
Advances in Computer-Aided Medical Image Processing
Abstract
:Featured Application
Abstract
1. Introduction
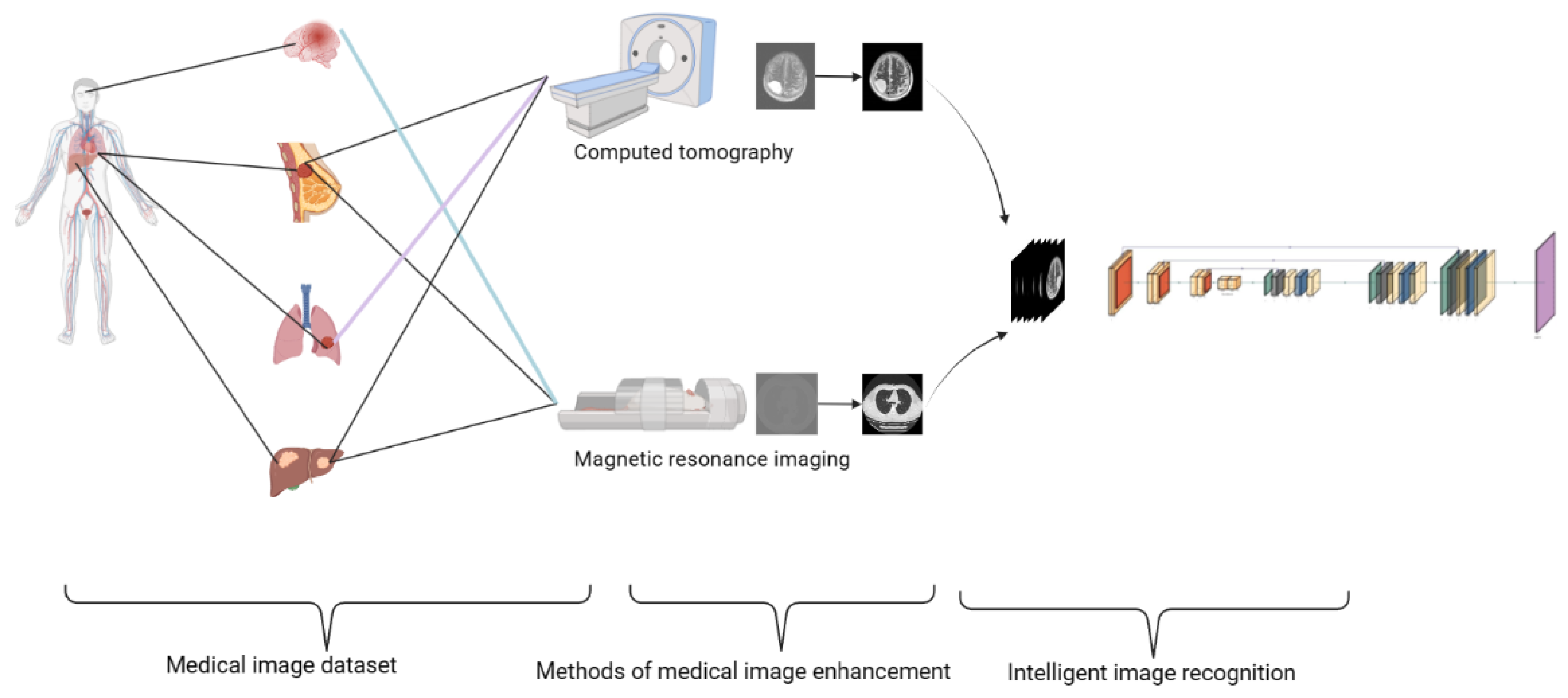
2. The Formation of Medical Images
2.1. Dataset
2.2. Defects in Medical Imaging
2.2.1. Defects of MRI
2.2.2. Defects of CT
3. Medical Image Processing
3.1. Direct Image Processing
3.1.1. Medical Image Enhancement Technology
3.1.2. Multimodal Medical Image Fusion
3.2. Intelligent Image Recognition
3.2.1. Image Processing Methods According to the Image Characteristics of Each Medical Part of the Body
3.2.2. Intelligent Algorithm for Medical Image Recognition after Image Enhancement
4. Neural Network Design for Medical Imaging
4.1. Reuse of Low-Level Features in Medical Images
4.1.1. U-Shaped Structure Reuse Low-Dimensional Edge Features
4.1.2. Dense Connection Reuse of Medical Image Low-Level Features
4.2. Utilization of Multilevel Information of Medical Images
4.2.1. 3D Convolution
4.2.2. Multimodal Feature Fusion
4.3. The Dimension of Medical Image Feature Extraction
5. Discussion
5.1. Challenge
- Data quality and availability: The limited availability of high-quality, labeled medical image datasets due to privacy concerns, data acquisition costs, and the need for expert annotations, as well as inconsistencies in medical images, pose significant challenges for training deep learning models.
