
HPC Platform for Railway Safety-Critical Functionalities Based on Artificial Intelligence

 , , and
, , and
Abstract
:1. Introduction
2. Related Work
3. Use Case Definition
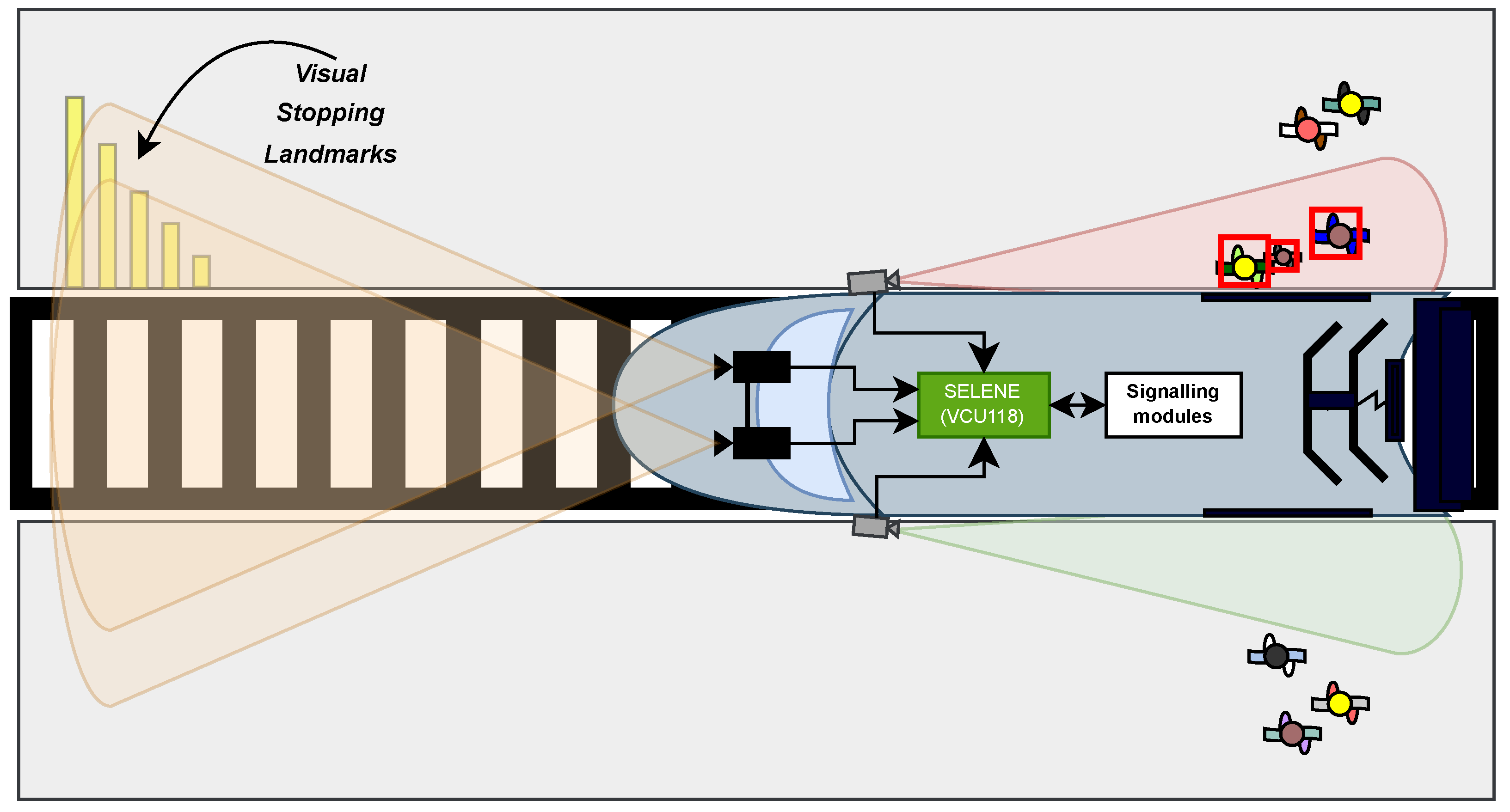
- Data collection and synchronization: this captures data from stereo vision-capable cameras in real time and it synchronizes and rectifies data of both video stream signals.
