
An Explanation of the LSTM Model Used for DDoS Attacks Classification

Abstract
:1. Introduction
- Assess the LSTM performance in detecting different classes of DDoS attacks by utilizing commonly used and publicly available CIC datasets;
- Investigate the explanation of LSTM predictions on DDoS attacks in CIC datasets using four different explanation methods;
- Utilize the output of explanation methods to demonstrate intrinsic classification features and improve LSTM classification performance, particularly on the CICDDoS2019 dataset;
- Compare and evaluate the explanation methods in the domain of DDoS attack classification using two evaluation metrics.
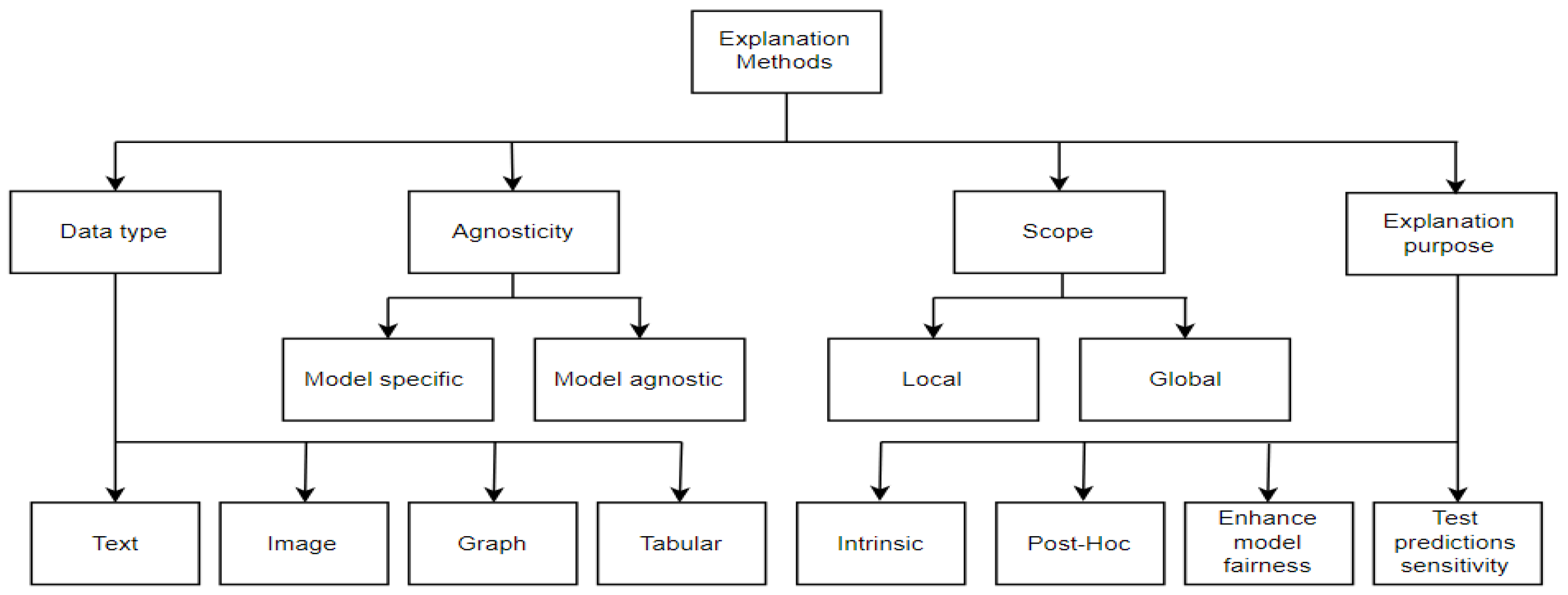
2. Explanation Methods
2.1. LIME
2.2. SHAP
2.3. Anchor
2.4. LORE
3. Related Work
3.1. DDoS Detection Using DL Models
3.2. Explanation Methods
- Investigate and evaluate four explanation methods (LIME, SHAP, Anchor, and LORE) to explain the use of the LSTM model for DDoS attacks detection;
- Perform multiclassification as well as binary classification on DDoS attacks extracted from three CIC datasets (CICIDS2017, CSECICIDS2018, and CICDDoS2019);
- Explain 18 network traffic classes (17 DDoS attacks plus a benign) and find the common features between explanations for each class;
- Find the intrinsic features extracted by the explanation methods to classify DDoS attacks in CIC datasets.
