
A Malware Detection and Extraction Method for the Related Information Using the ViT Attention Mechanism on Android Operating System




Abstract
:1. Introduction
- The proposed method effectively integrates the two goals of accuracy and interpretability in malware detection. It can detect malicious Android apps accurately while providing valuable insights into the underlying patterns and behaviors associated with the identified threats. The combination of detection accuracy and interpretability has broadened the scope of malware detection research and paved the way for the development of more reliable and trustworthy AI-based cybersecurity solutions.
- A method for extracting features related to malicious behavior is presented. We show that the proposed method can provide class and method names that are useful in static analysis and that the provided class and method names can help to understand the malware’s behavior and patterns.
- A simple structure and methodology for interpretation are proposed. The interpretation method is more straightforward than in other studies. An image heatmap is used to find out why the application is detected as malicious. This is an easy way to convert applications into images, providing detection and interpretability.
2. Related Work
2.1. Malware Detection
2.2. Malware Detection Interpretation
3. Background
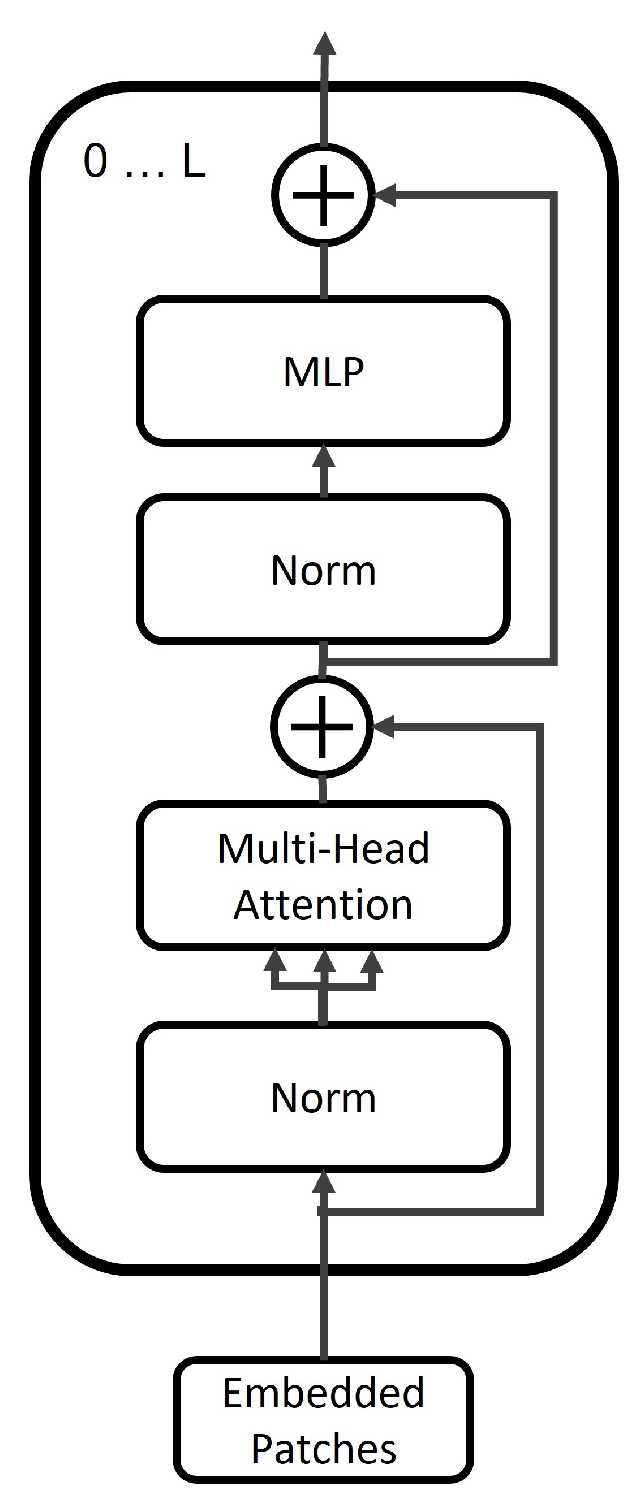
3.1. Vision Transformer
3.2. Android DEX File
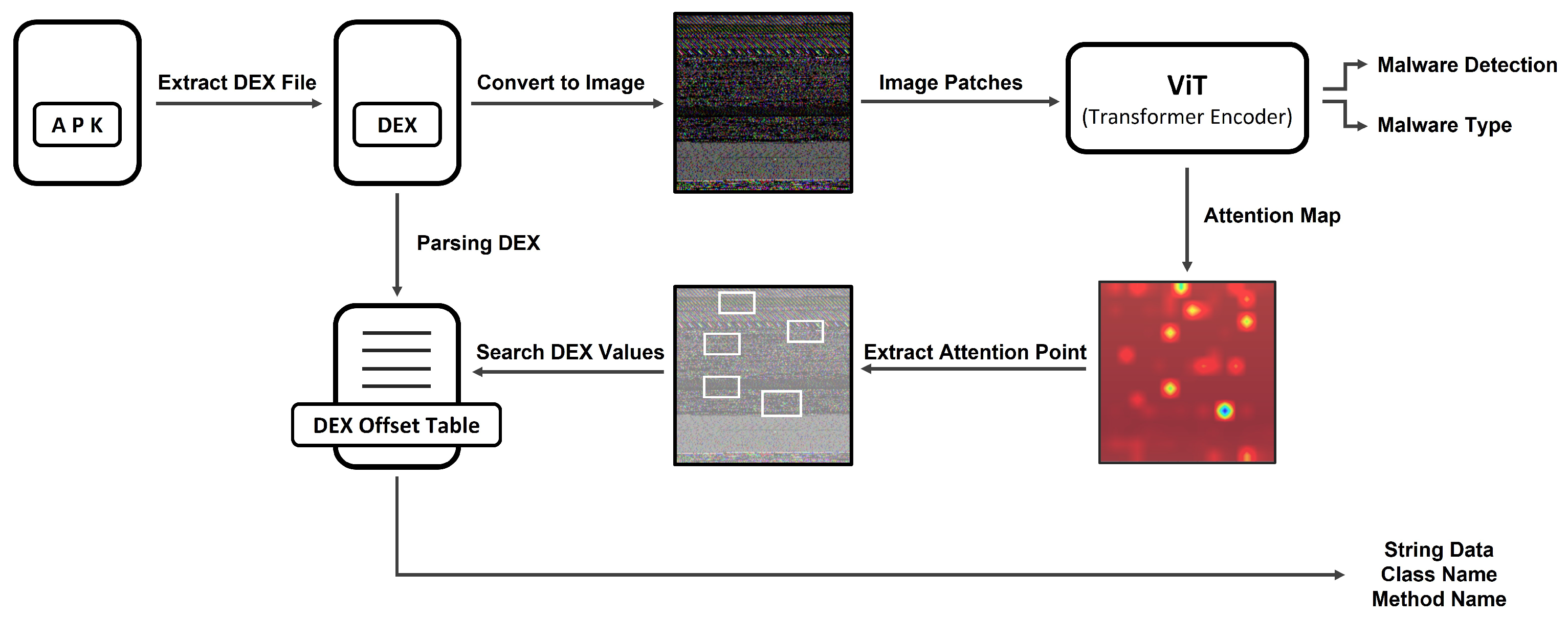
4. The Proposed Method
4.1. Overview
| Algorithm 1 Proposed overall progress Algorithm. |
| Input:
APK
Output: Detection Result, List of Class and Method Name 1: 2: 3: 4: 5: attention_map,attention_points=getAttentionMap(Vit,dex_rgb_image) 6: for do 7: 8: end for 9: class_method_names_list=extractInformation(dex_mm_list,dex_offset_index_table) 10: return prediction, class_method_names_list |
