu, M.; Soong, F.K.; Ye, W.P. Generalized segment posterior probability for automatic Mandarin pronunciation evaluation. In Proceedings of the 2007 IEEE International Conference on Acoustics, Speech and Signal Processing—ICASSP’07, Honolulu, HI, USA, 15–20 April 2007; Volume 4, pp. 201–204. [Google Scholar]
- Harrison, A.M.; Lo, W.K.; Qian, X.j.; Meng, H. Implementation of an extended recognition network for mispronunciation detection and diagnosis in computer-assisted pronunciation training. In Proceedings of the International Workshop on Speech and Language Technology in Education, Warwickshire, UK, 3–5 September 2009. [Google Scholar]
- Graves, A.; Fernández, S.; Gomez, F.; Schmidhuber, J. Connectionist temporal classification: Labelling unsegmented sequence data with recurrent neural networks. In Proceedings of the 23rd International Conference on Machine Learning, Pittsburgh, PA, USA, 25–29 June 2006; pp. 369–376. [Google Scholar]
- Leung, W.K.; Liu, X.; Meng, H. CNN-RNN-CTC based end-to-end mispronunciation detection and diagnosis. In Proceedings of the ICASSP 2019—2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 8132–8136. [Google Scholar]
- Yan, B.C.; Wu, M.C.; Hung, H.T.; Chen, B. An End-to-End Mispronunciation Detection System for L2 English Speech Leveraging Novel Anti-Phone Modeling. In Proceedings of the Interspeech 2020, Shanghai, China, 25–29 October 2020; pp. 3032–3036. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Radford, A.; Narasimhan, K.; Salimans, T.; Sutskever, I. Improving Language Understanding by Generative Pre-Training. 2018. Available online: https://www.cs.ubc.ca/~amuham01/LING530/papers/radford2018impring.pdf (accessed on 5 April 2023).
- Erhan, D.; Courville, A.; Bengio, Y.; Vincent, P. Why does unsupervised pre-training help deep learning? In Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics JMLR Workshop and Conference Proceedings, Sardinia, Italy, 13–15 May 2010; pp. 201–208. [Google Scholar]
- Doersch, C.; Zisserman, A. Multi-task self-supervised visual learning. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2051–2060. [Google Scholar]
- Baevski, A.; Zhou, Y.; Mohamed, A.; Auli, M. wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations. Adv. Neural Inf. Process. Syst. 2020, 33, 12449–12460. [Google Scholar]
- Wu, M.; Li, K.; Leung, W.K.; Meng, H. Transformer Based End-to-End Mispronunciation Detection and Diagnosis. In Proceedings of the Interspeech, Brno, Czech Republic, 27 May–1 April 2021; pp. 3954–3958. [Google Scholar]
- Zhang, Z.; Wang, Y.; Yang, J. End-to-end Mispronunciation Detection with Simulated Error Distance. In Proceedings of the Interspeech 2022, Incheon, Republich of Korea, 18–22 September 2022; pp. 4327–4331. [Google Scholar]
- Chen, Q.; Lin, B.; Xie, Y. An Alignment Method Leveraging Articulatory Features for Mispronunciation Detection and Diagnosis in L2 English. In Proceedings of the Interspeech 2022, Incheon, Republich of Korea, 18–22 September 2022; pp. 4342–4346. [Google Scholar]
- Lin, B.; Wang, L. Phoneme Mispronunciation Detection By Jointly Learning To Align. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 22–25 May 2022; pp. 6822–6826. [Google Scholar]
- Baltrušaitis, T.; Ahuja, C.; Morency, L.P. Multimodal machine learning: A survey and taxonomy. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 41, 423–443. [Google Scholar] [CrossRef] [PubMed]
- Zheng, N.; Deng, L.; Huang, W.; Yeung, Y.T.; Xu, B.; Guo, Y.; Wang, Y.; Jiang, X.; Liu, Q. CCA-MDD: A Coupled Cross-Attention based Framework for Streaming Mispronunciation detection and diagnosis. arXiv 2021, arXiv:2111.08191. [Google Scholar]
