1. Introduction
The Albayzin evaluations are a series of technological benchmarks and challenges open to the scientific community within different fields of the broad area of speech technologies. Organized every two years since 2006 and supported by the Spanish Thematic Network on Speech Technologies (Red Temática en Tecnologías del Habla (RTTH), (
http://www.rtth.es (accessed on 24 July 2023)), starting from 2018 the evaluations have focused on the broadcast media area. Thanks to Radio Televisión Española, RTVE (
http://www.rtve.es (accessed on 24 July 2023)), the Spanish Public Broadcast Corporation, and the RTVE Chair at the University of Zaragoza (Cátedra RTVE de la Universidad de Zaragoza: (
http://catedrartve.unizar.es (accessed on 24 July 2023)), new and more challenging datasets are being released to support the assessment of speech technologies in broadcast media tasks. Speech technologies have been introduced in this area due to their high potential to automate processes as subtitling and caption generation and alignment, or automatic metadata generation for audiovisual content. This requires continuous efforts to evaluate the performance of these technologies and to support new developments. In the last years, deep learning approaches have completely changed the landscape with a great boost in performance in image recognition, natural language processing and speech recognition applications. This has allowed the introduction of speech technologies in the work pipeline of broadcast archives and documentation services.
Different evaluation campaigns for broadcast speech have been carried out from the first one proposed in 1996 [
1], most of them using English as the target language [
2,
3]. In the past few years, speech evaluations organized by the National Institute of Standards and Technology (NIST) have expanded the range of languages of interest (sometimes including low-resourced languages such as Cantonese, Pashto, Tagalog, Swahili, Tamil, to name a few) and speech domains, such as telephone and public safety communication. These evaluations included automatic speech recognition (ASR), spoken term detection and keyword spotting tasks [
4,
5,
6,
7,
8,
9,
10]. The Albayzin evaluations have always focused on Iberian languages, mainly Spanish and to a lesser extent Catalan and Basque. Spanish is the second language with the highest number of native speakers and the fourth most spoken language in the world (
https://www.ethnologue.com/insights/ethnologue200/ (accessed on 24 July 2023)). The Albayzin evaluations have the purpose of tracking the evolution of speech technologies for Iberian Languages with new and increasingly challenging datasets in each evaluation campaign. In the last editions, the evaluations have focused on Spanish language in the broadcast media sector. In the 2022 edition, four challenges have been proposed:
Speech to Text Challenge (S2TC), organized by RTVE and Universidad de Zaragoza, which consists of automatically transcribing different types of TV shows.
Speaker Diarization (SDC) and Identity Assignment Challenge (SDIAC), organized by RTVE and Universidad de Zaragoza, which consists of segmenting broadcast audio documents according to different speakers, linking those segments which originate from the same speaker and identifying a closed set of speakers.
Text and Speech Alignment Challenge (TaSAC), which consists of two sub-challenges:
- –
(Task 1) TaSAC-ST: Alignment of re-speaking generated subtitles, organized by RTVE and Universidad de Zaragoza, which consists of synchronizing the broadcast subtitles created by re-speaking of different TV shows.
- –
(Task 2) TaSAC-BP: Alignment and validation of speech signals with partial and inaccurate text transcriptions, organized by the University of the Basque Country (UPV/EHU), which consists of aligning text and audio extracted from a plenary session of the Basque Parliament.
Search on Speech Challenge (SoSC), organized by Universidad San Pablo-CEU and AuDIaS from Universidad Autónoma de Madrid, which consists of searching in audio content a list of terms/queries.
The main novelty of the IberSpeech-RTVE 2022 Challenges compared to previous evaluations [
11,
12] relies on the two following features: (1) A text and speech alignment challenge has been proposed for the very first time in the Albayzin evaluation series, including two different sub-tasks for two possible applications; and (2) new and more challenging databases have been released for all the evaluation tasks, covering different domains but focusing on broadcast media content, some of them, such as the RTVE and the Basque Parliament databases, being specifically created for these challenges.