- Automatic station detection and accurate stop aligning the vehicle and platform: this detects the station platform and it accomplishes precise localization inside the platform area by detecting, recognizing and tracking visual patterns. The visual landmarks have been chosen to maximize the results of the detection and identification process in any possible lighting conditions. Visual stereo sensors that have been properly calibrated assess the physical distance.
- Safe passenger transfer: this captures data from rear cameras and it manages automatic safe door functionality preventing (a) door opening operation if the train and platform are not precisely aligned and (b) door shutting operations if any passengers are entering or exiting.
3.1. System Set-Up
3.2. System Workflow
- Platform landmark detection and identification: this detects the start/end landmarks of the platform by a pre-trained AI model (YOLOv4 [19] architecture) inference process, determining if the train is on the platform and establishing a reference point in the approximation phase for the ultimate accurate stop.
- Distance estimation: this support the precise stop process in the platform area. The distance to station stopping landmarks is calculated updating the predicted remaining distance of ATO. This calculus is based on a dense disparity map calculated by the Semi-Global Block Matching (SGBM) method [20].
- Passenger detection: using the same techniques but a different AI model, it detects passengers when they are boarding or exiting the train, managing the door opening and closing commands.
4. Deployment on SELENE Platform
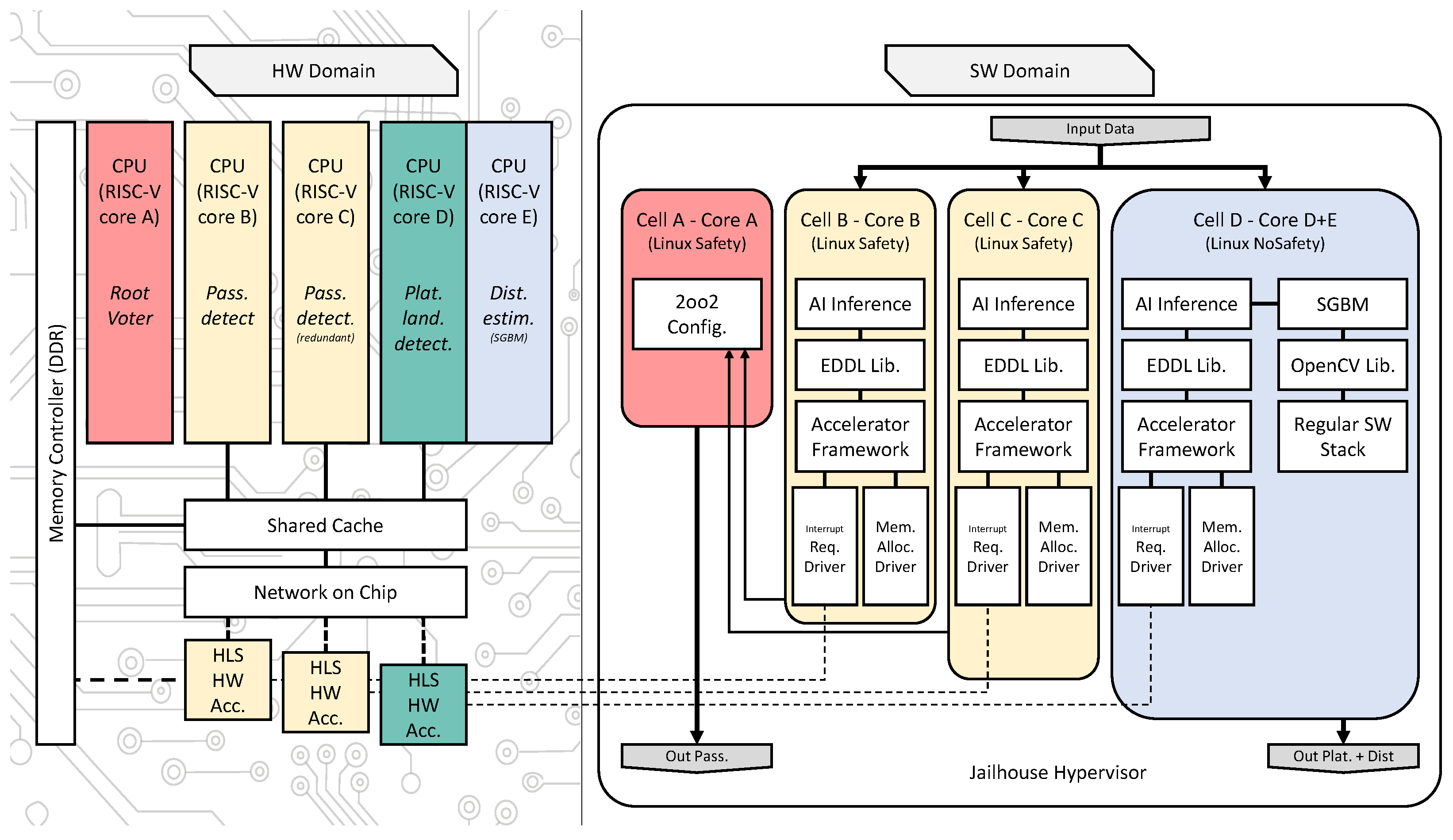
- HLSinf HW Accelerator extension: the creation of new layers to support the YOLOv4 architecture: a Support Tensor Machine (STM) layer which is a grouping of the three different layers (softmax, hyperbolic tangent and element-to-element multiplication), and an ADD layer (element-to-element addition).
