

A Flame Detection Algorithm Based on Improved YOLOv7

Abstract
:1. Introduction
2. Background and Related Work
2.1. Background on Target Detection
2.2. Parameter-Free Attention Module
2.3. ConvNeXt Model
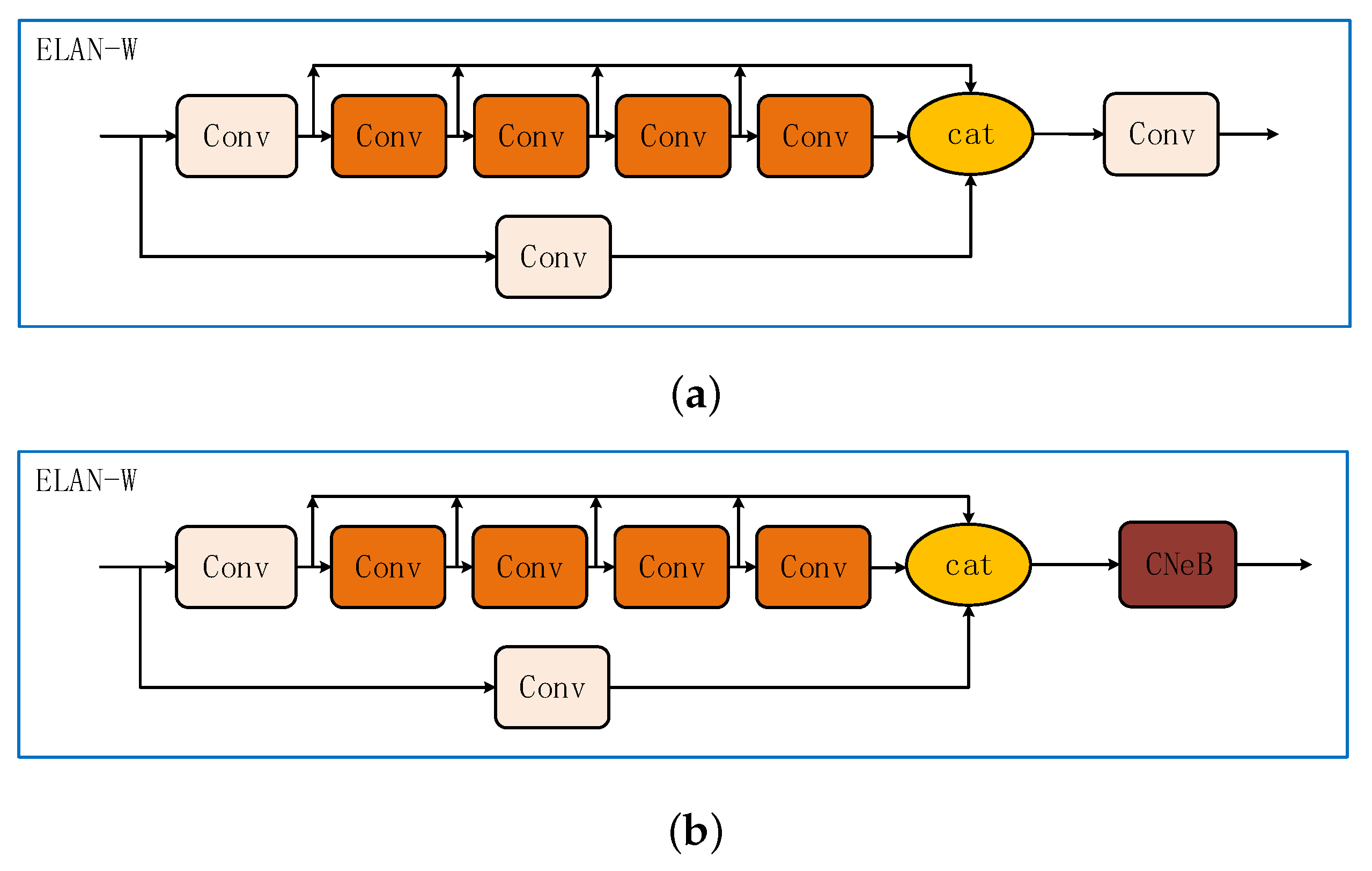
3. Proposed Model
3.1. Improvement on YOLOv7 Backbone Structure
3.2. Improvement on YOLOv7 Head Structure
4. Experiments Design
4.1. Dataset
4.2. Evaluation Metrics
5. Results and Analysis
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhang, L.; Wang, G. Design and Implementation of Automatic Fire Alarm System based on Wireless Sensor Networks. In Proceedings of the 2009 International Symposium on Information Processing, ISIP’09, Huangshan, China, 13–16 April 2009; pp. 410–413. [Google Scholar]
- Foggia, P.; Saggese, A.; Vento, M. Real-Time Fire Detection for Video-Surveillance Applications Using a Combination of Experts Based on Color, Shape, and Motion. IEEE Trans. Circuits Syst. Video Technol. 2015, 25, 1545–1556. [Google Scholar] [CrossRef]
- Zhang, Q.; Liu, X.; Huang, L. Video Image Fire Recognition Based on Color Space and Moving Object Detection. In Proceedings of the International Conference on Artificial Intelligence and Computer Engineering (ICAICE), Beijing, China, 23–25 October 2020. [Google Scholar]
- Girshick, R.B.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2014, Columbus, OH, USA, 23–28 June 2014; IEEE Computer Society: Washington, DC, USA, 2014; pp. 580–587. [Google Scholar] [CrossRef] [Green Version]
- Wu, R.; Hua, C.; Ding, W.; Wang, Y.; Wang, Y. Flame and Smoke Detection Algorithm for UAV Based on Improved YOLOv4-Tiny. In Proceedings of the PRICAI 2021: Trends in Artificial Intelligence—18th Pacific Rim International Conference on Artificial Intelligence, PRICAI 2021, Hanoi, Vietnam, 8–12 November 2021; Pham, D.N., Theeramunkong, T., Governatori, G., Liu, F., Eds.; Springer: Berlin/Heidelberg, Germany, 2021; Volume 13031, pp. 226–238. [Google Scholar] [CrossRef]
- Zhang, H.; Wang, Z.; Chen, M.; Peng, Y.; Gao, Y.; Zhou, J. An Improved YOLOv3 Algorithm Combined with Attention Mechanism for Flame and Smoke Detection. In Proceedings of the Artificial Intelligence and Security—7th International Conference, ICAIS 2021, Dublin, Ireland, 19–23 July 2021; Sun, X., Zhang, X., Xia, Z., Bertino, E., Eds.; Springer: Berlin/Heidelberg, Germany, 2021; Volume 12736, pp. 226–238. [Google Scholar] [CrossRef]
- Wang, Y.; Hua, C.; Ding, W.; Wu, R. Real-time detection of flame and smoke using an improved YOLOv4 network. Signal Image Video Process 2022, 16, 1109–1116. [Google Scholar] [CrossRef]
- Yang, T.; Xu, S.; Li, W.; Wang, H.; Shen, G.; Wang, Q. A Smoke and Flame Detection Method Using an Improved YOLOv5 Algorithm. In Proceedings of the IEEE International Conference on Real-Time Computing and Robotics, RCAR 2022, Guiyang, China, 17–22 July 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 366–371. [Google Scholar] [CrossRef]
