

Recognition of Student Engagement State in a Classroom Environment Using Deep and Efficient Transfer Learning Algorithm


 ,
,  ,
, 
Abstract
1. Introduction
1.1. Background
1.2. Major Contributions
- We collected a dataset of 45 students in a total of 32 videos from an offline and least controlled classroom setting. The extracted frames from these videos were classified into engaged and non-engaged frames based on features extracted from literature and student survey.
- A transfer-learning-assisted model is presented to compute the affective state in an offline classroom environment while attaining surpassing correctness.
- The explicit contribution is the subsequent analysis in which 14 different experiments are performed with respect to timestamps and six different experiments are performed to evaluate the impact of gender while incorporating Poisson and Negative Binomial Regression models.
- The policy recommendations are suggested regarding lecture schedules of male and female students and variation in contents of the course considering findings of the underlying research.
1.3. Paper Organization
2. Literature Review

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Year | Affective States | Classifier/Method | Key Features | Dataset | No. of Students | Results | Offline |
|---|---|---|---|---|---|---|---|
| 2014 [35] | not engaged, nominally engaged, engaged, very engaged | Linear regression, multinomial logistic regression | Only head pose and eyes features | Self-generated | 34 (9 male, 25 female) | F-score: 0.369 | × |
| 2015 [44] | low, medium, and high attention levels | SVM | Head movement patterns | Self-generated | 35% female & 65% male | ACC: 0.89 | √ |
| 2017 [45] | engaged and distracted | SVM, logistic regression | Head pose and eye gaze | Self-generated | 10 (3 male, 7 female) | ACC: 90% | × |
| 2019 [12] | not engaged, normally engaged, and highly-engaged | CNN | Facial Action Unit | DAiSEE Dataset [46] | 112 (32 females and 80 males) | ACC: 89% | × |
| 2020 [23] | engaged, non-engaged, neutral | Inception v3 | Facial expressions, hand gestures, and body postures | Self-generated | 50 | ACC: 86% | × |
| 2021 [21] | low level, high-level engagement | LSTM and TCN, fully-connected neural network, SVM, and RF | Eye movement, gaze direction, and head pose | DAiSEE [46] and EmotiW [47] | 112 (32 females and 80 males) | ACC: 63% | × |
