1. Introduction
Smart cities are developing rapidly, as they ease human lifestyles by overcoming the challenges faced by rapidly growing cities. Thus, they are considered the future of urban development. Smart cities offer several benefits, including safe transportation, a green environment, and efficient healthcare [
1,
2,
3]. Furthermore, smart cities empower citizen engagement, with sustainable development and increased economic growth. The use of technological advancements such as the Internet of things (IoTs) further augments smart-city applications.
Most smart city applications comprise IoT devices that are ubiquitously connected. These IoT devices produce a large amount of data that are forwarded and stored in remotely located cloud servers [
4,
5]. Storing and retrieving this data from a remote cloud server is time-consuming and not suitable for time-constrained applications. To meet these limitations, fog computing is emerging rapidly, by placing a single or group of computing nodes at the edge of the network, avoiding the Internet backbone [
6,
7,
8,
9]. Transferring IoT node data to these fog computing nodes on the same network is quick compared to transferring data to a multi-hop remote server. That is why fog computing nodes are preferred over the cloud in delay-sensitive applications and for emergency services such as in health care [
10,
11].
In smart cities and health care systems, the patient’s vital sign data need to be sent to medical consultants for online monitoring, as well as being necessary for online treatment. Unreliable and error-prone transfer of vital sign data may cause loss of human life. Due to wireless data communication, the chances of errors in data increase. This requires a foolproof and secure data transfer mechanism, such as blockchain technology.
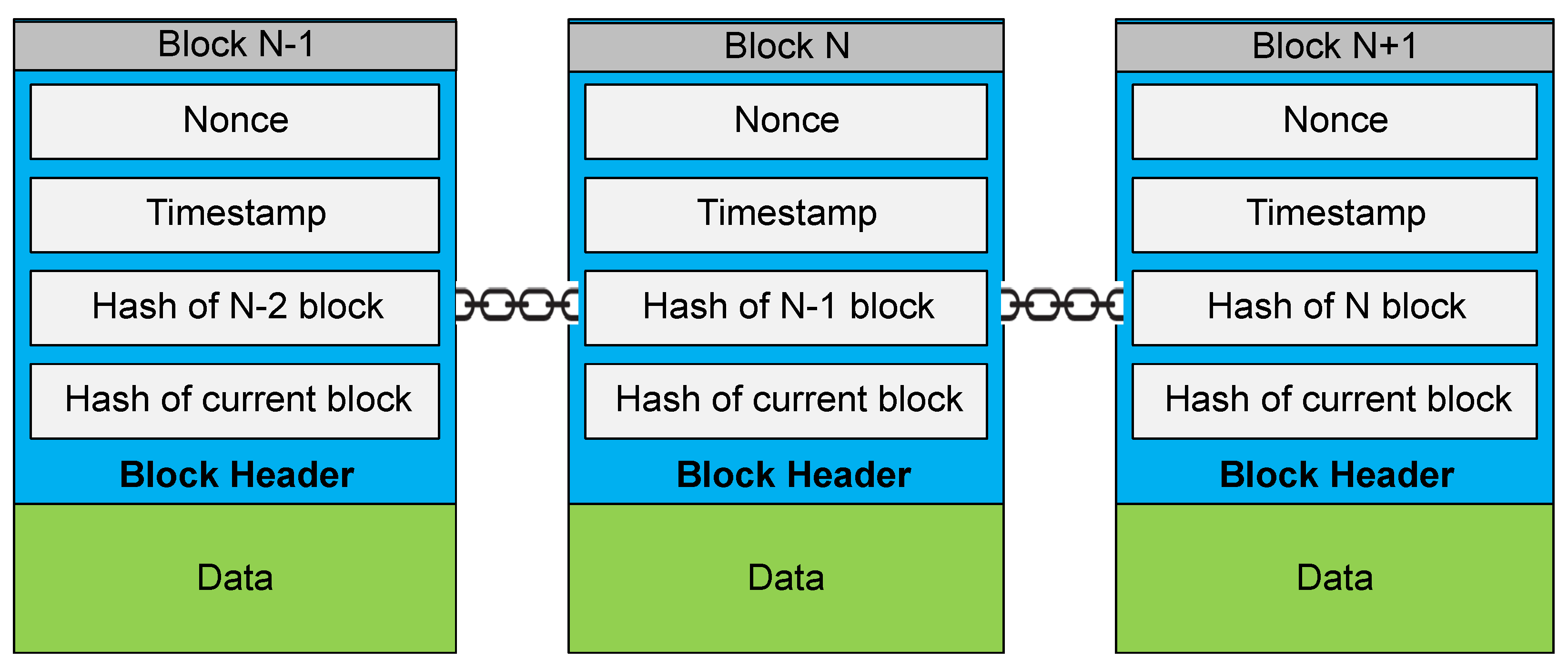
Blockchain technology is developing rapidly and has been used in many applications over the last decade [
12,
13,
14]. It consists of a large number of decentralized and immutable data blocks that are cryptographically secured. Each block is assigned a unique identification number and contains time-stamped data. All blocks are connected and contain the encrypted hash values of the previous and next data blocks [
15,
16]. In this way, all blocks are linked together and any change in one of the data blocks is communicated to the whole system and can easily be retrieved, as presented in
Figure 1.
Blockchain technology has immutability features that avoid alteration of data, and the time-stamped data of each block are kept permanently [
17,
18]. In addition, it supports secure and swift data storage. A secure hash algorithm (SHA-256) is used to calculate the hash function and achieve the required cryptography. Miners placed in different locations compute a nonce (number only used once) to determine an encrypted hash value that must be within a specific range. Blockchain technology is used in various health care applications, such as in medical equipment procurement and health monitoring [
19,
20,
21].
Blockchain technology comprises multiple mining nodes to authenticate a valid block [