- Ma, J.; Zhang, Z.; Xiao, W.; Zhang, X.; Xiao, S. Flame and Smoke Detection Algorithm Based on ODConvBS-YOLOv5s. IEEE Access 2023, 11, 34005–34014. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, Honolulu, HI, USA, 21–26 July 2017; IEEE Computer Society: Washington, DC, USA, 2017; pp. 6517–6525. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.; Liao, H.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Kuznetsova, A.; Maleva, T.; Soloviev, V. Detecting Apples in Orchards Using YOLOv3 and YOLOv5 in General and Close-Up Images. In Proceedings of the Advances in Neural Networks—ISNN 2020—17th International Symposium on Neural Networks, ISNN 2020, Cairo, Egypt, 4–6 December 2020; Han, M., Qin, S., Zhang, N., Eds.; Springer: Berlin/Heidleberg, Germany, 2020; pp. 233–243. [Google Scholar]
- Li, C.; Li, L.; Jiang, H.; Weng, K.; Geng, Y.; Li, L.; Ke, Z.; Li, Q.; Cheng, M.; Nie, W.; et al. YOLOv6: A Single-Stage Object Detection Framework for Industrial Applications. arXiv 2022, arXiv:2209.02976. [Google Scholar]
- Wang, C.; Bochkovskiy, A.; Liao, H.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. arXiv 2022, arXiv:abs/2207.02696. [Google Scholar]
- Chen, K.; Yan, G.; Zhang, M.; Xiao, Z.; Wang, Q. Safety Helmet Detection Based on YOLOv7. In Proceedings of the The 6th International Conference on Computer Science and Application Engineering, CSAE 2022, Virtual Event, China, 21–23 October 2022; Emrouznejad, A., Ed.; ACM: New York, NY, USA, 2022; pp. 31:1–31:6. [Google Scholar] [CrossRef]
- Zhang, Y.; Sun, Y.; Wang, Z.; Jiang, Y. YOLOv7-RAR for Urban Vehicle Detection. Sensors 2023, 23, 1801. [Google Scholar] [CrossRef]
- Liu, X.; Yan, W.Q. Vehicle-Related Distance Estimation Using Customized YOLOv7. In Proceedings of the Image and Vision Computing—37th International Conference, IVCNZ 2022, Auckland, New Zealand, 24–25 November 2022; Yan, W.Q., Nguyen, M., Stommel, M., Eds.; Springer: Berlin/Heidelberg, Germany, 2022; Volume 13836, pp. 91–103. [Google Scholar] [CrossRef]
- Hu, B.; Zhu, M.; Chen, L.; Huang, L.; Chen, P.; He, M. Tree species identification method based on improved YOLOv7. In Proceedings of the 8th IEEE International Conference on Cloud Computing and Intelligent Systems, CCIS 2022, Chengdu, China, 26–28 November 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 622–627. [Google Scholar] [CrossRef]
- Pham, V.; Nguyen, D.; Donan, C. Road Damage Detection and Classification with YOLOv7. In Proceedings of the IEEE International Conference on Big Data, Big Data 2022, Osaka, Japan, 17–20 December 2022; Tsumoto, S., Ohsawa, Y., Chen, L., den Poel, D.V., Hu, X., Motomura, Y., Takagi, T., Wu, L., Xie, Y., Abe, A., et al., Eds.; IEEE: Piscataway, NJ, USA, 2022; pp. 6416–6423. [Google Scholar] [CrossRef]
