

Attention-Based Personalized Compatibility Learning for Fashion Matching


Abstract
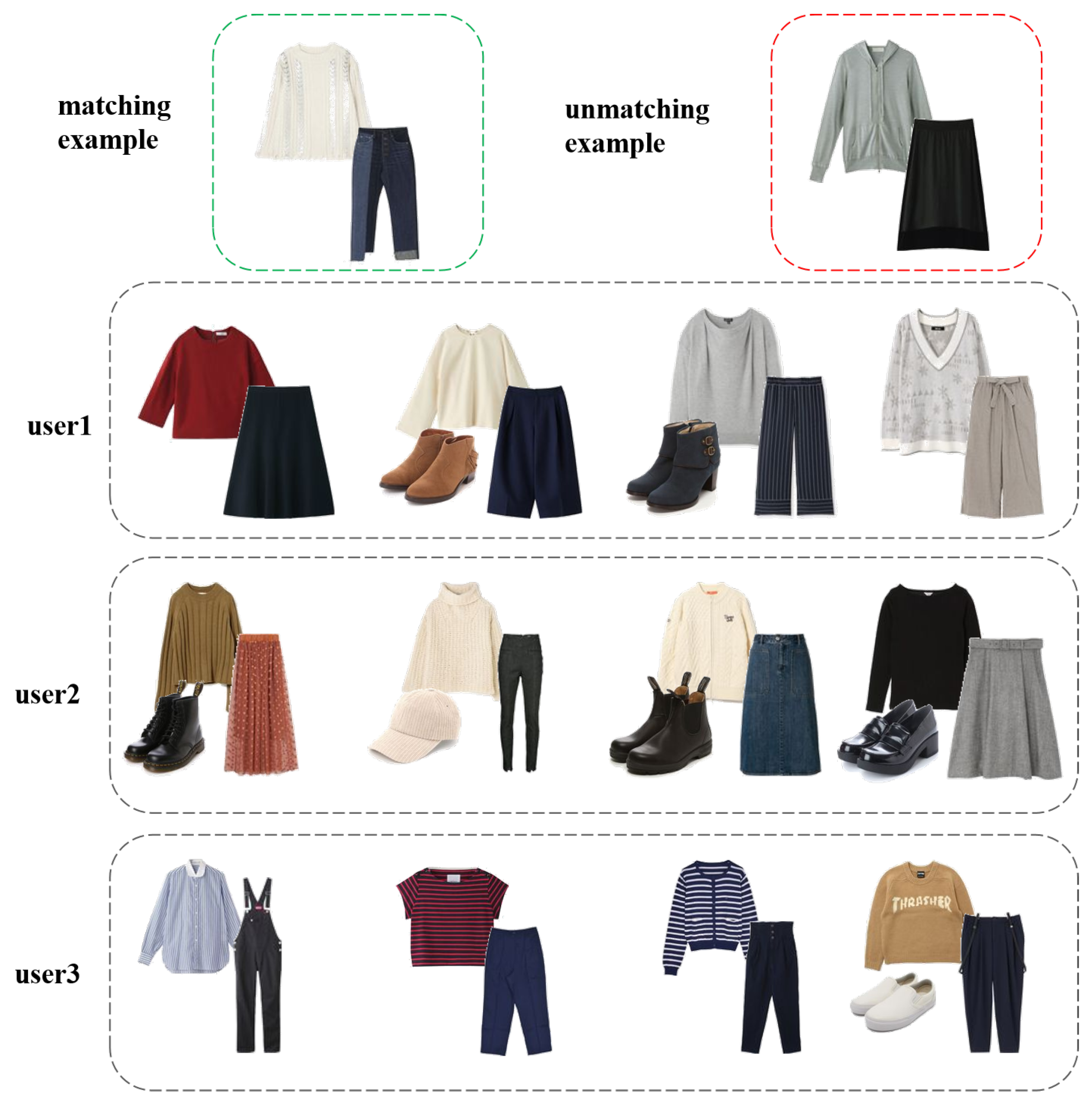
:1. Introduction
- First itemFirstly, we present an attention-based personalized compatibility embedding scheme for personalized clothing matching, namely PCE-Net, which jointly models attention-based (item-item) compatibility and personal (user-item) preferences;
- Secondly, we propose an innovative approach to capture the compatibility embeddings of multi-modal