1. Introduction
Since their origins, video games and their associated industries have continued to evolve, limited only by developers’ creativity and cutting-edge technologies. These technological advances include artificial intelligence (AI), a growing field that began in the 1950s when Alan Turing questioned whether machines could think [
1].
It is known that computers do not think like humans but can use learning techniques to learn to perform tasks autonomously. This action is known as machine learning (ML), a category of AI that provides the ability to learn based on data (datasets) through various learning strategies to classify or predict outcomes by simulating human behavior before events occur [
2]. ML focuses on developing systems that collect data, identify patterns, and learn from different scenarios for decision making. For example, in the case of a video game, its behavior can be improved autonomously without explicit programming [
3,
4].
There are various approaches to ML, and deep learning (DL) is one of the most popular approaches. DL models differ from most ML methods in that human brain functions motivate their operation by mimicking neuronal networks. For this reason, artificial neural networks (ANNs) are described as a set of simple (often adaptive) segments interconnected in massive parallel and hierarchically organized to interact with real-world objects in the same way as the human nervous system. Therefore, DL is defined as a generalization of an ANN in which multiple hidden layers are used, meaning that more neurons are used to implement the model. Deep learning has been successfully applied in many domains [
5,
6], including gaming [
7].
Two essential and fundamental aspects of the video game industry are game development and user experience. The development of a game involves the technologies and platforms available to create the game, and the user experience is the tangible events perceived by the player supported by the overall game–player interaction, including how satisfactory the player experience is [
8].
The concept of flow [
9,
10], a psychological state in which individuals become fully engaged in an activity, experiencing a sense of control and enjoyment, plays a pivotal role in understanding player–game interaction dynamics. This state is closely associated with optimal experiences in gameplay, leading to increased player immersion, satisfaction, and, ultimately, retention [
11]. Thus, accounting for flow becomes crucial as it provides key insights into how to enhance the gaming experience, making it an integral part of our study. Cowley et al. [
12] described the relationship between the player and the game, characterized by learning and enjoyment during the game, which is fundamental for analyzing the player’s experience in front of a video game. They focus on improving the understanding of how gamers interact with games, thus providing valuable information to video game researchers who aim to design immersive games for every user.
As technology advances, video game players demand an increasing number of good user experiences (UX). Therefore, video game difficulty has become a valuable indicator to keep gamers engaged, as games that are easy for an expert gamer can become tedious, while games that are difficult for a novice player can frustrate them, and in both cases, the player will stop playing the game [
13]. Similarly, it has been found that once players understand the game pattern and discover their weaknesses, the video game is perceived as boring, uninteresting, and lacking in challenges [
14].
Therefore, according to the game flow, there is a natural relationship between the game’s difficulty and the player’s skill [
11]. This study proposes a deep learning-based approach to improve player engagement through two steps: (1) skill-based classification and (2) dynamic difficulty adjustment (DDA). Dynamic difficulty adjustment is a method that automatically modifies video game behavior and features in real-time based on a player’s skills [
7].
The main contribution of our work is twofold:
Implementing a dynamic difficulty adjustment system in a video game. This system classifies players in real-time based on their skill level, allowing difficulty adjustment that aligns with the player’s experience. In this way, the game provides challenges proportional to the players’ skills, improving their engagement and immersion.
Finally, our DL model was proven to be effective in improving the gaming experience and obtaining a high degree of accuracy in classifying the player’s skill level. This effectiveness leads to an improved personalized game experience, marking an important step forward in player-centered video game design.
2. Related Works
The application of DL techniques to dynamically adjust the complexity of video games has become an increasingly popular research topic in recent years. This approach seeks to enhance player engagement and enjoyment by creating an adaptive gaming experience that challenges players without overwhelming their skills or knowledge. In this section, we present some of the most relevant works in this area, ranging from using reinforcement learning algorithms to training intelligent agents in specific games to implementing neural networks that can learn from player metrics and dynamically adjust the difficulty level of the game.
Porssut et al. [
15] proposed an intelligent agent that trains a virtual reality (VR) engine using adaptive and reinforcement learning methods. The purpose of this engine is to adjust the visual effects of the response depending on the executed movements to improve the robot’s reactions, increase the participant’s performance limits, or correct their errors in the executions.
