1. Introduction
A vital prerequisite for portable electronic devices such as digital cameras, tablets, mobiles, and laptops is lowering the utilization and dissipation of power. An essential technique for image compression in digital signal and image processing is the Discrete Cosine Transform (DCT). Due to its excellent power compaction property, a significant part of image and signal processing applications is performed by DCT and Inverse DCT (IDCT). The hardware implementation of DCT necessitates a substantial number of arithmetic computations and power, especially for image and video coding applications. Data integration, reduced bit error, and compression applications utilize the DCT, a universal orthogonal lossless transformation for digital image and signal processing. The limitations imposed on the processors’ capacity due to technological advancements make it challenging to obtain accurate outputs while performing a DCT operation.
The frequently used transforms in compression applications are the DCT, most notably when processing digital images. It is most often 2D DCT that is used in these applications on smaller input sizes of 8 × 8, 16 × 16, or 32 × 32. The prevalent use of DCT has attracted much attention in researching these fast algorithms’ implementation. The power can be lowered by minimizing the multiplications involved in the DCT implementation. The early 1980s saw the appearance of eight-point DCT/IDCT in the fast algorithm [
1,
2,
3,
4,
5] implementations, requiring more mathematical computations and increased power consumption. The DCT implementation using the Loeffler algorithm [
6] consumes less power as it can be realized with 29 add and 11 multiply operations. Optimizing the hardware implementation is essential to reduce the power while maintaining the speed required for high-performance processors. The efficiency of the hardware resources used, such as multipliers and adders, directly indicates the performance of the hardware implementation of the DCT algorithm used. DCT implementations with reduced hardware and optimized arithmetic computations have been proposed and designed in the past.
A computationally intensive algorithm, DCT encompasses many multiplications. In the contemporary era, several DCT algorithms were designed to minimize the computations and power consumed. The DCT has recently taken over as the de facto norm for compressing images before transmission via communication channels with constrained capacity. In contrast to the Fast Fourier Transform, lesser multiplications are one of the main advantages of DCT and the computationally efficient Fast Cosine Transform.
Numerous excellent algorithms were devised in the past, and there is considerable literature to support these algorithms. Although there is a noticeable reduction in the computational complexity of DCT implementations using fast algorithms, there still arises a necessity to perform floating-point operations. Despite their accuracy, floating-point computations are costly when considering circuit complexity and power. One way to improve these fast algorithms’ speed is by minimizing the floating-point operations. This issue can be circumvented to a small extent by utilizing fixed-point multipliers and shifters.
Different algorithms are presented in the literature, and it was found that the algorithms could be improved using various techniques. In existing DCT algorithm implementations, there was a trade-off between the design metrics of power, area, and delay. In the past, various techniques were used to lower the hardware complexity of the algorithms.
An implementation of the Loeffler DCT algorithm was designed by Aakif et al. [
7] using adders and shifters. A Flow Graph Algorithm (FGA) was proposed by using unsigned constant coefficient multiplications. Improvements in power, speed, and area were achieved as add and shift operations were used to accomplish multiplications. Madanayake et al. [
8] presented an algorithm by incorporating algebraic integer coding in the ID DCT computation. This modified ID transform was used to realize a 2D DCT architecture further. The 2D DCT computation of the proposed architecture was based on the Arai algorithm. An eight-point DCT based on the Loeffler algorithm using pipelining was proposed in the work presented by Shen et al. [
9]. The implementation was optimized by using 2D Algebraic Integer (AI) encoding and the computations were minimized using shifters and adders instead of multipliers.
Kitsos et al. [
10] proposed two FPGA architectures for high-performance processors to perform 2D DCT computations using Distributed Arithmetic for arithmetic computations. The DCT operation was implemented on 8 × 8 image blocks, and the row–column arithmetic realization was utilized in the design. Edirisuriya et al. [
11] proposed a 1D DCT computation algorithm based on algebraic integer encoding. The Arai DCT algorithm was used for the 8 × 8 DCT transform computation in 2D. The real-time implementation of the algebraic integer DCT was designed using an area-efficient architecture that showed a performance improvement compared to the architecture using four channels.
