1. Introduction
Advances in networking and hardware technology have led to the rapid proliferation of the Internet of Things (IoTs) and decentralized applications. These advancements, including fog computing and edge computing technologies, enable data processing and analysis to be performed at node devices, avoiding the need for data aggregation. This naturally brings benefits such as efficiency and privacy, but on the other hand, it forces data analysis tasks to be carried out in a distributed manner. To this end, federated learning (FL) has emerged as a promising solution in this context, allowing multiple parties to collaboratively train models without sharing raw data. Instead, only intermediate results are exchanged with an aggregator server, ensuring privacy preservation and decentralized data analysis [
1].
With respect to machine learning tasks, research has shown that sensitive information can be leaked from the models [
2,
3,
4,
5]. For example, in [
3], Shokri et al. demonstrated membership inference attacks against machine learning tasks. In such an attack, an attacker can determine whether a data sample has been used in the model training. This will violate privacy if the data sample is sensitive. Regardless of its privacy friendly status, FL suffers similar privacy issues, as demonstrated by Nasr, Shokri and Houmansadr [
5]. This makes it necessary to incorporate additional privacy protection mechanisms into FL and to make it rigorously privacy-preserving.
To mitigate information leakages, FL can be aided with other privacy-enhancing technologies, such as secure aggregation (SA) [
6] and differential privacy (DP) [
7]. SA hides the individual contributions from the aggregator server in each intermediate step in a way that does not affect the trained model’s utility. In other words, the standalone updates are masked such that the masks cancel out during aggregation; therefore, the aggregated results remain intact. The masks could be seen as temporary noise; hence, the privacy protection does not extend to the aggregated data. In contrast, DP adds persistent noise to the model, i.e., it provides broader privacy protection but with an inevitable utility loss (due to the permanent noise). We differentiate between two DP settings depending on where the noise is injected. In local DP (LDP), the participants add noise to their updates, while in central DP (CDP), the server applies noise to the aggregate result. A comparison of LDP, CDP and SA is summarized in
Table 1. While there are many privacy protection mechanisms, incorporating them into FL is not a trivial task and remains as open challenges [
1].
Among many data analysis methods, this paper focuses on singular value decomposition (SVD). Plainly, SVD factorizes a matrix into three new matrices. Originating from linear algebra, SVD has several interesting properties and conveys crucial insights about the underlying matrix. Hence, SVD has essential applications in data science, such as in recommendation systems [
8,
9], principal component analysis [
10], latent semantic analysis [
11], noise filtering [
12,
13], dimension reduction [
14], clustering [
15], matrix completion [
16], etc. Existing federated SVD solutions fall into two categories: SVD over horizontally and vertically partitioned datasets [
17]. In real-world applications, the former is much more common [
18,
19]; therefore, in this paper, we choose the horizontal setting and focus on the privacy protection challenges.
1.1. Related Work
The concept of privacy-preserving federated SVD has been studied in several works, which are briefly summarized below.
In the literature, many anonymization techniques have been proposed to enable privacy protection in federated machine learning and other tasks. Ref. [
20] proposed substitute vectors and length-based frequent pattern tree (LFP-tree) to achieve the data anonymization. It focuses on what data can be published and how they can be published without associating subjects or identities. With the concept of data anonymization in mind, Ref. [
21] proposed a strategy by decreasing the correlation between data and the identities. However, the utility of the data will be affected. And, Ref. [
22] focused on high-dimensional dataset, which is divided into different subsets; then, each subset is generalized with a novel heuristic method based on local re-coding. While these works contain interesting techniques, they do not directly offer a solution for privacy-preserving federated SVD. A more detailed analysis can be found in [
1].
Technically speaking, the algorithms utilized to compute SVD are mostly iterative, such as the power iteration method [
23]. Recently, these algorithms were adopted to a distributed setting to solve large-scale problems [
24,
25]. While these works tackle important issues and advance the field, they all disregard privacy issues: we are only aware of two federated SVD solutions in the literature explicitly providing a privacy analysis [
18,
19]. Hartebrodt et al. [
19] proposed a federated SVD algorithm with a star-like architecture for high-dimensional data such that the aggregator cannot access the complete eigenvector matrix of SVD results. Instead, each node device has access, but only to its shared part of the eigenvector matrix. In addition to the lack of a rigorous privacy analysis, its aim is different from most other federated SVD solutions where the aim is to jointly compute a global feature space. In contrast, Guo et al. [
18] proposed a federated SVD algorithm based on the distributed power method, where both the server and all the participants learn the entire eigenvector matrix. Their solution incorporated additional privacy-preserving features, such as participant and aggregator server noise injection, but without a rigorous privacy analysis. We improve upon this solution by pointing out an error in its privacy analysis and by providing a tighter privacy protection with less utilized noise. Overall, these existing literature works do not provide a privacy-preserving federated SVD solution with a rigorous analysis in our setting.