A total of 7 teams from industry and academia registered to participate in the IberSpeech-RTVE 2022 challenges, with 20 different systems submitted in total. Compared to previous evaluations, the number of participants has significantly decreased. In the 2018 edition, 16 teams submitted 85 systems in the different challenges. In the 2020 edition, 12 teams submitted a total of 31 systems.
We present in this paper an overview of the IberSpeech-RTVE 2022 challenges along with the data supplied by the organization to the participants and the performance metrics. The overview includes a detailed description of the systems showcased for evaluation, their corresponding results, and a comprehensive set of conclusions derived from the 2022 evaluation campaign and previous campaigns in 2018 [
11] and 2020 [
12]. This paper will serve as reference for anyone wanting to use the datasets provided in the evaluation. Up to the date of writing this paper, more than 50 international research groups have asked for access to the RTVE database.
The paper is organized as follows:
Section 2 presents the databases used in the different challenges;
Section 3 describes the four IberSpeech-RTVE 2022 challenge tasks: speech-to-text transcription, speaker diarization and identity assignment, text and speech alignment, and search on speech, along with with the performance metrics used in each challenge;
Section 4 provides a brief description of the submitted systems;
Section 5 presents and discusses the results; and finally, a summary of the paper, conclusions and future work are outlined in
Section 6.
3. IberSpeech-RTVE 2022 Evaluation Tasks
3.1. Speech to Text Challenge
The speech-to-text transcription evaluation consists of automatically transcribing different types of TV shows. The main objective is to evaluate the state-of-the-art in automatic speech recognition (ASR) for the Spanish language in the broadcast sector. There is no specific training partition, thus participants are free to use the previous RTVE datasets (2018 and 2020) or any other data to train their systems provided that these data are fully documented in the system’s description paper. For public databases, the name of the database must be provided. For private databases, a brief description of the origin of the data must be provided. Each participant team should submit at least a primary system, but they could also submit up to three contrastive systems.
3.2. Speaker Diarization and Identity Assignment Challenge
The Speaker Diarization and Identity Assignment evaluation consists of segmenting broadcast audio documents according to different speakers and linking those segments which originate from the same speaker. On top of that, for a limited number of speakers, the evaluation asked for assigning the name of these people to the correct diarization labels. No prior knowledge is provided about the number of speakers participating in the audio to be analyzed. Participants are free to use any dataset for training their diarization systems provided that these data were fully documented in the system’s description paper. The organization provides all the RTVE datasets (
http://catedrartve.unizar.es/rtvedatabase.html (accessed on 24 July 2023)), the Catalan broadcast news database from the 3/24 TV channel proposed for the 2010 Albayzin Audio Segmentation Evaluation [
15,
16] and the Corporación Aragonesa de Radio y Televisión (CARTV) database proposed for the 2016 Albayzin Speaker Diarization evaluation. For the identity assignment task, the RTVE2022 dataset provides enrolment audio files for 74 speakers (38 male, 36 female). At least 30 s of speech from each speaker to identify are included in the dataset.
3.2.1. Diarization Scoring
As in the NIST RT Diarization evaluations (
https://www.nist.gov/itl/iad/mig/rich-transcription-evaluation (accessed on 24 July 2023)), to measure the performance of the proposed systems, the diarization error rate (DER) is computed as the fraction of speaker time that is not correctly attributed to that specific speaker. This score is computed over the entire file to be processed, including regions where more than one speaker is present (overlap regions).
Given the dataset to evaluate
, each document is divided into contiguous segments at all speaker change points found in both the reference and the hypothesis, and the diarization error time for each segment
n is defined as:
where
is the duration of segment
n,
is the number of speakers that are present in segment
n,
is the number of system speakers that are present in segment
n, and
is the number of reference speakers in segment
n correctly assigned by the diarization system.