Comi [
16] discussed the use of artificial intelligence in video games using deep reinforced learning techniques. This article explains the techniques used to create an intelligent agent that can learn from its environment for the game Snake and achieve better results with each interaction with the game.
The creators of the video game Unreal Tournament
® [
17] allow open access to cognitive computing developers to create an intelligent agent that simulates the reactions that a human player could have. This opens many possibilities for the video game industry because they use accurate data to assist developers in the construction of new, more competitive, and, most importantly, different and adaptable games. In [
18], an intelligent agent was implemented in Unreal Tournament
® that can execute the shots and actions that a player can perform to learn from these events and surpass the player’s performance.
As described in [
19], intelligent agents contain FALCON, a neural network that exercises reinforcement learning, which measures the results as the game environment changes or makes real-time predictions for the acquisition of new and improved skills. It has been demonstrated that an intelligent agent constantly learns, and its learning scales with each iteration it passes through.
Ismail et al. [
20] showcase how reinforcement learning is implemented, evaluating its results and categorizing them into three primary motivations. The goal is to create intelligent agents that can be implemented as non-playable video game characters to identify and solve performance or maintenance tasks. Next, two new metrics are proposed to evaluate and compare agents using these methods to better describe and differentiate character behavior according to their motivation to learn different tasks. These metrics quantify the focus of attention and the duration of the agents’ stay. Finally, an empirical evaluation of reinforcement learning agents controlling characters in a simulated game scenario was conducted, comparing the effects of the three motivations on learning achievement and maintenance tasks.
In [
21], recent advances in DL were discussed in the context of how they have been applied to play different types of video games, such as first-person shooters, arcade games, and real-time strategy games. The unique requirements that different genres of games pose to a deep learning system are analyzed, and important open challenges are highlighted in the context of applying these machine learning methods to video games. These challenges include dealing with huge decision spaces, sparse rewards, difficulty alterations, and even the creation of new objectives.
3. Materials and Methods
This research consists of designing and developing a video game to evaluate whether dynamic complexity adjustment of a video game can be achieved by identifying a player’s skills using a deep learning model. This paper also reports on the design, training, and evaluation of the intelligent model and the assessment of the player’s experience.
A project-based methodology [
22] was used to develop this study. The methodology was as follows.
Design and create a video game to train and test the DL model;