- Feng, Y.; Fu, G.; Chen, Q.; Chen, K. SED-MDD: Towards sentence dependent end-to-end mispronunciation detection and diagnosis. In Proceedings of the ICASSP 2020—2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Virtual, 4–8 May 2020; pp. 3492–3496. [Google Scholar]
- Fu, K.; Lin, J.; Ke, D.; Xie, Y.; Zhang, J.; Lin, B. A Full Text-Dependent End to End Mispronunciation Detection and Diagnosis with Easy Data Augmentation Techniques. arXiv 2021, arXiv:2104.08428. [Google Scholar]
- Jiang, S.W.F.; Yan, B.C.; Lo, T.H.; Chao, F.A.; Chen, B. Towards Robust Mispronunciation Detection and Diagnosis for L2 English Learners with Accent-Modulating Methods. arXiv 2021, arXiv:2108.11627. [Google Scholar]
- Ye, W.; Mao, S.; Soong, F.; Wu, W.; Xia, Y.; Tien, J.; Wu, Z. An Approach to Mispronunciation Detection and Diagnosis with Acoustic, Phonetic and Linguistic (APL) Embeddings. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 22–27 May 2022; pp. 6827–6831. [Google Scholar]
- Zhang, D.; Ganesan, A.; Campbell, S.; Korzekwa, D. L2-GEN: A Neural Phoneme Paraphrasing Approach to L2 Speech Synthesis for Mispronunciation Diagnosis. In Proceedings of the Interspeech 2022, 23rd Annual Conference of the International Speech Communication Association, Incheon, Republic of Korea, 18–22 September 2022; Ko, H., Hansen, J.H.L., Eds.; ISCA: Lyon, France, 2022; pp. 4317–4321. [Google Scholar]
- Zhang, L.; Zhao, Z.; Ma, C.; Shan, L.; Sun, H.; Jiang, L.; Deng, S.; Gao, C. End-to-end automatic pronunciation error detection based on improved hybrid ctc/attention architecture. Sensors 2020, 20, 1809. [Google Scholar] [CrossRef]
- Zhang, Z.; Wang, Y.; Yang, J. Text-conditioned transformer for automatic pronunciation error detection. Speech Commun. 2021, 130, 55–63. [Google Scholar] [CrossRef]
- Korzekwa, D.; Lorenzo-Trueba, J.; Drugman, T.; Calamaro, S.; Kostek, B. Weakly-supervised word-level pronunciation error detection in non-native English speech. arXiv 2021, arXiv:2106.03494. [Google Scholar]
- West, J.; Ventura, D.; Warnick, S. Spring Research Presentation: A Theoretical Foundation for Inductive Transfer; Brigham Young University, College of Physical and Mathematical Sciences: Provo, UT, USA, 2007; Volume 1. [Google Scholar]
- Lin, Y.P.; Jung, T.P. Improving EEG-based emotion classification using conditional transfer learning. Front. Hum. Neurosci. 2017, 11, 334. [Google Scholar] [CrossRef] [PubMed]
- Ben-David, S.; Blitzer, J.; Crammer, K.; Kulesza, A.; Pereira, F.; Vaughan, J.W. A theory of learning from different domains. Mach. Learn. 2010, 79, 151–175. [Google Scholar] [CrossRef]
- Redko, I.; Morvant, E.; Habrard, A.; Sebban, M.; Bennani, Y. Advances in Domain Adaptation Theory; Elsevier: Amsterdam, The Netherlands, 2019. [Google Scholar]
- Ramachandram, D.; Taylor, G.W. Deep multimodal learning: A survey on recent advances and trends. IEEE Signal Process. Mag. 2017, 34, 96–108. [Google Scholar] [CrossRef]
- Chung, Y.A.; Hsu, W.N.; Tang, H.; Glass, J.R. An Unsupervised Autoregressive Model for Speech Representation Learning. In Proceedings of the INTERSPEECH, Graz, Austria, 15–19 September 2019; pp. 146–150. [Google Scholar]
- Schneider, S.; Baevski, A.; Collobert, R.; Auli, M. wav2vec: Unsupervised Pre-Training for Speech Recognition. In Proceedings of the INTERSPEECH, Graz, Austria, 15–19 September 2019; pp. 3465–3469. [Google Scholar]