- Model interpretability: The “black box” nature of AI-based medical image recognition models makes their inner workings difficult to understand, hindering their adoption in clinical practice as doctors may be reluctant to trust AI-generated diagnoses without clear explanations.
- Generalizability and robustness: Deep learning models’ sensitivity to variations in input data and their potential struggle to generalize to unseen data or new imaging modalities make it critical to ensure their robustness and generalizability in clinical settings.
- Computational resource requirements: The resource-intensive nature of training and deploying deep learning models, requiring powerful GPUs and high memory capacity, can be a barrier to the widespread adoption of AI in medical imaging, particularly in resource-limited settings.
5.2. Future Directions
- Improve data accessibility: Promote the sharing of medical image datasets, develop open-source data repositories, and leverage synthetic or augmented data and transfer learning techniques to overcome data-related challenges.
- Given the heterogeneity of medical imaging data across different institutions and modalities, data harmonization techniques need to be developed. These will help to standardize datasets, reducing technical variations and making aggregated data more reliable and useful. Implement machine learning algorithms, such as ComBat or DeepHarmony, to minimize batch effects and other sources of nonbiological variation in datasets acquired from different sources. Harmonization can help to standardize datasets, making aggregated data more reliable and useful.
- Enhance model interpretability: Explore the use of explainable AI techniques, such as layer-wise relevance propagation (LRP), SHAP (SHapley Additive exPlanations), or attention mechanisms, which can make the model’s decision-making process more transparent. Additionally, techniques such as feature visualization and saliency maps can be utilized to identify key input features responsible for predictions, thereby building trust with clinicians.
- Foster generalizability and robustness: Employ data augmentation, domain adaptation, adversarial training, and novel model architectures to enhance the generalizability and robustness of AI-based medical image recognition methods.
- Optimize computational efficiency: Explore lightweight models, pruning techniques, and distributed training approaches to reduce the computational resource requirements of AI-based medical image recognition methods.
- Active learning techniques: Utilize active learning strategies to identify the most informative samples for manual annotation, addressing the limitations of annotated data.
- Clinical integration and interpretability: Work closely with clinical teams to understand their workflows and needs. Focus on developing models that not only have high predictive performance but also provide interpretable outputs. For instance, developing a model that can output a heatmap showing areas of concern in an image, alongside its predictions, could make it more useful to clinicians.
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Yu, K.H.; Beam, A.L.; Kohane, I.S. Artificial intelligence in healthcare. Nat. Biomed. Eng. 2018, 2, 719–731. [Google Scholar] [CrossRef] [PubMed]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Litjens, G.; Kooi, T.; Bejnordi, B.E.; Setio, A.A.A.; Ciompi, F.; Ghafoorian, M.; van der Laak, J.A.W.M.; van Ginneken, B.; Sánchez, C.I. A survey on deep learning in medical image analysis. Med. Image Anal. 2017, 42, 60–88. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Topol, E.J. High-performance medicine: The convergence of human and artificial intelligence. Nat. Med. 2019, 25, 44–56. [Google Scholar] [CrossRef]
- Harmon, S.A.; Sanford, T.H.; Xu, S.; Turkbey, E.B.; Roth, H.; Xu, Z.; Yang, D.; Myronenko, A.; Anderson, V.; Amalou, A.; et al. Artificial intelligence for the detection of COVID-19 pneumonia on chest CT using multinational datasets. Nat. Commun. 2020, 11, 4080. [Google Scholar] [CrossRef]
- Fang, Y.; Zhang, H.; Xie, J.; Lin, M.; Ying, L.; Pang, P.; Ji, W. Sensitivity of Chest CT for COVID-19: Comparison to RT-PCR. Radiology 2020, 296, E115–E117. [Google Scholar] [CrossRef]
- Yazdani, A.; Fekri-Ershad, S.; Jelvay, S. Diagnosis of COVID-19 Disease in Chest CT-Scan Images Based on Combination of Low-Level Texture Analysis and MobileNetV2 Features. Comput. Intell. Neurosci. 2022, 2022, 1658615. [Google Scholar] [CrossRef]
