
Modeling Graph Neural Networks and Dynamic Role Sorting for Argument Extraction in Documents

Abstract
:1. Introduction
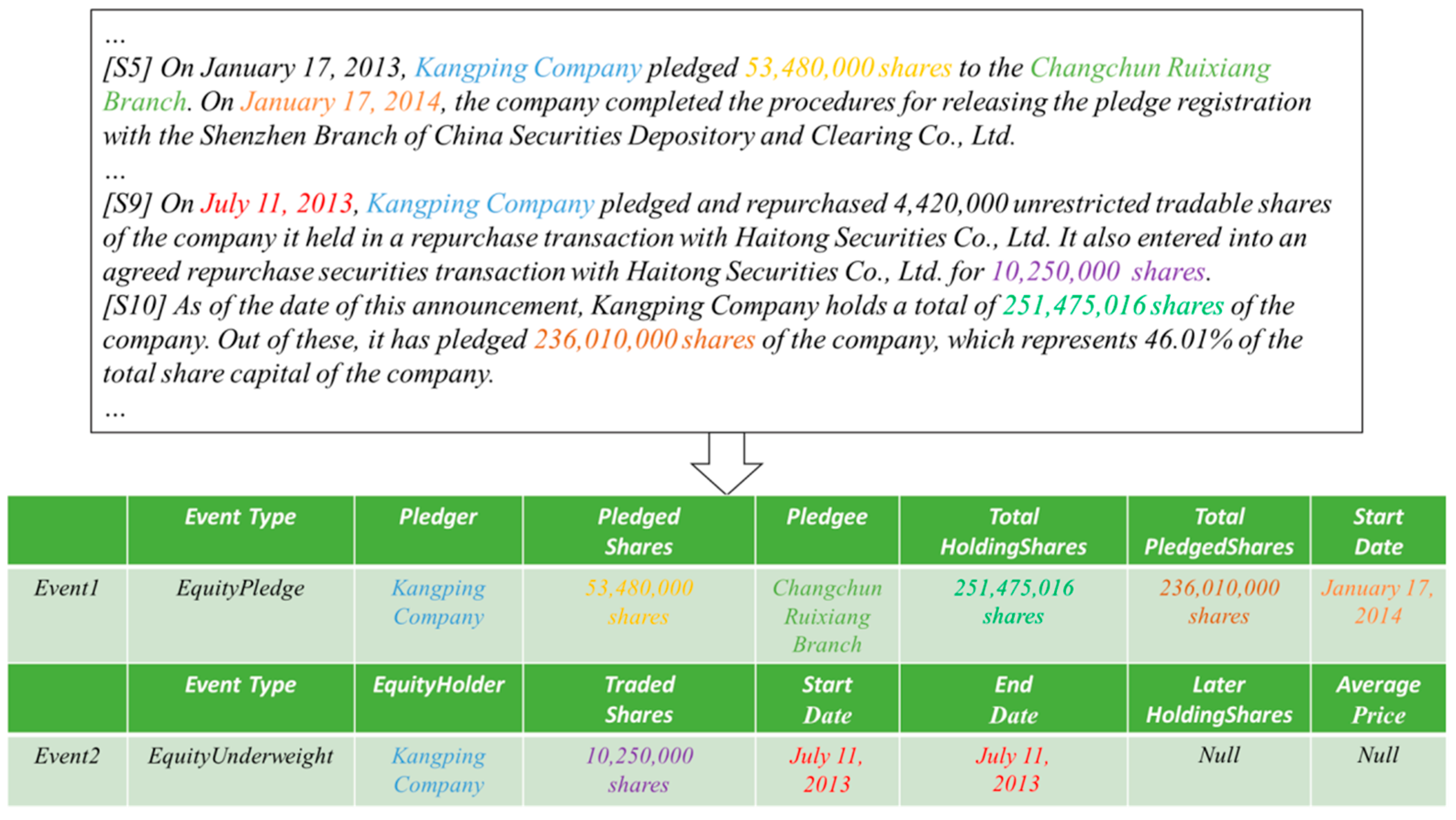
- We propose the GNNDRS model for addressing the two mentioned challenges. GNNDRS constructs a heterogeneous graph interaction network, which can better capture the connections among the different pieces of information within the document.