- Yi, C.; Wang, J.; Cheng, N.; Zhou, S.; Xu, B. Applying wav2vec2. 0 to Speech Recognition in various low-resource languages. arXiv 2020, arXiv:2012.12121. [Google Scholar]
- Sharma, M. Multi-lingual multi-task speech emotion recognition using wav2vec 2.0. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 4–10 June 2022; pp. 6907–6911. [Google Scholar]
- Van den Oord, A.; Vinyals, O.; Kavukcuoglu, K. Neural Discrete Representation Learning. In Proceedings of the NIPS, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Oord, A.v.d.; Li, Y.; Vinyals, O. Representation learning with contrastive predictive coding. arXiv 2018, arXiv:1807.03748x. [Google Scholar]
- Hsu, W.N.; Bolte, B.; Tsai, Y.H.H.; Lakhotia, K.; Salakhutdinov, R.; Mohamed, A. Hubert: Self-supervised speech representation learning by masked prediction of hidden units. IEEE/ACM Trans. Audio Speech Lang. Process. 2021, 29, 3451–3460. [Google Scholar] [CrossRef]
- Peng, L.; Fu, K.; Lin, B.; Ke, D.; Zhang, J. A Study on Fine-Tuning wav2vec2. 0 Model for the Task of Mispronunciation Detection and Diagnosis. In Proceedings of the Interspeech, Brno, Czech Republic, 27 May–1 April 2021; pp. 4448–4452. [Google Scholar]
- Jaiswal, A.; Babu, A.R.; Zadeh, M.Z.; Banerjee, D.; Makedon, F. A survey on contrastive self-supervised learning. Technologies 2020, 9, 2. [Google Scholar] [CrossRef]
- Le-Khac, P.H.; Healy, G.; Smeaton, A.F. Contrastive representation learning: A framework and review. IEEE Access 2020, 8, 193907–193934. [Google Scholar] [CrossRef]
- Wickstrøm, K.; Kampffmeyer, M.; Mikalsen, K.Ø.; Jenssen, R. Mixing up contrastive learning: Self-supervised representation learning for time series. Pattern Recognit. Lett. 2022, 155, 54–61. [Google Scholar] [CrossRef]
- Lin, N.; Fu, S.; Lin, X.; Jiang, S.; Yang, A. A Chinese Spelling Check Framework Based on Reverse Contrastive Learning. arXiv 2022, arXiv:2210.13823. [Google Scholar]
- Zhao, G.; Sonsaat, S.; Silpachai, A.O.; Lucic, I.; Chukharev-Hudilainen, E.; Levis, J.; Gutierrez-Osuna, R. L2-ARCTIC: A non-native English speech corpus. In Proceedings of the Interspeech, Hyderabad, India, 2–6 September 2018; pp. 2783–2787. [Google Scholar]
- Garofolo, J.S.; Lamel, L.F.; Fisher, W.M.; Fiscus, J.G.; Pallett, D.S. DARPA TIMIT Acoustic-Phonetic Continous Speech Corpus CD-ROM. NIST Speech Disc 1-1.1; NASA STI/Recon Technical Report n; NIST Publications: Washington, DC, USA, 1993; Volume 93, p. 27403. [Google Scholar]
- SoX. Audio Manipulation Tool. Available online: http://sox.sourceforge.net/ (accessed on 15 March 2021).
- Lee, K.F.; Hon, H.W. Speaker-independent phone recognition using hidden Markov models. IEEE Trans. Acoust. Speech Signal Process. 1989, 37, 1641–1648. [Google Scholar] [CrossRef]
- Ott, M.; Edunov, S.; Baevski, A.; Fan, A.; Gross, S.; Ng, N.; Grangier, D.; Auli, M. fairseq: A Fast, Extensible Toolkit for Sequence Modeling. In Proceedings of the NAACL-HLT (Demonstrations), Minneapolis, MN, USA, 2–7 June 2019. [Google Scholar]
- Panayotov, V.; Chen, G.; Povey, D.; Khudanpur, S. Librispeech: An asr corpus based on public domain audio books. In Proceedings of the 2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), South Brisbane, Australia, 19–24 April 2015; pp. 5206–5210. [Google Scholar]
- Li, K.; Qian, X.; Meng, H. Mispronunciation detection and diagnosis in l2 english speech using multidistribution deep neural networks. IEEE/ACM Trans. Audio Speech Lang. Process. 2016, 25, 193–207. [Google Scholar] [CrossRef]