1.2. Contribution and Organization
This work focuses on a setting similar to Guo et al. [
18], i.e., when the server and all the participants are expected to learn the final eigenvector matrix. As our main contribution, we improve the FedPower algorithm [
18] from two perspectives, i.e., both from the privacy and utility points of view. Our detailed contributions are summarized below.
Firstly, we point out several inefficiencies and shortcomings of FedPower, such as the avoidable double noise injection steps and the unclear and confusing privacy guarantee.
Secondly, we propose a utility enhanced solution, where the added noise is reduced due to the introduction of SA.
Thirdly, we propose a privacy enhanced solution, which (in contrast to FedPower) satisfies DP.
Finally, we empirically validate our proposed algorithms by measuring the privacy-utility trade-off using a real-world recommendation system use-case.
The rest of the paper is organized as follows. In
Section 2, we list the fundamental definitions of the relevant techniques used throughout the paper. In
Section 3, we recap the scheme proposed by Guo et al. [
18], while in
Section 4 and
Section 5, we propose two improved schemes focusing on utility and privacy, respectively. In
Section 6, we empirically compare the proposed schemes with the original work. Finally, in
Section 7, we conclude the paper.
4. Enhancing the Utility of FedPower
Adversary Model. Throughout this paper, we consider a semi-honest setup, i.e., where the clients and the server are honest but curious. This means that they follow the protocol truthfully, but in the meantime, they try to learn as much as possible about the dataset of other participants. We also assume that the server and the clients cannot collude, so the server cannot control node devices.
Utility Analysis of FedPower. It is not a surprise that adding Gaussian noise twice (i.e., the local and the central noise in Step 6 and 8 in Algorithm 1) severely affects the accuracy of the final result. A straightforward way to increase the utility is to eliminate some of this noise. As highlighted in
Table 1, the local noise protects the individual clients from the server. Moreover, it also protects the aggregate from other clients and from external attackers. On the other hand, the central noise merely covers the aggregate. Hence, if the protection level against the server is sufficient against other clients and external attackers, the central noise becomes obsolete.
Moreover, all the locally added noise accumulates during aggregation, which also negatively affects the utility of the final result. Loosely speaking, as shown in
Table 1, CDP combined with SA could provide the same protection as LDP. Consequently, by utilizing cryptographic techniques with a single local noise, we can hide the individual updates and protect the aggregate as well.
Utility Enhanced FedPower. We improve on FedPower [
18] from two aspects: (1) we apply an SA protocol to hide the individual intermediate results of the node devices from the server, and (2) we use a secure multi-party computation (SMPC) protocol to enforce the CDP in an oblivious manner to the server. In SMPC, multiple parties can jointly compute a function over their private inputs without revealing those inputs to each other or to the server. More details of this topic can be found in the book [
32]. We supplement the assumptions and the setup of Guo et al. [
18] with a homomorphic encryption key pair generated by the server. The server holds the private key and shares the public key with all node devices. The remaining part of our solution is shown in Algorithm 2. To ease understanding, the pseudo code is simplified. The actual implementation is more optimized, e.g., the encrypted results are aggregated before decryption in Step 11, and in Step 7, the ciphertexts are re-randomized rather than generated from scratch. We describe all these tricks in
Section 6.
By performing SA in Step 7, the server obtains the aggregated result with Gaussian noises from all node devices. With the simple SMPC procedure (Steps 8–12), the server receives all Gaussian noises apart from the one (i.e., node device
j) is randomly selected (which is hidden from the node devices). Then, in Step 13, it removes them from the output of the SA protocol. Compared with FedPower [
18], our intermediate aggregation result only contains a single instance of Gaussian noise from the randomly chosen node device instead of
n. Consequently, via SA and SMPC, the proposed utility-enhancing protocol reduced the locally added noise
n-fold and completely eliminated the central noise.