data using different attention branches separately, which has not been attempted before to the best of our knowledge. In addition, we demonstrate the effectiveness of different attention branches through ablation experiments;
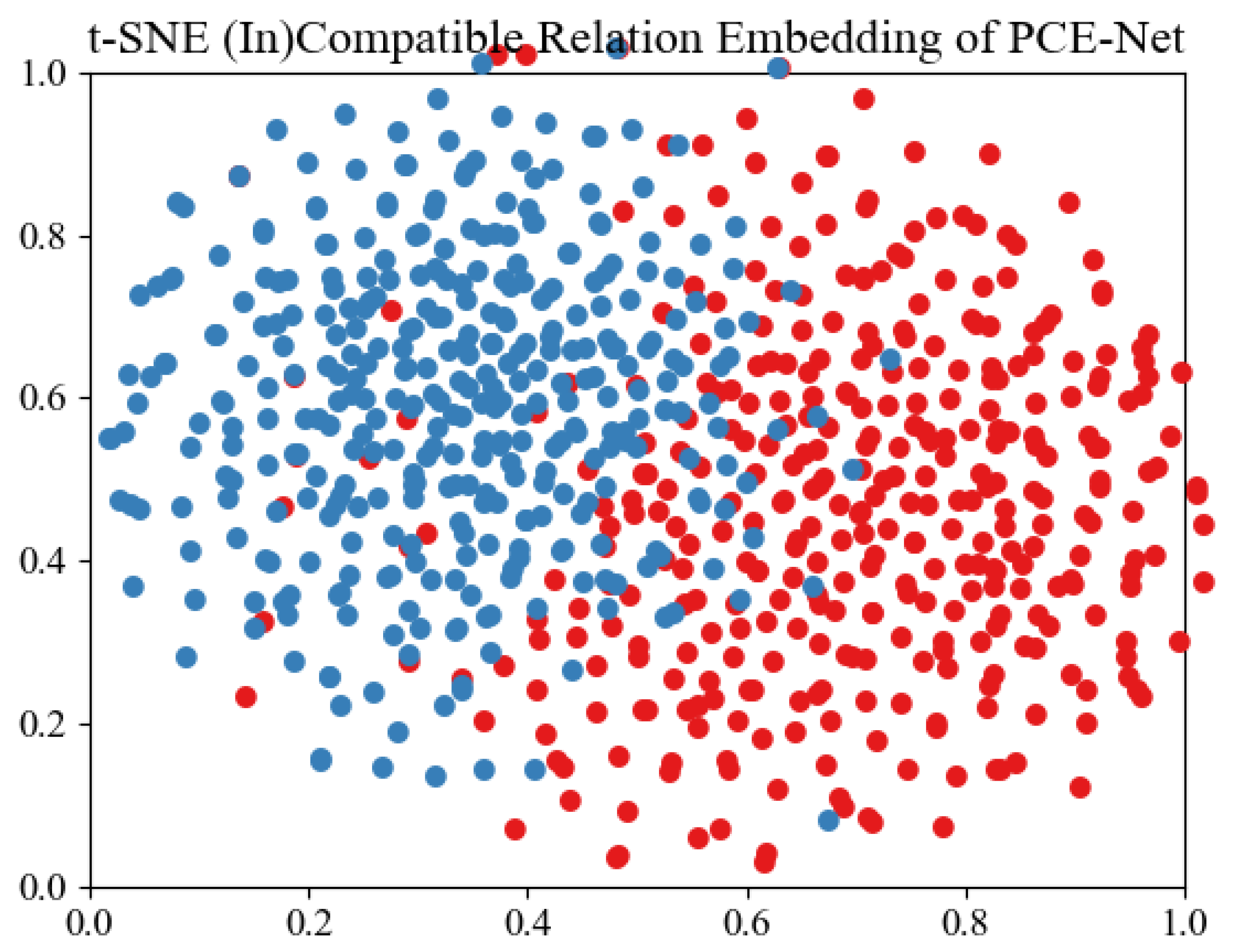
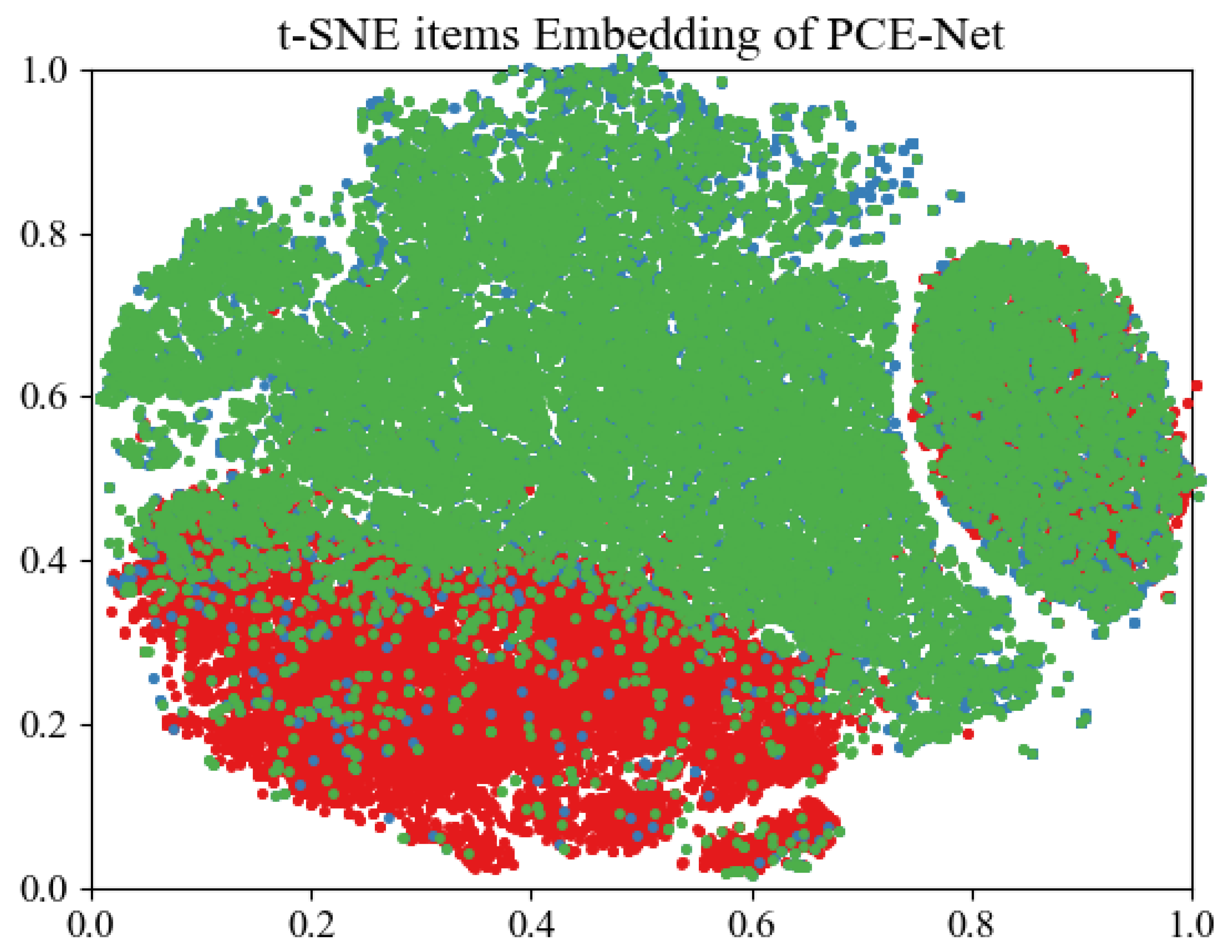
- Lastly, we conduct extensive experiments and use t-SNE visualization on the real-world dataset IQON3000 to validate the effectiveness of our scheme against state-of-the-art methods.
