
Sentiment Analysis of Online New Energy Vehicle Reviews

Abstract
:1. Introduction
- A comprehensive dataset of comments specifically focused on new energy vehicles is curated. Accurate polarity labels for each comment are obtained through meticulous preprocessing steps, including data cleaning, tokenization, and sentiment category labeling.
- Multiple layers of Convolutional Neural Networks are leveraged by our deep Convolutional Neural Network model to extract localized features from sentences. The vanishing gradient problem is mitigated by introducing residual connections, and diverse channel representations are effectively fused using channel attention to adeptly handle cases of ambiguous sentiment tendencies in comments. Furthermore, contextual information, especially in the face of abrupt and unexpected comments, is captured excellently by our model.
- The novel hybrid sentiment analysis model is enhanced by combining the strengths of ERNIE and deep CNN. ERNIE, which is based on the Transformer deep learning architecture, demonstrates remarkable performance in pretraining Chinese language models. By integrating ERNIE’s capabilities into our model, advantages are gained when processing Chinese new energy vehicle comments, which are characterized by incomplete context, suddenness, and the presence of domain-specific terminology.
2. Related Works
2.1. Sentiment Analysis
2.2. BERT Model
2.3. CNN Model
3. The Proposed Model EDC
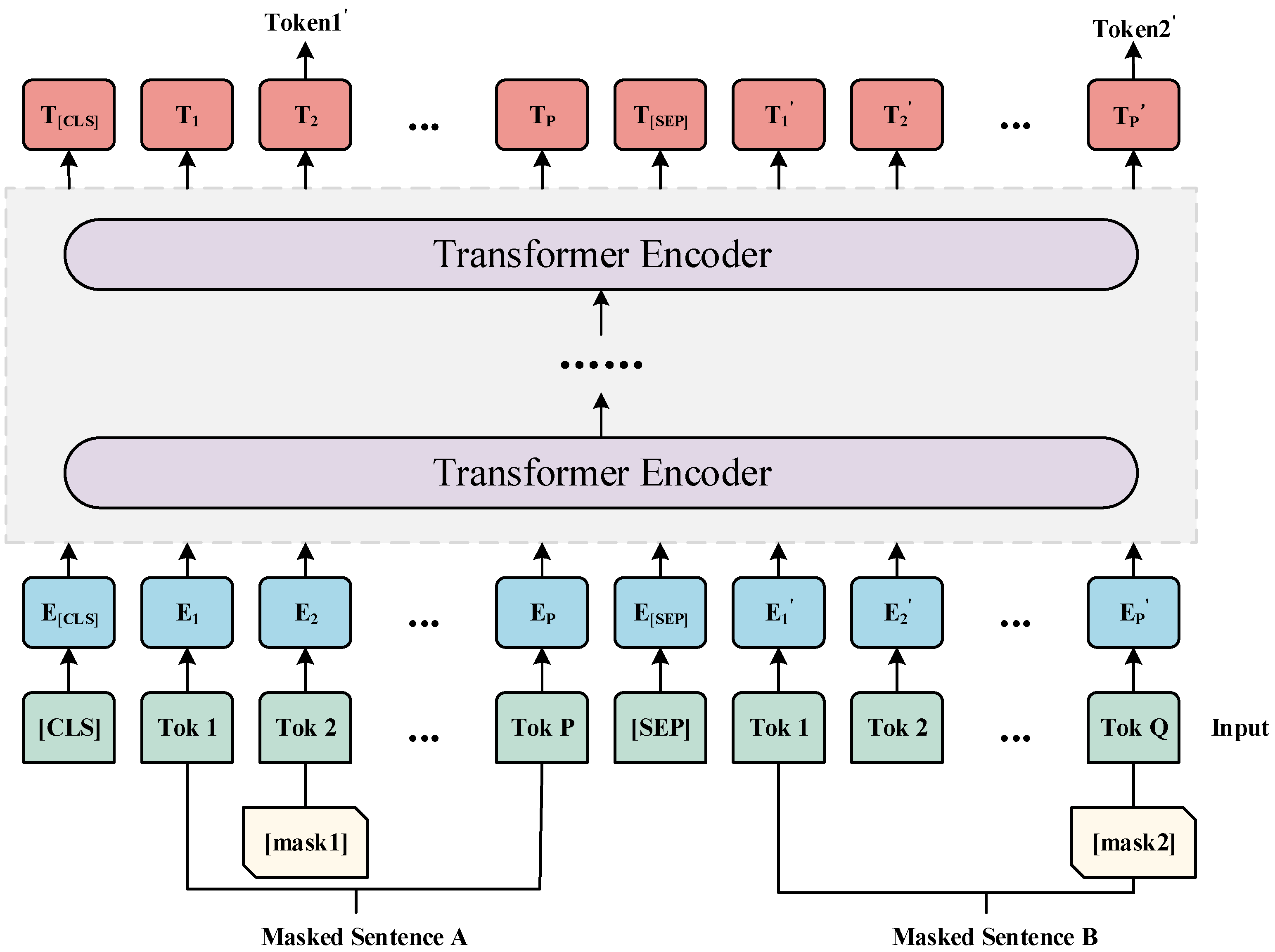
3.1. ERNIE Model
- Chinese words and phrases are semantically rich, often exhibiting polysemy and other challenges, which leads to inaccurate semantic representation in the encoded vectors.
- Some automotive comments employ highly specialized vocabulary, making the text obscure and difficult to comprehend. The prevailing pretrained language model, BERT, has addressed problems related to the insufficient extraction of contextual semantics in traditional models. However, it still faces certain challenges in Chinese sentiment analyses of new energy vehicle comments, including unclear recognition of Chinese semantic concepts and limited Chinese representation capabilities.
3.2. Deep CNN Model
- (1)