4. Methodology
4.1. Dataset Preprocessing
4.2. LSTM Classification Model
4.3. Explanation Models
| Algorithm 1: procedures of explaining each class in CIC datasets. |
| : all instances, : single instance, : true class, : predicted class, : explanation, distinct explanation of class . Input: Output: |
| , : : , , : , where is an explanation, , , |
4.4. Evaluation of Classification and Explanation Models
5. Results and Discussion
5.1. DDoS Attacks Classification
5.2. LSTM Model Explanation
5.3. Evaluation of the Explanation Methods
6. Conclusions
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Almaiah, M.A. Almaiah, M.A. A New Scheme for Detecting Malicious Attacks in Wireless Sensor Networks Based on Blockchain Technology. In Artificial Intelligence and Blockchain for Future Cybersecurity Applications; Springer: Berlin/Heidelberg, Germany, 2021; pp. 217–234. [Google Scholar]
- Zargar, S.T.; Joshi, J.; Tipper, D. A Survey of Defense Mechanisms Against Distributed Denial of Service (DDoS) Flooding Attacks. IEEE Commun. Surv. Tutor. 2013, 15, 2046–2069. [Google Scholar]
- Hou, J.; Fu, P.; Cao, Z.; Xu, A. Machine Learning Based DDos Detection Through NetFlow Analysis. In Proceedings of the IEEE Military Communications Conference MILCOM, Los Angeles, CA, USA, 29 October 2018. [Google Scholar]
- DDoS Attacks History. Radware. Available online: https://www.radware.com/security/ddos-knowledge-center/ddos-chronicles/ddos-attacks-history/ (accessed on 17 July 2023).
- Choi, H.; Lee, H. Identifying Botnets by Capturing Group Activities in DNS Traffic. Comput. Netw. 2012, 56, 20–33. [Google Scholar]
- Suresh, S.; Ram, N. A Review on Various DPM Traceback Schemes to Detect DDoS Attacks. Indian J. Sci. Technol. 2016, 9, 1–8. [Google Scholar] [CrossRef] [Green Version]
- Argyraki, K.; Cheriton, D. Active Internet Traffic Filtering: Real-Time Response to Denial of Service Attacks. arXiv 2003, arXiv:cs/0309054. [Google Scholar]
- Anjum, F.; Subhadrabandhu, D.; Sarkar, S. Signature Based Intrusion Detection for Wireless Ad-Hoc Networks: A Comparative Study of Various Routing Protocols. In Proceedings of the IEEE 58th Vehicular Technology Conference, Orlando, FL, USA, 6 October 2003. [Google Scholar]
- Cloudflare DDoS Threat Report 2022 Q3. Cloudflare. Available online: https://blog.cloudflare.com/cloudflare-ddos-threat-report-2022-q3/ (accessed on 17 July 2023).
- Hoque, N.; Kashyap, H.; Bhattacharyya, D.K. Real-Time DDoS Attack Detection Using FPGA. Comput. Commun. 2017, 110, 48–58. [Google Scholar] [CrossRef]
- Swami, R.; Dave, M.; Ranga, V. Software-Defined Networking-Based DDoS Defense Mechanisms. ACM Comput. Surv. 2019, 52, 36. [Google Scholar]
- Ribeiro, M.; Singh, S.; Guestrin, C. “Why Should I Trust You?”: Explaining the Predictions of Any Classifier. In Proceedings of the Conference of the North American Chapter of the Association for Computational Linguistics, San Diego, CA, USA, 12 June 2016. [Google Scholar]
- Lundberg, S.M.; Lee, S. A Unified Approach to Interpreting Model Predictions. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Montréal, QC, Canada, 3 December 2017. [Google Scholar]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. Anchors: High-Precision Model-Agnostic Explanations. In Proceedings of the AAAI conference on artificial intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32. [Google Scholar]
- Guidotti, R.; Monreale, A.; Ruggieri, S.; Pedreschi, D.; Turini, F.; Giannotti, F. Local Rule-Based Explanations of Black Box Decision Systems. arXiv 2018, arXiv:1805.10820. [Google Scholar]
- Ugwu, C.C.; Obe, O.O.; Popoọla, O.S.; Adetunmbi, A.O. A Distributed Denial of Service Attack Detection System Using Long Short Term Memory with Singular Value Decomposition. In Proceedings of the IEEE 2nd International Conference on Cyberspac (CYBER NIGERIA), Abuja, Nigeria, 23 February 2021. [Google Scholar]
- Gadze, J.D.; Bamfo-Asante, A.A.; Agyemang, J.O.; Nunoo-Mensah, H.; Opare, K.A.-B. An Investigation into the Application of Deep Learning in the Detection and Mitigation of DDOS Attack on SDN Controllers. Technologies 2021, 9, 14. [Google Scholar]
- Prakash, K.B.; Kanagachidambaresan, G.R. (Eds.) Programming with TensorFlow: Solution for Edge Computing Applications; Springer International Publishing: Cham, Switzerland, 2021; pp. 53–61. [Google Scholar]
- Keshk, M.; Koroniotis, N.; Pham, N.; Moustafa, N.; Turnbull, B.; Zomaya, A.Y. An Explainable Deep Learning-Enabled Intrusion Detection Framework in IoT Networks. Inf. Sci. 2023, 639, 119000. [Google Scholar]