2. Related Work
3. Methodology
3.1. Problem Formulation
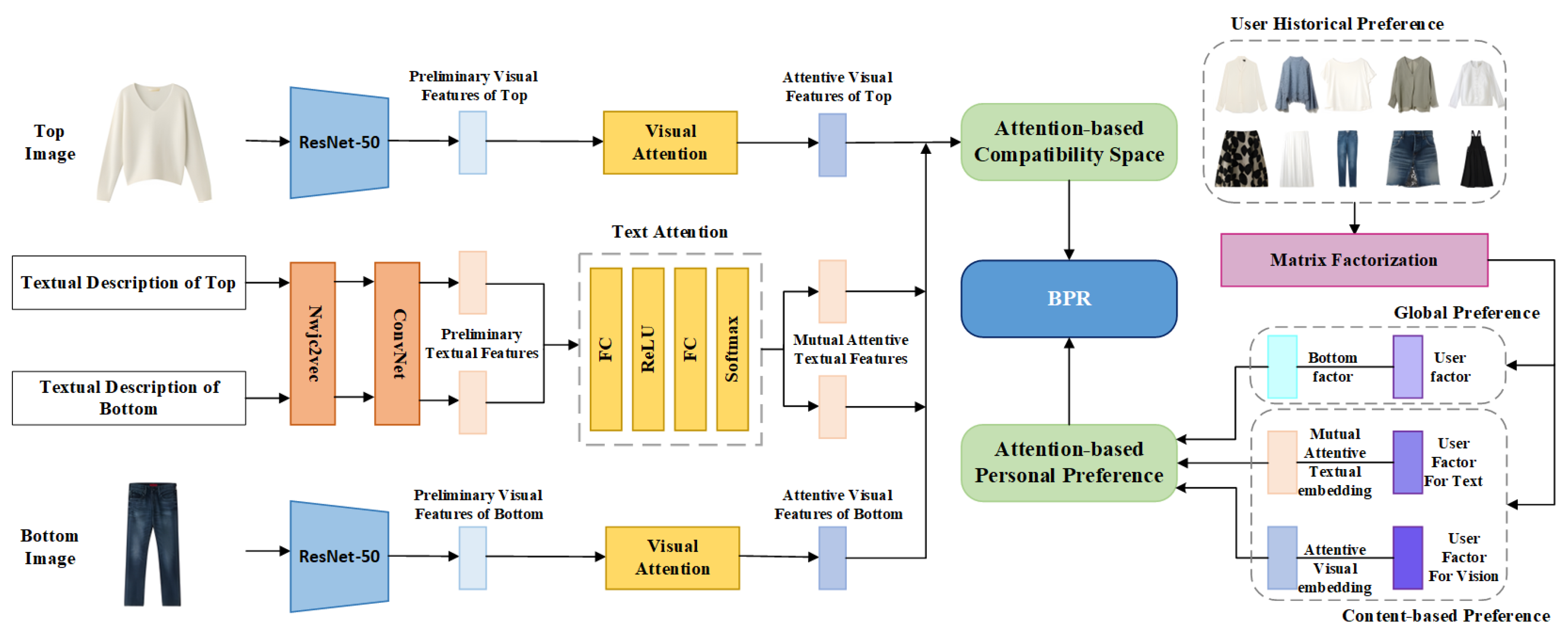
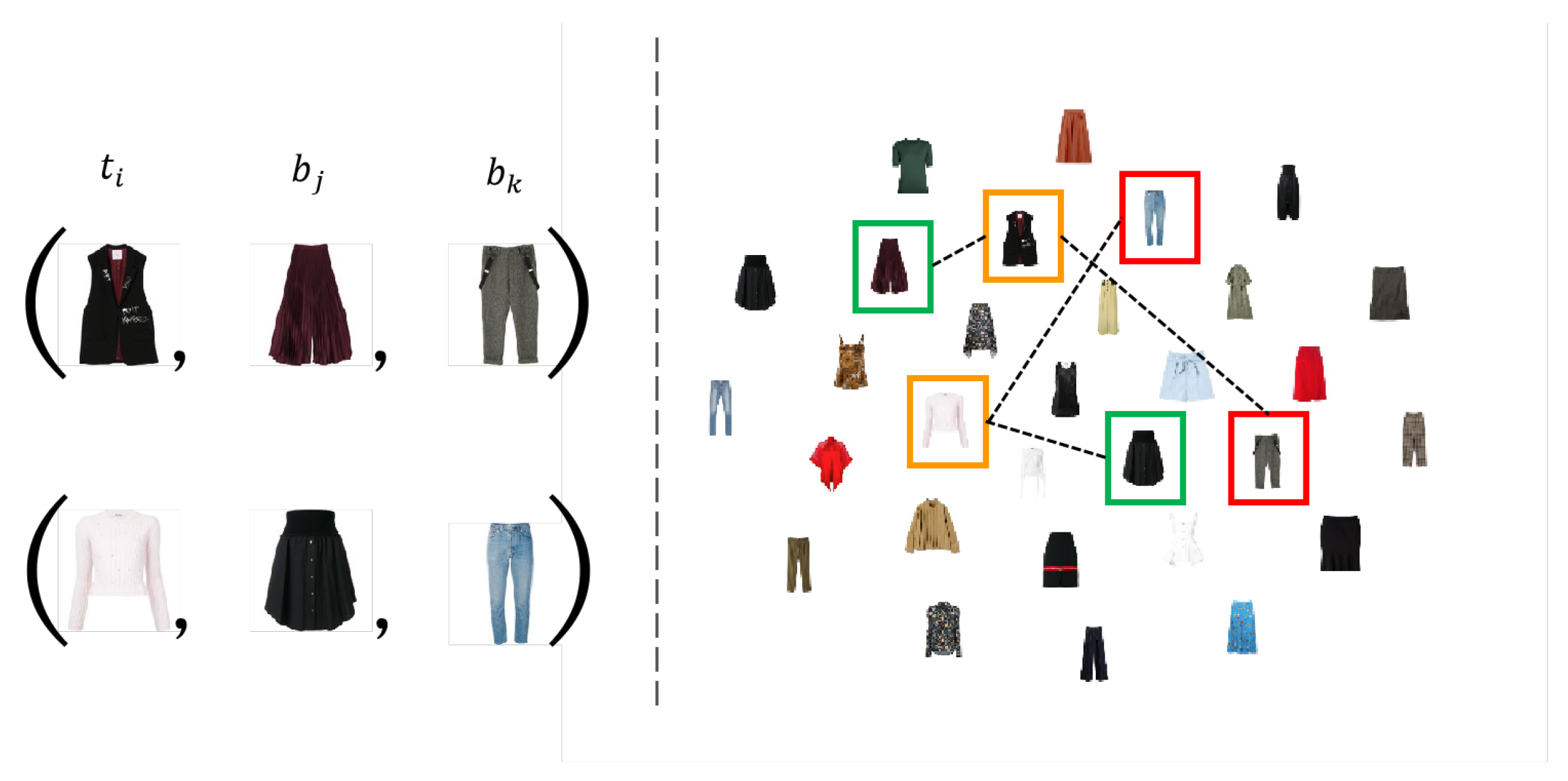
3.2. PCE-Net
3.2.1. Attention-Based Compatibility Embedding Modeling
3.2.2. Attention-Based Personal Preference Modeling
3.2.3. Objective Function
4. Experiment
4.1. Dataset
4.2. Implementation
4.3. Results and Discussion
- POP-T: POP is frequently used as a baseline in recommender systems [49]. POP-T simply selects the most popular bottoms for each top and vice versa. Here, “popularity” is defined as the number of tops paired with the bottom, i.e., the number of top-bottom pairs in the training set.
- POP-U: For this baseline [49], the number of users that used this bottom as a component of an outfit in the training set is used to determine the “popularity” of the bottom.
- RAND: The compatibility ratings between positive and negative pairs were randomly assigned.
- Bi-LSTM: The bidirectional LSTM method in [8] modeled an outfit as an ordered sequence. Its operating principle is to predict the next item conditioned on previous ones. We keep the variables constant by setting the sequence length to 2, i.e., there are only a top and a bottom.
- BPR-DAE: The baseline [16] uses a dual autoencoder network (DAE) to learn the potential compatibility space by jointly modeling the consistent relationship between visual and textual patterns and the implicit preference between items by Bayesian Personalized Ranking.
- BPR-MF: This model [18] is one of the most commonly used techniques for personalized recommendation tasks, which captures the latent user-item interaction by the Matrix Factorization (MF) method in the pairwise ranking tasks.
- VBPR: Unlike MF, the model [2] also considers the user’s preference for visual factors. The model represents the visual characteristics of an outfit by averaging the visual characteristics of the items in the set.
- TBPR: The difference between TBPR [2] and VBPR is using information from different modalities.
- VTBPR: This model [2] uses a combination of both visual and text modalities to model user preferences.