Computational Complexity. Regarding computational complexity, we compare the proposed scheme with the original solution in
Table 2. The major difference is that we have integrated SA to facilitate our new privacy protection strategy. Let
and
be the asymptotic computational complexities of SA on each node device and server side, respectively.
Although we have added more operations, as seen in
Table 2, we have distributed some computations to individual node devices. Most importantly, we no longer add secondary server-side Gaussian noise to the final aggregation result and only retain the Gaussian noise from one node device.
Analysis. As we mentioned in our adversarial model, the semi-honest server cannot collude with any of the node devices, which are also semi-honest. Thus, the server cannot eliminate the remaining noise from the final result. In terms of the node device, since no one except the server is aware of the random index in Step 8, apart from its data, a node device only knows the aggregation result with the added noise, even if the retained noise comes from itself.
| Algorithm 2 Utility-enhanced FedPower. |
- Input:
Datasets , target rank k, iteration rank r, number of iteration T, synchronous trigger p, the variance of noise , and key pair - Output:
Approximated eigenspace - 1:
initialise with orthonormal columns and generate an zero matrix and another all-ones matrix of the same size - 2:
for to T do - 3:
each node device i computes , where - 4:
if then - 5:
each node device i computes (orthogonal transformation) - 6:
each node device i adds Gaussian noise: - 7:
SA protocol is executed among the server and all node devices, with inputs and output - 8:
the server chooses one random index and encrypts and : and for - 9:
the server sends value and to the appropriate node devices - 10:
each node device i computes which is if and otherwise - 11:
each node device i sends back to the server - 12:
for all , the server decrypts the receiving messages to obtain - 13:
the server updates aggregation result as - 14:
the server performs orthogonalization - 15:
the server broadcasts to all node devices - 16:
each node device i sets - 17:
else - 18:
each node device i calculates the latest - 19:
end if - 20:
end for - 21:
return approximated eigenspace
|
Compared with the original solution by Guo et al. [
18], we have improved the utility of the aggregation result by keeping the added noise from one single node device. As a side effect, the complexity has grown due to the SA protocol. This is a trade-off between result accuracy and solution efficiency.
5. Differentially Private Federated SVD Solution
Privacy Analysis of FedPower. Algorithm 1 injects noise both at the local (Step 6) and the global (Step 8) levels. Consequently, the claimed privacy protection of Algorithm 1 is
-DP, which originates from
-LDP and
-CDP [
18]. Firstly, as we highlighted in
Table 1, LDP and CDP provide different privacy protections; hence, merely combining them is inappropriate, so the claim must be more precise. Instead, Algorithm 1 seems to provide
-DP for the clients from the server and stronger protection (due to the additional central noise) from other clients and external attackers.
Yet, this is still not entirely sound, as not all computations were included in the sensitivity calculation; hence, the noise scaling is incorrect. Indeed, the authors only considered the sensitivity of the multiplication with in Step 3 when determining the variance of the Gaussian noise in Step 6; however, the noise is only added after the multiplication with in Step 5. Thus, the sensitivity of the orthogonalization is discarded.
Privacy-Enhanced FedPower. We improve on FedPower [
18] from two aspects: (1) we incorporate clipping in the protocol to bound the sensitivity of the local operations performed by the clients and (2) we use SA with DP to obtain a strong privacy guarantee. For this reason, similar to FedPower [
18], we assume that for all
i the elements of
are bounded with
. In Algorithm 1, the computations the nodes undertake (besides noise injection at Step 6) are in Steps 3, 5 and 12, where the last two could be either discarded for the sensitivity computation or completely removed, as explained below.
Step 12: Orthogonalization is intricate, so its sensitivity is not necessarily traceable. To tackle this, we propose applying the noise before, in which case it would not affect the privacy guarantee, as it would count as post-processing.
Step 5: We remove this client-side operation from our privacy-enhanced solution, as it is not essential; only the convergence speed would be affected slightly.
The FedPower protocol with enhanced privacy is present in Algorithm 3, where besides the orthogonalization, clipping is also performed with . The only client operation which must be considered for the sensitivity computation (i.e., before noise injection) is Step 3. We calculate its sensitivity in Theorem 1.
Theorem 1. If we assume for all , then the sensitivity (calculated via the Euclidean distance) of the client-side operations (i.e., Step 3 in Algorithm 3 is bounded by .