- The GNNDRS model dynamically adjusts the detection order of argument roles, prioritizing the roles with fewer arguments. This approach enhances the accuracy of extracting each event and its associated arguments.
- We experimentally validate the effectiveness of the GNNDRS model on the datasets, demonstrating its superior performance.
2. Related Work
2.1. Sentence-Level Event Extraction (SEE)
2.2. Document-Level Event Extraction (DEE)
3. Methodology
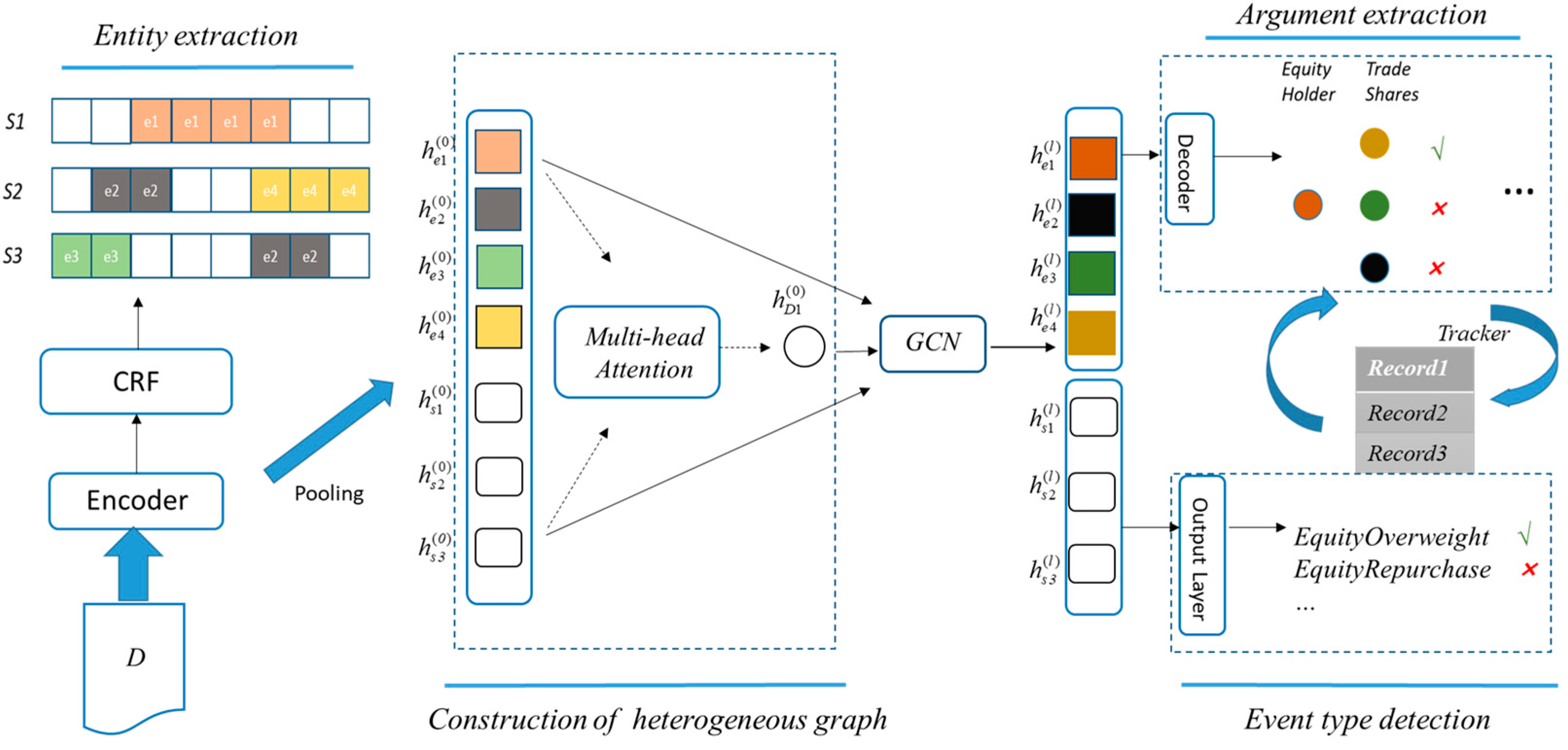
3.1. Model Architecture
3.2. Entity Extraction
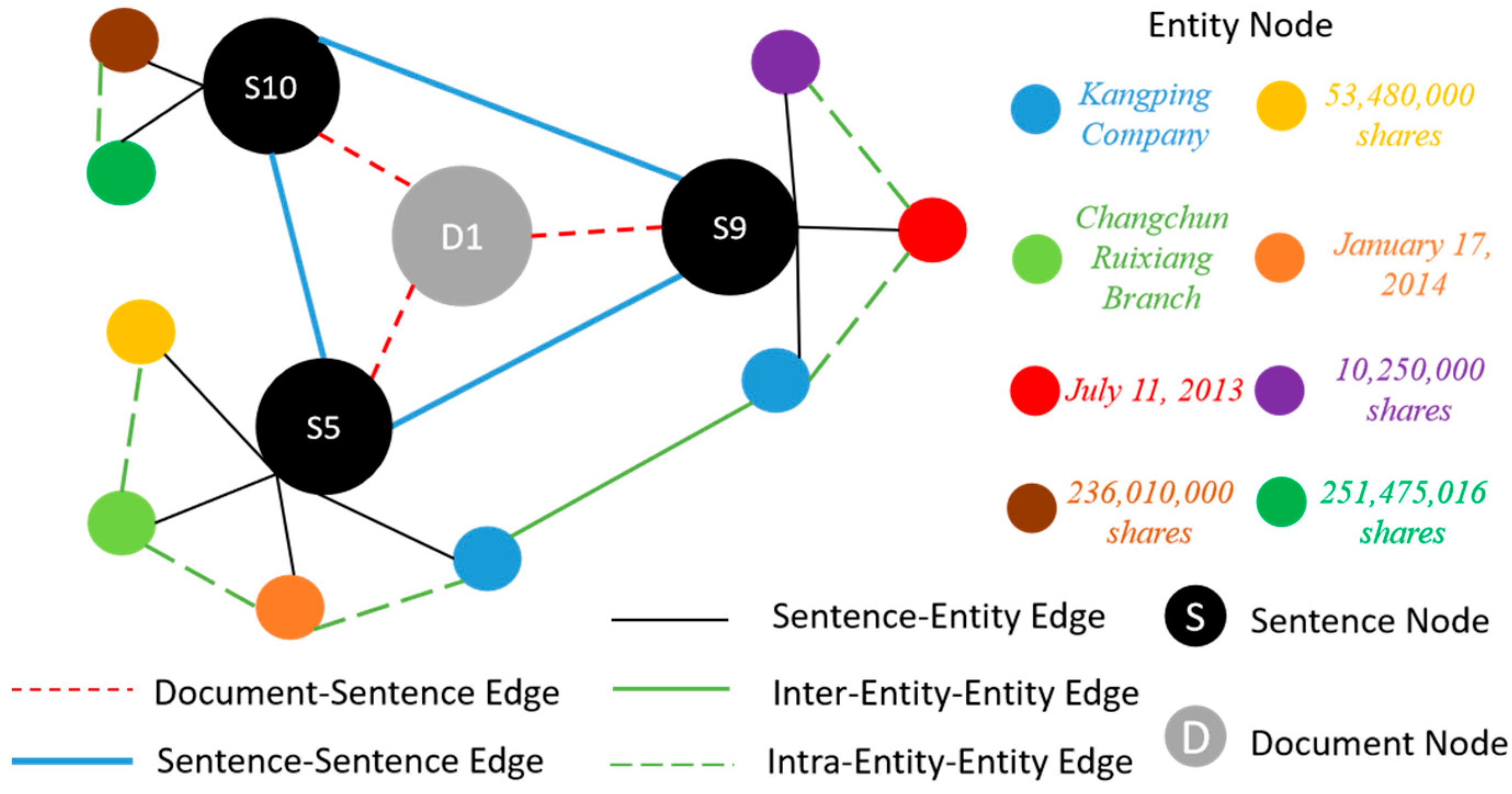
3.3. Construction of Heterogeneous Graph
3.4. Event Type Detection
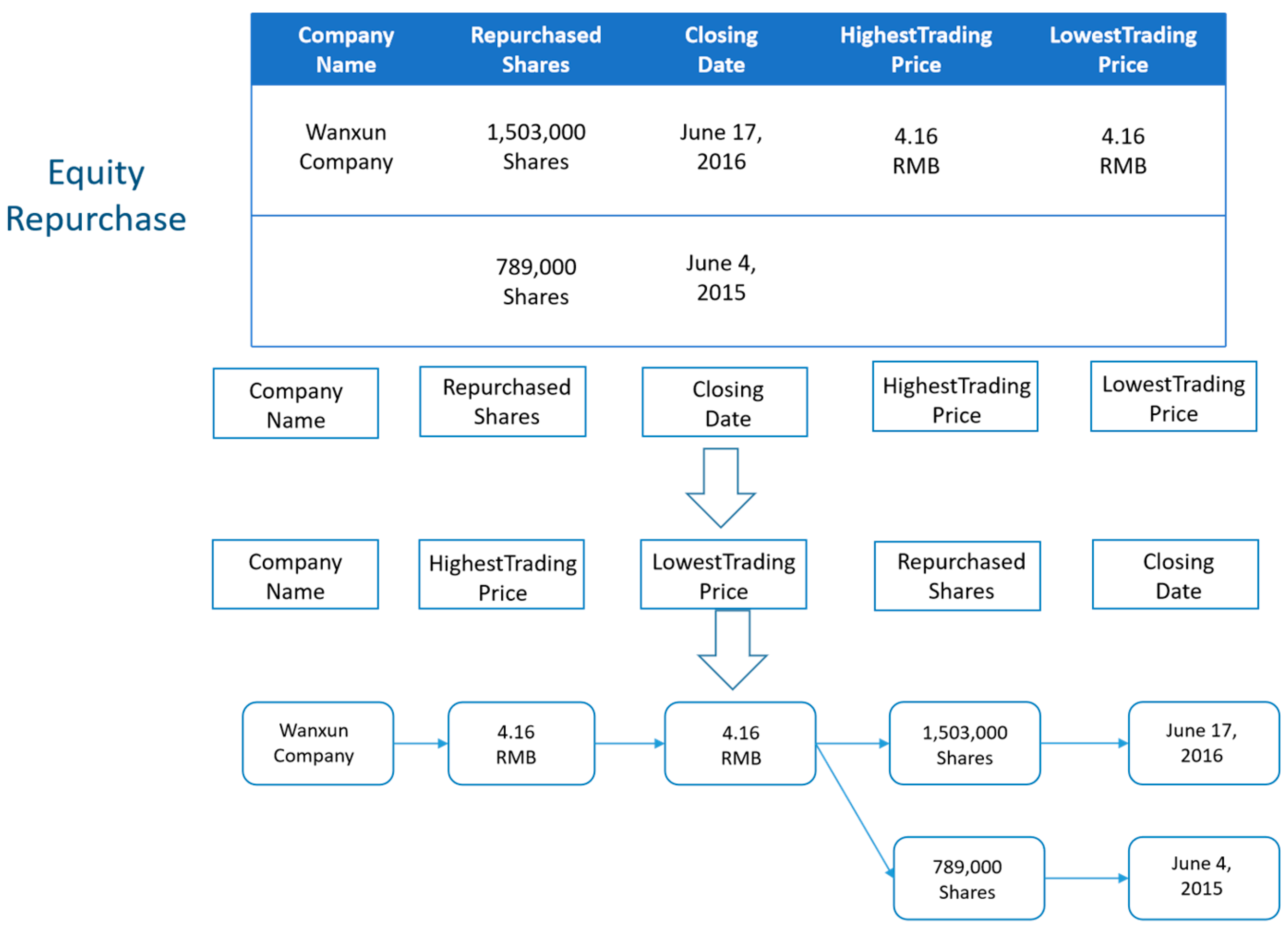
3.5. Argument Extraction
3.6. Training
4. Experiments
4.1. Datasets and Evaluation Metrics
4.2. Experiments Setting
4.3. Results and Analysis
4.4. Ablation Study
4.5. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Xiang, W.; Wang, B. A survey of event extraction from text. IEEE Access 2019, 7, 173111–173137. [Google Scholar] [CrossRef]
- Wang, S.; Cao, L.; Wang, Y.; Sheng, Q.Z.; Orgun, M.A.; Lian, D. A Survey on Session-based Recommender Systems. ACM Comput. Surv. (CSUR) 2021, 54, 1–38. [Google Scholar] [CrossRef]
- Xiong, R.; Wang, J.; Zhang, N.; Ma, Y. Deep hybrid collaborative filtering for web service recommendation. Expert Syst. Appl. 2018, 110, 191–205. [Google Scholar] [CrossRef]
- Zhou, Y.; Wang, W.; Yi, D.; Qiao, Z.; Xiao, M. A survey on the construction methods and applications of sci-tech big data knowledge graph. Sci. Sin. Inf. 2020, 50, 957. [Google Scholar] [CrossRef]
- Wang, X.; Zhang, X.; Liu, F. Knowledge graph construction and application in geosciences: A review. Comput. Geosci. 2022, 161, 105082. [Google Scholar]
