
Hyperspectral Point Cloud Projection for the Semantic Segmentation of Multimodal Hyperspectral and Lidar Data with Point Convolution-Based Deep Fusion Neural Networks

Abstract
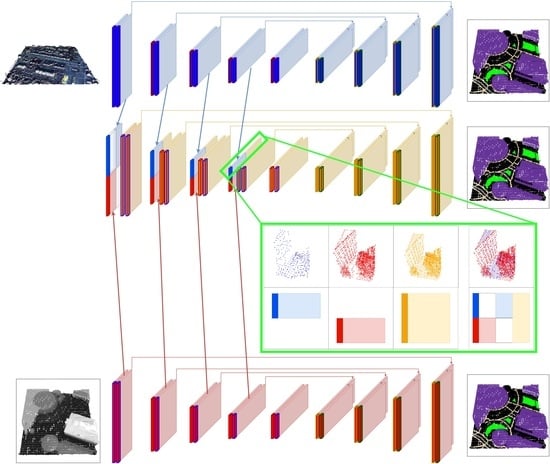
:
1. Introduction
- We introduce an innovative method for generating Hyperspectral Point Cloud (HSPC) representations, one focusing on the exploitation of primarily spectral features and another allowing for the utilization of both spectral and structural features (Section 2.1.2).
- We develop a composite style fusion network based on Kernel Point Convolution (KPConv), as well as other network architectures, which form part of an ablative study aimed at evaluating the performance of unimodal networks in comparison to the multimodal network (Section 2.2.1). This fusion network is the first to perform a learned feature fusion of 3D point clouds in a fully 3D point convolution-based neural network.
- We propose a unique method for associating hyperspectral point locations with lidar point locations, enabling the generation of a canonical set of points where multimodal features are localized (Section 2.2.2).
- We offer a comprehensive performance analysis of both unimodal and multimodal networks, discussing their results in the context of our proposed hyperspectral representation and fusion implementation (Section 3).
2. Materials and Methods
2.1. Materials
2.1.1. Preprocessing and Lidar Labeling
2.1.2. Hyperspectral Point Cloud Generation
2.1.3. Multimodal Sample Generation
2.2. Methods
2.2.1. Architectures
2.2.2. Canonical Multimodal Point Creation and Unimodal Feature Fusion
2.2.3. Graph Pyramid Generation
2.2.4. Network Training
2.2.5. Post-Processing
3. Results
4. Discussion
- Harness the power of LiDAR data in its native, information-rich point cloud format. Over the past decade, remarkable progress has been made in point cloud processing networks research [30], with novel processing methodologies and network architectures emerging at a rapid pace. This progress should be extended to the field of multimodal remote sensing. The encouraging results of the L3D network further support this notion, as the point cloud processing-based network L3D (trained in this work) achieves a 9% higher pixel accuracy than the lidar DSM network L2D. Continued exploration of point cloud processing methodologies promises to yield enhanced performance.