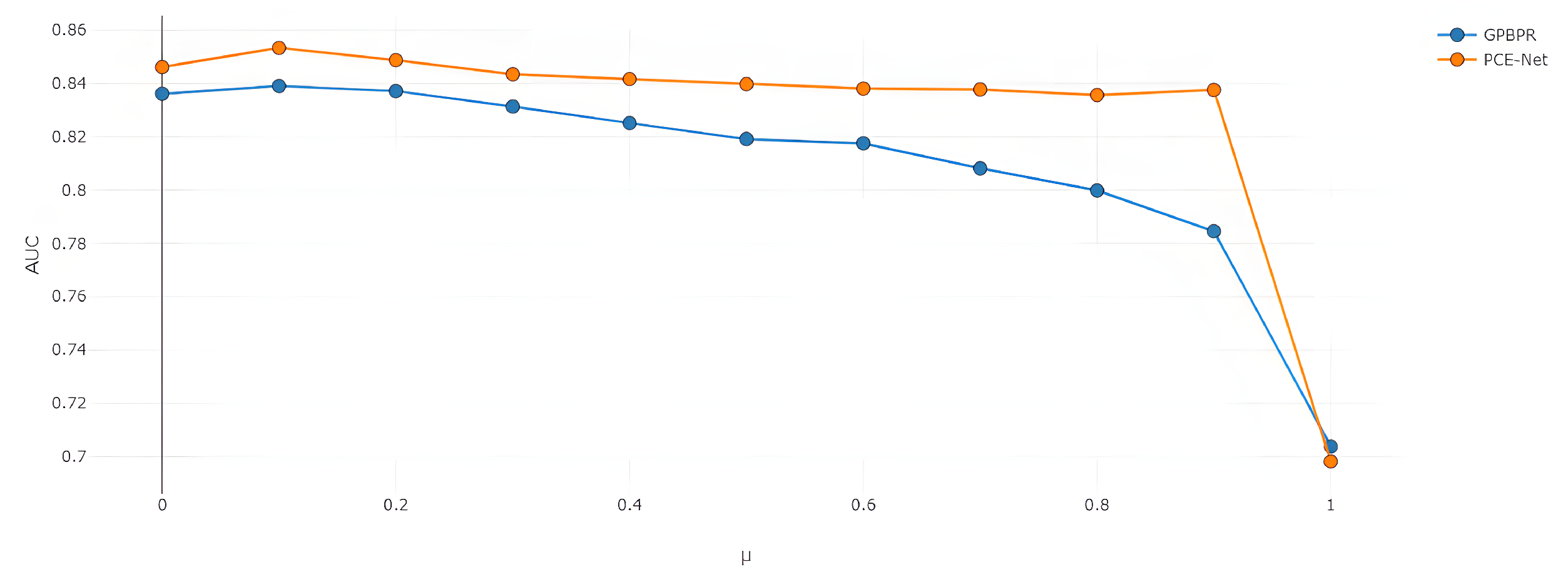
- GP-BPR: This baseline [11] combines visual and textual features of clothing with personal preferences to jointly model general (item-item) compatibility and personal (user-item) preferences, where matrix factorization for the user-item interaction matrix is performed to obtain the potential user preferences.
- PAI-BPR: This model [12] is an attribute-based interpretable personal preference modeling scheme, where personalization is achieved by taking inspiration from GP-BPR [11] and adding attribute-wise interpretable results. Since the code is not publicly available, we directly report the experimental results of Table III in the original paper [12] for quantitative comparison.
- BPR-DAE outperforms Bi-LSTM, demonstrating that the content-based model, which captures the compatibility relationship between items by directly extracting features from multimodal data, is superior to the sequential model (predicting the following item from the previous one).
- VTBPR performs better than VBPR, TBPR, and BPR-MF, indicating the value of multimodal data in enhancing model performance.
- To solve the problem of personalized clothing matching, GP-BPR and PAI-BPR combine generalized item-item compatibility and user-item preferences using multi-modal characteristics. Since PAI-BPR uses an attribute classification network to address the interpretability of the model, performance has been slightly improved.
- PCE-NET obtains the best performance compared to the above baseline, but there is no modeling attribute classification module because PCE-NET does not focus on interpretability problems. Our model can automatically capture the compatibility features of multi-modal data using two attention branches separately, which indicates that further development and exploitation of multi-modal data is necessary for embedding learning tasks.
