
Improving Monocular Camera Localization for Video-Based Three-Dimensional Outer Ear Reconstruction Tasks
 ,
,  , , , , , and
, , , , , and {kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
- Proposed a simple solution for the improvement of camera 3D localization for the ear 3D reconstruction tasks. The proposed solution is based on enriching the background texture.
- Presented a dataset construction approach for the evaluation of camera 3D localization.
- Performed comparative evaluation of different cap textures’ influence on the precision of camera 3D localization.
- Presented comparative results of camera 3D localization improvement solutions; the results show that the proposed method is effective and using a cap with texture allows a reduction in camera localization error. The results also show that caps with sparse dot patterns and a regular knitted patterned winter hat are the preferred patterns.
2. Materials and Methods
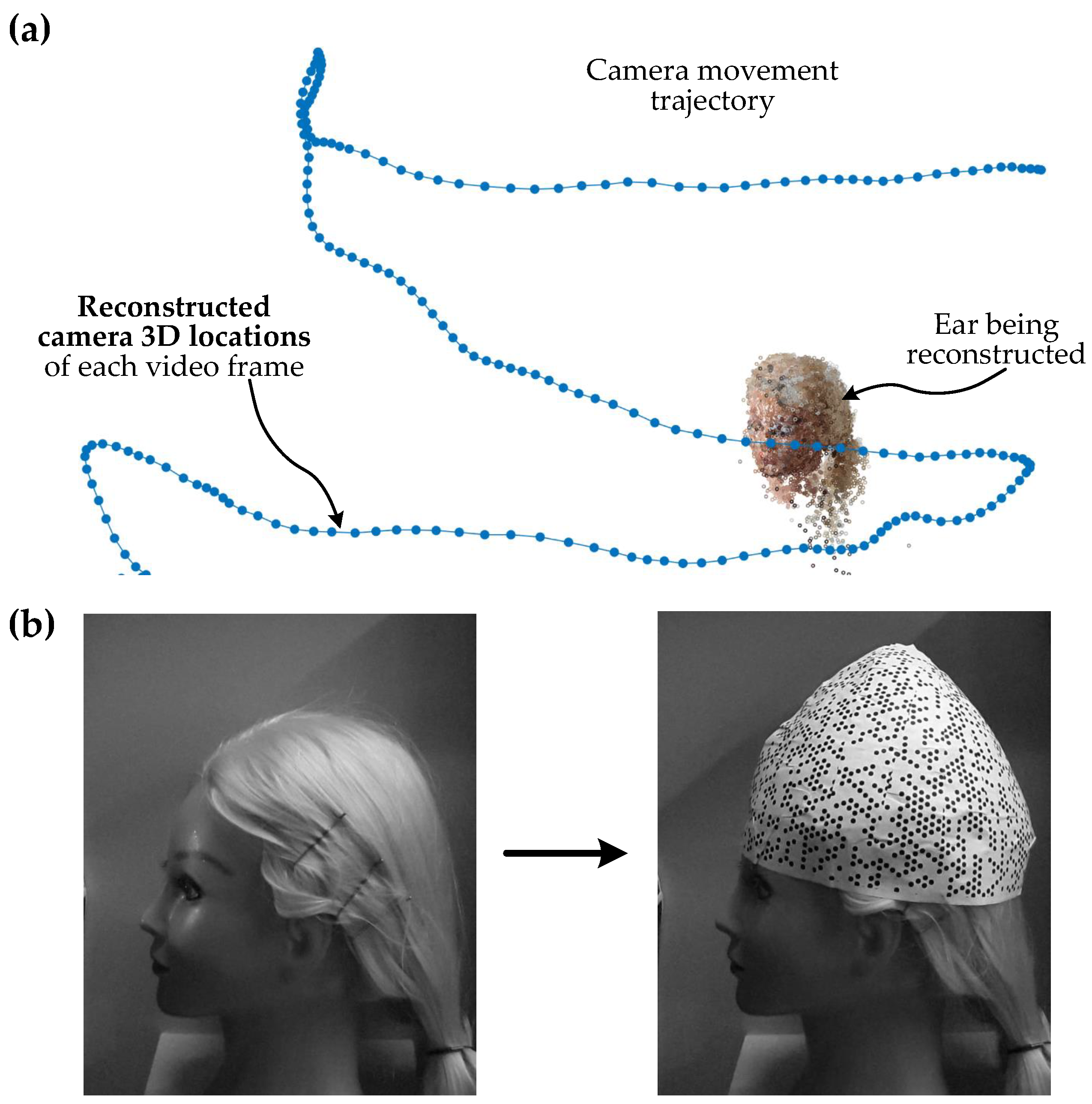
2.1. Improvement of Camera 3D Localization
2.2. Experimental Scenarios
- No cap—regular case of image collection for ear reconstruction;
- Dots 1—regularly arranged dot pattern of the 1st size;
- Dots 1s—sparse dot pattern of the 1st size;
- Dots 2—regularly arranged dot pattern of the 2nd size;
- Dots 2s—sparse dot pattern of the 2nd size;
- Dots 3—regularly arranged dot pattern of the 3rd size;
- Dots 3s—sparse dot pattern of the 3rd size;
- Dots 4—regularly arranged dot pattern of the 4th size;
- Dots 4s—sparse dot pattern of the 4th size;
- Painted blobs—pattern of randomly painted blobs of different sizes;
- Checkerboard—a well-known pattern used for camera calibration;
- Printed irreg.—printed pattern of irregularly scattered small dots;
- Winter hat—a regular knitted patterned winter hat.
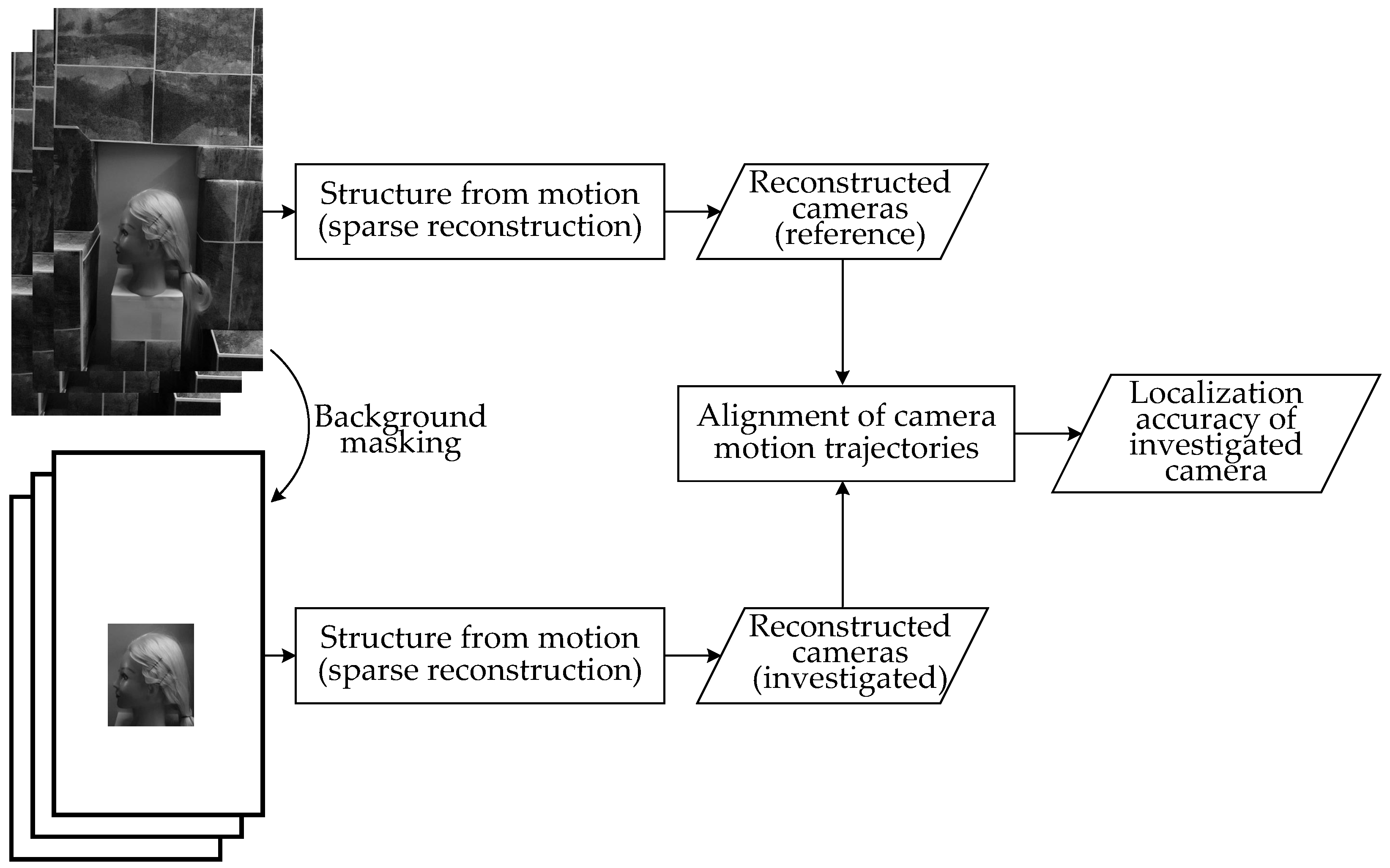
2.3. Camera Localization Quality Evaluation
2.4. Software Used
- MATLAB programming and numeric computing platform (version R2022a, The Mathworks Inc., Natick, MA, USA) for the implementation of the introduced improvements to the baseline reconstruction algorithm by integrating with AliceVision/Meshroom; MATLAB was also used for data analysis and visualization;
- Meshroom (version 2021.1.0) (https://alicevision.org accessed on 15 September 2022) [80], 3D reconstruction software based on the AliceVision photogrammetric computer vision framework. Used for the execution of the SfM reconstruction algorithms;
2.5. Setup and Data Collection
3. Results and Discussion
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| SfM | Structure-from-motion |
| HRTF | Head-related transfer function |
| ITD | Interaural time difference |
| ILD | Interaural level difference |