Coelho et al. [
12] focused on using algebraic integers to perform the DCT algorithm computation. The Loeffler algorithm was used to implement the eight-point DCT design with error-free operation up to the last step. Further, the final reconstruction step (FRS) algorithm was implemented using the newly proposed digital architecture. Xing et al. [
13] presented an architecture for a multiplier-less DCT suitable for capsule endoscopy applications. The application of three approximating methods such as threshold setting, approximate adders, and coefficient optimization was used in the design of the multiplierless DCT algorithm. Potluri et al. [
14] introduced a novel approximation technique for an eight-point DCT requiring just 14 additions with no multiplication operations. Compared to the existing DCT approximations, the computational and algorithm complexity was less. The separability property of 2D DCT was utilized to implement the proposed designs by successively calling the 1D DCT architecture.
Kumar et al. [
15] proposed an architecture design for inexact adders to implement DCT without multipliers. The utilization of the proposed inexact adders resulted in power and area savings due to the tolerance of errors by the DCT computations. The main inferences observed from the analysis results were a noticeable reduction in computational complexity while maintaining an acceptable PNSR. Balasubramanian et al. [
16], in their work, explored and analyzed the impact of approximate addition while performing image compression. The DCT implementation in an Application Specific Integrated Circuit (ASIC) design environment was carried out using both accurate and approximate adders. A considerable reduction in the size of the compressed images was observed when DCT was implemented using approximate adders. Compared with the carry look ahead adder, the approximate adders exhibited reduced power, area, and delay when implemented using standard cells. Their work focused on obtaining the best possible approximate adder design for image compression applications in the digital domain.
Almurib et al. [
17] designed a framework using inexact computing addressing a few difficulties linked with DCT compression. The processing of the framework proposed involved three different stages. The first stage encompassed eradicating floating-point computations and designing the DCT using additions and logical left and right shift operations. Further data reduction was accomplished in the second stage by filtering the frequencies the human eye cannot detect. The third stage introduced inexact adders to compute DCT to minimize delay and power. A reduction in the delay and energy with acceptable accuracy was achieved with the proposed framework for image processing applications.
In their work, Zhang et al. [
18] designed a CORDIC-based DCT/IDCT unified architecture. An additional mode controller was required to decide whether to use a DCT or IDCT operation in contrast to the existing architectures. This reduced the total hardware resources required for the unified architecture. The design was improved further by incorporating an efficient adder and approximation-based shifter. Although the power was reduced, the critical path delay was slightly increased compared to existing architectures.
A DCT technique using approximate computing was proposed by Huang et al. [
19] to configure the transform matrix size in accordance with the retained coefficients obtained in the scanning. The proposed technique’s addition operations and energy were lesser than the existing approximate computing technique. The simulation of the proposed technique was evaluated using MATLAB and on an FPGA platform. Significant reductions in power, gate counts, implementation time, and the number of adders were observed compared to the existing approximate adders. Wu et al. [
20] computed an eight-point DCT using a modified Loeffler scheme where the multiplications are performed in the last stage. A new approximation algorithm using shift and add operations in place of multiplications is also incorporated into their work.
A novel distributed arithmetic architecture was proposed by Shams et al. [
21] that focused on reducing the area and power. The newly introduced compression scheme generated a butterfly structure with lesser additions. Lee et al. [
22] introduced a 2m-point algorithm for DCT with almost half the multiplication operations compared to the efficient prevailing algorithms in his work. Even though the structural design of the algorithm was more straightforward than the existing algorithms, the number of additions involved was slightly higher.
The algorithms mentioned above, even though fast, require floating-point multiplications resulting in complex and slow implementations. Faster computations can be accomplished by scaling and approximating the coefficients in the algorithms to substitute floating-point multiplications with fixed-point multiplications. The resulting algorithms are considerably faster than the existing designs, making them beneficial in many practical applications. These fast algorithms require a data bus of larger width to perform the fixed-point computations demanding an expensive VLSI implementation and higher power consumption. Hence, the DCT implementations using regular arithmetic computations and limited bus width is an area that attracts research.