| 2021 [22] | completely disengaged, barely engaged, engaged, and highly engaged | Neural Turing Machine | Eye-gaze features, FAU, head pose, and body pose | DAiSEE [46] | 112 (32 females and 80 males) | ACC: 61% | × |
3. Materials and Methods
3.1. Data Acquisition
3.2. Model Training
3.3. Data Annotations
- Engaged Frames: The frames in which the student is looking towards the teacher or board, taking notes, or discussing with a teacher are labelled as engaged.
- Non-Engaged Frames: The frames in which the student seems not interested in the lecture, is looking away from the teacher, barely opening or closing their eyes, yawning, leaning on the desk, using a mobile phone, or talking with fellows are labelled as non-engaged.
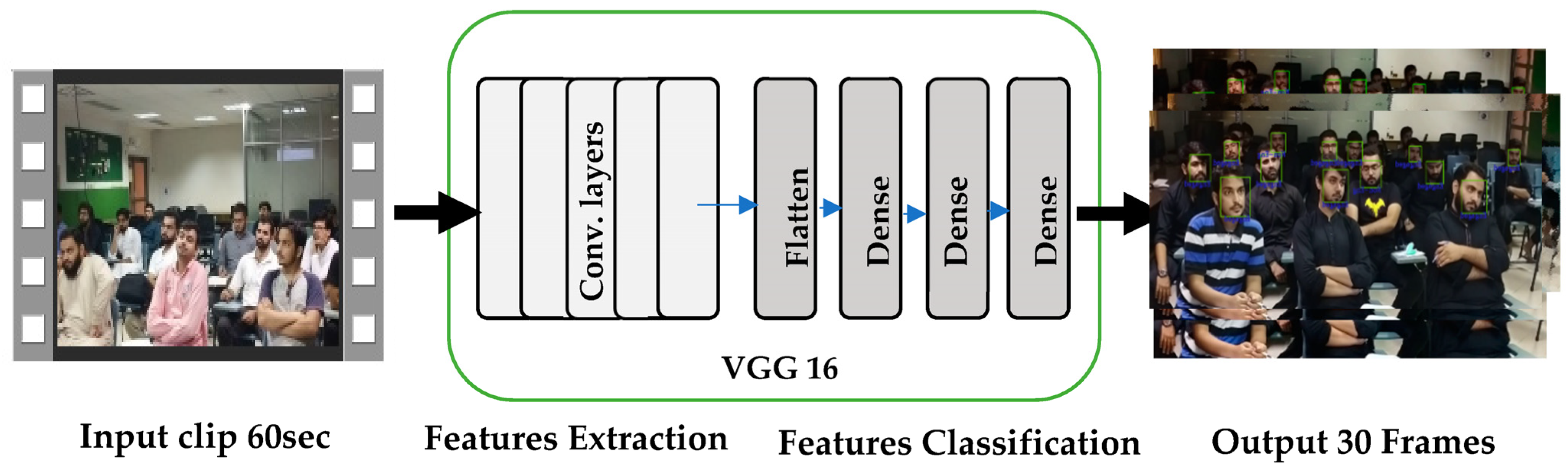
3.4. Proposed Transfer Learning Model
| Algorithm 1: That proposed VGG16 with dense layers and fine-tuning of the model and hyperparameters |
| Step 1: Input: Video frames with annotations (engaged or non-engaged) and—Timestamps and gender information for each student. Step 2: Output: Affective states of each student (engaged or non-engaged) based on the video frames and Regression analysis results (impact of timestamps and gender on affective states). Step 3: Data Collection: Let ‘X’ be the set of video frames with annotations and Let ‘Y’ be the corresponding labels for each frame (1 for engaged, 0 for non-engaged). Step 4: Data Preprocessing: Resize and preprocess the frames in ‘X’ to a standardized size and split the data into training and testing sets: ‘X_train’, ‘Y_train’, ‘X_test’, ‘Y_test’. Step 5: Transfer Learning with VGG16 and Fine-tuning:
Step 7: Define the loss function: Loss(Y_true, Y_pred), e.g., categorical cross-entropy, and define the optimization algorithm: Optimization Algorithm with appropriate hyperparameters (e.g., learning rate, momentum). Step 8: Compile the model: Train the model on the training data with a batch size and number of epochs, Evaluate the fine-tuned model on the testing data, Apply the fine-tuned model to predict the affective states of each student. Step 9: Combine affective state predictions with metadata (timestamps and gender) for each student. |
3.5. Fine-Tuned Model and Hyperparameters
4. Results and Discussions
4.1. Environmental Setup
4.2. Computations of Engagement State
4.3. Methods for Post Analysis
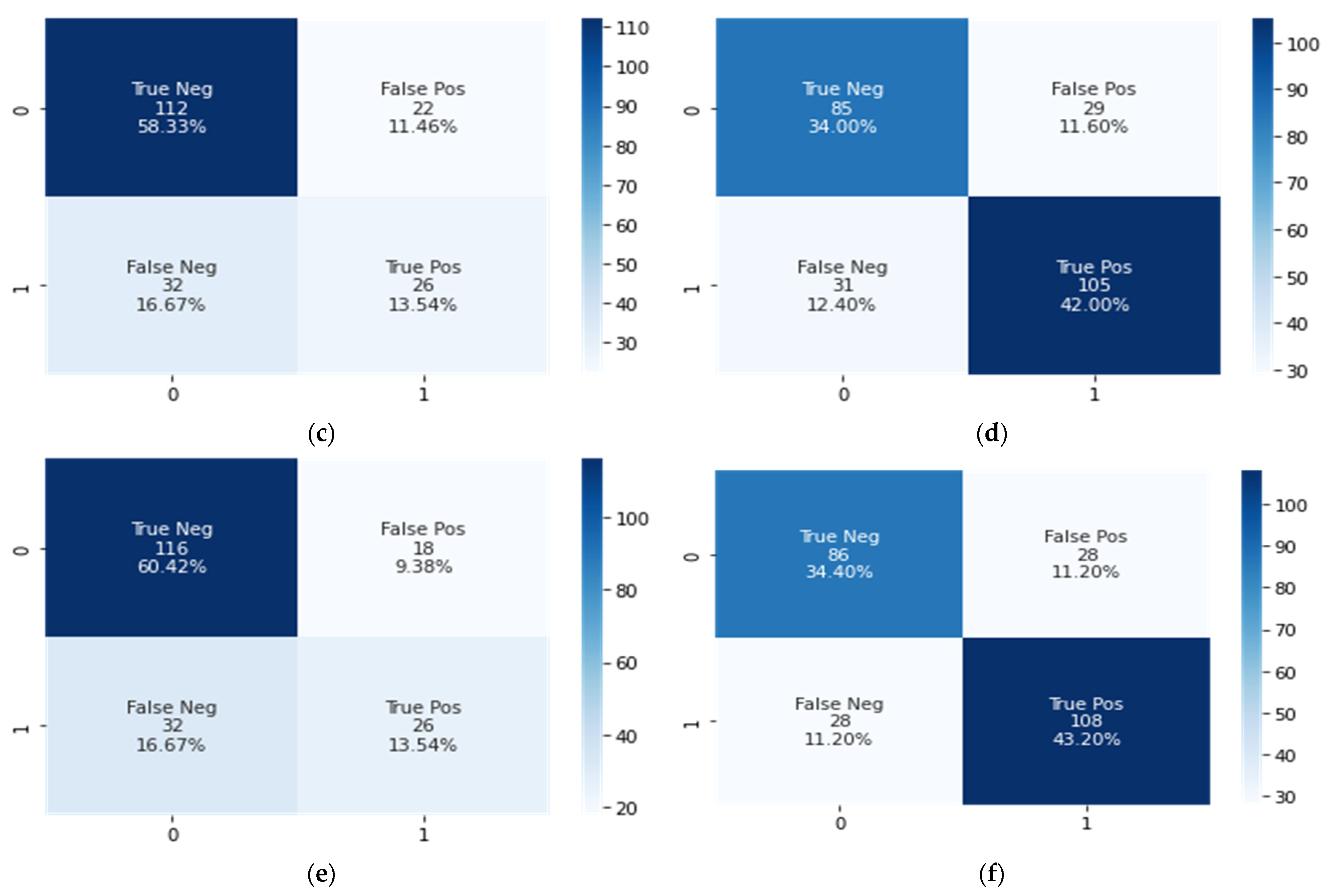
4.4. Results Analysis
4.5. Timestep Analysis
4.6. Gender-Wise Analysis