| DNN | Deep neural network |
| MAA | Minimum audible angle |
| BBox | Bounding box |
References
- Algazi, V.R.; Avendano, C.; Duda, R.O. Elevation localization and head-related transfer function analysis at low frequencies. J. Acoust. Soc. Am. 2001, 109, 1110–1122. [Google Scholar] [CrossRef]
- Brinkmann, F.; Dinakaran, M.; Pelzer, R.; Grosche, P.; Voss, D.; Weinzierl, S. A cross-evaluated database of measured and simulated HRTFs including 3D head meshes, anthropometric features, and headphone impulse responses. J. Audio Eng. Soc. 2019, 67, 705–718. [Google Scholar] [CrossRef]
- Ziegelwanger, H.; Reichinger, A.; Majdak, P. Calculation of listener-specific head-related transfer functions: Effect of mesh quality. In Proceedings of the Meetings on Acoustics ICA2013, Montreal, QC, Canada, 2–7 June 2013; Volume 19, p. 050017. [Google Scholar]
- Møller, H.; Sørensen, M.F.; Hammershøi, D.; Jensen, C.B. Head-related transfer functions of human subjects. J. Audio Eng. Soc. 1995, 43, 300–321. [Google Scholar]
- Stitt, P.; Katz, B.F. Sensitivity analysis of pinna morphology on head-related transfer functions simulated via a parametric pinna model. J. Acoust. Soc. Am. 2021, 149, 2559–2572. [Google Scholar] [CrossRef] [PubMed]
- Thavam, S.; Dietz, M. Smallest perceivable interaural time differences. J. Acoust. Soc. Am. 2019, 145, 458–468. [Google Scholar] [CrossRef]
- Pollack, K.; Majdak, P.; Kreuzer, W. Modern acquisition of personalised head-related transfer functions: An overview. In Advances in Fundamental and Applied Research on Spatial Audio; BoD—Books on Demand: Norderstedt, Germany, 2022. [Google Scholar]
- Aggius-Vella, E.; Kolarik, A.J.; Gori, M.; Cirstea, S.; Campus, C.; Moore, B.C.; Pardhan, S. Comparison of auditory spatial bisection and minimum audible angle in front, lateral, and back space. Sci. Rep. 2020, 10, 6279. [Google Scholar] [CrossRef] [Green Version]
- Wilson, J.; Walker, B.N.; Lindsay, J.; Cambias, C.; Dellaert, F. Swan: System for wearable audio navigation. In Proceedings of the 2007 11th IEEE International Symposium on Wearable Computers, Boston, MA, USA, 11–13 October 2007; pp. 91–98. [Google Scholar]
- Guezenoc, C.; Seguier, R. HRTF individualization: A survey. arXiv 2020, arXiv:2003.06183. [Google Scholar]
- Wenzel, E.M.; Arruda, M.; Kistler, D.J.; Wightman, F.L. Localization using nonindividualized head-related transfer functions. J. Acoust. Soc. Am. 1993, 94, 111–123. [Google Scholar] [CrossRef]
- Yu, G.; Wu, R.; Liu, Y.; Xie, B. Near-field head-related transfer-function measurement and database of human subjects. J. Acoust. Soc. Am. 2018, 143, EL194–EL198. [Google Scholar] [CrossRef]
