
Root Dilaceration Using Deep Learning: A Diagnostic Approach


Abstract
:Featured Application
Abstract
1. Introduction
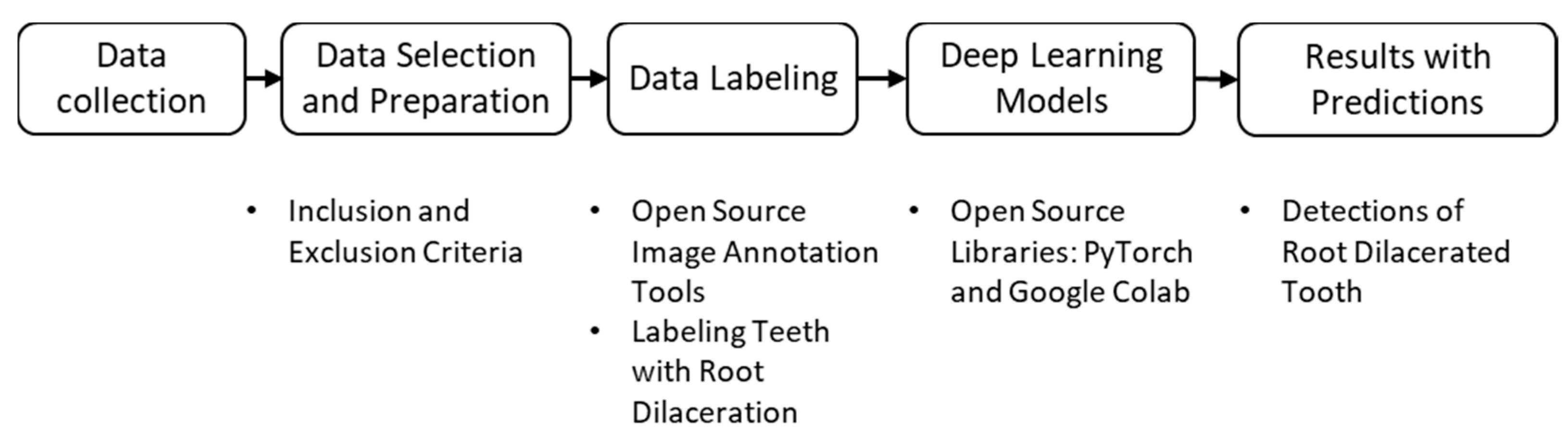
2. Materials and Methods
2.1. Object Detection and Detectors
2.2. Evaluation Criteria
3. Results
4. Discussion
- Early Detection: Deep learning models can identify root dilacerations at an early stage even if the patient is not there for a root dilaceration-related case, which allows clinicians to promptly intervene and implement appropriate treatment strategies. Early detection may prevent further complications, such as tooth impaction, misalignment, or delayed eruption;
- Accurate Diagnosis: Deep learning algorithms can aid in accurately diagnosing root dilacerations with high performance. This can reduce the risk of misinterpretation or missed diagnoses, ensuring that patients receive timely and accurate treatment;
- Treatment Planning: The detection of root dilacerations through deep learning can significantly influence treatment planning decisions. Clinicians can better anticipate the complexity and challenges associated with these conditions, leading to more informed treatment plans, including orthodontic interventions, surgical approaches, or alternative treatment options.
- Enhanced Patient Care: By leveraging deep learning technology, clinicians can deliver more personalized and tailored care to patients with root dilacerations. This can lead to improved patient satisfaction, reduced treatment time, and enhanced treatment outcomes.