- Linardatos, P.; Papastefanopoulos, V.; Kotsiantis, S. Explainable AI: A Review of Machine Learning Interpretability Methods. Entropy 2020, 23, 18. [Google Scholar] [CrossRef]
- Turlach, B. Least Angle Regression. Ann. Stat. 2004, 32, 481–490. [Google Scholar]
- Shapley, L.S. A Value for N-Person Games, Contributions to the Theory of Games; Princeton University Press: Princeton, NJ, USA, 1953; Volume 2, pp. 307–317. [Google Scholar]
- Kaelbling, L.P.; Littman, M.L.; Moore, A.W. Reinforcement Learning: A Survey. J. Artif. Intell. Res. 1996, 4, 237–285. [Google Scholar] [CrossRef] [Green Version]
- Even, S. Graph Algorithms, 2nd ed.; Guy Even, T.-A.U., Ed.; Cambridge University Press: Cambridge, UK, 2011. [Google Scholar]
- Kaufmann, E. Information Complexity in Bandit Subset Selection. J. Mach. Learn. Res. 2013, 30, 228–251. [Google Scholar]
- Fan, F.; Xiong, J.; Li, M.; Wang, G. On Interpretability of Artificial Neural Networks: A Survey. IEEE Trans. Radiat. Plasma Med. Sci. 2021, 5, 741–760. [Google Scholar] [CrossRef] [PubMed]
- Elsayed, M.; LeKhac, N.; Dev, S.; Jurcut, A. DDoSNet: A Deep-Learning Model for Detecting Network Attacks. In Proceedings of the 2020 IEEE 21st International Symposium on “A World of Wireless, Mobile and Multimedia Networks” (WoWMoM), Cork, Ireland, 31 August 2020. [Google Scholar]
- Kim, M. Supervised Learning-based DDoS Attacks Detection: Tuning Hyperparameters. ETRI J. 2019, 41, 560–573. [Google Scholar] [CrossRef]
- Hwang, R.; Peng, M.; Nguyen, V.; Chang, Y. An LSTM-Based Deep Learning Approach for Classifying Malicious Traffic at the Packet Level. Appl. Sci. 2019, 9, 3414. [Google Scholar] [CrossRef] [Green Version]
- Yuan, X.; Li, C.; Li, X. DeepDefense: Identifying DDoS Attack via Deep Learning. In Proceedings of the 2017 IEEE International Conference on Smart Computing (SMARTCOMP), Hong Kong, China, 29 May 2017. [Google Scholar]
- Cui, J.; Long, J.; Min, E.; Liu, Q.; Li, Q. Comparative Study of CNN and RNN for Deep Learning Based Intrusion Detection System; Springer: Berlin/Heidelberg, Germany, 2018; pp. 159–170. [Google Scholar]
- Zhang, Y.; Xu, C.; Jin, L.; Wang, X.; Guo, D. Network Intrusion Detection: Based on Deep Hierarchical Network and Original Flow Data. IEEE Access 2019, 7, 37004–37016. [Google Scholar]
- Azizjon, M.; Jumabek, A.; Wooseong, K. 1D CNN Based Network Intrusion Detection with Normalization on Imbalanced Data. In Proceedings of the 2020 International Conference on Artificial Intelligence in Information and Communication (ICAIIC), Fukuoka, Japan, 19 February 2020. [Google Scholar]
- Batchu, R.K.; Seetha, H. An Integrated Approach Explaining the Detection of Distributed Denial of Service Attacks. Comput. Netw. 2022, 216, 109269. [Google Scholar]
- Bårli, E.M.; Yazidi, A.; Viedma, E.H.; Haugerud, H. DoS and DDoS Mitigation Using Variational Autoencoders. Comput. Netw. 2021, 199, 108399. [Google Scholar] [CrossRef]
- Han, D.; Wang, Z.; Chen, W.; Zhong, Y.; Wang, S.; Zhang, H.; Yang, J.; Shi, X.; Yin, X. DeepAID: Interpreting and Improving Deep Learning-Based Anomaly Detection in Security Applications. In Proceedings of the 2021 ACM SIGSAC Conference on Computer and Communications Security, New York, NY, USA, 15 November 2021. [Google Scholar]
- Le, T.-T.-H.; Kim, H.; Kang, H.; Kim, H. Classification and Explanation for Intrusion Detection System Based on Ensemble Trees and SHAP Method. Sensors 2022, 22, 1154. [Google Scholar]
- Neupane, S.; Ables, J.; Anderson, W.; Mittal, S.; Rahimi, S.; Banicescu, I.; Seale, M. Explainable Intrusion Detection Systems (x-Ids): A Survey of Current Methods, Challenges, and Opportunities. IEEE Access 2022, 10, 112392–112415. [Google Scholar] [CrossRef]
- Zhang, Z.; Al Hamadi, H.; Damiani, E.; Yeun, C.Y.; Taher, F. Explainable Artificial Intelligence Applications in Cyber Security: State-of-the-Art in Research. IEEE Access 2022, 10, 93104–93139. [Google Scholar] [CrossRef]
- Capuano, N.; Fenza, G.; Loia, V.; Stanzione, C. Explainable Artificial Intelligence in CyberSecurity: A Survey. IEEE Access 2022, 10, 93575–93600. [Google Scholar] [CrossRef]
- Warnecke, A.; Arp, D.; Wressnegger, C.; Rieck, K. Evaluating Explanation Methods for Deep Learning in Security. In Proceedings of the 2020 IEEE European Symposium on Security and Privacy (EuroS&P), Zoom, Online, 7 September 2020. [Google Scholar]
- Fan, M.; Wei, W.; Xie, X.; Liu, Y.; Guan, X.; Liu, T. Can We Trust Your Explanations? Sanity Checks for Interpreters in Android Malware Analysis. IEEE Trans. Inf. Forensics Secur. 2021, 16, 838–853. [Google Scholar] [CrossRef]
- Datasets. Canadian Institute for Cybersecurity. Available online: https://www.unb.ca/cic/datasets/index.html (accessed on 17 July 2023).
