
Low-Light Image Enhancement Method for Electric Power Operation Sites Considering Strong Light Suppression
Abstract
:1. Introduction
- We designed a strong light judgment method based on sliding windows, which used a sliding window to segment the image; a brightness judgment was performed based on the average value of the deviation and the average deviation of the subimages of the grayscale image from the strong light threshold in order to search for strong light.
- We used a light effect decomposition method based on a layer decomposition network to decompose the light effects of RGB images in the presence of strong light to eliminate the light effect layer and to reduce the interference of strong light effects on the enhancement of low-light images.
- We constructed a Zero-DCE low-light enhancement network based on a kernel selection module, with a significant decrease in the number of parameters (Params) and the number of floating-point operations (FLOPs) compared with the original Zero-DCE; the subjective visual quality and objective evaluation metrics of the enhanced images outperformed those of other current state-of-the-art methods.
2. Related Work
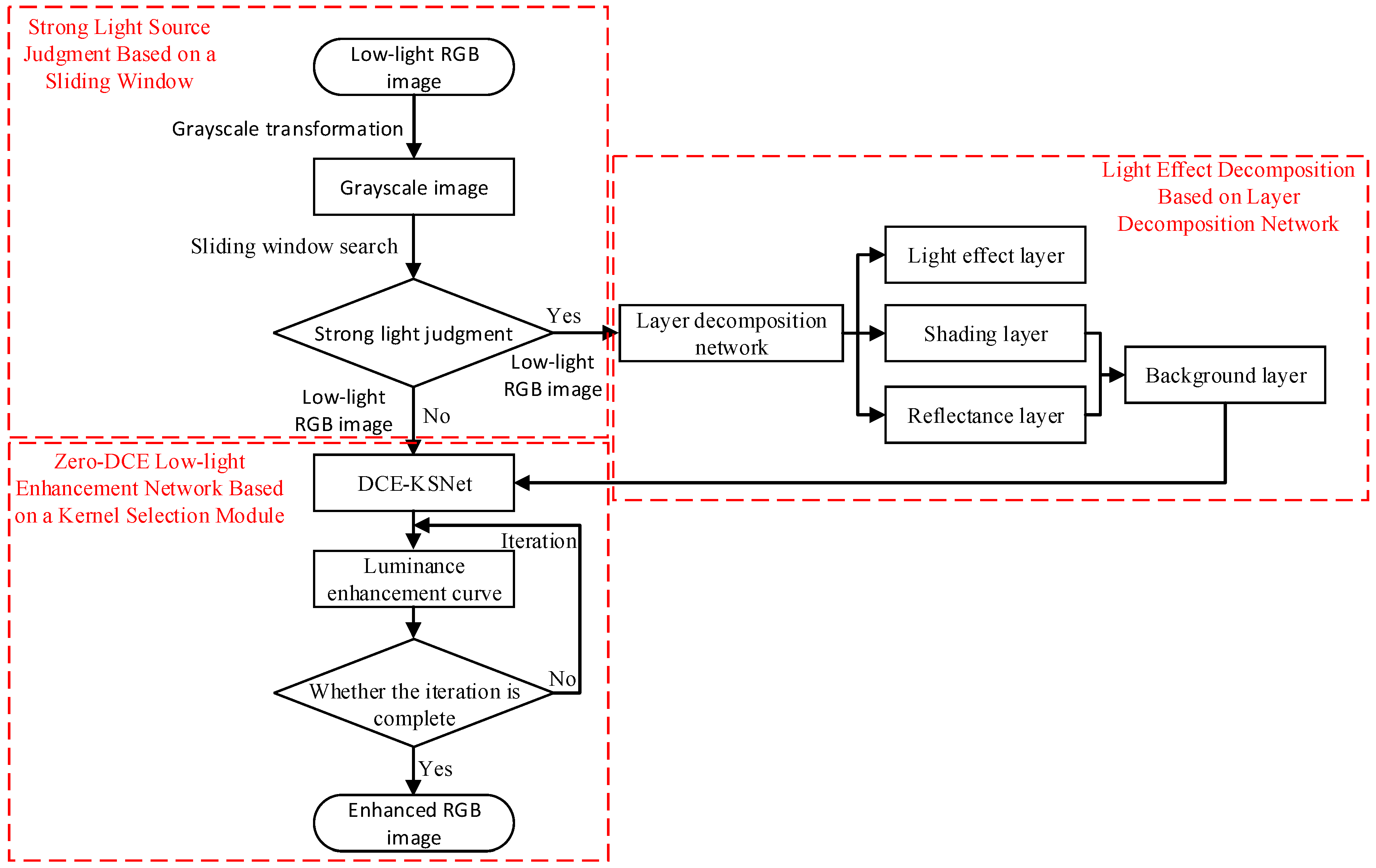
3. Methods
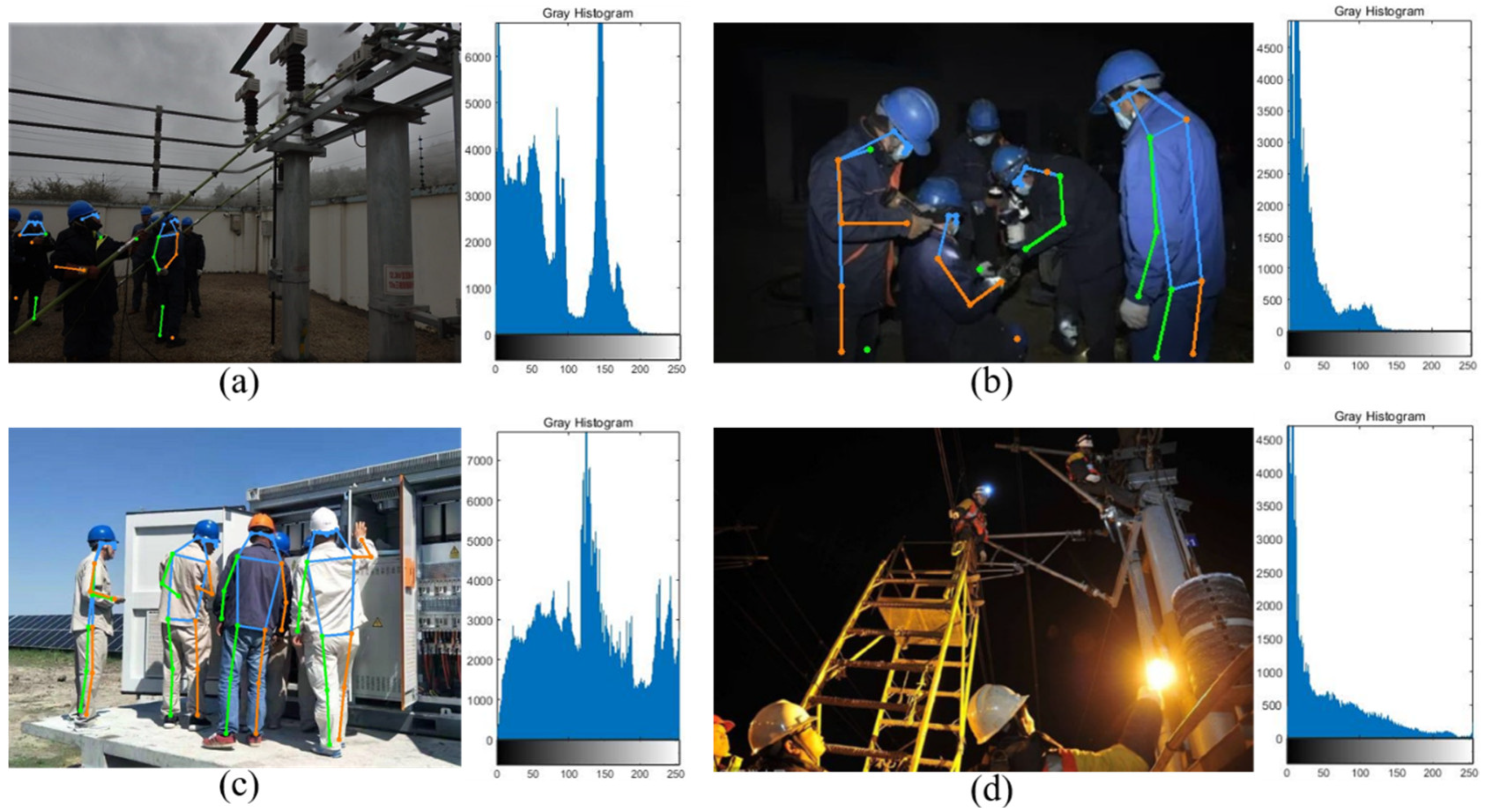
3.1. Strong Light Source Judgment Based on a Sliding Window
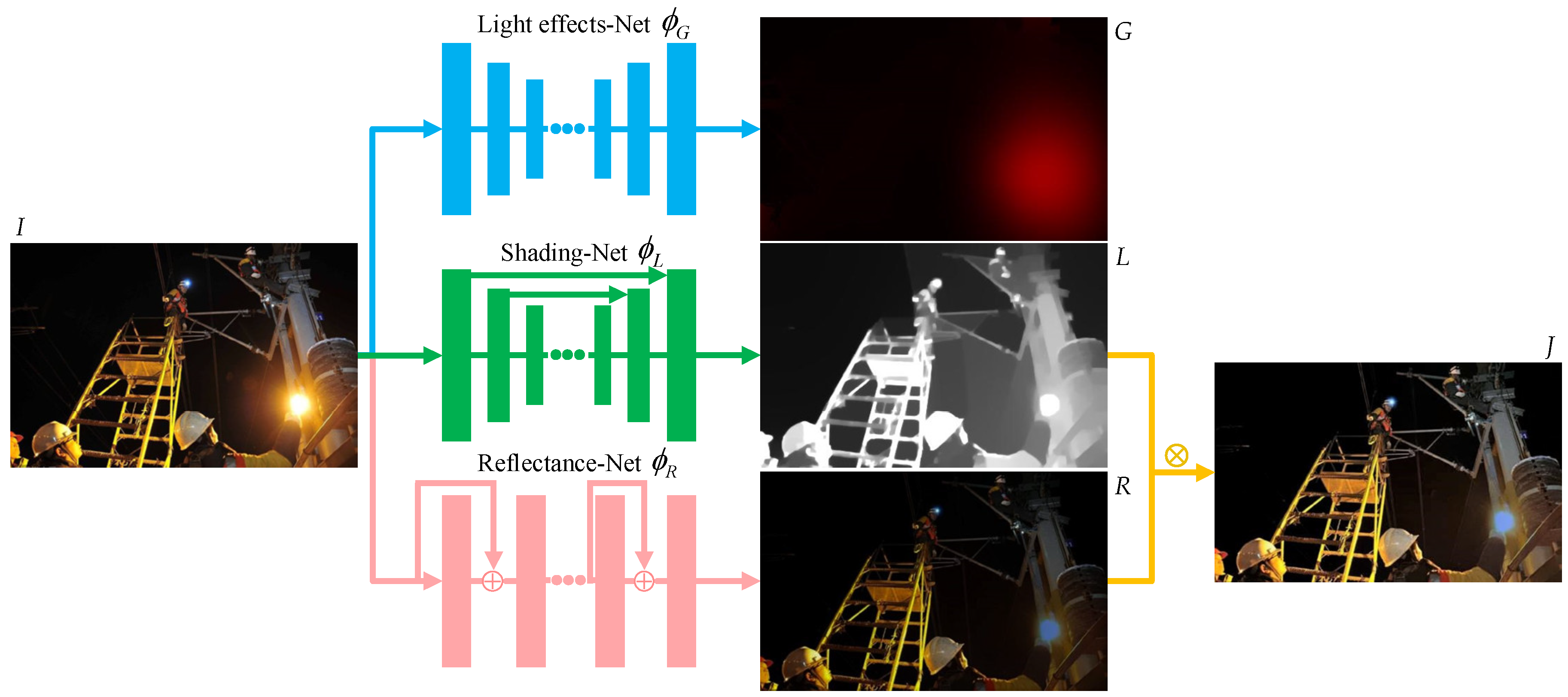
3.2. Light Effect Decomposition Based on Layer Decomposition Network
3.3. Zero-DCE Low-Light Enhancement Network Based on a Kernel Selection Module
- (1)
- Spatial Consistency Loss
- (2)
- Exposure Control Loss
- (3)
- Color Constancy Loss
- (4)
- Luminance Smoothing Loss
4. Experiments
4.1. Datasets
4.2. Environment Configuration
4.3. Training and Testing
4.4. Evaluation
4.5. Results