4.2. Conversion into Image
4.3. Malware Detection Model
4.4. Extraction Malicious Function Identifiers
4.4.1. DEX Parsing
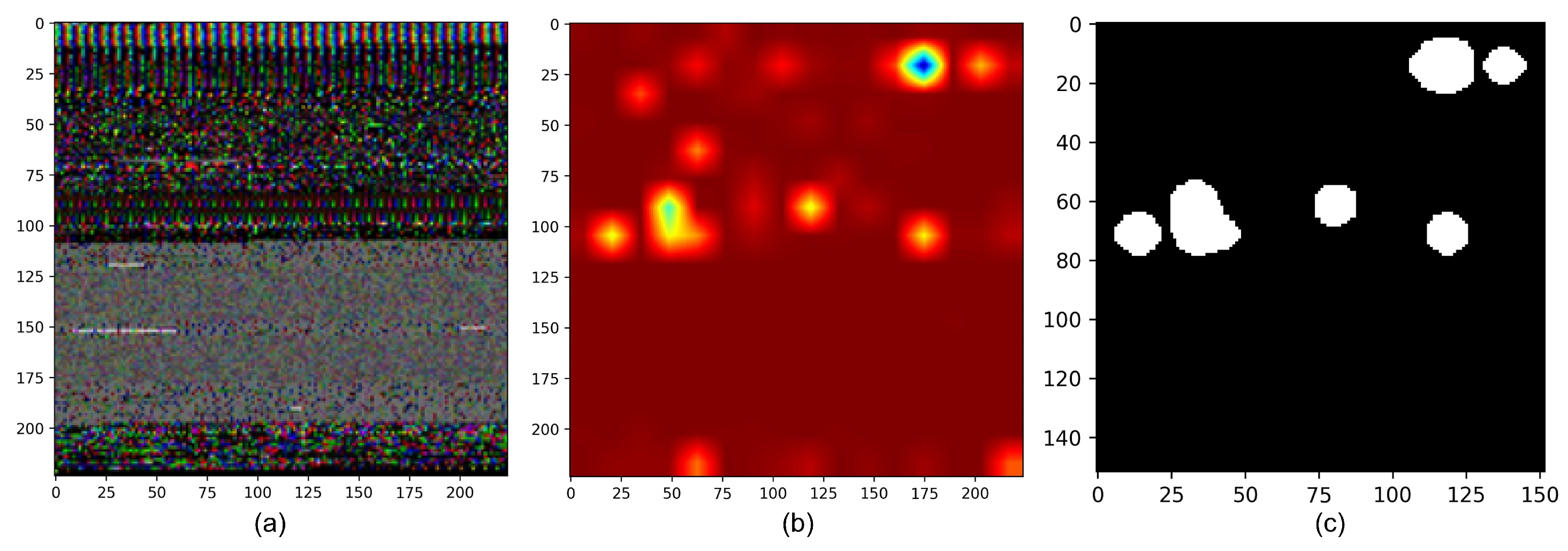
4.4.2. Attention Map
4.4.3. Extraction Function Identifiers
| Algorithm 2 Coordinate Conversion Algorithm. |
| Input:
(x, y) ▹ Attention Point Coordinate
Output: List with DEX Offset 1: function ConvertToDexOffsets(x,y) 2: 3: 4: 5: 6: 7: 8: 9: return 10: end function |
5. Experiment
5.1. Experimental Setup
5.2. Dataset
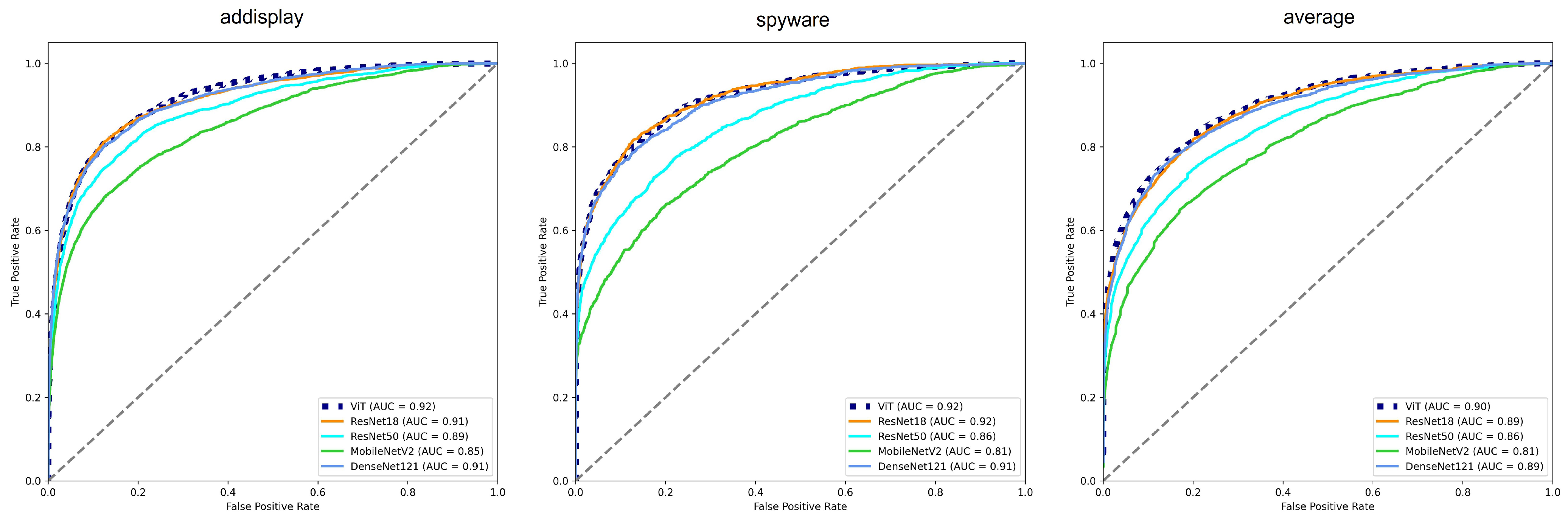
5.3. Malware Detection Model Performance Validation

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Macro Average | Weighted Average |
|---|---|
5.4. Accuracy of Malware Detection
5.5. Experiment with the Interpretation Process
Comparison with Malware Detection Interpretation Methods
5.6. Example of Extraction Information
SMS Malware—trojan.fakeinst/smsagent
6. Discussion
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Šembera, V.; Paquet-Clouston, M.; Garcia, S.; Erquiaga, M.J. Cybercrime specialization: An exposé of a malicious Android Obfuscation-as-a-Service. In Proceedings of the 2021 IEEE European Symposium on Security and Privacy Workshops (EuroS&PW), Vienna, Austria, 6–10 September 2021; pp. 213–226. [Google Scholar]
- Liu, K.; Xu, S.; Xu, G.; Zhang, M.; Sun, D.; Liu, H. A review of android malware detection approaches based on machine learning. IEEE Access 2020, 8, 124579–124607. [Google Scholar] [CrossRef]
- Liu, Y.; Tantithamthavorn, C.; Li, L.; Liu, Y. Deep learning for android malware defenses: A systematic literature review. ACM Comput. Surv. 2022, 55, 1–36. [Google Scholar] [CrossRef]
- Freitas, S.; Duggal, R.; Chau, D.H. MalNet: A Large-Scale Image Database of Malicious Software. In Proceedings of the 31st ACM International Conference on Information & Knowledge Management, Atlanta, GA, USA, 17–21 October 2022; pp. 3948–3952. [Google Scholar]