High compression rates can be attained with DCT, but with high computational complexity and energy overheads. The human eye can tolerate minor degradations in the quality of the images by including small errors. DCT computations utilizing approximate computing have been proposed and designed in this research to reduce the computations and improve performance.
The input data are optimized using pipelining in the different stages of the DCT and IDCT algorithm improving the processing speed. The complexity of the arithmetic computations and power are minimized by utilizing error-tolerant adders, signed fixed-point multipliers, and shifters. Through the separability property of 2D DCT, the row–column decomposition approach is applied to compute the 2D DCT of each 8 × 8 image block segment. Each 8 × 8 image block’s DCT and IDCT can be accomplished with an abridged circuit complexity and enhanced efficiency in 34 clock cycles.
The B.G. Lee DCT algorithm design structure and the optimization of the B.G. Lee DCT algorithm using the proposed method is discussed in the methodology section.
Section 3 illustrates the ASIC implementation of 2D DCT/IDCT based on the B.G. Lee algorithm and the detailed architectural design utilizing the proposed error-tolerant adders and fixed-point multipliers. The implementation of the proposed method and the performance metric comparison of the proposed and prevailing DCT/IDCT architectures is presented in
Section 4.
Section 5 concludes the overall research.
3. ASIC Implementation of 2D DCT/IDCT Based on B.G Lee DCT Algorithm
The B.G. Lee algorithm [
24] architecture with a novel hardware implementation is used to compute the 2D DCT for each 8 × 8 image segment. As 2D DCT is a separable transform, each 8 × 8 image block can be implemented using the row–column decomposition method. The 2D IDCT computation reconstructs the original image using the same method.
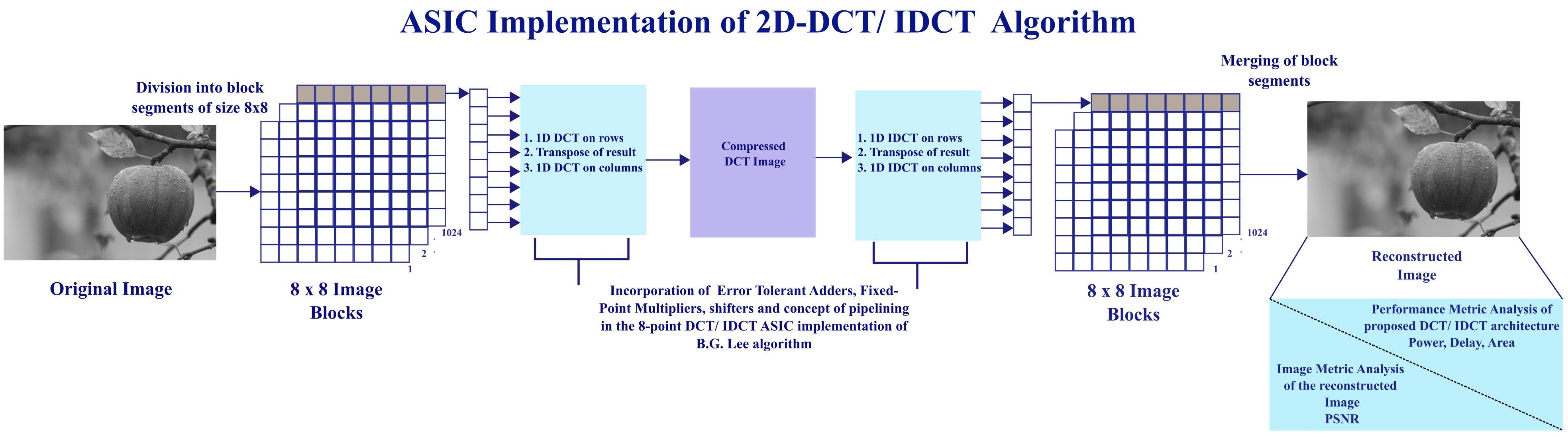
The digital image compression using the B.G. Lee algorithm was implemented on digital images of 256 × 256 pixels with a resolution of 8 bits. The structure of the 2D DCT/IDCT using the B.G. Lee algorithm with the proposed error-tolerant adders, the proposed fixed-point multiplier, and shifters is illustrated in
Figure 5. The 256 × 256 digital image is divided into 1024 image segment blocks of size 8 × 8. Each 8 × 8 image segment block is then converted to [64:1] column matrices. Eight-point 1D DCT is performed on each [64:1] column matrix. This column matrix is once again converted to an 8 × 8 matrix, and then transposed and converted back to a [64:1] column matrix. Once again, eight-point 1D DCT is performed on this transposed column matrix. Now the compressed image is obtained.