The diarization error time includes the time that is assigned to the wrong speaker, missed speech time, and false alarm speech time:
Speaker error time: The speaker error time is the amount of time that has been assigned to an incorrect speaker.
Missed speech time: The missed speech time refers to the amount of time that speech is present but not labeled by the diarization system.
False alarm time: The false alarm time is the amount of time that a speaker has been labeled by the diarization system but is not present.
Consecutive speech segments of audio labelled with the same speaker identification tag and separated by a non-speech segment less than 2 s long are merged and considered a single segment. A region of 0.25 s around each segment boundary, usually known as the forgiveness collar, is considered. These regions are excluded from the computation of the diarization error in order to take into account both inconsistent human annotations and the uncertainty about when a speaker turn begins or ends.
3.2.2. Identity Assignment Scoring
For the Identity Assignment Task, the assignment error rate (AER) is used, which is a slightly modified version of the previously described DER. This metric is defined as the amount of time incorrectly attributed to the speakers of interest divided by the total amount of time that those specific speakers are active. Mathematically, it can be expressed as:
where:
FA represents the False Alarm Time, which contains the length of the silence segments or speech segments that belong to unknown speakers incorrectly attributed to a certain speaker.
MISS represents the Missed Speech Time, which takes into account the length of the speech segments that belong to speakers of interest not attributed to any speaker.
SPEAKER ERROR (Speaker Error Time) considers the length of the speech segments that belong to speakers of interest attributed to an incorrect speaker.
REFERENCE LENGTH is the sum of the lengths of all the speech segments uttered by the people of interest (i.e., those identities for which the participants will have audio to train their models).
3.3. Text and Speech Alignment Challenge
The Text and Speech Alignment Challenge (TaSAC) consists of two subchallenges:
Alignment of re-speaking generated subtitles (TaSAC-ST). This challenge consists of synchronizing the broadcast subtitles created by re-speaking different TV shows.
Alignment and validation of speech signals with partial and inaccurate text transcriptions (TaSAC-BP). This challenge consists of aligning text and audio extracted from a plenary session of the Basque Parliament.
3.3.1. Alignment of Re-Speaking Generated Subtitles (TaSAC-ST)
The IberSPEECH-RTVE 2022 Text and Speech Alignment Challenge aims to evaluate the text-to-speech alignment systems on the actual problem of synchronizing re-speaking subtitles with the corresponding audio. The task assesses the state of the art of offline alignment technology. The purpose is to provide subtitles without delay for a new broadcast. In this task, participants are supplied with the subtitles as they originally appeared on TV, including the start and end timestamps of each subtitle. Participants must provide an output with the exact same sequence of subtitles but with new start and end timestamps for each subtitle. It should be noted that re-speaking subtitles often differ from the actual spoken words. If the speech is too fast the re-speaker tends to suppress words (deletions) or even to paraphrase, which introduces a new level of difficulty in the alignment process. The performance is measured by computing the time differences between the aligned start and end timestamps given by the alignment systems and the reference timestamps derived from a careful manual alignment.
3.3.2. Alignment and Validation of Speech Signals with Partial and Inaccurate Text Transcriptions (TaSAC-BP)
Over the last years, with the widespread adoption of data-intensive deep learning approaches to ASR, the semi-supervised collection of training data for ASR has gained renewed interest. The Internet is plenty of resources pairing speech and text. Sometimes the paired text is an accurate transcription of the spoken content, but frequently it is only a loose or partial transcription or even a translation to some other language. Therefore, a text-to-speech alignment system able to detect and extract accurately paired speech and text segments becomes a very valuable tool. The second task of the Text-and-Speech Alignment Challenge (TaSAC-BP) was designed with that goal in mind. The alignment systems would deal with a long audio file, including sections in Spanish and Basque, but the paired texts (which could be partial or approximate transcripts of the audio) would cover only the Spanish sections. The audio parts in Basque were not expected to be paired with any text, though some words or word fragments (proper names, technical terms, etc.) may actually match (and be wrongly paired with) text in Spanish.