- Gerlings, J.; Shollo, A.; Constantiou, I. Reviewing the need for explainable artificial intelligence (xAI). arXiv 2020, arXiv:2012.01007. [Google Scholar]
- Perarasi, T.; Vidhya, S.; Ramya, P. Malicious vehicles identifying and trust management algorithm for enhance the security in 5G-VANET. In Proceedings of the 2020 Second International Conference on Inventive Research in Computing Applications (ICIRCA), Coimbatore, India, 15–17 July 2020; pp. 269–275. [Google Scholar]
- Iadarola, G.; Martinelli, F.; Mercaldo, F.; Santone, A. Towards an interpretable deep learning model for mobile malware detection and family identification. Comput. Secur. 2021, 105, 102198. [Google Scholar] [CrossRef]
- Kinkead, M.; Millar, S.; McLaughlin, N.; O’Kane, P. Towards explainable CNNs for Android malware detection. Procedia Comput. Sci. 2021, 184, 959–965. [Google Scholar] [CrossRef]
- Wu, B.; Chen, S.; Gao, C.; Fan, L.; Liu, Y.; Wen, W.; Lyu, M.R. Why an android app is classified as malware: Toward malware classification interpretation. ACM Trans. Softw. Eng. Methodol. TOSEM 2021, 30, 1–29. [Google Scholar] [CrossRef]
- Zhang, Z.; Hamadi, H.A.; Damiani, E.; Yeun, C.Y.; Taher, F. Explainable Artificial Intelligence Applications in Cyber Security: State-of-the-Art in Research. arXiv 2022, arXiv:2208.14937. [Google Scholar] [CrossRef]
- Liu, H.; Yin, Q.; Wang, W.Y. Towards explainable NLP: A generative explanation framework for text classification. arXiv 2018, arXiv:1811.00196. [Google Scholar]
- Alzahrani, N.; Alghazzawi, D. A review on android ransomware detection using deep learning techniques. In Proceedings of the 11th International Conference on Management of Digital EcoSystems, Limassol, Cyprus, 12–14 November 2019; pp. 330–335. [Google Scholar]
