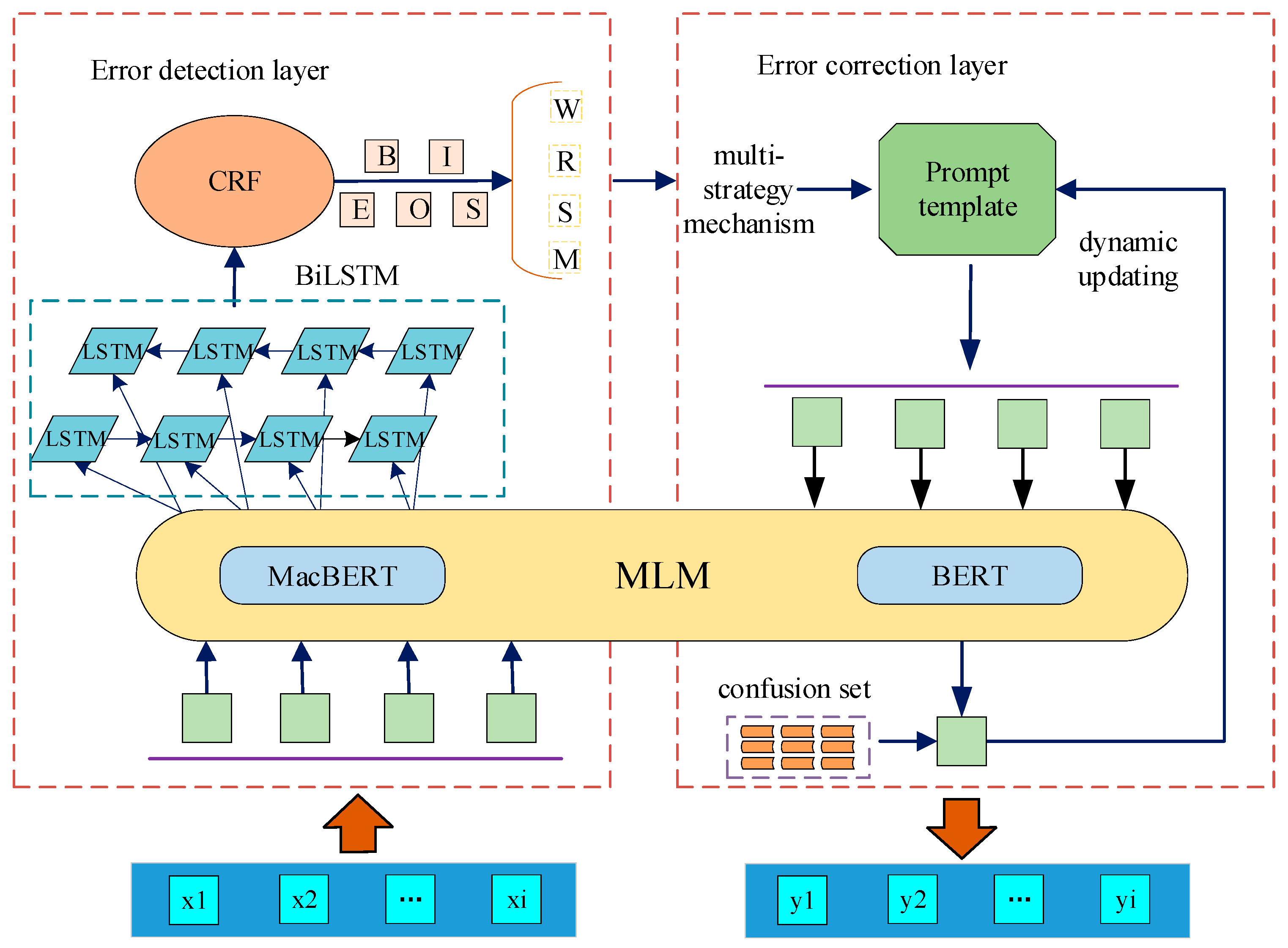
In the error-detection layer, we constructed the MacBERT-BiLSTM-CRF sequence labeling model to obtain information about the grammatical error types and positions in a sentence. The process is as follows: (1) Utilizing the pre-trained model MacBERT to capture the semantic relationships between characters in the input text and extract the semantic information within the text. (2) Encoding the output of MacBERT further in the BiLSTM to better capture the contextual features of the sequence. (3) Finally, utilizing the labeling dependency modeling capability of the CRF network, the prediction and decoding of labels are performed on the output of the BiLSTM, resulting in the final annotation results.
3.1.1. MacBERT Layer
In the process of detecting errors, we use MacBERT to convert the input text into vector representations. MacBERT is a pre-trained model optimized for Chinese language tasks. Through training on a large-scale Chinese corpus, it learns rich representations of the Chinese language. MacBERT is a variant of BERT, and its structure is similar to BERT, consisting of compositional embedding layers and multiple stacked transformer encoder layers. The embedding layer transforms the input text into a mathematical representation and includes token, positional, and segment embeddings. Token embedding converts each character of the input text into a fixed-dimensional word-embedding vector. Positional embedding captures the positional information within the input sequence, encoding the position of each word in the sequence. It is added after word embedding. Segment embedding is used to differentiate relationships between different sentences. Each word is marked as belonging to the first sentence (Segment A) or the second sentence (Segment B). The outputs of these three embedding layers are element-wise summed and passed as input to the transformer encoder layers.