- Average Pooling and Max Pooling: Firstly, the extracted feature map matrix x is subjected to spatial dimension pooling using adaptive average pooling (avg_pool) and adaptive max pooling (max_pool). This compresses the feature map into the size of [batch_size, num_filters, 1, 1], resulting in an average value and a maximum value for each channel.
- (2)
- Fully Connected Layers: The two-dimensionally reduced one-dimensional vectors are separately passed through two fully connected layers, fc1 and fc2. fc1 reduces the input channel size to 1/16 of the original size and applies the ReLU activation function. fc2 restores the channel size to the original size. The outputs of fc1 and fc2 are then added together to obtain the outputs of the channel attention mechanism, avg_out and max_out. The avg_out and max_out are further added together to produce the final output of the channel attention mechanism, out.
- (3)
- Adding Contextual Information: The input feature map x is processed through two convolutional layers, conv1 and conv2, where conv1 has an output channel size of 1/2 of the input channels, and conv2 has the same output channel size as the input. The results of conv1 and conv2 are added to the input x to incorporate the contextual information.
- (4)
- Implementing Residual Connections: The output out of the channel attention mechanism is added to the input x to achieve residual connections.
- (5)
- Sequence Processing: The input feature map x is transformed from a feature map to a sequence. This is done by using the view and permute operations to flatten the height and width dimensions of the feature map into a one-dimensional sequence, with the batch size placed in the second dimension. The sequence feature x is then input into the BiGRU module (bigru), with an initial hidden state h0 set to a zero matrix. The BiGRU module processes the input sequence feature x and produces a new sequence feature x. The processed sequence feature x is then transformed back into the shape of the input feature map. This is achieved through dimension permutation and reshaping operations, resulting in a feature map with the same dimensions as the input x.
- (6)
- Residual Connections: The feature map x obtained after sequence processing is added to the previously obtained output of the residual connections to yield the final feature map output.