- Zhang, Y.; Yang, Y.; Wang, X. A novel android malware detection approach based on convolutional neural network. In Proceedings of the 2nd International Conference on Cryptography, Security and Privacy, Guiyang, China, 16–18 March 2018; pp. 144–149. [Google Scholar]
- Wang, W.; Zhao, M.; Wang, J. Effective android malware detection with a hybrid model based on deep autoencoder and convolutional neural network. J. Ambient. Intell. Humaniz. Comput. 2019, 10, 3035–3043. [Google Scholar] [CrossRef]
- Ren, Z.; Wu, H.; Ning, Q.; Hussain, I.; Chen, B. End-to-end malware detection for android IoT devices using deep learning. Ad Hoc Netw. 2020, 101, 102098. [Google Scholar] [CrossRef]
- Hsien-De Huang, T.; Kao, H.Y. R2-d2: Color-inspired convolutional neural network (cnn)-based android malware detections. In Proceedings of the 2018 IEEE International Conference on Big Data (Big Data), Seattle, DC, USA, 10–13 December 2018; pp. 2633–2642. [Google Scholar]
- Daoudi, N.; Samhi, J.; Kabore, A.K.; Allix, K.; Bissyandé, T.F.; Klein, J. Dexray: A simple, yet effective deep learning approach to android malware detection based on image representation of bytecode. In Proceedings of the Deployable Machine Learning for Security Defense: Second International Workshop, MLHat 2021, Virtual, 15 August 2021; Springer: Berlin/Heidelberg, Germany, 2021; pp. 81–106. [Google Scholar]
- Yadav, P.; Menon, N.; Ravi, V.; Vishvanathan, S.; Pham, T. EfficientNet convolutional neural networks-based Android malware detection. Elsevier Comput. Secur. 2022, 115, 102622. [Google Scholar]
- Yakura, H.; Shinozaki, S.; Nishimura, R.; Oyama, Y.; Sakuma, J. Malware analysis of imaged binary samples by convolutional neural network with attention mechanism. In Proceedings of the Eighth ACM Conference on Data and Application Security and Privacy, Tempe, AZ, USA, 19–21 March 2018; pp. 127–134. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Khan, S.; Naseer, M.; Hayat, M.; Zamir, S.W.; Khan, F.S.; Shah, M. Transformers in vision: A survey. ACM Comput. Surv. CSUR 2022, 54, 1–41. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 2017, 30. [Google Scholar]