- Hasan, M.K.; Alam, M.A.; Roy, S.; Dutta, A.; Md, J.; Das, S. Missing Value Imputation Affects the Performance of Machine Learning: A Review and Analysis of the Literature (2010–2021). Inform. Med. Unlocked 2021, 27, 100799. [Google Scholar]
- sklearn.preprocessing.MinMaxScaler. Scikit Learn. Available online: https://scikit-learn.org/stable/modules/generated/sklearn.preprocessing.MinMaxScaler.html (accessed on 17 July 2023).
- De Araujo, P.H.H.N.; Silva, A.; Junior, N.F.; Cabrini, F.; Santiago, A.; Guelfi, A.; Kofuji, S. Impact of Feature Selection Methods on the Classification of DDoS Attacks Using XGBoost. J. Commun. Inf. Syst. 2021, 36, 200–214. [Google Scholar] [CrossRef]
- Bolodurina, I.; Shukhman, A.; Parfenov, D.; Zhigalov, A.; Zabrodina, L. Investigation of the Problem of Classifying Unbalanced Datasets in Identifying Distributed Denial of Service Attacks. J. Phys. Conf. Ser. 2020, 1679, 042020. [Google Scholar] [CrossRef]
- Wei, Y.; Jang-Jaccard, J.; Sabrina, F.; Singh, A.; Xu, W.; Camtepe, S. AE-MLP: A Hybrid Deep Learning Approach for DDoS Detection and Classification. IEEE Access 2021, 9, 146810–146821. [Google Scholar] [CrossRef]
- Chartuni, A.; Márquez, J. Multi-Classifier of DDoS Attacks in Computer Networks Built on Neural Networks. Appl. Sci. 2021, 11, 10609. [Google Scholar] [CrossRef]
- Mohammed, R.; Rawashdeh, J.; Abdullah, M. Machine Learning with Oversampling and Undersampling Techniques: Overview Study and Experimental Results. In Proceedings of the 2020 11th International Conference on Information and Communication Systems (ICICS), Irbid, Jordan, 7 April 2020. [Google Scholar]
- RandomUnderSampler. Imbalanced-Learn. Available online: https://imbalanced-learn.org/stable/references/generated/imblearn.under_sampling.RandomUnderSampler.html (accessed on 17 July 2023).
- Arya, V.; Bellamy, R.K.E.; Chen, P.-Y.; Dhurandhar, A.; Hind, M.; Hoffman, S.C.; Houde, S.; Liao, Q.V.; Luss, R.; Mojsilović, A. One Explanation Does Not Fit All: A Toolkit and Taxonomy of Ai Explainability Techniques. arXiv 2019, arXiv:1909.03012. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| 0–11 | 12–23 | 24–35 | 36–47 | 48–59 | 60–71 | 72–83 |
|---|---|---|---|---|---|---|
| Flow ID | Fwd Packet Length Max | Flow IAT Max | Fwd PSH Flags | Packet Length Variance | Avg Bwd Segment Size | Init_Win_bytes_ forward |
| Source IP | Fwd Packet Length Min | Flow IAT Min | Bwd PSH Flags | FIN Flag Count | Fwd Header Length | Init_Win_bytes_ backward |
| Destination IP | Fwd Packet Length Mean | Fwd IAT Total | Fwd URG Flags | PSH Flag Count | Fwd Avg Bytes/ Bulk | act_data_pkt_fwd |
| Time stamp | Fwd Packet Length Std | Fwd IAT Mean | Bwd URG Flags | SYN Flag Count | Fwd Avg Packets/ Bulk | min_seg_size_ forward |
| Source Port | Bwd Packet Length Max | Fwd IAT Std | Fwd Header Length | ECE Flag Count | Fwd Avg Bulk Rate | Active Mean |
| Destination Port | Bwd Packet Length Min | Fwd IAT Max | Bwd Header Length | RST Flag Count | Bwd Avg Bytes/ Bulk | Active Std |