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Ahmed, H.M.A.; Dummer, P.M.H. A new system for classifying tooth, root and canal anomalies. Int. Endod. J. 2018, 51, 389–404. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Tomes, J. A Course of Lectures on Dental Physiology and Surgery, Delivered at the Middlesex Hospital School. Am. J. Dent. Sci. 1848, 8, 120–147. [Google Scholar] [PubMed]
- Jafarzadeh, H.; Abbott, P.V. Dilaceration: Review of an endodontic challenge. J. Endod. 2007, 33, 1025–1030. [Google Scholar] [CrossRef] [PubMed]
- Topouzelis, N.; Tsaousoglou, P.; Pisoka, V.; Zouloumis, L. Dilaceration of maxillary central incisor: A literature review. Dent. Traumatol. 2010, 26, 335–341. [Google Scholar] [CrossRef] [PubMed]
- Chohayeb, A.A. Dilaceration of Permanent Upper Lateral Incisors—Frequency, Direction, and Endodontic Treatment Implications. Oral Surg. Oral Med. Oral Pathol. 1983, 55, 519–520. [Google Scholar] [CrossRef] [PubMed]
- Hamasha, A.A.; Al-Khateeb, T.; Darwazeh, A. Prevalence of dilaceration in Jordanian adults. Int. Endod. J. 2002, 35, 910–912. [Google Scholar] [CrossRef]
- Tanaka, E.; Hasegawa, T.; Hanaoka, K.; Yoneno, K.; Matsumoto, E.; Dalla-Bona, D.; Yamano, E.; Suekawa, Y.; Watanabe, M.; Tanne, K. Severe crowding and a dilacerated maxillary central incisor in an adolescent. Angle Orthod. 2006, 76, 510–518. [Google Scholar]
- Caeiro-Villasenin, L.; Serna-Munoz, C.; Perez-Silva, A.; Vicente-Hernandez, A.; Poza-Pascual, A.; Ortiz-Ruiz, A.J. Developmental Dental Defects in Permanent Teeth Resulting from Trauma in Primary Dentition: A Systematic Review. Int. J. Environ. Res. Public Health 2022, 19, 754. [Google Scholar] [CrossRef]
- Malcic, A.; Jukic Krmek, S.; Brzovic, V.; Miletic, I.; Pelivan, I.; Anic, I. Prevalence of root dilaceration in adult dental patients in Croatia. Oral Surg. Oral Med. Oral Pathol. Oral Radiol. Endodontol. 2006, 102, 104–109. [Google Scholar] [CrossRef]
- Ledesma-Montes, C.; Hernandez-Guerrero, J.; Jimenez-Farfan, M. Frequency of dilaceration in a mexican school-based population. J. Clin. Exp. Dent. 2018, 10, e665–e667. [Google Scholar] [CrossRef]
- Gurbuz, O.; Ersen, A.; Dikmen, B.; Gumustas, B.; Gundogar, M. The prevalence and distribution of the dental anomalies in the Turkish population. J. Anat. Soc. India 2019, 68, 46–51. [Google Scholar] [CrossRef]
- Haghanifar, S.; Moudi, E.; Abesi, F.; Kheirkhah, F.; Arbabzadegan, N.; Bijani, A. Radiographic Evaluation of Dental Anomaly Prevalence in a Selected Iranian Population. J. Dent. 2019, 20, 90–94. [Google Scholar] [CrossRef]
- Cao, D.; Shao, B.; Izadikhah, I.; Xie, L.; Wu, B.; Li, H.; Yan, B. Root dilaceration in maxillary impacted canines and adjacent teeth: A retrospective analysis of the difference between buccal and palatal impaction. Am. J. Orthod. Dentofac. Orthop. 2021, 159, 167–174. [Google Scholar] [CrossRef] [PubMed]
- Asheghi, B.; Sahebi, S.; Zangooei Booshehri, M.; Sheybanifard, F. Evaluation of Root Dilaceration by Cone Beam Computed Tomography in Iranian South Subpopulation: Permanent Molars. J. Dent. 2022, 23, 369–376. [Google Scholar] [CrossRef]
- Luke, A.M.; Kassem, R.K.; Dehghani, S.N.; Mathew, S.; Shetty, K.; Ali, I.K.; Pawar, A.M. Prevalence of Dental Developmental Anomalies in Patients Attending a Faculty of Dentistry in Ajman, United Arab Emirates. Pesqui. Bras. Odontopediatr. 2017, 17, 1–5. [Google Scholar] [CrossRef]
