
Factory Simulation of Optimization Techniques Based on Deep Reinforcement Learning for Storage Devices



Abstract
:1. Introduction
2. Related Work
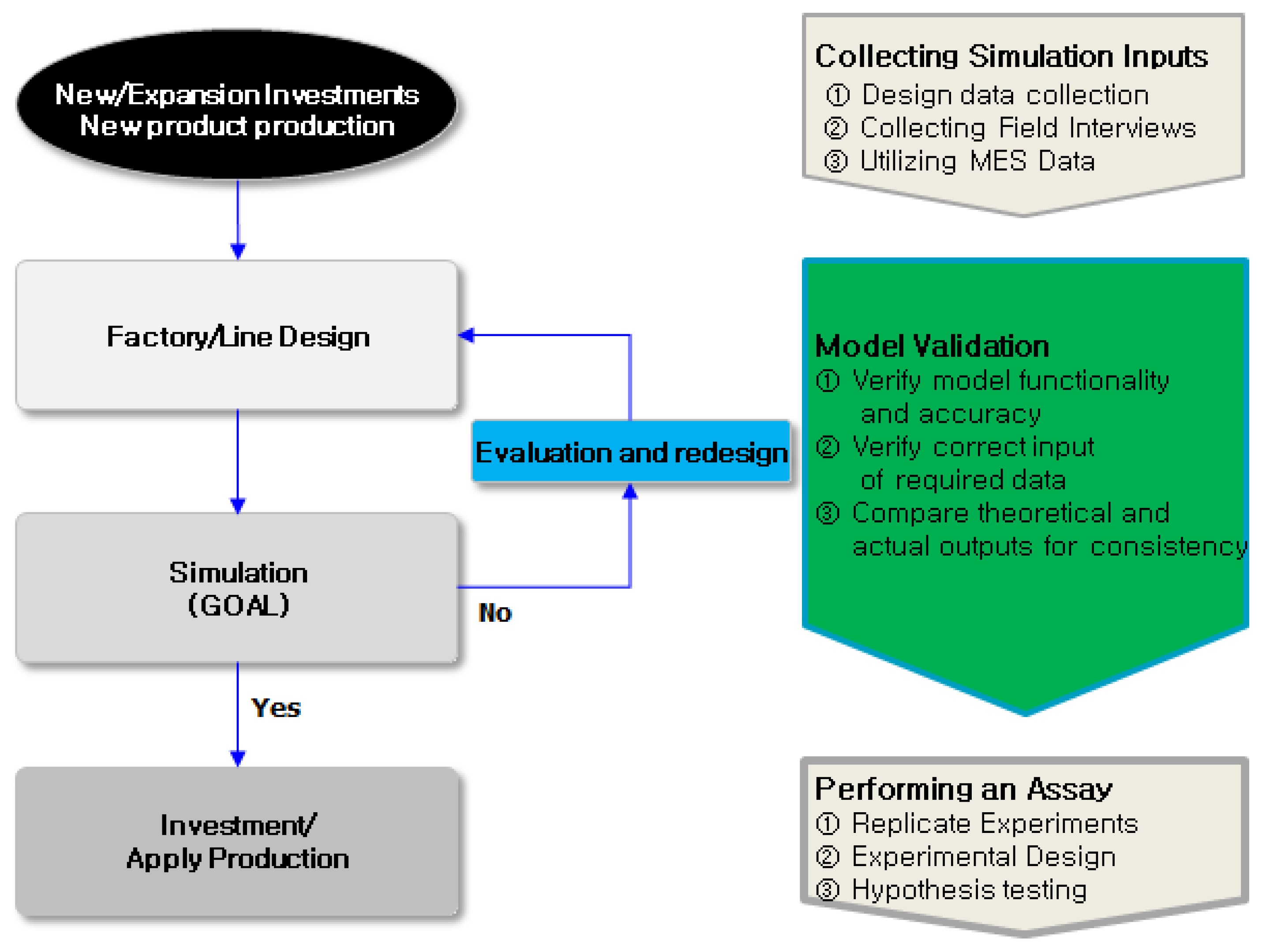
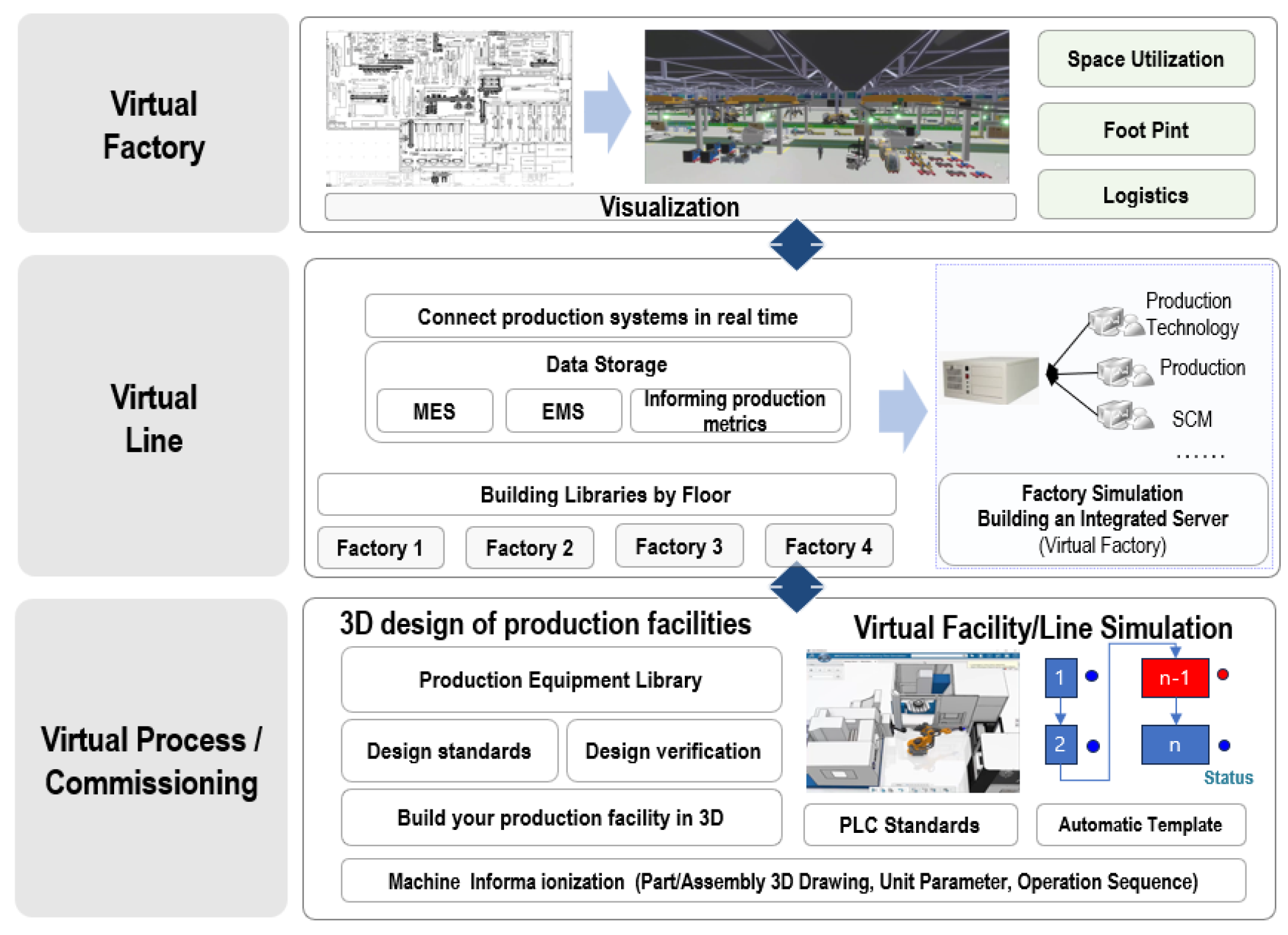
2.1. Factory Simulation
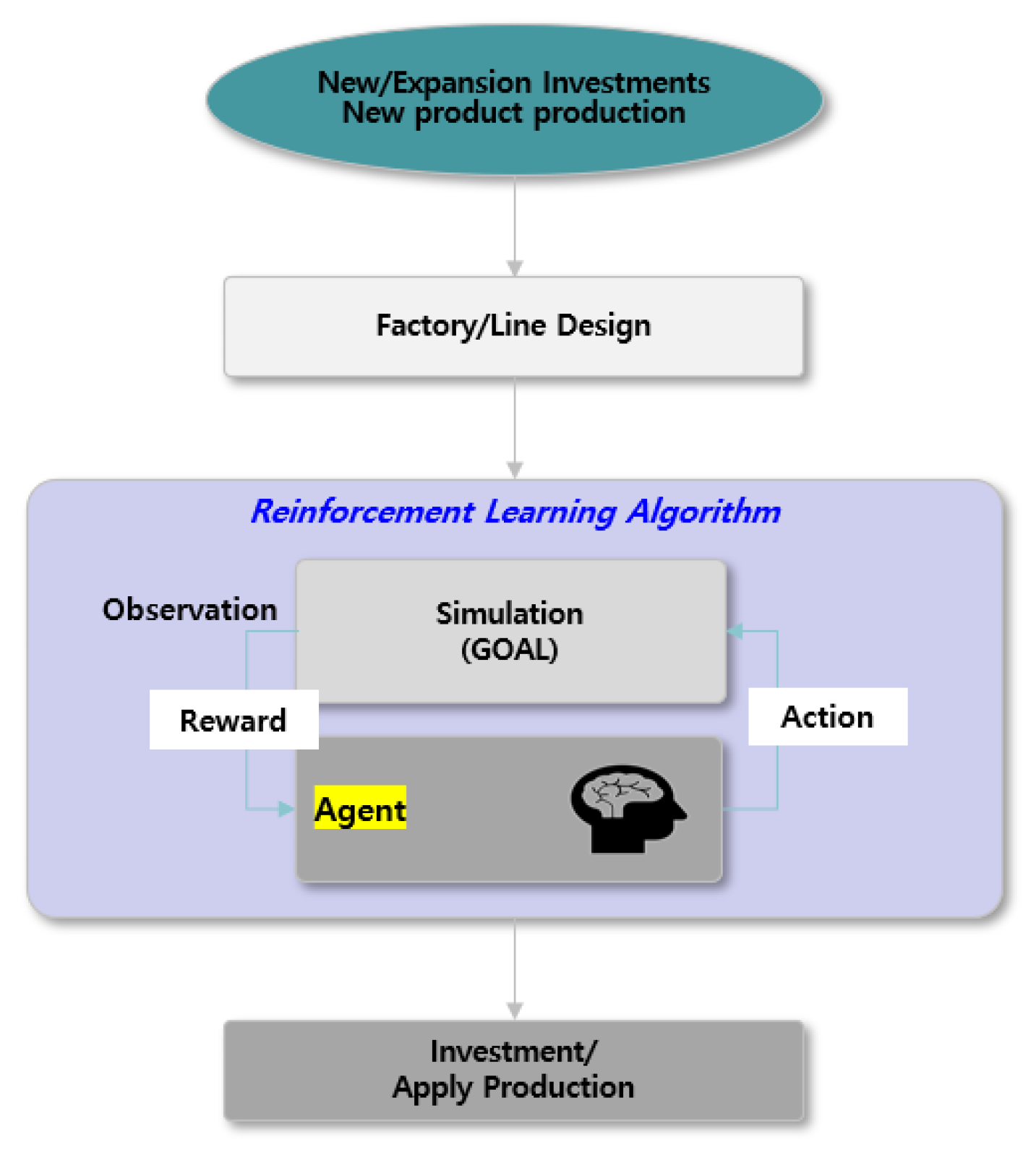
2.2. RL
- 1
- ;
- 2
- , representing the set of all possible states in the MDP;
- 3
- , representing the set of all actions that an agent can take;
- 4
- The state transition probability , representing the probability of changing from any state when taking action a;
- 5
- The reward function is a function that rewards an agent for an action taken in any state where . The environment rewards the agent for taking the action in a certain state .
- 1