- Fekri-Ershad, S.; Alsaffar, M.F. Developing a Tuned Three-Layer Perceptron Fed with Trained Deep Convolutional Neural Networks for Cervical Cancer Diagnosis. Diagnostics 2023, 13, 686. [Google Scholar] [CrossRef]
- Fekri-Ershad, S.; Ramakrishnan, S. Cervical cancer diagnosis based on modified uniform local ternary patterns and feed forward multilayer network optimized by genetic algorithm. Comput. Biol. Med. 2022, 144, 105392. [Google Scholar] [CrossRef]
- AlEisa, H.N.; Touiti, W.; Ali ALHussan, A.; Ben Aoun, N.; Ejbali, R.; Zaied, M.; Saadia, A. Breast Cancer Classification Using FCN and Beta Wavelet Autoencoder. Comput. Intell. Neurosci. 2022, 2022, 8044887. [Google Scholar] [CrossRef]
- Rahman, H.; Naik Bukht, T.F.; Ahmad, R.; Almadhor, A.; Javed, A.R. Efficient Breast Cancer Diagnosis from Complex Mammographic Images Using Deep Convolutional Neural Network. Comput. Intell. Neurosci. 2023, 2023, 7717712. [Google Scholar] [CrossRef] [PubMed]
- Brody, H. Medical imaging. Nature 2013, 502, S81. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Owens, B. Scans: Enhanced medical vision. Nature 2013, 502, S82–S83. [Google Scholar] [CrossRef] [Green Version]
- Caro, M.C.; Huang, H.-Y.; Cerezo, M.; Sharma, K.; Sornborger, A.; Cincio, L.; Coles, P.J. Generalization in quantum machine learning from few training data. Nat. Commun. 2022, 13, 4919. [Google Scholar] [CrossRef] [PubMed]
- Li, Y.; Su, Y.; Guo, M.; Han, X.; Liu, J.; Vishwasrao, H.D.; Li, X.; Christensen, R.; Sengupta, T.; Moyle, M.W.; et al. Incorporating the image formation process into deep learning improves network performance. Nat. Methods 2022, 19, 1427–1437. [Google Scholar] [CrossRef] [PubMed]
- Available online: https://www.rms.org.uk/community/networks-affiliates/bioimaginguk-network.html (accessed on 1 June 2023).
- Grand Challenge. Available online: https://www.grand-challenge.org/ (accessed on 1 June 2023).
- Boss, A.; Stegger, L.; Bisdas, S.; Kolb, A.; Schwenzer, N.; Pfister, M.; Claussen, C.D.; Pichler, B.J.; Pfannenberg, C. Feasibility of simultaneous PET/MR imaging in the head and upper neck area. Eur. Radiol. 2011, 21, 1439–1446. [Google Scholar] [CrossRef] [Green Version]
- Kim, H.W.; Lee, H.E.; Oh, K.; Lee, S.; Yun, M.; Yoo, S.K. Multi-slice representational learning of convolutional neural network for Alzheimer’s disease classification using positron emission tomography. Biomed. Eng. Online 2020, 19, 1–15. [Google Scholar] [CrossRef] [PubMed]
- Kim, H.W.; Lee, H.E.; Lee, S.; Oh, K.T.; Yun, M.; Yoo, S.K. Slice-selective learning for Alzheimer’s disease classification using a generative adversarial network: A feasibility study of external validation. Eur. J. Nucl. Med. 2020, 47, 2197–2206. [Google Scholar] [CrossRef]
- Alzheimer’s Disease Neuroimaging Initiative (ADNI). Available online: http://adni.loni.usc.edu/ (accessed on 1 June 2023).
- Saba, T.; Mohamed, A.S.; El-Affendi, M.; Amin, J.; Sharif, M. Brain tumor detection using fusion of hand crafted and deep learning features. Cogn. Syst. Res. 2020, 59, 221–230. [Google Scholar] [CrossRef]
- Noori, M.; Bahri, A.; Mohammadi, K. Attention-guided version of 2D UNet for automatic brain tumor segmentation. In Proceedings of the 9th International Conference on Computer and Knowledge Engineering (ICCKE), Mashhad, Iran, 24–25 October 2019; pp. 269–275. [Google Scholar]
- Menze, B.H.; Jakab, A.; Bauer, S.; Kalpathy-Cramer, J.; Farahani, K.; Kirby, J.; Burren, Y.; Porz, N.; Slotboom, J.; Wiest, R.; et al. The Multimodal Brain Tumor Image Segmentation Benchmark (BRATS). IEEE Trans. Med. Imaging 2014, 34, 1993–2024. [Google Scholar] [CrossRef]
- Bakas, S.; Akbari, H.; Sotiras, A.; Bilello, M.; Rozycki, M.; Kirby, J.S.; Freymann, J.B.; Farahani, K.; Davatzikos, C. Advancing the Cancer Genome Atlas glioma MRI collections with expert segmentation labels and radiomic features. Sci. Data 2017, 4, 170117. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Henschel, L.; Kügler, D.; Reuter, M. FastSurferVINN: Building resolution-independence into deep learning segmentation methods—A solution for HighRes brain MRI. Neuroimage 2022, 251, 118933. [Google Scholar] [CrossRef] [PubMed]
- Pareek, K.; Tiwari, P.K.; Bhatnagar, V. State of the art and prediction model for brain tumor detection. In Smart Systems: Innovations in Computing; Somani, A.K., Mundra, A., Doss, R., Bhattacharya, S., Eds.; Springer: Singapore, 2022; pp. 557–563. [Google Scholar]
- University of South Florida Digital Mammography Home Page. Available online: http://www.eng.usf.edu/cvprg/Mammography/Database.html (accessed on 1 June 2023).