- Reijniers, J.; Partoens, B.; Steckel, J.; Peremans, H. HRTF measurement by means of unsupervised head movements with respect to a single fixed speaker. IEEE Access 2020, 8, 92287–92300. [Google Scholar] [CrossRef]
- Yang, Z.; Choudhury, R.R. Personalizing head related transfer functions for earables. In Proceedings of the 2021 ACM SIGCOMM 2021 Conference, Virtual Event, 23–27 August 2021; pp. 137–150. [Google Scholar]
- Zotkin, D.; Hwang, J.; Duraiswaini, R.; Davis, L.S. HRTF personalization using anthropometric measurements. In Proceedings of the 2003 IEEE Workshop on Applications of Signal Processing to Audio and Acoustics (IEEE Cat. No. 03TH8684), New Paltz, NY, USA, 19–22 October 2003; pp. 157–160. [Google Scholar]
- Lu, D.; Zeng, X.; Guo, X.; Wang, H. Personalization of head-related transfer function based on sparse principle component analysis and sparse representation of 3D anthropometric parameters. Acoust. Aust. 2020, 48, 49–58. [Google Scholar] [CrossRef]
- Guo, Z.; Lu, Y.; Zhou, H.; Li, Z.; Fan, Y.; Yu, G. Anthropometric-based clustering of pinnae and its application in personalizing HRTFs. Int. J. Ind. Ergon. 2021, 81, 103076. [Google Scholar] [CrossRef]
- Dinakaran, M.; Brinkmann, F.; Harder, S.; Pelzer, R.; Grosche, P.; Paulsen, R.R.; Weinzierl, S. Perceptually motivated analysis of numerically simulated head-related transfer functions generated by various 3D surface scanning systems. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 551–555. [Google Scholar]
- Dellepiane, M.; Pietroni, N.; Tsingos, N.; Asselot, M.; Scopigno, R. Reconstructing head models from photographs for individualized 3D-audio processing. In Proceedings of the Computer Graphics Forum; Blackwell Publishing Ltd.: Oxford, UK, 2008; Volume 27, pp. 1719–1727. [Google Scholar]
- Trojnacki, M.; Dąbek, P.; Jaroszek, P. Analysis of the Influence of the Geometrical Parameters of the Body Scanner on the Accuracy of Reconstruction of the Human Figure Using the Photogrammetry Technique. Sensors 2022, 22, 9181. [Google Scholar] [CrossRef]
- Ziegelwanger, H.; Kreuzer, W.; Majdak, P. Mesh2hrtf: Open-source software package for the numerical calculation of head-related transfer functions. In Proceedings of the 22nd International Congress on Sound and Vibration, Florence, Italy, 12–16 July 2015. [Google Scholar]
- Lee, G.W.; Kim, H.K. Personalized HRTF modeling based on deep neural network using anthropometric measurements and images of the ear. Appl. Sci. 2018, 8, 2180. [Google Scholar] [CrossRef] [Green Version]
- Lu, D.; Zeng, X.; Guo, X.; Wang, H. Head-related Transfer Function Reconstruction with Anthropometric Parameters and the Direction of the Sound Source: Deep Learning-Based Head-Related Transfer Function Personalization. Acoust. Aust. 2021, 49, 125–132. [Google Scholar] [CrossRef]