- The agent must decide what action a to take in any state , which is called a policy. A policy is defined as follows [16]:
- 2
- RL is a learning policy that involves trial and error to maximize the reward. The goodness or badness of an action is determined by the sum of the rewards, which is defined as the return value .The depreciation rate and the return determine the weight of the reward, with the weighted sum of the rewards expressed as follows:
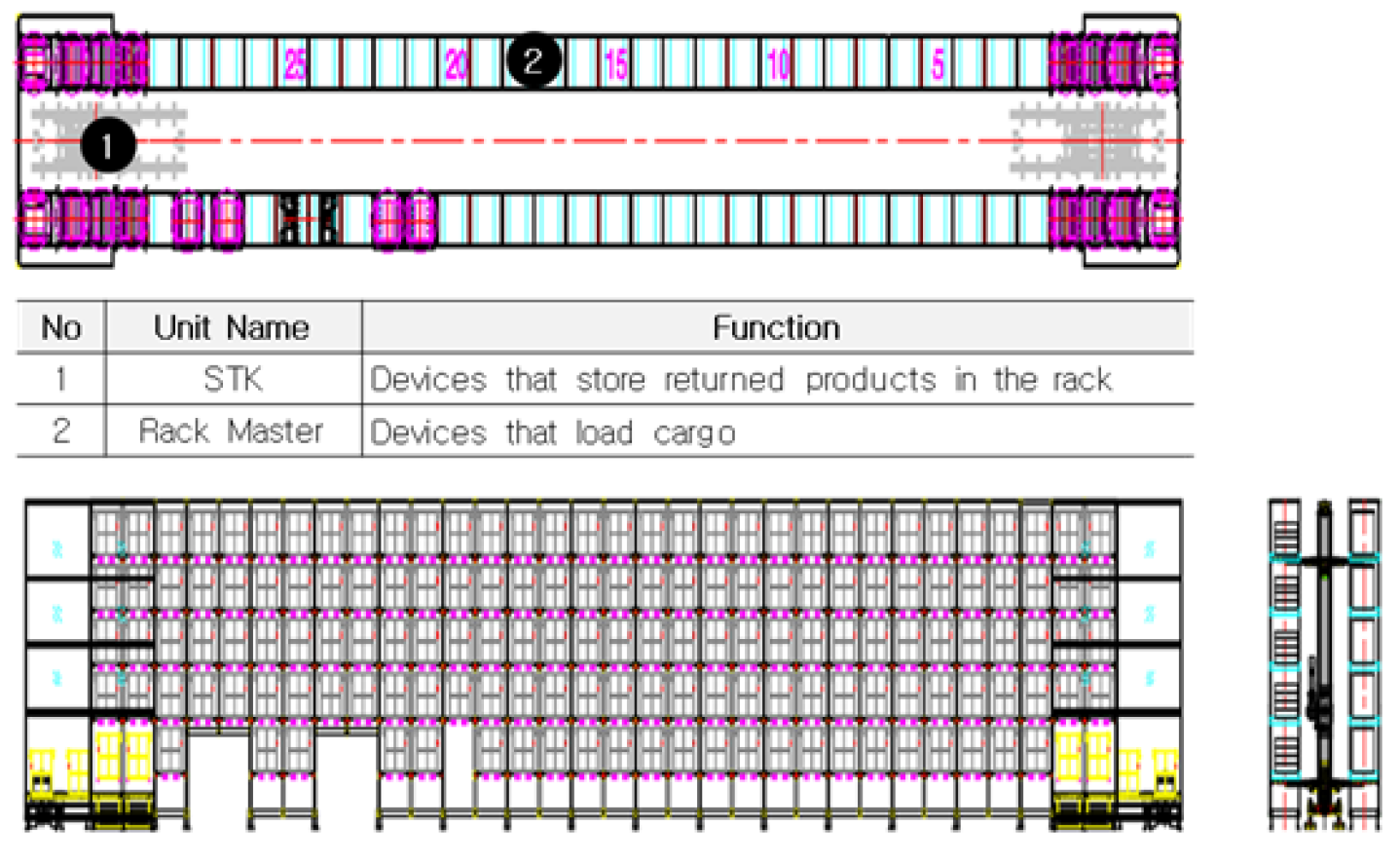
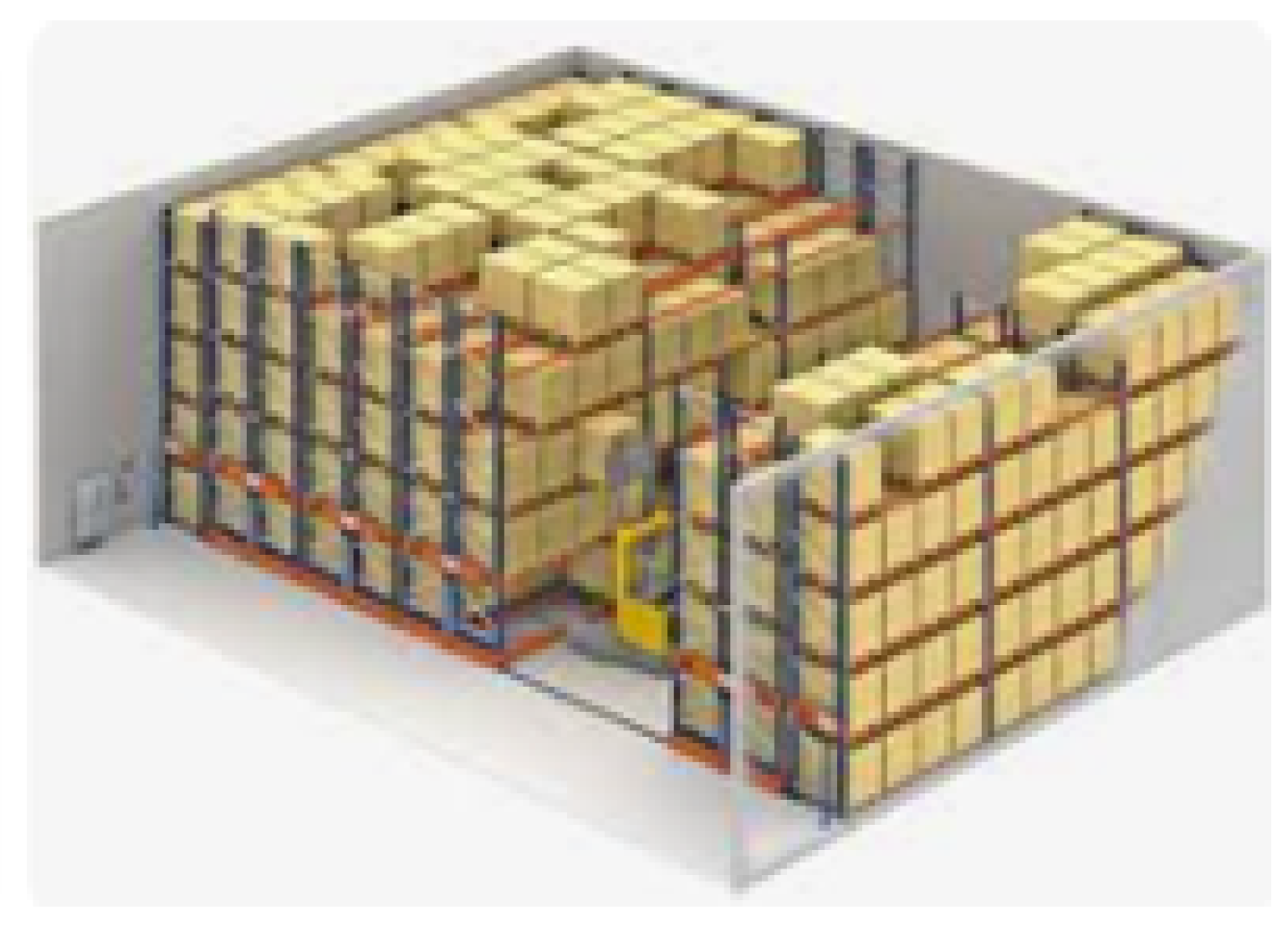
2.3. Storage Devices
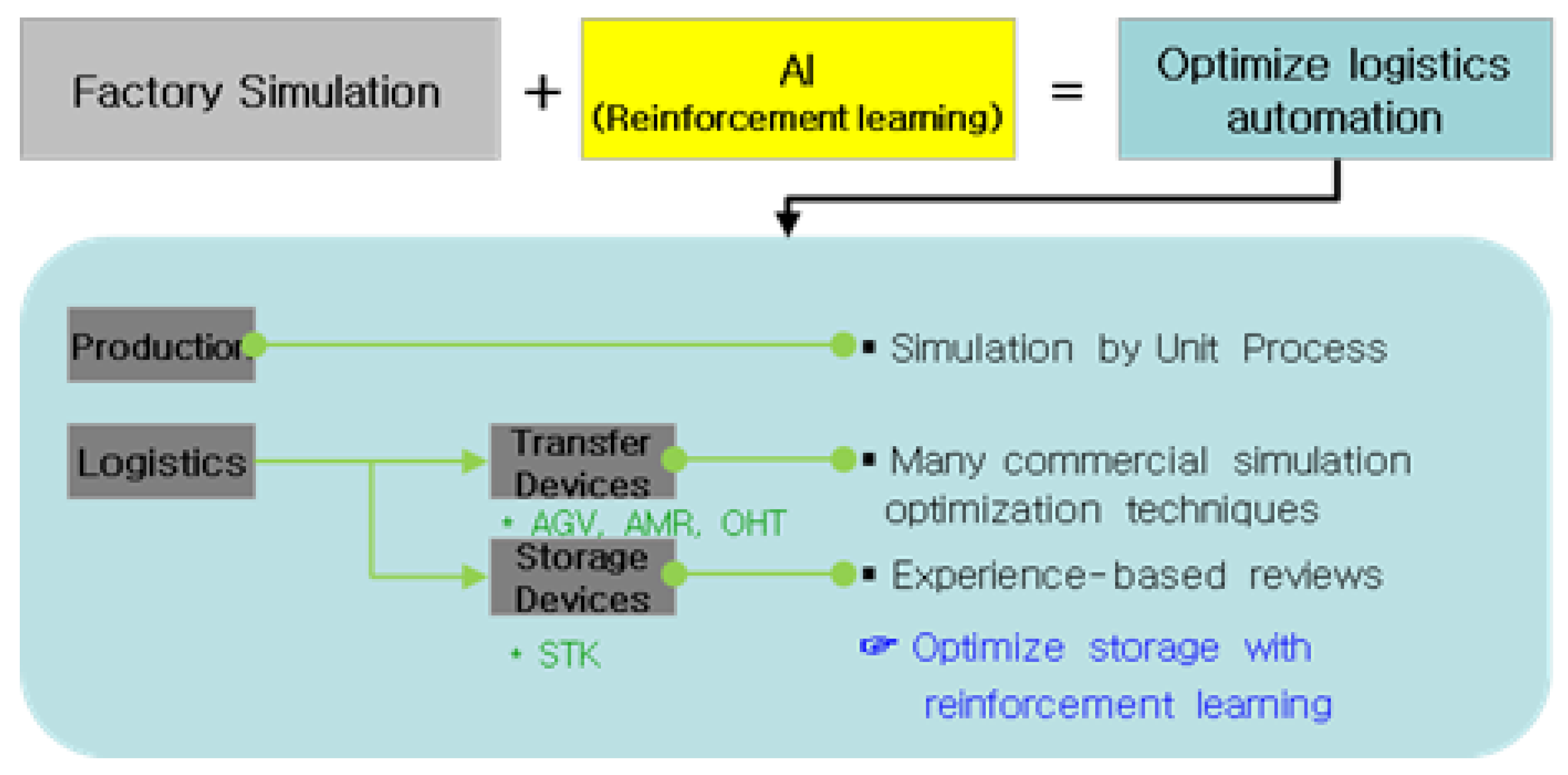
3. RL-Based Storage Optimization
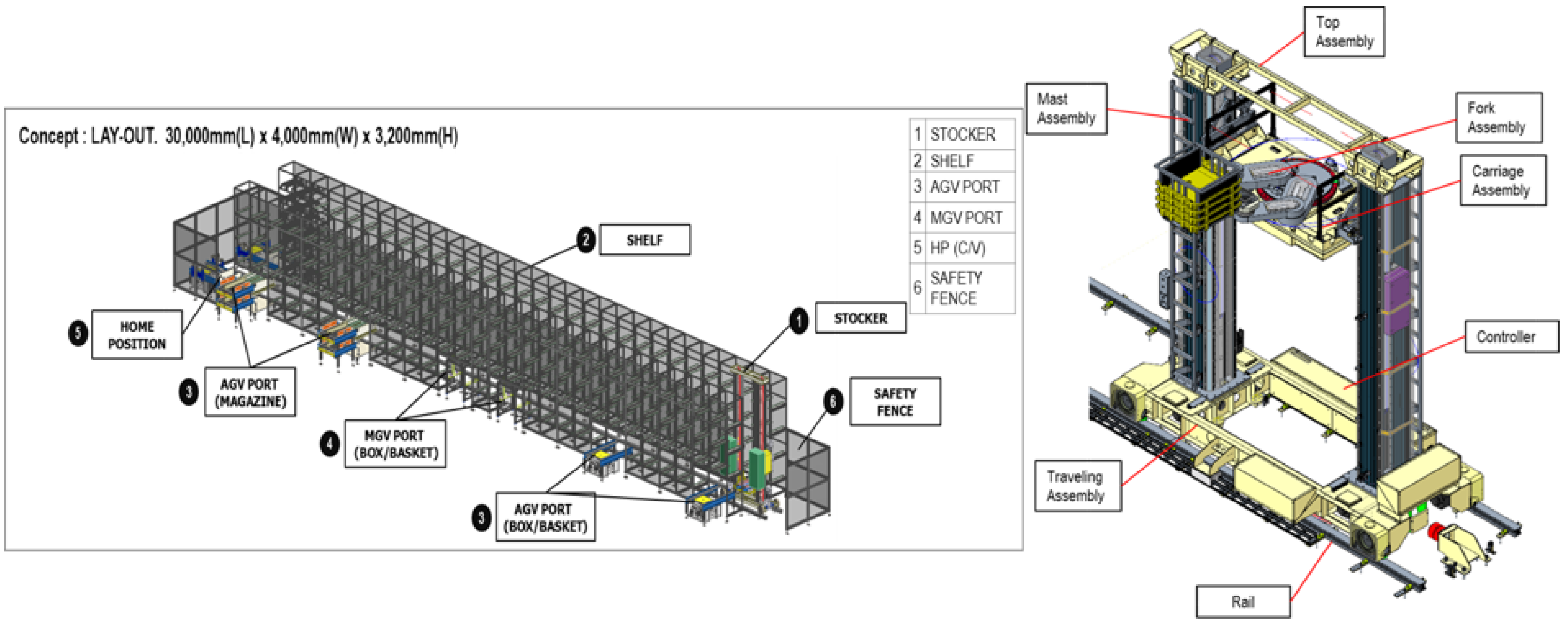
3.1. Overall Architecture
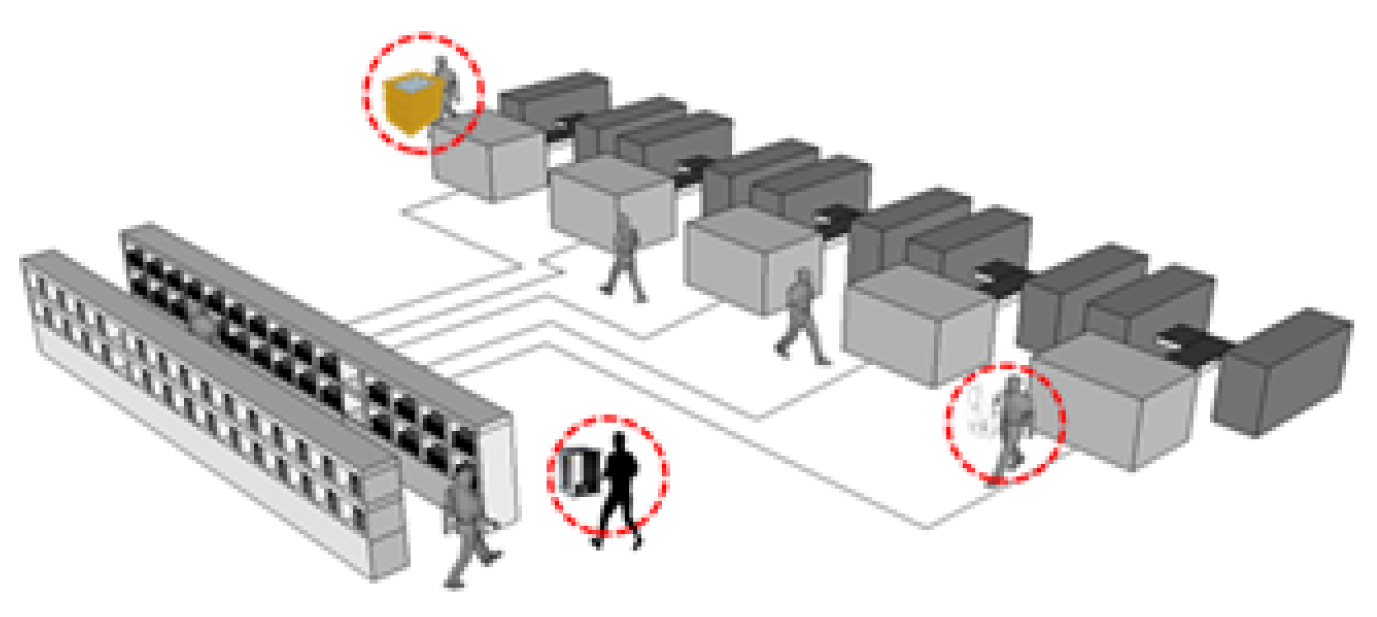
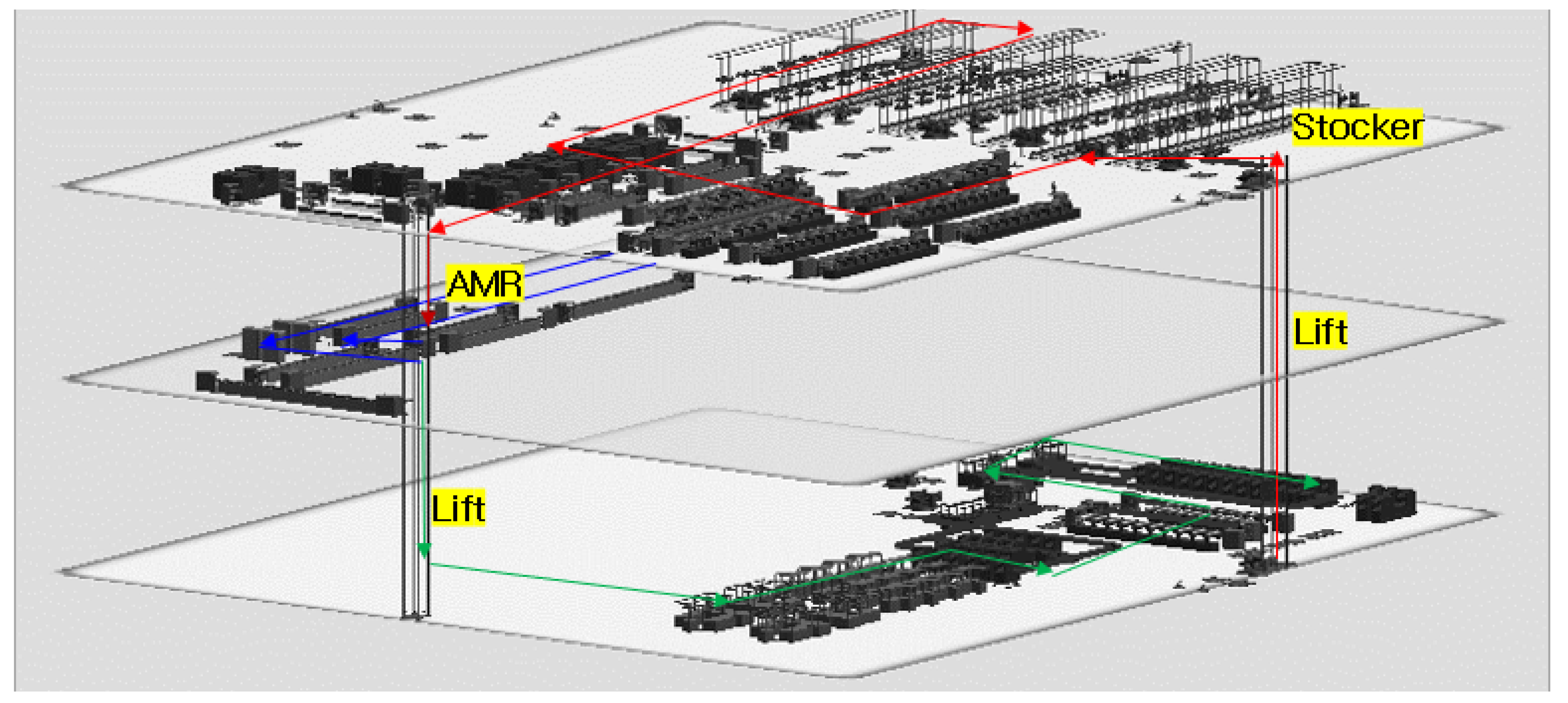