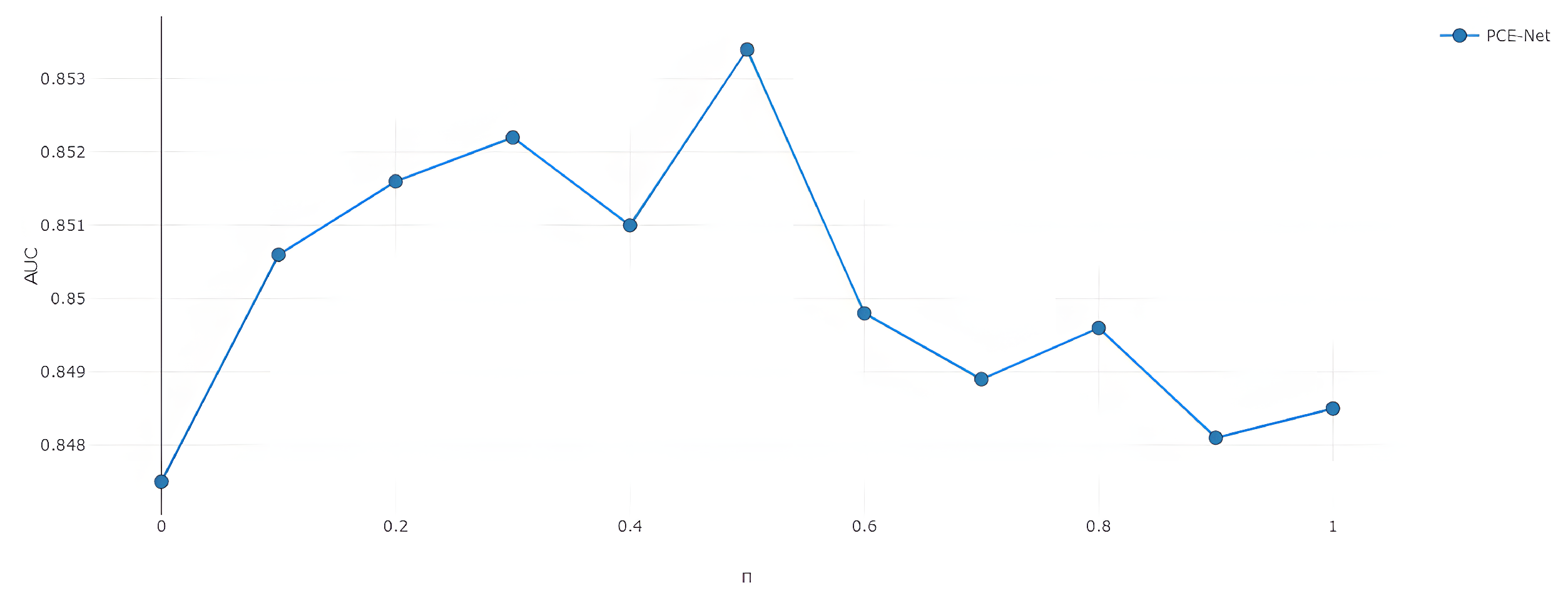
4.4. Ablation Study
4.5. User Study
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Veit, A.; Belongie, S.; Karaletsos, T. Conditional similarity networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 830–838. [Google Scholar]
- He, R.; McAuley, J. VBPR: Visual bayesian personalized ranking from implicit feedback. In Proceedings of the AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016; Volume 30. [Google Scholar]
- He, T.; Hu, Y. FashionNet: Personalized outfit recommendation with deep neural network. arXiv 2018, arXiv:1810.02443. [Google Scholar]
- Shih, Y.S.; Chang, K.Y.; Lin, H.T.; Sun, M. Compatibility family learning for item recommendation and generation. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32. [Google Scholar]
- Vasileva, M.I.; Plummer, B.A.; Dusad, K.; Rajpal, S.; Kumar, R.; Forsyth, D. Learning type-aware embeddings for fashion compatibility. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 390–405. [Google Scholar]
- Tan, R.; Vasileva, M.I.; Saenko, K.; Plummer, B.A. Learning similarity conditions without explicit supervision. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 10373–10382. [Google Scholar]
- Singhal, A.; Chopra, A.; Ayush, K.; Govind, U.P.; Krishnamurthy, B. Towards a unified framework for visual compatibility prediction. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Snowmass Village, CO, USA, 1–5 March 2020; pp. 3607–3616. [Google Scholar]
- Han, X.; Wu, Z.; Jiang, Y.G.; Davis, L.S. Learning fashion compatibility with bidirectional lstms. In Proceedings of the 25th ACM International Conference on Multimedia, Mountain View, CA, USA, 23–27 October 2017; pp. 1078–1086. [Google Scholar]
- Laenen, K.; Moens, M.F. Attention-based fusion for outfit recommendation. In Fashion Recommender Systems; Springer: Berlin/Heidelberg, Germany, 2017; pp. 69–86. [Google Scholar]
- Lin, Y.; Ren, P.; Chen, Z.; Ren, Z.; Ma, J.; De Rijke, M. Explainable outfit recommendation with joint outfit matching and comment generation. IEEE Trans. Knowl. Data Eng. 2019, 32, 1502–1516. [Google Scholar] [CrossRef]
- Song, X.; Han, X.; Li, Y.; Chen, J.; Xu, X.S.; Nie, L. GP-BPR: Personalized compatibility modeling for clothing matching. In Proceedings of the 27th ACM International Conference on Multimedia, Nice, France, 21–25 October 2019; pp. 320–328. [Google Scholar]
- Sagar, D.; Garg, J.; Kansal, P.; Bhalla, S.; Shah, R.R.; Yu, Y. Pai-bpr: Personalized outfit recommendation scheme with attribute-wise interpretability. In Proceedings of the 2020 IEEE Sixth International Conference on Multimedia Big Data (BigMM), New Delhi, India, 24–26 September 2020; pp. 221–230. [Google Scholar]
- Li, X.; Wang, X.; He, X.; Chen, L.; Xiao, J.; Chua, T.S. Hierarchical fashion graph network for personalized outfit recommendation. In Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval, Xi’an, China, 25–30 July 2020; pp. 159–168. [Google Scholar]
- Chen, W.; Huang, P.; Xu, J.; Guo, X.; Guo, C.; Sun, F.; Li, C.; Pfadler, A.; Zhao, H.; Zhao, B. POG: Personalized outfit generation for fashion recommendation at Alibaba iFashion. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Anchorage, AK, USA, 4–8 August 2019; pp. 2662–2670. [Google Scholar]
- Dong, X.; Song, X.; Feng, F.; Jing, P.; Xu, X.S.; Nie, L. Personalized capsule wardrobe creation with garment and user modeling. In Proceedings of the 27th ACM International Conference on Multimedia, Nice, France, 21–25 October 2019; pp. 302–310. [Google Scholar]
- Song, X.; Feng, F.; Liu, J.; Li, Z.; Nie, L.; Ma, J. Neurostylist: Neural compatibility modeling for clothing matching. In Proceedings of the 25th ACM International Conference on Multimedia, Mountain View, CA, USA, 23–27 October 2017; pp. 753–761. [Google Scholar]
- Cui, Z.; Li, Z.; Wu, S.; Zhang, X.Y.; Wang, L. Dressing as a whole: Outfit compatibility learning based on node-wise graph neural networks. In Proceedings of the World Wide Web Conference, San Francisco, CA, USA, 13–17 May 2019; pp. 307–317. [Google Scholar]