Task Description
The task consisted of aligning each word of the text with a segment of the audio file so that the audio content corresponds to the pronunciation of the given word. Alignments were required to be monotonous, that is, the sequence of timestamps had to be non-decreasing. Obviously, it was guaranteed that there was an optimal monotonous alignment between the audio signal X and the paired text W. Let be the sequence of N words to be aligned with an audio signal X, and let be the corresponding sequence of aligned segments in X. Then, if a word is aligned to a segment and another word is aligned to a segment , with , then the timestamps defining those segments must be . Non-monotonic alignments were not allowed and non-monotonic submissions were not accepted.
The output of an alignment system was required to be a text file containing a line for each word in the paired text, each line including 5 columns (separated by any amount of spaces or tabs) with the following information:
: A real number with the time when the segment starts.
: A real number with the time when the segment ends.
word: The word paired with the audio segment.
score: A real number reflecting the confidence on the alignment, the more positive the score, the higher the confidence; the more negative the score, the lower the confidence.
decision: A binary value (0/1), 0 meaning Reject and 1 meaning Accept. Since only the accepted words would be evaluated, this decision should be made by applying a confidence score threshold.
The participants could submit results for at most five (one primary + four contrastive) systems. Each system should automatically align the paired text with the audio, taking into account that some parts of the audio should not be aligned with any text and that the paired text did not reflect exactly the audio contents. It was not allowed to listen to the audio or use any kind of human intervention (e.g., crowdsourcing). Otherwise, any approach could be applied with no limit to the type or amount of resources that the participants could use to perform the task, as long as the employed methods and resources were described with enough detail and, if possible, links to papers, data and/or software repositories were provided to make it easier to reproduce their approach. For each system, two separate result files were required, for the development and test sets, respectively. Finally, participants would be ranked according to the performance obtained by their primary systems on the test set.
Scoring Script
The scoring script provided to participants is a command-line application that requires a basic installation of Python 3 including the matplotlib module (used to produce a graphical analysis of system scores). The script takes the system alignment and the ground truth files as input and allows to specify collar time (in this case, 0.02 s) as well as other optional arguments, such as the text and graphical output file names.
The output text includes two lines, the first one showing the performance obtained using system decisions, and the second one showing the best performance that can be obtained by applying a threshold on the provided scores to make decisions. By default, the text output is written on the console. The optional graphical output (a PNG file) presents the performance obtained by applying system decisions and the evolution of the correctly aligned time, the wrongly aligned time and the difference between them (that is, the performance metric) by using all the possible thresholds to make decisions. The optimal performance and the corresponding threshold are marked on the performance curve. The figure also includes the total time accepted and rejected by applying different thresholds. Obviously, applying the minimum threshold implies accepting all the words of the paired text, which does not usually yield the best performance, while applying the maximum threshold implies rejecting all the words, meaning a performance of 0. A reasonable criterion to make decisions on the test set would be to apply the optimal threshold found on the development set.
3.4. Search on Speech Challenge
The Search on Speech challenge involves searching in audio content a list of terms or queries and it is suitable for groups working on speech indexing/retrieval and speech recognition. In other words, this challenge focuses on retrieving the audio files that contain any of those terms/queries along with the corresponding timestamps.
This challenge consists of two different tasks:
Spoken Term Detection (STD), where the input to the system is a list of terms, but these terms are unknown when processing the audio. This task must generate a set of occurrences for each term detected in the audio files, along with their timestamps and score as output. This is the same task as in NIST STD 2006 evaluation [
17] and Open Keyword Search in 2013 [
4], 2014 [
5], 2015 [
6], and 2016 [
7].
Query-by-Example Spoken Term Detection (QbE STD), where the input to the system is an acoustic query and hence a prior knowledge of the correct word/phone transcription corresponding to each query cannot be used. This task must generate a set of occurrences for each query detected in the audio files, along with their timestamps and score as output, as in the STD task. This QbE STD is the same task as those proposed in MediaEval 2011, 2012, and 2013 [
18].