3.2. Virtual Factory Processes
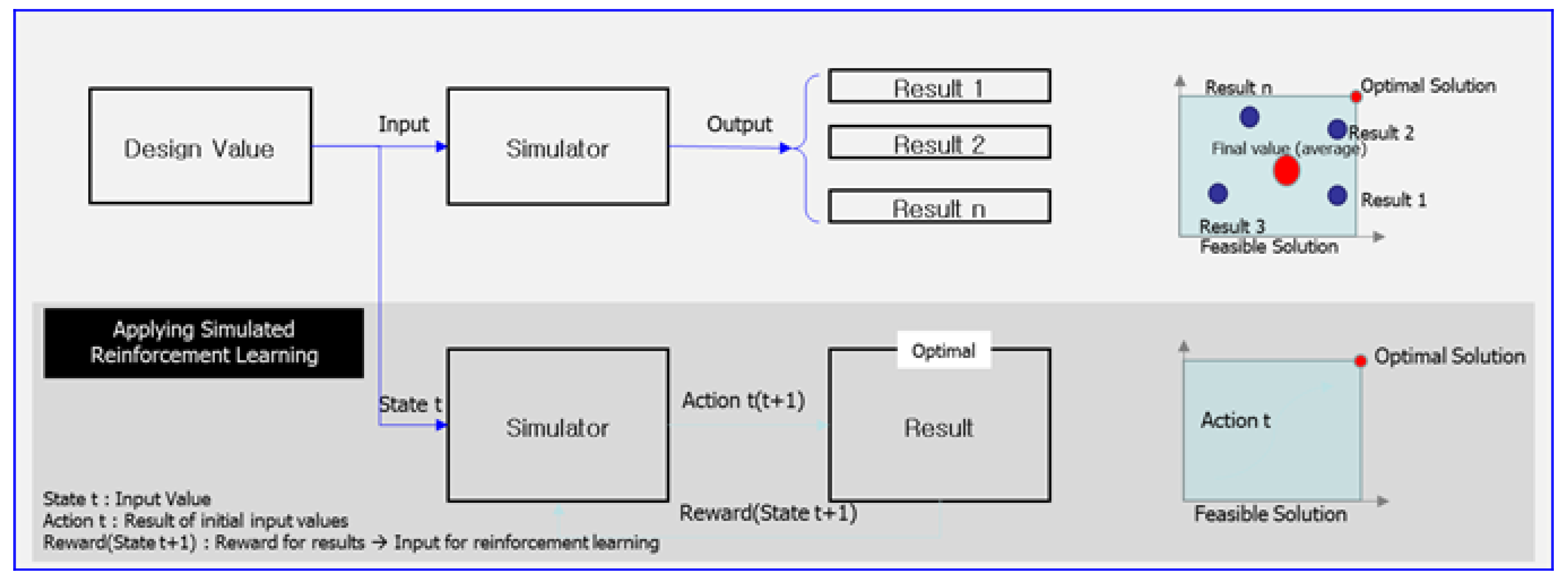
3.3. Applying AI Technology
4. Simulation and Results
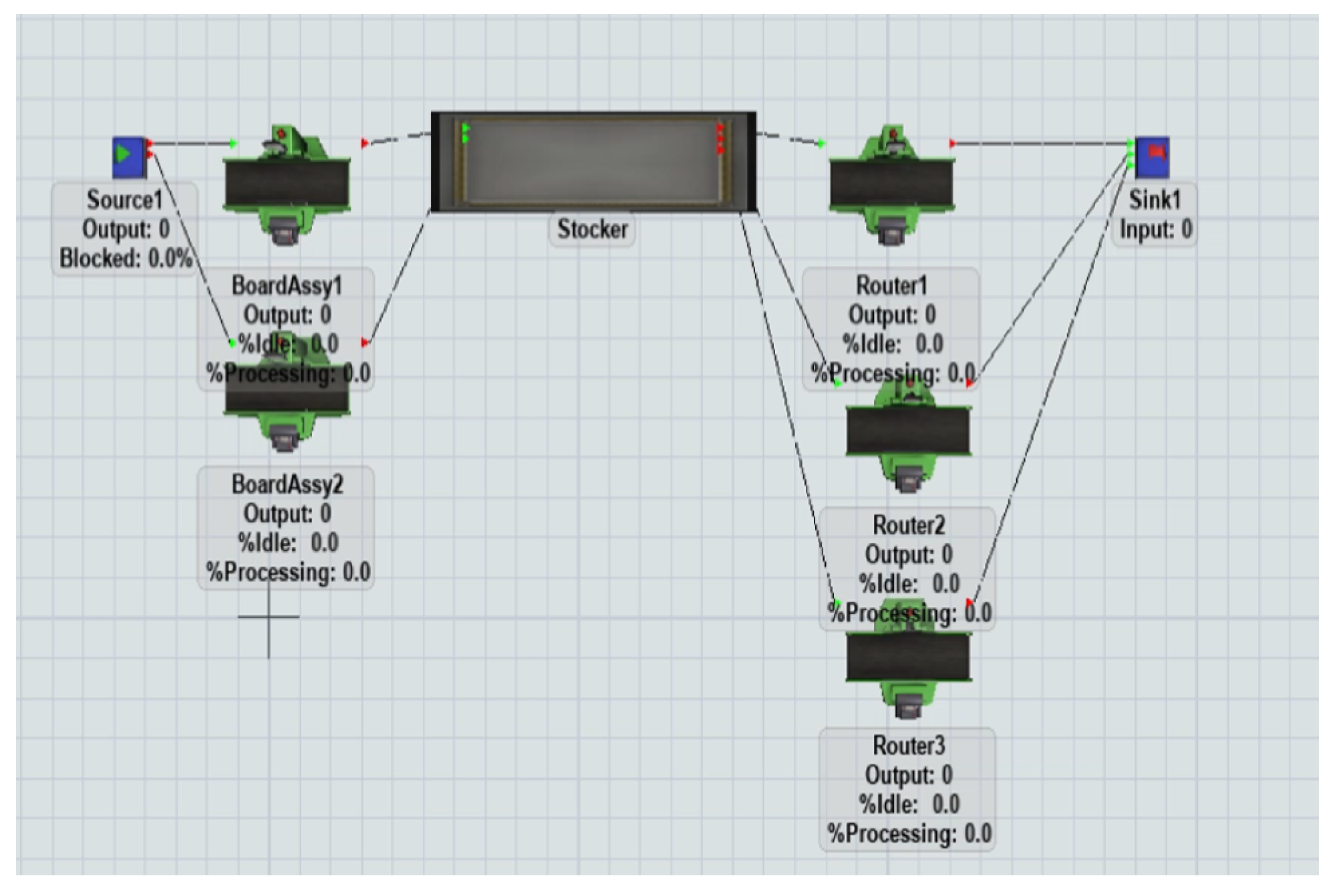
4.1. Simulation Environment
4.2. Performance Metrics
- -
- Average production per type;
- -
- Average stocker load;
- -
- Average buffer latency per type.
- -
- Router set-up time: 20 s;
- -
- Item generation: Type 1–4 with uniform probability;
- -
- Run time: 10 days (warm-up time of 3 days);
- -
- RL (PPO algorithm);
- -
- Time step (number of training times): 10,000 times;
- -
- Reward definition, illustrated below.
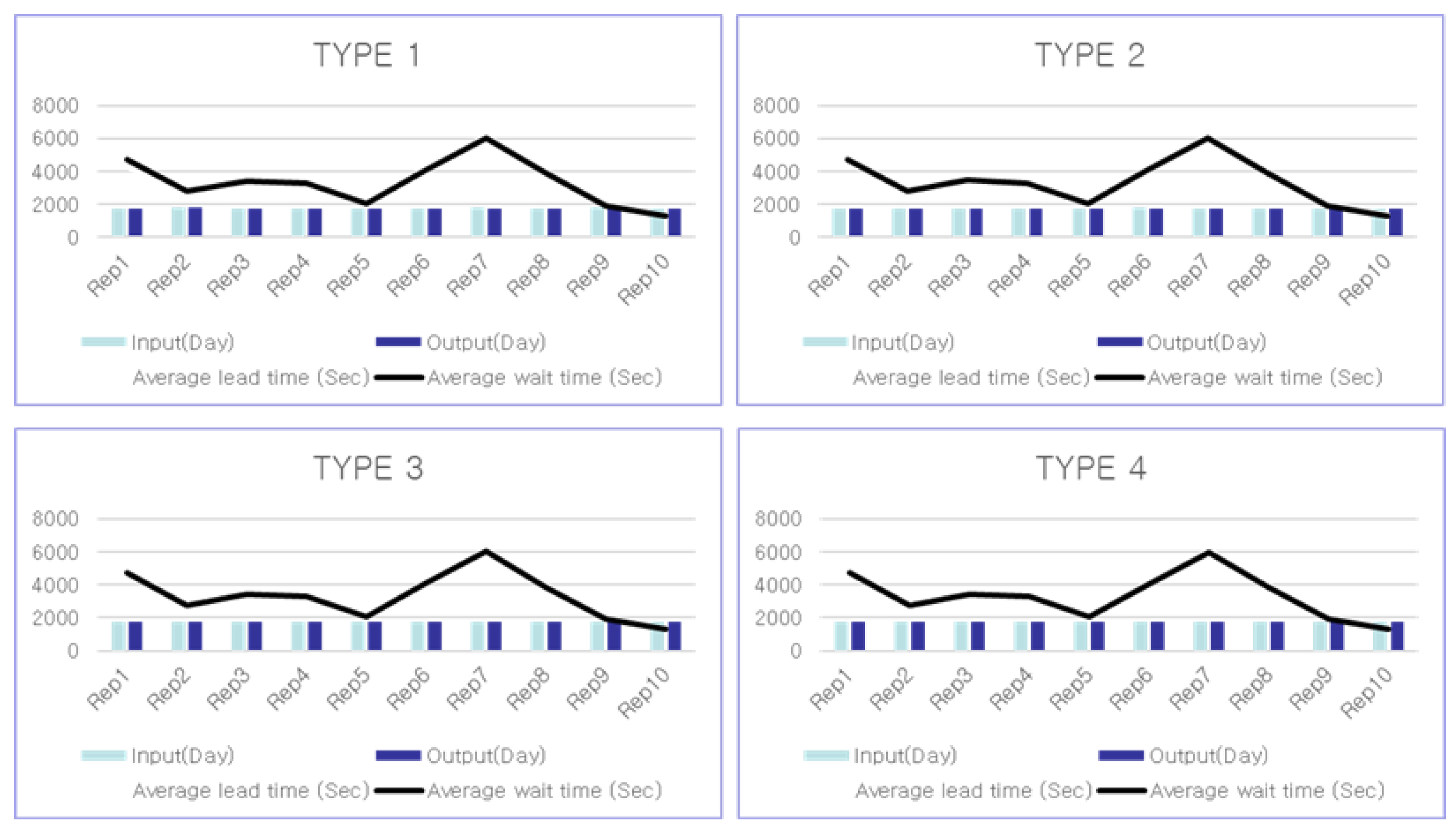
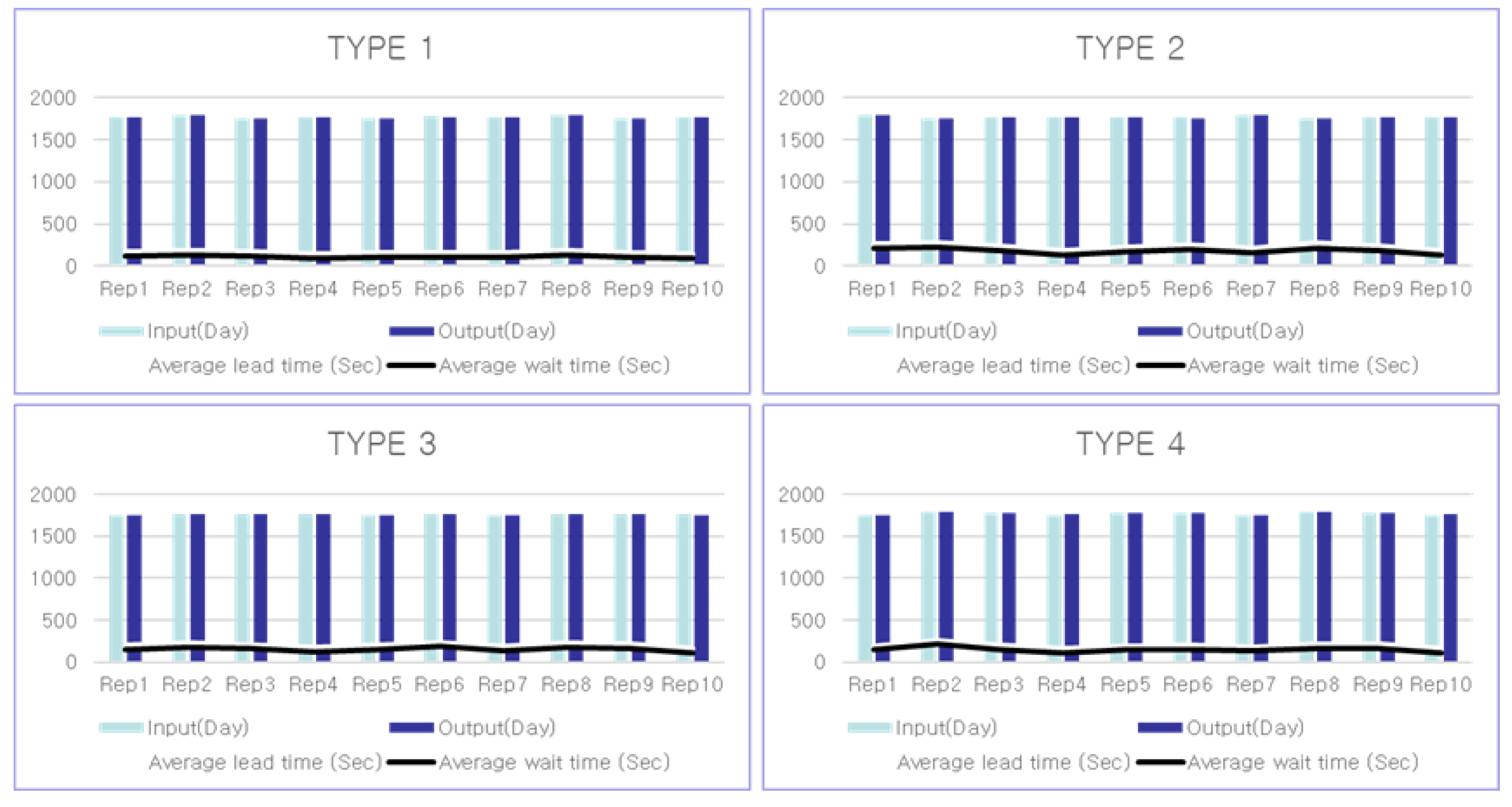
4.3. Results