- Bilge, N.H.; Yesiltepe, S.; Agirman, K.T.; Caglayan, F.; Bilge, O.M. Investigation of prevalence of dental anomalies by using digital panoramic radiographs. Folia Morphol. 2018, 77, 323–328. [Google Scholar] [CrossRef] [Green Version]
- Goswami, M.; Bhardwaj, S.; Grewal, N. Prevalence of Shape-related Developmental Dental Anomalies in India: A Retrospective Study. Int. J. Clin. Pediatr. Dent. 2020, 13, 407–411. [Google Scholar] [CrossRef]
- Schneider, S.W. A comparison of canal preparations in straight and curved root canals. Oral Surg. Oral Med. Oral Pathol. 1971, 32, 271–275. [Google Scholar] [CrossRef]
- Chen, H.; Zhang, K.L.; Lyu, P.J.; Li, H.; Zhang, L.D.; Wu, J.; Lee, C.H. A deep learning approach to automatic teeth detection and numbering based on object detection in dental periapical films. Sci. Rep. 2019, 9, 3840. [Google Scholar] [CrossRef] [Green Version]
- Hiraiwa, T.; Ariji, Y.; Fukuda, M.; Kise, Y.; Nakata, K.; Katsumata, A.; Fujita, H.; Ariji, E. A deep-learning artificial intelligence system for assessment of root morphology of the mandibular first molar on panoramic radiography. Dentomaxillofac. Radiol. 2019, 48, 20180218. [Google Scholar] [CrossRef]
- Tuzoff, D.V.; Tuzova, L.N.; Bornstein, M.M.; Krasnov, A.S.; Kharchenko, M.A.; Nikolenko, S.I.; Sveshnikov, M.M.; Bednenko, G.B. Tooth detection and numbering in panoramic radiographs using convolutional neural networks. Dentomaxillofac. Radiol. 2019, 48, 20180051. [Google Scholar] [CrossRef]
- Chang, H.J.; Lee, S.J.; Yong, T.H.; Shin, N.Y.; Jang, B.G.; Kim, J.E.; Huh, K.H.; Lee, S.S.; Heo, M.S.; Choi, S.C.; et al. Deep Learning Hybrid Method to Automatically Diagnose Periodontal Bone Loss and Stage Periodontitis. Sci. Rep. 2020, 10, 7531. [Google Scholar] [CrossRef]
- Carrillo-Perez, F.; Pecho, O.E.; Morales, J.C.; Paravina, R.D.; Della Bona, A.; Ghinea, R.; Pulgar, R.; Perez, M.D.; Herrera, L.J. Applications of artificial intelligence in dentistry: A comprehensive review. J. Esthet. Restor. Dent. 2022, 34, 259–280. [Google Scholar] [CrossRef]
- Celik, B.; Celik, M.E. Automated detection of dental restorations using deep learning on panoramic radiographs. Dentomaxillofac. Radiol. 2022, 51, 20220244. [Google Scholar] [CrossRef] [PubMed]
- Celik, M.E. Deep Learning Based Detection Tool for Impacted Mandibular Third Molar Teeth. Diagnostics 2022, 12, 942. [Google Scholar] [CrossRef]
- Cai, Z.W.; Vasconcelos, N. Cascade R-CNN: Delving into High Quality Object Detection. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 6154–6162. [Google Scholar] [CrossRef] [Green Version]
- Ren, S.Q.; He, K.M.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. In Proceedings of the Advances in Neural Information Processing Systems 28: Annual Conference on Neural Information Processing Systems 2015, Montreal, QC, Canada, 7–12 December 2015. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.M.; Dollar, P. Focal Loss for Dense Object Detection. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2999–3007. [Google Scholar] [CrossRef] [Green Version]
- Joseph Redmon, A.F. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. Lect. Notes Comput. Sci. 2016, 9905, 21–37. [Google Scholar] [CrossRef] [Green Version]
- Pang, J.M.; Chen, K.; Shi, J.P.; Feng, H.J.; Ouyang, W.L.; Lin, D.H. Libra R-CNN: Towards Balanced Learning for Object Detection. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR 2019), Long Beach, CA, USA, 15–20 June 2019; pp. 821–830. [Google Scholar] [CrossRef] [Green Version]