- Cintas, C.; Quinto-Sánchez, M.; Acuña, V.; Paschetta, C.; De Azevedo, S.; Cesar Silva de Cerqueira, C.; Ramallo, V.; Gallo, C.; Poletti, G.; Bortolini, M.C.; et al. Automatic ear detection and feature extraction using geometric morphometrics and convolutional neural networks. IET Biom. 2017, 6, 211–223. [Google Scholar] [CrossRef]
- Ban, K.; Jung, E.S. Ear shape categorization for ergonomic product design. Int. J. Ind. Ergon. 2020, 80, 102962. [Google Scholar] [CrossRef]
- Wang, X.; Liu, B.; Dong, Y.; Pang, S.; Tao, X. Anthropometric Landmarks Extraction and Dimensions Measurement Based on ResNet. Symmetry 2020, 12, 1997. [Google Scholar] [CrossRef]
- Varna, D.; Abromavičius, V. A System for a Real-Time Electronic Component Detection and Classification on a Conveyor Belt. Appl. Sci. 2022, 12, 5608. [Google Scholar] [CrossRef]
- Sledevič, T.; Serackis, A.; Plonis, D. FPGA Implementation of a Convolutional Neural Network and Its Application for Pollen Detection upon Entrance to the Beehive. Agriculture 2022, 12, 1849. [Google Scholar] [CrossRef]
- Matuzevicius, D.; Navakauskas, D. Feature selection for segmentation of 2-D electrophoresis gel images. In Proceedings of the 2008 11th International Biennial Baltic Electronics Conference, Tallinn, Estonia, 6–8 October 2008; pp. 341–344. [Google Scholar]
- Xu, Z.; Wu, T.; Shen, Y.; Wu, L. Three dimentional reconstruction of large cultural heritage objects based on uav video and tls data. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2016, 41, 985. [Google Scholar] [CrossRef] [Green Version]
- Matuzevičius, D. Synthetic Data Generation for the Development of 2D Gel Electrophoresis Protein Spot Models. Appl. Sci. 2022, 12, 4393. [Google Scholar] [CrossRef]
- Matuzevičius, D.; Serackis, A.; Navakauskas, D. Mathematical models of oversaturated protein spots. Elektron. Elektrotechnika 2007, 73, 63–68. [Google Scholar]
- Hamzah, N.B.; Setan, H.; Majid, Z. Reconstruction of traffic accident scene using close-range photogrammetry technique. Geoinf. Sci. J. 2010, 10, 17–37. [Google Scholar]
- Caradonna, G.; Tarantino, E.; Scaioni, M.; Figorito, B. Multi-image 3D reconstruction: A photogrammetric and structure from motion comparative analysis. In Proceedings of the International Conference on Computational Science and Its Applications, Melbourne, VIC, Australia, 2–5 July 2018; Springer: Berlin/Heidelberg, Germany, 2018; pp. 305–316. [Google Scholar]
- Žuraulis, V.; Matuzevičius, D.; Serackis, A. A method for automatic image rectification and stitching for vehicle yaw marks trajectory estimation. Promet-Traffic Transp. 2016, 28, 23–30. [Google Scholar] [CrossRef] [Green Version]