4.5.1. Luminance Enhancement Curve Effectiveness Experiment
4.5.2. Ablation Experiment of Each Loss
4.5.3. Low-Light Enhancement Effect Comparison Experiment
4.5.4. Model Complexity Comparison Experiment
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhang, F.; Shao, Y.; Sun, Y.; Zhu, K.; Gao, C.; Sang, N. Unsupervised low-light image enhancement via histogram equalization prior. arXiv 2021, arXiv:2112.01766. [Google Scholar]
- Jeong, I.; Lee, C. An optimization-based approach to gamma correction parameter estimation for low-light image enhancement. Multimed. Tools Appl. 2021, 80, 18027–18042. [Google Scholar] [CrossRef]
- Liu, S.; Long, W.; He, L.; Li, Y.; Ding, W. Retinex-based fast algorithm for low-light image enhancement. Entropy 2021, 23, 746. [Google Scholar] [CrossRef] [PubMed]
- Ismail, M.K.; Al-Ameen, Z. Adapted single scale Retinex algorithm for nighttime image enhancement. AL-Rafidain J. Comput. Sci. Math. 2022, 16, 59–69. [Google Scholar] [CrossRef]
- Ma, L.; Lin, J.; Shang, J.; Zhong, W.; Fan, X.; Luo, Z.; Liu, R. Learning multi-scale retinex with residual network for low-light image enhancement. In Proceedings of the Chinese Conference on Pattern Recognition and Computer Vision, Nanjing, China, 16–18 October 2020; pp. 291–302. [Google Scholar]
- Wang, F.; Zhang, B.; Zhang, C.; Yan, W.; Zhao, Z.; Wang, M. Low-light image joint enhancement optimization algorithm based on frame accumulation and multi-scale Retinex. Ad Hoc Netw. 2021, 113, 102398. [Google Scholar] [CrossRef]
- Lore, K.G.; Akintayo, A.; Sarkar, S. LLNet: A deep autoencoder approach to natural low-light image enhancement. Pattern Recognit. 2017, 61, 650–662. [Google Scholar] [CrossRef]
- Wei, C.; Wang, W.; Yang, W.; Liu, J. Deep retinex decomposition for low-light enhancement. arXiv 2018, arXiv:1808.04560. [Google Scholar]