- Spatial information vs. temporal information: VGG16 focuses on capturing spatial information within individual frames, but it does not explicitly model temporal dependencies between frames. In contrast, architectures such as InceptionV3 and GoogLeNet incorporate components such as temporal convolutional layers or recurrent neural networks (RNNs) that can capture temporal information and dependencies in video sequences. This can be beneficial for object detection in videos, where the motion and temporal context of objects play an important role.
- Computational efficiency: VGG16 has a relatively high number of parameters and computational complexity due to its deeper architecture, which can make it computationally expensive for real-time object detection in videos. InceptionV3 and GoogLeNet, on the other hand, have been designed with computational efficiency in mind. They utilize techniques like 1 × 1 convolutions and factorized convolutions, which reduce the number of parameters and computational cost while maintaining or even improving performance. This efficiency is particularly advantageous for video processing tasks that require real-time or near-real-time performance.
- Architectural innovations: InceptionV3 and GoogLeNet incorporate architectural innovations that aim to address specific challenges in object detection, such as the problem of vanishing/exploding gradients or the efficient use of network capacity. These innovations, such as the use of inception modules, auxiliary classifiers, and reduction layers, can enhance the model’s ability to detect objects accurately in videos.
| Independent Variable | Dependent Variable | Const. | Coefficient | Std. Err | Z Value | Prob | Test |
|---|---|---|---|---|---|---|---|
| Gender | Non-engaged | 2.720974 | −0.0379002 | 0.0682888 | −0.55 | 0.579 | PR |
| 2.720974 | −0.0379002 | 0.0753602 | −0.50 | 0.615 | NBR |


4.7. Generalizability Analysis
4.8. Computational Analysis
- Frame Down sampling: We process one frame after two seconds.
- Image Size: Each image is converted to a size of 224 × 224 pixels before being passed to the model. This means each frame consists of 224 × 224 × 0.5 (RGB channels) = 25,088 input values.
- Model Inference: The computational complexity of these layers can be estimated based on the number of operations required for each layer type. However, the exact number of operations can vary depending on the specific architecture and implementation details.
5. Conclusions and Future Works
- A class having more male students is better to be scheduled in the morning.
- A class having more female students may also be scheduled in the evening.