Proof. To make the proof easier to follow, we remove the subscript round counter from the notation. Let us define
and
such that they are equal except at position
. Now, multiply these with
from the left results in
and
, respectively, which are the same except in row
i:
Hence, the Euclidean distance of
and
boils down to this row
i:
As a direct corollary of , we know that each of the r squared elements is bounded by . Therefore, . □
It is known that adding Gaussian noise with
(where
s is the sensitivity) results in
-DP. As a corollary, we can state in Theorem 2 that a single round in Algorithm 3 is differentially private. An even tighter result was presented in [
33]; we leave the exploration of this as future work. The best practice is to set
as the inverse of the size of the underlying dataset, so there is a direct connection between the variance
and the privacy parameter
.
Theorem 2. If , then Algorithm 3 provides -DP, where Proof. Can be verified by combining the provided formula with the appropriate sensitivity. □
| Algorithm 3 Privacy-enhanced FedPower. |
- Input:
Datasets , target rank k, iteration rank r, number of iteration T, the clipping bound , the variance of noise - Output:
Approximated eigenspace - 1:
initialise with orthonormal columns - 2:
for to T do - 3:
each node device i computes , where - 4:
each node device i adds Gaussian noise: - 5:
if then - 6:
SA protocol is executed among the server and all node devices, with inputs and output - 7:
the server performs orthogonalization and clipping - 8:
the server broadcasts to all node devices - 9:
each node device i sets - 10:
else - 11:
each node device i calculates the latest - 12:
end if - 13:
end for - 14:
return approximated eigenspace
|
One can easily extend this result for
with the composition property of DP: Algorithm 3 satisfies
-DP. Besides this basic loose composition, one can obtain better results by utilizing more involved composition theorems such as in [
34]. We leave this for future work.
Analysis. Similarly to
Section 4, we protect the individual intermediate results with SA. On the other hand, it is equivalent to generate
n Gaussian noise with variance
and select one, or to generate
n Gaussian noise with variance
and sum them all up. Consequently, instead of relying on an SMPC protocol to eliminate most of the local noise, we could merely scale them down. combining SA with such a downsized local noise is, in fact, a common practice in FL: this is what distributed differential privacy (DDP) [
35] does, i.e., DDP combined with SA provides LDP but with
n times smaller noise, where
n is the number of participants.
6. Empirical Comparison
In order to compare our proposed schemes with FedPower, we implement the schemes in Python [
36]. As we only encrypt 0 and 1 in
Section 4, we optimize the performance and take advantage of the utilized Paillier cryptosystem. More specifically, we re-randomize the corresponding ciphertexts to obtain new ciphertexts. In addition, we also exploit the homomorphic property, and instead of decrypting each value (
times), we first calculate the product of all the ciphertexts (elementary matrix multiplication) and then perform the decryption on a signal matrix. In this way, we obtain the sum of all Gaussian noises more efficiently. The decryption result is the sum of noise which will be canceled in Algorithm 2. Furthermore, we prepare the
,
and all keys of SA offline for each node device
i.
Metric. We use Euclidean distance to represent the similarity of two matrix and , i.e., . Let denote the true eigenspace computed without any noise, let denote the eigenspace generated with Algorithm 1, let denote the eigenspace generated with Algorithm 2, and let denote the eigenspace generated with Algorithm 3.
Setup. For our experiments, we used the well-known NETFLIX rating dataset [
37], and we pre-process it similarly to [
38] (instead of 10, we removed users and movies with less than 50 ratings). It consists of
ratings corresponding to
movies from
users. We split them horizontally into 100 random blocks to simulate node devices. Moreover, we set the security parameter to 128; thus, we adopt 3072 bits for
N in Paillier cryptosystem (this is equivalent to RSA-3072, which provides a 128-bit security level [
39]). The number of iteration rank and top eigenvectors is set to
, and we keep the same synchronous trigger
as [
18]. To compare FedPower with our enhanced solutions, we set the noise size for these algorithms as
. Moreover, for Algorithm 3 we bounded
with
and
with
for all possible
i and
t. Using Theorem 2, we can calculate that a single round corresponds to privacy budget
with
.