- Afifi, M.; Derpanis, K.G.; Ommer, B.; Brown, M.S. Learning multi-scale photo exposure correction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 9157–9167. [Google Scholar]
- Jiang, Y.; Gong, X.; Liu, D.; Cheng, Y.; Fang, C.; Shen, X.; Yang, J.; Zhou, P.; Wang, Z. Enlightengan: Deep light enhancement without paired supervision. IEEE Trans. Image Process. 2021, 30, 2340–2349. [Google Scholar] [CrossRef] [PubMed]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention, Part III 18, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Guo, C.; Li, C.; Guo, J.; Loy, C.C.; Hou, J.; Kwong, S.; Cong, R. Zero-reference deep curve estimation for low-light image enhancement. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 1780–1789. [Google Scholar]
- Jin, Y.; Yang, W.; Tan, R.T. Unsupervised night image enhancement: When layer decomposition meets light-effects suppression. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; pp. 404–421. [Google Scholar]
- Radulescu, V.M.; Maican, C.A. Algorithm for image processing using a frequency separation method. In Proceedings of the 2022 23rd International Carpathian Control Conference (ICCC), Sinaia, Romania, 29 May–1 June 2022; pp. 181–185. [Google Scholar]
- Li, X.; Wang, W.; Hu, X.; Yang, J. Selective kernel networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 510–519. [Google Scholar]
- Chollet, F. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1251–1258. [Google Scholar]
- Mertens, T.; Kautz, J.; Van Reeth, F. Exposure fusion. In Proceedings of the 15th Pacific Conference on Computer Graphics and Applications (PG’07), Maui, HI, USA, 29 October–2 November 2007; IEEE: Piscataway, NJ, USA, 2007; pp. 382–390. [Google Scholar]