- Şenol, H.İ.; Polat, N.; Yunus, K.; Memduhoğlu, A.; Ulukavak, M. Digital documentation of ancient stone carving in Şuayip City. Mersin Photogramm. J. 2021, 3, 10–14. [Google Scholar] [CrossRef]
- SARICAOĞLU, T.; Kaya, N.K. A combined use of image and range-based data acquisition for the three-dimensional information mapping archaeological heritage. Mersin Photogramm. J. 2021, 3, 1–9. [Google Scholar] [CrossRef]
- Doğan, Y.; Yakar, M. GIS and three-dimensional modeling for cultural heritages. Int. J. Eng. Geosci. 2018, 3, 50–55. [Google Scholar] [CrossRef] [Green Version]
- Genchi, S.A.; Vitale, A.J.; Perillo, G.M.; Delrieux, C.A. Structure-from-motion approach for characterization of bioerosion patterns using UAV imagery. Sensors 2015, 15, 3593–3609. [Google Scholar] [CrossRef] [Green Version]
- Mistretta, F.; Sanna, G.; Stochino, F.; Vacca, G. Structure from motion point clouds for structural monitoring. Remote Sens. 2019, 11, 1940. [Google Scholar] [CrossRef] [Green Version]
- Zeraatkar, M.; Khalili, K. A Fast and Low-Cost Human Body 3D Scanner Using 100 Cameras. J. Imaging 2020, 6, 21. [Google Scholar] [CrossRef] [Green Version]
- Straub, J.; Kerlin, S. Development of a large, low-cost, instant 3D scanner. Technologies 2014, 2, 76–95. [Google Scholar] [CrossRef]
- Straub, J.; Kading, B.; Mohammad, A.; Kerlin, S. Characterization of a large, low-cost 3D scanner. Technologies 2015, 3, 19–36. [Google Scholar] [CrossRef] [Green Version]
- Westoby, M.J.; Brasington, J.; Glasser, N.F.; Hambrey, M.J.; Reynolds, J.M. ‘Structure-from-Motion’photogrammetry: A low-cost, effective tool for geoscience applications. Geomorphology 2012, 179, 300–314. [Google Scholar] [CrossRef] [Green Version]
- Li, X.; Iyengar, S. On computing mapping of 3d objects: A survey. ACM Comput. Surv. (CSUR) 2014, 47, 1–45. [Google Scholar] [CrossRef]
- Özyeşil, O.; Voroninski, V.; Basri, R.; Singer, A. A survey of structure from motion. Acta Numer. 2017, 26, 305–364. [Google Scholar] [CrossRef]
- Matuzevičius, D.; Serackis, A. Three-Dimensional Human Head Reconstruction Using Smartphone-Based Close-Range Video Photogrammetry. Appl. Sci. 2021, 12, 229. [Google Scholar] [CrossRef]
- Trujillo-Jiménez, M.A.; Navarro, P.; Pazos, B.; Morales, L.; Ramallo, V.; Paschetta, C.; De Azevedo, S.; Ruderman, A.; Pérez, O.; Delrieux, C.; et al. body2vec: 3D Point Cloud Reconstruction for Precise Anthropometry with Handheld Devices. J. Imaging 2020, 6, 94. [Google Scholar] [CrossRef]
- Zhao, Y.; Mo, Y.; Sun, M.; Zhu, Y.; Yang, C. Comparison of three-dimensional reconstruction approaches for anthropometry in apparel design. J. Text. Inst. 2019, 110, 1635–1643. [Google Scholar] [CrossRef]