- Qiu, B.; Chen, X.; Xu, J.; Sun, Y. A survey on neural machine reading comprehension. Neurocomputing 2019, 338, 28–41. [Google Scholar]
- Qi, L.; Heng, J.; Liang, H. Joint event extraction via structured prediction with global features. In Proceedings of the 51st Annual Meeting of the Association for Computational Linguistics, Sofia, Bulgaria, 4–5 August 2013. [Google Scholar]
- Jang, K.; Lee, K.; Jang, G.; Jung, S.; Myaeng, S. Food hazard event extraction based on news and social media: A preliminary work. In Proceedings of the 2016 International Conference on Big Data and Smart Computing (BigComp), Hong Kong, China, 18–20 January 2016. [Google Scholar] [CrossRef]
- Ihm, H.; Jang, H.; Lee, K.; Jang, G.; Seo, M.; Han, K.; Myaeng, S. Multi-source Food Hazard Event Extraction for Public Health. In Proceedings of the 2017 IEEE International Conference on Big Data and Smart Computing (BigComp), Jeju, Republic of Korea, 13–16 February 2017. [Google Scholar] [CrossRef]
- Wang, X.; Zhang, Q. Food Safety Event Detection Based on Multi-Feature Fusion. Symmetry 2019, 11, 1222. [Google Scholar] [CrossRef] [Green Version]
- Du, X.; Cardie, C. Event extraction by answering (almost) natural questions. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Online, 16–20 November 2020. [Google Scholar]
- Wang, X.; Wang, Z.; Han, X.; Liu, Z.; Li, J.; Li, P.; Sun, M.; Zhou, J.; Ren, X. HMEAE: Hierarchical modular e vent argument extraction. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019. [Google Scholar]
- Jin, Y.; Jiang, W.; Yang, Y.; Mu, Y. Zero-Shot Video Event Detection with High-Order Semantic Concept Discovery and Matching. IEEE Trans. Multimed. 2022, 24, 1896–1908. [Google Scholar] [CrossRef]