Generate a dataset to train the model from the player event log;
Train and validate a DL model appropriate to the game design created;
Integrate the DL model in the video game;
Validate the user experience.
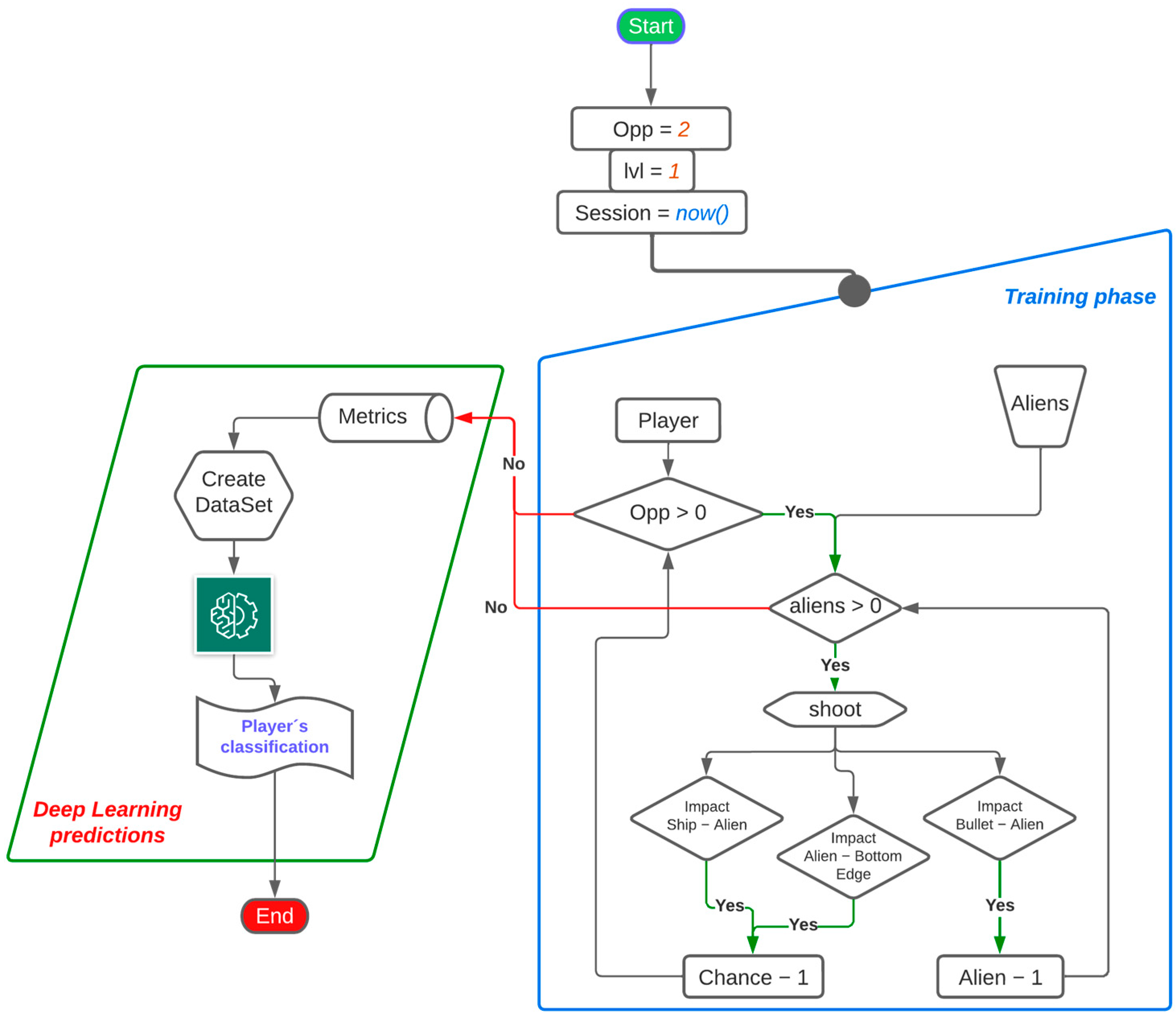
Figure 1 shows a flowchart of the general process of this methodology, in which we appreciate the integration of the training and learning phases of the DL model.
3.1. Astro the Video game
A game called Astro was developed (
Figure 2). It was inspired by the Space Invaders© [
23] video game, and its gameplay consists of the player controlling a spaceship and, during its journey, facing scenarios of alien ships blocking their path, which must be eliminated to continue with the next level of the game. Once the entire fleet of alien ships has been eliminated, the game displays the same number of alien ships on the screen, but with faster scrolling according to the level being played. Astro development was performed in Python programming language using the Pygame library [
24].
The functional requirements that Astro must meet are:
The player can control a spaceship and move on its four axes;
The game must create a fleet of enemy ships;
The player-controlled ship will have the ability to shoot at enemy ships;
Enemy ships can zigzag horizontally and vertically from the top of the screen to the bottom or collide with a player’s ship;
The player will have two opportunities to beat the game;
- a.
An opportunity is lost every time the player’s ship collides with an alien or the alien float reaches the bottom of the screen.
The game must end when the player’s opportunities have been finished;
The game must collect metrics and group them in a dataset per session.
3.2. Dataset Creation
Classifying a player’s abilities while playing the game requires data-driven DL model training.
It is necessary to first collect the necessary data for the training phase to utilize DL techniques to analyze player metrics. This process involves gathering information on various aspects of player behavior, including player movement, interactions with game objects, and the time spent in different areas of the game.
After analyzing the various variables and metrics that can be considered to classify a player in a video game like Astro, the following dataset (see
Table 1) was designed (variable names are mainly based on their Spanish name).
With the variable selection finished, we generated a dataset from 148 gaming sessions carried out by 56 players using Astro (see
Figure 3), with a total of 32,280 data records in the dataset.
Table 2 provides an overview of the players sampled to generate the dataset for the deep learning model to identify player levels in the video game. In addition, the table presents the players’ age ranges and number of players in each category.
The players were categorized based on their age ranges: adolescents (13–18 years old), young adults (19–25 years old), adults (26–59 years old), and seniors (above 59 years). The sample included 16 players in the “Adolescents” category, nine players in the “Young Adults” category, 28 players in the “Adults” category, and three players in the “Seniors” category.