- Iglhaut, J.; Cabo, C.; Puliti, S.; Piermattei, L.; O’Connor, J.; Rosette, J. Structure from motion photogrammetry in forestry: A review. Curr. For. Rep. 2019, 5, 155–168. [Google Scholar] [CrossRef] [Green Version]
- Yakar, M.; Dogan, Y. 3D Reconstruction of Residential Areas with SfM Photogrammetry. In Proceedings of the Advances in Remote Sensing and Geo Informatics Applications: Proceedings of the 1st Springer Conference of the Arabian Journal of Geosciences (CAJG-1), Hammamet, Tunisia, 12–15 November 2018; Springer: Berlin/Heidelberg, Germany, 2019; pp. 73–75. [Google Scholar]
- Leipner, A.; Obertová, Z.; Wermuth, M.; Thali, M.; Ottiker, T.; Sieberth, T. 3D mug shot—3D head models from photogrammetry for forensic identification. Forensic Sci. Int. 2019, 300, 6–12. [Google Scholar] [CrossRef] [PubMed]
- Wei, Y.m.; Kang, L.; Yang, B.; Wu, L.D. Applications of structure from motion: A survey. J. Zhejiang Univ. SCIENCE C 2013, 14, 486–494. [Google Scholar] [CrossRef]
- Duran, Z.; Atik, M.E. Accuracy comparison of interior orientation parameters from different photogrammetric software and direct linear transformation method. Int. J. Eng. Geosci. 2021, 6, 74–80. [Google Scholar] [CrossRef]
- Barbero-García, I.; Pierdicca, R.; Paolanti, M.; Felicetti, A.; Lerma, J.L. Combining machine learning and close-range photogrammetry for infant’s head 3D measurement: A smartphone-based solution. Measurement 2021, 182, 109686. [Google Scholar] [CrossRef]
- Barbero-García, I.; Lerma, J.L.; Mora-Navarro, G. Fully automatic smartphone-based photogrammetric 3D modelling of infant’s heads for cranial deformation analysis. ISPRS J. Photogramm. Remote Sens. 2020, 166, 268–277. [Google Scholar] [CrossRef]
- Lerma, J.L.; Barbero-García, I.; Marqués-Mateu, Á.; Miranda, P. Smartphone-based video for 3D modelling: Application to infant’s cranial deformation analysis. Measurement 2018, 116, 299–306. [Google Scholar] [CrossRef] [Green Version]
- Barbero-García, I.; Cabrelles, M.; Lerma, J.L.; Marqués-Mateu, Á. Smartphone-based close-range photogrammetric assessment of spherical objects. Photogramm. Rec. 2018, 33, 283–299. [Google Scholar] [CrossRef] [Green Version]
- Fawzy, H.E.D. The accuracy of mobile phone camera instead of high resolution camera in digital close range photogrammetry. Int. J. Civ. Eng. Technol. (IJCIET) 2015, 6, 76–85. [Google Scholar]
- Tamulionis, M.; Sledevič, T.; Abromavičius, V.; Kurpytė-Lipnickė, D.; Navakauskas, D.; Serackis, A.; Matuzevičius, D. Finding the Least Motion-Blurred Image by Reusing Early Features of Object Detection Network. Appl. Sci. 2023, 13, 1264. [Google Scholar] [CrossRef]
- Yao, G.; Huang, P.; Ai, H.; Zhang, C.; Zhang, J.; Zhang, C.; Wang, F. Matching wide-baseline stereo images with weak texture using the perspective invariant local feature transformer. J. Appl. Remote Sens. 2022, 16, 036502. [Google Scholar] [CrossRef]