- Employ and integrate advanced neural network architectures and components. This work has primarily focused on traditional pixel and point-based convolutions. However, more sophisticated pixel and point convolution-based architectures hold the potential to improve performance. For instance, pixel-based convolution can be enhanced with residual layers or attention mechanisms, which are commonly employed in practice. Similarly, KPConv can be augmented with residual layers or deformable kernels. Another potential modification for KPConv, not yet implemented, is a 2D mode of operation. This would facilitate the processing of images (after being converted into spectral point clouds as described in Section 2.1.2) and make full use of the kernel points set, requiring only structural information for point feature fusion to co-locate features spatially.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A
Appendix A.1. Superclass Generation from GRSS18 Classes

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| GRSS18 Class | Pixel Count | Percentage of Total | Superclass Assignment |
|---|---|---|---|
| unlabeled | 3,712,226 | 64.773 | unlabeled |
| non-residential buildings | 894,769 | 15.612 | buildings |
| major thoroughfares | 185,438 | 3.236 | vehicle path |
| roads | 183,283 | 3.198 | vehicle path |
| residential buildings | 158,995 | 2.774 | buildings |
| sidewalks | 136,035 | 2.374 | human path |
| stressed grass | 130,008 | 2.268 | foliage |
| evergreen trees | 54,322 | 0.948 | foliage |
| paved parking lots | 45,932 | 0.801 | vehicle path |
| highways | 39,438 | 0.688 | vehicle path |
| healthy grass | 39,196 | 0.684 | foliage |
| railways | 27,748 | 0.484 | vehicle path |
| stadium seats | 27,296 | 0.476 | unlabeled |
| cars | 26,289 | 0.459 | vehicle |
| trains | 21,479 | 0.375 | vehicle |
| deciduous trees | 20,172 | 0.352 | foliage |
| bare earth | 18,064 | 0.315 | foliage |
| crosswalks | 6059 | 0.106 | human path |
| artificial turf | 2736 | 0.048 | unlabeled |
| water | 1064 | 0.019 | unlabeled |
| unpaved parking lots | 587 | 0.010 | vehicle path |
| Total | 5,731,136 |
| Superclass | Pixel Count | Percentage of Total | Percentage of TVT Sets |
|---|---|---|---|
| unlabeled | 3,743,322 | 65.316 | 66.75, 67.33, 56.37 |
| building | 1,053,764 | 18.387 | 18.45, 11.69, 25.06 |
| vehicle path | 482,426 | 8.418 | 8.73, 8.52, 6.83 |
| foliage | 261,762 | 4.567 | 2.05, 4.05, 2.87 |
| human path | 142,094 | 2.479 | 3.31, 7.18, 7.83 |
| vehicle | 47,768 | 0.833 | 0.7, 1.23, 1.04 |

Appendix A.2. Model Training Histories

References
- Kuras, A.; Brell, M.; Rizzi, J.; Burud, I. Hyperspectral and Lidar Data Applied to the Urban Land Cover Machine Learning and Neural-Network-Based Classification: A Review. Remote Sens. 2021, 13, 3393. [Google Scholar] [CrossRef]
- Singh, M.K.K.; Mohan, S.; Kumar, B. Fusion of hyperspectral and LiDAR data using sparse stacked autoencoder for land cover classification with 3D-2D convolutional neural network. J. Appl. Remote Sens. 2022, 16, 034523. [Google Scholar] [CrossRef]
- Tang, J.; Liang, J.; Yang, Y.; Zhang, S.; Hou, H.; Zhu, X. Revealing the Structure and Composition of the Restored Vegetation Cover in Semi-Arid Mine Dumps Based on LiDAR and Hyperspectral Images. Remote Sens. 2022, 14, 978. [Google Scholar] [CrossRef]
- Nguyen, C.; Sagan, V.; Bhadra, S.; Moose, S. UAV Multisensory Data Fusion and Multi-Task Deep Learning for High-Throughput Maize Phenotyping. Sensors 2023, 23, 1827. [Google Scholar] [CrossRef] [PubMed]
- Kuras, A.; Brell, M.; Liland, K.H.; Burud, I. Multitemporal Feature-Level Fusion on Hyperspectral and LiDAR Data in the Urban Environment. Remote Sens. 2023, 15, 632. [Google Scholar] [CrossRef]
- Wu, H.; Dai, S.; Liu, C.; Wang, A.; Iwahori, Y. A Novel Dual-Encoder Model for Hyperspectral and LiDAR Joint Classification via Contrastive Learning. Remote Sens. 2023, 15, 924. [Google Scholar] [CrossRef]
- Lu, T.; Ding, K.; Fu, W.; Li, S.; Guo, A. Coupled adversarial learning for fusion classification of hyperspectral and LiDAR data. Inf. Fusion 2023, 93, 118–131. [Google Scholar] [CrossRef]
- Decker, K.T.; Borghetti, B.J. Composite Style Pixel and Point Convolution-Based Deep Fusion Neural Network Architecture for the Semantic Segmentation of Hyperspectral and Lidar Data. Remote Sens. 2022, 14, 2113. [Google Scholar] [CrossRef]