Table 2 presents the age range and number of players in each category sampled to generate the dataset for the deep learning model. The table provides a quick and clear overview of the sample composition and insights into the age distribution of the players in the dataset.
3.3. Model Training
Once the player metrics have been recollected during the training phase, a model can be trained using DL techniques to apply it to the obtained metrics. Finally, the game should evaluate the events performed by the players and classify their level of familiarity with the game into three categories: beginner, intermediate, and expert. By categorizing players according to their expertise levels, gameplay mechanics can be adjusted to provide a better experience for all players.
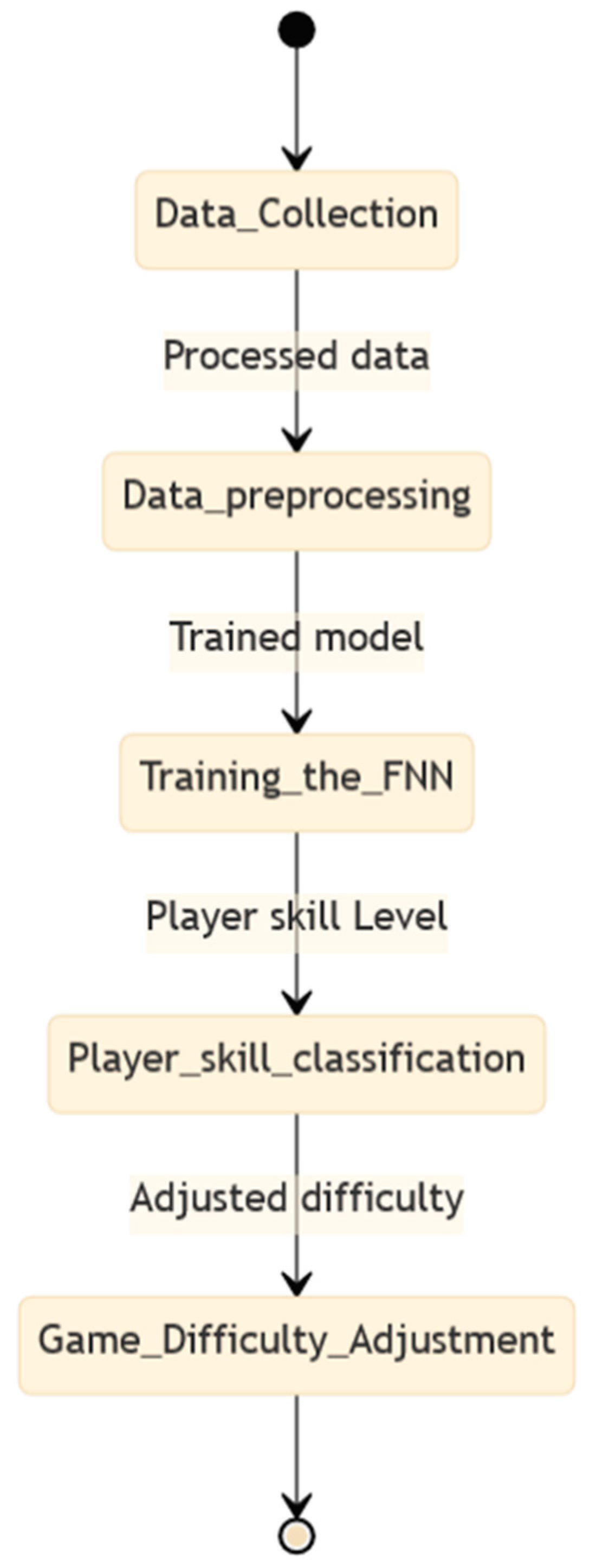
Figure 4 illustrates the process of utilizing DL techniques to analyze player metrics. This process is divided into three main paths.
Path 1 represents the traditional method for evaluating a player’s performance in a game scenario. First, the players’ performance metrics were measured, and the results were obtained based on these metrics.
Path 2 represents the data collection and training processes. First, the player plays the scenario, and the performance metrics are collected to create a dataset. The dataset was then used to train a deep learning model. Finally, model evaluation was conducted, and if the model performance was satisfactory, it was compiled and used for further analysis.