The reverse process is applied to recover the digital image from the compressed form. Eight-point 1D IDCT is performed on each [64:1] column matrix. The column matrix is rearranged to form 8 × 8 image segments, the transpose of each image segment is taken, and then each 8 × 8 image segment is converted to a [64:1] column matrix. Finally, eight-point 1D IDCT is applied on this transposed matrix. The resultant column matrix is converted to the original 8 × 8 image block. The original image is recovered by merging all of the 8 × 8 image blocks.
3.1. Transposition Buffer Register for 2D DCT
The decomposition row–column technique is used for the DCT computation of each 8 × 8 image segment using the separability property of 2D DCT. The 2D DCT of an 8 × 8 image matrix is carried out with eight 8 × 1 1D DCTs.
Figure 6 depicts the synchronization of a single pixel on an 8 × 8 block of an image using a clock signal. The 1D DCT is performed initially on the image block’s first row, represented by addresses R11 to R18. Then, the 1D DCT is carried out on the second row till it traverses to the eighth row. The 1D DCT is performed similarly for all 8 × 8 image blocks of the 256 × 256 image.
The data are input in a parallel manner in the proposed method. The transpose of each image block is as depicted in
Figure 6 and each pixel element is 8 bits in size, represented by Rij, where the row is denoted by i and the column by j. In the first eight clock cycles, each row is written in parallel to the corresponding memory location such that each row becomes the column in the memory. To realize the transpose of each 8 × 8 image block, in the ninth clock, the pixels in M0 to M7 are read out simultaneously. The columns 1 to 8 of each 8 × 8 image block are read out in parallel in the clock cycles from 10 to 17. Once the 1D DCT is performed on all 8 × 8 image blocks, the transpose of each image block is taken to obtain the matrix, as indicated in
Figure 6. The 1D DCT is applied on each 8 × 8 image block of the resultant matrix similarly. The image matrix obtained after 1D DCT operation is further processed to execute the 1D IDCT on each of the 8 × 8 image segments. The transpose of the resultant image matrix is obtained and the 1D IDCT is applied on the resultant 8 × 8 image blocks.
3.2. Architectural Design for B.G. LEE DCT Algorithm
The concepts of pipelining and approximate computing are applied to enhance the data of B.G. Lee’s eight-point algorithm for DCT and IDCT computations. The operations involved in each cycle are further simplified, and the performance is improved by using shift and add operations to reduce the multiplications.
The eight-point DCT design utilizing the B.G. Lee algorithm in conjunction with pipelining is shown in
Figure 7. A pipelined method of eight stages is employed, where only a single mathematical computation is performed in each stage. Four adders and four subtractors are utilized to add and subtract the inputs x
0–x
7 in the first stage. The signed error-tolerant adders proposed in our work in [
23] execute the arithmetic operations. The results of the first stage are stored in registers. The decimal values of the cosine coefficients are converted to their hexadecimal equivalents, which are stored as constants. In the second stage, these cosine constants are used in the multiplication process using the proposed fixed-point signed multiplier. The remaining multiplications of the second stage are accomplished utilizing shift and additions. Registers are utilized to store the results.
The third stage results are obtained using four addition and four subtraction operations. In the fourth stage, fixed-point signed multipliers are used to multiply the cosine constants with the subtractor results of the third stage. Alternate addition and subtraction operations are carried out in the fifth stage. The subtractor results obtained in the fifth stage are multiplied with cosine constants in the sixth stage. Four adders are used to carry out the addition operations in the seventh stage. Finally, in the eighth stage, the final DCT output is obtained by shifting the results of the seventh stage by one bit to the right to accomplish division by 2. The cosine constant factors used in
Figure 7 are given in
Table 1.