- New Acceleration Runtime: enabling HLSinf HW accelerator and Linux OS communications, accelerators control, memory allocation, and interruption manager.
- AI-inference SW library extension: a new compute service, called SELENE, to port and extend the inference library, making the platform compatible with most known AI architectures.
- Hypervisor new extension: a porting solution to RISC-V CPU and enabling process isolation.
- RootVoter new extension: a porting solution to RISC-V CPU and enabling safety-related executions on the SELENE platform based on redundant execution.
4.1. SELENE AI HW Accelerator
4.2. Acceleration Runtime
4.3. AI-Inference SW Library
4.4. Jailhouse Hypervisor
4.5. RootVoter
5. Test Description
- System workflow validation test: the entire workflow of the system has been validated using dataset images. Apart from the correct functioning of the main functionalities, special attention has been paid to the following two points:
- –
- Back support libraries for the distance calculus: distance calculus requires an available implementation for the SGBM algorithm [26]. This implementation is ready in the OpenCV library but must be validated to ensure that the libraries that compute stereo SGBM matching can be cross compiled and executed in the SELENE platform with RISC-V architecture.
- –
- Model parsing compatibility: the models used for the use case are trained using the Darknet framework [30]. The Darknet output is not compatible with other frameworks and, for that reason, ONNX has been chosen as the sharing format. As ONNX establishes a standard format, but there are no standard parsers or exporters, the compatibility of exported models with the EDDL ONNX parser must be validated. Inference tests were used to validate this compatibility.
- AI models (passenger and landmark detectors) inference performance test: this test focuses on the performance of the machine learning algorithm in the platform. In the test, the Tiny-YOLOv4 inferences for landmark and passenger detection are executed with different computing precision. The models are 608 × 608 RGB image input models that were trained using transfer learning with a database labelled with railway traffic signals, platform landmarks and people/passengers. In addition, the goal has also been to compare the performance of the accelerator against SoA existing hardware such as Xilinx Alveo and Nvidia AGX Xavier after normalising inference time with respect to frequency.
- –
- VCU118: this test aims to compare the performance executing the Tiny-YOLOv4 use-case model in the VCU118 SELENE platform using different accelerator configurations (different NN layer distribution on CPU and HW accelerator and different bit number precision). It also compares the performance of the accelerator against the CPU on inference tasks to calculate the impact of implementing the accelerator over the whole platform performance.
- –
- Xilinx Alveo: this test is based on an inference benchmark (a technology-agnostic evaluation) evaluating HLSinf in a Xilinx Alveo Board in order to validate and evaluate the accelerator in an existing environment to isolate the results from the custom SW stack that is required for VCU118 board. Tiny-YOLOv4 for railway signalling detection was evaluated on a Xilinx Alveo with external Intel CPUs facilitating the evaluation of the accelerator isolated from CPU performance.
- –
- Nvidia Jetson AGX Xavier: the same image inference test is executed in the GPU of the SoA edge computing platforms.
- Distance calculus performance test: an evaluation on SGBM performance is also a target for the test. The performance of the SGBM algorithm also allows a CPU speed evaluation.