- Li, P.; Zhou, G. Joint Argument Inference in Chinese Event Extraction with Argument Consistency and Event Relevance. IEEE/ACM Trans. Audio Speech Lang. Process. 2016, 24, 612–622. [Google Scholar] [CrossRef]
- Kanetaki, Z.; Stergiou, C.; Bekas, G.; Troussas, C.; Sgouropoulou, C. Creating a Metamodel for Predicting Learners’ Satisfaction by Utilizing an Educational Information System During COVID-19 Pandemic. In Proceedings of the International Conference on Novelties in Intelligent Digital Systems, Athens, Greece, 30 September–1 October 2021; pp. 127–136. [Google Scholar] [CrossRef]
- Doddington, G.R.; Mitchell, A.; Przybocki, M.; Ramshaw, L.; Strassel, S.; Weischedel, R. The automatic content extraction (ACE) program-tasks, data, and evaluation. In Proceedings of the 4th International Conference on Language Resources and Evaluation (LREC), Lisbon, Portugal, 26–28 May 2004. [Google Scholar]
- Chen, Y.; Xu, L.; Liu, K.; Zeng, D.; Zhao, J. Event extraction via dynamic multi-pooling convolutional neural networks. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing (ACL-IJCNLP), Beijing, China, 26–31 July 2015. [Google Scholar]
- Liu, X.; Luo, Z.; Huang, H. Jointly Multiple Events Extraction via Attention-based Graph Information Aggregation. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 30 October–1 November 2018. [Google Scholar]
- Zhang, T.; Ji, H. Event extraction with generative adversarial imitation learning. Data Intell. 2018, 1, 99–120. [Google Scholar] [CrossRef]
- Nguyen, T.; Cho, K.; Grishman, R. Joint Event Extraction via Recurrent Neural Networks. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, San Diego, CA, USA, 12–17 June 2016. [Google Scholar]