22,
23]. A data block is validated once the mining node computes a valid SHA-256-based hash value. A mining node uses different nonce values to compute that a certain 256-bit has a value that is within the specified range. In smart cities, fog computing nodes can be placed at different locations to act as mining nodes, as shown in
Figure 2. This facilitates quick delivery of patients’ data due to their proximity, instead of mining the data block from remotely placed mining servers. At the same time, computing a specific hash value using a different nonce is a time-consuming process and may result in unnecessary delays, which could cause a serious threat to life for patients. The motivation for this work was to improve the nonce computing time through efficient allocation of computing resources to mining nodes.
It should be noted that, once the nonce is computed to generate the desired hash function in the blockchain, a block is created and broadcast to the network. Other nodes in the network can verify the generated hash function. A consensus algorithm can be developed, so that nodes agree on the validity of the created block and its addition to the blockchain. Thus, the consensus part comes after the nonce computation of a valid hash function. However, the consensus part is not the focus of this paper.
This work proposes a mechanism to efficiently distribute the nonce computing load from the patient’s sensors to the mining nodes. The proposed technique comprises two algorithms. The first algorithm works in cases in which the nonce computing load is less than the caching capacity of the mining nodes. In this case, a load-balancing mechanism is used to balance the load among all mining nodes. The second algorithm is used when the nonce computing load is higher than the caching capacity of the fog nodes used for mining. Knapsack-based allocation for computing the nonce at the mining nodes is proposed for this scenario. The main ambition of the proposed scheme is to reduce the nonce computing time, as well as to give preference to the computation of nonces for the most sensitive data blocks.
The contributions of the proposed technique are described as follows:
The proposed technique effectively balances the computing load (for nonce evaluation) at the mining nodes, while considering the caching capacity of the mining nodes and the priority of the patient’s health data;
The proposed technique accommodates high-priority patient data in computing their nonce value by considering the origin time;
The proposed technique provides a mechanism to optimally allocate the caching space of the mining nodes among the nonce computing requests.
2. Related Work
Blockchain technology, due to its wide acceptability in diverse applications, is an intensive research area. In [
24], the authors proposed a consortium blockchain to share data securely in a scalable network. In that work, the authors used a digital signature-based smart contract technique for data security. The results highlighted that the proposed solution resulted in an increase of 83.33% with a sixfold reduction in data blocks.