- (7)
- Output: The final feature map is passed through a global average pooling layer, which reduces the height and width dimensions to 1. The resulting feature map is then reshaped using the view operation into the shape of (batch_size, channels). This output is input into a fully connected layer, which maps the feature vector to the desired number of output classes. The softmax function is applied for classification purposes.
| Algorithm 1: Algorithm EV Car review sentiment analysis channel attention |
| Input: Feature map processed by convolutional neural network (x) Output: Feature map processed by channel attention mechanism (out) 1: avg_out = fully_connected_layer1(average_pooling(x)) 2: max_out = fully_connected_layer1(max_pooling(x)) 3: out = avg_out + max_out 4: context = convolutional_layer2(ReLU(convolutional_layer1(x))) 5: out += context 6: out = out + x 7: x = reshape(x) 8: h0 = initialize_hidden_state() 9: x, _ = BiGRU(x, h0) 10: x = reshape(x) 11: out = out + x 12: return sigmoid_activation(out) |
3.3. EDC Model
3.4. Loss Function
4. Experiment and Analysis
4.1. Experimental Environment
4.2. Experimental Data
4.3. Evaluation Metrics
4.4. Model Parameter Settings
4.5. Baseline Model
- (a)
- Word2vec-based Word Embedding Methods
- (b)
- BERT-based Word Embedding Methods
5. Experimental Results
5.1. Loss Experimental Results
5.2. Comparison of Accuracy Experimental Results
5.3. Precision Experimental Results Comparison
5.4. Recall Experimental Results Comparison
5.5. Comparison of F1 Score Experimental Results
5.6. Comprehensive Comparison of Experimental Evaluation Metrics
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Andreopoulou, Z.; Koliouska, C.; Galariotis, E.; Zopounidis, C. Renewable energy sources: Using PROMETHEE II for ranking websites to support market opportunities. Technol. Forecast. Soc. Chang. 2018, 131, 31–37. [Google Scholar] [CrossRef]
- Mopidevi, S.; Narasipuram, R.P.; Aemalla, S.R.; Rajan, H. E-mobility: Impacts and analysis of future transportation electrification market in economic, renewable energy and infrastructure perspective. Int. J. Powertrains 2022, 11, 264–284. [Google Scholar] [CrossRef]
- Chen, Y.-J.; Chen, Y.M. Online Information-based Product Evolution Course Mining and Prediction. Int. J. Inf. Technol. Decis. Mak. 2023, 1–29. [Google Scholar] [CrossRef]
- Narasipuram, R.P.; Mopidevi, S. A technological overview & design considerations for developing electric vehicle charging stations. J. Energy Storage 2021, 43, 103225. [Google Scholar]
- Zhang, X.; Wen, S.; Yan, L.; Feng, J.; Xia, Y. A Hybrid-Convolution Spatial–Temporal Recurrent Network for Traffic Flow Prediction. Comput. J. 2022, bxac171. [Google Scholar] [CrossRef]
- Zhang, S.; Zhou, Z.; Luo, R.; Zhao, R.; Xiao, Y.; Xu, Y. A low-carbon, fixed-tour scheduling problem with time windows in a time-dependent traffic environment. Int. J. Prod. Res. 2022, 1–20. [Google Scholar] [CrossRef]
- Zhang, X.; Wang, Y.; Yuan, X.; Shen, Y.; Lu, Z.; Wang, Z. Adaptive Dynamic Surface Control with Disturbance Observers for Battery/Supercapacitor-based Hybrid Energy Sources in Electric Vehicles. IEEE Trans. Transp. Electrif. 2022. [Google Scholar] [CrossRef]