- Dai, J.F.; Qi, H.Z.; Xiong, Y.W.; Li, Y.; Zhang, G.D.; Hu, H.; Wei, Y.C. Deformable Convolutional Networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22 October 2017; pp. 764–773. [Google Scholar] [CrossRef] [Green Version]
- Qiao, S.Y.; Chen, L.C.; Yuille, A. DetectoRS: Detecting Objects with Recursive Feature Pyramid and Switchable Atrous Convolution. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2021, Nashville, TN, USA, 20–25 June 2021; pp. 10208–10219. [Google Scholar] [CrossRef]
- Zhang, H.; Chang, H.; Ma, B.; Wang, N.; Chen, X. Dynamic R-CNN: Towards High Quality Object Detection via Dynamic Training. arXiv 2020, arXiv:2004.06002. [Google Scholar]
- Ghiasi, G.; Lin, T.Y.; Le, Q.V. NAS-FPN: Learning Scalable Feature Pyramid Architecture for Object Detection. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR 2019), Long Beach, CA, USA, 15–20 June 2019; pp. 7029–7038. [Google Scholar] [CrossRef] [Green Version]
- Lu, X.; Li, B.Y.; Yue, Y.X.; Li, Q.Q.; Yan, J.J. Grid R-CNN. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR 2019), Long Beach, CA, USA, 15–20 June 2019; pp. 7355–7364. [Google Scholar] [CrossRef]
- Chen, K.; Pang, J.M.; Wang, J.Q.; Xiong, Y.; Li, X.X.; Sun, S.Y.; Feng, W.S.; Liu, Z.W.; Shi, J.P.; Ouyang, W.L.; et al. Hybrid Task Cascade for Instance Segmentation. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR 2019), Long Beach, CA, USA, 15–20 June 2019; pp. 4969–4978. [Google Scholar] [CrossRef] [Green Version]
- Qiao, S.; Wang, H.; Liu, C.; Shen, W.; Yuille, A. Micro-Batch Training with Batch-Channel Normalization and Weight Standardization. arXiv 2020, arXiv:1903.10520. [Google Scholar]
- Zhang, X.S.; Wan, F.; Liu, C.; Ji, R.R.; Ye, Q.X. FreeAnchor: Learning to Match Anchors for Visual Object Detection. In Proceedings of the Advances in Neural Information Processing Systems 32 (Nips 2019), Vancouver, BC, Canada, 8–14 December 2019; Volume 32. [Google Scholar]
- Tian, Z.; Shen, C.H.; Chen, H.; He, T. FCOS: Fully Convolutional One-Stage Object Detection. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV 2019), Seoul, Republic of Korea, 27–28 October 2019; pp. 9626–9635. [Google Scholar] [CrossRef] [Green Version]
- Zhang, S.; Chi, C.; Yao, Y.; Lei, Z.; Li, S.Z. Bridging the Gap Between Anchor-based and Anchor-free Detection via Adaptive Training Sample Selection. arXiv 2020, arXiv:1912.02424. [Google Scholar]
- Kong, T.; Sun, F.C.; Liu, H.P.; Jiang, Y.N.; Li, L.; Shi, J.B. FoveaBox: Beyound Anchor-Based Object Detection. IEEE Trans. Image Process. 2020, 29, 7389–7398. [Google Scholar] [CrossRef]
- Wang, J.; Zhang, W.; Cao, Y.; Chen, K.; Pang, J.; Gong, T.; Shi, J.; Loy, C.C.; Lin, D. Side-Aware Boundary Localization for More Precise Object Detection. arXiv 2020, arXiv:1912.04260. [Google Scholar]
- Nardi, C.; Talamonti, C.; Pallotta, S.; Saletti, P.; Calistri, L.; Cordopatri, C.; Colagrande, S. Head and neck effective dose and quantitative assessment of image quality: A study to compare cone beam CT and multislice spiral CT. Dentomaxillofac. Radiol. 2017, 46, 20170030. [Google Scholar] [CrossRef] [PubMed]