- Zhao, H.; Jia, J.; Koltun, V. Exploring self-attention for image recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Abnar, S.; Zuidema, W. Quantifying attention flow in transformers. arXiv 2020, arXiv:2005.00928. [Google Scholar]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar]
- Zhou, B.; Khosla, A.; Lapedriza, A.; Oliva, A.; Torralba, A. Learning deep features for discriminative localization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NA, USA, 27–30 June 2016; pp. 2921–2929. [Google Scholar]
- Chefer, H.; Gur, S.; Wolf, L. Transformer interpretability beyond attention visualization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 19–25 June 2021; pp. 782–791. [Google Scholar]
- JADX. Available online: https://github.com/skylot/jadx (accessed on 7 January 2023).
- dex2jar. Available online: https://github.com/pxb1988/dex2jar (accessed on 7 January 2023).
- Apktool. Available online: https://ibotpeaches.github.io/Apktool/ (accessed on 7 January 2023).
- Almomani, I.; Alkhayer, A.; El-Shafai, W. An automated vision-based deep learning model for efficient detection of android malware attacks. IEEE Access 2022, 10, 2700–2720. [Google Scholar] [CrossRef]
- Wang, Q.; Li, B.; Xiao, T.; Zhu, J.; Li, C.; Wong, D.F.; Chao, L.S. Learning deep transformer models for machine translation. arXiv 2019, arXiv:1906.01787. [Google Scholar]
- Ba, J.L.; Kiros, J.R.; Hinton, G.E. Layer normalization. arXiv 2016, arXiv:1607.06450. [Google Scholar]
- Dalvik Executable Format. Available online: https://source.android.com/docs/core/runtime/dex-format (accessed on 14 December 2022).