- Wei, L.; Huo, J. A Global fundamental matrix estimation method of planar motion based on inlier updating. Sensors 2022, 22, 4624. [Google Scholar] [CrossRef] [PubMed]
- Ma, J.; Jiang, X.; Fan, A.; Jiang, J.; Yan, J. Image matching from handcrafted to deep features: A survey. Int. J. Comput. Vis. 2021, 129, 23–79. [Google Scholar] [CrossRef]
- Zhang, L.; Wang, Q.; Lu, H.; Zhao, Y. End-to-end learning of multi-scale convolutional neural network for stereo matching. In Proceedings of the Asian Conference on Machine Learning, PMLR, Beijing, China, 14–16 November 2018; pp. 81–96. [Google Scholar]
- Jiang, X.; Ma, J.; Xiao, G.; Shao, Z.; Guo, X. A review of multimodal image matching: Methods and applications. Inf. Fusion 2021, 73, 22–71. [Google Scholar] [CrossRef]
- Fu, Y.; Lei, Y.; Wang, T.; Curran, W.J.; Liu, T.; Yang, X. Deep learning in medical image registration: A review. Phys. Med. Biol. 2020, 65, 20TR01. [Google Scholar] [CrossRef] [Green Version]
- Haskins, G.; Kruger, U.; Yan, P. Deep learning in medical image registration: A survey. Mach. Vis. Appl. 2020, 31, 1–18. [Google Scholar] [CrossRef] [Green Version]
- De Vos, B.D.; Berendsen, F.F.; Viergever, M.A.; Staring, M.; Išgum, I. End-to-end unsupervised deformable image registration with a convolutional neural network. In Proceedings of the Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support: Third International Workshop, DLMIA 2017, and 7th International Workshop, ML-CDS 2017, Held in Conjunction with MICCAI 2017, Québec City, QC, Canada, 14 September 2017; Proceedings 3. Springer: Berlin/Heidelberg, Germany, 2017; pp. 204–212. [Google Scholar]
- De Vos, B.D.; Berendsen, F.F.; Viergever, M.A.; Sokooti, H.; Staring, M.; Išgum, I. A deep learning framework for unsupervised affine and deformable image registration. Med. Image Anal. 2019, 52, 128–143. [Google Scholar] [CrossRef] [Green Version]
- Yang, X.; Kwitt, R.; Styner, M.; Niethammer, M. Quicksilver: Fast predictive image registration—A deep learning approach. NeuroImage 2017, 158, 378–396. [Google Scholar] [CrossRef]
- Zhou, T.; Brown, M.; Snavely, N.; Lowe, D.G. Unsupervised learning of depth and ego-motion from video. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1851–1858. [Google Scholar]
- Gao, L.; Zhao, Y.; Han, J.; Liu, H. Research on multi-view 3D reconstruction technology based on SFM. Sensors 2022, 22, 4366. [Google Scholar] [CrossRef]
- Sun, Q.; Tang, Y.; Zhao, C. Cycle-SfM: Joint self-supervised learning of depth and camera motion from monocular image sequences. Chaos Interdiscip. J. Nonlinear Sci. 2019, 29, 123102. [Google Scholar] [CrossRef]