- Sha, L.; Qian, F.; Chang, B.; Sui, Z. Jointly Extracting Event Triggers and Arguments by Dependency-bridge RNN and Tensor-based Argument Interaction. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Yang, S.; Feng, D.; Qiao, L.; Kan, Z.; Li, D. Exploring Pre-trained Language Models for Event Extraction and Generation. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019. [Google Scholar]
- Yang, H.; Chen, Y.; Liu, K.; Xiao, Y.; Zhao, J. DCFEE: A Document-level Chinese Financial Event Extraction System based on Automatically Labeled Training Data. Proceedings of ACL 2018, System Demonstrations, Melbourne, Australia, 15–20 July 2018. [Google Scholar]
- Yang, B.; Mitchell, T. Joint Extraction of Events and Entities within a Document Context. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, San Diego, CA, USA, 12–17 June 2016. [Google Scholar]
- Chen, Y.; Chen, T.; Van Durme, B. Joint Modeling of Arguments for Event Understanding. In Proceedings of the First Workshop on Computational Approaches to Discourse of the Association for Computational Linguistics, Online, 10–11 November 2021; pp. 96–101. [Google Scholar]
- Ebner, S.; Xia, P.; Culkin, R.; Rawlins, K.; Van Durme, B. Multi-sentence argument linking. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020. [Google Scholar]
- Li, H.; Zhao, X.; Yu, L.; Zhao, Y.; Zhang, J. DEEDP: Document-Level Event Extraction Model Incorporating Dependency Paths. Appl. Sci. 2023, 13, 2846. [Google Scholar] [CrossRef]
- Li, S.; Ji, H.; Han, J. Document-level event argument extraction by conditional generation. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Online, 6–11 June 2021; pp. 894–908. [Google Scholar]
- Zhang, Z.; Kong, X.; Liu, Z.; Ma, X.; Eduard, H. A two-step approach for implicit event argument detection. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 6–8 July 2020; pp. 7479–7485. [Google Scholar]