- Arras, L.; Osman, A.; Samek, W. Ground truth evaluation of neural network explanations with clevr-xai. arXiv 2020, arXiv:2003.07258. [Google Scholar]
- Allix, K.; Bissyandé, T.F.; Klein, J.; Le Traon, Y. AndroZoo: Collecting Millions of Android Apps for the Research Community. In Proceedings of the 13th International Conference on Mining Software Repositories, Austin, TX, USA, 14–15 May 2016; ACM: New York, NY, USA, 2016; pp. 468–471. [Google Scholar]
- Hurier, M.; Suarez-Tangil, G.; Dash, S.K.; Bissyandé, T.F.; Traon, Y.L.; Klein, J.; Cavallaro, L. Euphony: Harmonious unification of cacophonous anti-virus vendor labels for Android malware. In Proceedings of the 14th International Conference on Mining Software Repositories, Buenos Aires, Argentina, 20–28 May 2017; pp. 425–435. [Google Scholar]
- Mahdavifar, S.; Kadir, A.F.A.; Fatemi, R.; Alhadidi, D.; Ghorbani, A.A. Dynamic android malware category classification using semi-supervised deep learning. In Proceedings of the 2020 IEEE Intlernational Conference on Dependable, Autonomic and Secure Computing, Intlernational Conference on Pervasive Intelligence and Computing, Intlernational Conference on Cloud and Big Data Computing, Intlernational Conference on Cyber Science and Technology Congress (DASC/PiCom/CBDCom/CyberSciTech), Calgary, AB, Canada, 17–22 August 2020; pp. 515–522. [Google Scholar]
- Mahdavifar, S.; Alhadidi, D.; Ghorbani, A.A. Effective and efficient hybrid android malware classification using pseudo-label stacked auto-encoder. J. Netw. Syst. Manag. 2022, 30, 1–34. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 4510–4520. [Google Scholar]
- Arp, D.; Spreitzenbarth, M.; Hubner, M.; Gascon, H.; Rieck, K.; Siemens, C. Drebin: Effective and explainable detection of android malware in your pocket. Ndss 2014, 14, 23–26. [Google Scholar]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. “Why should i trust you?”. Explaining the predictions of any classifier. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 1135–1144. [Google Scholar]
- Duan, Y.; Zhang, M.; Bhaskar, A.V.; Yin, H.; Pan, X.; Li, T.; Wang, X.; Wang, X. Things You May Not Know About Android (Un) Packers: A Systematic Study based on Whole-System Emulation. In Proceedings of the NDSS, San Diego, CA, USA, 18–21 February 2018. [Google Scholar]





| Dataset | Number of Samples | Number of Categories |
|---|---|---|
| AndroZoo | 1,046,190 | 37 |
| CICMalDroid2020 | 17,246 | 5 |
| Dataset | Category | Number of Samples |
|---|---|---|
| AndroZoo | adware | 771,299 |
| trojan | 163,671 | |
| riskware | 30,534 | |
| addisplay | 14,310 | |
| spr | 10,104 | |
| spyware | 7559 | |
| smssend | 7055 | |
| troj | 6139 | |
| exploit | 5395 | |
| clicker | 4412 | |
| CICMalDroid2020 | SMS | 4822 |
| Riskware | 4362 | |
| Benign | 4042 | |
| Banking | 2506 | |
| Adware | 1514 |
| Model | Layers | Hidden Size D | MLP Size | Heads | Patch Size |
|---|---|---|---|---|---|
| our proposed model | 12 | 128 | 2048 | 8 | 14 |
| Model | Accuracy | F1 Score | Precision | Recall | F1 Score | Precision | Recall |
|---|---|---|---|---|---|---|---|
| Weighted Avg | Macro Avg | ||||||
| our proposed model | 0.8027 | 0.7743 | 0.7775 | 0.8027 | 0.3113 | 0.5219 | 0.2509 |
| ResNet18 | 0.8005 | 0.7737 | 0.7762 | 0.8005 | 0.2748 | 0.4800 | 0.2207 |
| ResNet50 | 0.7843 | 0.7514 | 0.7528 | 0.7843 | 0.2230 | 0.3767 | 0.1803 |