However, unlike BERT, MacBERT improves the masking strategy used during pre-training. It discards the strategy of masking tokens with the whole word [MASK] and, instead, uses a similar word replacement for masking. When a masked word is not similar, a random word is selected for replacement. In this strategy, 15% of the characters in the input sentence are masked, 80% are replaced with similar words, 10% are replaced with random words, and the remaining 10% are kept unchanged. As shown in
Table 2, in the masking strategy of BERT, masking the original sentence would result in “小猫[MASK]一个老[MASK]” (The cat [MASK] an [MASK]). In the masking strategy of MacBERT, masking the original sentence would result in “小猫桌一个老书” (The cat table an old book), where “桌” (table) and “书” (book) are similar characters corresponding to the characters “猫” (cat) and “鼠” (mouse) in the original sentence. This masking strategy reduces the gap between the pre-training and fine-tuning stages and makes MacBERT more suitable for the task of text error detection.
3.1.2. BiLSTM Layer
LSTM, as a particular type of recurrent neural network (RNN), addresses the two challenges encountered in handling extended textual information in traditional RNNs by introducing gate mechanisms to control information flow and retention. The first challenge is ‘gradient explosion’, where gradients (amounts used for optimizing the network) grow exponentially and disrupt the learning process. The second challenge is ‘long-term dependencies’, i.e., the difficulty of associating information that appeared earlier with the later parts of a long sequence [
18]. It consists of three main gate controllers: the forget gate, input gate, and output gate, along with a memory cell state for information transmission within the network. The architecture of an LSTM unit is depicted in
Figure 2, where we show the hidden state
output at time step
t. The forget gate
combines the previous time step’s hidden state
with the current input
and passes it through a sigmoid activation function σ to determine which information to discard from the cell state. The input gate has two parts determining which new information should be stored in the cell state. The first part is a sigmoid layer, which decides which values to update, and the second part is a tanh layer, which generates a new candidate value vector
that could be added to the state. The old cell state
is then updated to obtain the new cell state
. Finally, the output gate determines which values to output. Specifically, it first applies a sigmoid layer to determine the output portion and then processes the state with a tanh function. The two are multiplied to obtain the final hidden state
.
The calculation formulas for each part of an LSTM unit are as follows, with the formula for the forget gate shown in Equation (1):
In the equations, represents the weight matrix for the forget gate, is the bias term for the forget gate, is the input at the current time step, and is the previous hidden state.
The input gate consists of the activation value
and the candidate value vector
, which are calculated as shown in Equations (2) and (3):
In this case, represents the weight matrix for the input gate, is the bias term for the input gate, is the weight matrix for the candidate value vector, and is the bias term for the candidate value vector.
We can now obtain the updated cell state
, which is calculated as shown in Equation (4):
In the equations, represents the previous cell state, is the activation value of the forget gate, is the activation value of the input gate, and is the candidate value vector.
Finally, we obtain the hidden state
through the output gate, which is calculated as shown in Equations (5) and (6):
In the equations, represents the weight matrix for the output gate, is the bias term for the output gate, and is the current cell state.
The LSTM network composed of the aforementioned structure has achieved good results in addressing the issues of gradient explosion and long-term dependencies encountered in processing long textual information. However, it can only capture information in a sequential manner from either the forward or backward direction, thus being unable to consider the contextual information of an element in both preceding and succeeding contexts. On the other hand, BiLSTM can simultaneously consider the past and future contexts, allowing for better capture of bidirectional semantic dependencies. It consists of two LSTM units: a forward LSTM and a backward LSTM. At a given time point
t, the forward LSTM receives the input
X = (
x1,
x2, …,
xt), while the backward LSTM receives the input
X = (
xT,
x(
T − 1), …,
xt), where
T is the total length of the input sequence. Therefore, for BiLSTM, the hidden state at each time point
t is composed of the hidden states of both the forward and backward LSTMs, as shown in Equation (7):
where
represents the current hidden state of the BiLSTM,
f is the function used to combine the two LSTMs,
represents the hidden state of the forward LSTM, and
represents the hidden state of the backward LSTM.
3.1.3. CRF Layer
The Conditional Random Field (CRF) network is a discriminative model used for sequence labeling tasks, primarily aimed at assigning labels to sequential data. In this study, because BiLSTM does not consider label information during the prediction process, the CRF network is employed to compensate for this deficiency, serving as a constraint to improve the accuracy of predicted labels. The objective of the CRF network is to learn a conditional probability P(Y|X), given the input X = (x1, x2, …, xn), which represents the probability of an output label sequence Y = (y1, y2, …, yn).
In the CRF network, given the input
X, the label sequence scores for every possible output
Y are typically computed based on two components: transition scores and emission scores. Transition scores consider the transitions between adjacent labels in the label sequence, while emission scores consider the matching degree between labels and corresponding input features at each position. The computation formula is shown in Equation (8):
where
represents the emission score, indicating the matching degree between the given input at position
i and the label
.
, which represents the transition score from label
to label
.
Next, the scores of the label sequences are exponentiated, and the exponential sum of all possible label sequences is normalized to obtain the probabilities of the label sequences. The computation formula is shown in Equation (9):
Finally, the Viterbi algorithm is used to obtain the label sequence
with the highest probability. The computation formula is shown in Equation (10):
In addition, when using the CRF network, it is necessary to add label constraints to avoid generating illegal sequences. In this study, the BIOES annotation scheme is employed to label four types of errors: redundancy (R), missing (M), disorder (W), and wrong word (S). Specifically, the errors are represented by the following prefixes: the prefix “B-” indicates the beginning of an error, “I-” is for the middle part, “E-” represents the end, “S-” is used for a single character error, and “O-” is for other situations. For example, the labels for redundancy (R) errors can include “B-R”, “I-R”, “E-R”, and so on.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}