For the QbE STD task, participants are allowed to make use of the target language information (Spanish) when building their system/s (i.e., system/s can be language-dependent). Nevertheless, participants are strongly encouraged to build language-independent QbE STD systems, as in past MediaEval Search on Speech evaluations, where no information about the target language was given to participants.
This evaluation defined two different sets of terms/queries for STD and QbE STD tasks: an in-vocabulary (INV) set of terms/queries and an out-of-vocabulary (OOV) set of terms/queries from lexicon and language model perspectives. The OOV set of terms/queries will be composed of out-of-vocabulary words for the LVCSR system. This means that, in case participants employ an LVCSR system for processing the audio for any task (STD, QbE STD), these OOV terms (i.e., all the words that compose the term) must be previously removed from the system dictionary/language model and hence, other methods (e.g., phone-based systems) have to be used for searching OOV terms/queries. Participants can consider OOV words for acoustic model training if they find it suitable.
Regarding the QbE STD task, three different acoustic examples per query were provided for both development and test datasets. One example was extracted from the same dataset as the one to be searched (hence in-domain acoustic examples). This scenario considered the case in which the user finds a term of interest within a certain speech dataset and he/she wants to search for new occurrences of the same query. The two other examples were recorded by the evaluation organizers and comprised a scenario where the user pronounces the query to be searched (hence out-of-domain acoustic examples). These two out-of-domain acoustic examples amount to 3 s of speech with PCM, 16 kHz, single channel and 16 bits per sample with the microphone of an HP ProBook Core i5, 7th Gen and with a Sennheiser SC630 USR CTRL microphone with noise cancellation, respectively.
The queries employed for the QbE STD task were chosen from the STD queries. It should be noted that for both the STD and QbE STD tasks, a multi-word query was considered OOV in case any of the words that form the query was OOV.
Evaluation Metric
In search on speech systems (both for STD and QbE STD tasks), a hypothesized occurrence is called a detection; if the detection corresponds to an actual occurrence, it is called a hit; otherwise, it is called a false alarm. If an actual occurrence is not detected, this is called a miss. The main metric for the evaluation is the actual term weighted value (ATWV) metric proposed by NIST [
17]. This metric combines the hit rate and false alarm rate of each query and averages over all the queries, as shown in Equation (
13):
where
denotes the set of queries and
is the number of queries in this set.
and
represent the numbers of hits and false alarms of query
Q, respectively and
is the number of actual occurrences of query
Q in the audio.
T denotes the audio length in seconds and
is a weight factor set to
, as in the ATWV proposed by NIST [
17]. This weight factor causes an emphasis placed on recall compared to precision with a 10:1 ratio.
ATWV represents the term weighted value (TWV) for an optimal threshold given by the system (usually tuned on the development data). An additional metric, called maximum term weighted value (MTWV) [
17] is also used to evaluate the upper-bound system performance regardless of the decision threshold.
Additionally, p(Miss) and p(FA), which represent the probability of miss and false alarm of the system as defined in Equations (
14) and (
15), respectively, are also reported:
where
is the number of hits obtained by the system,
is the actual number of occurrences of the queries in the audio,
is the number of false alarms produced by the system and
T denotes the audio length (in seconds). These values, therefore, provide a quantitative way to measure system performance in terms of misses (or equivalently, hits) and false alarms.