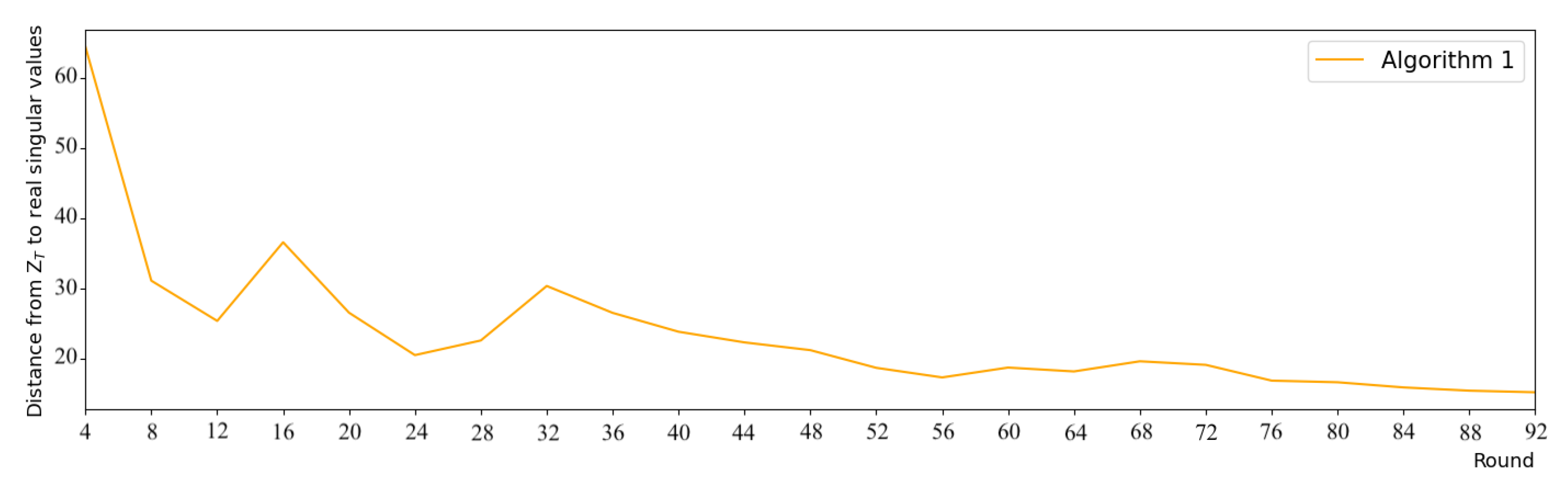
In order to determine the number of global rounds
T, we set up a small experiment. We built a data matrix
of size
filled with integers in
, and randomly divided it for 100 node devices (each has at least 10 rows). We executed Algorithm 1 for 200 rounds and compared the distance between the aggregation result
and the real singular values of
. From the result in
Figure 2, we can see that convergence occurs around the round 92, since the subsequent results vary only slightly (
). Thus, we set
for our experiments.
The experiment is implemented in a Docker container of 40-core Intel(R) Xeon(R) Silver 4210 CPU @ 2.20GHz and 755G RAM. We run our experiments 10-fold and take the average execution time.
Results. Firstly, we compare the efficiency of our enhanced schemes and the original algorithm. The computation times are presented in
Table 3. Compared with FedPower, the overall computation burden of the devices increased by a factor of
for the utility-enhanced solution in
Section 4 and only
and the privacy-enhanced solution in
Section 5. Concerning the server, the increase is
and
, respectively.