4.4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Kamble, S.S.; Gunasekaran, A.; Parekh, H. Digital twin for sustainable manufacturing supply chains: Current trends, future perspectives, and an implementation framework. Technol. Forecast. Soc. Chang. 2022, 176, 121448. [Google Scholar] [CrossRef]
- Fragapane, G. Increasing flexibility and productivity in Industry 4.0 production networks with autonomous mobile robots and smart intralogistics. Ann. Oper. Res. 2022, 308, 125–143. [Google Scholar] [CrossRef]
- Xue, T.; Zeng, P.; Yu, H. A reinforcement learning method for multi-AGV scheduling in manufacturing. In Proceedings of the 2018 IEEE International Conference on Industrial Technology (ICIT), Lyon, France, 20–22 February 2018. [Google Scholar]
- Paritala, P.K.; Manchikatla, S.; Yarlagadda, P.K.D.V. Digital Manufacturing- Applications Past, Current, and Future Trends. Procedia Eng. 2017, 174, 982–991. [Google Scholar] [CrossRef]
- Arents, J.; Greitans, M. Smart Industrial Robot Control Trends, Challenges and Opportunities within Manufacturing. Appl. Sci. 2022, 12, 937. [Google Scholar] [CrossRef]
- Werth, B.; Karder, J.; Beham, A. Simulation-based Optimization of Material Requirements Planning Parameters. Procedia Comput. Sci. 2023, 217, 1117–1126. [Google Scholar] [CrossRef]
- Dotoli, M. An overview of current technologies and emerging trends in factory automation. Int. J. Prod. Res. 2019, 57, 5047–5067. [Google Scholar] [CrossRef]
- Wu, J.; Peng, Z.; Cui, D.; Li, Q.; He, J. A multi-object optimization cloud workflow scheduling algorithm based on reinforcement learning. In Proceedings of the International