- Chang, C.B.; Mishler, A. Evidence for language transfer leading to a perceptual advantage for non-native listeners. J. Acoust. Soc. Am. 2012, 132, 2700–2710. [Google Scholar] [CrossRef] [PubMed]
- Duan, R.; Kawahara, T.; Dantsuji, M.; Nanjo, H. Cross-lingual transfer learning of non-native acoustic modeling for pronunciation error detection and diagnosis. IEEE/ACM Trans. Audio Speech Lang. Process. 2019, 28, 391–401. [Google Scholar] [CrossRef]
- Yan, B.C.; Chen, B. End-to-End Mispronunciation Detection and Diagnosis From Raw Waveforms. arXiv 2021, arXiv:2103.03023. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Train | Dev | Test | |
|---|---|---|---|
| Default | 2.50 | 0.28 | 0.88 |
| −33% | 1.49 | 0.37 | 0.88 |
| −66% | 0.73 | 0.19 | 0.88 |
| +TIMIT | 6.07 | 0.28 | 0.88 |
| Models | Data | Correct Pronunciations | Mispronunciations | F1 | |||
|---|---|---|---|---|---|---|---|
| True Accept | False Rejection | False Accept | True Rejection | ||||
| Corroct Diag. | Diag. Error | ||||||
| wav2vec2.0-BASE | - | 94.12% | 5.88% | 49.53% | 65.86% | 34.14% | 54.28% |
| wav2vec2-LV60 | - | 94.01% | 5.99% | 43.37% | 68.08% | 31.91% | 58.75% |
| wav2vec2-XLSR | - | 94.57% | 5.43% | 43.95% | 65.75% | 34.25% | 59.37% |
| wav2vec2-XLSR | −33% | 94.11% | 5.89% | 41.23% | 69.13% | 30.87% | 59.27% |
| wav2vec2-XLSR | −66% | 93.35% | 6.65% | 46.06% | 64.67% | 35.33% | 55.52% |
| wav2vec2.0-XLSR | +TIMIT | 94.30% | 5.70% | 41.80% | 70.72% | 29.28% | 60.44% |
| Models | Precision (%) | Recall (%) | F1 (%) |
|---|---|---|---|
| GOP [53] | 35.42 | 52.88 | 42.42 |
| CTC-ATT [7] | 46.57 | 70.28 | 56.02 |
| CNN-RNN-CTC+VC [20] | 56.04 | 56.12 | 56.08 |
| XLSR | 63.12 | 56.05 | 59.37 |
| XLSR(+TIMIT) | 62.86 | 58.20 | 60.44 |
| Models | Correct Pronunciations | Mispronunciations | F1 | |||
|---|---|---|---|---|---|---|
| True Accept | False Rejection | False Accept | True Rejection | |||
| Corroct Diag. | Diag. Error | |||||
| BaselineConventional | 92.65% | 7.35% | 43.88% | 74.96% | 25.04% | 56.08% |
| BaselineConcatenate | 93.68% | 6.31% | 42.87% | 68.52% | 31.48% | 58.87% |
| BaselineAdd | 94.15% | 5.85% | 45.36% | 63.21% | 36.79% | 57.51% |
| DoubleGate | 94.59% | 5.41% | 44.00% | 68.68% | 31.32% | 59.34% |
| TextGate | 94.50% | 5.50% | 42.52% | 68.26% | 31.74% | 60.27% |
| TextGate | 94.29% | 5.71% | 41.89% | 69.86% | 30.14% | 60.34% |
| TextGate | 94.53% | 5.47% | 46.33% | 64.22% | 35.78% | 57.48% |
| TextGate R * | 95.07% | 4.93% | 47.66% | 63.62% | 36.38% | 57.47% |
| TextGateXLSR | 94.94% | 5.06% | 43.72% | 68.79% | 31.21% | 60.23% |
| TextGateContrast | 93.72% | 6.28% | 40.43% | 69.77% | 30.23% | 60.32% |
| TextGateXLSRContrast | 93.81% | 6.19% | 38.62% | 71.08% | 28.92% | 61.75% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Peng, L.; Gao, Y.; Bao, R.; Li, Y.; Zhang, J. End-to-End Mispronunciation Detection and Diagnosis Using Transfer Learning. Appl. Sci. 2023, 13, 6793. https://doi.org/10.3390/app13116793
Peng L, Gao Y, Bao R, Li Y, Zhang J. End-to-End Mispronunciation Detection and Diagnosis Using Transfer Learning. Applied Sciences. 2023; 13(11):6793. https://doi.org/10.3390/app13116793
Chicago/Turabian StylePeng, Linkai, Yingming Gao, Rian Bao, Ya Li, and Jinsong Zhang. 2023. "End-to-End Mispronunciation Detection and Diagnosis Using Transfer Learning" Applied Sciences 13, no. 11: 6793. https://doi.org/10.3390/app13116793
APA StylePeng, L., Gao, Y., Bao, R., Li, Y., & Zhang, J. (2023). End-to-End Mispronunciation Detection and Diagnosis Using Transfer Learning. Applied Sciences, 13(11), 6793. https://doi.org/10.3390/app13116793