The multiplication operation is carried out using the proposed signed 16-bit fixed-point multipliers that are designed using shift and add operations. The most significant 8 bits represent the integer part, and the fraction part is represented by the least significant 8 bits of the multiplier and the multiplicand.
Figure 8 illustrates the design of the eight-point IDCT using the B.G. Lee algorithm in conjunction with pipelining. The coefficients obtained after DCT y
0 to y
7 are used as input to the IDCT structure. The different stages transition from 1 to 8 as the reverse operation of DCT. The input data x
0 to x
7 applied to the DCT are obtained as output after IDCT.
The input registers x
0 to x
7 in
Figure 7 reflect the eight-point input pixel data. Clocks from 1 to 8 indicate the eight stages of the pipelined DCT/IDCT design. Eight clock cycles are needed to compute the 1D DCT/IDCT for an 8 × 8 image segment. The B.G. Lee algorithm’s DCT transformation involves four clock cycles for each row of pixels, making it idle for the next four clock cycles before taking the next pixel row. The redistribution of the input data and the incorporation of pipelining to uniformly distribute the arithmetic operations over the various stages is achieved in the proposed method. The DCT/IDCT operation is carried out for eight clock cycles by the inclusion of registers in such a way that only one addition or multiplication operation is included in each clock cycle.
Table 2 and
Table 3 depict the input data flow of the B.G. Lee eight-point DCT/IDCT algorithm.
The pipelined architecture that performs 2D DCT using the separability property by performing 1D DCT on the rows of each 8 × 8 image segment and on the columns is illustrated in
Figure 9. The hardware architecture designed to perform 1D IDCT on the rows and columns of each 8 × 8 image segment is the same and has been reused. A 256 × 256 image is divided into smaller blocks of size 8 × 8. Each 8 × 8 image block comprises 64 pixels, containing eight rows and eight columns. All of the pixels are stored in the generated memory.
Each row of image pixels of the first 8 × 8 block is given as input to compute the 1D DCT and then each row is output per cycle after the transformation. Eight clock cycles are needed to compute the 1D DCT of the eight rows of each 8 × 8 image block. The bit widths of the digital input and output data of the eight-point DCT and IDCT with respect to the eight-stage pipeline architecture of
Figure 7 and
Figure 8 are tabulated in
Table 4. The data range of the input image is −255 to 255 and the bit width is 9 bits for the first 1D DCT, where the sign bit is represented by the 9th bit. The width of the output obtained from the first 1D DCT is 17 bits. After eight clock cycles, the transpose of the transformed coefficients is taken. The transpose of the transformed coefficients is obtained in the 9th clock cycle. The columns of the transposed image is then subjected to 1D DCT. The input and output bit width of the data for the second 1D DCT is 17 bits. The computation of the 1D DCT on the resultant 8 × 8 image block requires 8 clock cycles. Once the 1D DCT is carried out, the 8 × 8 image blocks are ready for the IDCT transformation to recover the original image. The input and output bit width for the first 1D IDCT is 17 bits. In the next 8 clock cycles, the 1D IDCT is performed on the rows of the transformed image segment. The transpose of the resultant matrix is taken in the 9th clock cycle. Eight clocks are required to perform 1D IDCT on the columns of the resultant image segment to obtain the reconstructed image. The input bit width of the final 1D IDCT is 17 bits and the output bit width is 9 bits. Each 8 × 8 image block takes 34 clock cycles for the DCT and IDCT computation. The DCT algorithm is made more efficient by the integration of pipelining.
The incorporation of error-tolerant adders in the butterfly diagram computations, the utilization of the proposed low-power fixed point multipliers and shifters for the multiplications involved, along with the application of pipelining with the efficient row–column architectural design makes the B.G Lee algorithm implementation efficient in terms of power and computational efficiency. The 2D DCT/IDCT of each 8 × 8 image segment can be quickly processed in 34 clock cycles with a substantially reduced level of circuit complexity.

 ,
, 












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}