An area-based message transfer solution suited for blockchain-enabled vehicular networks was proposed in [
25,
26]. In [
25], the authors proposed using a blockchain to increase trustworthiness and for secure delivery of vehicle data to neighboring vehicles. The work divided the area into regions and used the regional blockchain concept. The authors in [
26] addressed trust management in transferring data among vehicles in vehicular ad hoc networks by discarding low-value messages from the network after considering a threshold value. The authors proposed blockchains for revocation, trust, and certificatation, and message blockchains under government-administered blockchains. The authors claimed an efficient message transmission, having a low delay time in the presence or absence of malicious attacks.
Regarding smart health care, an identity-based authentication system was proposed in [
27]. This is useful for the registration process in hospitals and has the benefits of being distributed and secure. The authors used blockchain technology for the secure and speedy transfer of data to the referred medical center. In [
28], the authors addressed security concerns about patients’ information using blockchain technology and smart contracts. In their work, intelligent records of patient health, with immutable and authentic accessibility and a secure and prompt payment method, were proposed.
In [
29,
30], blockchain-based solutions were proposed by addressing different problems faced in patient-centric healthcare systems. In [
29], the data privacy of patients was addressed, and the proposed blockchain-based uncheckable and secured distributed ledger technology was used to maintain the privacy of patients’ data. In [
30], the work was related to the internet challenges of cloud computing and blockchain technologies in healthcare systems and presented a one-to-one care structure system with real-time remote healthcare.
The importance of healthcare increases with age. An IoT and blockchain-based healthcare system was proposed to address aging population problems [
31]. In that research, the authors emphasized the increasing cost of the care of elderly patients. The authors presented a solution for smart-health management of older patients. In [
32], the authors highlighted the problems faced in IoT-based healthcare, related to security and functional parameters. The authors addressed these problems by proposing a systematic identity and access management (IAM) system that was based on blockchain technology.
Most research has proposed blockchain technology in the healthcare system, to address the security and confidentiality of patients’ data from different perspectives. The nonce computing in blockchain technologies is an essential part and takes a long time, which may not be feasible for transferring the health care data of critical condition patients. This work presents a priority-based nonce computing load technique for allocation to the fog nodes that significantly benefits critical patients’ data.
3. System Model
In this work, we consider the new data blocks that are required to become part of a consortium blockchain by attaining their nonce value. The health care information of patients has to be processed in a secure way by the central health care center. The patient healthcare data have different severity levels and have been divided into three different severity levels. To become part of the blockchain system, each data block requires a nonce value. Mining nodes are sparsely placed in different locations, and it is not possible to place computing machines such as mining machines in locations near to these healthcare patients. To obtain these healthcare data, load balancing machines (LBMs) are used to carry data and forward these data blocks to their nearby mining nodes, in such a way that no mining node is under- or overutilized.
The system model comprises
N number of health care data blocks that are generated continuously from the patients for which a nonce needs to be computed. These data blocks are categorized into 3 different levels of severity, such as highly sensitive
, medium sensitivity
, and low sensitivity
data blocks. The healthcare system is segregated into
C clustering regions and each cluster comprises
D load-balancing nodes within communication range of these patients’ data. Each
load balancing machine (LBM) in a cluster is backwardly connected to the
M mining machines, in such a way that they are a single hop location from the LBMs. The data forwarded from the LBMs in each cluster
are cached in the
M mining machine, before processing to find the nonce value. Each
mining node has limited caching capacity and can store
Y number of fixed-size data blocks. The mining node picks one data block from its cache and computes the nonce value to determine the valid hash value. Each
LBM in a cluster has live information on the caching capacities of all its associated mining machines. The total number of blocks of data that can be cached on all mining machines in a cluster
is computed as
The total caching capacity of data blocks
in
C clusters are computed as:
It is assumed that the data block transmission from the patients’ sensors to the LBMs can be carried out concurrently, without any queuing. A system model of a complete network cluster for blockchain-based healthcare systems is shown in
Figure 2.