Path 3 represents an alternative approach when model evaluation results are unsatisfactory. In this case, technical analysis was conducted to identify the shortcomings of the model. The dataset was then further refined based on this analysis, and the model training and evaluation process was repeated until satisfactory results were obtained. The compiled model was then used for further analysis.
The process involves data collection, model training, and evaluation, and may require multiple iterations to achieve satisfactory results.
Deep learning has shown great potential for creating models that can adapt to the changing skill levels of players in a game. By analyzing player metrics, such as the bullet number in contact with an alien, accuracy, and game progress, neural nodes can be trained to dynamically adjust the complexity of the game to enhance the player’s experience and provide a personalized gameplay experience that caters to the individual’s skill level.
Once the model is validated, it must be implemented in a game.
Figure 5 illustrates how integrating the trained model into Astro expedites the game level adjustment process. The diagram begins with the initial level of the game.
As the player proceeded through the game scenario from the initial game level, their performance metrics were recorded. If the player completes the scenario successfully, the process advances to the “Scenario completed (Yes)” point.
At this juncture, the trained model leveraged the player’s performance metrics to calibrate the game level. Subsequently, the game presents an adjusted game level scenario for the player, and the performance metrics are measured again. If a player succeeds in the scenario, the model further tailors the game level. This cycle continues until the player can no longer complete the scenario, and the process proceeds to the “Scenario completed (No)” point.
The game level adjustment process concludes by presenting the outcomes to players. Finally, the player can restart or finalize the game.
Scatter plots were generated for each attribute in the original dataset (
Figure 6). Notably, patterns emerged concerning the precision of players’ ship movement events. The relationship between the main attributes of the dataset can be observed in the case of collisions (
hit), where a linear relationship with the rest of the attributes can be identified in the central column. However, for the level (
lvl) in the right column of the same Figure, a discernible pattern that would allow us to prioritize the attribute cannot be identified.
3.4. Model Validation
The model was developed in Python running TensorFlow, Scikit-learn, and other libraries, such as NumPy, Matplotlib, and Pandas.
A confusion matrix [
25] was generated to analyze how our FFN algorithm works.
Figure 7 shows the confusion matrix.
A confusion matrix is a performance measurement tool used in machine learning to evaluate the accuracy of a classification model. This helps us visualize the true positive, true negative, false positive, and false negative predictions of the model [
26]. In this case, the confusion matrix helped to identify the input and output attributes for generating the deep learning model. For example, it revealed a strong correlation between the number of shots and the level of execution, as well as the movements of the player’s ship with the collision attribute. Furthermore, by analyzing the confusion matrix, we identified the attributes that were most influential in predicting the outcome, allowing us to choose the most relevant attributes to be used in developing the deep learning model.
We used a Feedforward Neural Network (FNN) architecture [
27] because the connections between the nodes do not create a cycle, allowing the data flow from their input to move through the hidden layers until they reach the output node. This prevents a cycle from occurring between nodes; that is, information flows in one direction from the input layer through several hidden layers to the output layer.
An FNN is useful in supervised learning [
28], where there is a set of input data and its corresponding expected output. The network is trained to learn the relationship between the inputs and outputs by adjusting the weights and biases of the neurons in the hidden layers of the network. Once the network has been trained, it can predict the output of the new inputs.
One of the advantages of the FNN architecture is that it can be trained to solve a wide variety of problems, from classification to regression. It can also handle data with multiple features, meaning that it can work with complex and high-dimensional datasets [
29].
The complexity of the Feedforward Neural Network (FNN) used in our study contributes to the robustness and adaptability of the system, enabling it to handle a variety of players and skill levels. The multilayered structure of the FNN, combined with its ability to learn from and adapt to new data, allows the system to analyze a wide range of player skills in-depth [
30]. By discerning complex patterns within the gameplay data, our system can accurately adjust game difficulty to enhance player engagement and satisfaction. Our analysis demonstrates the equilibrium we achieved between system complexity and its ability to accommodate various player skill levels.
However, the FNN architecture has certain disadvantages. One of these is that it can be prone to overfitting, which means that the network can learn to fit too closely to the training data and cannot generalize well to new data. Additionally, training the network requires intensive data and computation [
31].