- The Cancer Genome Atlas (TCGA) Research Network. Comprehensive molecular portraits of human breast tumours. Nature 2012, 490, 61–70. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Spanhol, F.A.; Oliveira, L.S.; Petitjean, C.; Heutte, L. A Dataset for Breast Cancer Histopathological Image Classification. IEEE Trans. Biomed. Eng. 2015, 63, 1455–1462. [Google Scholar] [CrossRef] [PubMed]
- Han, X.; Qi, L.; Yu, Q.; Zhou, Z.; Zheng, Y.; Shi, Y.; Gao, Y. Deep Symmetric Adaptation Network for Cross-Modality Medical Image Segmentation. IEEE Trans. Med. Imaging 2021, 41, 121–132. [Google Scholar] [CrossRef]
- Gao, X.W.; Hui, R.; Tian, Z. Classification of CT brain images based on deep learning networks. Comput. Methods Programs Biomed. 2017, 138, 49–56. [Google Scholar] [CrossRef] [Green Version]
- Wan, Z.; Dong, Y.; Yu, Z.; Lv, H.; Lv, Z. Semi-Supervised Support Vector Machine for Digital Twins Based Brain Image Fusion. Front. Neurosci. 2021, 15, 705323. [Google Scholar] [CrossRef]
- Yuan, Y. Automatic head and neck tumor segmentation in PET/CT with scale attention network. In Head and Neck Tumor Segmentation; Andrearczyk, V., Oreiller, V., Depeursinge, A., Eds.; Springer International Publishing: Cham, Switzerland, 2021; pp. 44–52. [Google Scholar]
- Andrearczyk, V.; Oreiller, V.; Boughdad, S.; Le Rest, C.C.; Elhalawani, H.; Jreige, M.; Prior, J.O.; Vallières, M.; Visvikis, D.; Hatt, M.; et al. Overview of the HECKTOR Challenge at MICCAI 2021: Automatic Head and Neck Tumor Segmentation and Outcome Prediction in PET/CT Images. In Head and Neck Tumor Segmentation and Outcome Prediction: Second Challenge, HECKTOR 2021, Strasbourg, France, 27 September 2021; Springer: Cham, Switzerland, 2021; pp. 1–37. [Google Scholar] [CrossRef]
- Srivastava, A.; Kulkarni, C.; Huang, K.; Parwani, A.; Mallick, P.; Machiraju, R. Imitating Pathologist Based Assessment with Interpretable and Context Based Neural Network Modeling of Histology Images. Biomed. Inform. Insights 2018, 10, 1–7. [Google Scholar] [CrossRef] [Green Version]
- Khan, S.; Islam, N.; Jan, Z.; Din, I.U.; Rodrigues, J.J.P.C. A novel deep learning based framework for the detection and classification of breast cancer using transfer learning. Pattern Recognit. Lett. 2019, 125, 1–6. [Google Scholar] [CrossRef]
- Seo, H.; Huang, C.; Bassenne, M.; Xiao, R.; Xing, L. Modified U-Net (mU-Net) with Incorporation of Object-Dependent High Level Features for Improved Liver and Liver-Tumor Segmentation in CT Images. IEEE Trans. Med. Imaging 2019, 39, 1316–1325. [Google Scholar] [CrossRef] [Green Version]
- Li, X.; Chen, H.; Qi, X.; Dou, Q.; Fu, C.-W.; Heng, P.-A. H-DenseUNet: Hybrid Densely Connected UNet for Liver and Tumor Segmentation from CT Volumes. IEEE Trans. Med. Imaging 2018, 37, 2663–2674. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Dou, Q.; Yu, L.; Chen, H.; Jin, Y.; Yang, X.; Qin, J.; Heng, P.-A. 3D deeply supervised network for automated segmentation of volumetric medical images. Med. Image Anal. 2017, 41, 40–54. [Google Scholar] [CrossRef] [PubMed]
- Soler, L.; Hostettler, A.; Agnus, V.; Charnoz, A.; Fasquel, J.B.; Moreau, J.; Osswald, A.B.; Bouhadjar, M.; Marescaux, J. 3D Image Reconstruction for Comparison of Algorithm Database: A Patient Specific Anatomical and Medical Image Database; Tech. Rep 1.1; IRCAD: Strasbourg, France, 2010. [Google Scholar]
- Fu, X.; Bi, L.; Kumar, A.; Fulham, M.; Kim, J. Multimodal Spatial Attention Module for Targeting Multimodal PET-CT Lung Tumor Segmentation. IEEE J. Biomed. Health Inform. 2021, 25, 3507–3516. [Google Scholar] [CrossRef]
- Available online: https://luna16.grand-challenge.org/ (accessed on 1 June 2023).