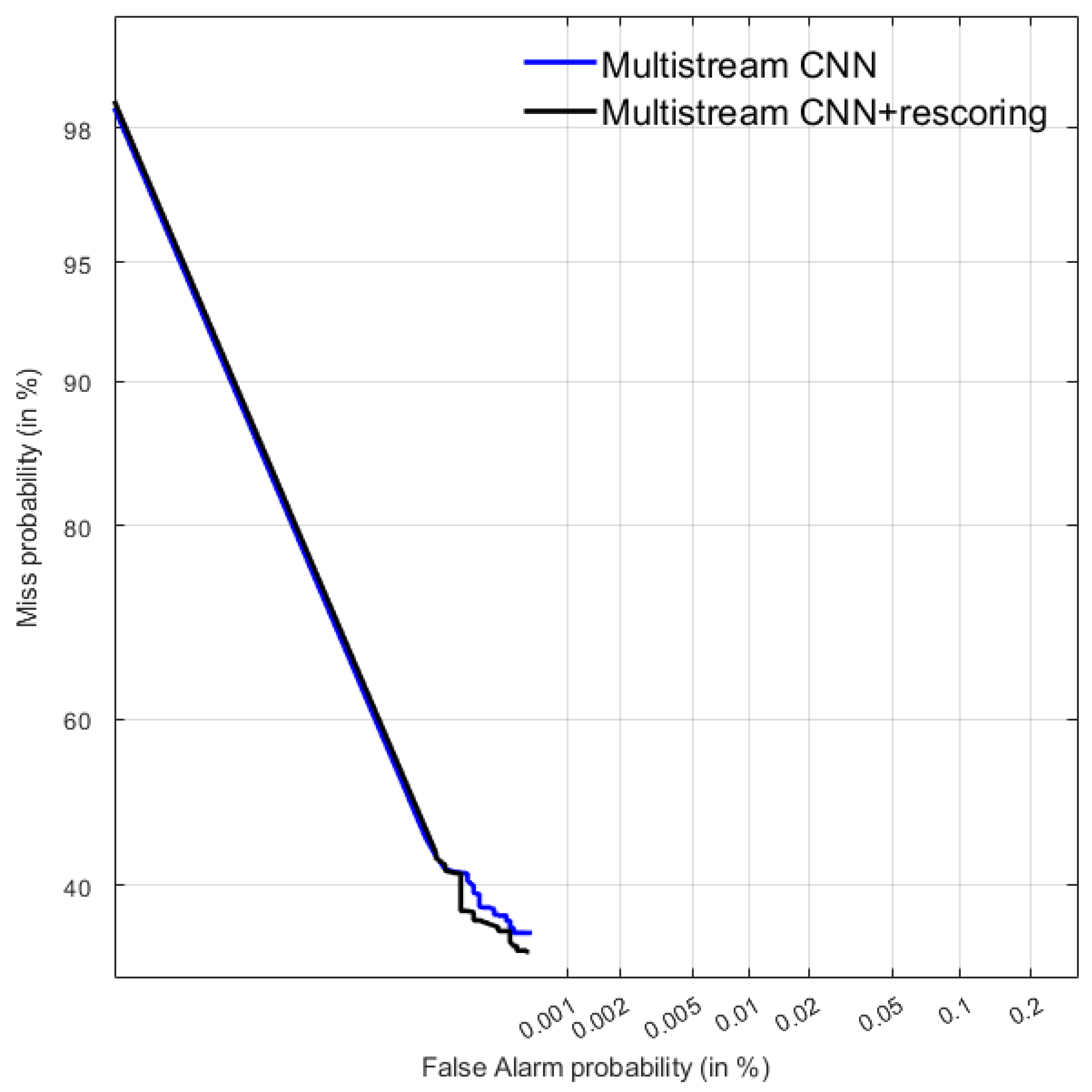
In addition to ATWV, MTWV, p(Miss) and p(FA) figures, NIST also proposed a detection error tradeoff (DET) curve [
19] that evaluates the performance of a system at various miss/FA ratios. Although DET curves were not used for the evaluation itself, they are also presented in this paper for system comparison.
The NIST STD evaluation tool [
20] was employed to compute the MTWV, ATWV, p(Miss) and p(FA) figures, along with the DET curves.