In summary, the FNN architecture is a powerful machine learning tool that is used in a wide variety of applications. Although it has some disadvantages, its ability to handle complex data and solve classification and regression problems makes it a valuable tool for data scientists and machine learning engineers.
These advantages fit our sequential model process since the recording of the game sessions is performed every time the player makes a shot; therefore, the obtained metrics depend on the previous metrics to perform their classification. It has 13 main input attributes and 64 unique enemy ship identifiers. The main attributes are mentioned in the previous metric collection section of this document with a ReLU activation function. This layer is considered the input layer in a neural network [
32].
The next hidden layer of the network consisted of eight states with softmax activation. Finally, three result attributes were identified in the last layer using a sigmoid activation function. Finally, the model was compiled with the instruction to perform a binary cross-entropy algorithm with the Adam optimizer.
Model validation, which enables the classification of the video gamer level, reveals a high degree of accuracy in both the training and validation phases. The results demonstrated a precision of 99.6% in the training phase and 99.83% in the validation phase. These findings suggest that the Feedforward Neural Network architecture used in this study is highly effective in accurately classifying the level of a video gamer.
The high accuracy achieved by the model in this study can be attributed to the ability of Feedforward Neural Networks to learn complex patterns and relationships within the data. During the training phase, the network adjusts the weights of its connections to minimize the difference between the predicted and actual outputs. This learning process continues until the network can accurately classify new data.
The deep learning model’s predictions are represented by ranges from 0 to 2 and divided into three distinct categories based on the player’s level of expertise. A prediction of 0 indicates that the player has a high level of experience in the game, whereas a prediction of 1 suggests an intermediate level of experience. Finally, a prediction of 2 indicated that the player had a low level of experience in the game.
Dynamic difficulty adjustment (DDA) was developed with this deep learning model to adjust game difficulty based on player performance. When the model classifies the player as having a high level of experience (0), the game difficulty increases by 3. When a player is classified as having an intermediate experience level (1), the game difficulty increases by 1. Conversely, when the player is classified as having a low level of experience (2), the game difficulty is decreased by one, allowing for the dynamic adjustment of game complexity based on the player’s detected level. This approach to DDA has significant implications for game design as it creates personalized and challenging gaming experiences that can adapt to the player’s skill level in real-time. Furthermore, this approach can enhance player engagement and satisfaction by providing a more immersive and enjoyable gaming experience.
To validate the player engagement through DDA and adjust the game difficulty in real-time based on the player’s performance, we conducted a user experience evaluation. The following section presents a study with users to evaluate the effectiveness of DDA in enhancing player engagement in the video game, Astro. The evaluation aimed to investigate how the DDA algorithm adapts to a player’s skill level and affects the game experience. The findings of this study provide insights into the potential of DDA to improve player engagement and inform the development of future games.
Finally,
Figure 8 presents a flowchart to illustrate our research framework visually. This diagram offers readers a quick overview of the research process.
4. Evaluation
To validate whether the dynamic adjustment of game complexity improves engagement in video game players, a gameplay experience evaluation was conducted. Ten undergraduate students, who were convenience sampled based on availability, participated in the evaluation (see
Figure 9).
The average age of the participants was 20 years (min. 20, max. 22). All participants mentioned that they were video game players, with 60% identifying themselves as casual players and 40% as experienced players. The most commonly used platforms were PC (90%), laptops (60%), and consoles (30%).
4.1. Procedure
A two-hour evaluation was conducted, consisting of four stages [
33,
34]. During Stage 1 of the evaluation, the participants were given a brief explanation of the objectives and goals of the evaluation as well as an overview of the features and mechanics of Astro. This was done to provide context and establish expectations for the rest of the evaluation.
In Stage 2, the participants were given a live demonstration of Astro, where they were shown how to navigate the game’s menus, use the controls, and interact with various game elements. Again, this ensured that the participants understood how to play the game.
In Stage 3, the participants played through the entire Astro scenario, which involved completing various tasks and challenges while navigating at different levels. This stage aimed to assess how well the participants could engage with the game and how well they could perform under the different levels of complexity assigned by the deep learning model.
Finally, in Stage 4, participants were asked to complete a survey regarding their experience with the video game. The survey included questions about their level of engagement, enjoyment, and satisfaction with the game, and their opinions on the level of challenge and complexity presented by the game. The instrument was based on two validated instruments [
35,
36] and can be found in
Appendix A. These data were collected and analyzed to determine the overall effectiveness of the dynamic complexity adjustment feature in improving player engagement and satisfaction.