| Protocol | Bwd Packet Length Mean | Fwd IAT Min | Fwd Packets/s | ACK Flag Count | Bwd Avg Packets/ Bulk | Active Max |
| Flow Duration | Bwd Packet Length Std | Bwd IAT Total | Bwd Packets/s | URG Flag Count | Bwd Avg Bulk Rate | Active Min |
| Total Fwd Packets | Flow Bytes/s | Bwd IAT Mean | Min Packet Length | CWE Flag Count | Subflow Fwd Packets | Idle Mean |
| Total Backward Packets | Flow Packets/s | Bwd IAT Std | Max Packet Length | Down/Up Ratio | Subflow Fwd Bytes | Idle Std |
| Total Length of Fwd Packets | Flow IAT Mean | Bwd IAT Max | Packet Length Mean | Average Packet Size | Subflow Bwd Packets | Idle Max |
| Total Length of Bwd Packets | Flow IAT Std | Bwd IAT Min | Packet Length Std | Avg Fwd Segment Size | Subflow Bwd Bytes | Idle Min |
| Feature Set (# Features) | List of Features |
|---|---|
| Forward packet (25) | 8, 10, 12, 13, 14, 15, 26, 27, 28, 29, 30, 36, 38, 40, 42, 59, 61, 62, 63, 64, 68, 69, 72, 74, 75 |
| Backward packet (22) | 9, 11, 18, 17, 18, 19, 31, 32, 33, 34, 35, 37, 39, 41, 43, 60, 65, 66, 67, 70, 71, 73 |
| Flow-based (15) | 7, 20, 21, 22, 23, 24, 25, 76, 77, 78, 79, 80, 81, 82, 83 |
| Time-based (21) | 7, 20, 22, 23, 24, 25, 31, 32, 33, 34, 35, 42, 43, 76, 77, 78, 79, 80, 81, 82, 83 |
| Packet header-based (18) | 4, 5, 6, 36, 37, 38, 39, 41, 49, 50, 51, 52, 53, 54, 55, 56, 57, 61 |
| Packet payload-based (16) | 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 44, 45, 46, 47, 48, 58 |
| Socket features (4) | 0, 1, 2, 3 |
| CICIDS2017 | CSECICIDS2018 | CICDDoS2019 | ||
|---|---|---|---|---|
| TCP | UDP | TCP/UDP | ||
| GoldenEye | GoldenEye | MSSQL | NTP | DNS |
| Hulk | Hulk | SSDP | TFTP | LDAP |
| Slowhttp | Slowhttp | SYN | UDP | NetBIOS |
| Slowloris | Slowloris | - | UDP-Lag | SNMP |
| - | HOIC | - | - | WebDDoS |
| - | LOIChttp | - | - | - |
| Binary | Multiclass | ||
|---|---|---|---|
| Class | Instances | Class | Instances |
| Attacks | 50,006,249 | TFTP | 20,082,580 |
| DrDoS_SNMP | 5,159,870 | ||
| DrDoS_DNS | 5,071,011 | ||
| DrDoS_MSSQL | 4,522,492 | ||
| DrDoS_NetBIOS | 4,093,279 | ||
| DrDoS_UDP | 3,134,645 | ||
| DrDoS_SSDP | 2,610,611 | ||
| DrDoS_LDAP | 2,179,930 | ||
| SYN | 1,582,289 | ||
| DrDoS_NTP | 1,202,642 | ||
| UDP-lag | 366,461 | ||
| WebDDoS | 439 | ||
| Benign | 56,863 | Benign | 56,863 |
| LIME Explanations | SHAP Explanations | |
| F * (weight) | 54 (0.114), 19 (0.097), 26 (−0.093), 50 (0.072), 16 (0.068), 58 (−0.054), 47 (0.046), 46 (−0.044), 60 (0.036), 45 (0.032). | 50 (0.195), 19 (0.152), 16 (0.143), 26 (0.130), 58 (−0.114), 46 (−0.102), 28 (0.073), 47 (0.071), 45 (0.069), 60 (0.068). |
| Anchor Explanations | LORE Explanations | |
| F AND F | 58 AND 15 AND 74 AND 45 AND 12 AND 53 AND 60 AND 18 AND 72 AND 68. | 50 AND 46 AND 51 AND 58 AND19 AND 47 AND 60 AND 43 AND 20 AND 14. |
| Metric | Binary Classification | Multiclassification |
|---|---|---|
| Accuracy (ACC) | ||
| Precision (PR) | ||
| Recall (RE) | ||
| F1-score |
| Descriptive Accuracy (DA) | Descriptive Sparsity (DS) |
|---|---|
| Dataset | Class | Accuracy | Precision | Recall | F1-Score |