5.1. Limitations
5.2. Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Sattar, T.; Ullah, M.I.; Ahmad, B. The Role of Stakeholders Participation, Goal Directness and Learning Context in Determining Student Academic Performance: Student Engagement as a Mediator. Front. Psychol. 2022, 13, 875174. [Google Scholar] [CrossRef] [PubMed]
- Gupta, S.; Kumar, P.; Tekchandani, R.K. Facial emotion recognition based real-time learner engagement detection system in online learning context using deep learning models. Multimed. Tools Appl. 2023, 82, 11365–11394. [Google Scholar] [CrossRef]
- Pabba, C.; Kumar, P. An intelligent system for monitoring students’ engagement in large classroom teaching through facial expression recognition. Expert Syst. 2022, 39, e12839. [Google Scholar]
- Nazari, M.; Karimpour, S. Emotions, perspectives, and English language teacher identity construction: A phenomenographic-narrative study. Int. J. Appl. Linguist. 2023, 33, 150–168. [Google Scholar]
- Ha, S.; So, H.J. Examining the Effects of the Utility Value Intervention on Learners’ Emotions and Conceptual Understanding in Online Video-based Learning. Educ. Inf. Technol. 2023, 1–28. [Google Scholar] [CrossRef]
- Grafsgaard, J.F.; Fulton, R.M.; Boyer, K.E.; Wiebe, E.N.; Lester, J.C. Multimodal analysis of the implicit affective channel in computer-mediated textual communication. In Proceedings of the ICMI’12: ACM International Conference on Multimodal Interaction, Santa Monica, CA, USA, 22–26 October 2012; pp. 145–152. [Google Scholar] [CrossRef]
- Fan, J.; Tian, M. Influence of Online Learning Environment and Student Engagement on International Students’ Sustainable Chinese Learning. Sustainability 2022, 14, 11106. [Google Scholar] [CrossRef]
- Apicella, A.; Arpaia, P.; Frosolone, M.; Improta, G.; Moccaldi, N.; Pollastro, A. EEG-based measurement system for monitoring student engagement in learning 4.0. Sci. Rep. 2022, 12, 5857. [Google Scholar]
- Hasan, M.M.; Jankowski, K.S.; Khan, M.H. Morningness-eveningness preference and shift in chronotype during COVID-19 as predictors of mood and well-being in university students. Personal. Individ. Differ. 2022, 191, 111581. [Google Scholar]
- Goldberg, B.S.; Sottilare, R.A.; Brawner, K.W.; Holden, H.K. Predicting learner engagement during well-defined and ill-defined computer-based intercultural interactions. In International Conference on Affective Computing and Intelligent Interaction; Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Berlin/Heidelberg, Germany, 2011; pp. 538–547. [Google Scholar] [CrossRef]
- Karimah, S.N.; Hasegawa, S. Automatic engagement estimation in smart education/learning settings: A systematic review of engagement definitions, datasets, and methods. Smart Learn. Environ. 2022, 9, 31. [Google Scholar]
- Murshed, M.; Dewan, M.A.A.; Lin, F.; Wen, D. Engagement detection in e-learning environments using convolutional neural networks. In Proceedings of the 2019 IEEE International Conference on Dependable, Autonomic and Secure Computing, International Conference on Pervasive Intelligence and Computing, International Conference on Cloud and Big Data Computing, International Conference on Cyber Science and Technology Congress (DASC/PiCom/CBDCom/CyberSciTech), Fukuoka, Japan, 5–8 August 2019; pp. 80–86. [Google Scholar] [CrossRef]
- Li, Q.; Kumar, P.; Alazab, M. IoT-assisted physical education training network virtualization and resource management using a deep reinforcement learning system. Complex Intell. Syst. 2022, 8, 1229–1242. [Google Scholar] [CrossRef]
- Wang, Y.; Kotha, A.; Hong, P.H.; Qiu, M. Automated Student Engagement Monitoring and Evaluation during Learning in the Wild. In Proceedings of the 2020 7th IEEE International Conference on Cyber Security and Cloud Computing and 2020 6th IEEE International Conference on Edge Computing and Scalable Cloud, CSCloud-EdgeComm, New York, NY, USA, 1–3 August 2020; pp. 270–275. [Google Scholar] [CrossRef]
- Henrie, C.R.; Bodily, R.; Manwaring, K.C.; Graham, C.R. Exploring intensive longitudinal measures of student engagement in blended learning. Int. Rev. Res. Open Distance Learn. 2015, 16, 131–155. [Google Scholar] [CrossRef]