- Chen, A.; Wang, X.; Zhang, M.; Guo, J.; Xing, X.; Yang, D.; Zhang, H.; Hou, Z.; Jia, Z.; Yang, X. Fusion of LiDAR and Multispectral Data for Aboveground Biomass Estimation in Mountain Grassland. Remote Sens. 2023, 15, 405. [Google Scholar] [CrossRef]
- Brell, M.; Segl, K.; Guanter, L.; Bookhagen, B. 3D hyperspectral point cloud generation: Fusing airborne laser scanning and hyperspectral imaging sensors for improved object-based information extraction. ISPRS J. Photogramm. Remote Sens. 2019, 149, 200–214. [Google Scholar] [CrossRef]
- Zhang, L.; Jin, J.; Wang, L.; Rehman, T.U.; Gee, M.T.; Zhang, L.; Jin, J.; Wang, L.; Rehman, T.U.; Gee, M.T. Elimination of Leaf Angle Impacts on Plant Reflectance Spectra Using Fusion of Hyperspectral Images and 3D Point Clouds. Sensors 2022, 23, 44. [Google Scholar] [CrossRef] [PubMed]
- Mitschke, I.; Wiemann, T.; Igelbrink, F.; Hertzberg, J. Hyperspectral 3D Point Cloud Segmentation Using RandLA-Net; Springer Nature Switzerland: Cham, Switzerland, 2023; pp. 301–312. [Google Scholar] [CrossRef]
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Networks. In Proceedings of the 27th International Conference on Neural Information Processing Systems (NIPS 2014), Montreal, QC, Canada, 8–13 December 2014; pp. 2672–2680. [Google Scholar]
- Jaderberg, M.; Simonyan, K.; Zisserman, A.; Kavukcuoglu, K. Spatial Transformer Networks. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; Volume 2015, pp. 2017–2025. [Google Scholar]
- Zhang, M.; Li, W.; Zhang, Y.; Tao, R.; Du, Q. Hyperspectral and LiDAR Data Classification Based on Structural Optimization Transmission. IEEE Trans. Cybern. 2022, 53, 3153–3164. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Y.; Zhang, M.; Li, W.; Wang, S.; Tao, R. Language-Aware Domain Generalization Network for Cross-Scene Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2023, 61, 1–12. [Google Scholar] [CrossRef]
- Piramanayagam, S.; Saber, E.; Schwartzkopf, W.; Koehler, F. Supervised Classification of Multisensor Remotely Sensed Images Using a Deep Learning Framework. Remote Sens. 2018, 10, 1429. [Google Scholar] [CrossRef] [Green Version]
- Karpathy, A.; Toderici, G.; Shetty, S.; Leung, T.; Sukthankar, R.; Li, F.F. Large-scale video classification with convolutional neural networks. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; IEEE Computer Society: Washington, DC, USA; pp. 1725–1732. [Google Scholar] [CrossRef] [Green Version]
- Thomas, H.; Qi, C.R.; Deschaud, J.E.; Marcotegui, B.; Goulette, F.; Guibas, L.J. KPConv: Flexible and Deformable Convolution for Point Clouds. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; Volume 2019, pp. 6410–6419. [Google Scholar]
- Xu, Y.; Du, B.; Zhang, L.; Cerra, D.; Pato, M.; Carmona, E.; Prasad, S.; Yokoya, N.; Hansch, R.; Le Saux, B. Advanced multi-sensor optical remote sensing for urban land use and land cover classification: Outcome of the 2018 IEEE grss data fusion contest. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 12, 1709–1724. [Google Scholar] [CrossRef]
- Hong, D.; Chanussot, J.; Yokoya, N.; Kang, J.; Zhu, X.X. Learning-Shared Cross-Modality Representation Using Multispectral-LiDAR and Hyperspectral Data. IEEE Geosci. Remote Sens. Lett. 2020, 17, 1470–1474. [Google Scholar] [CrossRef] [Green Version]
- Xu, Y.; Du, B.; Zhang, L. Multi-source remote sensing data classification via fully convolutional networks and post-classification processing. In Proceedings of the International Geoscience and Remote Sensing Symposium (IGARSS), Valencia, Spain, 22–27 July 2018; Institute of Electrical and Electronics Engineers Inc.: Manhattan, NY, USA; Volume 2018, pp. 3852–3855. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015; Springer: Cham, Switzerland, 2015. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. In Advances in Neural Information Processing Systems 32; Wallach, H., Larochelle, H., Beygelzimer, A., d’Alché-Buc, F., Fox, E., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2019; pp. 8024–8035. [Google Scholar]
- Feydy, J.; Glaunès, J.; Charlier, B.; Bronstein, M. Fast geometric learning with symbolic matrices. Adv. Neural Inf. Process. Syst. 2020, 33, 14448–14462. [Google Scholar]
- GitHub-qinzheng93/Easy-KPConv: A More Easy-to-Use Implementation of KPConv. Available online: https://github.com/qinzheng93/vision3d-engine (accessed on 3 January 2022).