4.2. Results
Most participants enjoyed playing the game based on the survey responses. Most participants (8 out of 10) rated their enjoyment of the game as 4 out of 5, -1 (less enjoyment) and 5 (most enjoyment); however, the remaining two participants rated their enjoyment as 3 out of 5. This result suggests that most players found the game enjoyable, but not everyone found it to be equally engaging.
The participants’ responses varied more regarding the difficulty of the game, with scores ranging from 4 to 9 on a 10-point scale, 1 (too easy) and 10 (too hard). Most participants rated the game as moderately challenging, with 50% of the players giving scores ranging from four to six. However, one participant scored nine, suggesting that they found the game challenging. This suggests that the game is relatively easy for most players.
Regarding the self-perception of performance in the game, the results of the question were primarily negative, with 60% of players rating their performance below the average as < 5 out of 10 on the scale where one is very bad and ten is awesome. This result could indicate that the players found the game challenging and struggled to perform well. On the other hand, the remaining 40% rated their performance in a range from 6 to 10, indicating that they found the game more manageable than other players.
The survey also validates the player’s flow experience (see
Figure 10).
The results showed that playing Astro provided a flow experience to most participants, with 90% of the players reporting high levels of enjoyment, interest, and immersion in the game. Furthermore, all the participants felt in control of their actions and knew what to do during the gaming activity, indicating a high level of competence.
Interestingly, the participants’ responses were divided according to their feeling of time passing fast during the activity, with 70% agreeing and 30% disagreeing.
Overall, this result suggests that the dynamic adjustment of game complexity in Astro provided a flow experience to most participants, which is a positive outcome in this research project because we validated the flow experience of the player.
Finally, participants were asked about their self-perception of the dynamic adjustment of complexity. Seventy percent of the participants mentioned that they noticed some sort of complexity adjustment, while the remaining 30% did not. This result suggests that a significant majority of the participants noticed the dynamic adjustment of complexity in Astro, implying that the game provided a challenging and stimulating experience. Those who noticed the complexity adjustment were asked if they believed the adjustment affected their performance. Responses were on a scale of 1 to 10, where 1 was “Very bad” and 10 was “Wonderful.” A total of 29% believed that their performance was moderately affected, while 71% responded in the range of six to nine. This indicates that they perceived the dynamic adjustment of complexity in Astro to be favorable for their game experience, indicating that the game’s adaptive difficulty was effective in enhancing their experience. This confirms that incorporating dynamic complexity adjustment in game design can improve player satisfaction and enjoyment, showing that the intelligent model successfully classifies players into skill levels and leads to improved player engagement and satisfaction.
Four game sessions were randomly selected for analysis and discussion to demonstrate how the model adjusted difficulty and levels.
Table 3 shows that the FNN model can effectively adjust the difficulty of a game session. In most cases, players advanced to higher levels, demonstrating that FNN achieved a balance between challenge and accessibility.
In session 1, for example, the player started at Level 1 and advanced to Level 12. The model adjusted the difficulty so that the player experienced a progression of skill, ending up in the beginner category with an accuracy of 62.39%. In Session 2, the player also started at Level 1 but progressed to Level 16, finishing in the intermediate category with an accuracy of 65.60%.
This result suggests that the FNN model effectively matches the players’ abilities, allowing them to experience progression and maintain a high level of engagement. However, it is important to note that the model not only adjusts the difficulty upwards but can also decrease the difficulty if the player’s performance drops, ensuring that the game remains accessible and challenging.
Finally, the possibility of a placebo effect in the players’ knowledge that the system can adjust difficulty is evident, but further analysis is required to confirm this hypothesis.
5. Discussion
While the Feedforward Neural Network (FNN) used in this study demonstrated high precision in the training and validation phases, the inherent randomness in neural network algorithms may still introduce some uncertainty. Cross-validation can help manage this uncertainty and provide a more robust estimation of model performance. Cross-validation involves:
Partitioning the dataset into several subsets or folds;
Training the model on most of these folds;
Testing the model’s performance on the remaining fold.
This process is repeated with different folds serving as the test set each time, ensuring that the performance of the model is assessed on various subsets of data.