- Wang, S.; Ji, Q. Video affective content analysis: A survey of state-of-the-art methods. IEEE Trans. Affect. Comput. 2015, 6, 410–430. [Google Scholar] [CrossRef]
- Dermeval, D.; Paiva, R.; Bittencourt, I.I.; Vassileva, J.; Borges, D. Authoring tools for designing intelligent tutoring systems: A systematic review of the literature. Int. J. Artif. Intell. Educ. 2018, 28, 336–384. [Google Scholar]
- DeFalco, J.A.; Rowe, J.P.; Paquette, L.; Georgoulas-Sherry, V.; Brawner, K.; Mott, B.W.; Baker, R.S.; Lester, J.C. Detecting and addressing frustration in a serious game for military training. Int. J. Artif. Intell. Educ. 2018, 28, 152–193. [Google Scholar] [CrossRef]
- Abedi, A.; Khan, S.S. Improving state-of-the-art in Detecting Student Engagement with Resnet and TCN Hybrid Network. In Proceedings of the 2021 18th Conference on Robots and Vision, CRV, Burnaby, BC, Canada, 26–28 May 2021; pp. 151–157. [Google Scholar] [CrossRef]
- Abedi, A.; Khan, S. Affect-driven engagement measurement from videos. J. Latex Cl. Files 2021, 11, 1–13. [Google Scholar]
- Ma, X.; Xu, M.; Dong, Y.; Sun, Z. Automatic student engagement in online learning environment based on neural turing machine. Int. J. Inf. Educ. Technol. 2021, 11, 107–111. [Google Scholar] [CrossRef]
- TS, A.; Guddeti, R.M.R. Automatic detection of students’ affective states in classroom environment using hybrid convolutional neural networks. Educ. Inf. Technol. 2020, 25, 1387–1415. [Google Scholar] [CrossRef]
- Preckel, F.; Lipnevich, A.A.; Schneider, S.; Roberts, R.D. Chronotype, cognitive abilities, and academic achievement: A meta-analytic investigation. Learn. Individ. Differ. 2011, 21, 483–492. [Google Scholar] [CrossRef]
- Rahafar, A.; Maghsudloo, M.; Farhangnia, S.; Vollmer, C.; Randler, C. The role of chronotype, gender, test anxiety, and conscientiousness in academic achievement of high school students. Chronobiol. Int. 2016, 33, 1–9. [Google Scholar] [CrossRef]
- Kolomeichuk, S.N.; Randler, C.; Shabalina, I.; Fradkova, L.; Borisenkov, M. The influence of chronotype on the academic achievement of children and adolescents—Evidence from Russian Karelia. Biol. Rhythm Res. 2016, 47, 873–883. [Google Scholar] [CrossRef]
- Dewan, M.; Murshed, M.; Lin, F. Engagement detection in online learning: A review. Smart Learn. Environ. 2019, 6, 1. [Google Scholar] [CrossRef]
- Hu, Y.; Jiang, Z.; Zhu, K. An Optimized CNN Model for Engagement Recognition in an E-Learning Environment. Appl. Sci. 2022, 12, 8007. [Google Scholar] [CrossRef]
- Pereira, D.; Assunção Flores, M.; Barros, A. Perceptions of Portuguese undergraduate students about assessment: A study in five public universities. Educ. Stud. 2017, 43, 442–463. [Google Scholar] [CrossRef]
- Sambell, K.; McDowell, L.; Brown, S. “But is it fair?”: An exploratory study of student perceptions of the consequential validity of assessment. Stud. Educ. Eval. 1997, 23, 349–371. [Google Scholar] [CrossRef]
- Zepke, N. Student engagement in neo-liberal times: What is missing? High. Educ. Res. Dev. 2018, 37, 433–446. [Google Scholar] [CrossRef]
- Bosch, N. Detecting student engagement: Human versus machine. In Proceedings of the UMAP 2016: Conference on User Modeling Adaptation and Personalization, Halifax, NS, Canada, 13–17 July 2016; pp. 317–320. [Google Scholar] [CrossRef]
- D’Mello, S.K.; Craig, S.D.; Graesser, A.C. Multimethod assessment of affective experience and expression during deep learning. Int. J. Learn. Technol. 2009, 4, 165. [Google Scholar] [CrossRef]
- Monkaresi, H.; Bosch, N.; Calvo, R.A.; D’Mello, S.K. Automated Detection of Engagement Using Video-Based Estimation of Facial Expressions and Heart Rate. IEEE Trans. Affect. Comput. 2017, 8, 15–28. [Google Scholar] [CrossRef]
- Whitehill, J.; Serpell, Z.; Lin, Y.C.; Foster, A.; Movellan, J.R. The faces of engagement: Automatic recognition of student engagement from facial expressions. IEEE Trans. Affect. Comput. 2014, 5, 86–98. [Google Scholar] [CrossRef]
- Booth, B.M.; Ali, A.M.; Narayanan, S.S.; Bennett, I.; Farag, A.A. Toward active and unobtrusive engagement assessment of distance learners. In Proceedings of the 2017 7th International Conference on Affective Computing and Intelligent Interaction, ACII, San Antonio, TX, USA, 23–26 October 2017; pp. 470–476. [Google Scholar] [CrossRef]