4. Proposed Technique
In this work, an efficient resource allocation mechanism for transferring data blocks to mining machines to compute their nonce within a health care system is proposed. comprises two algorithms that assist LBMs in smartly distributing the received data blocks to multiple backwardly connected mining machines with a uniform distribution, when the received data block requests are within the caching capacity of the mining machines. The second algorithm efficiently scrutinizes the requested data blocks when the requested data blocks exceed the caching capacity of the mining machines.
In the proposed healthcare system for smart cities, multiple fog mining machines are placed in different areas to compute valid hash values for a patient’s health data block. It is obvious that some of these mining machines will be under a heavy load and some will have a lesser or zero computing load. For a uniform and fair distribution of data blocks to all fog mining machines, a smart load balancing mechanism is required. Furthermore, there is another probability, where the number of nonce computing requests at any time instant is greater than the caching limits of the mining machines, and all the requested data blocks can not be allocated to the associated mining machines. It is therefore required to scrutinize the data block requests to be cached on these mining machines.In this work, LBMs collect patients’ data and forward these data to fog mining machines placed in the cluster. This algorithm is designed for LBMs. The algorithm not only ensures the load balancing of fog mining machines within a cluster but also allocates data blocks by considering the sensitivity of patients’ data.
The main characteristics of this proposed algorithm are mentioned below:
4.1. Priority Calculation of Data Blocks
Suppose there is
n number of patient data blocks with different severity levels. These data blocks are received by a nearby LBM that is backwardly connected with
m mining nodes. The LBM knows the capacity of the mining machines connected to it. The LBM, after receiving these data blocks, computes their values by considering their origin time and the sensitivity of the data. If the sensitivity level of
ith node is
, and its originating time is
, then its value
is computed as
Suppose the LBM receives five data block requests, such as
A,
B,
C,
D, and
E, to compute nonces at time intervals of 13, 16, 21, 26, and 31. Each of these data have a priority that refers to the sensitivity of the patient data. The priorities are divided into three categories: the first is high (H), the second is medium (M), and the third is low (L). The priorities of 200, 50, and 20 are assigned to these H, M, and L level data blocks, respectively. The priority values corresponding to each data block can be given as in
Table 1.
4.2. Allocation of Data Blocks to Mining Machines
The allocation of data blocks at any time instant to the mining machines is based on the following two criteria:
If the number of received data blocks is less than the cache limit of the mining machines, then all data blocks are forwarded to these mining machines, in such a way that the most valuable data block is forwarded to a mining machine by applying a modified greedy algorithm;
If the data capacity of the received data blocks is more than the available caching limit of the mining machines, then the number of received data blocks is scrutinized by applying the 0/1 knapsack algorithm.
4.2.1. Algorithm for Load Balancing
In this section, an algorithm for the LBM is proposed for when the total size of the data blocks received by the LBM is less than the available caching capacity of all the associated mining machines.
Suppose there are M nodes used for the mining of blockchain data. The cache limit of each fog node is . There are N blocks of data, and the size of each block B is different from. To find out the optimal allocation of the blocks of data to the fog mining machines, we calculate the maximum load that has been assigned to a mining machine among all machines.The optimal value for the block distribution is computed in the following two ways:
Calculate the mean value by dividing the total size of the data blocks by the total number of mining machines. The optimum value
in this case can be given as
There is the possibility that there is one data block whose size is larger than the other data blocks. In this case, a larger block size is allocated to one machine, and the smaller blocks are placed on other fog nodes. In this case, the optimum load assignment
will be at least the size of the largest data block and is calculated as
Based on the two scenarios described above, the optimum allocation of data block size
is formulated as:
The objective of any load balancing technique is to allocate data blocks to minimize the
of the assigned mining machines. Suppose there are
X mining nodes in the coverage area of a load balancer with different numbers of blocks of data pending in their cache list. The load balancer allocates the most valuable data blocks to the mining nodes by following the below-mentioned criteria.