|---|---|---|---|---|---|
| CICIDS2017 | Benign | 0.998 | 0.997 | 0.997 | 0.998 |
| Attack | 0.998 | 0.998 | 0.997 | 0.997 | |
| CICIDS2018 | Benign | 0.998 | 0.998 | 0.998 | 0.998 |
| Attack | 0.997 | 0.997 | 0.997 | 0.997 | |
| CICDDoS2019 | Benign | 0.997 | 0.998 | 0.998 | 0.998 |
| Attack | 0.998 | 0.998 | 0.997 | 0.998 |
| Dataset | Class | Accuracy | Precision | Recall | F1-Score |
|---|---|---|---|---|---|
| CICIDS2017 | Benign | 0.95 | 0.99 | 0.95 | 0.97 |
| GoldenEye | 0.98 | 0.99 | 0.98 | 0.98 | |
| Hulk | 0.99 | 0.96 | 0.99 | 0.98 | |
| Slowhttp | 0.98 | 0.97 | 0.98 | 0.98 | |
| Slowloris | 0.97 | 0.97 | 0.97 | 0.97 | |
| CICIDS2018 | HOIC | 1.00 | 1.00 | 1.00 | 1.00 |
| LOIChttp | 0.98 | 1.00 | 0.99 | 0.99 | |
| CICDDoS2019 | DNS | 0.60 | 0.56 | 0.60 | 0.58 |
| LDAP | 0.34 | 0.56 | 0.34 | 0.42 | |
| MSSQL | 0.97 | 0.95 | 0.97 | 0.96 | |
| NTP | 0.99 | 0.99 | 0.99 | 0.99 | |
| NetBIOS | 0.98 | 0.95 | 0.98 | 0.96 | |
| SNMP | 0.84 | 0.65 | 0.84 | 0.73 | |
| SSDP | 0.10 | 0.49 | 0.10 | 0.17 | |
| SYN | 0.99 | 0.59 | 1.00 | 0.74 | |
| TFTP | 0.98 | 0.99 | 0.98 | 0.99 | |
| UDP | 0.89 | 0.48 | 0.89 | 0.62 | |
| UDP-Lag | 0.20 | 0.97 | 0.20 | 0.33 |
| Class (# Features) | Features (LIME ∩ SHAP ∩ Anchor ∩ LORE) |
|---|---|
| Benign (23) | 8, 12, 14, 15, 17, 18, 23, 24, 26, 28, 29, 34, 35, 36, 40, 41, 44, 45, 46, 51, 55, 59, 60 |
| GoldenEye (13) | 7, 15, 18, 19, 22, 27, 32, 33, 47, 48, 50, 54, 60 |
| Hulk (17) | 14, 15, 18, 19, 21, 23, 28, 33, 42, 43, 46, 47, 48, 49, 54, 58, 60 |
| Slowhttp (22) | 7, 13, 14, 15, 20, 23, 27, 28, 32, 33, 36, 42, 43, 46, 47, 48, 50, 51, 54, 55, 58, 59 |
| Slowloris (17) | 13, 14, 15, 21, 22, 23, 27, 28, 32, 33, 36, 42, 43, 48, 50, 51, 55 |
| HOIC (14) | 6, 13, 15, 16, 18, 19, 25, 33, 42, 43, 45, 46, 47, 48 |
| LOIChttp (20) | 6, 12, 13, 14, 15, 17, 22, 24, 25, 26, 27, 28, 29, 30, 42, 44, 45, 46, 50, 54 |
| DNS (33) | 6, 10, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 27, 28, 29, 31, 33, 34, 35, 36, 42, 43, 44, 45, 46, 47, 48, 53, 54, 56, 58 |
| LDAP (18) | 10, 16, 17, 18, 21, 22, 23, 24, 28, 29, 31, 32, 33, 34, 35, 36, 42, 43 |
| MSSQL (22) | 10, 12, 16, 19, 20, 21, 22, 23, 24, 27, 28, 29, 32, 33, 34, 35, 42, 44, 45, 58, 59, 76 |
| NTP (25) | 6, 11, 12, 14, 16, 17, 18, 19, 21, 31, 32, 33, 34, 35, 36, 42, 43, 45, 48, 53, 55, 56, 57, 59, 60 |
| NetBIOS (25) | 10, 12, 15, 16, 17, 18, 21, 22, 23, 24, 26, 27, 29, 31, 34, 35, 36, 43, 45, 47, 48, 53, 54, 56, 60 |
| SNMP (28) | 10, 12, 13, 16, 17, 19, 20, 21, 22, 23, 24, 26, 27, 28, 29, 33, 40, 42, 43, 44, 45, 46, 48, 53, 54, 56, 58, 59 |
| SSDP (10) | 6, 12, 16, 17, 21, 31, 36, 42, 56, 60 |
| SYN (20) | 6, 10, 15, 16, 17, 18, 19, 21, 28, 33, 35, 42, 45, 47, 48, 54, 55, 56, 57, 60 |
| TFTP (23) | 10, 12, 13, 14, 15, 16, 18, 21, 22, 23, 24, 26, 27, 29, 31, 42, 43, 45, 46, 47, 48, 53, 57 |
| UDP (21) | 6, 10, 12, 15, 16, 17, 18, 21, 31, 32, 33, 34, 35, 36, 42, 43, 45, 55, 56, 57, 60 |
| UDP-Lag (22) | 6, 10, 15, 16, 17, 18, 21, 22, 24, 26, 27, 29, 31, 33, 34, 35, 42, 47, 54, 55, 57, 60 |