- Zheng, S.; Cao, W.; Xu, W.; Bian, J. Doc2EDAG: An End-to-End Document-Level Framework for Chinese Financial Event Extraction. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019. [Google Scholar]
- Yang, H.; Sui, D.; Chen, Y.; Liu, K.; Zhao, J.; Wang, T. Document-Level Event Extraction via Parallel Prediction Networks. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing, Online, 1–6 August 2021. [Google Scholar]
- Xu, R.; Liu, T.; Li, L.; Chang, B. Document-level event extraction via heterogeneous graph-based interaction model with a tracker. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing, Online, 1–6 August 2021. [Google Scholar]
- Yang, H.; Chen, Y.; Liu, K.; Zhao, J.; Zhao, Z.; Sun, W. Multi-Turn and Multi-Granularity Reader for Document-Level Event Extraction. ACM Trans. Asian Low-Resour. Lang. Inf. Process. 2022, 22, 1–16. [Google Scholar] [CrossRef]
- Liang, Y.; Jiang, Z.; Yin, D.; Ren, B. RAAT: Relation-Augmented Attention Transformer for Relation Modeling in Document-Level Event Extraction. In Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Seattle, WA, USA, 10–15 July 2022; pp. 4985–4997. [Google Scholar]
- Lafferty, J.; McCallum, A.; Fernando, C. Conditional random fields: Probabilistic models for segmenting and labeling sequence data. In Proceedings of the Eighteenth International Conference on Machine Learning, Williamstown, MA, USA, 28 June–1 July 2001. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.; Lee, K.; Toutanova, K. BERT: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, MN, USA, 2–7 June 2019. [Google Scholar]