- Process isolation test: unfortunately, the process of porting the Jailhouse hypervisor to the SELENE platform could not be completed in time before the end of the project and is still ongoing. However, within this work, the correct functioning of hypervisor has been tested over RISC-V architecture using a QEMU [31] machine emulator and virtualizer. This consists of concurrently executing multiple applications of the use case on a single RICS-V SoC allowing it to evaluate non-interference properties. This also allows any impact on application precision to be evaluated as well as the performance impact of shared/contended resources. First of all, each process has been executed separately to obtain the performance data without interference from other processes. Then, in a second cell, a workload is introduced incrementally based on micro-benchmarks in interference analysis [32]. All combinations to two of the four cells have been tested. The result of these tests has been compared to the initial evaluation performed in isolation to check that performance degradation is bounded and functional behavior remains unaffected. With this configuration, the impact of several types of interference (shared memory, shared cache, shared buses) on each selected algorithm has been studied.
- Redundancy and RV test: two different tests have been carried out for RV evaluation. The first one at use-case level where PassengerDetector functionality is executed redundantly on the SELENE platform. The RV is configured for a 2oo2 scheme. The PC is used for interaction with the processes on the SELENE platform. Instead of the real door-closing command system, a stub is running on the PC to receive the command from the PassengerDetector.Each PassengerDetector process sends a vote containing the command value to the RV. In order to simulate the failure, a script has been developed enabling it to be injected in order to vote failure, send a wrong vote and test the system. The RV checks whether both of the two processes send the same vote. The master process checks the result of the RV. If the check was successful, the master process sends a command with the door-closing signal. If the check is not successful, it will send an order to keep the doors opened.The second one is related to low-level platform validation, where the RV subsystem has been validated by means of FPGA-based Fault Injection (FFI). This application performs a staggered redundant execution of a matrix multiplication kernel with two replicated processes. At the end of the kernel execution, each redundant process calculates the digest (CRC32) for the output results. These digests (from each process) are loaded to the dedicated dataset registers of the RV cell. For the sake of simplicity, this application uses only one RV cell. The voting scheme configured for the RV cell is 2oo2, and the configured timeout (maximum time to wait for the datasets) is 1 ms.FFI experiments have been carried out using a customized version of DAVOS [33] fault injection tool. Faults have been injected into the CPU cores: Cell C (which executes one of the kernel replicas), and Cell B (which executes the monitoring process). The considered faultload comprises single bit-flips in those cells of FPGA configuration memory that configure targeted SoC components (CPU cores). A total of ten thousand faults have been injected during FFI experiments (5000 faults per each targeted CPU core).The outcome of each individual injection run (fault effect) is described in terms of failure modes. The fault is masked when it produces no effect on the system. The fault leads to Replica fail when the RV raises the validity flag for one of the replicas. The fault leads to replica timeout when the RV raises the timeout flag for one of the replicas. Finally, the fault effect is double the modular redundancy fail when the RV is unable to establish an agreement, and the kernel result does not match the fault-free run. At the end of the experiment, DAVOS calculates the percentage of each failure mode as the ratio between the number of registered failure modes of each type and the total number of injected faults.
6. Test Results
6.1. AI Model Inference Performance Results
6.2. Distance Calculus Performance Results
6.3. Process Isolation Results
6.4. Redundancy and RootVoter Results
7. Discussion and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Shift2Rail—Home. Available online: https://shift2rail.org/ (accessed on 5 May 2023).
- Reddi, V.J.e.a. MLPerf Inference Benchmark. arXiv 2019, arXiv:1911.02549. [Google Scholar]
- CORDIS—SELENE. Available online: https://cordis.europa.eu/project/id/871467/en (accessed on 5 May 2023).
- Waterman, A.; Lee, Y.; Patterson, D.A.; Asanović, K. The RISC-V Instruction Set Manual, Volume I: User-Level ISA, Version 2.0.; Technical Report UCB/EECS-2014-54; EECS Department, University of California: Berkeley, CA, USA, 2014. [Google Scholar]
- Palmer, A.W.; Sema, A.; Martens, W.; Rudolph, P.; Waizenegger, W. The Autonomous Siemens Tram. In Proceedings of the IEEE 23rd International Conference on Intelligent Transportation Systems (ITSC), Rhodes, Greece, 20–23 September 2020; IEEE: Piscataway, NJ, USA, 2020. [Google Scholar] [CrossRef]
- Guerrieri, M.; Parla, G. Smart Tramway Systems for Smart Cities: A Deep Learning Application in ADAS Systems. Int. J. Intell. Transp. Syst. Res. 2022, 20, 745–758. [Google Scholar] [CrossRef]
- Ristić-Durrant, D.; Franke, M.; Michels, K. A Review of Vision-Based On-Board Obstacle Detection and Distance Estimation in Railways. Sensors 2021, 21, 3452. [Google Scholar] [CrossRef] [PubMed]
- Alstom Demonstrates Fully Autonomous Driving of a Shunting Locomotive in the Netherlands. Available online: https://www.alstom.com/press-releases-news/2022/11/alstom-demonstrates-fully-autonomous-driving-shunting-locomotive-netherlands (accessed on 5 May 2023).