- Yang, L.; Zhang, R.; Li, L.; Xie, X. SimAM: A Simple, Parameter-Free Attention Module for Convolutional Neural Networks. In Proceedings of the Proceedings of the 38th International Conference on Machine Learning, ICML 2021, Virtual Event, 18–24 July 2021; Meila, M., Zhang, T., Eds.; Proceedings of Machine Learning Research, PMLR: London, UK, 2021; Volume 139, pp. 11863–11874. [Google Scholar]
- Zheng, Y.; Zhang, Y.; Qian, L.; Zhang, X.; Diao, S.; Liu, X.; Cao, J.; Huang, H. A lightweight ship target detection model based on improved YOLOv5s algorithm. PLoS ONE 2023, 18, e0283932. [Google Scholar] [CrossRef]
- Felzenszwalb, P.F.; Girshick, R.B.; McAllester, D.A.; Ramanan, D. Object Detection with Discriminatively Trained Part-Based Models. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 32, 1627–1645. [Google Scholar] [CrossRef] [Green Version]
- Liu, D.; Teng, W. Deep learning-based image target detection and recognition of fractal feature fusion for BIOmetric authentication and monitoring. Netw. Model. Anal. Health Inform. Bioinform. 2022, 11, 17. [Google Scholar] [CrossRef]
- Kumar, M.B.; Kumar, P.R. Moving Target Detection Strategy Using the Deep Learning Framework and Radar Signatures. Int. J. Swarm Intell. Res. 2022, 13, 1–21. [Google Scholar] [CrossRef]
- Israsena, P.; Pan-Ngum, S. A CNN-Based Deep Learning Approach for SSVEP Detection Targeting Binaural Ear-EEG. Frontiers Comput. Neurosci. 2022, 16, 868642. [Google Scholar] [CrossRef]
- Zheng, H.; Liu, J.; Ren, X. Dim Target Detection Method Based on Deep Learning in Complex Traffic Environment. J. Grid Comput. 2022, 20, 8. [Google Scholar] [CrossRef]
- Jia, P.; Zheng, Y.; Wang, M.; Yang, Z. A deep learning based astronomical target detection framework for multi-colour photometry sky survey projects. Astron. Comput. 2023, 42, 100687. [Google Scholar] [CrossRef]
- Viola, P.A.; Jones, M.J. Rapid Object Detection using a Boosted Cascade of Simple Features. In Proceedings of the 2001 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR 2001), with CD-ROM, Kauai, HI, USA, 8–14 December 2001; IEEE Computer Society: Washington, DC, USA, 2001; pp. 511–518. [Google Scholar] [CrossRef]
- Sisco, Y.J.; Carmona, R. Face recognition using deep learning feature injection: An accurate hybrid network combining neural networks based on feature extraction with convolutional neural network. In Proceedings of the XLVIII Latin American Computer Conference, CLEI 2022, Armenia, CO, USA, 17–21 October 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 1–11. [Google Scholar] [CrossRef]
- Kashir, B.; Ragone, M.; Ramasubramanian, A.; Yurkiv, V.; Mashayek, F. Application of fully convolutional neural networks for feature extraction in fluid flow. J. Vis. 2021, 24, 771–785. [Google Scholar] [CrossRef]