| Intrinsic features (51) | 6, 7, 8, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 53, 54, 55, 56, 57, 58, 59, 60, 76 |
| C1 | C2 | C3 | C4 | C5 | C6 | C7 | C8 | C9 | C10 | C11 | C12 | C13 | C14 | C15 | C16 | C17 | C18 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| C1 | 1 | 0.39 | 0.21 | 0.25 | 0.21 | 0.21 | 0.34 | 0.33 | 0.28 | 0.29 | 0.30 | 0.37 | 0.31 | 0.14 | 0.23 | 0.28 | 0.29 | 0.29 |
| C2 | 0.39 | 1 | 0.36 | 0.35 | 0.30 | 0.29 | 0.18 | 0.24 | 0.15 | 0.17 | 0.19 | 0.27 | 0.17 | 0.05 | 0.32 | 0.20 | 0.17 | 0.30 |
| C3 | 0.21 | 0.36 | 1 | 0.44 | 0.36 | 0.41 | 0.19 | 0.43 | 0.25 | 0.22 | 0.27 | 0.27 | 0.32 | 0.13 | 0.42 | 0.33 | 0.23 | 0.26 |
| C4 | 0.25 | 0.35 | 0.44 | 1 | 0.63 | 0.29 | 0.27 | 0.41 | 0.21 | 0.26 | 0.23 | 0.21 | 0.35 | 0.07 | 0.24 | 0.29 | 0.19 | 0.19 |
| C5 | 0.21 | 0.30 | 0.36 | 0.63 | 1 | 0.24 | 0.28 | 0.35 | 0.35 | 0.26 | 0.27 | 0.33 | 0.29 | 0.13 | 0.23 | 0.33 | 0.27 | 0.22 |
| C6 | 0.21 | 0.29 | 0.41 | 0.29 | 0.24 | 1 | 0.26 | 0.38 | 0.19 | 0.17 | 0.30 | 0.22 | 0.27 | 0.14 | 0.42 | 0.37 | 0.30 | 0.24 |
| C7 | 0.34 | 0.18 | 0.19 | 0.27 | 0.28 | 0.26 | 1 | 0.21 | 0.16 | 0.15 | 0.23 | 0.20 | 0.26 | 0.12 | 0.30 | 0.32 | 0.23 | 0.22 |
| C8 | 0.33 | 0.24 | 0.43 | 0.41 | 0.35 | 0.38 | 0.21 | 1 | 0.46 | 0.49 | 0.49 | 0.61 | 0.65 | 0.26 | 0.47 | 0.56 | 0.46 | 0.45 |
| C9 | 0.28 | 0.15 | 0.25 | 0.21 | 0.35 | 0.19 | 0.16 | 0.46 | 1 | 0.48 | 0.39 | 0.48 | 0.35 | 0.27 | 0.31 | 0.37 | 0.50 | 0.48 |
| C10 | 0.29 | 0.17 | 0.22 | 0.26 | 0.26 | 0.17 | 0.15 | 0.49 | 0.48 | 1 | 0.31 | 0.34 | 0.56 | 0.14 | 0.27 | 0.32 | 0.30 | 0.33 |
| C11 | 0.30 | 0.19 | 0.27 | 0.23 | 0.27 | 0.3 | 0.23 | 0.49 | 0.39 | 0.31 | 1 | 0.43 | 0.33 | 0.40 | 0.50 | 0.33 | 0.70 | 0.38 |
| C12 | 0.37 | 0.27 | 0.27 | 0.21 | 0.33 | 0.22 | 0.2 | 0.61 | 0.48 | 0.34 | 0.43 | 1 | 0.47 | 0.30 | 0.41 | 0.60 | 0.48 | 0.57 |
| C13 | 0.31 | 0.17 | 0.32 | 0.35 | 0.29 | 0.27 | 0.26 | 0.65 | 0.35 | 0.56 | 0.33 | 0.47 | 1 | 0.19 | 0.33 | 0.50 | 0.26 | 0.32 |
| C14 | 0.14 | 0.05 | 0.13 | 0.07 | 0.13 | 0.14 | 0.12 | 0.26 | 0.27 | 0.14 | 0.40 | 0.30 | 0.19 | 1 | 0.30 | 0.18 | 0.48 | 0.28 |
| C15 | 0.23 | 0.32 | 0.42 | 0.24 | 0.23 | 0.42 | 0.3 | 0.47 | 0.31 | 0.27 | 0.50 | 0.41 | 0.33 | 0.3 | 1 | 0.30 | 0.58 | 0.56 |
| C16 | 0.28 | 0.2 | 0.33 | 0.29 | 0.33 | 0.37 | 0.32 | 0.56 | 0.37 | 0.32 | 0.33 | 0.60 | 0.50 | 0.18 | 0.3 | 1 | 0.33 | 0.45 |
| C17 | 0.29 | 0.17 | 0.23 | 0.19 | 0.27 | 0.3 | 0.23 | 0.46 | 0.50 | 0.30 | 0.70 | 0.48 | 0.26 | 0.48 | 0.58 | 0.33 | 1 | 0.54 |
| C18 | 0.29 | 0.3 | 0.26 | 0.19 | 0.22 | 0.24 | 0.22 | 0.45 | 0.48 | 0.33 | 0.38 | 0.57 | 0.32 | 0.28 | 0.56 | 0.45 | 0.54 | 1 |
| Benign | C1 | Slowhttp | C4 | LOIChttp | C7 | MSSQL | C10 | SNMP | C13 | TFTP | C16 |
| GoldenEye | C2 | Slowloris | C5 | DNS | C8 | NTP | C11 | SSDP | C14 | UDP | C17 |
| Hulk | C3 | HOIC | C6 | LDAP | C9 | NetBIOS | C12 | SYN | C15 | UDP-Lag | C18 |
| Class | Accuracy | Precision | Recall | F1-Score |
|---|---|---|---|---|
| Benign | 0.999 | 1.00 | 1.00 | 1.00 |
| Group 1 | 0.994 | 0.98 | 0.99 | 0.99 |
| Group 2 | 0.978 | 0.99 | 0.98 | 0.98 |