- Chen, Y. Research on collaborative innovation of key common technologies in new energy vehicle industry based on digital twin technology. Energy Rep. 2022, 8, 15399–15407. [Google Scholar] [CrossRef]
- Qu, Z.; Liu, X.; Zheng, M. Temporal-Spatial Quantum Graph Convolutional Neural Network Based on Schrödinger Approach for Traffic Congestion Prediction. IEEE Trans. Intell. Transp. Syst. 2022. [Google Scholar] [CrossRef]
- Jiang, S.; Zhao, C.; Zhu, Y.; Wang, C.; Du, Y. A Practical and Economical Ultra-wideband Base Station Placement Approach for Indoor Autonomous Driving Systems. J. Adv. Transp. 2022, 2022, 3815306. [Google Scholar] [CrossRef]
- Huang, C.; Han, Z.; Li, M.; Wang, X.; Zhao, W. Sentiment evolution with interaction levels in blended learning environments: Using learning analytics and epistemic network analysis. Australas. J. Educ. Technol. 2021, 37, 81–95. [Google Scholar] [CrossRef]
- Liu, X.; He, J.; Liu, M.; Yin, Z.; Yin, L.; Zheng, W. A Scenario-Generic Neural Machine Translation Data Augmentation Method. Electronics 2023, 12, 2320. [Google Scholar] [CrossRef]
- Khan, F.M.; Khan, S.A.; Shamim, K.; Gupta, Y.; Sherwani, S.I. Analysing customers’ reviews and ratings for online food deliveries: A text mining approach. Int. J. Consum. Stud. 2022, 47, 953–976. [Google Scholar] [CrossRef]
- Aljuaid, H.; Iftikhar, R.; Ahmad, S.; Asif, M.; Afzal, M.T. Important citation identification using sentiment analysis of in-text citations. Telemat. Inform. 2021, 56, 101492. [Google Scholar] [CrossRef]
- Verma, S. Sentiment analysis of public services for smart society: Literature review and future research directions. Gov. Inf. Q. 2022, 39, 101708. [Google Scholar] [CrossRef]
- Ranjbar, M.; Effati, S. Symmetric and right-hand-side hesitant fuzzy linear programming. IEEE Trans. Fuzzy Syst. 2019, 28, 215–227. [Google Scholar] [CrossRef]
- Gharzouli, M.; Hamama, A.K.; Khattabi, Z. Topic-based sentiment analysis of hotel reviews. Curr. Issues Tour. 2022, 25, 1368–1375. [Google Scholar] [CrossRef]
- Vidanagama, D.; Silva, A.; Karunananda, A. Ontology based sentiment analysis for fake review detection. Expert Syst. Appl. 2022, 206, 117869. [Google Scholar] [CrossRef]
- Kaur, G.; Sharma, A. A deep learning-based model using hybrid feature extraction approach for consumer sentiment analysis. J. Big Data 2023, 10, 5. [Google Scholar] [CrossRef]
- Çalı, S.; Balaman, Ş.Y. Improved decisions for marketing, supply and purchasing: Mining big data through an integration of sentiment analysis and intuitionistic fuzzy multi criteria assessment. Comput. Ind. Eng. 2019, 129, 315–332. [Google Scholar] [CrossRef]
- Iqbal, A.; Amin, R.; Iqbal, J.; Alroobaea, R.; Binmahfoudh, A.; Hussain, M. Sentiment Analysis of Consumer Reviews Using Deep Learning. Sustainability 2022, 14, 10844. [Google Scholar] [CrossRef]
- Xiao, Y.; Li, C.; Thürer, M.; Liu, Y.; Qu, T. User preference mining based on fine-grained sentiment analysis. J. Retail. Consum. Serv. 2022, 68, 103013. [Google Scholar] [CrossRef]
- Hsu, T.-H.; Chen, C.-H.; Liao, W.-C. A Fuzzy MCDM Analytic Model for Building Customers’ Brand Attachment Preference in Car Firms. Int. J. Fuzzy Syst. 2021, 23, 2270–2282. [Google Scholar] [CrossRef]