- Yang, D.; Alsadoon, A.; Prasad, P.C.; Singh, A.K.; Elchouemi, A. An Emotion Recognition Model Based on Facial Recognition in Virtual Learning Environment. Procedia Comput. Sci. 2018, 125, 2–10. [Google Scholar] [CrossRef]
- Sharmila, S.; Kalaivani, A. Automatic Facial Emotion Analysis System for Student in Classroom Environment. Int. J. Pure Appl. Math. 2018, 119, 2887–2894. [Google Scholar]
- Sahla, K.S.; Senthil Kumar, T. Classroom teaching assessment based on student emotions. Adv. Intell. Syst. Comput. 2016, 530, 475–486. [Google Scholar] [CrossRef]
- Pan, M. Modelling Study on Learning Affects for Classroom Teaching/Learning Auto-Evaluation. Sci. J. Educ. 2018, 6, 81. [Google Scholar] [CrossRef]
- Xing, H.; Xiao, Z.; Qu, R.; Zhu, Z.; Zhao, B. An Efficient Federated Distillation Learning System for Multitask Time Series Classification. IEEE Trans. Instrum. Meas. 2022, 71, 2517012. [Google Scholar] [CrossRef]
- Xiao, Z.; Xu, X.; Xing, H.; Luo, S.; Dai, P.; Zhan, D. RTFN: A robust temporal feature network for time series classification. Inf. Sci. 2021, 571, 65–86. [Google Scholar] [CrossRef]
- Xiao, Z.; Zhang, H.; Tong, H.; Xu, X. An Efficient Temporal Network with Dual Self-Distillation for Electroencephalography Signal Classification. In Proceedings of the 2022 IEEE International Conference on Bioinformatics and Biomedicine, BIBM 2022, Las Vegas, NV, USA, 6–8 December 2022; pp. 1759–1762. [Google Scholar]
- Raca, M.; Kidzí, Ł.; Dillenbourg, P. Translating head motion into attention-towards processing of student’s body-language. In Proceedings of the 8th International Conference on Educational Data Mining, Madrid, Spain, 26–29 June 2015; pp. 320–326. [Google Scholar]
- Thomas, C.; Jayagopi, D.B. Predicting student engagement in classrooms using facial behavioral cues. In Proceedings of the MIE 2017: Proceedings of the 1st ACM SIGCHI International Workshop on Multimodal Interaction for Education, Co-located with ICMI 2017, Glasgow, UK, 13 November 2017; pp. 33–40. [Google Scholar] [CrossRef]
- Gupta, A.; D’Cunha, A.; Awasthi, K.; Balasubramanian, V. DAiSEE: Towards User Engagement Recognition in the Wild. arXiv 2016, arXiv:1609.01885. [Google Scholar]
- Dhall, A.; Sharma, G.; Goecke, R.; Gedeon, T. EmotiW 2020: Driver Gaze, Group Emotion, Student Engagement and Physiological Signal based Challenges. In Proceedings of the 2020 International Conference on Multimodal Interaction—ICMI 2020, Utrecht, The Netherlands, 25–29 October 2020; pp. 784–789. [Google Scholar] [CrossRef]
- Beşoluk, Ş. Morningness-eveningness preferences and university entrance examination scores of high school students. Personal. Individ. Differ. 2011, 50, 248–252. [Google Scholar] [CrossRef]
- Tison, E.B.; Bateman, T.; Culver, S.M. Examination of the gender-student engagement relationship at one university. Assess. Eval. High. Educ. 2011, 36, 27–49. [Google Scholar] [CrossRef]
- Akram, N.; Khan, N.; Ameen, M.; Mahmood, S.; Shamim, K.; Amin, M.; Rana, Q.U.A. Morningness-eveningness preferences, learning approach and academic achievement of undergraduate medical students. Chronobiol. Int. 2018, 35, 1262–1268. [Google Scholar] [CrossRef] [PubMed]
- Minoofam, S.A.H.; Bastanfard, A.; Keyvanpour, M.R. RALF: An adaptive reinforcement learning framework for teaching dyslexic students. Multimed. Tools Appl. 2022, 81, 6389–6412. [Google Scholar] [CrossRef]
- Bastanfard, A.; Rezaei, N.A. System for Hearing Impaired Children; Springer: Berlin/Heidelberg, Germany, 2010; pp. 705–715. [Google Scholar]
- Ciregan, D.; Meier, U.; Schmidhuber, J. Multi-column deep neural networks for image classification. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 3642–3649. [Google Scholar] [CrossRef]
- Zhang, Y.; Gao, J.; Zhou, H. Breeds Classification with Deep Convolutional Neural Network. In Proceedings of the ICMLC 2020: Proceedings of the 2020 12th International Conference on Machine Learning and Computing, Shenzhen, China, 15–17 February 2020; pp. 145–151. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015—Conference Track Proceedings, San Diego, CA, USA, 7–9 May 2015; pp. 1–14. [Google Scholar]