- Vallières, M.; Freeman, C.R.; Skamene, S.R.; El Naqa, I. A radiomics model from joint FDG-PET and MRI texture features for the prediction of lung metastases in soft-tissue sarcomas of the extremities. Phys. Med. Biol. 2015, 60, 5471–5496. [Google Scholar] [CrossRef] [PubMed]
- Zhao, X.; Li, L.; Lu, W.; Tan, S. Tumor co-segmentation in PET/CT using multi-modality fully convolutional neural network. Phys. Med. Biol. 2018, 64, 015011. [Google Scholar] [CrossRef]
- Zhou, T.; Lu, H.; Yang, Z.; Qiu, S.; Huo, B.; Dong, Y. The ensemble deep learning model for novel COVID-19 on CT images. Appl. Soft Comput. 2021, 98, 106885. [Google Scholar] [CrossRef]
- Pehrson, L.M.; Nielsen, M.B.; Lauridsen, C.A. Automatic Pulmonary Nodule Detection Applying Deep Learning or Machine Learning Algorithms to the LIDC-IDRI Database: A Systematic Review. Diagnostics 2019, 9, 29. [Google Scholar] [CrossRef] [Green Version]
- Available online: https://wiki.cancerimagingarchive.net/display/Public/TCGA-LUAD (accessed on 1 June 2023).
- Hutter, C.; Zenklusen, J.C. The Cancer Genome Atlas: Creating Lasting Value beyond Its Data. Cell 2018, 173, 283–285. [Google Scholar] [CrossRef]
- Available online: https://www.cancerimagingarchive.net/ (accessed on 1 June 2023).
- Available online: https://cdas.cancer.gov/datasets/nlst/ (accessed on 1 June 2023).
- Available online: https://wiki.cancerimagingarchive.net/display/Public/SPIEAAPM+Lung+CT+Challenge#534f52ab0e4d4bd8b2e7ef16d2b2bd0d (accessed on 1 June 2023).
- Wald, L.L.; McDaniel, P.C.; Witzel, T.; Stockmann, J.P.; Cooley, C.Z. Low-cost and portable MRI. J. Magn. Reson. Imaging 2019, 52, 686–696. [Google Scholar] [CrossRef]
- Lustig, M.; Donoho, D.L.; Santos, J.M.; Pauly, J.M. Compressed Sensing MRI. IEEE Signal Process. Mag. 2008, 25, 72–82. [Google Scholar] [CrossRef]
- Lu, H.; Nagae-Poetscher, L.M.; Golay, X.; Lin, D.; Pomper, M.; van Zijl, P.C. Routine clinical brain MRI sequences for use at 3.0 Tesla. J. Magn. Reson. Imaging 2005, 22, 13–22. [Google Scholar] [CrossRef] [PubMed]
- De González, A.B.; Mahesh, M.; Kim, K.-P.; Bhargavan, M.; Lewis, R.; Mettler, F.; Land, C. Projected Cancer Risks From Computed Tomographic Scans Performed in the United States in 2007. Arch. Intern. Med. 2009, 169, 2071–2077. [Google Scholar] [CrossRef] [Green Version]
- Smith-Bindman, R.; Lipson, J.; Marcus, R.; Kim, K.F.; Mahesh, M.; Gould, R.; de González, A.B.; Miglioretti, D.L. Radiation Dose Associated with Common Computed Tomography Examinations and the Associated Lifetime Attributable Risk of Cancer. Arch. Intern. Med. 2009, 169, 2078–2086. [Google Scholar] [CrossRef] [PubMed]
- Miglioretti, D.L.; Johnson, E.; Williams, A.; Greenlee, R.T.; Weinmann, S.; Solberg, L.I.; Feigelson, H.S.; Roblin, D.; Flynn, M.J.; Vanneman, N.; et al. The Use of Computed Tomography in Pediatrics and the Associated Radiation Exposure and Estimated Cancer Risk. JAMA Pediatr. 2013, 167, 700–707. [Google Scholar] [CrossRef] [PubMed]
- Pearce, M.S.; Salotti, J.A.; Little, M.P.; McHugh, K.; Lee, C.; Kim, K.P.; Howe, N.L.; Ronckers, C.M.; Rajaraman, P.; Craft, A.W., Sr.; et al. Radiation exposure from CT scans in childhood and subsequent risk of leukaemia and brain tumours: A retrospective cohort study. Lancet 2012, 380, 499–505. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- National Lung Screening Trial Research Team; Aberle, D.R.; Adams, A.M.; Berg, C.D.; Black, W.C.; Clapp, J.D.; Fagerstrom, R.M.; Gareen, I.F.; Gatsonis, C.; Marcus, P.M.; et al. Reduced Lung-Cancer Mortality with Low-Dose Computed Tomographic Screening. N. Engl. J. Med. 2011, 365, 395–409. [Google Scholar] [CrossRef] [Green Version]