- Nardi, C.; Calistri, L.; Grazzini, G.; Desideri, I.; Lorini, C.; Occhipinti, M.; Mungai, F.; Colagrande, S. Is Panoramic Radiography an Accurate Imaging Technique for the Detection of Endodontically Treated Asymptomatic Apical Periodontitis? J. Endod. 2018, 44, 1500–1508. [Google Scholar] [CrossRef]
- Lee, S.; Kim, D.; Jeong, H.G. Detecting 17 fine-grained dental anomalies from panoramic dental radiography using artificial intelligence. Sci. Rep. 2022, 12, 5172. [Google Scholar] [CrossRef]
- Welk, J. Prediction of Canine Eruption Problems and Other Developmental Anomalies in Panoramic Radiographs Using Machine Learning. Master’s Thesis, The University of Iowa, Iowa City, IA, USA, 2021. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Precision | |
| Recall (sensitivity) | |
| Accuracy | |
| F1 Score |
| Average Precision | Mean Average Precision for n-Classes |
|---|---|
| Detector—Backbone | mAP | A | P | R | F1 Score | T-Time |
|---|---|---|---|---|---|---|
| Cascade RCNN Resnet101 | 0.9 | 0.72 | 0.83 | 0.84 | 0.83 | 5 h-28 m |
| Faster RCNN Resnet101 | 0.84 | 0.62 | 0.91 | 0.66 | 0.77 | 4 h-11 m |
| RetinaNet Resnet50 | 0.89 | 0.72 | 0.9 | 0.78 | 0.83 | 2 h-54 m |
| Yolov3 DarkNet53 | 0.87 | 0.63 | 0.72 | 0.82 | 0.77 | 2 h-38 m |
| SSD | 0.68 | 0.48 | 0.66 | 0.65 | 0.65 | 3 h-31 m |
| RegNetx | 0.85 | 0.69 | 0.77 | 0.86 | 0.82 | 4 h-15 m |
| Libra RCNN Resnext101 | 0.87 | 0.67 | 0.91 | 0.72 | 0.80 | 16 h-02 m |
| Deformable CNs | 0.83 | 0.62 | 0.76 | 0.77 | 0.76 | 8 h-52 m |
| DetectoRS Resnet50 | 0.83 | 0.64 | 0.83 | 0.74 | 0.78 | 13 h-55 m |
| Dynamic RCNN Resnet50 | 0.87 | 0.7 | 0.83 | 0.81 | 0.82 | 3 h-13 m |
| NAS FPN | 0.85 | 0.69 | 0.88 | 0.76 | 0.81 | 2 h-32 m |
| Grid RCNN Resnext101 | 0.83 | 0.64 | 0.77 | 0.79 | 0.78 | 12 h-33 m |
| HTC RCNN Resnext101 | 0.89 | 0.67 | 0.79 | 0.81 | 0.80 | 11 h-00 m |
| Faster RCNN with WS BCN | 0.85 | 0.64 | 0.71 | 0.87 | 0.78 | 3 h-47 m |
| FreeAnchor Resnet50 | 0.92 | 0.56 | 0.91 | 0.59 | 0.72 | 3 h-7 m |
| FCOS Resnet50 Caffe | 0.89 | 0.62 | 0.72 | 0.81 | 0.76 | 7 h-31 m |
| ATSS Resnet101 | 0.92 | 0.66 | 0.81 | 0.78 | 0.8 | 7 h-14 m |
| FoveaBox | 0.89 | 0.69 | 0.88 | 0.76 | 0.81 | 4 h-36 m |
| SABL | 0.88 | 0.63 | 0.84 | 0.71 | 0.77 | 7 h-00 m |
| Author | Task | Type of Image | Model | Data Size | Metrics |
|---|---|---|---|---|---|
| Lee et al. | Detection—dental anomaly | Panoramic | Faster RCNN | 23,000 | Precision: between 42–74% Sensitivity: between 27–100% Specificity: between 89–99% |
| Welk | Classification—dental anomaly | Panoramic | ResNet-18 VGG11 ResNet-50 VGG16 Inception v2 Inception v3 | 1964 | Sensitivity (recall): 0.47 Specificity: 0.59 F1 score: 0.28 Accuracy: 0.57 |
| This work | Detection | Panoramic | 19 Deep Learning Models | 636 | mAP Accuracy Precision Recall F1 Score Time Duration |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Çelik, B.; Çelik, M.E. Root Dilaceration Using Deep Learning: A Diagnostic Approach. Appl. Sci. 2023, 13, 8260. https://doi.org/10.3390/app13148260
Çelik B, Çelik ME. Root Dilaceration Using Deep Learning: A Diagnostic Approach. Applied Sciences. 2023; 13(14):8260. https://doi.org/10.3390/app13148260
Chicago/Turabian StyleÇelik, Berrin, and Mahmut Emin Çelik. 2023. "Root Dilaceration Using Deep Learning: A Diagnostic Approach" Applied Sciences 13, no. 14: 8260. https://doi.org/10.3390/app13148260
APA StyleÇelik, B., & Çelik, M. E. (2023). Root Dilaceration Using Deep Learning: A Diagnostic Approach. Applied Sciences, 13(14), 8260. https://doi.org/10.3390/app13148260