- Zellner, A.; Kmenta, J.; Dreze, J. Specification and Estimation of Cobb-Douglas Production Function Models. Econometrica J. Econom. Soc. 1966, 34, 784–795. [Google Scholar] [CrossRef]
- Qureshi, I.; Yan, J.; Abbas, Q.; Shaheed, K.; Riaz, A.B.; Wahid, A.; Khan, M.W.J.; Szczuko, P. Medical image segmentation using deep semantic-based methods: A review of techniques, applications and emerging trends. Inf. Fusion 2022, 90, 316–352. [Google Scholar] [CrossRef]










| Hyperparameter | Optimal Value |
|---|---|
| Learning Rate | 0.001 |
| Batch Size | 16 |
| Epochs | 50 |
| Weight Decay | 0.0005 |
| Dropout Rate | 0.3 |
| Activation Function | ReLU |
| Optimizer | Adam |
| Training Platform | Training Time (h) | Testing Accuracy (%) | Testing Time |
|---|---|---|---|
| Google-Colab-Pro (16 GB GPU, 25 GB memory, 147 GB storage) | 1 | Accuracy 0.90 Precision 0.93 Recall 0.93 F-measure 0.93 | 6 s/frame |
| Year | Classifier/Method | Affective States | Accuracy | Offline Classroom Environment |
|---|---|---|---|---|
| 2014 [35] | Linear regression, multinomial logistic regression | not engaged, nominally engaged, engaged, very engaged | Not Reported | × |
| 2015 [44] | SVM | low, medium, and high attention levels | 62% | √ |
| 2017 [45] | SVM, logistic regression | engaged and distracted | 90% | × |
| 2019 [12] | CNN | not engaged, normally engaged, and highly engaged | 89% | × |
| 2020 [23] | Inception v3 | engaged, non-engaged, neutral | 86% | × |
| 2021 [21] | LSTM and TCN, fully connected neural network, SVM, and RF | low-level, high-level engagement | 63% | × |
| 2021 [22] | Neural Turing Machine | completely disengaged, barely engaged, engaged, and highly engaged | 61% | × |
| Proposed method | VGG16 (Extended layers) | engaged, non-engaged | 90% | √ |
| Experiments | Independent Variable | Dependent Variable | Results | |
|---|---|---|---|---|
| 1 | Class A: MorningMale (1) vs. EveningMale (0) students with engagement | Session | Engagement | No significant impact |
| 2 | Class A: MorningMale (1) vs. EveningMale (0) students with non-engagement | Session | Non-Engagement | Male students decrease non-engagement in the morning session |
| 3 | Class B: MorningMale (1) EveningMale (0) students with engagement | Session | Engagement | Male students increase engagement in the morning session |
| 4 | Class B: MorningMale (1) EveningMale (0) students with non-engagement | Session | Non-Engagement | Male students decrease non-engagement in the morning session |
| 5 | Class A: MorningFemale (1) vs. EveningFemale (0) students with engagement | Session | Engagement | No significant impact |
| 6 | Class A: MorningFemale (1) vs. EveningFemale (0) students with non-engagement | Session | Non-Engagement | No significant impact |
| 7 | Class B: MorningFemale (1) vs. EveningFemale (0) students with engagement | Session | Engagement | No significant impact |
| 8 | Class B: MorningFemale (1) vs. EveningFemale (0) students with non-engagement | Session | Non-Engagement | No significant impact |
| 9 | All MorningMale (1) vs. EveningMale (0) students with engagement | Session | Engagement | Male students increase engagement in the morning session |
| 10 | All MorningMale (1) vs. EveningMale (0) students with non-engagement | Session | Non-Engagement | Male students decrease non-engagement in the morning session |
| 11 | All MorningFemale (1) vs. EveningFemale (0) students with engagement | Session | Engagement | No significant impact |
| 12 | All MorningFemale (1) vs. EveningFemale (0) students with non-engagement | Session | Non-Engagement | No significant impact |
| 13 | All Morning (1) vs. all Evening (0) students with engagement | Session | Engagement | Engagement increases in the morning |
| 14 | All Morning(1) vs. all Evening(0) students with non-engagement | Session | Non-Engagement | Non-engagement decreases in the morning |
| Independent Variable | Dependent Variable | Const. | Coefficient | Std. Err | Z Value | Prob | Test |
|---|---|---|---|---|---|---|---|
| Session | Non-engaged | 2.782804 | −0.1842965 | 0.0639207 | −2.88 | 0.004 | PR |
| 2.782804 | −0.1842965 | 0.0677216 | −2.72 | 0.007 | NBR |
| Experiments | Independent Variable | Dependent Variable | Results | |