- Yong, L.; Xiaojun, Y.; Yi, L.; Ruijun, L.; Qingyu, J. A new emotion analysis fusion and complementary model based on online food reviews. Comput. Electr. Eng. 2022, 98, 107679. [Google Scholar] [CrossRef]
- Zhang, X.; Wu, Z.; Liu, K.; Zhao, Z.; Wang, J.; Wu, C. Text Sentiment Classification Based on BERT Embedding and Sliced Multi-Head Self-Attention Bi-GRU. Sensors 2023, 23, 1481. [Google Scholar] [CrossRef]
- Yang, Y.; Ke, W.; Wang, W.; Zhao, Y. Deep learning for web services classification. In Proceedings of the 2019 IEEE International Conference on Web Services (ICWS), Milan, Italy, 8–13 July 2019; pp. 440–442. [Google Scholar]
- Jain, P.K.; Quamer, W.; Saravanan, V.; Pamula, R. Employing BERT-DCNN with sentic knowledge base for social media sentiment analysis. J. Ambient. Intell. Humaniz. Comput. 2022, 14, 10417–10429. [Google Scholar] [CrossRef]
- Cui, Y.; Che, W.; Liu, T.; Qin, B.; Yang, Z. Pre-training with whole word masking for chinese bert. IEEE/ACM Trans. Audio Speech Lang. Process. 2021, 29, 3504–3514. [Google Scholar] [CrossRef]
- Yates, A.; Nogueira, R.; Lin, J. Pretrained transformers for text ranking: BERT and beyond. In Proceedings of the 14th ACM International Conference on Web Search and Data Mining, Online, 8–12 March 2021; pp. 1154–1156. [Google Scholar]
- Kim, K.; Park, S. AOBERT: All-modalities-in-One BERT for multimodal sentiment analysis. Inf. Fusion 2023, 92, 37–45. [Google Scholar] [CrossRef]
- Yang, X.; Li, Y.; Li, Q.; Liu, D.; Li, T. Temporal-spatial three-way granular computing for dynamic text sentiment classification. Inf. Sci. 2022, 596, 551–566. [Google Scholar] [CrossRef]
- Li, Z.; Ren, J. Fine-tuning ERNIE for chest abnormal imaging signs extraction. J. Biomed. Inform. 2020, 108, 103492. [Google Scholar] [CrossRef]
- Cheng, K.; Yue, Y.; Song, Z. Sentiment Classification Based on Part-of-Speech and Self-Attention Mechanism. IEEE Access 2020, 8, 16387–16396. [Google Scholar] [CrossRef]
- Li, Q.; Yao, N.; Zhao, J.; Zhang, Y. Self attention mechanism of bidirectional information enhancement. Appl. Intell. 2021, 52, 2530–2538. [Google Scholar] [CrossRef]
- Bae, J.; Lee, C. Korean Semantic Role Labeling with Bidirectional Encoder Representations from Transformers and Simple Semantic Information. Appl. Sci. 2022, 12, 5995. [Google Scholar] [CrossRef]
- Hao, S.; Zhang, P.; Liu, S.; Wang, Y. Sentiment recognition and analysis method of official document text based on BERT–SVM model. Neural Comput. Appl. 2023, 1–12. [Google Scholar] [CrossRef]
- Kawaguchi, K.; Bengio, Y. Depth with nonlinearity creates no bad local minima in ResNets. Neural Netw. 2019, 118, 167–174. [Google Scholar] [CrossRef]
- Qian, K.; Tian, L. A topic-based multi-channel attention model under hybrid mode for image caption. Neural Comput. Appl. 2021, 34, 2207–2216. [Google Scholar] [CrossRef]
- Lu, Y.; Yuan, M.; Liu, J.; Chen, M. Research on semantic representation and citation recommendation of scientific papers with multiple semantics fusion. Scientometrics 2023, 128, 1367–1393. [Google Scholar] [CrossRef]
- Loewenstein, Y.; Raviv, O.; Ahissar, M. Dissecting the roles of supervised and unsupervised learning in perceptual discrimination judgments. J. Neurosci. 2021, 41, 757–765. [Google Scholar] [CrossRef]