- Train Autonome Service Voyageurs: Essais Réussis. Available online: https://www.youtube.com/watch?v=vlEy7GYe684&ab_channel=GroupeSNCF (accessed on 5 May 2023).
- Autonomous Train Tests Were Carried Out Succesfully in Finland. Available online: https://www.proxion.fi/en/autonomous-train-tests-were-carried-out-succesfully-in-finland/ (accessed on 5 May 2023).
- Railtech—DB Cargo Automates Shunting to Boost Single Wagon Load Traffic. Available online: https://www.railfreight.com/railfreight/2021/10/27/db-cargo-automates-shunting-to-boost-single-wagon-load-traffic/?gdpr=accept (accessed on 5 May 2023).
- Cognitive Pilot—Tram Automation Software Contract Awarded in Shanghai. Available online: https://en.cognitivepilot.com/breaking-news/fitsco-tram-english/ (accessed on 5 May 2023).
- RailTech—Remote-Controlled Shunting. Available online: https://www.railtech.com/digitalisation/2020/09/25/remote-controlled-shunting-on-tests-in-switzerland/ (accessed on 5 May 2023).
- Digitale Schiene—Fourteen Eyes on the Road Ahead: Second Sensors4Rail Test Project Successful. Available online: https://digitale-schiene-deutschland.de/en/Sensors4Rail-test-project (accessed on 5 May 2023).
- Youtube—Train Autonome: Automatisation de la Lecture de la Signalisation Latérale. Available online: https://www.youtube.com/watch?v=WiYavvqh7Bk&ab_channel=GroupeSNCF (accessed on 5 May 2023).
- La Reconnaissance Faciale des Signaux, le Projet ARTE D’alstom. Available online: https://mediarail.wordpress.com/2022/10/23/alstom-projet-arte-basse-saxe/ (accessed on 5 May 2023).
- Perez-Cerrolaza, J.; Obermaisser, R.; Abella, J.; Cazorla, F.; Grüttner, K.; Agirre, I.; Ahmadian, H.; Allende, I. Multi-Core Devices for Safety-Critical Systems: A Survey. ACM Comput. Surv. 2020, 53, 1–38. [Google Scholar] [CrossRef]
- Mc Guire, N.; Allende, I. Approaching certification of complex systems. In Proceedings of the 50th Annual IEEE/IFIP International Conference on Dependable Systems and Networks Workshops (DSN-W), Valencia, Spain, 29 June–2 July 2020; pp. 70–71. [Google Scholar] [CrossRef]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Hirschmuller, H. Stereo Processing by Semiglobal Matching and Mutual Information. IEEE Trans. Pattern Anal. Mach. Intell. 2008, 30, 328–341. [Google Scholar] [CrossRef] [PubMed]
- Siemens. JAILHOUSE. Available online: https://github.com/siemens/jailhouse (accessed on 5 May 2023).
- Gerstinger, A.; Kantz, H.; Scherrer, C. TAS Control Platform: A Platform for Safety-Critical Railway Applications. ERCIM News 2008, 2008. [Google Scholar]
- Cancilla, M.; Canalini, L.; Bolelli, F.; Allegretti, S.; Carrión, S.; Paredes, R.; Gómez, J.A.; Leo, S.; Piras, M.E.; Pireddu, L.; et al. The DeepHealth Toolkit: A Unified Framework to Boost Biomedical Applications. In Proceedings of the 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021; pp. 9881–9888. [Google Scholar] [CrossRef]
- Flich, J.; Medina, L.; Catalán, I.; Hernández, C.; Bragagnolo, A.; Auzanneau, F.; Briand, D. Efficient Inference Of Image-Based Neural Network Models In Reconfigurable Systems With Pruning And Quantization. In Proceedings of the 2022 IEEE International Conference on Image Processing (ICIP), Bordeaux, France, 16–19 October 2022; pp. 2491–2495. [Google Scholar] [CrossRef]
- NOEL-V. Available online: https://www.gaisler.com/index.php/products/processors/noel-v (accessed on 5 May 2023).