- Collobert, R.; Weston, J. A unified architecture for natural language processing: Deep neural networks with multitask learning. In Proceedings of the 25th International Conference on Machine Learning, Helsinki, Finland, 5–9 June 2008. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
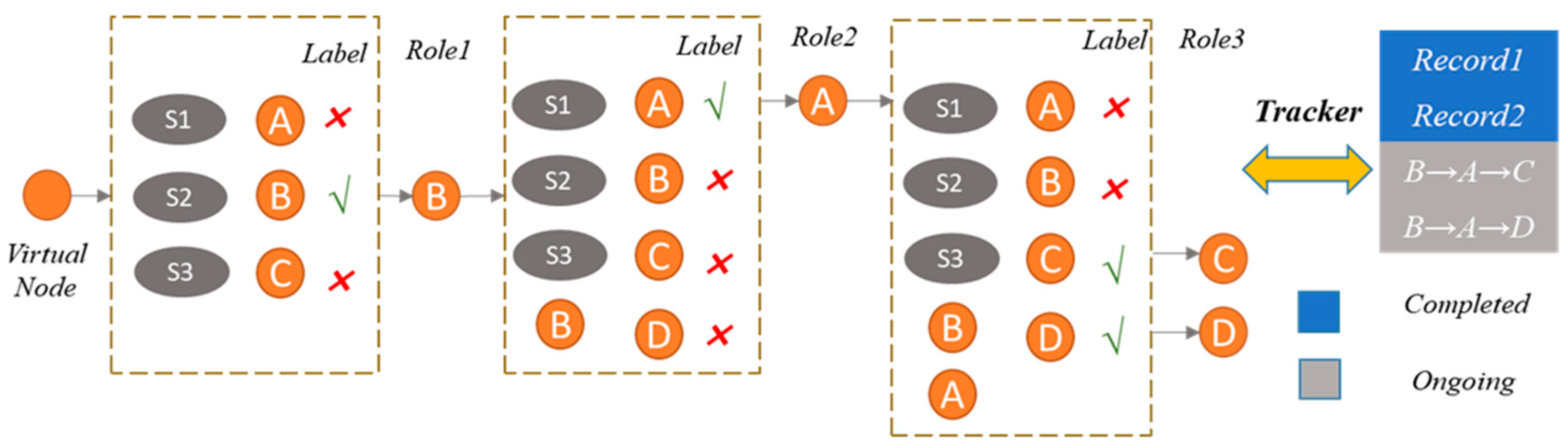{kind=link}
| Model | P (%) | R (%) | F1 (%) |
|---|---|---|---|
| DEPPN [31] | 70.9 | 57.5 | 63.5 |
| GIT [32] | 71.3 | 86.3 | 78.1 |
| RAAT [34] | 70.7 | 64.5 | 67.4 |
| GNNDRS (ours) | 88.2 | 82.2 | 85.1 |
| Model | EF | ER | EU | EO | EP | Average | Total | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| P (%) | R (%) | F1 (%) | P (%) | R (%) | F1 (%) | P (%) | R (%) | F1 (%) | P (%) | R (%) | F1 (%) | P (%) | R (%) | F1 (%) | P (%) | R (%) | F1 (%) | P (%) | R (%) | F1 (%) | |
| DEPPN [31] | 61.7 | 38.4 | 47.3 | 72.1 | 57.3 | 63.9 | 54.0 | 47.8 | 50.7 | 40.3 | 49.5 | 44.4 | 65.3 | 44.0 | 52.5 | 58.7 | 47.4 | 51.8 | 62.9 | 47.5 | 54.1 |
| GIT [32] | 69.2 | 33.2 | 44.9 | 69.1 | 61.3 | 65.0 | 61.4 | 52.8 | 56.7 | 70.0 | 55.5 | 62.0 | 68.2 | 59.0 | 63.3 | 67.6 | 52.4 | 58.4 | 68.2 | 57.4 | 62.3 |
| RAAT [34] | 70.0 | 36.3 | 47.8 | 55.0 | 50.1 | 52.4 | 57.7 | 43.4 | 49.6 | 51.5 | 49.7 | 50.6 | 62.3 | 57.7 | 59.9 | 59.3 | 47.5 | 52.1 | 59.7 | 53.2 | 56.3 |
| GNNDRS | 77.9 | 37.2 | 50.4 | 77.9 | 65.6 | 71.2 | 63.7 | 49.7 | 55.8 | 63.4 | 57.5 | 60.3 | 73.5 | 56.3 | 63.8 | 71.3 | 53.3 | 60.3 | 73.3 | 57.1 | 64.2 |
| Model | S. (%) | M. (%) |
|---|---|---|
| DEPPN [31] | 64.1 | 58.2 |
| GIT [32] | 80.2 | 61.1 |
| RAAT [34] | 69.2 | 54.5 |
| GNNDRS (ours) | 87.7 | 60.1 |
| Model | EF | ER | EU | EO | EP | Average | Total | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| S. (%) | M. (%) | S.%) | M. (%) | S. (%) | M. (%) | S. (%) | M. (%) | S. (%) | M. (%) | S.%) | M. (%) | S. (%) | M. (%) | |