- Sakai, Y.; Itoh, Y.; Jung, P.; Kokeyama, K.; Kozakai, C.; Nakahira, K.T.; Oshino, S.; Shikano, Y.; Takahashi, H.; Uchiyama, T.; et al. Training Process of Unsupervised Learning Architecture for Gravity Spy Dataset. Ann. Phys. 2022, 2200140. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Liu, N.; Zhao, J. A BERT-Based Aspect-Level Sentiment Analysis Algorithm for Cross-Domain Text. Comput. Intell. Neurosci. 2022, 2022, 8726621. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Projects | Configuration |
|---|---|
| Operating Platforms | CUDA 11.2/CUDNN8.1 |
| Operating System | Windows 10 |
| Memory | 16 GB |
| Python Versions | Python 3.7.0 |
| PyTorch Versions | PyTorch 1.9.1 |
| Parameter Name | Parameter Vaule |
|---|---|
| Maximum sentence length | 128 |
| Batch size | 64 |
| Transformer layers | 12 |
| Transformer number of hidden neurons | 768 |
| Learning rate | 0.00001 |
| Maximum number of iterations | 100 |
| Optimization methods | Adam |
| Algorithms | Accuracy | Precision | Precision | Recall | Recall | F1 Score | F1 Score |
|---|---|---|---|---|---|---|---|
| NEG | POS | NEG | POS | NEG | POS | ||
| FastText | 86.63% | 0.8675 | 0.8651 | 0.8665 | 0.8661 | 0.8670 | 0.8656 |
| TextCNN | 91.60% | 0.9088 | 0.9236 | 0.9259 | 0.9060 | 0.9173 | 0.9147 |
| TextRCNN | 89.70% | 0.8959 | 0.8981 | 0.8997 | 0.8943 | 0.8978 | 0.8962 |
| TextRNN | 84.77% | 0.8822 | 0.8185 | 0.8045 | 0.8914 | 0.8416 | 0.8534 |
| TextRNN_Att | 89.19% | 0.8830 | 0.9013 | 0.9048 | 0.8787 | 0.8938 | 0.8899 |
| Transformer | 87.79% | 0.8984 | 0.8591 | 0.8537 | 0.9023 | 0.8755 | 0.8802 |
| DPCNN | 93.57% | 0.9314 | 0.9402 | 0.9415 | 0.9299 | 0.9364 | 0.9350 |
| BERT_CNN | 94.27% | 0.9392 | 0.9464 | 0.9474 | 0.9379 | 0.9433 | 0.9421 |
| BERT_RNN | 94.36% | 0.9400 | 0.9472 | 0.9483 | 0.9388 | 0.9441 | 0.9430 |
| BERT_RCNN | 94.63% | 0.9408 | 0.9520 | 0.9531 | 0.9394 | 0.9469 | 0.9456 |
| BERT_DPCNN | 94.49% | 0.9399 | 0.9500 | 0.9511 | 0.9385 | 0.9455 | 0.9442 |
| EDC | 97.39% | 0.9728 | 0.9749 | 0.9753 | 0.9724 | 0.9740 | 0.9737 |
| Algorithms | TP | FP | TN | FN |
|---|---|---|---|---|
| FastText | 3050 | 466 | 3014 | 470 |
| TextCNN | 3259 | 327 | 3153 | 261 |
| TextRCNN | 3167 | 368 | 3112 | 353 |
| TextRNN | 3029 | 359 | 3121 | 301 |
| TextRNN_Att | 3185 | 422 | 3058 | 335 |
| Transformer | 3005 | 340 | 3140 | 515 |
| DPCNN | 3314 | 244 | 3236 | 206 |
| BERT_CNN | 3335 | 216 | 3264 | 185 |
| BERT_RNN | 3338 | 213 | 3267 | 182 |
| BERT_RCNN | 3354 | 218 | 3261 | 166 |
| BERT_DPCNN | 3348 | 214 | 3266 | 172 |
| EDC | 3433 | 96 | 3384 | 87 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, M.; You, H.; Ma, H.; Sun, X.; Wang, Z. Sentiment Analysis of Online New Energy Vehicle Reviews. Appl. Sci. 2023, 13, 8176. https://doi.org/10.3390/app13148176
Wang M, You H, Ma H, Sun X, Wang Z. Sentiment Analysis of Online New Energy Vehicle Reviews. Applied Sciences. 2023; 13(14):8176. https://doi.org/10.3390/app13148176
Chicago/Turabian StyleWang, Mengsheng, Hailong You, Hongbin Ma, Xianhe Sun, and Zhiqiang Wang. 2023. "Sentiment Analysis of Online New Energy Vehicle Reviews" Applied Sciences 13, no. 14: 8176. https://doi.org/10.3390/app13148176