- Liu, X.; Primak, A.N.; Krier, J.D.; Yu, L.; Lerman, L.O.; McCollough, C.H. Renal Perfusion and Hemodynamics: Accurate in Vivo Determination at CT with a 10-Fold Decrease in Radiation Dose and HYPR Noise Reduction. Radiology 2009, 253, 98–105. [Google Scholar] [CrossRef] [Green Version]
- Mansoor, A.; Cerrolaza, J.J.; Idrees, R.; Biggs, E.; Alsharid, M.A.; Avery, R.A.; Linguraru, M.G. Deep Learning Guided Partitioned Shape Model for Anterior Visual Pathway Segmentation. IEEE Trans. Med. Imaging 2016, 35, 1856–1865. [Google Scholar] [CrossRef]
- Garduño, E.; Herman, G.T.; Davidi, R. Reconstruction from a few projections by ℓ1-minimization of the Haar transform. Inverse Probl. 2011, 27, 055006. [Google Scholar] [CrossRef] [Green Version]
- Wang, X.B. Image enhancement based on lifting wavelet transform. In Proceedings of the 2009 4th International Conference on Computer Science & Education, Nanning, China, 25–28 July 2009; pp. 739–741. [Google Scholar]
- Starck, J.-L.; Candes, E.J.; Donoho, D.L. The curvelet transform for image denoising. IEEE Trans. Image Process. 2002, 11, 670–684. [Google Scholar] [CrossRef] [Green Version]
- Baâzaoui, A.; Barhoumi, W.; Ahmed, A.; Zagrouba, E. Semi-Automated Segmentation of Single and Multiple Tumors in Liver CT Images Using Entropy-Based Fuzzy Region Growing. IRBM 2017, 38, 98–108. [Google Scholar] [CrossRef]
- Lin, P.-L.; Huang, P.-W.; Lee, C.-H.; Wu, M.-T. Automatic classification for solitary pulmonary nodule in CT image by fractal analysis based on fractional Brownian motion model. Pattern Recognit. 2013, 46, 3279–3287. [Google Scholar] [CrossRef]
- Kanavati, F.; Toyokawa, G.; Momosaki, S.; Rambeau, M.; Kozuma, Y.; Shoji, F.; Yamazaki, K.; Takeo, S.; Iizuka, O.; Tsuneki, M.; et al. Weakly-supervised learning for lung carcinoma classification using deep learning. Sci. Rep. 2020, 10, 9297. [Google Scholar] [CrossRef]
- Rehman, A.; Naz, S.; Razzak, M.I.; Akram, F.; Imran, M. A Deep Learning-Based Framework for Automatic Brain Tumors Classification Using Transfer Learning. Circuits Syst. Signal Process. 2020, 39, 757–775. [Google Scholar] [CrossRef]
- Polat, Ö.; Güngen, C. Classification of brain tumors from MR images using deep transfer learning. J. Supercomput. 2021, 77, 7236–7252. [Google Scholar] [CrossRef]
- Cheng, J.; Huang, W.; Cao, S.; Yang, R.; Yang, W.; Yun, Z.; Wang, Z.; Feng, Q. Enhanced Performance of Brain Tumor Classification via Tumor Region Augmentation and Partition. PLoS ONE 2015, 10, e0140381. [Google Scholar] [CrossRef]
- Zhang, F.; Song, Y.; Cai, W.; Zhou, Y.; Shan, S.; Feng, D. Context curves for classification of lung nodule images. In Proceedings of the International Conference on Digital Image Computing: Techniques and Applications (DICTA), Hobart, TAS, Australia, 26–28 November 2013; pp. 1–7. [Google Scholar]
- Zhang, J.; Jiang, Z.; Dong, J.; Hou, Y.; Liu, B. Attention gate resU-Net for automatic MRI brain tumor segmentation. IEEE Access 2020, 8, 58533–58545. [Google Scholar] [CrossRef]
- Lei, T.; Zhou, W.; Zhang, Y.; Wang, R.; Meng, H.; Nandi, A.K. Lightweight V-Net for liver segmentation. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 1379–1383. [Google Scholar]
- Xiao, X.; Zhao, W.; Zhao, J.; Xiao, N.; Yang, X.; Yang, X. Segmentation and detection of liver tumors in contrast-free MRI images combined with multimodal features. J. Taiyuan Univ. Technol. 2021, 52, 411–416. [Google Scholar]