- GitHub-qinzheng93/Vision3d-Engine: Vision3d-Engine: An Easy-to-Use Yet Powerful Training Engine from Vision3d. Available online: https://github.com/qinzheng93/Easy-KPConv (accessed on 3 January 2022).
- Cerra, D.; Pato, M.; Carmona, E.; Azimi, S.M.; Tian, J.; Bahmanyar, R.; Kurz, F.; Vig, E.; Bittner, K.; Henry, C.; et al. Combining deep and shallow neural networks with ad hoc detectors for the classification of complex multi-modal urban scenes. In Proceedings of the International Geoscience and Remote Sensing Symposium (IGARSS), Valencia, Spain, 22–27 July 2018; Volume 2018, pp. 3856–3859. [Google Scholar] [CrossRef] [Green Version]
- Li, C.; Tang, X.; Shi, L.; Peng, Y.; Tang, Y. A Two-Staged Feature Extraction Method Based on Total Variation for Hyperspectral Images. Remote Sens. 2022, 14, 302. [Google Scholar] [CrossRef]
- Guo, Y.; Wang, H.; Hu, Q.; Liu, H.; Liu, L.; Bennamoun, M. Deep Learning for 3D Point Clouds: A Survey. arXiv 2019, arXiv:1912.12033. [Google Scholar] [CrossRef] [PubMed]








| Architecture | Input Modality | CNN Type/ Output Type | Input Data Type | Comprised of |
|---|---|---|---|---|
| L3D [8] | Single | Point | LI-PC | - |
| H3D-Flat (HSF) | Single | Point | HS-Spectral | - |
| H3D-DSM (HSD) | Single | Point | HS-Structural | - |
| HSD-L3D | Multi | Point | HS-Struct, LI-PC | H3D-DSM, L3D |
| Architecture | # Params | Max Epoch | Opt/LR | Batch Size | Epoch Time | VRAM Mean |
|---|---|---|---|---|---|---|
| L3D | 24.3 M | 150 | SGD/ | 16 | 8.8 min | 29 GB |
| H3D-Flat | 24.5 M | 150 | SGD/ | 64 | 7.2 min | 21 GB |
| H3D-DSM | 24.5 M | 150 | SGD/ | 64 | 6.9 min | 20 GB |
| HSD-L3D | 125.7 M | 150 | SGD/ | 12 | 13.5 min | 41 GB |
| L3D | HSD-L3D (Lidar) | H3D-Flat | H3D-DSM | HSD-L3D (HSPC) | HSD-L3D (Canonical) | |
|---|---|---|---|---|---|---|
| Point Locations | Lidar | Lidar | HSPC | HSPC | HSPC | Canonical |
| Class Accuracy | ||||||
| building (57.4%) | 0.996 | 0.958 | 0.735 | 0.960 | 0.960 | 0.958 |
| vehicle path (15.7%) | 0.861 | 0.896 | 0.861 | 0.952 | 0.908 | 0.897 |
| human path (17.9%) | 0.528 | 0.431 | 0.271 | 0.386 | 0.415 | 0.430 |
| foliage (6.6%) | 0.413 | 0.635 | 0.911 | 0.723 | 0.550 | 0.629 |
| vehicle (2.4%) | 0.928 | 0.841 | 0.241 | 0.767 | 0.796 | 0.837 |
| Statistics | ||||||
| Precision | 0.8218 | 0.7636 | 0.6881 | 0.8396 | 0.7679 | 0.7640 |
| Recall | 0.7451 | 0.7520 | 0.6038 | 0.7579 | 0.7256 | 0.7500 |
| F-measure | 0.7632 | 0.7461 | 0.6009 | 0.7848 | 0.7317 | 0.7452 |