| DEPPN [31] | 56.9 | 37.7 | 65.3 | 51.6 | 55.4 | 43.6 | 46.0 | 41.4 | 60.2 | 47.4 | 56.8 | 44.3 | 60.1 | 46.3 |
| GIT [32] | 59.6 | 45.7 | 70.0 | 58.4 | 61.1 | 46.2 | 66.1 | 54.0 | 76.8 | 54.2 | 66.7 | 51.7 | 71.2 | 53.4 |
| RAAT [34] | 56.7 | 39.3 | 53.3 | 46.5 | 54.4 | 42.8 | 55.2 | 44.0 | 67.7 | 55.2 | 57.5 | 45.5 | 59.6 | 52.4 |
| GNNDRS | 62.2 | 47.4 | 66.1 | 53.2 | 63.9 | 42.0 | 66.9 | 48.6 | 77.4 | 56.0 | 67.3 | 49.4 | 70.6 | 54.0 |
| Model | P (%) | R (%) | F1 (%) |
|---|---|---|---|
| GNNDRS | 88.2 | 82.2 | 85.1 |
| w/o doc-s | 72.7 | 83.6 | 77.8 |
| w/o sorting | 86.9 | 82.7 | 84.8 |
| Model | P (%) | R (%) | F1 (%) |
|---|---|---|---|
| GNNDRS | 73.3 | 57.1 | 64.2 |
| w/o doc-s | 70.5 | 57.3 | 63.3 |
| w/o sorting | 71.7 | 56.8 | 63.4 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, Q.; Chen, H.; Cai, Y.; Dong, W.; Liu, P. Modeling Graph Neural Networks and Dynamic Role Sorting for Argument Extraction in Documents. Appl. Sci. 2023, 13, 9257. https://doi.org/10.3390/app13169257
Zhang Q, Chen H, Cai Y, Dong W, Liu P. Modeling Graph Neural Networks and Dynamic Role Sorting for Argument Extraction in Documents. Applied Sciences. 2023; 13(16):9257. https://doi.org/10.3390/app13169257
Chicago/Turabian StyleZhang, Qingchuan, Hongxi Chen, Yuanyuan Cai, Wei Dong, and Peng Liu. 2023. "Modeling Graph Neural Networks and Dynamic Role Sorting for Argument Extraction in Documents" Applied Sciences 13, no. 16: 9257. https://doi.org/10.3390/app13169257
APA StyleZhang, Q., Chen, H., Cai, Y., Dong, W., & Liu, P. (2023). Modeling Graph Neural Networks and Dynamic Role Sorting for Argument Extraction in Documents. Applied Sciences, 13(16), 9257. https://doi.org/10.3390/app13169257