- Lu, L.; Dercle, L.; Zhao, B.; Schwartz, L.H. Deep learning for the prediction of early on-treatment response in metastatic colorectal cancer from serial medical imaging. Nat. Commun. 2021, 12, 6654. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional networks for biomedical image segmentation. In MICCAI 2015: Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015; Navab, N., Hornegger, J., Wells, W.M., Frangi, A.F., Eds.; Springer International Publishing: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Huang, G.; Liu, Z.; Maaten, L.V.D.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2261–2269. [Google Scholar]
- Kim, D.W.; Jang, H.Y.; Kim, K.W.; Shin, Y.; Park, S.H. Design Characteristics of Studies Reporting the Performance of Artificial Intelligence Algorithms for Diagnostic Analysis of Medical Images: Results from Recently Published Papers. Korean J. Radiol. 2019, 20, 405–410. [Google Scholar] [CrossRef]
- Zhou, T.; Ruan, S.; Canu, S. A review: Deep learning for medical image segmentation using multi-modality fusion. Array 2019, 3–4, 100004. [Google Scholar] [CrossRef]
- Taha, A.A.; Hanbury, A. Metrics for evaluating 3D medical image segmentation: Analysis, selection, and tool. BMC Med. Imaging 2015, 15, 29. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hara, K.; Kataoka, H.; Satoh, Y. Can spatiotemporal 3D CNNs retrace the history of 2D CNNs and ImageNet? In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6546–6555. [Google Scholar]
- Hubel, D.H.; Wiesel, T.N. Receptive fields of single neurones in the cat’s striate cortex. J. Physiol. 1959, 148, 574–591. [Google Scholar] [CrossRef]
- Lecun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef] [Green Version]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef] [Green Version]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Loshchilov, I.; Hutter, F. Decoupled weight decay regularization. arXiv 2017, arXiv:1711.05101v3. [Google Scholar]
- Krogh, A.; Hertz, J. A simple weight decay can improve generalization. In Proceedings of the 4th International Conference on Neural Information Processing Systems, Denver, CO, USA, 2–5 December 1991; ACM: New York, NY, USA, 1991; pp. 950–957. [Google Scholar]
- Loshchilov, I.; Hutter, F. Fixing weight decay regularization in adam. arXiv 2018, arXiv:1711.05101v2. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- DeVries, T.; Taylor, G.W. Dataset augmentation in feature space. arXiv 2017, arXiv:1702.05538. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Tumor Site | Dataset Series Name | Dataset Composition |
|---|---|---|
| Brain | ADNI | 483 elderly controls, 551MCI and 437AD. 300 early MCI and 150 late MCI [19,20,21] |
| BRATS | 1251 training cases and 219 test cases [22,23,24,25] | |
| ABIDE | 1114 datasets, including 521 ASD and 593 controls [26] | |
| Kaggle | 247 images, including 155 tumorous and 92 nontumorous [27] | |
| Breast | DDSM | 538 positive samples and 2313 negative samples [28,29] |
| BreaKHis | 7909 images, including 2480 benign and 5429 images [30] | |
| Liver | ISBI 2019 | 20 volumes of T2-SPIR MRI [25,31] |
| Tumor Site | Dataset Series Name | Dataset Composition |
|---|---|---|
| Brain | 335 slices | 285 datasets, including 57 AD, 115 lesion, and 113 normal [32] |
| 20 groups of clinical data + digital twin | 20 groups of clinical data processed by registration, skull peeling, and contrast enhancement [33] | |
| HECKTOR 2020 | 201 training cases and 53 test cases [34,35] | |
| Breast | TUPAC 2016 | 500 training cases and 321 test cases [36] |
| TGGA | 1000 images, including details of AJCC stage, tumor subtypes, and relevant mutational status [29,36] | |
| Standard benchmark dataset | 6000 training cases and 2000 test cases [37] | |