- Ezhilarasan, A.; Selvaraj, A.; Jebarani, W.S.L. MixNet: A Robust Mixture of Convolutional Neural Networks as Feature Extractors to Detect Stego Images Created by Content-Adaptive Steganography. Neural Process. Lett. 2022, 54, 853–870. [Google Scholar] [CrossRef]
- Uzkent, B.; Yeh, C.; Ermon, S. Efficient Object Detection in Large Images Using Deep Reinforcement Learning. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision, WACV 2020, Snowmass Village, CO, USA, 1–5 March 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1813–1822. [Google Scholar] [CrossRef]
- Tan, M.; Pang, R.; Le, Q.V. EfficientDet: Scalable and Efficient Object Detection. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2020, Seattle, WA, USA, 13–19 June 2020; Computer Vision Foundation/IEEE: Piscataway, NJ, USA, 2020; pp. 10778–10787. [Google Scholar] [CrossRef]
- Cui, Y.; Yang, L.; Liu, D. Dynamic Proposals for Efficient Object Detection. arXiv 2022, arXiv:2207.05252. [Google Scholar]
- Cai, Y.; Luan, T.; Gao, H.; Wang, H.; Chen, L.; Li, Y.; Sotelo, M.Á.; Li, Z. YOLOv4-5D: An Effective and Efficient Object Detector for Autonomous Driving. IEEE Trans. Instrum. Meas. 2021, 70, 1–13. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef] [Green Version]
- Uijlings, J.R.R.; van de Sande, K.E.A.; Gevers, T.; Smeulders, A.W.M. Selective Search for Object Recognition. Int. J. Comput. Vis. 2013, 104, 154–171. [Google Scholar] [CrossRef] [Green Version]
- Han, J.; Huang, C.; Sun, S.; Liu, Z.; Liu, J. bjXnet: An improved bug localization model based on code property graph and attention mechanism. Autom. Softw. Eng. 2023, 30, 12. [Google Scholar] [CrossRef]
- Duan, G.; Dong, Y.; Miao, J.; Huang, T. Position-Aware Attention Mechanism-Based Bi-graph for Dialogue Relation Extraction. Cogn. Comput. 2023, 15, 359–372. [Google Scholar] [CrossRef]
- Ma, H.; Yang, K.; Pun, M. Cellular traffic prediction via deep state space models with attention mechanism. Comput. Commun. 2023, 197, 276–283. [Google Scholar] [CrossRef]
- Chen, Z.; Li, J.; Liu, H.; Wang, X.; Wang, H.; Zheng, Q. Learning multi-scale features for speech emotion recognition with connection attention mechanism. Expert Syst. Appl. 2023, 214, 118943. [Google Scholar] [CrossRef]
- Wang, W.; Li, Q.; Xie, J.; Hu, N.; Wang, Z.; Zhang, N. Research on emotional semantic retrieval of attention mechanism oriented to audio-visual synesthesia. Neurocomputing 2023, 519, 194–204. [Google Scholar] [CrossRef]
- Ding, P.; Qian, H.; Zhou, Y.; Chu, S. Object detection method based on lightweight YOLOv4 and attention mechanism in security scenes. J. Real Time Image Process. 2023, 20, 34. [Google Scholar] [CrossRef]
