
Research on the Small Target Recognition Method of Automobile Tire Marking Points Based on Improved YOLOv5s
Abstract
:1. Introduction
- Introduction. The research background of tire marking points and its development trend is presented through company research and literature summary.
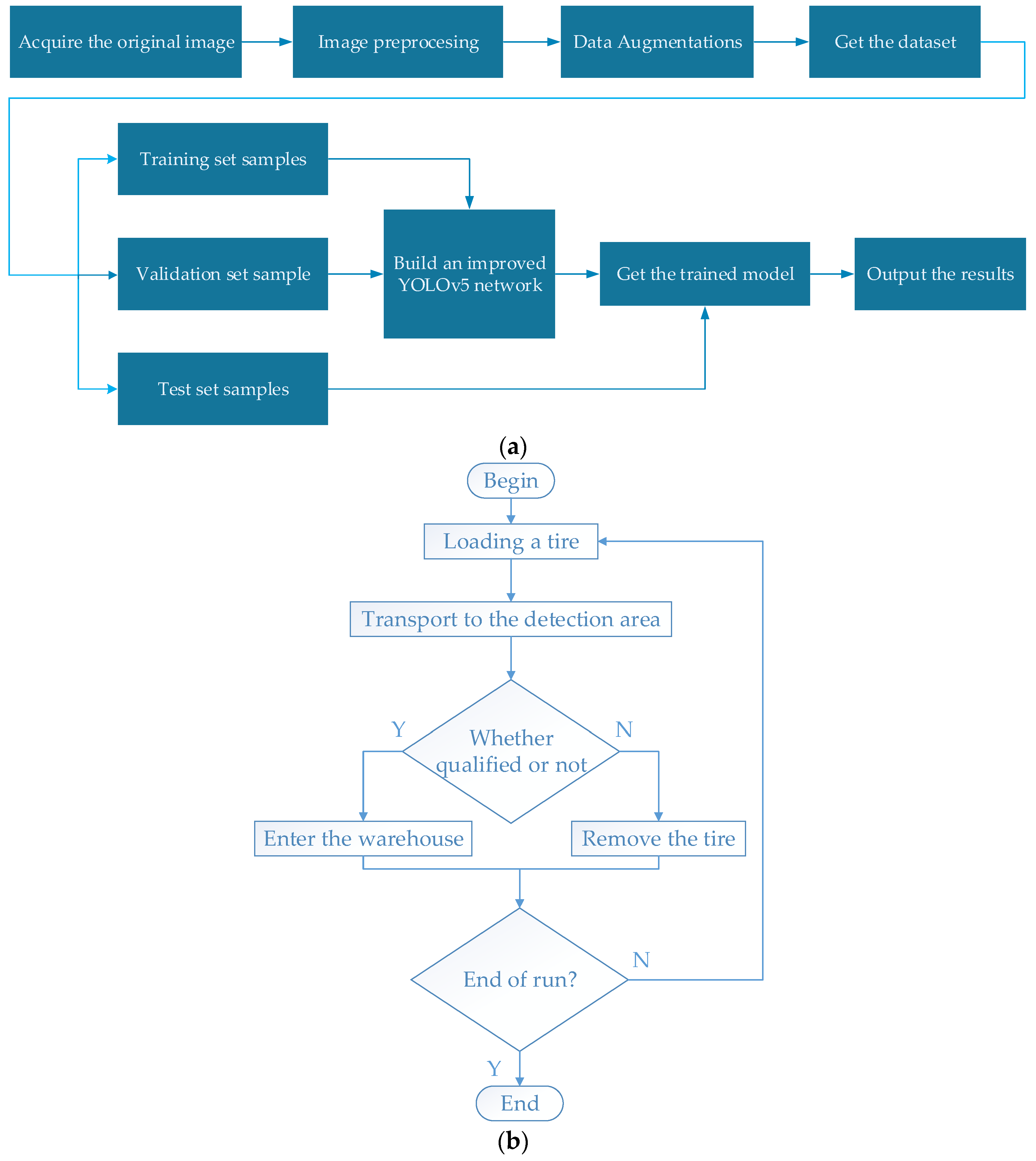
- Materials and methods. It mainly introduces the overall scheme of tire marking point recognition, the way of data collection composition, and image pre-processing to solve the influence of light, weather, and other factors.
- Tire marking point identification network structure. An improved YOLOv5s algorithm is proposed for the problem of tire marking point recognition:
- (1)
- Adding an attention mechanism
- (2)
- Loss function
- (3)
- Small target prediction head
- Model Training and Testing. To verify whether the improved algorithm is better than the original algorithm and to cerify the rationality of the improvement through ablation experiments.
- Conclusion. To summarize the whole text and draw conclusions.