- OpenCV. Available online: https://opencv.org/ (accessed on 5 May 2023).
- Accelerating DNNs with Xilinx Alveo Accelerator Cards. Available online: https://docs.xilinx.com/v/u/en-US/wp504-accel-dnns (accessed on 5 May 2023).
- Jetson AGX Xavier and the New Era of Autonomous Machines. Available online: https://info.nvidia.com/rs/156-OFN-742/images/Jetson_AGX_Xavier_New_Era_Autonomous_Machines.pdf (accessed on 5 May 2023).
- Etxeberria-Garcia, M.; Zamalloa, M.; Arana-Arexolaleiba, N.; Labayen, M. Visual Odometry in Challenging Environments: An Urban Underground Railway Scenario Case. IEEE Access 2022, 10, 69200–69215. [Google Scholar] [CrossRef]
- Biddle, P.; England, P.; Peinado, M.; Willman, B. The Darknet and the Future of Content Protection. In Proceedings of the ACM Workshop on Digital Rights Management, Washington, DC, USA, 18 November 2002; Volume 2696, pp. 155–176. [Google Scholar] [CrossRef]
- QEMU—A Generic and Open Source Machine Emulator and Virtualizer. Available online: https://www.qemu.org/ (accessed on 5 May 2023).
- Ensuring Software Timing Behavior in Critical Multicore-Based Embedded Systems. Available online: https://www.embedded.com/ensuring-software-timing-behavior-in-critical-multicore-based-embedded-systems/ (accessed on 5 May 2023).
- DAVOS—A Fault Injection Toolkit for Dependability Assessment, Verification, Optimization and Selection of Hardware Desings. Available online: https://github.com/IlyaTuzov/DAVOS (accessed on 5 May 2023).




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Tiny YOLOv4 Layers | VCU118 (100 MHz) (SELENE) | Alveo (250 MHz) (HW-Acc of SELENE) | AGX Xavier GPU (1.377 MHz) | AGX Xavier GPU (250 MHz) | |
|---|---|---|---|---|---|
| All executed on CPU | 45,685,922 | - | - | - | |
| FP32 | HLSinf | 1799 | 364 | 17 | 94 |
| Transform | 479 | 7 | |||
| Others | 4 | 0 | |||
| Total | 2282 | 371 | |||
| FP16 | HLSinf | 1548 | 119 | 13 | 72 |
| Transform | 726 | 6 | |||
| Others | 4 | 2 | |||
| Total | 2278 | 127 | |||
| INT8 | HLSinf | 796 | 66 | N/A | N/A |
| Transform | 1135 | 15 | |||
| Others | 4 | 1 | |||
| Total | 1935 | 82 |
| VCU118 w.r.t AGX Xavier | ||||||
|---|---|---|---|---|---|---|
| VCU118 (2 Core) SELENE | AGX Xavier (ARM 8 Core) | Raw Comp. | F.A. Comp. | |||
| OpenCV SGBM | Total time | Time Using Single Core | Total time | Time Using Single Core | % | % |
| Matching Time | 48 | 96 | 0.8 | 6.4 | 6.66 | 146.67 |
| Filtering Time | 20 | 40 | 0.3 | 2.4 | 6 | 132 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Labayen, M.; Medina, L.; Eizaguirre, F.; Flich, J.; Aginako, N. HPC Platform for Railway Safety-Critical Functionalities Based on Artificial Intelligence. Appl. Sci. 2023, 13, 9017. https://doi.org/10.3390/app13159017
Labayen M, Medina L, Eizaguirre F, Flich J, Aginako N. HPC Platform for Railway Safety-Critical Functionalities Based on Artificial Intelligence. Applied Sciences. 2023; 13(15):9017. https://doi.org/10.3390/app13159017
Chicago/Turabian StyleLabayen, Mikel, Laura Medina, Fernando Eizaguirre, José Flich, and Naiara Aginako. 2023. "HPC Platform for Railway Safety-Critical Functionalities Based on Artificial Intelligence" Applied Sciences 13, no. 15: 9017. https://doi.org/10.3390/app13159017
APA StyleLabayen, M., Medina, L., Eizaguirre, F., Flich, J., & Aginako, N. (2023). HPC Platform for Railway Safety-Critical Functionalities Based on Artificial Intelligence. Applied Sciences, 13(15), 9017. https://doi.org/10.3390/app13159017