|---|---|---|---|---|
| 1 | All MorningMale (1) vs. all MorningFemale (0) students with engagement | Gender | Engagement | No significant impact |
| 2 | All Morning(1) vs. all Evening(0) students with non-engagement | Gender | Non-Engagement | No significant impact |
| 3 | All EveningMale (1) vs. all EveningFemale (0) students with engagement | Gender | Engagement | Male students decrease engagement as compared to female |
| 4 | All EveningMale (1) vs. all EveningFemale (0) students with non-engagement | Gender | Non-Engagement | No significant impact |
| 5 | All Males (1) vs. All Females (0) with engagement | Gender | Engagement | Male students decrease engagement as compared to female |
| 6 | All Males (1) vs. All Females (0) with non-engagement | Gender | Non-Engagement | No significant impact |
| Independent Variable | Dependent Variable | Const. | Coefficient | Std. Err | Z Value | Prob | Test |
|---|---|---|---|---|---|---|---|
| Session | Engaged | 3.447717 | 0.1011712 | 0.0417288 | 2.42 | 0.015 | PR |
| 3.447717 | 0.1011712 | 0.0473721 | 2.14 | 0.033 | NBR |
| Model | Epochs | ACC |
|---|---|---|
| VGG16 | 40 | 79 |
| AlexNet | 40 | 81.3 |
| InceptionV3 | 40 | 82.7 |
| GoogleNet | 40 | 83.5 |
| Xception | 40 | 82.4 |
| MobileNet | 40 | 84.3 |
| SqueezeNet | 40 | 87.6 |
| Proposed VGG-16 | 40 | 90.01 |
| Independent Variable | Dependent Variable | Const. | Coefficient | Std. Err | Z Value | Prob | Test |
|---|---|---|---|---|---|---|---|
| Session | engaged | 3.568845 | −0.0985885 | 0.0417993 | −2.36 | 0.018 | PR |
| 3.568845 | −0.0985885 | 0.0520437 | −1.89 | 0.058 | NBR |
| Model | Disadvantages |
|---|---|
| SVM | -Limited ability to capture complex relationships in data |
| -Requires feature engineering | |
| -May struggle with large-scale datasets | |
| Random Forest | -Can be computationally expensive |
| -May require tuning of hyperparameters | |
| -Prone to overfitting with noisy or imbalanced datasets | |
| Neural Networks | -Requires large amounts of labeled training data |
| -Computationally intensive, especially for deep architectures | |
| -Prone to overfitting without proper regularization | |
| CNN | -Requires large amounts of labeled training data |
| (Convolutional | -Computationally intensive, especially for deep architectures |
| Neural Networks) | -Prone to overfitting without proper regularization |
| LSTM | -Requires longer training times |
| -Can be more complex to implement compared to other models | |
| -Prone to vanishing/exploding gradient problems | |
| InceptionV3 | -May not perform as well with limited training data |
| -Can be computationally expensive for real-time applications | |
| -Limited ability to model long-term temporal dependencies | |
| Compare to original VGG16, we have provided the following benefits of the proproposed VGG16-dense architecture as follows: | |
| VGG16-Dense | -Deep architecture for capturing intricate image features |
| -Transfer learning capabilities | |
| -Suitable for image-based tasks | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ikram, S.; Ahmad, H.; Mahmood, N.; Faisal, C.M.N.; Abbas, Q.; Qureshi, I.; Hussain, A. Recognition of Student Engagement State in a Classroom Environment Using Deep and Efficient Transfer Learning Algorithm. Appl. Sci. 2023, 13, 8637. https://doi.org/10.3390/app13158637
Ikram S, Ahmad H, Mahmood N, Faisal CMN, Abbas Q, Qureshi I, Hussain A. Recognition of Student Engagement State in a Classroom Environment Using Deep and Efficient Transfer Learning Algorithm. Applied Sciences. 2023; 13(15):8637. https://doi.org/10.3390/app13158637
Chicago/Turabian StyleIkram, Sana, Haseeb Ahmad, Nasir Mahmood, C. M. Nadeem Faisal, Qaisar Abbas, Imran Qureshi, and Ayyaz Hussain. 2023. "Recognition of Student Engagement State in a Classroom Environment Using Deep and Efficient Transfer Learning Algorithm" Applied Sciences 13, no. 15: 8637. https://doi.org/10.3390/app13158637
APA StyleIkram, S., Ahmad, H., Mahmood, N., Faisal, C. M. N., Abbas, Q., Qureshi, I., & Hussain, A. (2023). Recognition of Student Engagement State in a Classroom Environment Using Deep and Efficient Transfer Learning Algorithm. Applied Sciences, 13(15), 8637. https://doi.org/10.3390/app13158637