2. Materials and Methods
2.1. Dataset Preparation
2.2. Image Pre-Processing
2.3. Data Enhancement
3. Tire Marking Point Identification Network Structure
3.1. YOLOv5s Model Structure
3.2. YOLOv5s Model Improvements
3.2.1. Adding an Attention Mechanism
3.2.2. Loss Function
3.2.3. Small Target Prediction Head
4. Model Training and Testing
4.1. Experimental Environment
4.2. Training Results and Analysis
4.2.1. Comparison of Experimental Data
4.2.2. SimAM Module Validation
4.2.3. Model Visualization Comparison Experiments
4.2.4. Comparison of Test Results
5. Conclusions
- In image pre-processing, the MSRCR algorithm is introduced to improve the contrast of identification points in the image, which can adapt to different environments and reduce the difficulty of model training.
- Improve YOLOv5s model by adding a small target detection head to improve the accuracy of the model for small target recognition.
- The addition of the parameter-free simAM attention mechanism, which enhances the ability of the convolutional layer to protrude features, can better improve feature information.
- The loss function CIoU of the original network is replaced by Alpha-IoU, which is more flexible than the original CIoU in updating the parameters using back propagation and reducing the loss of predicted and true values, thus optimizing the model and enabling it to have better recognition results.
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Chen, N.; Li, Y.; Xiang, T. Influence of Tire Cornering Property on Ride Comfort Evaluation of Vehicles on Bridge. J. Southwest Jiaotong Univ. 2016, 51, 645–653. [Google Scholar]
- Wang, Y.; Guo, H. Color Recognition of Tyre Marking Points Based on Support Vector Machine. J. East China Univ. Sci. Technol. Nat. Sci. Ed. 2014, 40, 520–523+532. [Google Scholar]
- Kokubu, T.; Kunitake, H. Mark Inspecting System: US. U.S. Patent 6144033A, 21 February 2001. [Google Scholar]
- SICK Sensor Inteligence. Powerful Image Processing: For Added Quality and Added Efficiency [EB/OL]. Available online: https://www.sick.com/cn/en/powerful-image-processing-for-added-quality-and-added-efficiency/w/blog-powerful-image-processing-for-added-quality-and-added-efficienc/ (accessed on 13 January 2017).
- Wang, Y. Study on Recognition Technology of Automobile Tire Marking Points; East China University of Science and Technology: Shanghai, China, 2015. [Google Scholar]
- Zhang, Q. Research on the Method of Recognition Tire Marking Points Based on Machine Vision; Beijing University of Chemical Technology: Beijing, China, 2020. [Google Scholar]
- Zhao, L. Research and Design on Tire Surface Mark Recognition System; Shenyang University of Technology: Shenyang, China, 2012. [Google Scholar]
- Zhu, Q.; Li, J.; Zhu, Y.; Li, J.; Zhang, J. Adaptive Infrared Thermal Image Enhancement Based on Retinex. Microelectron. Comput. 2013, 30, 22–25. [Google Scholar]
- Zhu, S.; Hang, R.; Liu, Q. Underwater Object Detection Based on the Class-Weighted YOLO Net. J. Nanjing Norm. Univ. Nat. Sci. Ed. 2020, 43, 129–135. [Google Scholar]
- Wang, Q.; Li, S.; Qin, H.; Hao, A. Super-Resolution of Multi-Observed RGB-D Images Based on Nonlocal Regression and Total Variation. IEEE Trans. Image Process. 2016, 25, 1425–1440. [Google Scholar] [CrossRef] [PubMed]
- Wang, Y.; Wu, Y.; Qi, B. Study on UAV spray method of intercropping farmland based on Faster RCNN. J. Chin. Agric. Mech. 2019, 40, 76–81. [Google Scholar] [CrossRef]
- Jiang, Y.; Ma, Z.; Wu, C.; Zhang, Z.; Yan, W. RSAP-Net: Joint optic disc and cup segmentation with a residual spatial attention path module and MSRCR-PT pre-processing algorithm. BMC Bioinform. 2022, 23, 523. [Google Scholar]
- Shang, Z.J.; Zhang, H.; Zeng, C.; Le, M.; Zhao, Q. Automatic orientation method and experiment of Fructus aurantii based on machine vision. J. Chin. Agric. Mech. 2019, 40, 119–124. [Google Scholar]
- Zhang, J. Research on Multi-Object Tracking Method for Airport Surface; University of Electronic Science and Technology of China: Chengdu, China, 2021. [Google Scholar]
- Zhang, Z.; Xie, F.; Chen, J.; Li, M. Intelligent Extraction Method of Image Marker Point Features Based on Improved YOLOv5 Model. Laser J. 2023, 1–8. Available online: http://kns.cnki.net/kcms/detail/50.1085.TN.20230421.0915.004.html (accessed on 27 July 2023).