- Liu, W.; Lu, H.; Wang, Y.; Li, Y.; Qu, Z.; Li, Y. MMRAN: A novel model for finger vein recognition based on a residual attention mechanism. Appl. Intell. 2023, 53, 3273–3290. [Google Scholar] [CrossRef]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2020, Seattle, WA, USA, 13–19 June 2020; Computer Vision Foundation/IEEE: Piscataway, NJ, USA, 2020; pp. 11531–11539. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.; Kweon, I.S. CBAM: Convolutional Block Attention Module. In Proceedings of the Computer Vision—ECCV 2018—15th European Conference, Munich, Germany, 8–14 September 2018; Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y., Eds.; Springer: Berlin/Heidelberg, Germany, 2018; Volume 11211, pp. 3–19. [Google Scholar] [CrossRef] [Green Version]
- Webb, B.S.; Dhruv, N.T.; Solomon, S.G.; Tailby, C.; Lennie, P. Early and late mechanisms of surround suppression in striate cortex of macaque. J. Neurosci. Off. J. Soc. Neurosci. 2006, 25, 11666–11675. [Google Scholar] [CrossRef] [Green Version]
- Luo, F.; Zou, Z.; Liu, J.; Lin, Z. Dimensionality Reduction and Classification of Hyperspectral Image via Multistructure Unified Discriminative Embedding. IEEE Trans. Geosci. Remote. Sens. 2022, 60, 1–16. [Google Scholar] [CrossRef]
- Liu, Z.; Mao, H.; Wu, C.Y.; Feichtenhofer, C.; Darrell, T.; Xie, S. A ConvNet for the 2020s. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Orleans, LA, USA, 18–24 June 2022; pp. 11966–11976. [Google Scholar] [CrossRef]
- Hariharan, B.; Malik, J.; Ramanan, D. Discriminative Decorrelation for Clustering and Classification. In Proceedings of the Computer Vision—ECCV 2012, Florence, Italy, 7–13 October 2012; Fitzgibbon, A., Lazebnik, S., Perona, P., Sato, Y., Schmid, C., Eds.; Springer: Berlin/Heidelberg, Germany, 2012; pp. 459–472. [Google Scholar]
- Kaggle. Available online: https://www.kaggle.com (accessed on 11 March 2023).
- Image Net. Available online: https://image-net.org (accessed on 11 March 2023).








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | mAP_0.5 | Precision | Recall | Parameters (M) | F1 |
|---|---|---|---|---|---|
| YOLOv5 | |||||
| YOLOv7 | |||||
| YOLOv7-Improved-1 | |||||
| YOLOv7-Improved-2 | |||||
| YOLOv7-Improved-3 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yan, G.; Guo, J.; Zhu, D.; Zhang, S.; Xing, R.; Xiao, Z.; Wang, Q. A Flame Detection Algorithm Based on Improved YOLOv7. Appl. Sci. 2023, 13, 9236. https://doi.org/10.3390/app13169236
Yan G, Guo J, Zhu D, Zhang S, Xing R, Xiao Z, Wang Q. A Flame Detection Algorithm Based on Improved YOLOv7. Applied Sciences. 2023; 13(16):9236. https://doi.org/10.3390/app13169236
Chicago/Turabian StyleYan, Guibao, Jialin Guo, Dongyi Zhu, Shuming Zhang, Rui Xing, Zhangshu Xiao, and Qichao Wang. 2023. "A Flame Detection Algorithm Based on Improved YOLOv7" Applied Sciences 13, no. 16: 9236. https://doi.org/10.3390/app13169236
APA StyleYan, G., Guo, J., Zhu, D., Zhang, S., Xing, R., Xiao, Z., & Wang, Q. (2023). A Flame Detection Algorithm Based on Improved YOLOv7. Applied Sciences, 13(16), 9236. https://doi.org/10.3390/app13169236