| IoU | 0.6461 | 0.6135 | 0.4676 | 0.6695 | 0.5960 | 0.6123 |
| Kappa | 0.7060 | 0.7478 | 0.6017 | 0.7875 | 0.7252 | 0.7462 |
| Balanced Accuracy | 0.7451 | 0.7520 | 0.6038 | 0.7579 | 0.7256 | 0.7500 |
| Pixel Accuracy | 0.8360 | 0.8536 | 0.7442 | 0.8744 | 0.8385 | 0.8525 |
| HSD-L3D | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| L3D | HSF | HSD | Lidar | Hyper | Canon | H2D [8] | H2D_L2D [8] | H2D_L3D [8] | Li [29] | |
| Class Accuracy | ||||||||||
| building | 0.997 | 0.735 | 0.960 | 0.959 | 0.960 | 0.959 | 0.918 | 0.992 | 0.897 | 0.899 |
| vehicle path | 0.855 | 0.861 | 0.952 | 0.891 | 0.908 | 0.877 | 0.695 | 0.840 | 0.863 | 0.720 |
| human path | 0.434 | 0.271 | 0.386 | 0.347 | 0.415 | 0.308 | 0.482 | 0.472 | 0.459 | 0.508 |
| foliage | 0.335 | 0.911 | 0.723 | 0.565 | 0.550 | 0.561 | 0.932 | 0.856 | 0.934 | 0.860 |
| vehicle | 0.876 | 0.241 | 0.767 | 0.758 | 0.796 | 0.756 | 0.415 | 0.946 | 0.385 | 0.863 |
| Statistics | ||||||||||
| Precision | 0.8198 | 0.6881 | 0.8396 | 0.7729 | 0.7679 | 0.7652 | 0.825 | 0.899 | 0.854 | - |
| Recall | 0.6994 | 0.6038 | 0.7579 | 0.7040 | 0.7256 | 0.6922 | 0.831 | 0.897 | 0.844 | - |
| F-measure | 0.7277 | 0.6009 | 0.7848 | 0.7178 | 0.7317 | 0.7064 | 0.825 | 0.894 | 0.842 | - |
| IoU | 0.6039 | 0.4676 | 0.6695 | 0.5799 | 0.5960 | 0.5686 | 0.720 | 0.830 | 0.745 | - |
| Kappa | 0.6742 | 0.6017 | 0.7875 | 0.7079 | 0.7252 | 0.6959 | 0.730 | 0.838 | 0.756 | - |
| Balanced Acc | 0.6994 | 0.6038 | 0.7579 | 0.7040 | 0.7256 | 0.6922 | 0.688 | 0.821 | 0.708 | 0.768 |
| Pixel Accuracy | 0.8078 | 0.7442 | 0.8744 | 0.8214 | 0.8385 | 0.8149 | 0.831 | 0.897 | 0.844 | 0.819 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Decker, K.T.; Borghetti, B.J. Hyperspectral Point Cloud Projection for the Semantic Segmentation of Multimodal Hyperspectral and Lidar Data with Point Convolution-Based Deep Fusion Neural Networks. Appl. Sci. 2023, 13, 8210. https://doi.org/10.3390/app13148210
Decker KT, Borghetti BJ. Hyperspectral Point Cloud Projection for the Semantic Segmentation of Multimodal Hyperspectral and Lidar Data with Point Convolution-Based Deep Fusion Neural Networks. Applied Sciences. 2023; 13(14):8210. https://doi.org/10.3390/app13148210
Chicago/Turabian StyleDecker, Kevin T., and Brett J. Borghetti. 2023. "Hyperspectral Point Cloud Projection for the Semantic Segmentation of Multimodal Hyperspectral and Lidar Data with Point Convolution-Based Deep Fusion Neural Networks" Applied Sciences 13, no. 14: 8210. https://doi.org/10.3390/app13148210