For instance, one cross-validation method involves splitting the dataset into ten parts. The model is trained on nine parts; the remaining part is used for validation. This process is repeated ten times, each part being used for training and validation. The results are then averaged to provide a more accurate estimate of the model’s performance. Cross-validation can also help determine if the model is overfitting the training data, which is important when using complex models like FNNs. This method provides a better understanding of the model’s ability to classify player skill levels and reliability.
In terms of development challenges, we can highlight the following:
Data quality and availability: In the context of our project, the performance of the FNN relies heavily on the amount and diversity of the gameplay data it is trained on. Accumulating relevant, high-quality data representing diverse gameplay styles, skill levels, and game situations is a substantial challenge.
Hyperparameter tuning: The performance of our model depends significantly on the precise tuning of various hyperparameters, including the number of hidden layers, neurons in these layers, and the learning rate. Determining the optimal values of these parameters requires multiple trial-and-error runs.
6. Conclusions
The results of this study suggest that the use of the DL approach can be an effective strategy for generating a skill-based classification of players. This classification can personalize the gaming experience and improve player engagement. Furthermore, game developers can provide different challenges to players by understanding their expertise based on their skills, leading to a more tailored experience.
The results of this study indicate that incorporating dynamic complexity adjustment into game design can enhance player satisfaction and enjoyment. The intelligent model trained with DL effectively adapted the game’s difficulty level to the player’s skill level, leading to a more challenging and engaging game experience. In addition, players who found the game challenging and stimulating were likelier to rate their performance better, leading to a more satisfying experience. Moreover, incorporating dynamic complexity adjustment could lead to better retention rates, as players are more likely to continue playing a game that adapts to their skill level rather than one that is too easy or difficult.
However, this study also revealed that not all players might find the game equally engaging, and some may struggle with the difficulty level. Therefore, further research could investigate ways to adjust the game difficulty for individual players based on their performance to optimize their gaming experience.
Overall, this study’s results suggest that DL’s use of classifying players based on their skills and incorporating dynamic complexity adjustment into game design could lead to a more engaging and satisfying game experience for players. These findings have significant implications for game developers and could lead to more personalized and challenging games that appeal to a broader range of players.
7. Limitations and Future Works
Although our research findings are promising, we acknowledge certain limitations in our study that require further exploration in future research. The data to train and validate the deep learning model was limited to one game. Given the diversity of gameplay mechanics, styles, and player interactions across various games, it is not possible to acknowledge the model’s generalizability.
Furthermore, a player’s skill level may not match their preferred game difficulty. For instance, highly skilled players might opt for an easier gaming experience, whereas less-skilled players may seek challenges beyond their current abilities. Future research could explore mechanisms that account for player preferences when adjusting game difficulty to achieve a more personalized gaming experience.
In addition, our current system adjusts the difficulty level based on skill classification only once a game session is concluded. This method must be revised to adjust for real-time player skills and engagement fluctuations during a gaming session.
We must consider the computational complexity of our deep learning model, which may impose constraints on its practical implementation, particularly in environments with limited resources. Future research could leverage more computationally efficient models or optimization techniques to address complexity. The goal is to reduce the computational load while ensuring that the model’s accuracy in classifying player skill and adjusting game difficulty remains uncompromised.
The study did not present an evaluation with a control group in which the DL model is not utilized during gameplay. By comparing the standard gameplay of Astro with the gameplay featuring complexity adjustment, it would be possible to determine whether there were statistically significant differences in the gaming experience between the two conditions.
Moreover, there is a need to delve deeper into players’ perceptions of the complexity adjustment mechanism. Understanding how players perceive and react to dynamic difficulty adjustments can provide valuable insight into their subjective experiences and emotional responses. This exploration can shed light on the factors contributing to player motivation, self-evaluation, and overall enjoyment of the gaming experience.
Additionally, an analysis to explore potential gender differences in reactions and responses would allow for developing more inclusive and tailored approaches to game design and difficulty adjustment.
Our goal is to enhance the effectiveness and practicality of dynamic game difficulty adjustment systems by recognizing our limitations and developing strategies to overcome them. By doing so, we aim to improve the overall gaming experience and increase player engagement and satisfaction in the industry.



 ,
, 









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}