6. Conclusions
The Albayzin evaluation campaigns comprise a unique and closed framework to measure the progress of speech technologies in Iberian languages (especially Spanish). This paper provides a comprehensive overview of the most recent Albayzin evaluation campaign: the IberSpeech-RTVE 2022 Challenges, which featured four different evaluations focused on TV broadcast content: speech-to-text transcription, speaker diarization and identity assignment, text and speech alignment, and search on speech. This is the first time that the text and speech alignment task is addressed in the Albayzin evaluation campaigns. Since its first release in 2018, the RTVE database provided for system development has increased in size up to 1000 h, with half of the material human transcribed, 96 h labelled with speaker turns and 58 h annotated with identity labels from a closed set of around 200 characters. Besides RTVE broadcast data, conference talks and panels (MAVIR) and parliamentary sessions (SPARL22, Basque Parliament dataset) have been also used in some of the challenges, to expand the range of domains and conditions.
In the Speech-To-Text task, four teams participated with 13 different system submissions. The evaluation was carried out over 21 different shows with a total of 54 h and covering a broad range of acoustic conditions. The best results in terms of the lowest WER were given by a system composed of the fusion of 5 models with a WER of 14.35%. The best single system gave a WER of 14.78%. It is remarkable that the zero-shot system, the Whisper Large model, released in September 2022, when using proper post-processing of the output, obtained a WER of 14.87%. It is also noteworthy that the 2022 test dataset is more difficult than the previous one by a 22.3%, according to the results obtained using Whisper in both datasets.
With regard to the speaker diarization and identity assignment challenge, only two teams participated in the speaker diarization task and only one of them submitted systems to the identity assignment task. The organization provided a baseline system based on the best 2020 system. The evaluation was carried out over 9 different shows with a total of 25 h and covered a broad range of conditions: acoustic background, number of speakers, and amount of overlapping speech. The best system obtained 18.47% DER, which meant a big gap in terms of DER when compared to the other submissions, including the baseline system.
There were only two participants in the text and speech alignment challenge. In the first task, focused on re-speaking generated subtitles, the best submitted system obtained an average median error per program (APTEM) of 0.29 s, and a global mean error of 0.61 s, which are still too high for many applications. The system was trained on out-of-domain (non-RTVE) data so better results could be expected when using in-domain training data. Also, it was found that some programs could be more challenging than others, with almost twice global mean error. In the second task, focused on retrieving training materials from loosely transcribed audio involving two languages (Basque and Spanish), the submitted system leveraged state-of-the-art ASR technology to perform unrestricted text and speech alignments, obtaining very competitive scores and successfully matching most of the reference transcripts (only in Spanish) with the corresponding audio sections.
In the search on speech challenge, which employed a subset of the test dataset employed in the speech-to-text transcription task, a single participant submitted two different systems. The best system obtained an ATWV of 0.6694, which shows that there is still ample room for improvement in this task.
In summary, the results are showing an improvement in the performance of the speech technologies assessed in the four challenges comparing with previous challenges. Promising results in both speech-to-text transcription and speaker diarization tasks were obtained in some TV shows belonging to genres such as news, interviews, thematic magazines or daily magazines. However, there is still room for improvement when dealing with genres such as serial drama, reality shows and game shows. For text and speech alignment, more datasets are needed in order to cover all the problems associated to re-speaking where the re-speakers often end up paraphrasing, and more in-the-wild materials involving a wide range of acoustic conditions and transcript qualities should be used to assess the performance of text and speech alignment methods for leveraging loosely or partially transcribed audio resources as training data for ASR. With regard to the search on speech tasks (STD and QbE-STD), more research is needed to address the increased complexity posed by out-of-vocabulary terms and/or multi-word terms when compared to in-vocabulary and single-word terms.
We are now actively preparing a new edition of the Albayzin evaluations, to be held along with the next IberSpeech conference in 2024. An extension of the RTVE database with new challenging audiovisual material will be released by April 2024, which will hopefully help to assess new developments in speech and language technologies.


 ,
, 




{kind=link}