- Mertens, T.; Kautz, J.; Van Reeth, F. Exposure fusion: A simple and practical alternative to high dynamic range photography. Comput. Graph. Forum 2009, 28, 161–171. [Google Scholar] [CrossRef]
- Buchsbaum, G. A spatial processor model for object colour perception. J. Frankl. Inst. 1980, 310, 1–26. [Google Scholar]
- Cai, J.; Gu, S.; Zhang, L. Learning a deep single image contrast enhancer from multi-exposure images. IEEE Trans. Image Process. 2018, 27, 2049–2062. [Google Scholar]
- Wang, J.; Sun, K.; Cheng, T.; Jiang, B.; Deng, C.; Zhao, Y.; Liu, D.; Mu, Y.; Tan, M.; Wang, X.; et al. Deep high-resolution representation learning for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 3349–3364. [Google Scholar] [CrossRef]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. arXiv 2015, arXiv:1506.01497. [Google Scholar] [CrossRef]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xi, Y.; Zhang, Z.; Wang, W. Low-Light Image Enhancement Method for Electric Power Operation Sites Considering Strong Light Suppression. Appl. Sci. 2023, 13, 9645. https://doi.org/10.3390/app13179645
Xi Y, Zhang Z, Wang W. Low-Light Image Enhancement Method for Electric Power Operation Sites Considering Strong Light Suppression. Applied Sciences. 2023; 13(17):9645. https://doi.org/10.3390/app13179645
Chicago/Turabian StyleXi, Yang, Zihao Zhang, and Wenjing Wang. 2023. "Low-Light Image Enhancement Method for Electric Power Operation Sites Considering Strong Light Suppression" Applied Sciences 13, no. 17: 9645. https://doi.org/10.3390/app13179645
APA StyleXi, Y., Zhang, Z., & Wang, W. (2023). Low-Light Image Enhancement Method for Electric Power Operation Sites Considering Strong Light Suppression. Applied Sciences, 13(17), 9645. https://doi.org/10.3390/app13179645