Here,
is the total cache capacity of node i
is the currently available cache limit of node i
is the time elapsed in computing the under-process nonce by node i
is the expected time for computing the nonce by node i
To achieve this goal, the well-known greedy algorithm is modified by incorporating the longest job first (LJF) algorithm, so that the load allocation to the mining nodes can be made efficient.
The salient features of the modified greedy algorithms are
All the received data blocks are sorted in descending order, as per the size of the data;
Allocate these data blocks to mining machines with the most caching space available.
The complete algorithm of our proposed load balancing scheme for the LBM is shown in Algorithm 1.
| Algorithm 1: Load balancing algorithm |
![Applsci 13 09625 i001]() |
4.2.2. Knapsack Optimization Algorithm
The knapsack algorithm (0/1 type) can be used to fill a sack with items that are of the highest value, such that the total capacity of the sack is exceeded. In this work, the scrutinized problem was formulated as a knapsack problem, as we needed to allocate the most valuable data blocks to the mining machines, within their caching capacity. The mapping of our problem as a 0/1 knapsack problem is shown in
Table 2 and its algorithm is given in Algorithm 2.
| Algorithm 2: Knapsack-based selection of data blocks for computing |
![Applsci 13 09625 i002]() |
The LBM has the information for caching the blocks of the mining machines and fills the cache of each mining machine by applying the 0/1 knapsack algorithm in such a way that a node with the minimum cache is filled up to a certain capacity. The LBM scrutinizes the data blocks before distributing them to the mining machines when the number of data blocks is greater than the caching capacity of the mining machines. It is assumed that the LBM already knows the number of blocks of data placed in the fog mining nodes’ cache on a runtime basis.
Suppose that there are three mining machines in a cluster, such as
,
, and
, with the current caching capacity to store data blocks at any time instant
T, being
,
, and
, respectively. If the available caching capacity of
,
, and
varies from the highest to the lowest, respectively, then the 0/1 knapsack allows the LBM to allocate those data blocks to mining machine
, which has the maximum value. The caching capacity of the mining node
must be greater than the difference between the most available cache capacities, i.e.,
and
, and less than the difference between the two extreme cache capacities of the mining machines, i.e.,
and
, as follows:
The 0/1 knapsack allocates data blocks to the mining machines by considering two constraints:
Fill the mining cache with data blocks, provided their sizes do not exceed the cache limit of the mining machine. If there are
N nodes selected with varying block sizes
B, such that
The value of all the selected data blocks must be maximum.
The knapsack problem is resolved using a knapsack table. Suppose there are five nonce-requesting data blocks A, B, C, D, and E, with block sizes of 1, 2, 4, 4, and 5 MB, respectively, and is 7 MB. The values calculated against each of these A, B, C, D, and E blocks is 200, 300, 100, 400, and 300, respectively. This means 16 MB are required to cache these data blocks to a mining machine and only 7 MBs are available. As the requested data block sizes are more than the available caching limit, the data blocks need to be scrutinized with optimal values.
The knapsack table filled utilizing the above-mentioned example is shown in
Table 3.
The table shows that the knapsack algorithm optimally selects data blocks A, B, and D in this example, with the maximum value calculated as 1600.
5. Results and Analysis
We implemented the proposed
technique in MATLAB and evaluated its performance. The patient data were divided into three types as per their sensitivity. These data blocks were assumed to be of the same size and generated at different time intervals. The initiated data blocks were time-stamped and increased every second.The LBM manages the allocation of data to the fog mining nodes. The number of fog mining nodes and the capacity of their cache is variable. Similarly, the frequency of the data blocks that are sent to the fog mining nodes is also variable. The parameters used in the simulation are presented in
Table 4.
The proposed
for the LBM allocates the received nonce requested blocks of data to the associated mining nodes. The performance of
was evaluated with the state-of-the-art Delay Sensitive Patients’ Data for Smart Cities Healthcare System (
) technique [
33] and the well-known round-robin algorithm. The performance analysis considered a wide variety of scenarios with different frequencies and sizes of data, as well as different numbers of mining nodes. The caching capacity of all the mining machines was considered to be the same and each mining node was assumed to cache three data blocks in its memory pool before computing its hashing values.