| DenseNet121 | 0.8047 | 0.7770 | 0.7764 | 0.8047 | 0.2397 | 0.3831 | 0.1983 |
| MobileNetV2 | 0.7701 | 0.7258 | 0.7333 | 0.7701 | 0.1776 | 0.3803 | 0.1381 |
| Model | Accuracy | F1 Score | Precision | Recall | F1 Score | Precision | Recall |
|---|---|---|---|---|---|---|---|
| Weighted Avg | Macro Avg | ||||||
| our proposed model | 0.8681 | 0.8701 | 0.8753 | 0.8681 | 0.8422 | 0.8386 | 0.8521 |
| CNN [7] | 0.8107 | 0.8093 | 0.8090 | 0.8107 | 0.7734 | 0.7809 | 0.7676 |
| ResNet18 | 0.8859 | 0.8859 | 0.8869 | 0.8859 | 0.8617 | 0.8658 | 0.8585 |
| ResNet50 | 0.8525 | 0.8534 | 0.8553 | 0.8236 | 0.8190 | 0.8157 | 0.8236 |
| DenseNet121 | 0.9072 | 0.9071 | 0.9071 | 0.9072 | 0.8866 | 0.8883 | 0.8852 |
| MobileNetV2 | 0.7944 | 0.7925 | 0.7913 | 0.7944 | 0.7423 | 0.7464 | 0.7392 |
| Work | Year | Model | Features | Explanation Method | Explanation Result |
|---|---|---|---|---|---|
| Iadarola et al. [7] | 2021 | CNN | DEX grayscale Image | Grad-CAM | cumulative heatmap image |
| Kinkead et al. [8] | 2021 | CNN | opcode sequence | LIME | Visualizing activations |
| Wu et al. [9] | 2021 | XMal | API calls and Permissions | customised attention mechanism | natural language descriptions |
| Our approach | - | ViT | DEX RGB Image | attention mechanism | String, Class/Method Name |
| No. | Concept |
|---|---|
| 1 | activate |
| 2 | the mobile device is booted up |
| 3 | access the Internet |
| 4 | download components |
| 5 | steal some info |
| 6 | send to remote server |
| Feature | Semantic |
|---|---|
| Ljava/net/URL; ->openConnection | Access the Internet |
| Landroid/telephony/TelephonyManager; -> getDeviceId | Collect device ID(IMEI) |
| Landroid/telephony/gsm/SmsManager; ->sendDataMessage | Send SMS message |
| Ljava/lang/Runtime; ->getRuntime | download components |
| android.permission.READ_SMS | Collect SMS |
| android.permission.RECEIVE_BOOT_COMPLETED | Activited by BOOT |
| Malware Family | Drebin | LIME | XMal | Our Approach |
|---|---|---|---|---|
| FakeInstaller | 0.25 | 0.25 | 0.35 | 0.37 |
| DroidKungFu | 0.44 | 0.50 | 0.66 | 0.83 |
| Plankton | 0.50 | 0.57 | 0.80 | 0.60 |
| Opfake | 0.44 | 0.85 | 0.88 | 0.40 |
| Ginmaster | 0.75 | 0.75 | 0.92 | 0.83 |
| BaseBridge | 0.20 | 0.73 | 0.89 | 0.88 |
| Iconosys | 0.44 | 0.85 | 0.85 | 0.86 |
| Kwin | 0.44 | 0.75 | 0.93 | 0.88 |
| FakeDoc | 0.50 | 0.57 | 0.66 | 0.56 |
| Geinimi | 0.40 | 0.60 | 0.75 | 0.82 |
| Average | 0.43 | 0.64 | 0.76 | 0.70 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jo, J.; Cho, J.; Moon, J. A Malware Detection and Extraction Method for the Related Information Using the ViT Attention Mechanism on Android Operating System. Appl. Sci. 2023, 13, 6839. https://doi.org/10.3390/app13116839
Jo J, Cho J, Moon J. A Malware Detection and Extraction Method for the Related Information Using the ViT Attention Mechanism on Android Operating System. Applied Sciences. 2023; 13(11):6839. https://doi.org/10.3390/app13116839
Chicago/Turabian StyleJo, Jeonggeun, Jaeik Cho, and Jongsub Moon. 2023. "A Malware Detection and Extraction Method for the Related Information Using the ViT Attention Mechanism on Android Operating System" Applied Sciences 13, no. 11: 6839. https://doi.org/10.3390/app13116839
APA StyleJo, J., Cho, J., & Moon, J. (2023). A Malware Detection and Extraction Method for the Related Information Using the ViT Attention Mechanism on Android Operating System. Applied Sciences, 13(11), 6839. https://doi.org/10.3390/app13116839