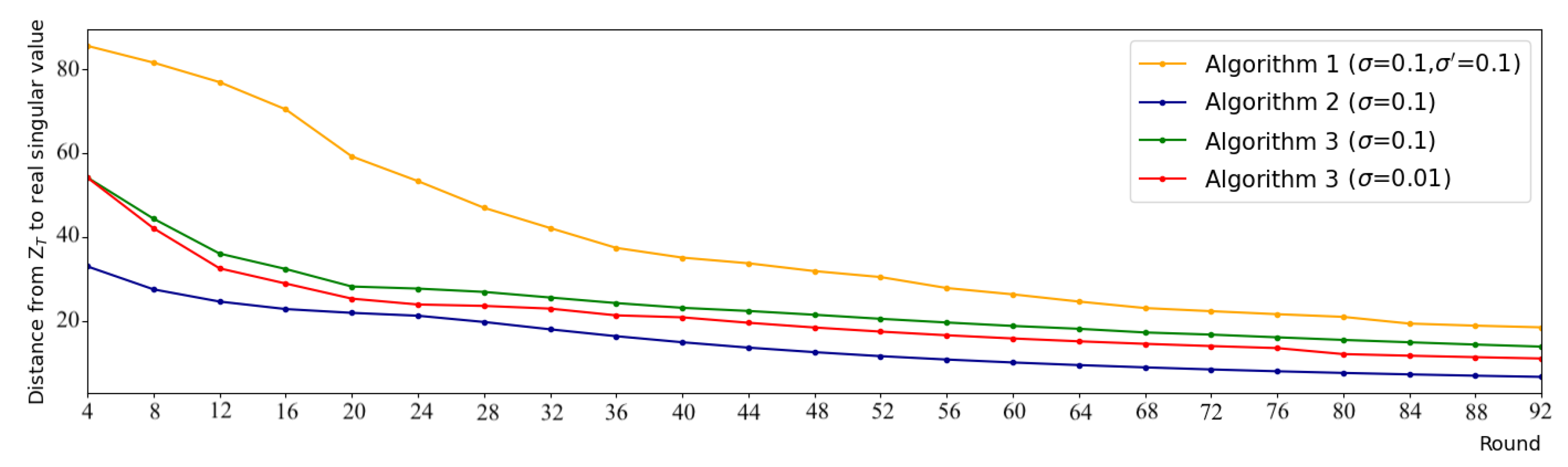
The rise in computational demand comes with benefits. Concerning Algorithm 2, significant progress is achieved in the utility while it offers a similar privacy guarantee as FedPower. Concerning Algorithm 3, the privacy guarantee is more robust, as it provides a formal DDP protection (while FedPower fails to satisfy DP). Moreover, it obtains a higher utility, which could make this solution preferable despite its computational appeal. We compare the distance between the results of each algorithm and the real eigenvalues, as shown in
Figure 3, and the utility is improved (i.e., the distances are lower) with both Algorithms 2 and 3.
Our utility-enhanced solution significantly outperforms FedPower: after 92 rounds, the obtained error of our scheme is almost three times () smaller than that for FedPower. The final error of Algorithm 2 is , while this value for Algorithm 1 is . Note that this level of accuracy (∼18.5) was obtained using our method in the 32nd round, i.e., almost three times () faster. Hence, the superior convergence speed can compensate for most of the computational increase caused by SA and SMPC.
Let us shift our attention to our privacy-enhanced solution. In that case, we can see that besides more robust privacy protection, our solution offers better utility: Algorithms 1 and 3 obtains and RMSE values, respectively, i.e., we acquired a 24% error reduction. Our method (with actual DP guarantees) achieved the same level of accuracy () only after 65 rounds, which is a 29% convergence speed increase.
We also compare our two proposed schemes, in a way, that the size of the accumulated noises is equal. Besides the nature of noise injection (many small vs. one large), the only factor that differentiates the results is the clipping bounds. As expected, the error is larger with clipping, i.e., compared with . Concerning the convergence speed, the utility enhanced solution is faster, reaching similar accuracy () in round 54. Note though that this result still vastly outperforms FedPower: the accuracy and the convergence speed are increased by 40% and 43%, respectively.