- Han, Z.; Wan, J.; Liu, Z.; Liu, K. Multispectral Imaging Detection Using the Ultraviolet Fluorescence Characteristics of Oil. Chin. J. Lumin. 2015, 36, 1335–1341. [Google Scholar]
- Chen, F.; Wang, C.; Gu, M.; Zhao, Y. Spruce Image Segmentation Algorithm Based on Fully Convolutional Networks. Trans. Chin. Soc. Agric. Mach. 2018, 49, 188–194+210. [Google Scholar]
- Huang, J.; Zhang, H.; Wang, L.; Zhang, Z.; Zhao, C. Improved YOLOv3 Model for miniature camera detection. Opt. Laser Technol. 2021, 142, 107133. [Google Scholar] [CrossRef]
- Liu, L.; Hou, D.; Hou, A.; Liang, C.; Zheng, H. Automatic driving target detection algorithm based on SimAM-YOLOv4. J. Chang. Univ. Technol. 2022, 43, 244–250. [Google Scholar]
- Qin, X.; Li, N.; Weng, C.; Su, D.; Li, M. Simple Attention Module based Speaker Verification with Iterative noisy label detection. In Proceedings of the ICASSP 2022—2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 23–27 May 2022. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Rezatofighi, H.; Tsoi, N.; Gwak, J.; Sadeghian, A.; Reid, I.; Savarese, S. Generalized Intersection over Union: A Metric and a Loss for Bounding Box Regression. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; IEEE: New York, NY, USA, 2019. [Google Scholar]
- Hu, X.; Liu, Y.; Zhao, Z.; Liu, J.; Yang, X.; Sun, C.; Chen, S.; Li, B.; Zhou, C. Real-time detection of uneaten feed pellets in underwater images for aquaculture using an improved YOLO-V4 network. Comput. Electron. Agric. 2021, 185, 106135. [Google Scholar] [CrossRef]
- He, J.; Erfani, S.; Ma, X.; Bailey, J.; Chi, Y.; Hua, X.S. Alpha-IoU: A Family of Power Intersection over Union Losses for Bounding Box Regression. Adv. Neural Inf. Process. Syst. 2021, 34, 20230–20242. [Google Scholar]
- Yuan, D.R.; Zhang, Y.; Tang, Y.J.; Li, B.Y.; Xie, B.L. Multiscale Residual Attention Network and Its Facial Expression Recognition Algorithm. J. Chin. Comput. Syst. 2023, 11, 1–9. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Categories | Advantages | Shortcomings |
|---|---|---|
| Methods of the literature | Low hardware configuration | Slow, inaccurate, requires human involvement |
| Methods of this paper | High speed and accuracy | High hardware configuration |
| Category (Software/Hardware) | Version/Model |
|---|---|
| Python | 3.7 |
| Pytorch | 1.5.1 |
| Pycharm | 2021.1.3 |
| CUDA | 11.0.2 |
| Cudnn | 11.0 |
| Operating system | Window11 |
| CPU | Intel i5-12500H |
| GPU | RTX 3050 |
| Models | Accuracy (P) | Recall (R) | Average Accuracy (mAP) |
|---|---|---|---|
| YOLOv5s | 0.87 | 0.84 | 0.860 |
| YOLOv5s+CBAM | 0.91 | 0.86 | 0.902 |
| Improved YOLOv5s | 0.96 | 0.89 | 0.955 |
| Models | Precision | Recall | Training Duration (Hour) | Detection Speed (ms/pic) |
|---|---|---|---|---|
| Improved YOLOv5s | 0.96 | 0.89 | 3.4 | 22 |
| YOLOv5s | 0.87 | 0.84 | 3.2 | 19 |
| YOLOv4 | 0.78 | 0.77 | 3.8 | 31 |
| Faster-RCNN | 0.82 | 0.81 | 3.5 | 25 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Guo, Z.; Yang, J.; Sun, J.; Zhao, W. Research on the Small Target Recognition Method of Automobile Tire Marking Points Based on Improved YOLOv5s. Appl. Sci. 2023, 13, 8771. https://doi.org/10.3390/app13158771
Guo Z, Yang J, Sun J, Zhao W. Research on the Small Target Recognition Method of Automobile Tire Marking Points Based on Improved YOLOv5s. Applied Sciences. 2023; 13(15):8771. https://doi.org/10.3390/app13158771
Chicago/Turabian StyleGuo, Zhongfeng, Junlin Yang, Jiahui Sun, and Wenzeng Zhao. 2023. "Research on the Small Target Recognition Method of Automobile Tire Marking Points Based on Improved YOLOv5s" Applied Sciences 13, no. 15: 8771. https://doi.org/10.3390/app13158771
APA StyleGuo, Z., Yang, J., Sun, J., & Zhao, W. (2023). Research on the Small Target Recognition Method of Automobile Tire Marking Points Based on Improved YOLOv5s. Applied Sciences, 13(15), 8771. https://doi.org/10.3390/app13158771