Conference on Intelligent Computing, Wuhan, China, 15–18 August 2018; Springer: Cham, Switzerland, 2018; pp. 550–559. [Google Scholar]
- Feldkamp, N.; Bergmann, S.; Strassburger, S. Simulation-based Deep Reinforcement Learning for Modular Production Systems. In Proceedings of the 2020 Winter Simulation Conference, Orlando, FL, USA, 14–18 December 2020; pp. 1596–1607. [Google Scholar]
- Tao, F.; Xiao, B.; Qi, Q. Digital twin modeling. J. Manuf. Syst. 2022, 64, 372–389. [Google Scholar] [CrossRef]
- Serrano-Ruiz, J.C.; Mula, J. Development of a multidimensional conceptual model for job shop smart manufacturing scheduling from the Industry 4.0 perspective. J. Manuf. Syst. 2022, 63, 185–202. [Google Scholar] [CrossRef]
- Cavalcante, I.M.; Frazzon, E.M.; Forcellini, F.A.; Ivanov, D. A supervised machine learning approach to data-driven simulation of resilient supplier selection in digital manufacturing. Int. J. Inf. Manag. 2019, 49, 86–97. [Google Scholar] [CrossRef]
- Huerta-Torruco, V.A.; Hernandez-Uribe, O.; Cardenas-Robledo, L.A.; Rodriguez-Olivares, N.A. Effectiveness of virtual reality in discrete event simulation models for manufacturing systems. Comput. Ind. Eng. 2022, 168, 108079. [Google Scholar] [CrossRef]
- de Ferreira, W.; Armellini, F.; de Santa-Eulalia, L.A. Extending the lean value stream mapping to the context of Industry 4.0: An agent-based technology approach. J. Manuf. Syst. 2022, 63, 1–14. [Google Scholar] [CrossRef]
- Available online: https://stevebong.tistory.com/4 (accessed on 1 August 2023).