| Liver | LiTS challenge 2017 | 22,500 images for training, 2550 images for validation, and 16,125 test images [38,39] |
| SLiver07 | 30 CT scans, including 20 training and 10 testing [40] | |
| 3DIRCADb | 20 CT scans with 15 liver tumors [39,41] | |
| Lung | NSCLC | 50 patients with 128-slice PET-CT [42] |
| LUNA | 888 CT images of 1084 tumors, with the help of experts, excluding tumors smaller than 3 mm [43] | |
| STSs | CT and MRI from 51 patients [42,44] | |
| Lung cancer patient dataset | 48 training cases and 36 test cases [45] | |
| COVID-19 dataset | 2500 high-quality images of COVID-19 [46] | |
| LIDC-IDRI | 1018 patients’ CT data and their marker information, [47] | |
| TCGA | 51 patients’ CT data [48,49] | |
| NIH Deeplesion dataset | over 32,000 annotated lesions identified on CT images, representing 4400 unique patients [50] | |
| NLST | More than 75,000 CT images and more than 1200 pathological images from NLST lung cancer patients [51] | |
| SPIE-AAPM | 70 patients who underwent CT and received diagnoses [52] |
| Tumor Types | Data Complement | Method | Result | |
|---|---|---|---|---|
| Brain tumor | 165 child subjects | Learning method based on local shape and sparse appearance [62] | DICE | 0.779 |
| Kaggle | Multilayer perceptron algorithm in the CNN [27] | ACCURACY | 86.63% | |
| BRATS 2017 | VGG-19 with hand-marked features [22] | DSC | 0.99 | |
| Figshare | DenseNet21 and Adadelta with transfer learning [70] | ACCURACY | 98.91% | |
| BRATS 2018 | U-Net with Squeeze-and-Excitation [23] | DICE | 0.823 | |
| HECKTOR2020 | U-Net with SA [73] | ACCURACY | 75.2 | |
| CT images of Naval General Hospital | fuse a 2D CNN with a 3D CNN | ACCURACY | 87.60% | |
| ABIDE | U-Net with VINN [26] | DSC | 1.46 | |
| HECKTOR 2020 | 3D FCN uses two independent V-Net [45] | ACCURACY | 89.10% | |
| Liver tumor | ImageCLEF | Entropy-based fuzzy region growth method [66] | DSM | 0.88 |
| MIDAS | Fuzzy C-means [53] | DSC | 0.81 | |
| MMWHS2017 challenge | UDA architecture with transfer learning [31] | ACCURACY | 78.50% | |
| Benchmark dataset | GoogLeNet with transfer learning [37] | ACCURACY | 97.53% | |
| LiTS | V-Net [74] | DICE | 0.954 | |
| SLiver07 | 3D CNN to directly guide the objective function [40] | VOE | 5.42 | |
| 3DIRCADb | H-DenseUNet [39] | ACCURACY | 93.70% | |
| MRI from McGil Health Center | U-Net extracted multiscale features of different modes [75] | ACCURACY | 81.98% | |
| Breast Tumor | TUPAC 2016 | CNN modelling method based on explainable context [36] | ACCURACY | 82% |
| BreaKHis | ResNet with Inception model [11] | ACCURACY | 82.60% | |
| BreaKHis | ResNet50 with transfer learning [64] | ACCURACY | 98% | |
| lung tumor | 107 different patients | Fractional Browne motion model [67] | ACCURACY | 88.82% |
| 952 patients | YOLO v3 with Google Inception v3 network [68] | ACCURACY-IMPROVE | 95.52% | |
| 2933 patients with COVID-19 | AlexNet with transfer learning [46] | ACCURACY | 99.05% | |
| STS | U-Net with multimode spatial attention module [42] | ACCURACY | 71.44% | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cui, H.; Hu, L.; Chi, L. Advances in Computer-Aided Medical Image Processing. Appl. Sci. 2023, 13, 7079. https://doi.org/10.3390/app13127079
Cui H, Hu L, Chi L. Advances in Computer-Aided Medical Image Processing. Applied Sciences. 2023; 13(12):7079. https://doi.org/10.3390/app13127079
Chicago/Turabian StyleCui, Hang, Liang Hu, and Ling Chi. 2023. "Advances in Computer-Aided Medical Image Processing" Applied Sciences 13, no. 12: 7079. https://doi.org/10.3390/app13127079