| MSSQL | 0.976 | 0.98 | 0.98 | 0.98 |
| Class | LIME | SHAP | Anchor | LORE | ||||
|---|---|---|---|---|---|---|---|---|
| AUDA | AUMAZ | AUDA | AUMAZ | AUDA | AUMAZ | AUDA | AUMAZ | |
| Benign | 0.6870 | 0.1034 | 0.9270 | 0.0878 | 0.9480 | 0.0853 | 0.9120 | 0.0883 |
| GoldenEye | 0.1030 | 0.1833 | 0.4610 | 0.1630 | 0.4780 | 0.1672 | 0.4350 | 0.0836 |
| Hulk | 0.0640 | 0.2703 | 0.5570 | 0.1926 | 0.4030 | 0.1915 | 0.5270 | 0.0846 |
| Slowhttp | 0.0420 | 0.1766 | 0.4710 | 0.1271 | 0.2480 | 0.1321 | 0.5420 | 0.0819 |
| Slowloris | 0.0140 | 0.1535 | 0.1790 | 0.1171 | 0.5480 | 0.1295 | 0.4660 | 0.0840 |
| HOIC | 0.0070 | 0.1375 | 0.8440 | 0.1021 | 0.6850 | 0.1304 | 0.0003 | 0.1132 |
| LOIChttp | 0.0125 | 0.1746 | 0.3926 | 0.1479 | 0.2673 | 0.1341 | 0.3354 | 0.1487 |
| DNS | 0.0465 | 0.1638 | 0.3498 | 0.1586 | 0.2766 | 0.1459 | 0.1692 | 0.1556 |
| LDAP | 0.0391 | 0.1638 | 0.1854 | 0.1620 | 0.3833 | 0.0891 | 0.0162 | 0.1733 |
| MSSQL | 0.0001 | 0.1944 | 0.0029 | 0.1570 | 0.0092 | 0.1209 | 0.2702 | 0.1573 |
| NTP | 0.0849 | 0.1402 | 0.3324 | 0.1636 | 0.6911 | 0.1601 | 0.5037 | 0.1556 |
| NetBIOS | 0.2721 | 0.0974 | 0.1259 | 0.1636 | 0.1053 | 0.1511 | 0.0449 | 0.1647 |
| SNMP | 0.0378 | 0.1620 | 0.4033 | 0.1694 | 0.3029 | 0.1634 | 0.0316 | 0.1573 |
| SSDP | 0.0066 | 0.1392 | 0.0001 | 0.1619 | 0.0077 | 0.1830 | 0.0237 | 0.1689 |
| SYN | 0.0202 | 0.0980 | 0.6977 | 0.1570 | 0.7653 | 0.1944 | 0.1313 | 0.1710 |
| TFTP | 0.0737 | 0.1492 | 0.2338 | 0.1604 | 0.0030 | 0.1885 | 0.0303 | 0.1711 |
| UDP | 0.0215 | 0.1002 | 0.0034 | 0.1619 | 0.3604 | 0.1714 | 0.3164 | 0.1647 |
| UDP-Lag | 0.0568 | 0.1035 | 0.1180 | 0.1636 | 0.1748 | 0.1074 | 0.0304 | 0.1689 |
| Class | Method | Dominant Contribution Features |
|---|---|---|
| Benign | LIME | 5, 31, 26, 83, 72, 55, 51, 36, 18, 35 |
| GoldenEye | LIME | 54, 19, 30, 16, 27, 31, 45, 47, 22, 7 |
| Hulk | LIME | 49, 58, 28, 46, 54 |
| Slowhttp | LIME | 33, 55, 50, 58, 51 |
| Slowloris | LIME | 50, 34, 51, 36 |
| HOIC | LORE | 72, 22 |
| LOIChttp | LIME | 54, 19 |
| DNS | LIME | 44, 58, 20, 57, 59, 6, 35, 72, 46 |
| LDAP | LORE | 12, 13, 59, 44, 14 |
| MSSQL | LIME | 4, 20 |
| NTP | LIME | 15, 47, 55, 6, 42 |
| NetBIOS | LORE | 45, 44, 59, 13, 14 |
| SNMP | LORE | 58, 13, 78, 44, 29 |
| SSDP | SHAP | 4, 42 |
| SYN | LIME | 54, 5, 4, 55, 7 |
| TFTP | Anchor | 59, 4 |
| UDP | SHAP | 4, 12, 47, 43, 33 |
| UDP-Lag | LORE | 54, 55, 12, 23, 21 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bashaiwth, A.; Binsalleeh, H.; AsSadhan, B. An Explanation of the LSTM Model Used for DDoS Attacks Classification. Appl. Sci. 2023, 13, 8820. https://doi.org/10.3390/app13158820
Bashaiwth A, Binsalleeh H, AsSadhan B. An Explanation of the LSTM Model Used for DDoS Attacks Classification. Applied Sciences. 2023; 13(15):8820. https://doi.org/10.3390/app13158820
Chicago/Turabian StyleBashaiwth, Abdulmuneem, Hamad Binsalleeh, and Basil AsSadhan. 2023. "An Explanation of the LSTM Model Used for DDoS Attacks Classification" Applied Sciences 13, no. 15: 8820. https://doi.org/10.3390/app13158820