Figure 3 and
Figure 4 show the data successfully assigned to the fog nodes for the different data block requests received and fog mining nodes. For comparison, the performance of the
and round-robin algorithms is also presented.
The results shown in
Figure 3 were obtained at different intervals when the number of data block requests received by the LBM had an incremental trend of 5 requests from 0 to 30 requests. The LBM had to forward these block requests to only one mining machine. The results show that the LBM allocated more data blocks to mining machines compared to the other two schemes when the number of data block requests was more than 20 and it did not allocate data blocks at any stage from its competitors.
The same trend was observed when the number of fog mining nodes was variable, as shown in
Figure 4. The results were observed for varying sizes of 30 data blocks. The results showed that the proposed
always allocated a greater number of blocks of data in comparison to the other techniques. As the number of fog mining nodes was increased to 6, all three schemes allowed the LBM to allocate all data blocks, because the caching capacity increased due to the increased number of mining nodes. This was because the LBM in the proposed scheme allocated data blocks by applying the 0/1 knapsack algorithm and through an optimal assignment of data to the fog mining nodes.
To observe the data block allocation according to the sensitivity levels, results were generated for different numbers of data requests and different numbers of fog mining nodes. Each result comprised three subplots and were categorized as high-priority, medium-priority, and low-priority patient data blocks, as shown in
Figure 5,
Figure 6,
Figure 7 and
Figure 8. The data blocks were equally divided into three different categories with varying sizes.
The results shown in
Figure 5 and
Figure 6 were obtained for the allocation of data blocks of different priority levels when the LBM had a fixed number of data blocks, and it had to allocate these data blocks to different numbers of fog mining nodes. The allocated data blocks with the different numbers of fog mining nodes were expressed in numbers, as well as in percentages, as shown in
Figure 5 and
Figure 6, respectively. There were 30 data blocks of varying sizes that were equally distributed in the three categories. The allocated data blocks with a varying number of mining nodes are shown in the three subplots. The graphs shown in
Figure 5 highlight that the proposed technique allocated seven blocks of data with highest priority, as compared to six ad two high-priority data blocks allocated by the
and round-robin algorithms, respectively, when there was only one mining node. However, for medium- and low-priority data blocks, round-robin performed better because it does not consider priority levels. However, when the number of mining nodes was increased, then the proposed scheme allocated all blocks of data with high priority and it’s allocation of medium-priority data blocks was higher than the other two schemes. Both
and
allocated data blocks by considering their priority levels. However, the proposed
allocated more priority data blocks to mining nodes as compared to
within the same caching capacity of fog mining nodes.The same trend was presented in terms of percentage, as shown in
Figure 6.
To validate the performance of the proposed
, the data block allocation to mining nodes was observed with an increasing number of data blocks on three mining machines. The number of allocated data blocks, along with their percentages, are shown in
Figure 7 and
Figure 8, respectively. The results of the allocated blocks of data with different priorities are represented in three subplots, and the number of data block requests was divided equally into the three different priority levels and increased from 15 to 90, with an increment of 15. It can be seen that the proposed technique allocated the highest number of blocks of data with high priority, as compared to the round-robin and
algorithms. When the LBM received 15 block requests, with 5 each for each priority level within the caching capacity of the mining nodes, then all blocks were allocated to mining nodes using all three schemes. However, when the number of requested data blocks was increased to 30, with 10 for each priority level, then the proposed scheme, as well as
, allocated all high-priority blocks; however, the proposed scheme allocated more medium- and low-priority blocks compared to
. On the other hand, the round-robin scheme allocated an almost equal number of data blocks to each priority level. Similarly, with an increased number of data block requests received by the LBM, the proposed scheme showed better performance in data block allocation, due to the use of the 0/1 knapsack algorithm.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}