- Klodt, M.; Vedaldi, A. Supervising the new with the old: Learning sfm from sfm. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 698–713. [Google Scholar]
- Acharya, D.; Khoshelham, K.; Winter, S. BIM-PoseNet: Indoor camera localisation using a 3D indoor model and deep learning from synthetic images. ISPRS J. Photogramm. Remote Sens. 2019, 150, 245–258. [Google Scholar] [CrossRef]
- Fraser, C.S. Automatic camera calibration in close range photogrammetry. Photogramm. Eng. Remote Sens. 2013, 79, 381–388. [Google Scholar] [CrossRef] [Green Version]
- Yi, G.; Jianxin, L.; Hangping, Q.; Bo, W. Survey of structure from motion. In Proceedings of the 2014 International Conference on Cloud Computing and Internet of Things, Changchun, China, 13–14 December 2014; pp. 72–76. [Google Scholar]
- Battistoni, G.; Cassi, D.; Magnifico, M.; Pedrazzi, G.; Di Blasio, M.; Vaienti, B.; Di Blasio, A. Does Head Orientation Influence 3D Facial Imaging? A Study on Accuracy and Precision of Stereophotogrammetric Acquisition. Int. J. Environ. Res. Public Health 2021, 18, 4276. [Google Scholar] [CrossRef] [PubMed]
- Nikolov, I.; Madsen, C.B. Calculating Absolute Scale and Scale Uncertainty for SfM Using Distance Sensor Measurements: A Lightweight and Flexible Approach. In Recent Advances in 3D Imaging, Modeling, and Reconstruction; IGI Global: Hershey, PA, USA, 2020; pp. 168–192. [Google Scholar]
- Griwodz, C.; Gasparini, S.; Calvet, L.; Gurdjos, P.; Castan, F.; Maujean, B.; Lillo, G.D.; Lanthony, Y. AliceVision Meshroom: An open-source 3D reconstruction pipeline. In Proceedings of the 12th ACM Multimedia Systems Conference—MMSys ’21, Istanbul, Turkey, 28 September–1 October 2021; ACM Press: New York, NY, USA, 2021. [Google Scholar] [CrossRef]


Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tamulionis, M.; Serackis, A.; Bartnykas, K.; Miniotas, D.; Mikučionis, Š.; Laptik, R.; Ušinskas, A.; Matuzevičius, D. Improving Monocular Camera Localization for Video-Based Three-Dimensional Outer Ear Reconstruction Tasks. Appl. Sci. 2023, 13, 8712. https://doi.org/10.3390/app13158712
Tamulionis M, Serackis A, Bartnykas K, Miniotas D, Mikučionis Š, Laptik R, Ušinskas A, Matuzevičius D. Improving Monocular Camera Localization for Video-Based Three-Dimensional Outer Ear Reconstruction Tasks. Applied Sciences. 2023; 13(15):8712. https://doi.org/10.3390/app13158712
Chicago/Turabian StyleTamulionis, Mantas, Artūras Serackis, Kęstutis Bartnykas, Darius Miniotas, Šarūnas Mikučionis, Raimond Laptik, Andrius Ušinskas, and Dalius Matuzevičius. 2023. "Improving Monocular Camera Localization for Video-Based Three-Dimensional Outer Ear Reconstruction Tasks" Applied Sciences 13, no. 15: 8712. https://doi.org/10.3390/app13158712