- Rendle, S.; Freudenthaler, C.; Gantner, Z.; Schmidt-Thieme, L. BPR: Bayesian personalized ranking from implicit feedback. arXiv 2012, arXiv:1205.2618. [Google Scholar]
- Rendle, S.; Schmidt-Thieme, L. Pairwise interaction tensor factorization for personalized tag recommendation. In Proceedings of the Third ACM International Conference on Web Search and Data Mining, New York, NY, USA, 4–6 February 2010; pp. 81–90. [Google Scholar] [CrossRef]
- McAuley, J.; Targett, C.; Shi, Q.; Van Den Hengel, A. Image-based recommendations on styles and substitutes. In Proceedings of the 38th International ACM SIGIR Conference on Research and Development in Information Retrieval, Santiago, Chile, 9–13 August 2015; pp. 43–52. [Google Scholar]
- Veit, A.; Kovacs, B.; Bell, S.; McAuley, J.; Bala, K.; Belongie, S. Learning visual clothing style with heterogeneous dyadic co-occurrences. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 13–16 December 2015; pp. 4642–4650. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Advances in Neural Information Processing Systems; Springer: Long Beach, CA, USA, 2017; Volume 30. [Google Scholar]
- Cucurull, G.; Taslakian, P.; Vazquez, D. Context-aware visual compatibility prediction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 12617–12626. [Google Scholar]
- Song, X.; Feng, F.; Han, X.; Yang, X.; Liu, W.; Nie, L. Neural compatibility modeling with attentive knowledge distillation. In Proceedings of the 41st International ACM SIGIR Conference on Research & Development in Information Retrieval, Ann Arbor, MI, USA, 8–12 July 2018; pp. 5–14. [Google Scholar]
- Yang, X.; Ma, Y.; Liao, L.; Wang, M.; Chua, T.S. Transnfcm: Translation-based neural fashion compatibility modeling. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 403–410. [Google Scholar]
- Lu, Z.; Hu, Y.; Jiang, Y.; Chen, Y.; Zeng, B. Learning binary code for personalized fashion recommendation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 10562–10570. [Google Scholar]
- Taraviya, M.; Beniwal, A.; Lin, Y.L.; Davis, L. Personalized compatibility metric learning. In Proceedings of the KDD 2021 International Workshop on Industrial Recommendation Systems, Singapore, 14–18 August 2021. [Google Scholar]
- Lin, Y.L.; Tran, S.; Davis, L.S. Fashion outfit complementary item retrieval. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 3311–3319. [Google Scholar]
- Sarkar, R.; Bodla, N.; Vasileva, M.I.; Lin, Y.L.; Beniwal, A.; Lu, A.; Medioni, G. Outfittransformer: Learning outfit representations for fashion recommendation. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 4–6 January 2023; pp. 3601–3609. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef] [PubMed]
- Wang, Z.; Bai, X.; Ye, M.; Satoh, S. Incremental deep hidden attribute learning. In Proceedings of the 26th ACM international conference on Multimedia, Seoul, Republic of Korea, 22–26 October 2018; pp. 72–80. [Google Scholar]
- Liu, M.; Wang, X.; Nie, L.; Tian, Q.; Chen, B.; Chua, T.S. Cross-modal moment localization in videos. In Proceedings of the 26th ACM International Conference on Multimedia, Seoul, Republic of Korea, 22–26 October 2018; pp. 843–851. [Google Scholar]
- Lee, D.; Seung, H.S. Algorithms for non-negative matrix factorization. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2000; Volume 13. [Google Scholar]
- Mnih, A.; Salakhutdinov, R.R. Probabilistic matrix factorization. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2007; Volume 20. [Google Scholar]
- Koren, Y.; Bell, R.; Volinsky, C. Matrix factorization techniques for recommender systems. Computer 2009, 42, 30–37. [Google Scholar] [CrossRef]
- Koren, Y.; Bell, R. Advances in Collaborative Filtering. In Recommender Systems Handbook; Ricci, F., Rokach, L., Shapira, B., Eds.; Springer: New York, NY, USA, 2015; pp. 77–118. [Google Scholar] [CrossRef]
- Kim, D.; Park, C.; Oh, J.; Lee, S.; Yu, H. Convolutional matrix factorization for document context-aware recommendation. In Proceedings of the 10th ACM Conference on Recommender Systems, Boston, MA, USA, 15–19 September 2016; pp. 233–240. [Google Scholar]
- Packer, C.; McAuley, J.; Ramisa, A. Visually-aware personalized recommendation using interpretable image representations. arXiv 2018, arXiv:1806.09820. [Google Scholar]