- Available online: https://minsuksung-ai.tistory.com/13 (accessed on 1 August 2023).
- Chen, Y.-L.; Cai, Y.-R.; Cheng, M.-Y. Vision-Based Robotic Object Grasping—A Deep Reinforcement Learning Approach. Machines 2023, 11, 275. [Google Scholar] [CrossRef]
- Peyas, I.S.; Hasan, Z.; Tushar, M.R.R. Autonomous Warehouse Robot using Deep Q-Learning. In Proceedings of the TENCON 2021—2021 IEEE Region 10 Conference (TENCON), Auckland, New Zealand, 7–10 December 2021. [Google Scholar]
- Available online: https://velog.io/@baekgom/LIFO-%EC%84%A0%EC%9E%85%EC%84%A0%EC%B6%9C-FIFO-%ED%9B%84%EC%9E%85%EC%84%A0%EC%B6%9C (accessed on 1 August 2023).
- Utami, M.C.; Sabarkhah, D.R.; Fetrina, E.; Huda, M.Q. The Use of FIFO Method For Analysing and Designing the Inventory Information System. In Proceedings of the 2018 6th International Conference on Cyber and IT Service Management (CITSM), Parapat, Indonesia, 7–9 August 2018. [Google Scholar]
- Zhang, M.; Tao, F. Digital Twin Enhanced Dynamic Job-Shop Scheduling. J. Manuf. Syst. 2021, 58 Pt B, 146–156. [Google Scholar] [CrossRef]
- Yildiz, E.; Møller, C.; Bilberg, A. Virtual Factory: Digital Twin Based Integrated Factory Simulations. Procedia CIRP 2020, 93, 216–221. [Google Scholar] [CrossRef]
- Fahle, S.; Prinz, C.; Kuhlenkötter, B. Systematic review on machine learning (ML) methods for manufacturing processes—Identifying artificial intelligence (AI) methods for field application. Procedia CIRP 2020, 93, 413–418. [Google Scholar] [CrossRef]
- Jain, S.; Lechevalier, D. Standards based generation of a virtual factory model. In Proceedings of the 2016 Winter Simulation Conference (WSC), Washington, DC, USA, 11–14 December 2016. [Google Scholar]
- Leon, J.F.; Marone, P. A Tutorial on Combining Flexsim with Python for Developing Discrete-Event Simheuristics. In Proceedings of the 2022 Winter Simulation Conference (WSC), Singapore, 11–14 December 2022. [Google Scholar]
- Sławomir, L.; Vitalii, I. A simulation study of Industry 4.0 factories based on the ontology on flexibility with using FlexSim® software. Manag. Prod. Eng. Rev. 2020, 11, 74–83. [Google Scholar]
- Belsare, S.; Badilla, E.D. Reinforcement Learning with Discrete Event Simulation: The Premise, Reality, and Promise. In Proceedings of the 2022 Winter Simulation Conference (WSC), Singapore, 11–14 December 2022. [Google Scholar]
- Park, J.-S.; Kim, J.-W. Developing Reinforcement Learning based Job Allocation Model by Using FlexSim Software. In Proceedings of the Winter Conference of the Korea Computer Information Society, Daegwallyeong, Republic of Korea, 8–10 February 2023; Volume 31. [Google Scholar]
- Available online: https://ropiens.tistory.com/85 (accessed on 1 August 2023).
- Krenczyk, D.; Paprocka, I. Integration of Discrete Simulation, Prediction, and Optimization Methods for a Production Line Digital Twin Design. Materials 2023, 16, 2339. [Google Scholar] [CrossRef] [PubMed]
- Mayer, S.; Classen, T.; Endisch, C. Modular production control using deep reinforcement learning: Proximal policy optimization. J. Intell. Manuf. 2021, 32, 2335–2351. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhu, H. Dynamic job shop scheduling based on deep reinforcement learning for multi-agent manufacturing systems. Robot. Comput.-Integr. Manuf. 2022, 78, 102412. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Item | Board Assembly | Router |
|---|---|---|
| Type 1 | 20 | 19 |
| Type 2 | 17 | 25 |
| Type 3 | 14 | 23 |
| Type 4 | 15 | 21 |
| Item | Input | Output | Average | |
|---|---|---|---|---|
| Lead Time (s) | Wait Time (s) | |||
| Type 1 | 1766 | 1757 | 3351 | 3347 |
| Type 2 | 1760 | 1754 | 3406 | 3349 |
| Type 3 | 1756 | 1749 | 3400 | 3348 |
| Type 4 | 1754 | 1748 | 3400 | 3349 |
| Item | Input | Output | Average | ||
|---|---|---|---|---|---|
| Lead Time (s) | Wait Time (s) | Waiting Quantity | |||
| Result | 7034 | 7009 | 3402 | 3348 | 272 |
| Item | Input | Output | Average | |
|---|---|---|---|---|
| Lead Time (s) | Wait Time (s) | |||
| Type 1 | 1767 | 1767 | 159 | 106 |
| Type 2 | 1760 | 1767 | 233 | 176 |
| Type 3 | 1756 | 1756 | 204 | 152 |
| Type 4 | 1766 | 1766 | 198 | 148 |
| Item | Input | Output | Average | ||
|---|---|---|---|---|---|
| Lead Time (s) | Wait Time (s) | Waiting Quantity | |||
| Result | 7058 | 7058 | 198 | 145 | 12 |
| Item | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Time Step | 0 | 1000 | 2000 | 3000 | 4000 | 5000 | 6000 | 7000 | 8000 | 9000 | 10,000 |
| Average STK W/Q | 278 | 68 | 68 | 24 | 23 | 23 | 20 | 17 | 13 | 9 | 9 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lim, J.-B.; Jeong, J. Factory Simulation of Optimization Techniques Based on Deep Reinforcement Learning for Storage Devices. Appl. Sci. 2023, 13, 9690. https://doi.org/10.3390/app13179690
Lim J-B, Jeong J. Factory Simulation of Optimization Techniques Based on Deep Reinforcement Learning for Storage Devices. Applied Sciences. 2023; 13(17):9690. https://doi.org/10.3390/app13179690
Chicago/Turabian StyleLim, Ju-Bin, and Jongpil Jeong. 2023. "Factory Simulation of Optimization Techniques Based on Deep Reinforcement Learning for Storage Devices" Applied Sciences 13, no. 17: 9690. https://doi.org/10.3390/app13179690
APA StyleLim, J.-B., & Jeong, J. (2023). Factory Simulation of Optimization Techniques Based on Deep Reinforcement Learning for Storage Devices. Applied Sciences, 13(17), 9690. https://doi.org/10.3390/app13179690