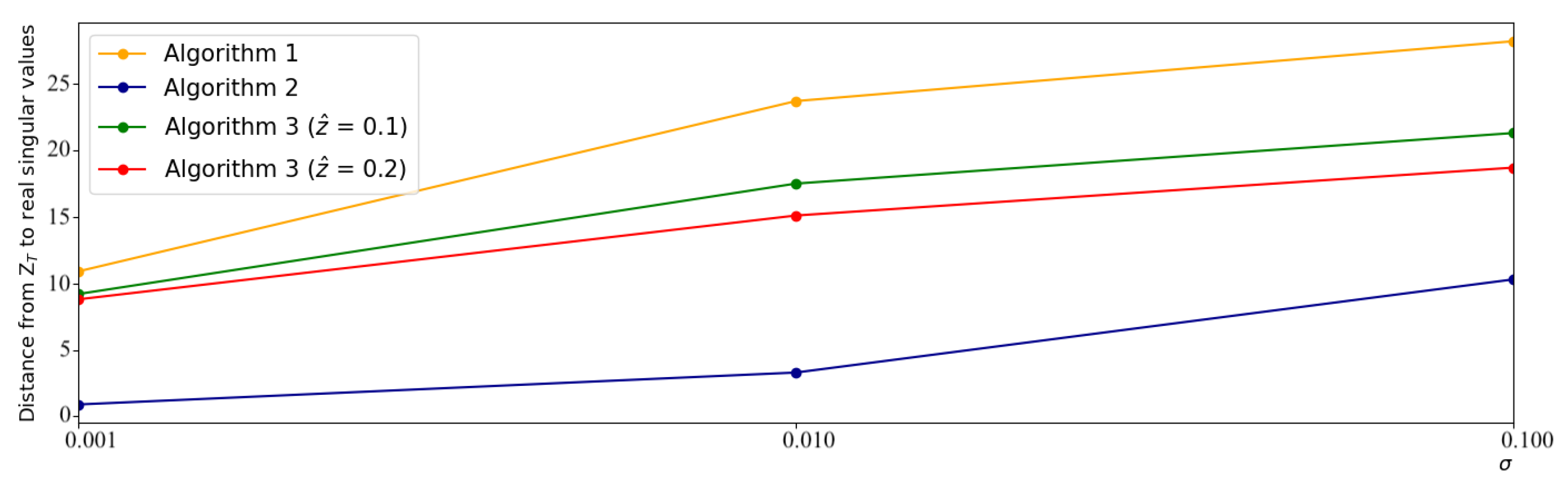
Finally, we study the effect of different levels of privacy protection on the accuracy of each algorithm. As we noticed in
Figure 3, after the 60th round, the error ratios of the algorithms are reasonably stable, so for this experiment, we set
. Since the clipping rate
and the noise variance
both contributed to the privacy parameter
(as seen in Theorem 2), we varied each independently. Our results are presented in
Figure 4. It is visible that the previously seen trends hold with other levels of privacy protection, making our proposed schemes favorable for a wide range of settings.




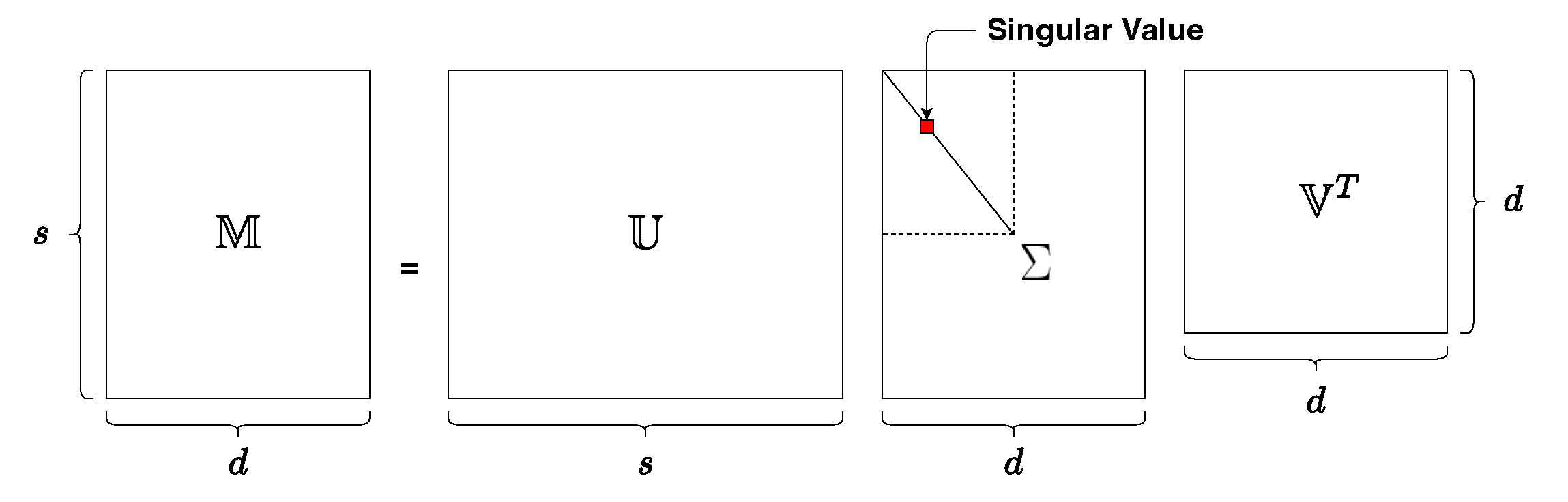{kind=link}
{kind=link}
{kind=link}
{kind=link}