- Loni, B.; Pagano, R.; Larson, M.; Hanjalic, A. Bayesian personalized ranking with multi-channel user feedback. In Proceedings of the 10th ACM Conference on Recommender Systems, Boston, MA, USA, 15–19 September 2016; pp. 361–364. [Google Scholar]
- Cao, D.; Nie, L.; He, X.; Wei, X.; Zhu, S.; Chua, T.S. Embedding factorization models for jointly recommending items and user generated lists. In Proceedings of the 40th International ACM SIGIR Conference on Research and Development in Information Retrieval, Shinjuku, Japan, 7–11 August 2017; pp. 585–594. [Google Scholar]
- Khosla, A.; Das Sarma, A.; Hamid, R. What makes an image popular? In Proceedings of the 23rd International Conference on World Wide Web, Seoul, Republic of Korea, 7–11 April 2014; pp. 867–876. [Google Scholar]
- Kim, Y. Convolutional neural networks for sentence classification. arXiv 2014, arXiv:1408.5882. [Google Scholar]
- Severyn, A.; Moschitti, A. Twitter sentiment analysis with deep convolutional neural networks. In Proceedings of the 38th International ACM SIGIR Conference on Research and Development in Information Retrieval, Santiago, Chile, 9–13 August 2015; pp. 959–962. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Asahara, M. NWJC2Vec: Word Embedding Dataset from ‘NINJAL Web Japanese Corpus’; John Benjamins Publishing Company: Amsterdam, The Netherlands; Philadelphia, PA, USA, 2018; Volume 24, pp. 7–22. [Google Scholar]
- Glorot, X.; Bengio, Y. Understanding the difficulty of training deep feedforward neural networks. In Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics, JMLR Workshop and Conference Proceedings, Sardinia, Italy, 13–15 May 2010; pp. 249–256. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Zhang, H.; Zha, Z.J.; Yang, Y.; Yan, S.; Gao, Y.; Chua, T.S. Attribute-augmented semantic hierarchy: Towards bridging semantic gap and intention gap in image retrieval. In Proceedings of the 21st ACM International Conference on Multimedia, Barcelona, Spain, 21–25 October 2013; pp. 33–42. [Google Scholar]
- He, X.; Liao, L.; Zhang, H.; Nie, L.; Hu, X.; Chua, T.S. Neural collaborative filtering. In Proceedings of the 26th International Conference on World Wide Web, Perth, Australia, 3–7 April 2017; pp. 173–182. [Google Scholar]
- Van der Maaten, L.; Hinton, G. Visualizing data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Approach | AUC | |
|---|---|---|
| Baselines | POP-T | 0.6042 |
| POP-U | 0.5951 | |
| RAND | 0.5014 | |
| Bi-LSTM | 0.6675 | |
| BPR-DAE | 0.7004 | |
| BPR-MF | 0.7913 | |
| VBPR | 0.8129 | |
| TBPR | 0.8146 | |
| VTBPR | 0.8213 | |
| GP-BPR | 0.8314 | |
| PAI-BPR | 0.8502 | |
| Proposed | PCE-Net | 0.8534 |
| Modality | Approach | AUC |
|---|---|---|
| Visual modality | GP-BPR-V | 0.8239 |
| PAI-BPR-V | 0.8413 | |
| PCE-Net-V | 0.8485 | |
| Textual modality | GP-BPR-T | 0.8313 |
| PAI-BPR-T | 0.8432 | |
| PCE-Net-T | 0.8475 | |
| Muti-modal | GP-BPR | 0.8314 |
| PAI-BPR | 0.8502 | |
| PCE-Net | 0.8534 |
| Approach | AUC | |
|---|---|---|
| Attention branch | Visual Attention | 0.8432 |
| Text Attention | 0.8508 | |
| (V + T) Attention | 0.8534 |
| Approach | AUC | |
|---|---|---|
| Different component | PCE-Net-P | 0.8376 |
| PCE-Net-C | 0.6982 | |
| ours | PCE-Net | 0.8534 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nie, X.; Xu, Z.; Zhang, J.; Tian, Y. Attention-Based Personalized Compatibility Learning for Fashion Matching. Appl. Sci. 2023, 13, 9638. https://doi.org/10.3390/app13179638
Nie X, Xu Z, Zhang J, Tian Y. Attention-Based Personalized Compatibility Learning for Fashion Matching. Applied Sciences. 2023; 13(17):9638. https://doi.org/10.3390/app13179638
Chicago/Turabian StyleNie, Xiaozhe, Zhijie Xu, Jianqin Zhang, and Yu Tian. 2023. "Attention-Based Personalized Compatibility Learning for Fashion Matching" Applied Sciences 13, no. 17: 9638. https://doi.org/10.3390/app13179638
APA StyleNie, X., Xu, Z., Zhang, J., & Tian, Y. (2023). Attention-Based Personalized Compatibility Learning for Fashion Matching. Applied Sciences, 13(17), 9638. https://doi.org/10.3390/app13179638